 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text-Aware Predictive Monitoring of Business Processes
Apr 21, 2021
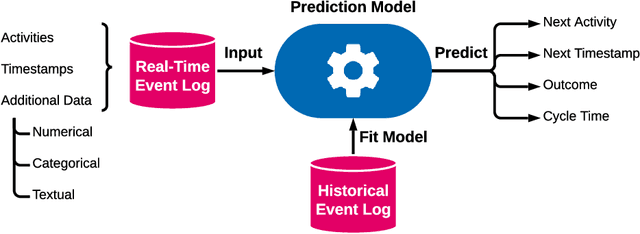

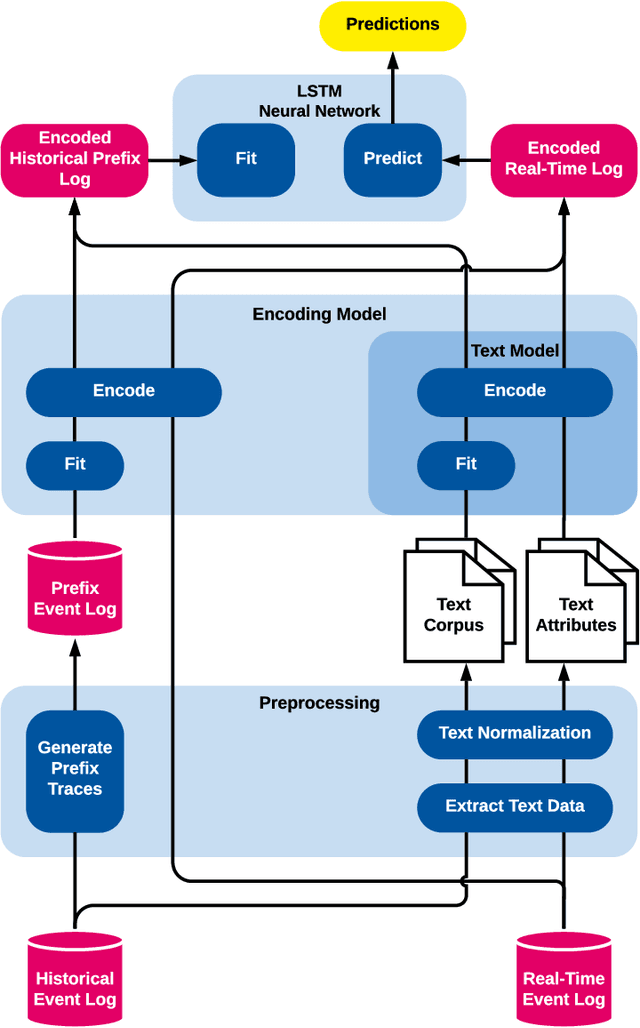
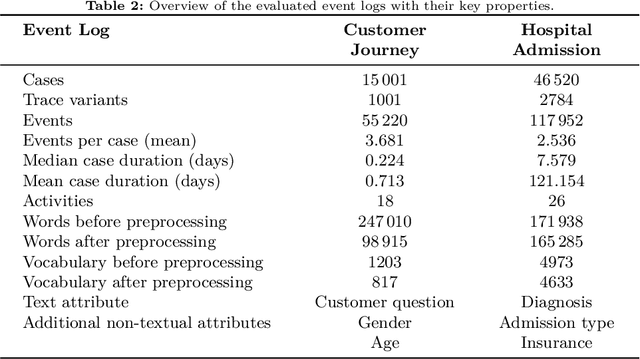
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
May 06, 2021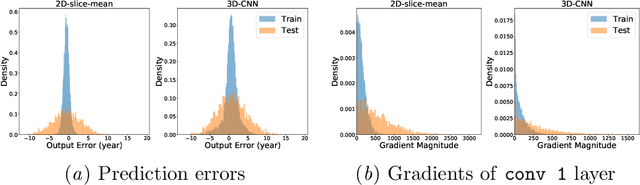


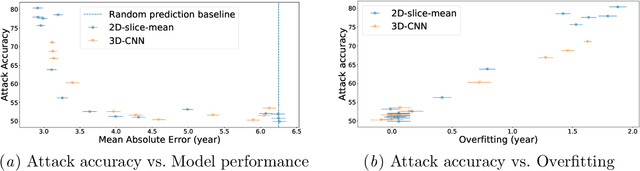
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.
Heterogeneous Network Embedding for Deep Semantic Relevance Match in E-commerce Search
Jan 13, 2021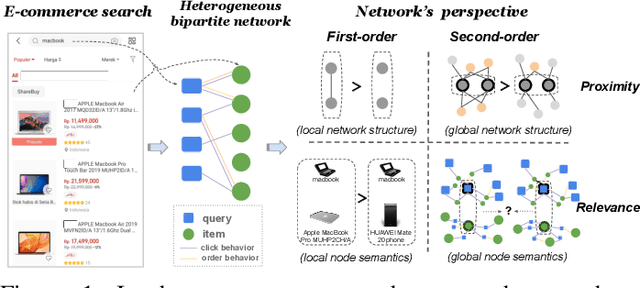
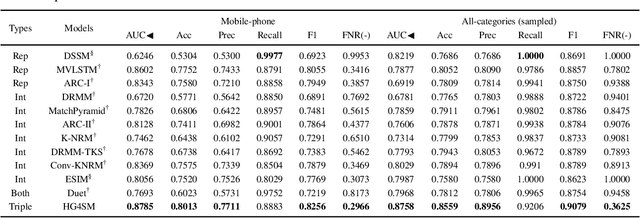
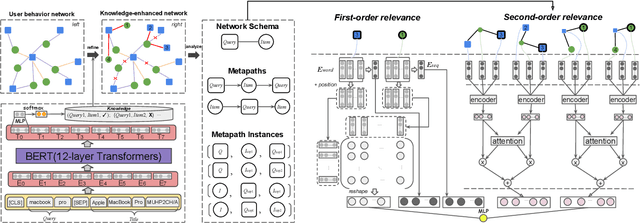
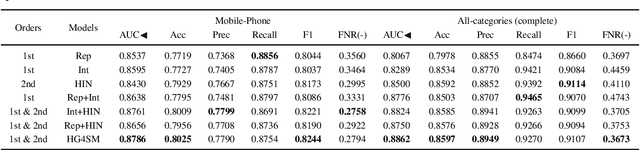
Result relevance prediction is an essential task of e-commerce search engines to boost the utility of search engines and ensure smooth user experience. The last few years eyewitnessed a flurry of research on the use of Transformer-style models and deep text-match models to improve relevance. However, these two types of models ignored the inherent bipartite network structures that are ubiquitous in e-commerce search logs, making these models ineffective. We propose in this paper a novel Second-order Relevance, which is fundamentally different from the previous First-order Relevance, to improve result relevance prediction. We design, for the first time, an end-to-end First-and-Second-order Relevance prediction model for e-commerce item relevance. The model is augmented by the neighborhood structures of bipartite networks that are built using the information of user behavioral feedback, including clicks and purchases. To ensure that edges accurately encode relevance information, we introduce external knowledge generated from BERT to refine the network of user behaviors. This allows the new model to integrate information from neighboring items and queries, which are highly relevant to the focus query-item pair under consideration. Results of offline experiments showed that the new model significantly improved the prediction accuracy in terms of human relevance judgment. An ablation study showed that the First-and-Second-order model gained a 4.3% average gain over the First-order model. Results of an online A/B test revealed that the new model derived more commercial benefits compared to the base model.
Active learning for medical code assignment
Apr 12, 2021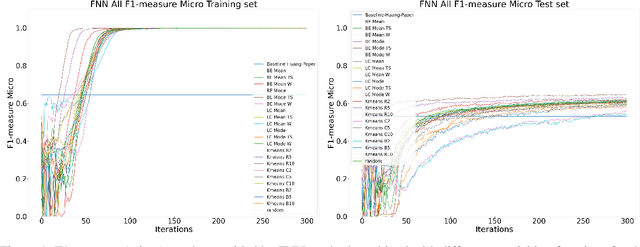
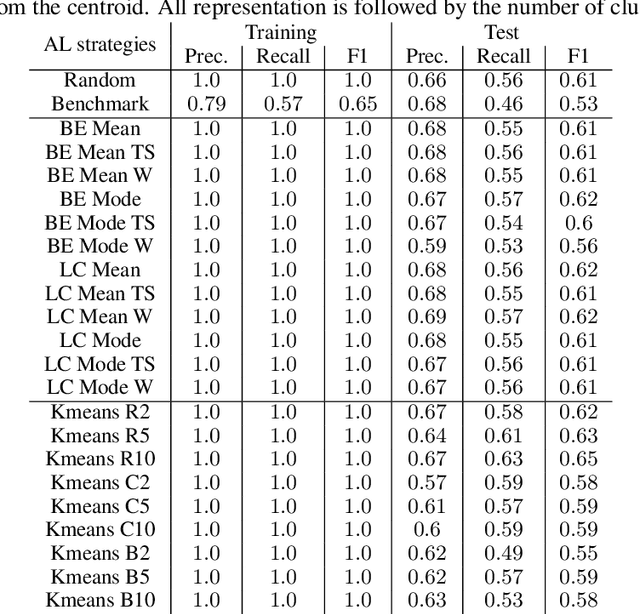
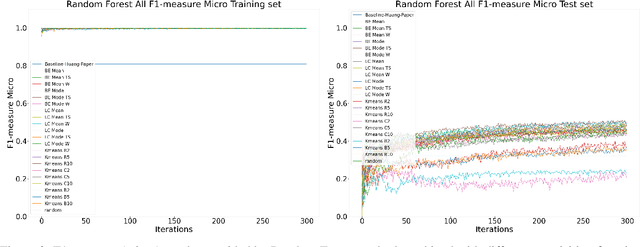
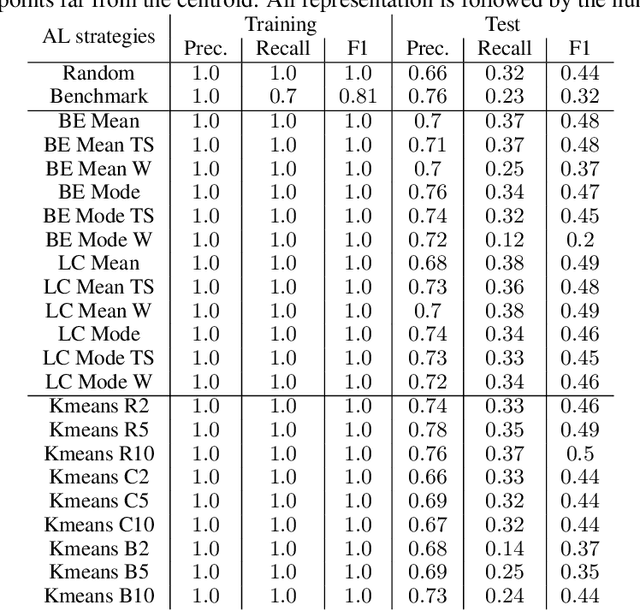
Machine Learning (ML) is widely used to automatically extract meaningful information from Electronic Health Records (EHR) to support operational, clinical, and financial decision-making. However, ML models require a large number of annotated examples to provide satisfactory results, which is not possible in most healthcare scenarios due to the high cost of clinician-labeled data. Active Learning (AL) is a process of selecting the most informative instances to be labeled by an expert to further train a supervised algorithm. We demonstrate the effectiveness of AL in multi-label text classification in the clinical domain. In this context, we apply a set of well-known AL methods to help automatically assign ICD-9 codes on the MIMIC-III dataset. Our results show that the selection of informative instances provides satisfactory classification with a significantly reduced training set (8.3\% of the total instances). We conclude that AL methods can significantly reduce the manual annotation cost while preserving model performance.
Multi-Domain Adaptation in Neural Machine Translation Through Multidimensional Tagging
Feb 19, 2021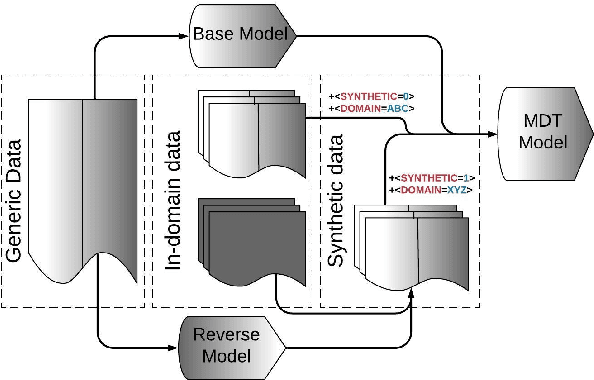
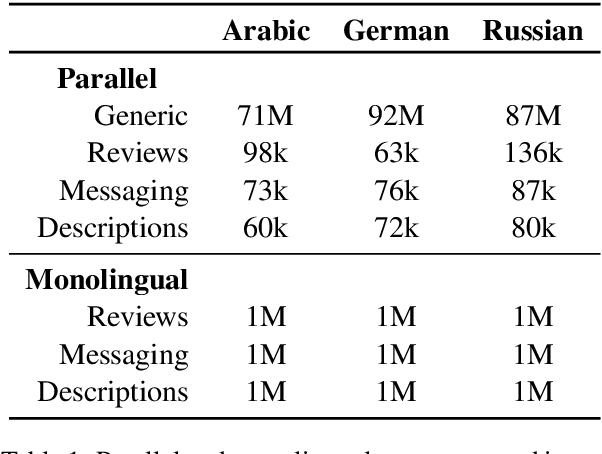
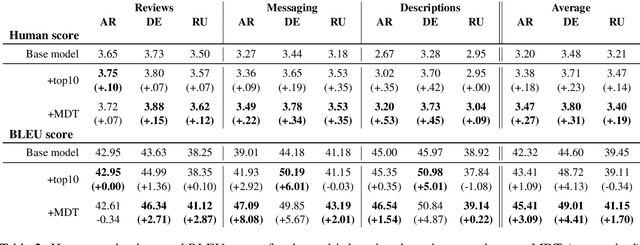
Many modern Neural Machine Translation (NMT) systems are trained on nonhomogeneous datasets with several distinct dimensions of variation (e.g. domain, source, generation method, style, etc.). We describe and empirically evaluate multidimensional tagging (MDT), a simple yet effective method for passing sentence-level information to the model. Our human and BLEU evaluation results show that MDT can be applied to the problem of multi-domain adaptation and significantly reduce training costs without sacrificing the translation quality on any of the constituent domains.
Towards Efficient Graph Convolutional Networks for Point Cloud Handling
Apr 12, 2021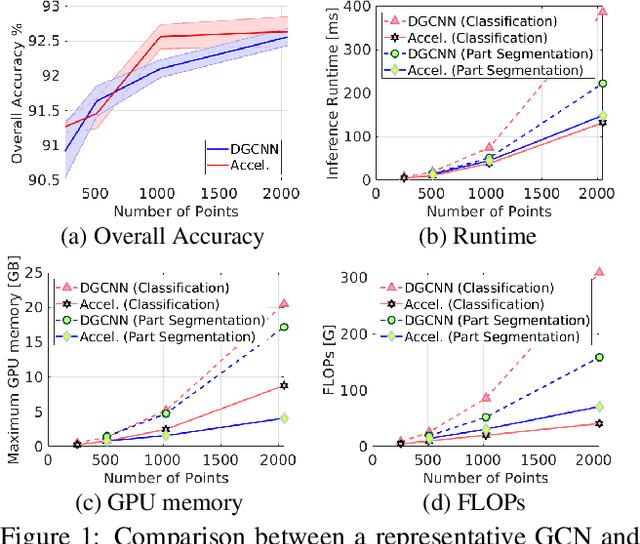
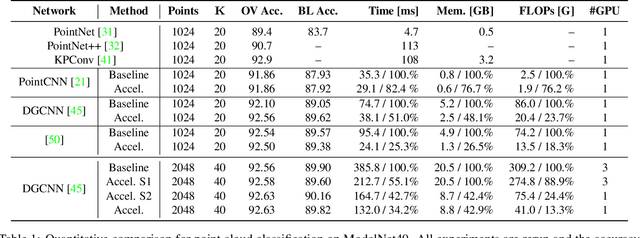
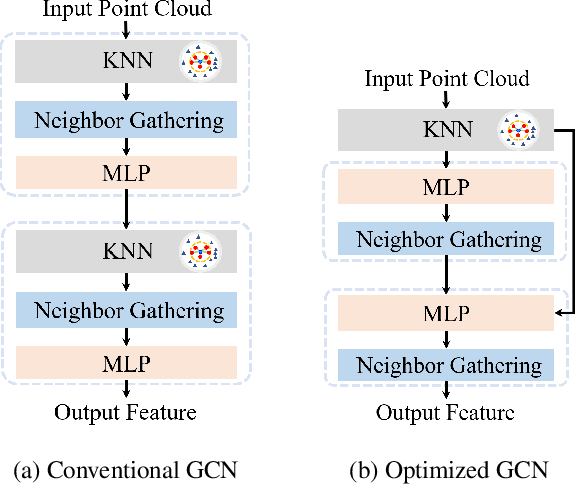

In this paper, we aim at improving the computational efficiency of graph convolutional networks (GCNs) for learning on point clouds. The basic graph convolution that is typically composed of a $K$-nearest neighbor (KNN) search and a multilayer perceptron (MLP) is examined. By mathematically analyzing the operations there, two findings to improve the efficiency of GCNs are obtained. (1) The local geometric structure information of 3D representations propagates smoothly across the GCN that relies on KNN search to gather neighborhood features. This motivates the simplification of multiple KNN searches in GCNs. (2) Shuffling the order of graph feature gathering and an MLP leads to equivalent or similar composite operations. Based on those findings, we optimize the computational procedure in GCNs. A series of experiments show that the optimized networks have reduced computational complexity, decreased memory consumption, and accelerated inference speed while maintaining comparable accuracy for learning on point clouds. Code will be available at \url{https://github.com/ofsoundof/EfficientGCN.git}.
FaceLeaks: Inference Attacks against Transfer Learning Models via Black-box Queries
Oct 27, 2020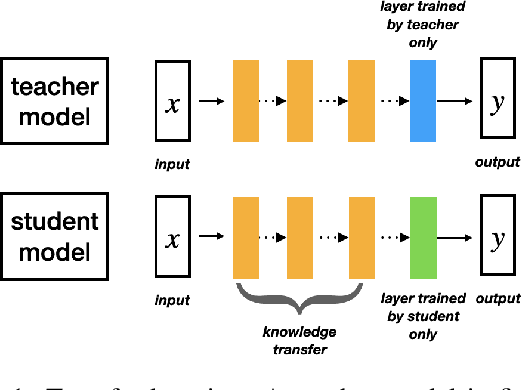
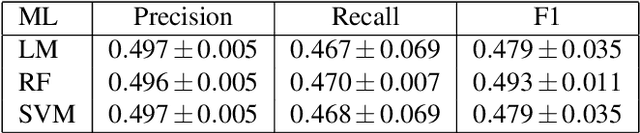
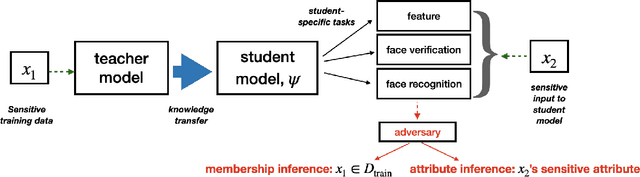
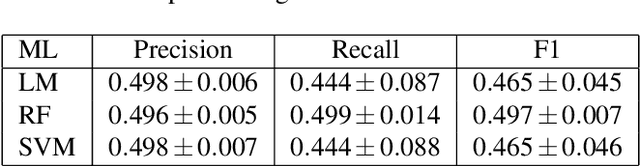
Transfer learning is a useful machine learning framework that allows one to build task-specific models (student models) without significantly incurring training costs using a single powerful model (teacher model) pre-trained with a large amount of data. The teacher model may contain private data, or interact with private inputs. We investigate if one can leak or infer such private information without interacting with the teacher model directly. We describe such inference attacks in the context of face recognition, an application of transfer learning that is highly sensitive to personal privacy. Under black-box and realistic settings, we show that existing inference techniques are ineffective, as interacting with individual training instances through the student models does not reveal information about the teacher. We then propose novel strategies to infer from aggregate-level information. Consequently, membership inference attacks on the teacher model are shown to be possible, even when the adversary has access only to the student models. We further demonstrate that sensitive attributes can be inferred, even in the case where the adversary has limited auxiliary information. Finally, defensive strategies are discussed and evaluated. Our extensive study indicates that information leakage is a real privacy threat to the transfer learning framework widely used in real-life situations.
Gigapixel Histopathological Image Analysis using Attention-based Neural Networks
Jan 25, 2021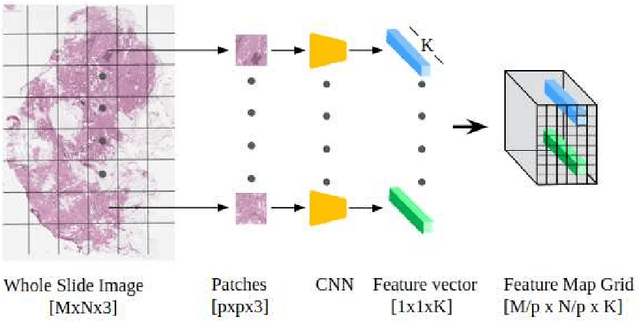
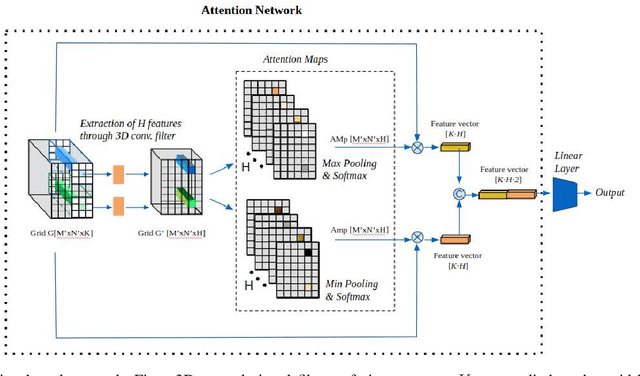
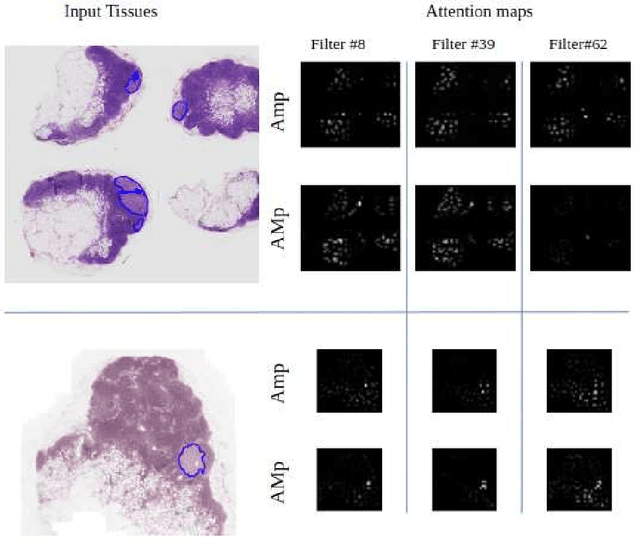
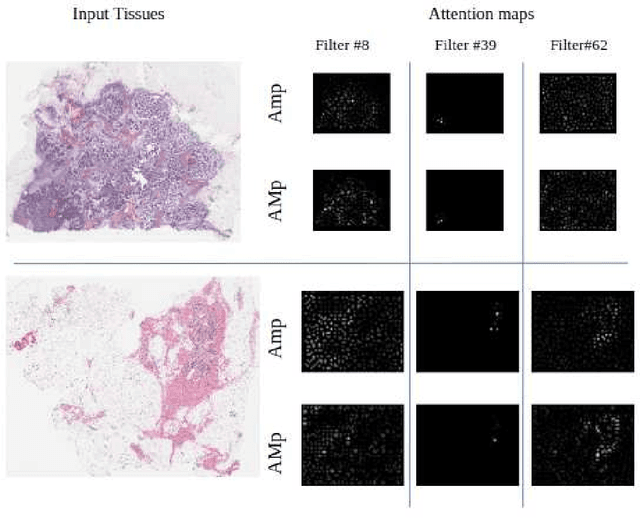
Although CNNs are widely considered as the state-of-the-art models in various applications of image analysis, one of the main challenges still open is the training of a CNN on high resolution images. Different strategies have been proposed involving either a rescaling of the image or an individual processing of parts of the image. Such strategies cannot be applied to images, such as gigapixel histopathological images, for which a high reduction in resolution inherently effects a loss of discriminative information, and in respect of which the analysis of single parts of the image suffers from a lack of global information or implies a high workload in terms of annotating the training images in such a way as to select significant parts. We propose a method for the analysis of gigapixel histopathological images solely by using weak image-level labels. In particular, two analysis tasks are taken into account: a binary classification and a prediction of the tumor proliferation score. Our method is based on a CNN structure consisting of a compressing path and a learning path. In the compressing path, the gigapixel image is packed into a grid-based feature map by using a residual network devoted to the feature extraction of each patch into which the image has been divided. In the learning path, attention modules are applied to the grid-based feature map, taking into account spatial correlations of neighboring patch features to find regions of interest, which are then used for the final whole slide analysis. Our method integrates both global and local information, is flexible with regard to the size of the input images and only requires weak image-level labels. Comparisons with different methods of the state-of-the-art on two well known datasets, Camelyon16 and TUPAC16, have been made to confirm the validity of the proposed model.
An augmentation strategy to mimic multi-scanner variability in MRI
Mar 23, 2021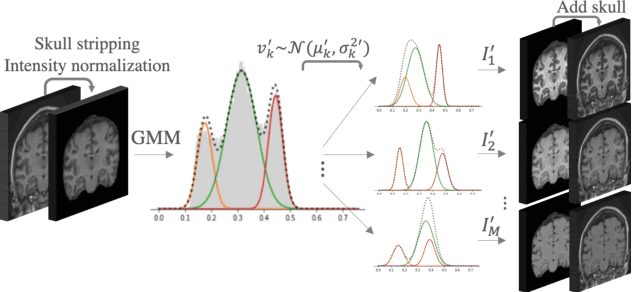
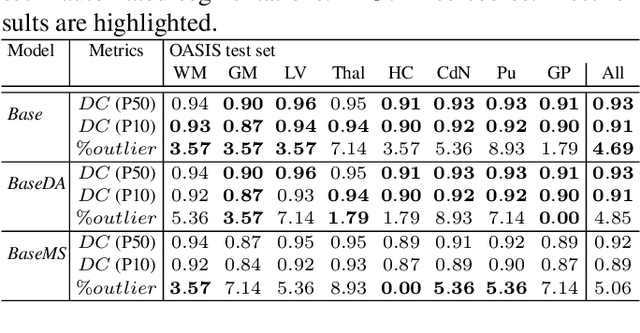
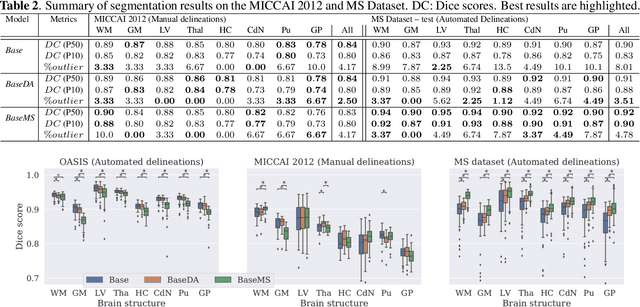
Most publicly available brain MRI datasets are very homogeneous in terms of scanner and protocols, and it is difficult for models that learn from such data to generalize to multi-center and multi-scanner data. We propose a novel data augmentation approach with the aim of approximating the variability in terms of intensities and contrasts present in real world clinical data. We use a Gaussian Mixture Model based approach to change tissue intensities individually, producing new contrasts while preserving anatomical information. We train a deep learning model on a single scanner dataset and evaluate it on a multi-center and multi-scanner dataset. The proposed approach improves the generalization capability of the model to other scanners not present in the training data.
Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning
May 19, 2021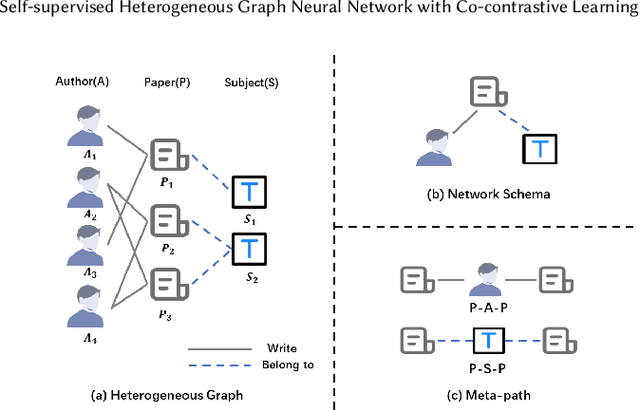
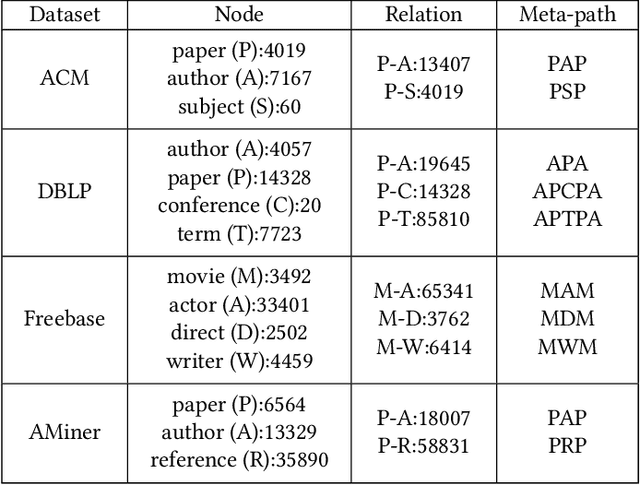
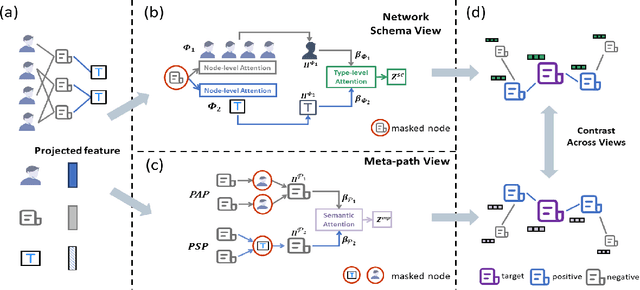
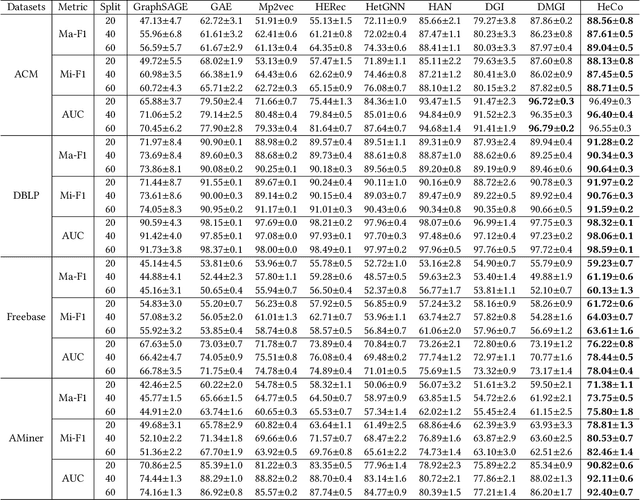
Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-viewcontrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, two extensions of HeCo are designed to generate harder negative samples with high quality, which further boosts the performance of HeCo. Extensive experiments conducted on a variety of real-world networks show the superior performance of the proposed methods over the state-of-the-arts.