 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations
Nov 17, 2020

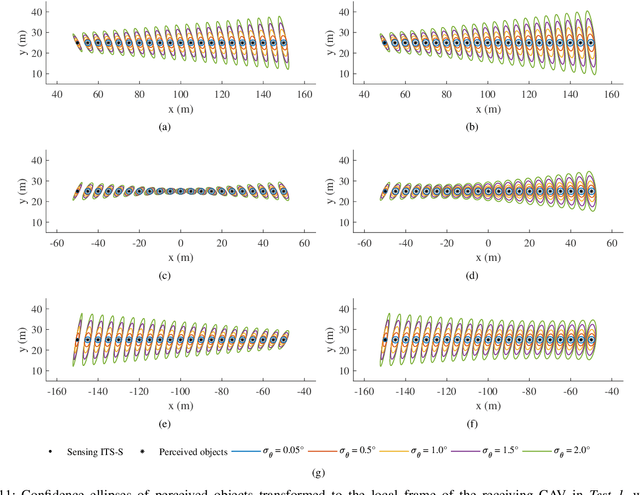
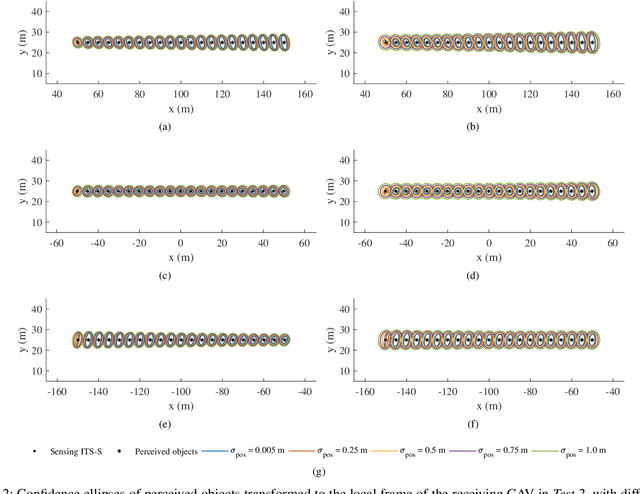
Cooperative perception, or collective perception (CP) is an emerging and promising technology for intelligent transportation systems (ITS). It enables an ITS station (ITS-S) to share its local perception information with others by means of vehicle-to-X (V2X) communication, thereby achieving improved efficiency and safety in road transportation. In this paper, we present our recent progress on the development of a connected and automated vehicle (CAV) and intelligent roadside unit (IRSU). We present three different experiments to demonstrate the use of CP service within intelligent infrastructure to improve awareness of vulnerable road users (VRU) and thus safety for CAVs in various traffic scenarios. We demonstrate in the experiments that a connected vehicle (CV) can "see" a pedestrian around the corners. More importantly, we demonstrate how CAVs can autonomously and safely interact with walking and running pedestrians, relying only on the CP information from the IRSU through vehicle-to-infrastructure (V2I) communication. This is one of the first demonstrations of urban vehicle automation using only CP information. We also address in the paper the handling of collective perception messages (CPMs) received from the IRSU, and passing them through a pipeline of CP information coordinate transformation with uncertainty, multiple road user tracking, and eventually path planning/decision making within the CAV. The experimental results were obtained with manually driven CV, fully autonomous CAV, and an IRSU retrofitted with vision and laser sensors and a road user tracking system.
Fast discovery of multidimensional subsequences for robust trajectory classification
Feb 09, 2021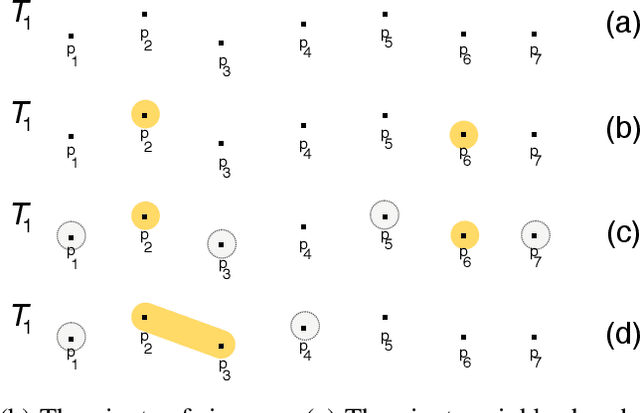
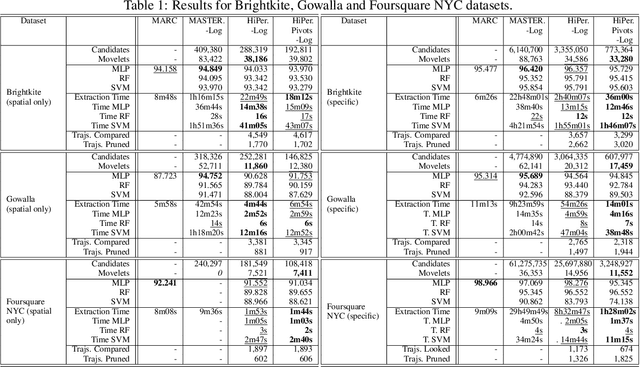
Trajectory classification tasks became more complex as large volumes of mobility data are being generated every day and enriched with new sources of information, such as social networks and IoT sensors. Fast classification algorithms are essential for discovering knowledge in trajectory data for real applications. In this work we propose a method for fast discovery of subtrajectories with the reduction of the search space and the optimization of the MASTERMovelets method, which has proven to be effective for discovering interpretable patterns in classification problems.
Successful Nash Equilibrium Agent for a 3-Player Imperfect-Information Game
Apr 13, 2018
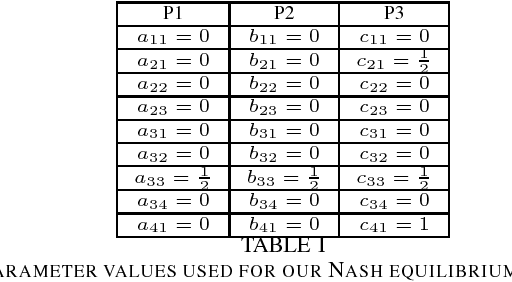
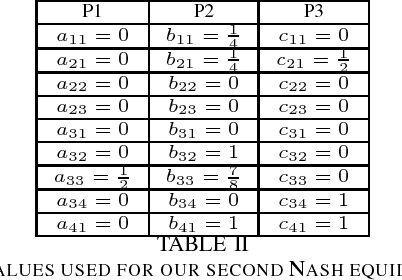
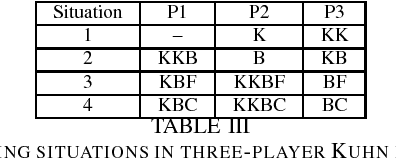
Creating strong agents for games with more than two players is a major open problem in AI. Common approaches are based on approximating game-theoretic solution concepts such as Nash equilibrium, which have strong theoretical guarantees in two-player zero-sum games, but no guarantees in non-zero-sum games or in games with more than two players. We describe an agent that is able to defeat a variety of realistic opponents using an exact Nash equilibrium strategy in a 3-player imperfect-information game. This shows that, despite a lack of theoretical guarantees, agents based on Nash equilibrium strategies can be successful in multiplayer games after all.
Multi-view Contrastive Coding of Remote Sensing Images at Pixel-level
May 18, 2021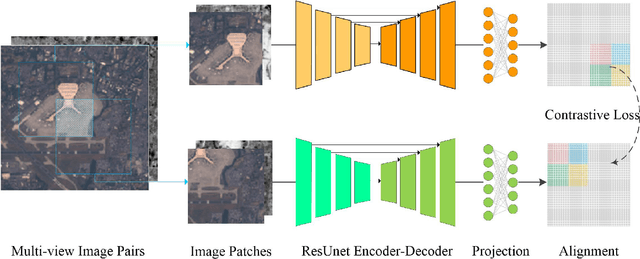
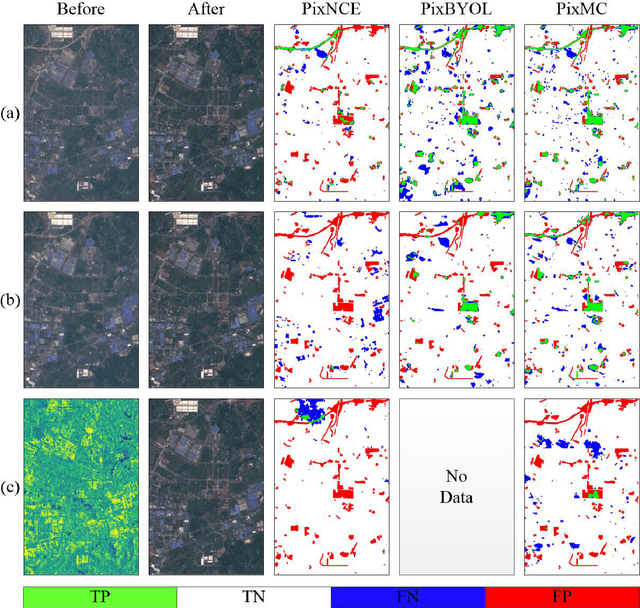
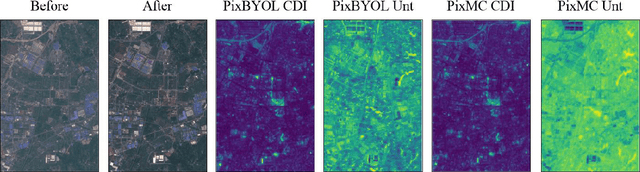
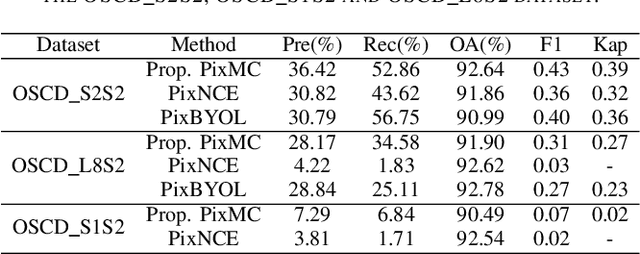
Our planet is viewed by satellites through multiple sensors (e.g., multi-spectral, Lidar and SAR) and at different times. Multi-view observations bring us complementary information than the single one. Alternatively, there are common features shared between different views, such as geometry and semantics. Recently, contrastive learning methods have been proposed for the alignment of multi-view remote sensing images and improving the feature representation of single sensor images by modeling view-invariant factors. However, these methods are based on the pretraining of the predefined tasks or just focus on image-level classification. Moreover, these methods lack research on uncertainty estimation. In this work, a pixel-wise contrastive approach based on an unlabeled multi-view setting is proposed to overcome this limitation. This is achieved by the use of contrastive loss in the feature alignment and uniformity between multi-view images. In this approach, a pseudo-Siamese ResUnet is trained to learn a representation that aims to align features from the shifted positive pairs and uniform the induced distribution of the features on the hypersphere. The learned features of multi-view remote sensing images are evaluated on a liner protocol evaluation and an unsupervised change detection task. We analyze key properties of the approach that make it work, finding that the requirement of shift equivariance ensured the success of the proposed approach and the uncertainty estimation of representations leads to performance improvements. Moreover, the performance of multi-view contrastive learning is affected by the choice of different sensors. Results demonstrate both improvements in efficiency and accuracy over the state-of-the-art multi-view contrastive methods.
Spatiotemporal Transformer for Video-based Person Re-identification
Mar 30, 2021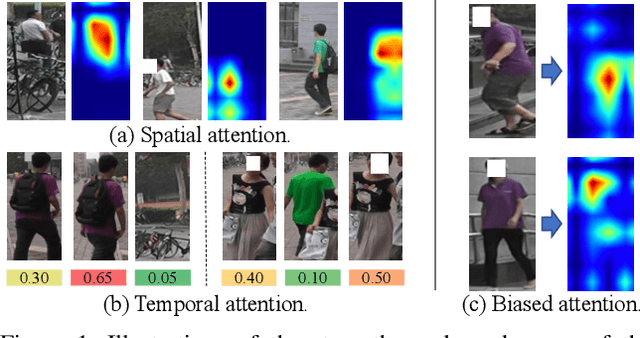
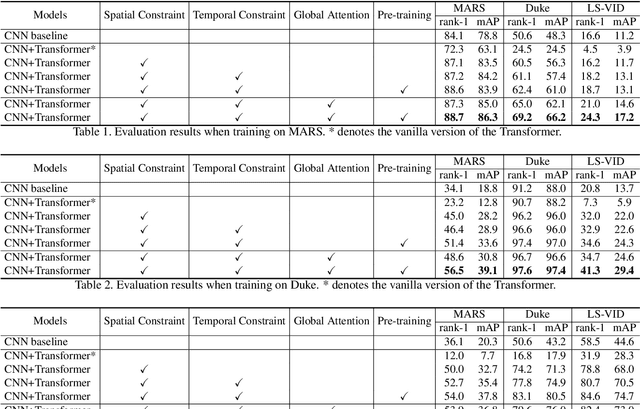
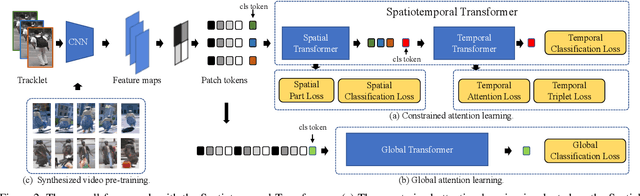
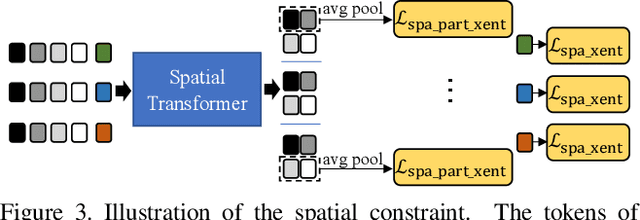
Recently, the Transformer module has been transplanted from natural language processing to computer vision. This paper applies the Transformer to video-based person re-identification, where the key issue is to extract the discriminative information from a tracklet. We show that, despite the strong learning ability, the vanilla Transformer suffers from an increased risk of over-fitting, arguably due to a large number of attention parameters and insufficient training data. To solve this problem, we propose a novel pipeline where the model is pre-trained on a set of synthesized video data and then transferred to the downstream domains with the perception-constrained Spatiotemporal Transformer (STT) module and Global Transformer (GT) module. The derived algorithm achieves significant accuracy gain on three popular video-based person re-identification benchmarks, MARS, DukeMTMC-VideoReID, and LS-VID, especially when the training and testing data are from different domains. More importantly, our research sheds light on the application of the Transformer on highly-structured visual data.
Bilevel Online Adaptation for Out-of-Domain Human Mesh Reconstruction
Mar 30, 2021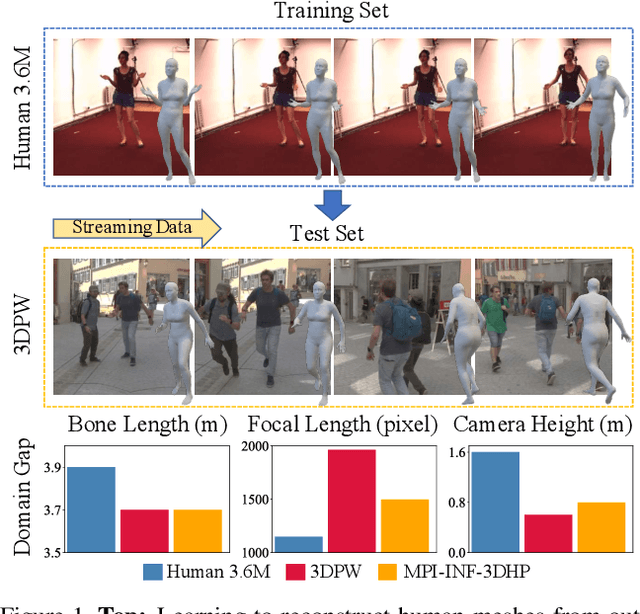
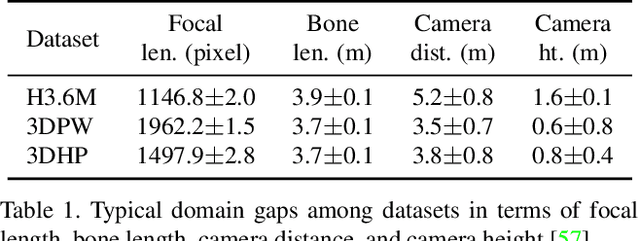
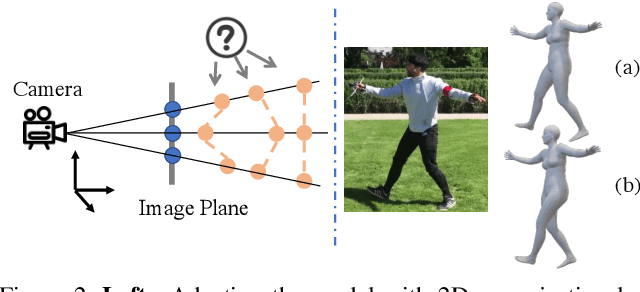
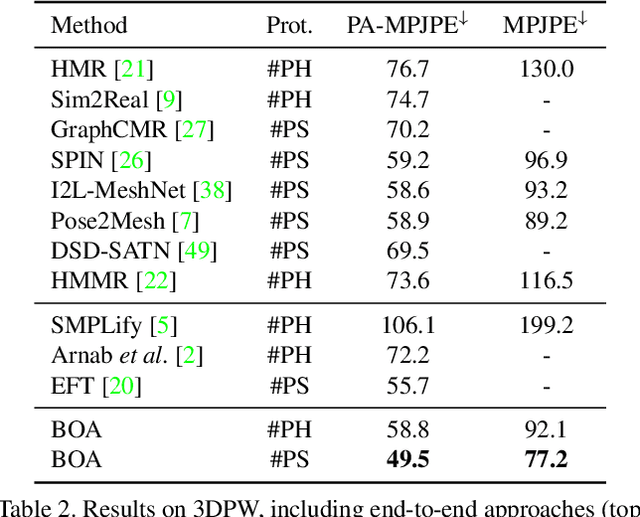
This paper considers a new problem of adapting a pre-trained model of human mesh reconstruction to out-of-domain streaming videos. However, most previous methods based on the parametric SMPL model \cite{loper2015smpl} underperform in new domains with unexpected, domain-specific attributes, such as camera parameters, lengths of bones, backgrounds, and occlusions. Our general idea is to dynamically fine-tune the source model on test video streams with additional temporal constraints, such that it can mitigate the domain gaps without over-fitting the 2D information of individual test frames. A subsequent challenge is how to avoid conflicts between the 2D and temporal constraints. We propose to tackle this problem using a new training algorithm named Bilevel Online Adaptation (BOA), which divides the optimization process of overall multi-objective into two steps of weight probe and weight update in a training iteration. We demonstrate that BOA leads to state-of-the-art results on two human mesh reconstruction benchmarks.
One-Round Active Learning
Apr 23, 2021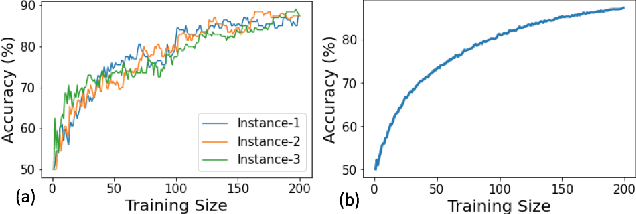

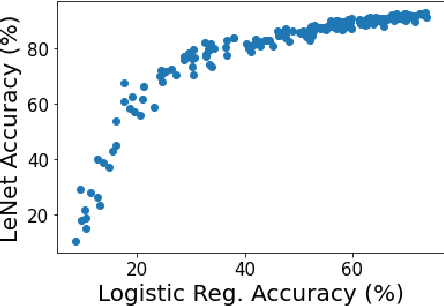
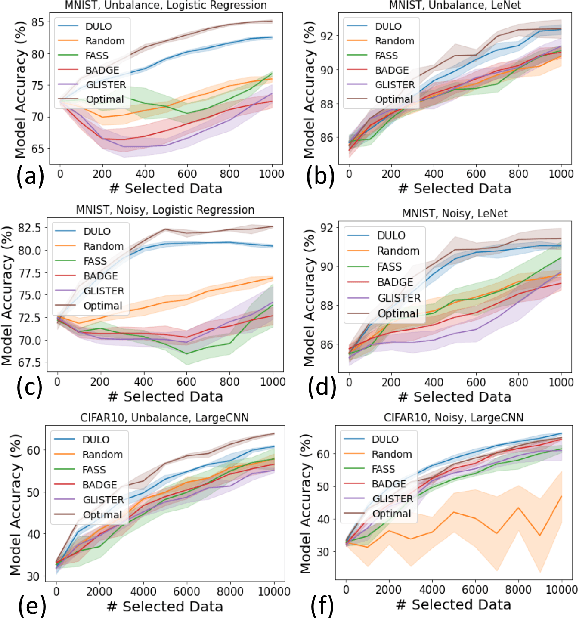
Active learning has been a main solution for reducing data labeling costs. However, existing active learning strategies assume that a data owner can interact with annotators in an online, timely manner, which is usually impractical. Even with such interactive annotators, for existing active learning strategies to be effective, they often require many rounds of interactions between the data owner and annotators, which is often time-consuming. In this work, we initiate the study of one-round active learning, which aims to select a subset of unlabeled data points that achieve the highest utility after being labeled with only the information from initially labeled data points. We propose DULO, a general framework for one-round active learning based on the notion of data utility functions, which map a set of data points to some performance measure of the model trained on the set. We formulate the one-round active learning problem as data utility function maximization. We further propose strategies to make the estimation and optimization of data utility functions scalable to large models and large unlabeled data sets. Our results demonstrate that while existing active learning approaches could succeed with multiple rounds, DULO consistently performs better in the one-round setting.
Learning Intuitive Physics with Multimodal Generative Models
Jan 19, 2021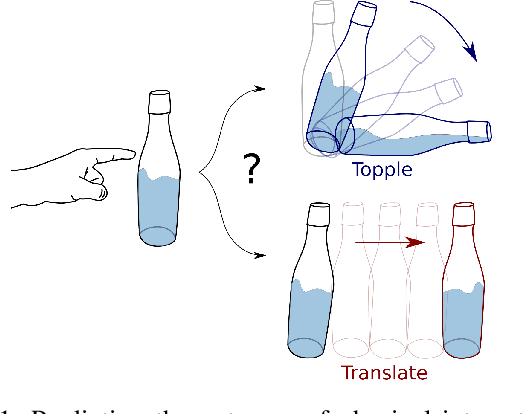
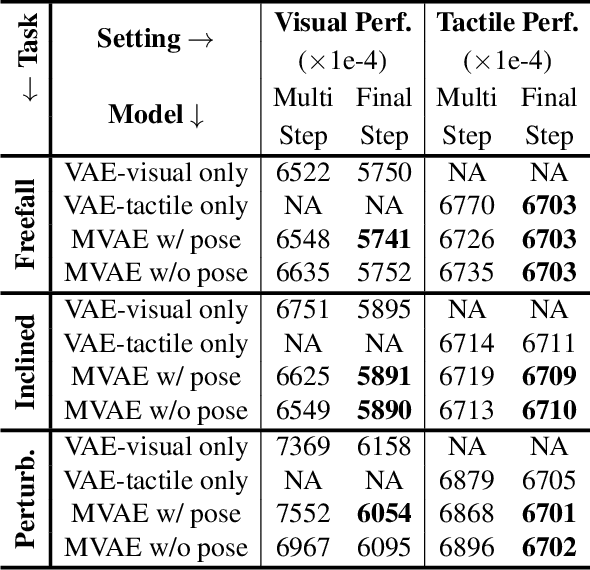
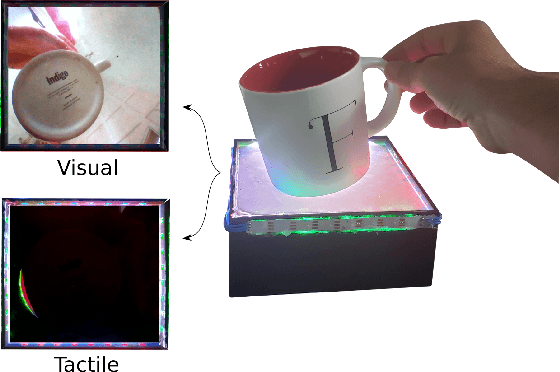

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
Graph Attention Networks for Anti-Spoofing
Apr 08, 2021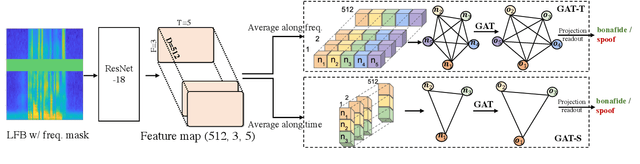
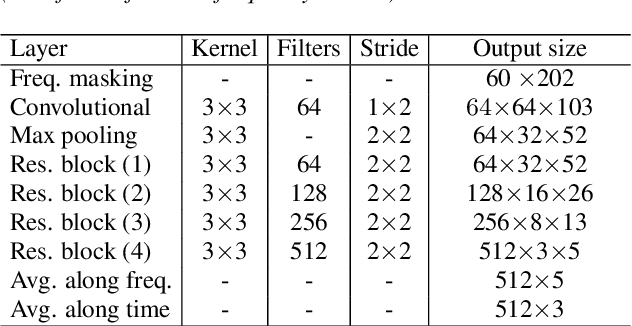
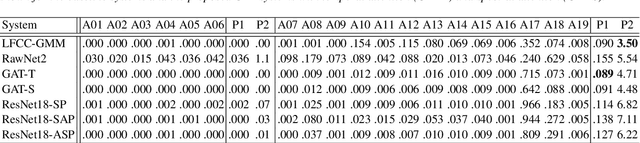
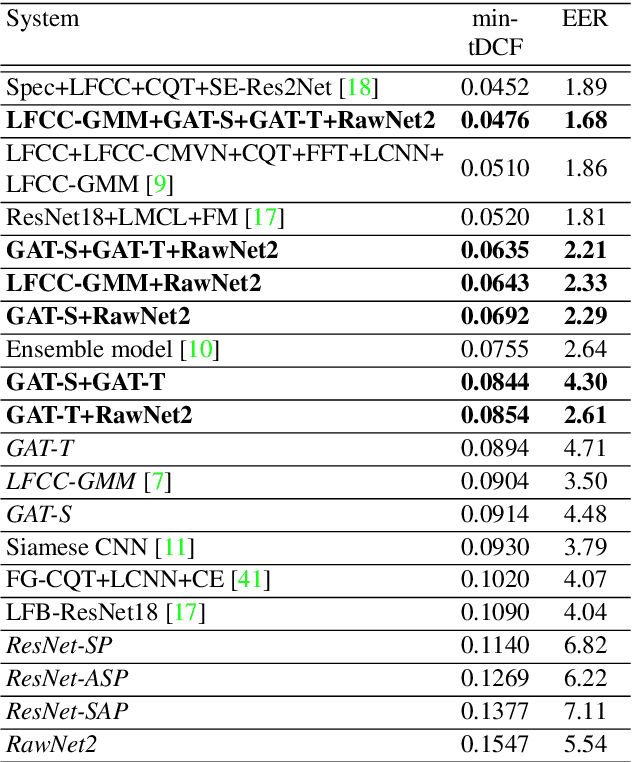
The cues needed to detect spoofing attacks against automatic speaker verification are often located in specific spectral sub-bands or temporal segments. Previous works show the potential to learn these using either spectral or temporal self-attention mechanisms but not the relationships between neighbouring sub-bands or segments. This paper reports our use of graph attention networks (GATs) to model these relationships and to improve spoofing detection performance. GATs leverage a self-attention mechanism over graph structured data to model the data manifold and the relationships between nodes. Our graph is constructed from representations produced by a ResNet. Nodes in the graph represent information either in specific sub-bands or temporal segments. Experiments performed on the ASVspoof 2019 logical access database show that our GAT-based model with temporal attention outperforms all of our baseline single systems. Furthermore, GAT-based systems are complementary to a set of existing systems. The fusion of GAT-based models with more conventional countermeasures delivers a 47% relative improvement in performance compared to the best performing single GAT system.
Fine-tuning deep learning model parameters for improved super-resolution of dynamic MRI with prior-knowledge
Feb 04, 2021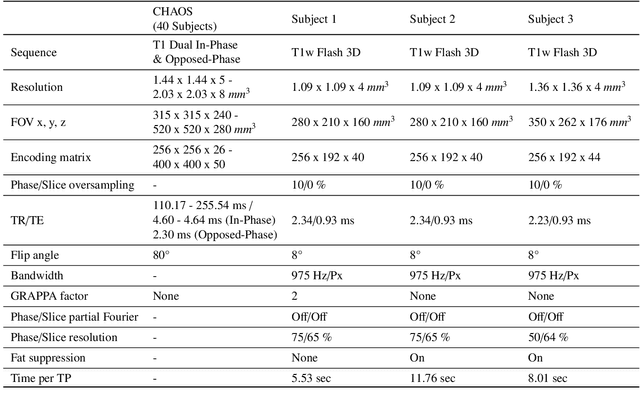
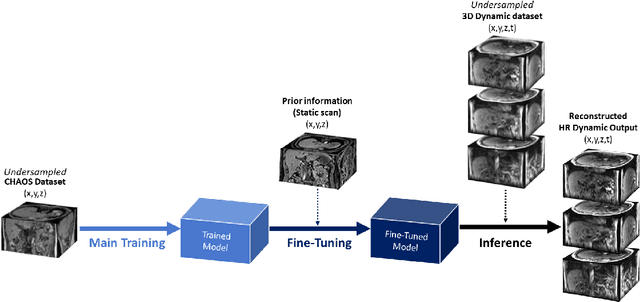
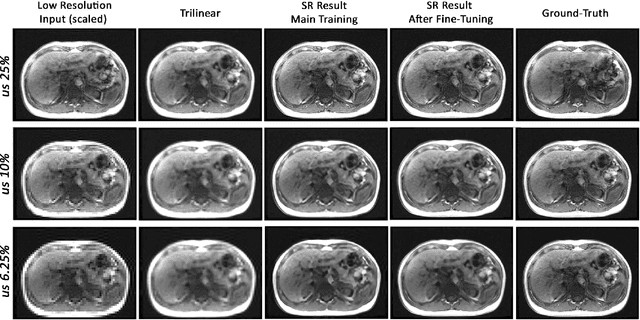

Dynamic imaging is a beneficial tool for interventions to assess physiological changes. Nonetheless during dynamic MRI, while achieving a high temporal resolution, the spatial resolution is compromised. To overcome this spatio-temporal trade-off, this research presents a super-resolution (SR) MRI reconstruction with prior knowledge based fine-tuning to maximise spatial information while preserving high temporal resolution of dynamic MRI. An U-Net based network with perceptual loss is trained on a benchmark dataset and fine-tuned using one subject-specific static high resolution MRI as prior knowledge to obtain high resolution dynamic images during the inference stage. 3D dynamic data for three subjects were acquired with different parameters to test the generalisation capabilities of the network. The method was tested for different levels of in-plane undersampling for dynamic MRI. The reconstructed dynamic SR results showed higher similarity with the high resolution ground-truth after fine-tuning. The average SSIM of the lowest resolution experimented during this research (6.25~\% of the k-space) before and after fine-tuning were 0.939 $\pm$ 0.008 and 0.957 $\pm$ 0.006 respectively. This could theoretically result in an acceleration factor of 16, which can potentially be acquired in less than half a second. The proposed approach shows that the super-resolution MRI reconstruction with prior-information can alleviate the spatio-temporal trade-off in dynamic MRI, even for high acceleration factors.