 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Scoring with Delayed Information: A Convex Optimization Viewpoint
Jul 09, 2018
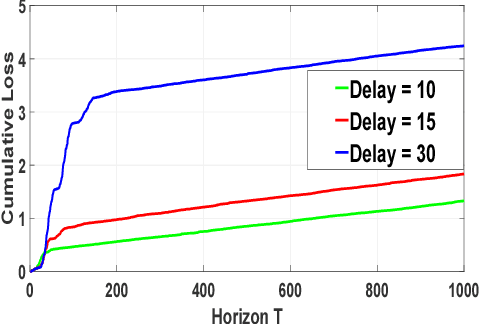
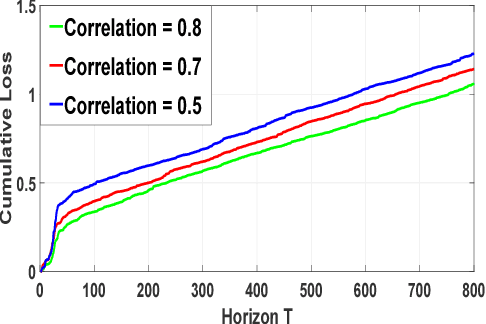
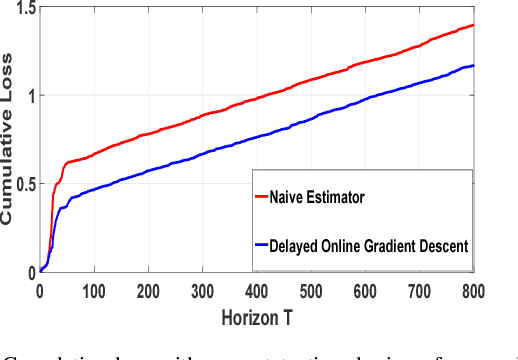
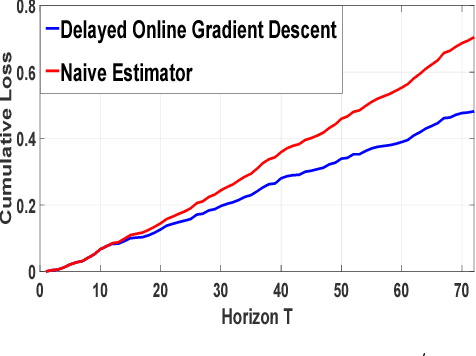
We consider a system where agents enter in an online fashion and are evaluated based on their attributes or context vectors. There can be practical situations where this context is partially observed, and the unobserved part comes after some delay. We assume that an agent, once left, cannot re-enter the system. Therefore, the job of the system is to provide an estimated score for the agent based on her instantaneous score and possibly some inference of the instantaneous score over the delayed score. In this paper, we estimate the delayed context via an online convex game between the agent and the system. We argue that the error in the score estimate accumulated over $T$ iterations is small if the regret of the online convex game is small. Further, we leverage side information about the delayed context in the form of a correlation function with the known context. We consider the settings where the delay is fixed or arbitrarily chosen by an adversary. Furthermore, we extend the formulation to the setting where the contexts are drawn from some Banach space. Overall, we show that the average penalty for not knowing the delayed context while making a decision scales with $\mathcal{O}(\frac{1}{\sqrt{T}})$, where this can be improved to $\mathcal{O}(\frac{\log T}{T})$ under special setting.
Communication Topology Co-Design in Graph Recurrent Neural Network Based Distributed Control
Apr 28, 2021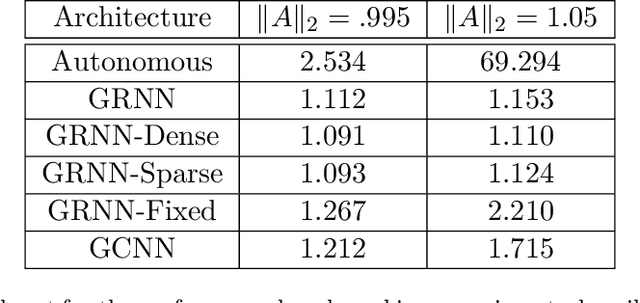
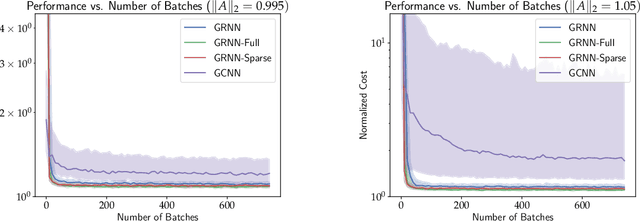


When designing large-scale distributed controllers, the information-sharing constraints between sub-controllers, as defined by a communication topology interconnecting them, are as important as the controller itself. Controllers implemented using dense topologies typically outperform those implemented using sparse topologies, but it is also desirable to minimize the cost of controller deployment. Motivated by the above, we introduce a compact but expressive graph recurrent neural network (GRNN) parameterization of distributed controllers that is well suited for distributed controller and communication topology co-design. Our proposed parameterization enjoys a local and distributed architecture, similar to previous Graph Neural Network (GNN)-based parameterizations, while further naturally allowing for joint optimization of the distributed controller and communication topology needed to implement it. We show that the distributed controller/communication topology co-design task can be posed as an $\ell_1$-regularized empirical risk minimization problem that can be efficiently solved using stochastic gradient methods. We run extensive simulations to study the performance of GRNN-based distributed controllers and show that (a) they achieve performance comparable to GNN-based controllers while having fewer free parameters, and (b) our method allows for performance/communication density tradeoff curves to be efficiently approximated.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 02, 2021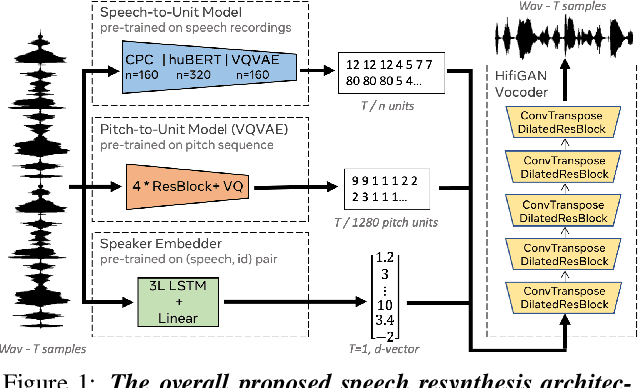
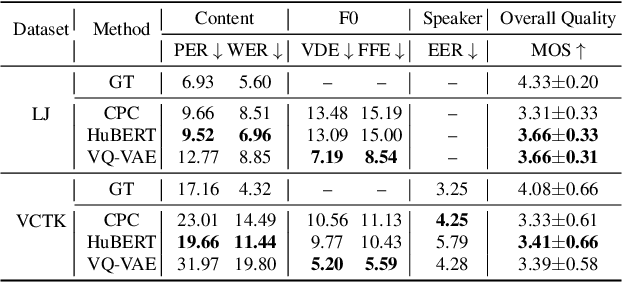
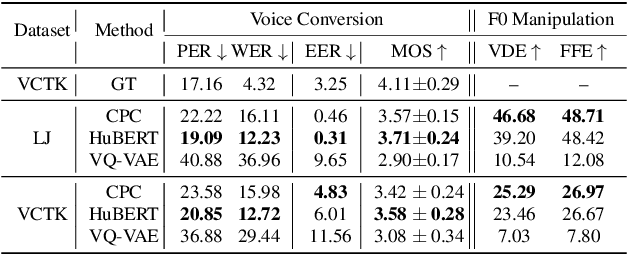
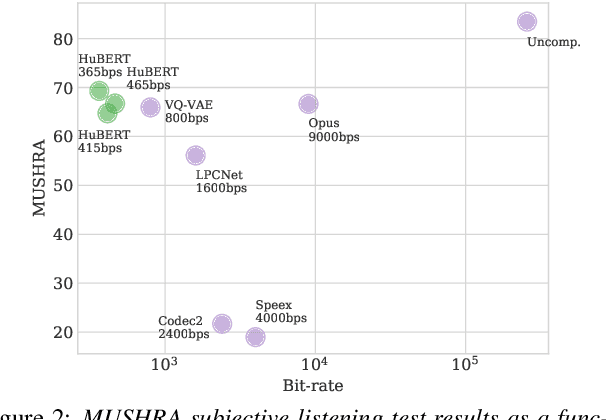
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
Multimodal Self-Supervised Learning of General Audio Representations
Apr 28, 2021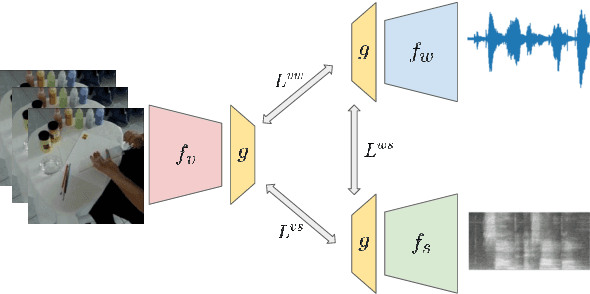

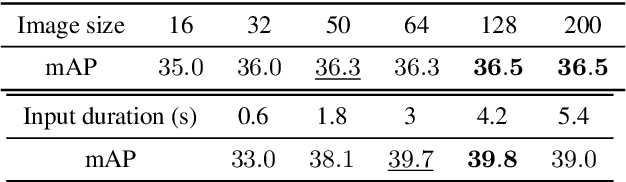

We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.
APIK: Active Physics-Informed Kriging Model with Partial Differential Equations
Dec 22, 2020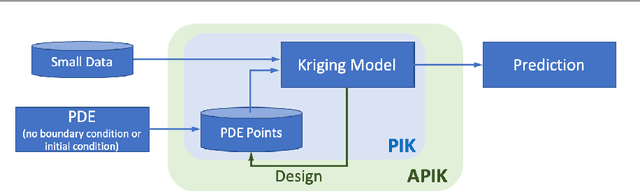
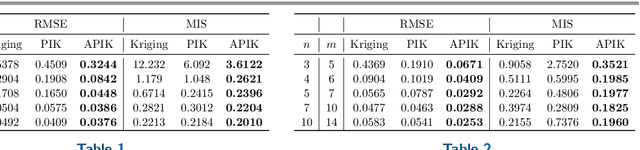


Kriging (or Gaussian process regression) is a popular machine learning method for its flexibility and closed-form prediction expressions. However, one of the key challenges in applying kriging to engineering systems is that the available measurement data is scarce due to the measurement limitations and high sensing costs. On the other hand, physical knowledge of the engineering system is often available and represented in the form of partial differential equations (PDEs). We present in this work a PDE Informed Kriging model (PIK), which introduces PDE information via a set of PDE points and conducts posterior prediction similar to the standard kriging method. The proposed PIK model can incorporate physical knowledge from both linear and nonlinear PDEs. To further improve learning performance, we propose an Active PIK framework (APIK) that designs PDE points to leverage the PDE information based on the PIK model and measurement data. The selected PDE points not only explore the whole input space but also exploit the locations where the PDE information is critical in reducing predictive uncertainty. Finally, an expectation-maximization algorithm is developed for parameter estimation. We demonstrate the effectiveness of APIK in two synthetic examples, a shock wave case study, and a laser heating case study.
Geometric Deep Learning on Anatomical Meshes for the Prediction of Alzheimer's Disease
Apr 20, 2021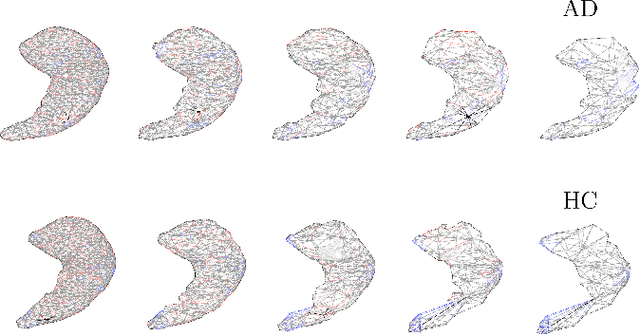
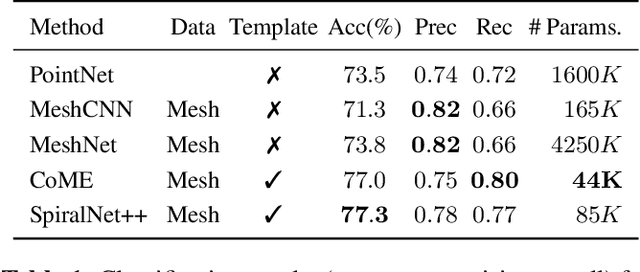
Geometric deep learning can find representations that are optimal for a given task and therefore improve the performance over pre-defined representations. While current work has mainly focused on point representations, meshes also contain connectivity information and are therefore a more comprehensive characterization of the underlying anatomical surface. In this work, we evaluate four recent geometric deep learning approaches that operate on mesh representations. These approaches can be grouped into template-free and template-based approaches, where the template-based methods need a more elaborate pre-processing step with the definition of a common reference template and correspondences. We compare the different networks for the prediction of Alzheimer's disease based on the meshes of the hippocampus. Our results show advantages for template-based methods in terms of accuracy, number of learnable parameters, and training speed. While the template creation may be limiting for some applications, neuroimaging has a long history of building templates with automated tools readily available. Overall, working with meshes is more involved than working with simplistic point clouds, but they also offer new avenues for designing geometric deep learning architectures.
DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data
May 05, 2021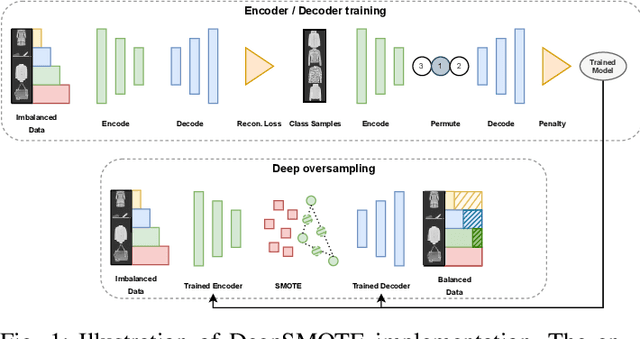

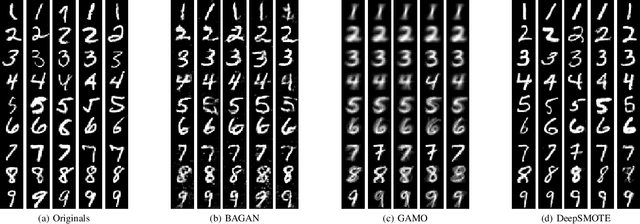

Despite over two decades of progress, imbalanced data is still considered a significant challenge for contemporary machine learning models. Modern advances in deep learning have magnified the importance of the imbalanced data problem. The two main approaches to address this issue are based on loss function modifications and instance resampling. Instance sampling is typically based on Generative Adversarial Networks (GANs), which may suffer from mode collapse. Therefore, there is a need for an oversampling method that is specifically tailored to deep learning models, can work on raw images while preserving their properties, and is capable of generating high quality, artificial images that can enhance minority classes and balance the training set. We propose DeepSMOTE - a novel oversampling algorithm for deep learning models. It is simple, yet effective in its design. It consists of three major components: (i) an encoder/decoder framework; (ii) SMOTE-based oversampling; and (iii) a dedicated loss function that is enhanced with a penalty term. An important advantage of DeepSMOTE over GAN-based oversampling is that DeepSMOTE does not require a discriminator, and it generates high-quality artificial images that are both information-rich and suitable for visual inspection. DeepSMOTE code is publicly available at: https://github.com/dd1github/DeepSMOTE
Pose-driven Attention-guided Image Generation for Person Re-Identification
Apr 28, 2021
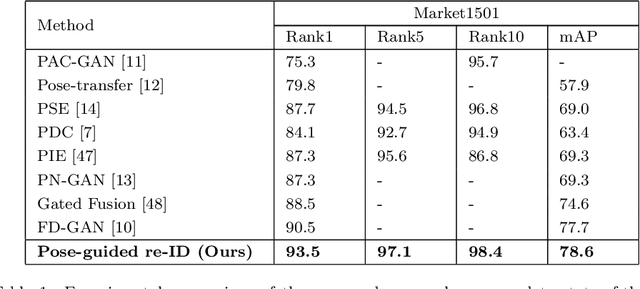
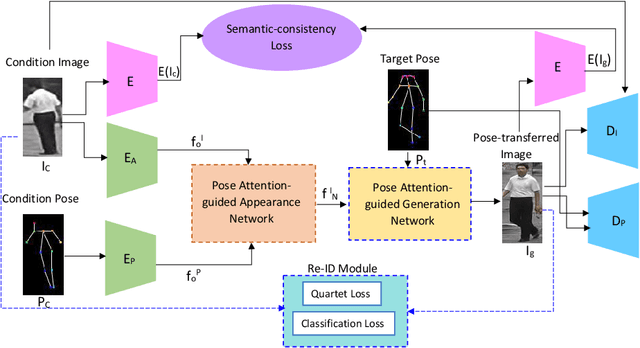
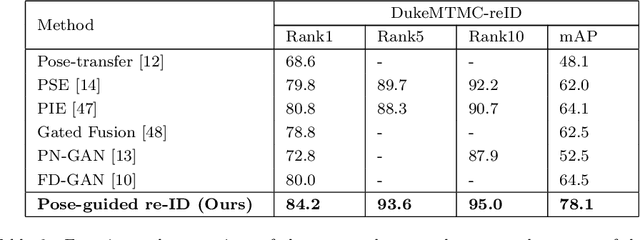
Person re-identification (re-ID) concerns the matching of subject images across different camera views in a multi camera surveillance system. One of the major challenges in person re-ID is pose variations across the camera network, which significantly affects the appearance of a person. Existing development data lack adequate pose variations to carry out effective training of person re-ID systems. To solve this issue, in this paper we propose an end-to-end pose-driven attention-guided generative adversarial network, to generate multiple poses of a person. We propose to attentively learn and transfer the subject pose through an attention mechanism. A semantic-consistency loss is proposed to preserve the semantic information of the person during pose transfer. To ensure fine image details are realistic after pose translation, an appearance discriminator is used while a pose discriminator is used to ensure the pose of the transferred images will exactly be the same as the target pose. We show that by incorporating the proposed approach in a person re-identification framework, realistic pose transferred images and state-of-the-art re-identification results can be achieved.
Text-Aware Predictive Monitoring of Business Processes
Apr 20, 2021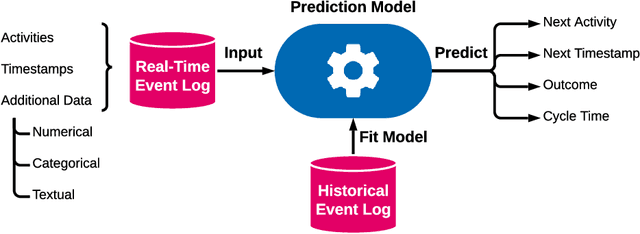

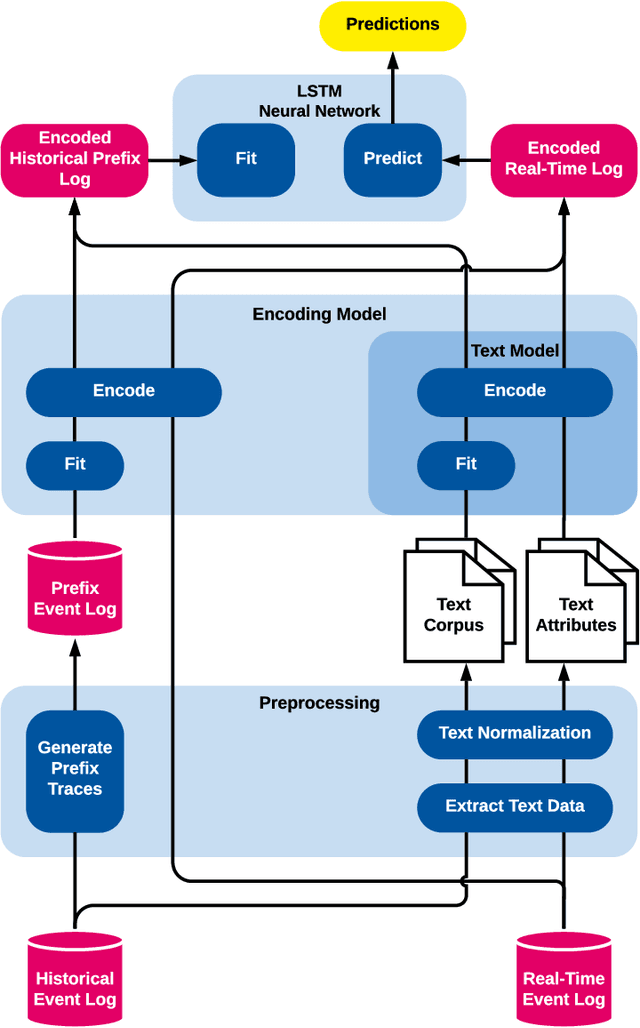
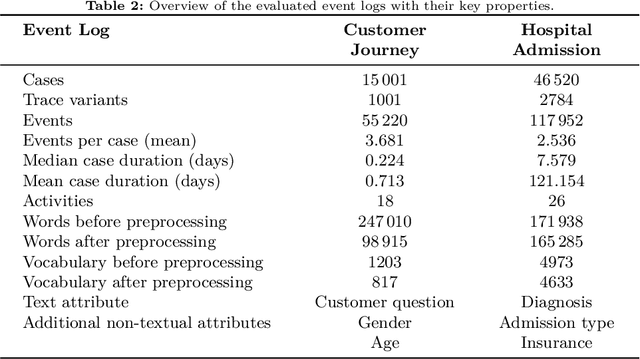
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
Introducing the Talk Markup Language (TalkML):Adding a little social intelligence to industrial speech interfaces
May 24, 2021



Virtual Personal Assistants like Siri have great potential but such developments hit the fundamental problem of how to make computational devices that understand human speech. Natural language understanding is one of the more disappointing failures of AI research and it seems there is something we computer scientists don't get about the nature of language. Of course philosophers and linguists think quite differently about language and this paper describes how we have taken ideas from other disciplines and implemented them. The background to the work is to take seriously the notion of language as action and look at what people actually do with language using the techniques of Conversation Analysis. The observation has been that human communication is (behind the scenes) about the management of social relations as well as the (foregrounded) passing of information. To claim this is one thing but to implement it requires a mechanism. The mechanism described here is based on the notion of language being intentional - we think intentionally, talk about them and recognise them in others - and cooperative in that we are compelled to help out. The way we are compelled points to a solution to the ever present problem of keeping the human on topic. The approach has led to a recent success in which we significantly improve user satisfaction independent of task completion. Talk Markup Language (TalkML) is a draft alternative to VoiceXML that, we propose, greatly simplifies the scripting of interaction by providing default behaviours for no input and not recognised speech events.