 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Successful Nash Equilibrium Agent for a 3-Player Imperfect-Information Game
Apr 13, 2018

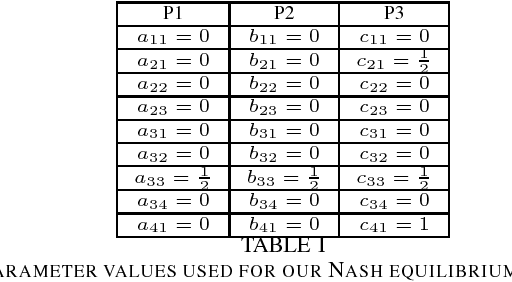
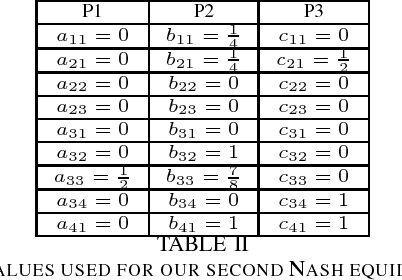
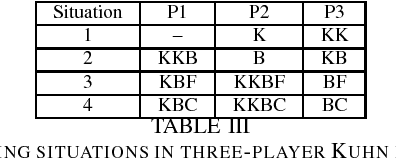
Creating strong agents for games with more than two players is a major open problem in AI. Common approaches are based on approximating game-theoretic solution concepts such as Nash equilibrium, which have strong theoretical guarantees in two-player zero-sum games, but no guarantees in non-zero-sum games or in games with more than two players. We describe an agent that is able to defeat a variety of realistic opponents using an exact Nash equilibrium strategy in a 3-player imperfect-information game. This shows that, despite a lack of theoretical guarantees, agents based on Nash equilibrium strategies can be successful in multiplayer games after all.
3D-to-2D Distillation for Indoor Scene Parsing
Apr 07, 2021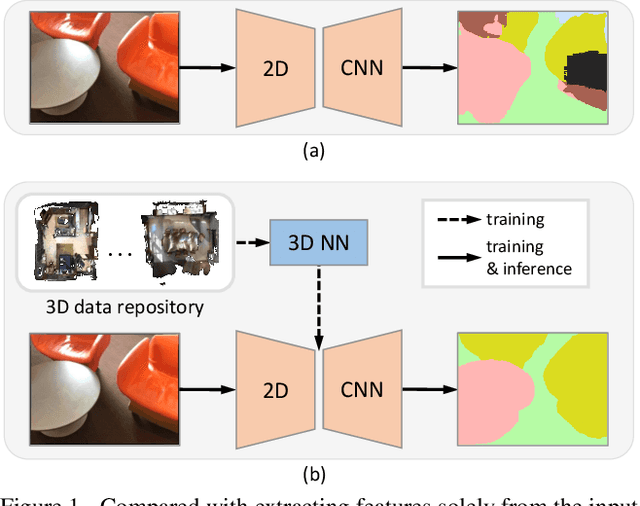

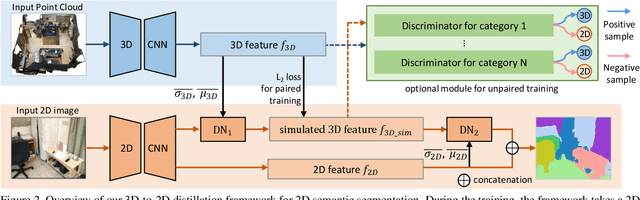
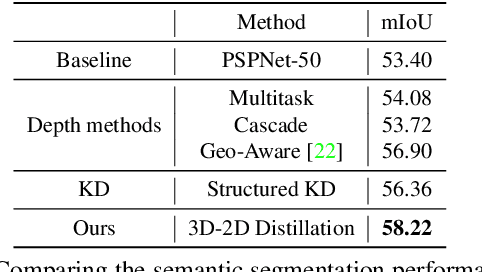
Indoor scene semantic parsing from RGB images is very challenging due to occlusions, object distortion, and viewpoint variations. Going beyond prior works that leverage geometry information, typically paired depth maps, we present a new approach, a 3D-to-2D distillation framework, that enables us to leverage 3D features extracted from large-scale 3D data repository (e.g., ScanNet-v2) to enhance 2D features extracted from RGB images. Our work has three novel contributions. First, we distill 3D knowledge from a pretrained 3D network to supervise a 2D network to learn simulated 3D features from 2D features during the training, so the 2D network can infer without requiring 3D data. Second, we design a two-stage dimension normalization scheme to calibrate the 2D and 3D features for better integration. Third, we design a semantic-aware adversarial training model to extend our framework for training with unpaired 3D data. Extensive experiments on various datasets, ScanNet-V2, S3DIS, and NYU-v2, demonstrate the superiority of our approach. Also, experimental results show that our 3D-to-2D distillation improves the model generalization.
Privacy-Preserving Portrait Matting
Apr 29, 2021



Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting. P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization capabilities when following the Privacy-Preserving Training (PPT) setting, i.e., "training on face-blurred images and testing on arbitrary images". To devise a better trimap-free portrait matting model, we propose P3M-Net, which leverages the power of a unified framework for both semantic perception and detail matting, and specifically emphasizes the interaction between them and the encoder to facilitate the matting process. Extensive experiments on P3M-10k demonstrate that P3M-Net outperforms the state-of-the-art methods in terms of both objective metrics and subjective visual quality. Besides, it shows good generalization capacity under the PPT setting, confirming the value of P3M-10k for facilitating future research and enabling potential real-world applications. The source code and dataset will be made publicly available.
Weakly-supervised Salient Instance Detection
Sep 29, 2020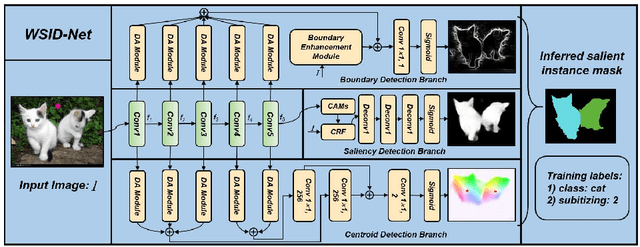
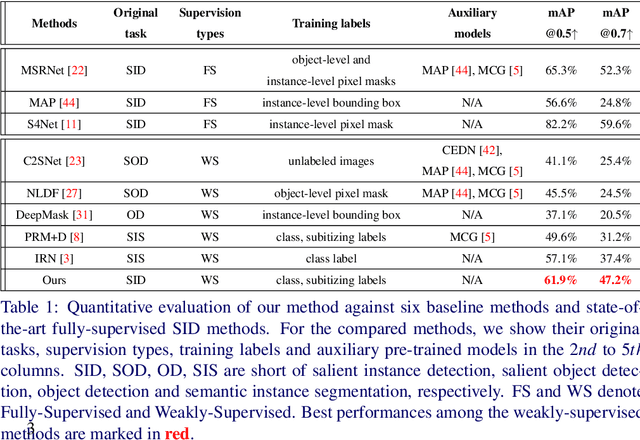

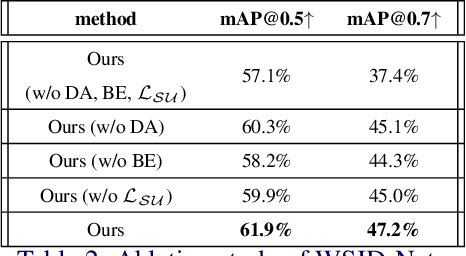
Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. We note that subitizing information provides an instant judgement on the number of salient items, which naturally relates to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this insight, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is further fused to produce salient instance maps. We conduct extensive experiments to demonstrate that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
KLearn: Background Knowledge Inference from Summarization Data
Oct 13, 2020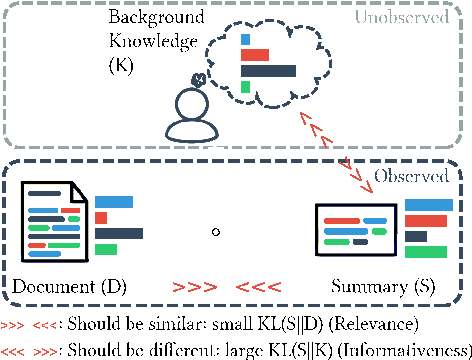
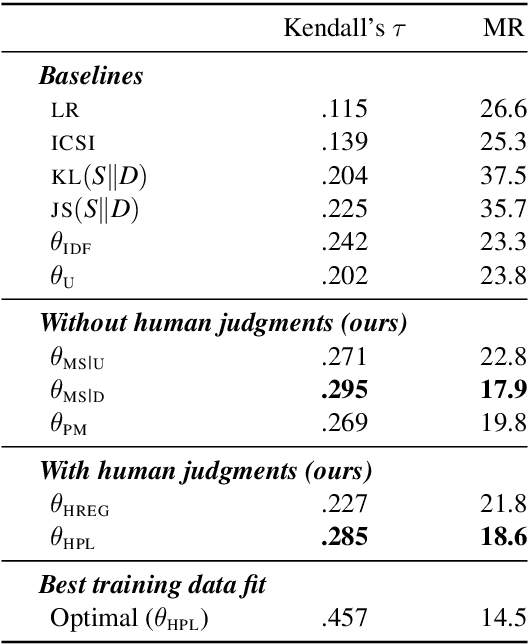
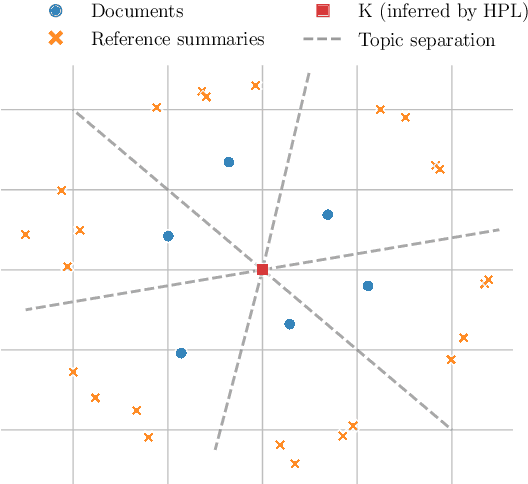
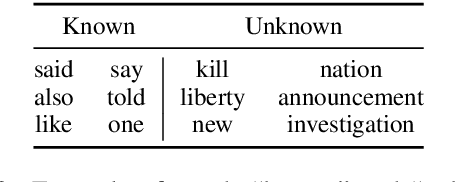
The goal of text summarization is to compress documents to the relevant information while excluding background information already known to the receiver. So far, summarization researchers have given considerably more attention to relevance than to background knowledge. In contrast, this work puts background knowledge in the foreground. Building on the realization that the choices made by human summarizers and annotators contain implicit information about their background knowledge, we develop and compare techniques for inferring background knowledge from summarization data. Based on this framework, we define summary scoring functions that explicitly model background knowledge, and show that these scoring functions fit human judgments significantly better than baselines. We illustrate some of the many potential applications of our framework. First, we provide insights into human information importance priors. Second, we demonstrate that averaging the background knowledge of multiple, potentially biased annotators or corpora greatly improves summary-scoring performance. Finally, we discuss potential applications of our framework beyond summarization.
Occupancy Detection in Room Using Sensor Data
Jan 10, 2021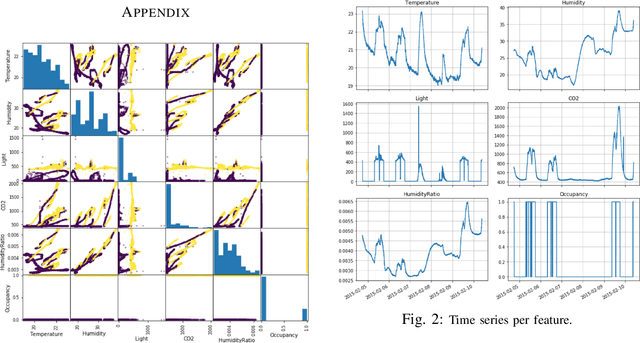
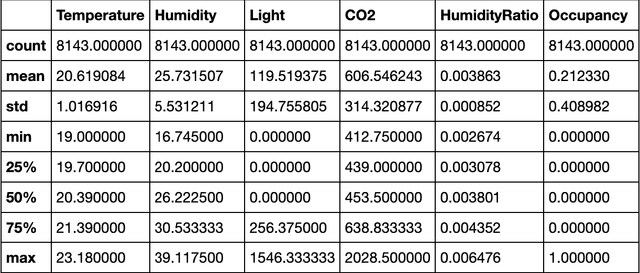
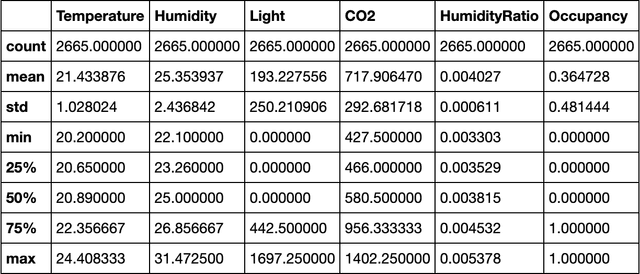
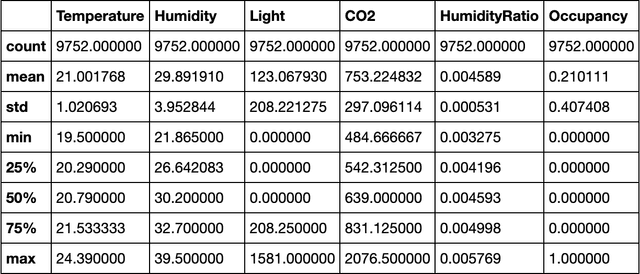
With the advent of Internet of Thing (IoT), and ubiquitous data collected every moment by either portable (smart phone) or fixed (sensor) devices, it is important to gain insights and meaningful information from the sensor data in context-aware computing environments. Many researches have been implemented by scientists in different fields, to analyze such data for the purpose of security, energy efficiency, building reliability and smart environments. One study, that many researchers are interested in, is to utilize Machine Learning techniques for occupancy detection where the aforementioned sensors gather information about the environment. This paper provides a solution to detect occupancy using sensor data by using and testing several variables. Additionally we show the analysis performed over the gathered data using Machine Learning and pattern recognition mechanisms is possible to determine the occupancy of indoor environments. Seven famous algorithms in Machine Learning, namely as Decision Tree, Random Forest, Gradient Boosting Machine, Logistic Regression, Naive Bayes, Kernelized SVM and K-Nearest Neighbors are tested and compared in this study.
Three-class Overlapped Speech Detection using a Convolutional Recurrent Neural Network
Apr 07, 2021
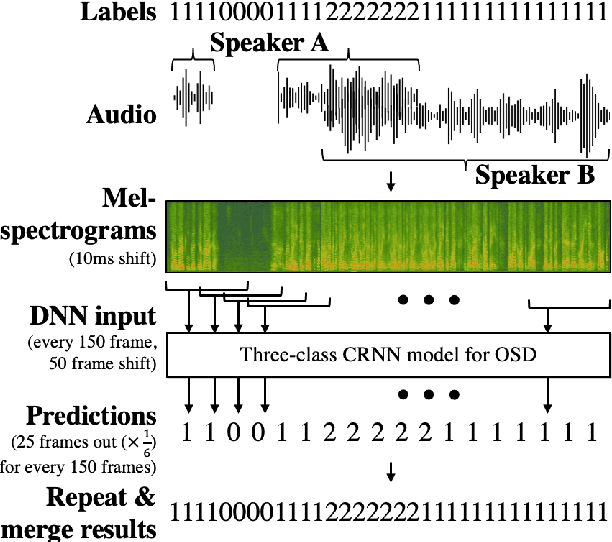
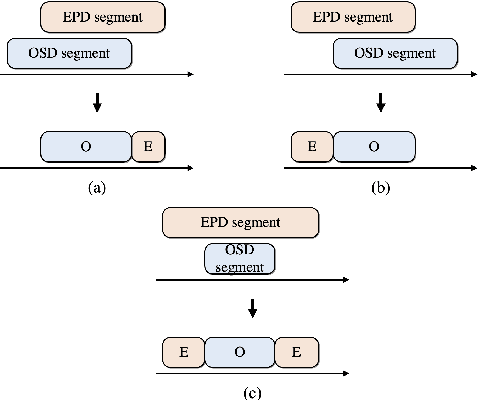
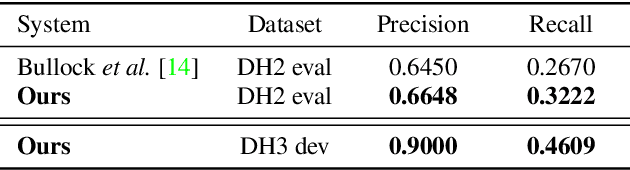
In this work, we propose an overlapped speech detection system trained as a three-class classifier. Unlike conventional systems that perform binary classification as to whether or not a frame contains overlapped speech, the proposed approach classifies into three classes: non-speech, single speaker speech, and overlapped speech. By training a network with the more detailed label definition, the model can learn a better notion on deciding the number of speakers included in a given frame. A convolutional recurrent neural network architecture is explored to benefit from both convolutional layer's capability to model local patterns and recurrent layer's ability to model sequential information. The proposed overlapped speech detection model establishes a state-of-the-art performance with a precision of 0.6648 and a recall of 0.3222 on the DIHARD II evaluation set, showing a 20% increase in recall along with higher precision. In addition, we also introduce a simple approach to utilize the proposed overlapped speech detection model for speaker diarization which ranked third place in the Track 1 of the DIHARD III challenge.
FocusedDropout for Convolutional Neural Network
Mar 29, 2021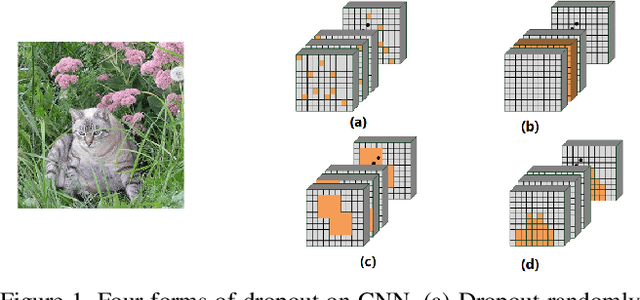
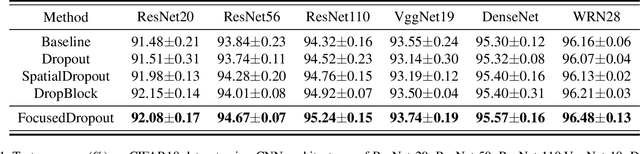
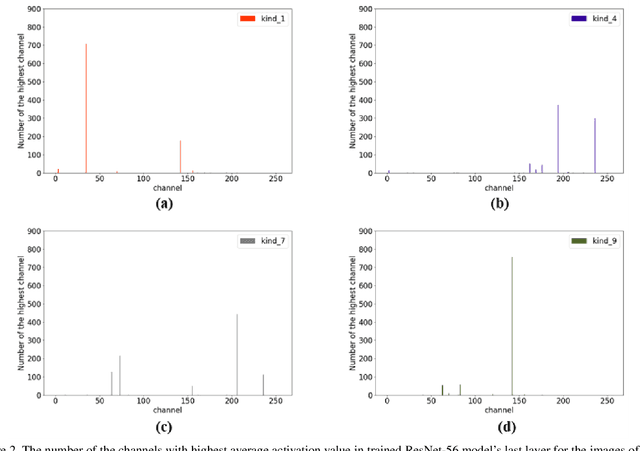
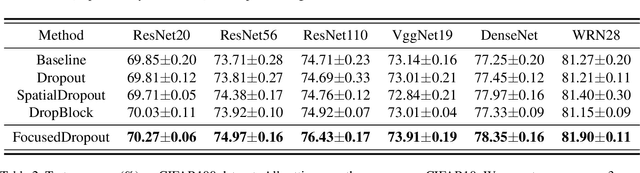
In convolutional neural network (CNN), dropout cannot work well because dropped information is not entirely obscured in convolutional layers where features are correlated spatially. Except randomly discarding regions or channels, many approaches try to overcome this defect by dropping influential units. In this paper, we propose a non-random dropout method named FocusedDropout, aiming to make the network focus more on the target. In FocusedDropout, we use a simple but effective way to search for the target-related features, retain these features and discard others, which is contrary to the existing methods. We found that this novel method can improve network performance by making the network more target-focused. Besides, increasing the weight decay while using FocusedDropout can avoid the overfitting and increase accuracy. Experimental results show that even a slight cost, 10\% of batches employing FocusedDropout, can produce a nice performance boost over the baselines on multiple datasets of classification, including CIFAR10, CIFAR100, Tiny Imagenet, and has a good versatility for different CNN models.
Capturing Multi-Resolution Context by Dilated Self-Attention
Apr 07, 2021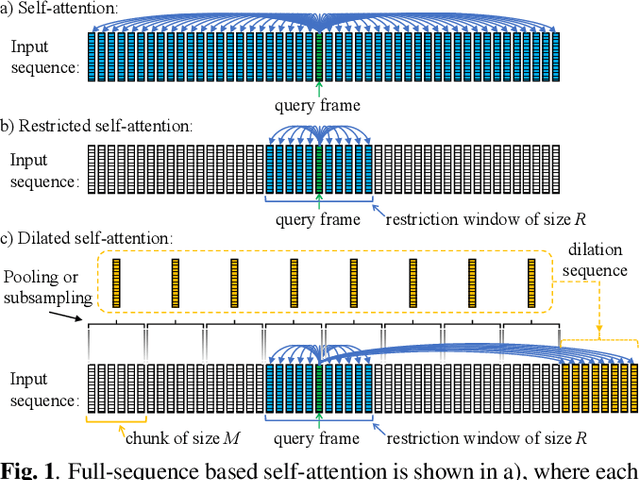
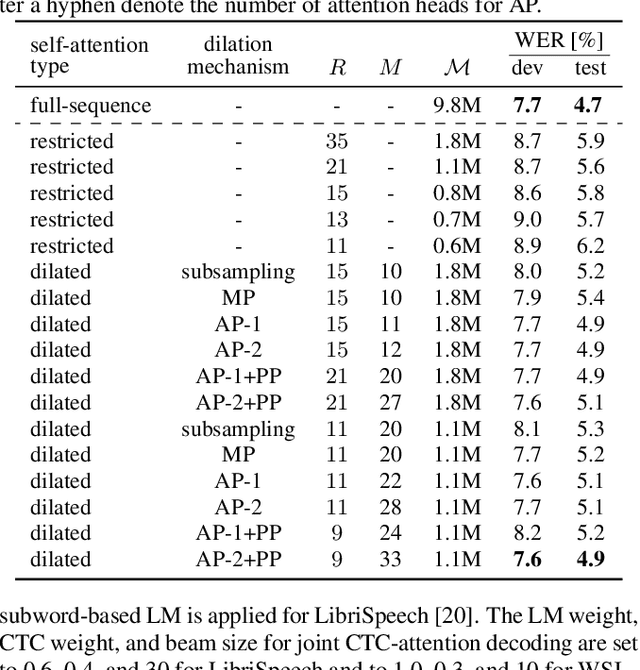
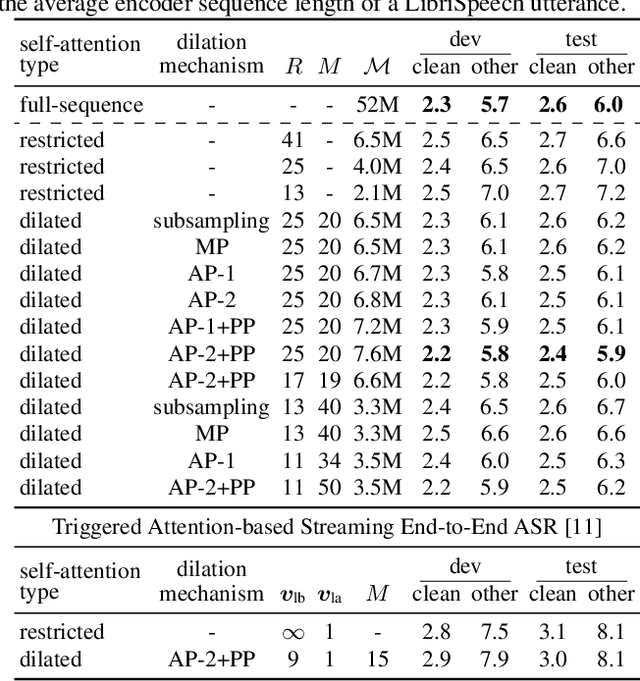
Self-attention has become an important and widely used neural network component that helped to establish new state-of-the-art results for various applications, such as machine translation and automatic speech recognition (ASR). However, the computational complexity of self-attention grows quadratically with the input sequence length. This can be particularly problematic for applications such as ASR, where an input sequence generated from an utterance can be relatively long. In this work, we propose a combination of restricted self-attention and a dilation mechanism, which we refer to as dilated self-attention. The restricted self-attention allows attention to neighboring frames of the query at a high resolution, and the dilation mechanism summarizes distant information to allow attending to it with a lower resolution. Different methods for summarizing distant frames are studied, such as subsampling, mean-pooling, and attention-based pooling. ASR results demonstrate substantial improvements compared to restricted self-attention alone, achieving similar results compared to full-sequence based self-attention with a fraction of the computational costs.
Rank Minimization-based Toeplitz Reconstruction for DoA Estimation Using Coprime Array
Mar 29, 2021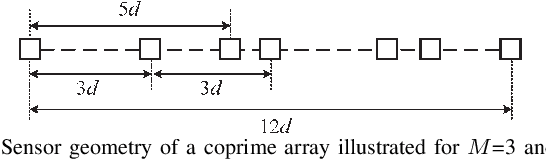
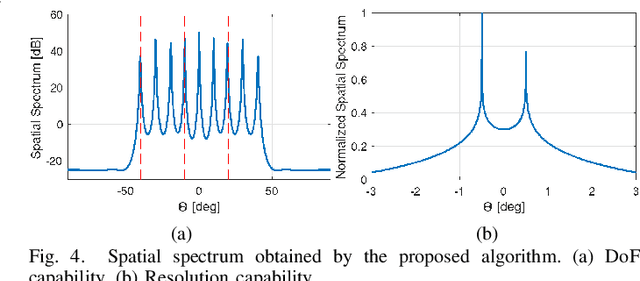
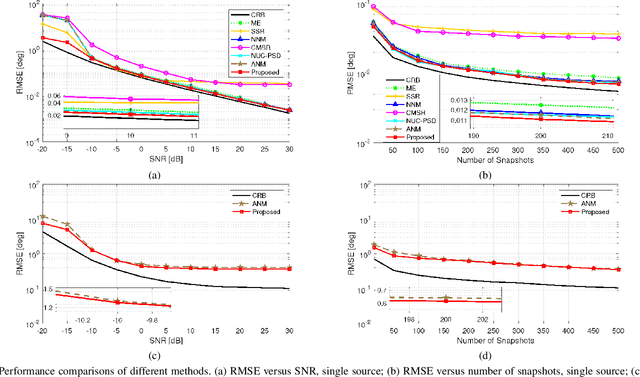
In this paper, we address the problem of direction finding using coprime array, which is one of the most preferred sparse array configurations. Motivated by the fact that non-uniform element spacing hinders full utilization of the underlying information in the receive signals, we propose a direction-of-arrival (DoA) estimation algorithm based on low-rank reconstruction of the Toeplitz covariance matrix. The atomic-norm representation of the measurements from the interpolated virtual array is considered, and the equivalent dual-variable rank minimization problem is formulated and solved using a cyclic optimization approach. The recovered covariance matrix enables the application of conventional subspace-based spectral estimation algorithms, such as MUSIC, to achieve enhanced DoA estimation performance. The estimation performance of the proposed approach, in terms of the degrees-of-freedom and spatial resolution, is examined. We also show the superiority of the proposed method over the competitive approaches in the root-mean-square error sense.