 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-tuning deep learning model parameters for improved super-resolution of dynamic MRI with prior-knowledge
Feb 04, 2021
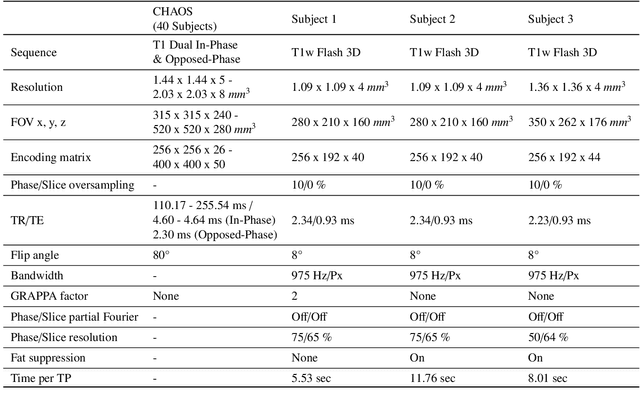
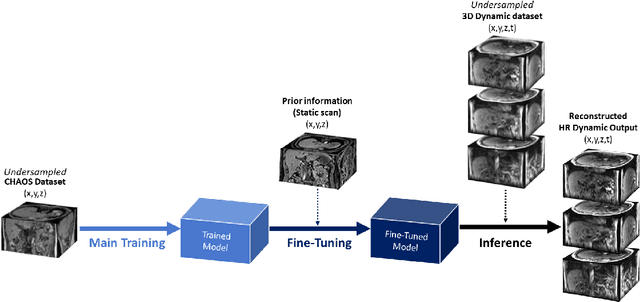
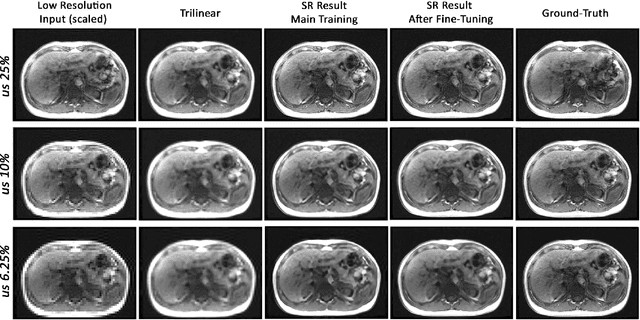

Dynamic imaging is a beneficial tool for interventions to assess physiological changes. Nonetheless during dynamic MRI, while achieving a high temporal resolution, the spatial resolution is compromised. To overcome this spatio-temporal trade-off, this research presents a super-resolution (SR) MRI reconstruction with prior knowledge based fine-tuning to maximise spatial information while preserving high temporal resolution of dynamic MRI. An U-Net based network with perceptual loss is trained on a benchmark dataset and fine-tuned using one subject-specific static high resolution MRI as prior knowledge to obtain high resolution dynamic images during the inference stage. 3D dynamic data for three subjects were acquired with different parameters to test the generalisation capabilities of the network. The method was tested for different levels of in-plane undersampling for dynamic MRI. The reconstructed dynamic SR results showed higher similarity with the high resolution ground-truth after fine-tuning. The average SSIM of the lowest resolution experimented during this research (6.25~\% of the k-space) before and after fine-tuning were 0.939 $\pm$ 0.008 and 0.957 $\pm$ 0.006 respectively. This could theoretically result in an acceleration factor of 16, which can potentially be acquired in less than half a second. The proposed approach shows that the super-resolution MRI reconstruction with prior-information can alleviate the spatio-temporal trade-off in dynamic MRI, even for high acceleration factors.
Self-supervised asymmetric deep hashing with margin-scalable constraint for image retrieval
Dec 07, 2020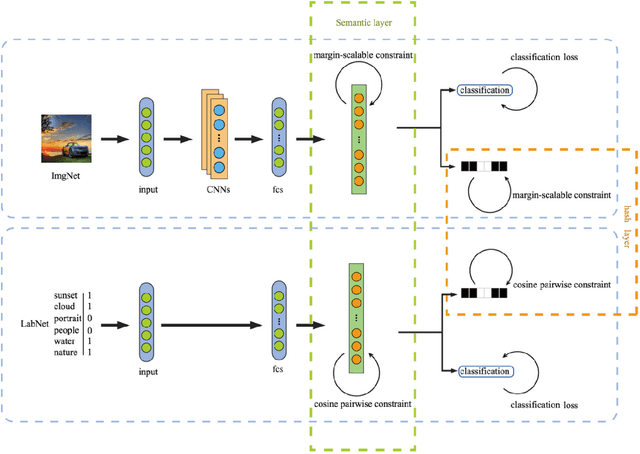
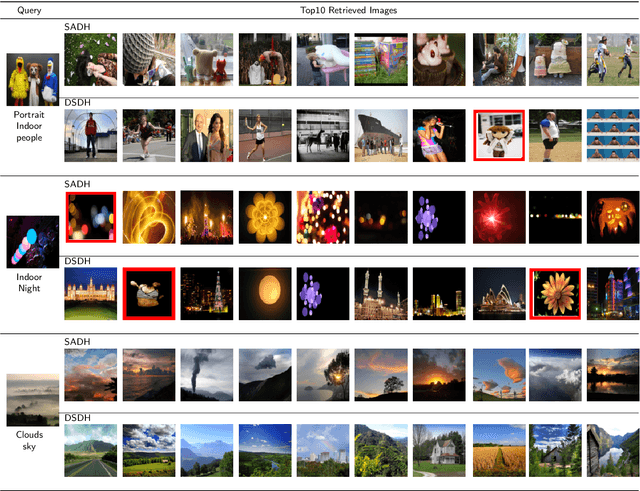
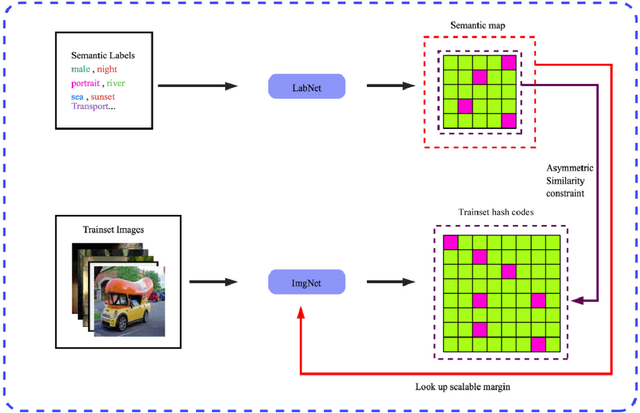
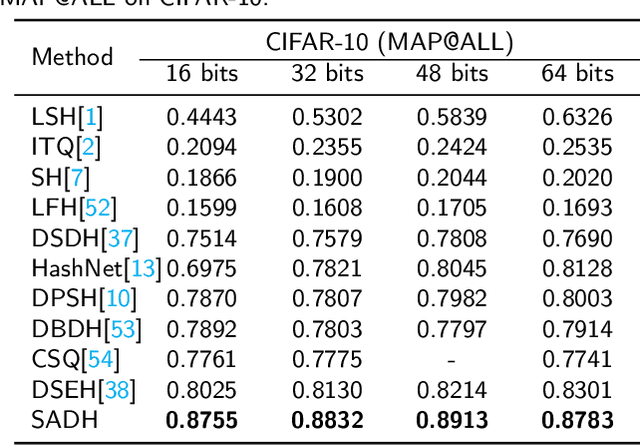
Due to its validity and rapidity, image retrieval based on deep hashing approaches is widely concerned especially in large-scale visual search. However, many existing deep hashing methods inadequately utilize label information as guidance of feature learning network without more advanced exploration in semantic space, besides the similarity correlations in hamming space are not fully discovered and embedded into hash codes, by which the retrieval quality is diminished with inefficient preservation of pairwise correlations and multi-label semantics. To cope with these problems, we propose a novel self-supervised asymmetric deep hashing with margin-scalable constraint(SADH) approach for image retrieval. SADH implements a self-supervised network to preserve supreme semantic information in a semantic feature map and a semantic code map for each semantics of the given dataset, which efficiently-and-precisely guides a feature learning network to preserve multi-label semantic information with asymmetric learning strategy. Moreover, for the feature learning part, by further exploiting semantic maps, a new margin-scalable constraint is employed for both highly-accurate construction of pairwise correlation in the hamming space and more discriminative hash code representation. Extensive empirical research on three benchmark datasets validate that the proposed method outperforms several state-of-the-art approaches.
Head2HeadFS: Video-based Head Reenactment with Few-shot Learning
Mar 30, 2021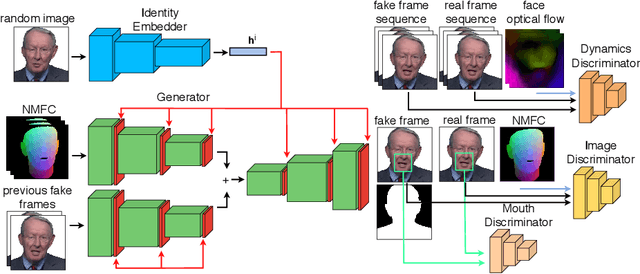
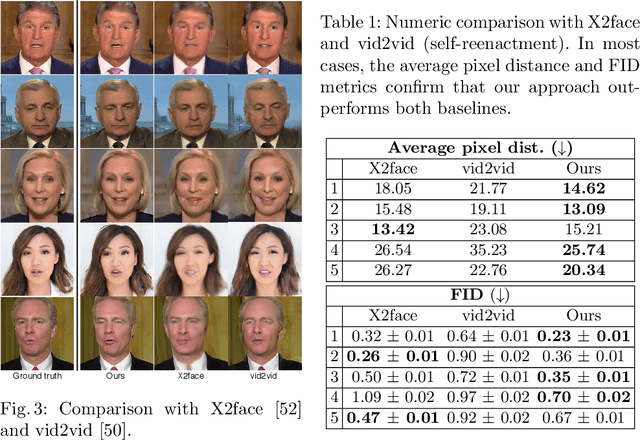


Over the past years, a substantial amount of work has been done on the problem of facial reenactment, with the solutions coming mainly from the graphics community. Head reenactment is an even more challenging task, which aims at transferring not only the facial expression, but also the entire head pose from a source person to a target. Current approaches either train person-specific systems, or use facial landmarks to model human heads, a representation that might transfer unwanted identity attributes from the source to the target. We propose head2headFS, a novel easily adaptable pipeline for head reenactment. We condition synthesis of the target person on dense 3D face shape information from the source, which enables high quality expression and pose transfer. Our video-based rendering network is fine-tuned under a few-shot learning strategy, using only a few samples. This allows for fast adaptation of a generic generator trained on a multiple-person dataset, into a person-specific one.
M-Net with Bidirectional ConvLSTM for Cup and Disc Segmentation in Fundus Images
Apr 08, 2021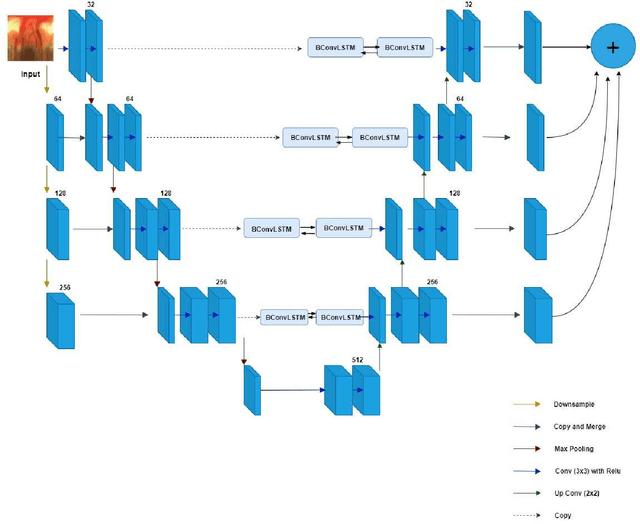
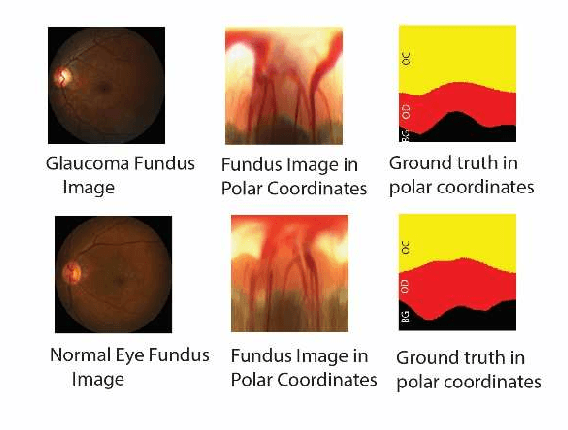

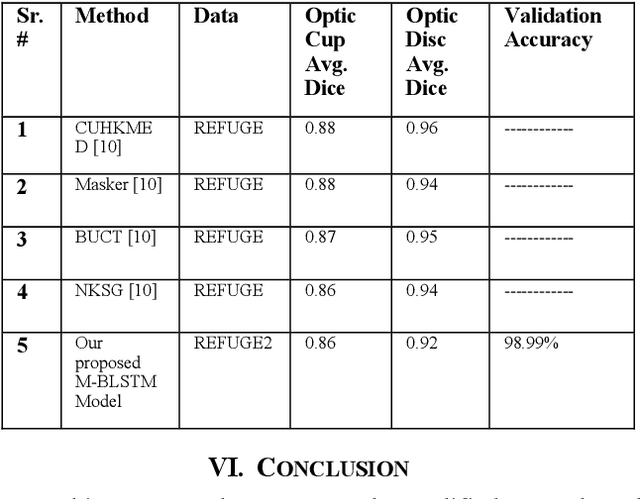
Glaucoma is a severe eye disease that is known to deteriorate optic never fibers, causing cup size to increase, which could result in permanent loss of vision. Glaucoma is the second leading cause of blindness after cataract, but glaucoma being more dangerous as it is not curable. Early diagnoses and treatment of glaucoma can help to slow the progression of glaucoma and its damages. For the detection of glaucoma, the Cup to Disc ratio (CDR) provides significant information. The CDR depends heavily on the accurate segmentation of cup and disc regions. In this paper, we have proposed a modified M-Net with bidirectional convolution long short-term memory (LSTM), based on joint cup and disc segmentation. The proposed network combines features of encoder and decoder, with bidirectional LSTM. Our proposed model segments cup and disc regions based on which the abnormalities in cup to disc ratio can be observed. The proposed model is tested on REFUGE2 data, where our model achieves a dice score of 0.92 for optic disc and an accuracy of 98.99% in segmenting cup and disc regions
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021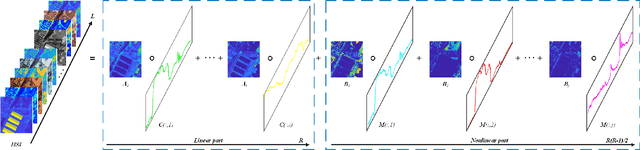

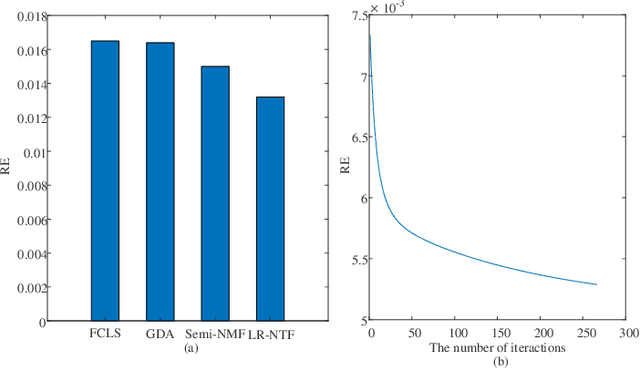
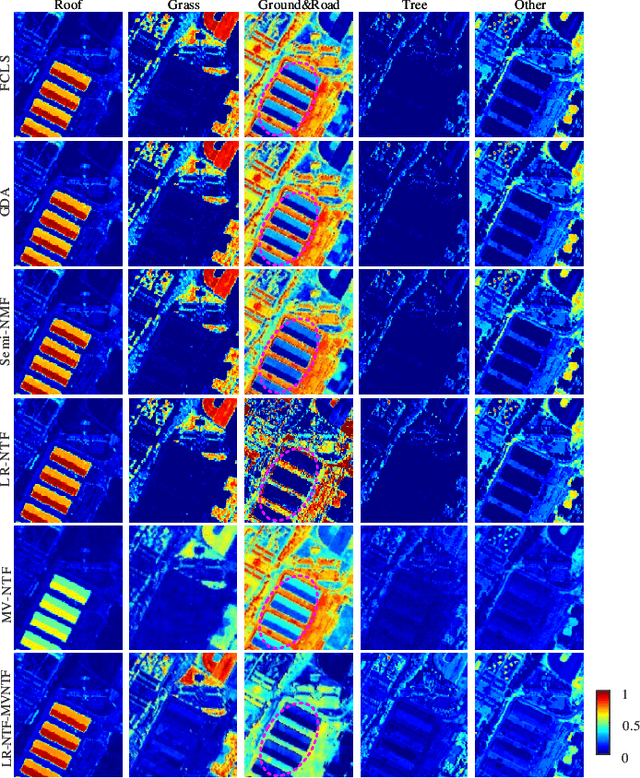
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Hierarchical Topic Presence Models
Apr 16, 2021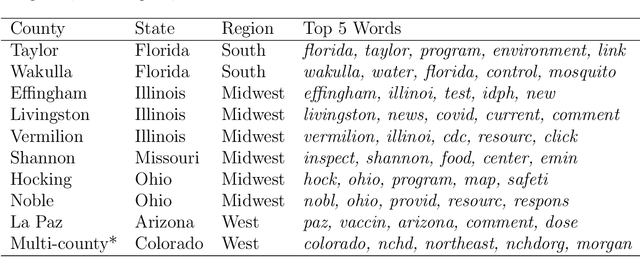
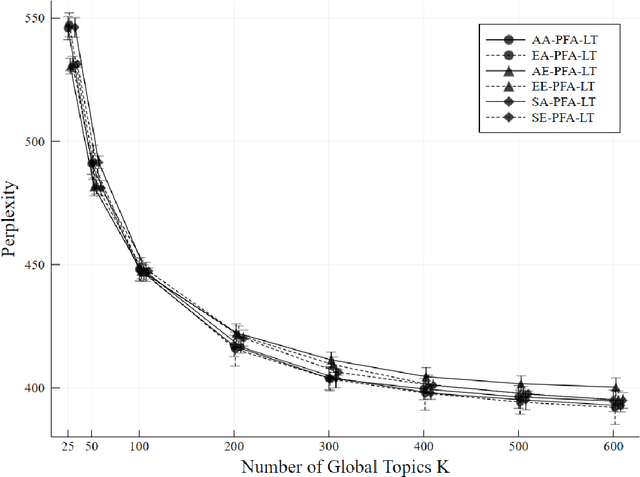
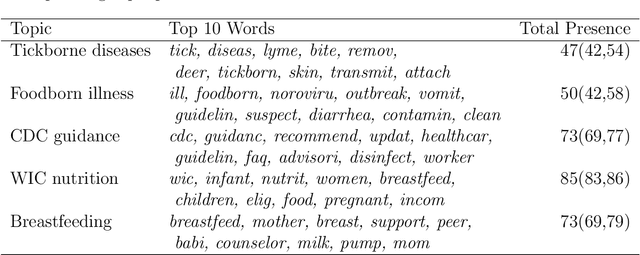
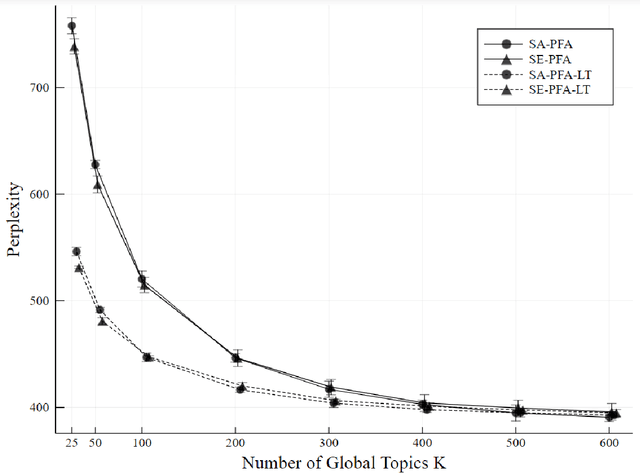
Topic models analyze text from a set of documents. Documents are modeled as a mixture of topics, with topics defined as probability distributions on words. Inferences of interest include the most probable topics and characterization of a topic by inspecting the topic's highest probability words. Motivated by a data set of web pages (documents) nested in web sites, we extend the Poisson factor analysis topic model to hierarchical topic presence models for analyzing text from documents nested in known groups. We incorporate an unknown binary topic presence parameter for each topic at the web site and/or the web page level to allow web sites and/or web pages to be sparse mixtures of topics and we propose logistic regression modeling of topic presence conditional on web site covariates. We introduce local topics into the Poisson factor analysis framework, where each web site has a local topic not found in other web sites. Two data augmentation methods, the Chinese table distribution and P\'{o}lya-Gamma augmentation, aid in constructing our sampler. We analyze text from web pages nested in United States local public health department web sites to abstract topical information and understand national patterns in topic presence.
Iterative Reweighted Algorithms for Joint User Identification and Channel Estimation in Spatially Correlated Massive MTC
Mar 15, 2021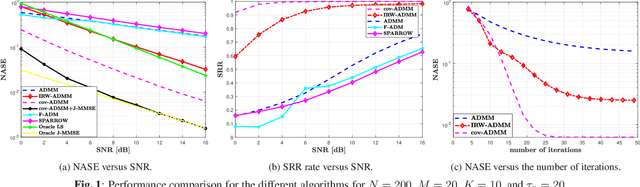
Joint user identification and channel estimation (JUICE) is a main challenge in grant-free massive machine-type communications (mMTC). The sparse pattern in users' activity allows to solve the JUICE as a compressed sensing problem in a multiple measurement vector (MMV) setup. This paper addresses the JUICE under the practical spatially correlated fading channel. We formulate the JUICE as an iterative reweighted $\ell_{2,1}$-norm optimization. We develop a computationally efficient alternating direction method of multipliers (ADMM) approach to solve it. In particular, by leveraging the second-order statistics of the channels, we reformulate the JUICE problem to exploit the covariance information and we derive its ADMM-based solution. The simulation results highlight the significant improvements brought by the proposed approach in terms of channel estimation and activity detection performances.
LightCAKE: A Lightweight Framework for Context-Aware Knowledge Graph Embedding
Mar 04, 2021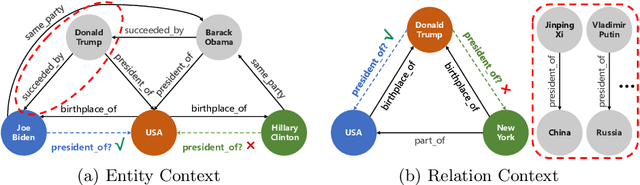
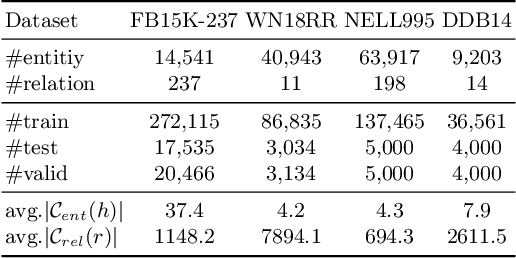
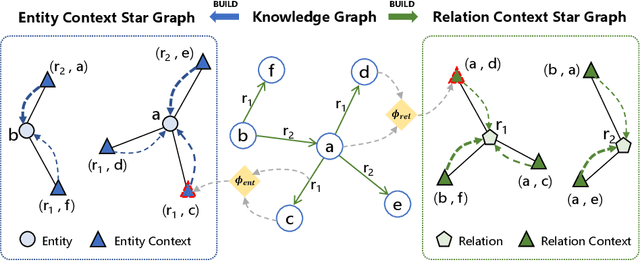
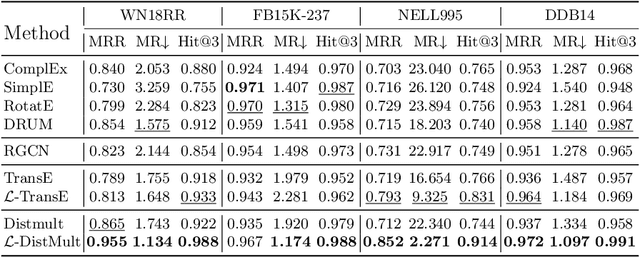
Knowledge graph embedding (KGE) models learn to project symbolic entities and relations into a continuous vector space based on the observed triplets. However, existing KGE models cannot make a proper trade-off between the graph context and the model complexity, which makes them still far from satisfactory. In this paper, we propose a lightweight framework named LightCAKE for context-aware KGE. LightCAKE explicitly models the graph context without introducing redundant trainable parameters, and uses an iterative aggregation strategy to integrate the context information into the entity/relation embeddings. As a generic framework, it can be used with many simple KGE models to achieve excellent results. Finally, extensive experiments on public benchmarks demonstrate the efficiency and effectiveness of our framework.
Information Compression, Intelligence, Computing, and Mathematics
Jul 13, 2015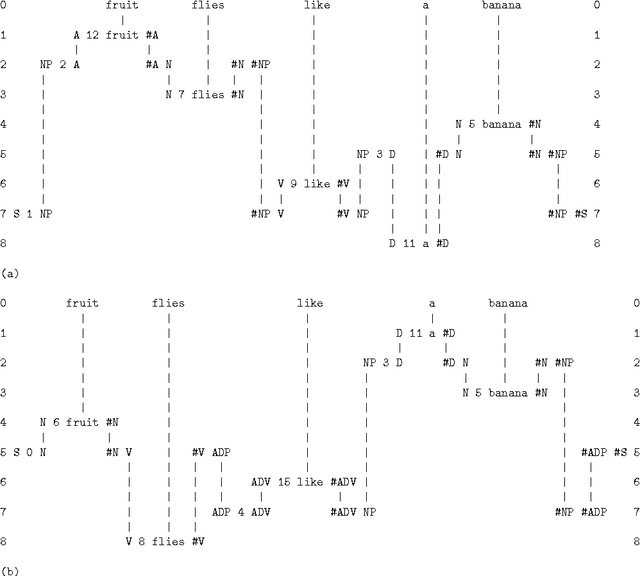

This paper presents evidence for the idea that much of artificial intelligence, human perception and cognition, mainstream computing, and mathematics, may be understood as compression of information via the matching and unification of patterns. This is the basis for the "SP theory of intelligence", outlined in the paper and fully described elsewhere. Relevant evidence may be seen: in empirical support for the SP theory; in some advantages of information compression (IC) in terms of biology and engineering; in our use of shorthands and ordinary words in language; in how we merge successive views of any one thing; in visual recognition; in binocular vision; in visual adaptation; in how we learn lexical and grammatical structures in language; and in perceptual constancies. IC via the matching and unification of patterns may be seen in both computing and mathematics: in IC via equations; in the matching and unification of names; in the reduction or removal of redundancy from unary numbers; in the workings of Post's Canonical System and the transition function in the Universal Turing Machine; in the way computers retrieve information from memory; in systems like Prolog; and in the query-by-example technique for information retrieval. The chunking-with-codes technique for IC may be seen in the use of named functions to avoid repetition of computer code. The schema-plus-correction technique may be seen in functions with parameters and in the use of classes in object-oriented programming. And the run-length coding technique may be seen in multiplication, in division, and in several other devices in mathematics and computing. The SP theory resolves the apparent paradox of "decompression by compression". And computing and cognition as IC is compatible with the uses of redundancy in such things as backup copies to safeguard data and understanding speech in a noisy environment.
Machine Learning the period finding algorithm
Mar 09, 2021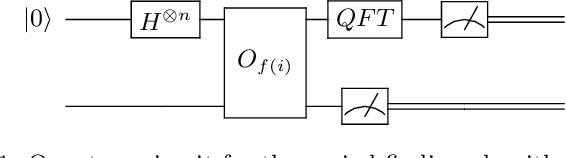
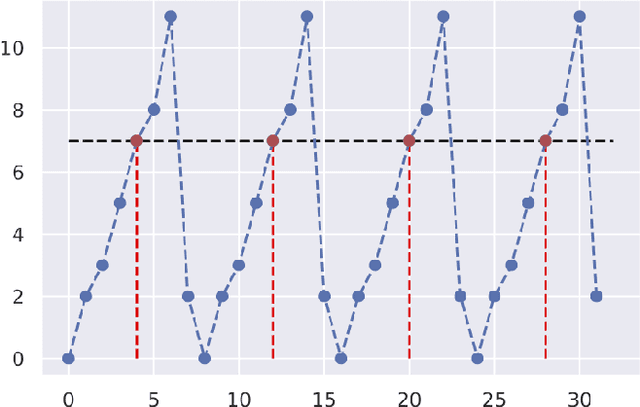
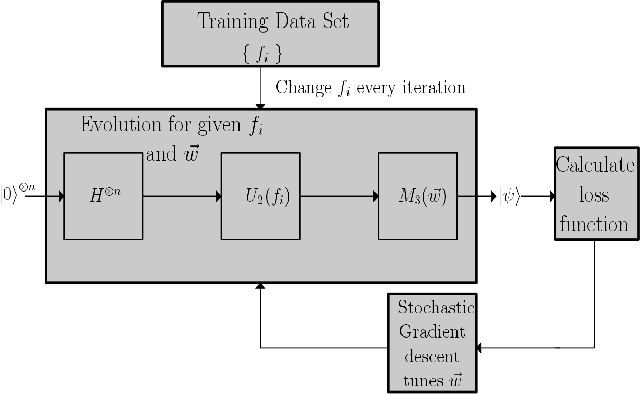
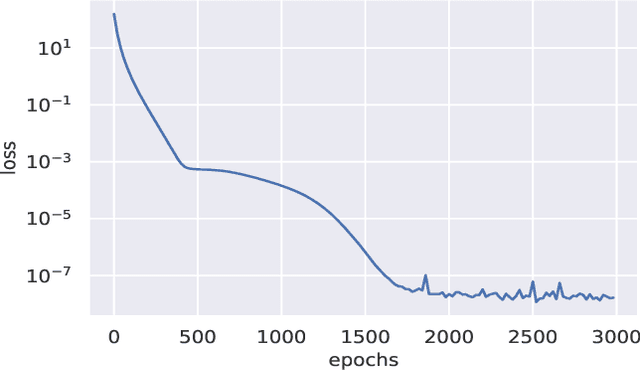
We use differentiable programming and gradient descent to find unitary matrices that can be used in the period finding algorithm to extract period information from the state of a quantum computer post application of the oracle. The standard procedure is to use the inverse quantum Fourier transform. Our findings suggest that that this is not the only unitary matrix appropriate for the period finding algorithm, There exist several unitary matrices that can affect out the same transformation and they are significantly different from each other as well. These unitary matrices can be learned by an algorithm. Neural networks can be applied to differentiate such unitary matrices from randomly generated ones indicating that these unitaries do have characteristic features that cannot otherwise be discerned easily.