 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification
Apr 23, 2021



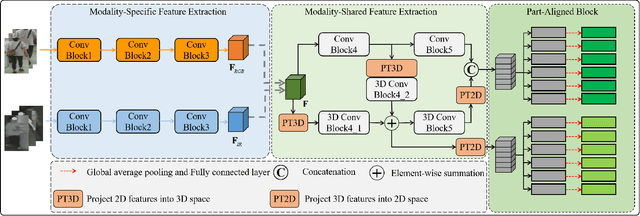
Most existing cross-modality person re-identification works rely on discriminative modality-shared features for reducing cross-modality variations and intra-modality variations. Despite some initial success, such modality-shared appearance features cannot capture enough modality-invariant discriminative information due to a massive discrepancy between RGB and infrared images. To address this issue, on the top of appearance features, we further capture the modality-invariant relations among different person parts (referred to as modality-invariant relation features), which are the complement to those modality-shared appearance features and help to identify persons with similar appearances but different body shapes. To this end, a Multi-level Two-streamed Modality-shared Feature Extraction (MTMFE) sub-network is designed, where the modality-shared appearance features and modality-invariant relation features are first extracted in a shared 2D feature space and a shared 3D feature space, respectively. The two features are then fused into the final modality-shared features such that both cross-modality variations and intra-modality variations can be reduced. Besides, a novel cross-modality quadruplet loss is proposed to further reduce the cross-modality variations. Experimental results on several benchmark datasets demonstrate that our proposed method exceeds state-of-the-art algorithms by a noticeable margin.
A generalised log-determinant regularizer for online semi-definite programming and its applications
Dec 11, 2020We consider a variant of online semi-definite programming problem (OSDP): The decision space consists of semi-definite matrices with bounded $\Gamma$-trace norm, which is a generalization of trace norm defined by a positive definite matrix $\Gamma.$ To solve this problem, we utilise the follow-the-regularized-leader algorithm with a $\Gamma$-dependent log-determinant regularizer. Then we apply our generalised setting and our proposed algorithm to online matrix completion(OMC) and online similarity prediction with side information. In particular, we reduce the online matrix completion problem to the generalised OSDP problem, and the side information is represented as the $\Gamma$ matrix. Hence, due to our regret bound for the generalised OSDP, we obtain an optimal mistake bound for the OMC by removing the logarithmic factor.
Persistent Homology and Graphs Representation Learning
Feb 25, 2021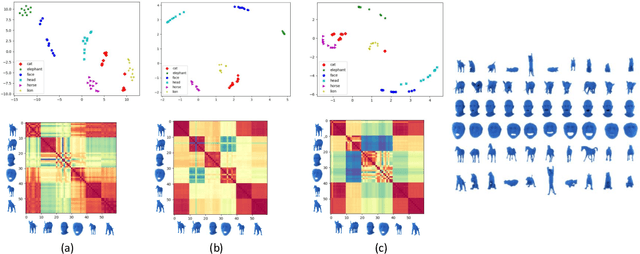
This article aims to study the topological invariant properties encoded in node graph representational embeddings by utilizing tools available in persistent homology. Specifically, given a node embedding representation algorithm, we consider the case when these embeddings are real-valued. By viewing these embeddings as scalar functions on a domain of interest, we can utilize the tools available in persistent homology to study the topological information encoded in these representations. Our construction effectively defines a unique persistence-based graph descriptor, on both the graph and node levels, for every node representation algorithm. To demonstrate the effectiveness of the proposed method, we study the topological descriptors induced by DeepWalk, Node2Vec and Diff2Vec.
AVA: Adversarial Vignetting Attack against Visual Recognition
May 12, 2021
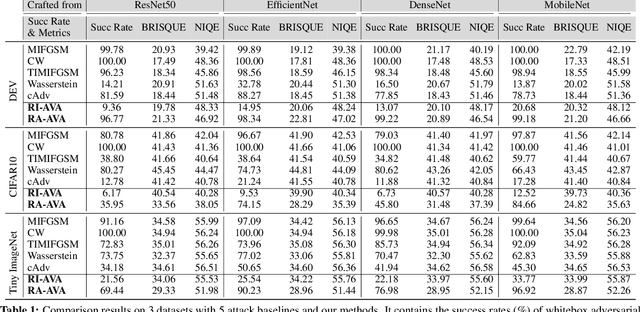
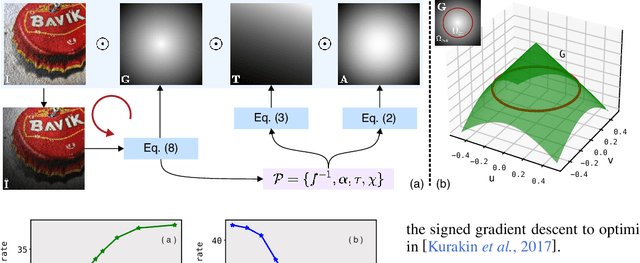
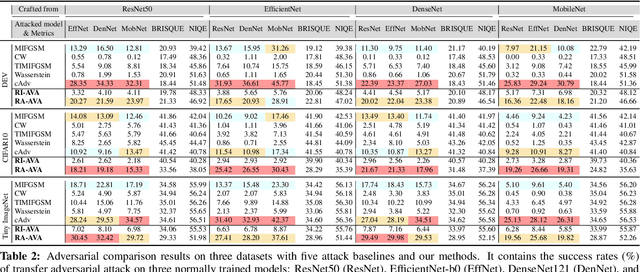
Vignetting is an inherited imaging phenomenon within almost all optical systems, showing as a radial intensity darkening toward the corners of an image. Since it is a common effect for photography and usually appears as a slight intensity variation, people usually regard it as a part of a photo and would not even want to post-process it. Due to this natural advantage, in this work, we study vignetting from a new viewpoint, i.e., adversarial vignetting attack (AVA), which aims to embed intentionally misleading information into vignetting and produce a natural adversarial example without noise patterns. This example can fool the state-of-the-art deep convolutional neural networks (CNNs) but is imperceptible to humans. To this end, we first propose the radial-isotropic adversarial vignetting attack (RI-AVA) based on the physical model of vignetting, where the physical parameters (e.g., illumination factor and focal length) are tuned through the guidance of target CNN models. To achieve higher transferability across different CNNs, we further propose radial-anisotropic adversarial vignetting attack (RA-AVA) by allowing the effective regions of vignetting to be radial-anisotropic and shape-free. Moreover, we propose the geometry-aware level-set optimization method to solve the adversarial vignetting regions and physical parameters jointly. We validate the proposed methods on three popular datasets, i.e., DEV, CIFAR10, and Tiny ImageNet, by attacking four CNNs, e.g., ResNet50, EfficientNet-B0, DenseNet121, and MobileNet-V2, demonstrating the advantages of our methods over baseline methods on both transferability and image quality.
Link Prediction Approach to Recommender Systems
Feb 18, 2021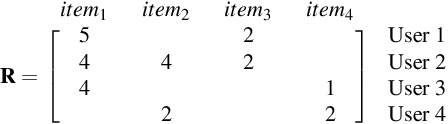

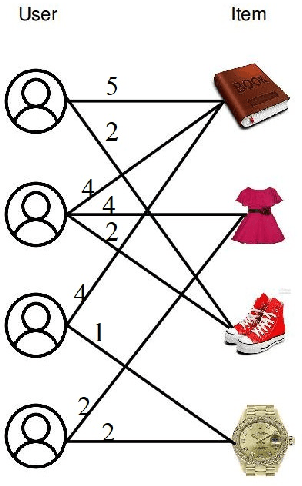
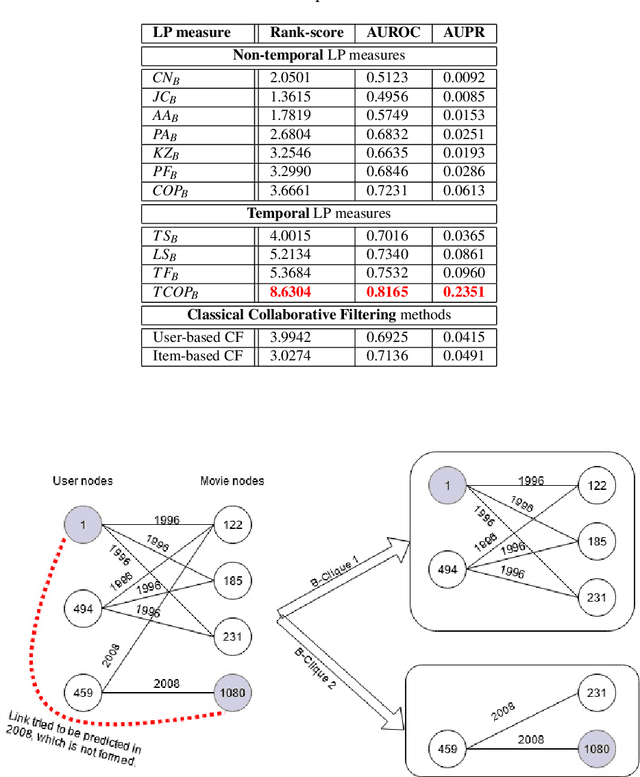
The problem of recommender system is very popular with myriad available solutions. A novel approach that uses the link prediction problem in social networks has been proposed in the literature that model the typical user-item information as a bipartite network in which link prediction would actually mean recommending an item to a user. The standard recommender system methods suffer from the problems of sparsity and scalability. Since link prediction measures involve computations pertaining to small neighborhoods in the network, this approach would lead to a scalable solution to recommendation. One of the issues in this conversion is that link prediction problem is modelled as a binary classification task whereas the problem of recommender systems is solved as a regression task in which the rating of the link is to be predicted. We overcome this issue by predicting top k links as recommendations with high ratings without predicting the actual rating. Our work extends similar approaches in the literature by focusing on exploiting the probabilistic measures for link prediction. Moreover, in the proposed approach, prediction measures that utilize temporal information available on the links prove to be more effective in improving the accuracy of prediction. This approach is evaluated on the benchmark 'Movielens' dataset. We show that the usage of temporal probabilistic measures helps in improving the quality of recommendations. Temporal random-walk based measure T_Flow improves recommendation accuracy by 4% and Temporal cooccurrence probability measure improves prediction accuracy by 10% over item-based collaborative filtering method in terms of AUROC score.
Machine Learning Prediction of Gamer's Private Networks
Dec 07, 2020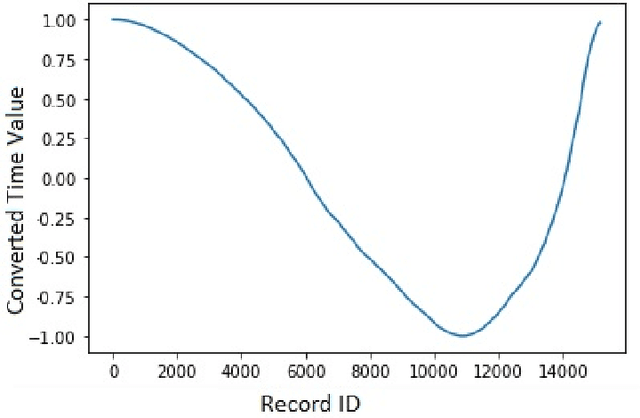
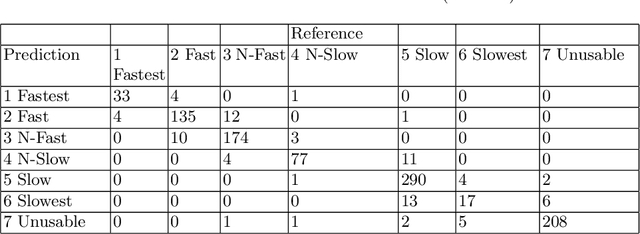
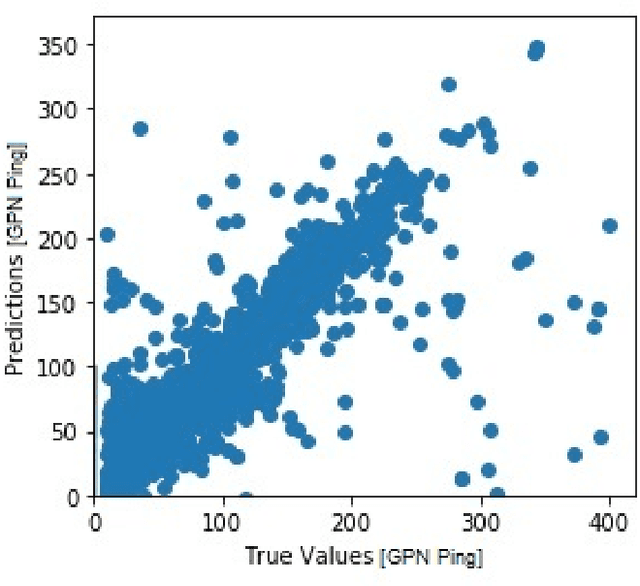
The Gamer's Private Network (GPN) is a client/server technology created by WTFast for making the network performance of online games faster and more reliable. GPN s use middle-mile servers and proprietary algorithms to better connect online video-game players to their game's servers across a wide-area network. Online games are a massive entertainment market and network latency is a key aspect of a player's competitive edge. This market means many different approaches to network architecture are implemented by different competing companies and that those architectures are constantly evolving. Ensuring the optimal connection between a client of WTFast and the online game they wish to play is thus an incredibly difficult problem to automate. Using machine learning, we analyzed historical network data from GPN connections to explore the feasibility of network latency prediction which is a key part of optimization. Our next step will be to collect live data (including client/server load, packet and port information and specific game state information) from GPN Minecraft servers and bots. We will use this information in a Reinforcement Learning model along with predictions about latency to alter the clients' and servers' configurations for optimal network performance. These investigations and experiments will improve the quality of service and reliability of GPN systems.
AsymmNet: Towards ultralight convolution neural networks using asymmetrical bottlenecks
Apr 15, 2021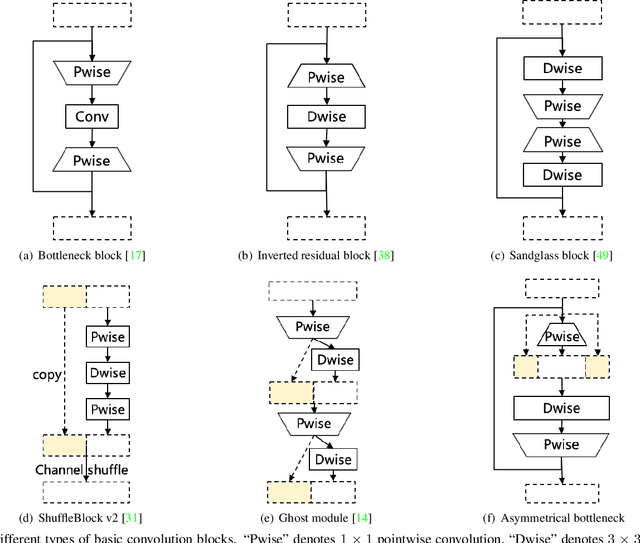
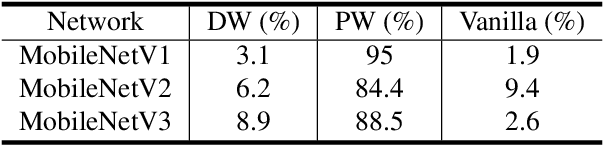
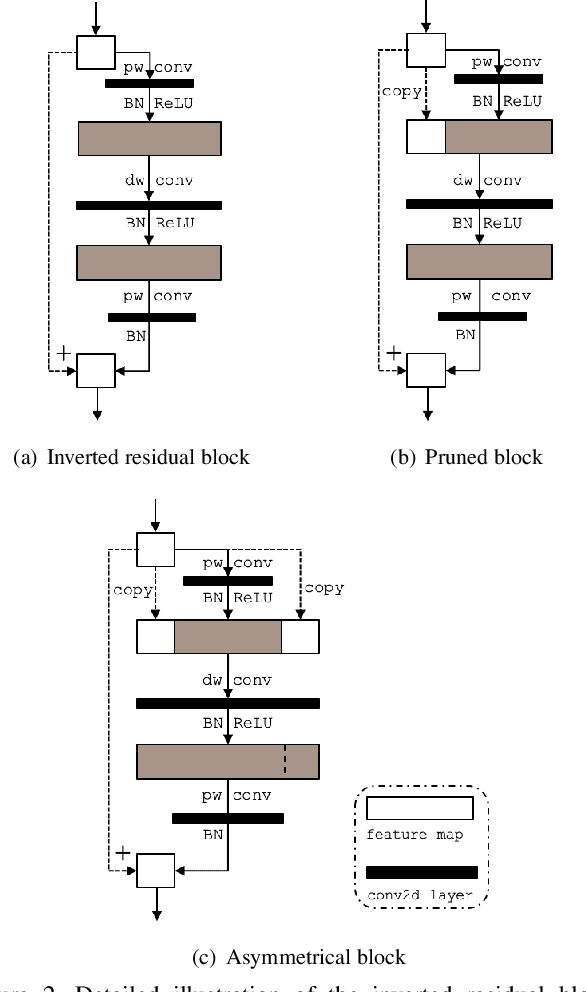

Deep convolutional neural networks (CNN) have achieved astonishing results in a large variety of applications. However, using these models on mobile or embedded devices is difficult due to the limited memory and computation resources. Recently, the inverted residual block becomes the dominating solution for the architecture design of compact CNNs. In this work, we comprehensively investigated the existing design concepts, rethink the functional characteristics of two pointwise convolutions in the inverted residuals. We propose a novel design, called asymmetrical bottlenecks. Precisely, we adjust the first pointwise convolution dimension, enrich the information flow by feature reuse, and migrate saved computations to the second pointwise convolution. By doing so we can further improve the accuracy without increasing the computation overhead. The asymmetrical bottlenecks can be adopted as a drop-in replacement for the existing CNN blocks. We can thus create AsymmNet by easily stack those blocks according to proper depth and width conditions. Extensive experiments demonstrate that our proposed block design is more beneficial than the original inverted residual bottlenecks for mobile networks, especially useful for those ultralight CNNs within the regime of <220M MAdds. Code is available at https://github.com/Spark001/AsymmNet
Reasoning in Dialog: Improving Response Generation by Context Reading Comprehension
Dec 14, 2020
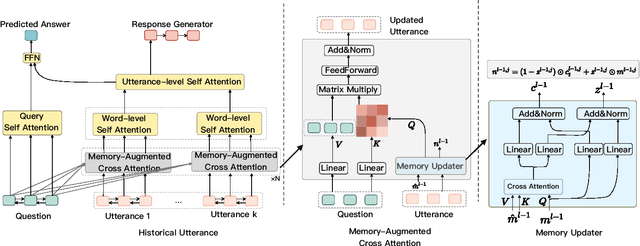
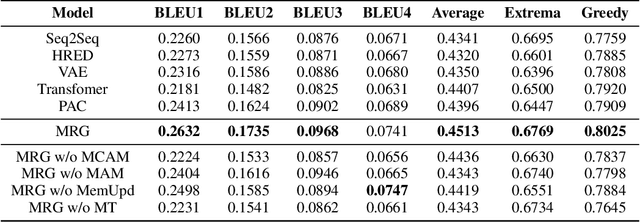
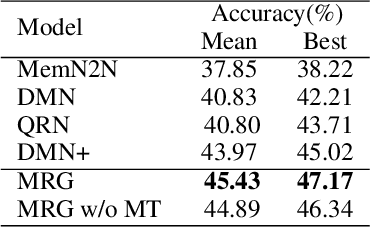
In multi-turn dialog, utterances do not always take the full form of sentences \cite{Carbonell1983DiscoursePA}, which naturally makes understanding the dialog context more difficult. However, it is essential to fully grasp the dialog context to generate a reasonable response. Hence, in this paper, we propose to improve the response generation performance by examining the model's ability to answer a reading comprehension question, where the question is focused on the omitted information in the dialog. Enlightened by the multi-task learning scheme, we propose a joint framework that unifies these two tasks, sharing the same encoder to extract the common and task-invariant features with different decoders to learn task-specific features. To better fusing information from the question and the dialog history in the encoding part, we propose to augment the Transformer architecture with a memory updater, which is designed to selectively store and update the history dialog information so as to support downstream tasks. For the experiment, we employ human annotators to write and examine a large-scale dialog reading comprehension dataset. Extensive experiments are conducted on this dataset, and the results show that the proposed model brings substantial improvements over several strong baselines on both tasks. In this way, we demonstrate that reasoning can indeed help better response generation and vice versa. We release our large-scale dataset for further research.
* 9 pages, 1 figure
Image Block Loss Restoration Using Sparsity Pattern as Side Information
Aug 27, 2016
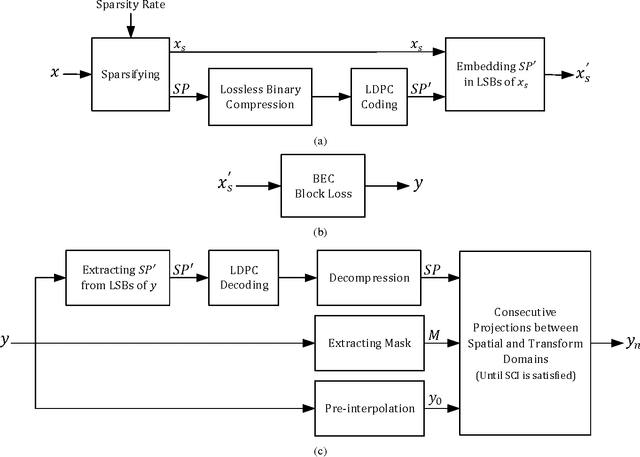
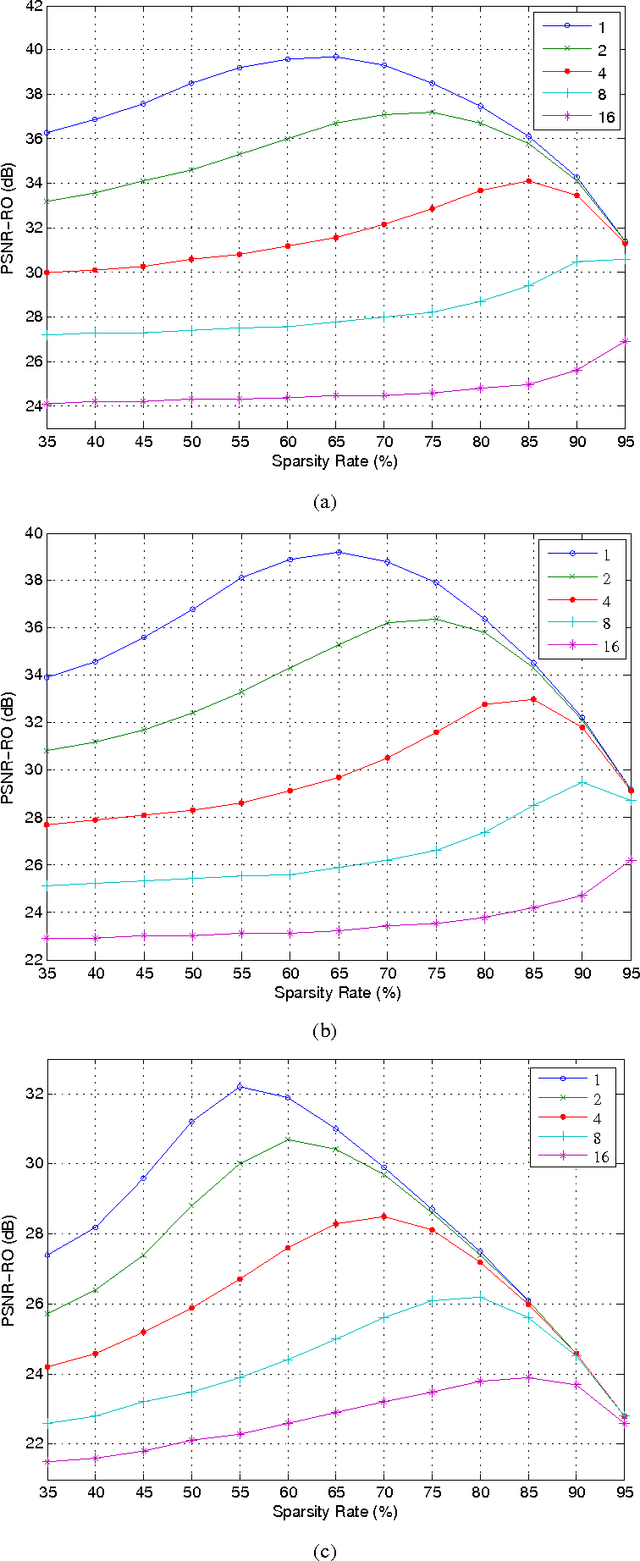
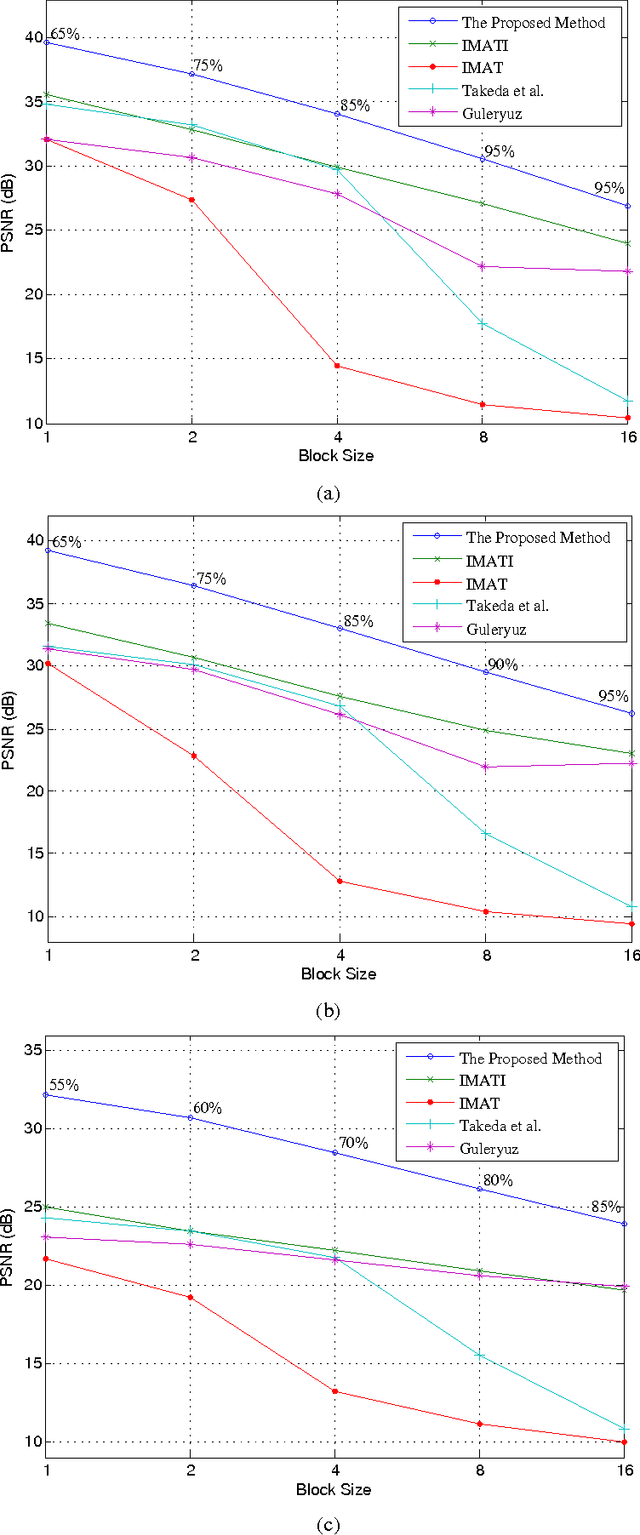
In this paper, we propose a method for image block loss restoration based on the notion of sparse representation. We use the sparsity pattern as side information to efficiently restore block losses by iteratively imposing the constraints of spatial and transform domains on the corrupted image. Two novel features, including a pre-interpolation and a criterion for stopping the iterations, are proposed to improve the performance. Also, to deal with practical applications, we develop a technique to transmit the side information along with the image. In this technique, we first compress the side information and then embed its LDPC coded version in the least significant bits of the image pixels. This technique ensures the error-free transmission of the side information, while causing only a small perturbation on the transmitted image. Mathematical analysis and extensive simulations are performed to validate the method and investigate the efficiency of the proposed techniques. The results verify that the proposed method outperforms its counterparts for image block loss restoration.
A Simple Approach for Zero-Shot Learning based on Triplet Distribution Embeddings
Mar 29, 2021Given the semantic descriptions of classes, Zero-Shot Learning (ZSL) aims to recognize unseen classes without labeled training data by exploiting semantic information, which contains knowledge between seen and unseen classes. Existing ZSL methods mainly use vectors to represent the embeddings to the semantic space. Despite the popularity, such vector representation limits the expressivity in terms of modeling the intra-class variability for each class. We address this issue by leveraging the use of distribution embeddings. More specifically, both image embeddings and class embeddings are modeled as Gaussian distributions, where their similarity relationships are preserved through the use of triplet constraints. The key intuition which guides our approach is that for each image, the embedding of the correct class label should be closer than that of any other class label. Extensive experiments on multiple benchmark data sets show that the proposed method achieves highly competitive results for both traditional ZSL and more challenging Generalized Zero-Shot Learning (GZSL) settings.