 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accurate Learning of Graph Representations with Graph Multiset Pooling
Feb 23, 2021
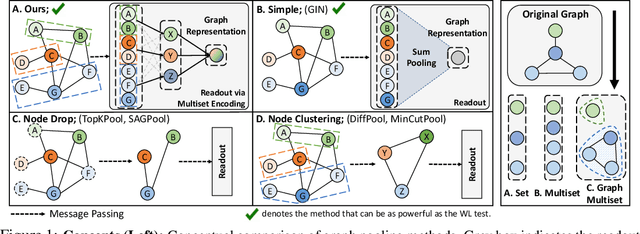
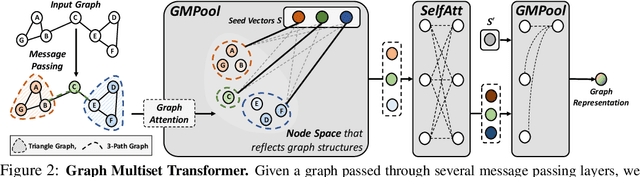
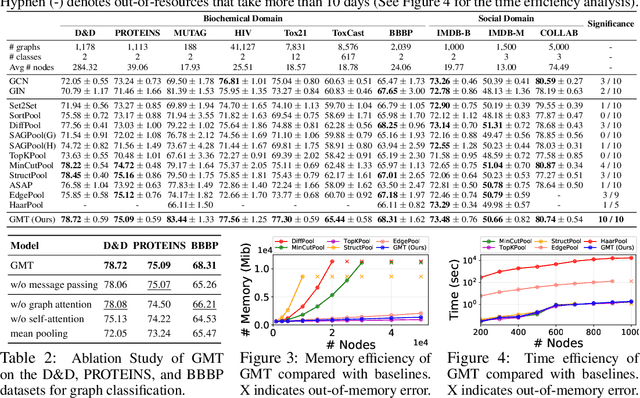
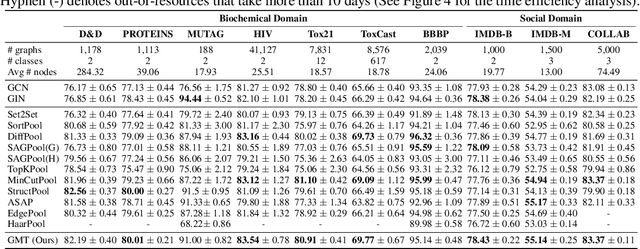
Graph neural networks have been widely used on modeling graph data, achieving impressive results on node classification and link prediction tasks. Yet, obtaining an accurate representation for a graph further requires a pooling function that maps a set of node representations into a compact form. A simple sum or average over all node representations considers all node features equally without consideration of their task relevance, and any structural dependencies among them. Recently proposed hierarchical graph pooling methods, on the other hand, may yield the same representation for two different graphs that are distinguished by the Weisfeiler-Lehman test, as they suboptimally preserve information from the node features. To tackle these limitations of existing graph pooling methods, we first formulate the graph pooling problem as a multiset encoding problem with auxiliary information about the graph structure, and propose a Graph Multiset Transformer (GMT) which is a multi-head attention based global pooling layer that captures the interaction between nodes according to their structural dependencies. We show that GMT satisfies both injectiveness and permutation invariance, such that it is at most as powerful as the Weisfeiler-Lehman graph isomorphism test. Moreover, our methods can be easily extended to the previous node clustering approaches for hierarchical graph pooling. Our experimental results show that GMT significantly outperforms state-of-the-art graph pooling methods on graph classification benchmarks with high memory and time efficiency, and obtains even larger performance gain on graph reconstruction and generation tasks.
Monitoring electrical systems data-network equipment by means ofFuzzy and Paraconsistent Annotated Logic
May 17, 2021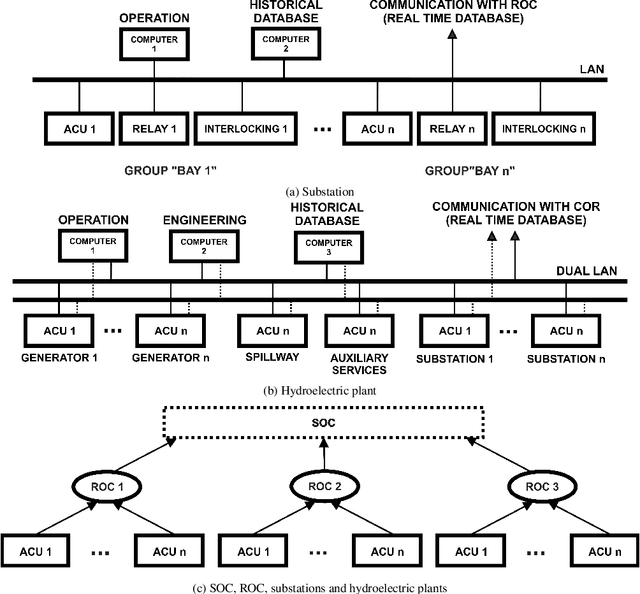
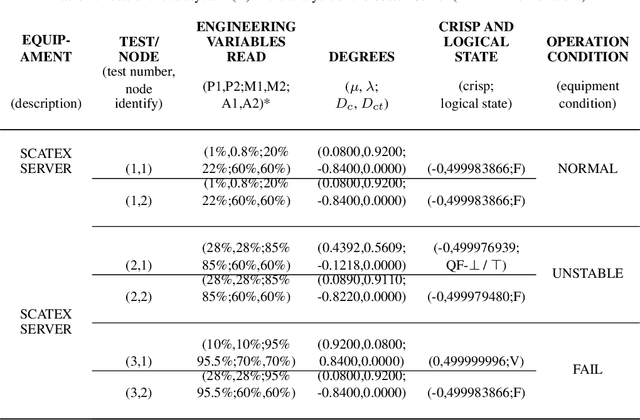
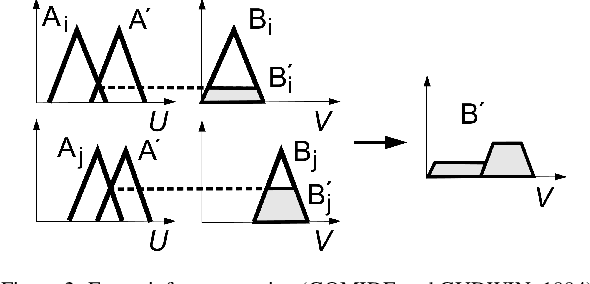
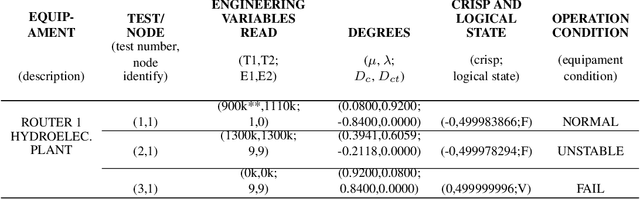
The constant increase in the amount and complexity of information obtained from IT data networkelements, for its correct monitoring and management, is a reality. The same happens to data net-works in electrical systems that provide effective supervision and control of substations and hydro-electric plants. Contributing to this fact is the growing number of installations and new environmentsmonitored by such data networks and the constant evolution of the technologies involved. This sit-uation potentially leads to incomplete and/or contradictory data, issues that must be addressed inorder to maintain a good level of monitoring and, consequently, management of these systems. Inthis paper, a prototype of an expert system is developed to monitor the status of equipment of datanetworks in electrical systems, which deals with inconsistencies without trivialising the inferences.This is accomplished in the context of the remote control of hydroelectric plants and substationsby a Regional Operation Centre (ROC). The expert system is developed with algorithms definedupon a combination of Fuzzy logic and Paraconsistent Annotated Logic with Annotation of TwoValues (PAL2v) in order to analyse uncertain signals and generate the operating conditions (faulty,normal, unstable or inconsistent / indeterminate) of the equipment that are identified as importantfor the remote control of hydroelectric plants and substations. A prototype of this expert systemwas installed on a virtualised server with CLP500 software (from the EFACEC manufacturer) thatwas applied to investigate scenarios consisting of a Regional (Brazilian) Operation Centre, with aGeneric Substation and a Generic Hydroelectric Plant, representing a remote control environment.
Graph Attention Tracking
Nov 23, 2020

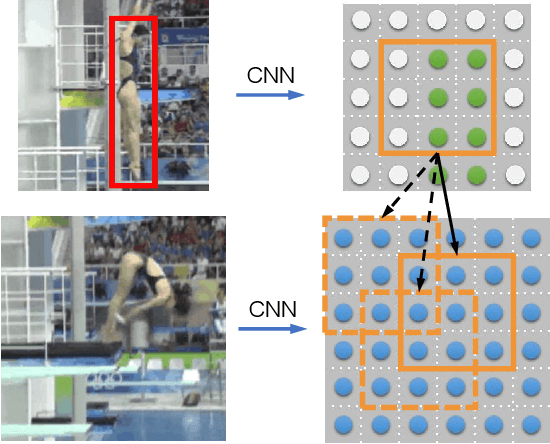
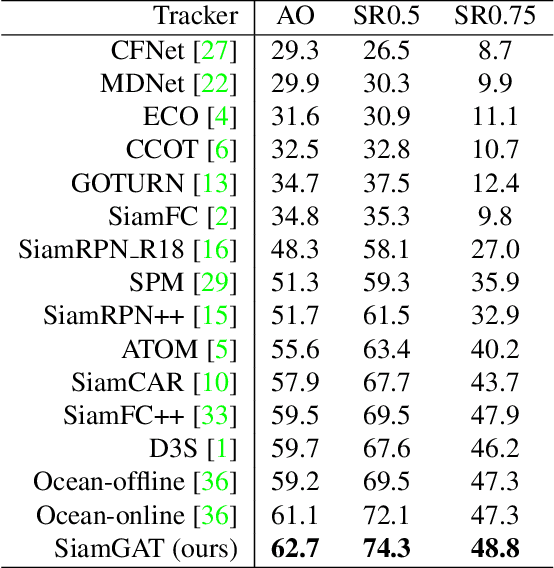
Siamese network based trackers formulate the visual tracking task as a similarity matching problem. Almost all popular Siamese trackers realize the similarity learning via convolutional feature cross-correlation between a target branch and a search branch. However, since the size of target feature region needs to be pre-fixed, these cross-correlation base methods suffer from either reserving much adverse background information or missing a great deal of foreground information. Moreover, the global matching between the target and search region also largely neglects the target structure and part-level information. In this paper, to solve the above issues, we propose a simple target-aware Siamese graph attention network for general object tracking. We propose to establish part-to-part correspondence between the target and the search region with a complete bipartite graph, and apply the graph attention mechanism to propagate target information from the template feature to the search feature. Further, instead of using the pre-fixed region cropping for template-feature-area selection, we investigate a target-aware area selection mechanism to fit the size and aspect ratio variations of different objects. Experiments on challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance. Code is available at: https://git.io/SiamGAT
R2D2: Relational Text Decoding with Transformers
May 10, 2021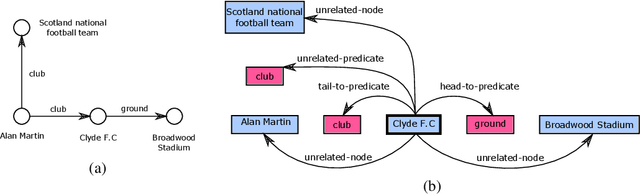
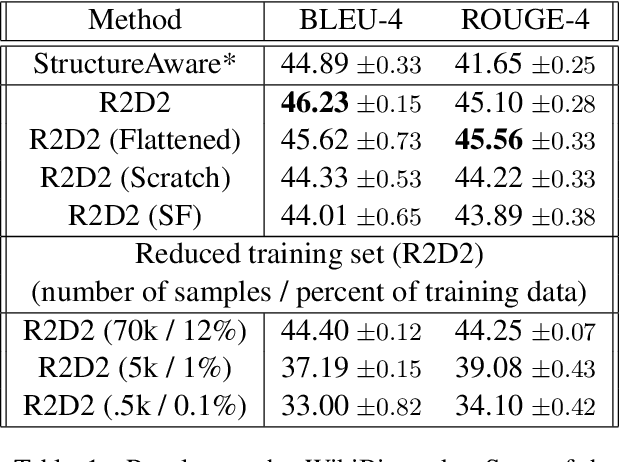
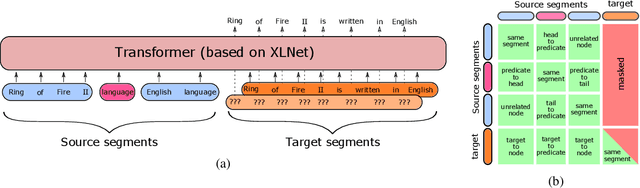
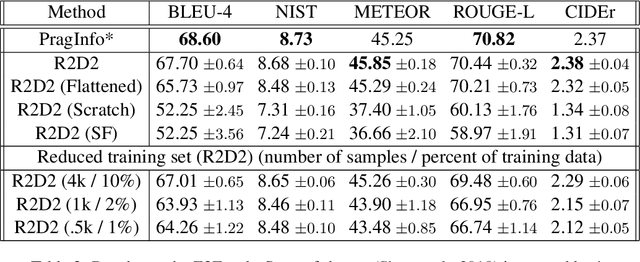
We propose a novel framework for modeling the interaction between graphical structures and the natural language text associated with their nodes and edges. Existing approaches typically fall into two categories. On group ignores the relational structure by converting them into linear sequences and then utilize the highly successful Seq2Seq models. The other side ignores the sequential nature of the text by representing them as fixed-dimensional vectors and apply graph neural networks. Both simplifications lead to information loss. Our proposed method utilizes both the graphical structure as well as the sequential nature of the texts. The input to our model is a set of text segments associated with the nodes and edges of the graph, which are then processed with a transformer encoder-decoder model, equipped with a self-attention mechanism that is aware of the graphical relations between the nodes containing the segments. This also allows us to use BERT-like models that are already trained on large amounts of text. While the proposed model has wide applications, we demonstrate its capabilities on data-to-text generation tasks. Our approach compares favorably against state-of-the-art methods in four tasks without tailoring the model architecture. We also provide an early demonstration in a novel practical application -- generating clinical notes from the medical entities mentioned during clinical visits.
geoGAT: Graph Model Based on Attention Mechanism for Geographic Text Classification
Jan 13, 2021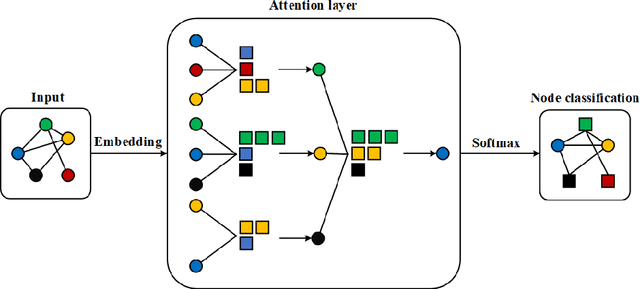

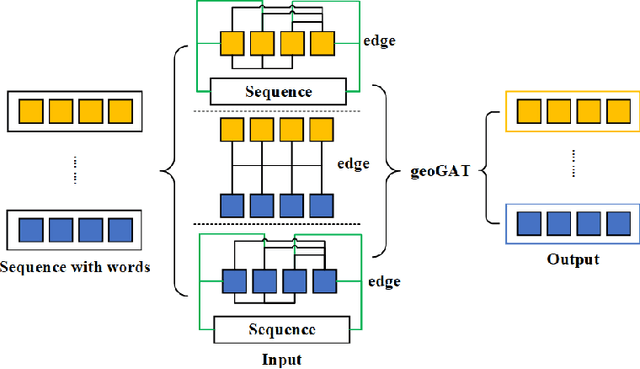
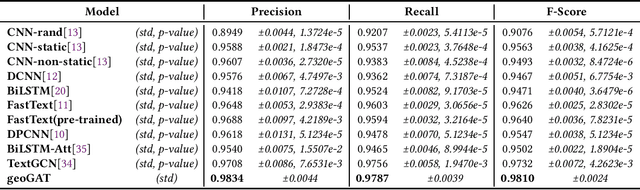
In the area of geographic information processing. There are few researches on geographic text classification. However, the application of this task in Chinese is relatively rare. In our work, we intend to implement a method to extract text containing geographical entities from a large number of network text. The geographic information in these texts is of great practical significance to transportation, urban and rural planning, disaster relief and other fields. We use the method of graph convolutional neural network with attention mechanism to achieve this function. Graph attention networks is an improvement of graph convolutional neural networks. Compared with GCN, the advantage of GAT is that the attention mechanism is proposed to weight the sum of the characteristics of adjacent nodes. In addition, We construct a Chinese dataset containing geographical classification from multiple datasets of Chinese text classification. The Macro-F Score of the geoGAT we used reached 95\% on the new Chinese dataset.
Weighted Least Squares Twin Support Vector Machine with Fuzzy Rough Set Theory for Imbalanced Data Classification
May 03, 2021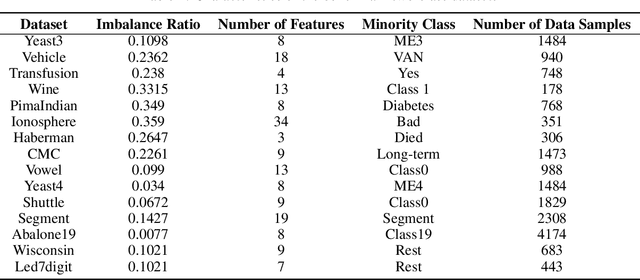
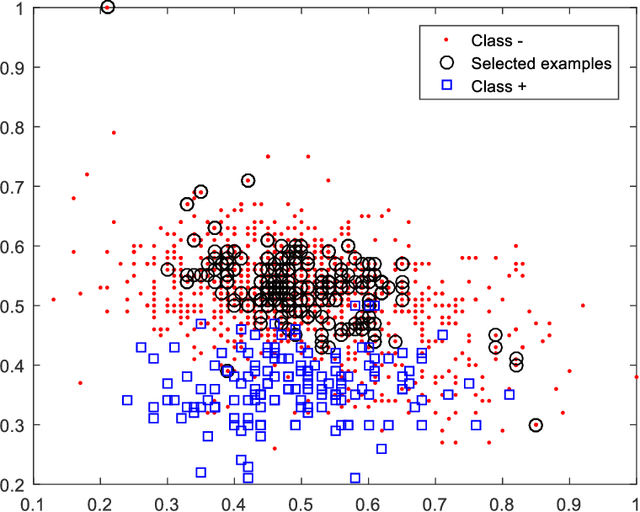

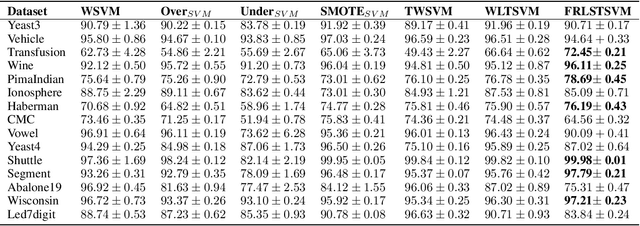
Support vector machines (SVMs) are powerful supervised learning tools developed to solve classification problems. However, SVMs are likely to perform poorly in the classification of imbalanced data. The rough set theory presents a mathematical tool for inference in nondeterministic cases that provides methods for removing irrelevant information from data. In this work, we propose an approach that efficiently used fuzzy rough set theory in weighted least squares twin support vector machine called FRLSTSVM for classification of imbalanced data. The first innovation is introducing a new fuzzy rough set based under-sampling strategy to make the classifier robust in terms of imbalanced data. For constructing the two proximal hyperplanes in FRLSTSVM, data points from the minority class remain unchanged while a subset of data points in the majority class are selected using a new method. In this model, we embedded the weight biases in the LSTSVM formulations to overcome the bias phenomenon in the original twin SVM for the classification of imbalanced data. In order to determine these weights in this formulation, we introduced a new strategy that uses fuzzy rough set theory as the second innovation. Experimental results on famous imbalanced datasets, compared with related traditional SVM-based methods, demonstrate the superiority of our proposed FRLSTSVM model in imbalanced data classification.
Flexible Operations for Natural Language Deduction
Apr 18, 2021
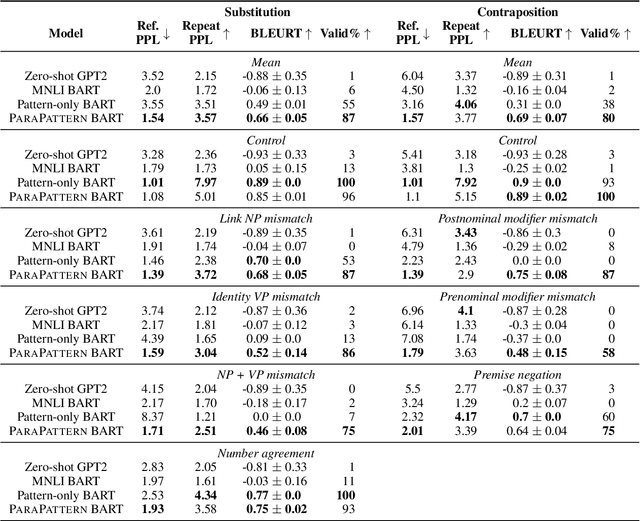
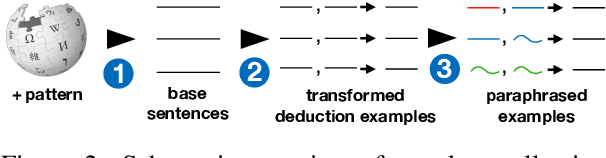
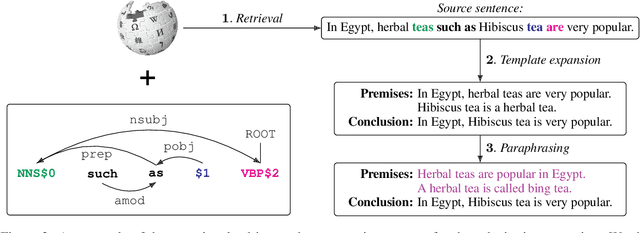
An interpretable system for complex, open-domain reasoning needs an interpretable meaning representation. Natural language is an excellent candidate -- it is both extremely expressive and easy for humans to understand. However, manipulating natural language statements in logically consistent ways is hard. Models have to be precise, yet robust enough to handle variation in how information is expressed. In this paper, we describe ParaPattern, a method for building models to generate logical transformations of diverse natural language inputs without direct human supervision. We use a BART-based model (Lewis et al., 2020) to generate the result of applying a particular logical operation to one or more premise statements. Crucially, we have a largely automated pipeline for scraping and constructing suitable training examples from Wikipedia, which are then paraphrased to give our models the ability to handle lexical variation. We evaluate our models using targeted contrast sets as well as out-of-domain sentence compositions from the QASC dataset (Khot et al., 2020). Our results demonstrate that our operation models are both accurate and flexible.
MonoGRNet: A General Framework for Monocular 3D Object Detection
Apr 18, 2021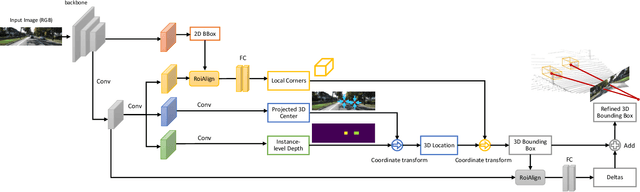
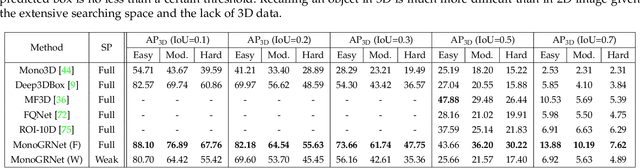
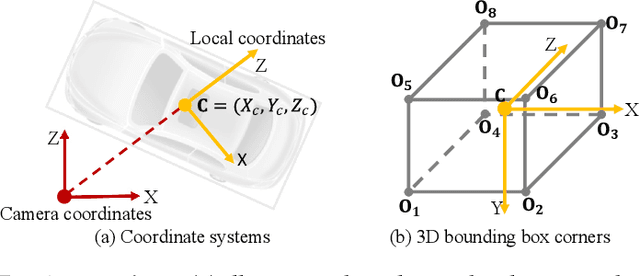
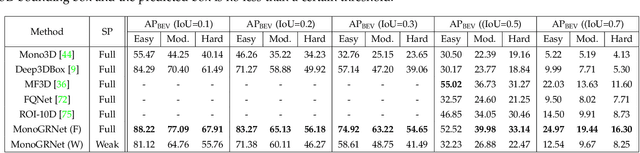
Detecting and localizing objects in the real 3D space, which plays a crucial role in scene understanding, is particularly challenging given only a monocular image due to the geometric information loss during imagery projection. We propose MonoGRNet for the amodal 3D object detection from a monocular image via geometric reasoning in both the observed 2D projection and the unobserved depth dimension. MonoGRNet decomposes the monocular 3D object detection task into four sub-tasks including 2D object detection, instance-level depth estimation, projected 3D center estimation and local corner regression. The task decomposition significantly facilitates the monocular 3D object detection, allowing the target 3D bounding boxes to be efficiently predicted in a single forward pass, without using object proposals, post-processing or the computationally expensive pixel-level depth estimation utilized by previous methods. In addition, MonoGRNet flexibly adapts to both fully and weakly supervised learning, which improves the feasibility of our framework in diverse settings. Experiments are conducted on KITTI, Cityscapes and MS COCO datasets. Results demonstrate the promising performance of our framework in various scenarios.
UniParma at SemEval-2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
Apr 09, 2021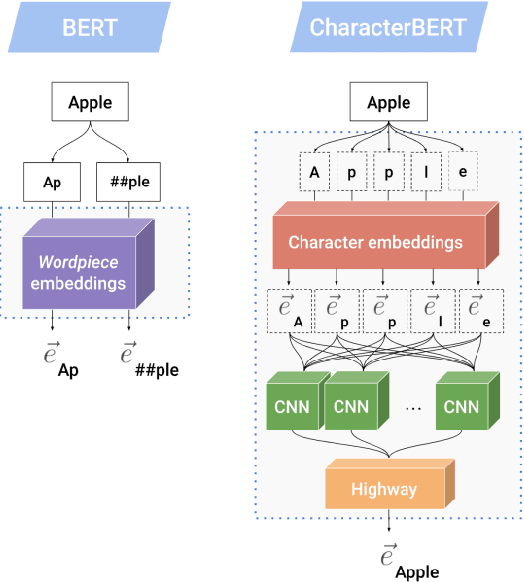

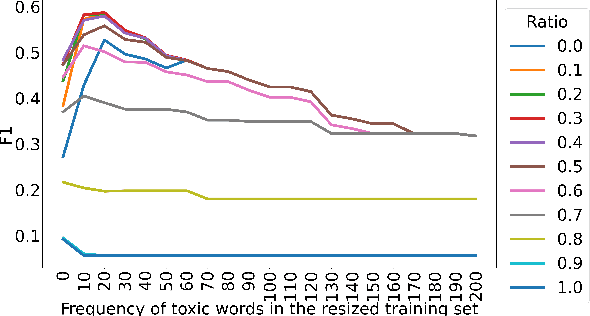
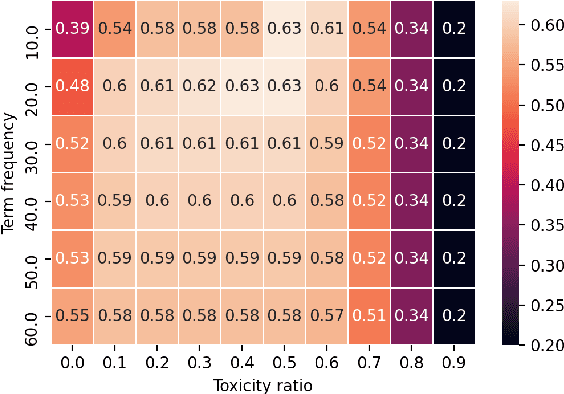
With the ever-increasing availability of digital information, toxic content is also on the rise. Therefore, the detection of this type of language is of paramount importance. We tackle this problem utilizing a combination of a state-of-the-art pre-trained language model (CharacterBERT) and a traditional bag-of-words technique. Since the content is full of toxic words that have not been written according to their dictionary spelling, attendance to individual characters is crucial. Therefore, we use CharacterBERT to extract features based on the word characters. It consists of a CharacterCNN module that learns character embeddings from the context. These are, then, fed into the well-known BERT architecture. The bag-of-words method, on the other hand, further improves upon that by making sure that some frequently used toxic words get labeled accordingly. With a 4 percent difference from the first team, our system ranked 36th in the competition. The code is available for further re-search and reproduction of the results.
Automatic Breast Lesion Detection in Ultrafast DCE-MRI Using Deep Learning
Feb 07, 2021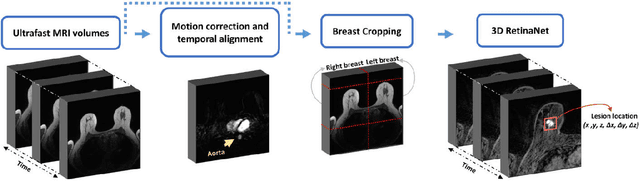
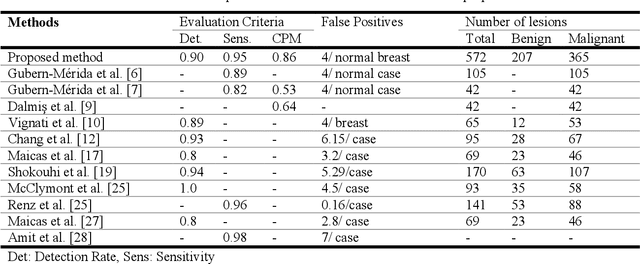

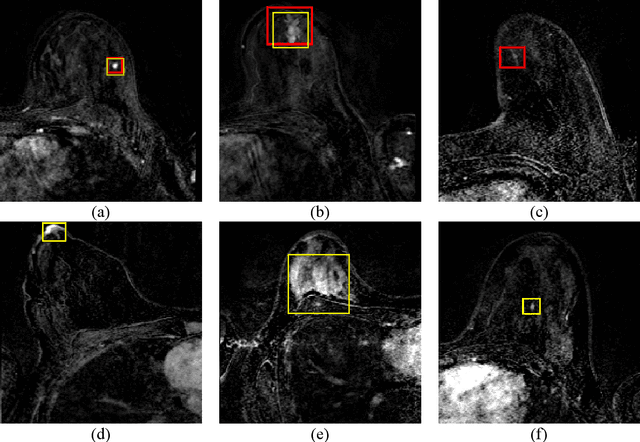
Purpose: We propose a deep learning-based computer-aided detection (CADe) method to detect breast lesions in ultrafast DCE-MRI sequences. This method uses both the three-dimensional spatial information and temporal information obtained from the early-phase of the dynamic acquisition.Methods: The proposed CADe method, based on a modified 3D RetinaNet model, operates on ultrafast T1 weighted sequences, which are preprocessed for motion compensation, temporal normalization, and are cropped before passing into the model. The model is optimized to enable the detection of relatively small breast lesions in a screening setting, focusing on detection of lesions that are harder to differentiate from confounding structures inside the breast.Results: The method was developed based on a dataset consisting of 489 ultrafast MRI studies obtained from 462 patients containing a total of 572 lesions (365 malignant, 207 benign) and achieved a detection rate, sensitivity, and detection rate of benign lesions of 0.90, 0.95, and 0.86 at 4 false positives per normal breast with a 10-fold cross-validation, respectively.Conclusions: The deep learning architecture used for the proposed CADe application can efficiently detect benign and malignant lesions on ultrafast DCE-MRI. Furthermore, utilizing the less visible hard-to detect-lesions in training improves the learning process and, subsequently, detection of malignant breast lesions.