 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Robust Beamforming for MISO Downlink Systems
Mar 02, 2021
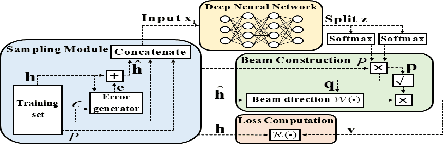
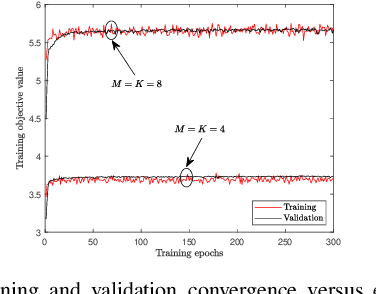
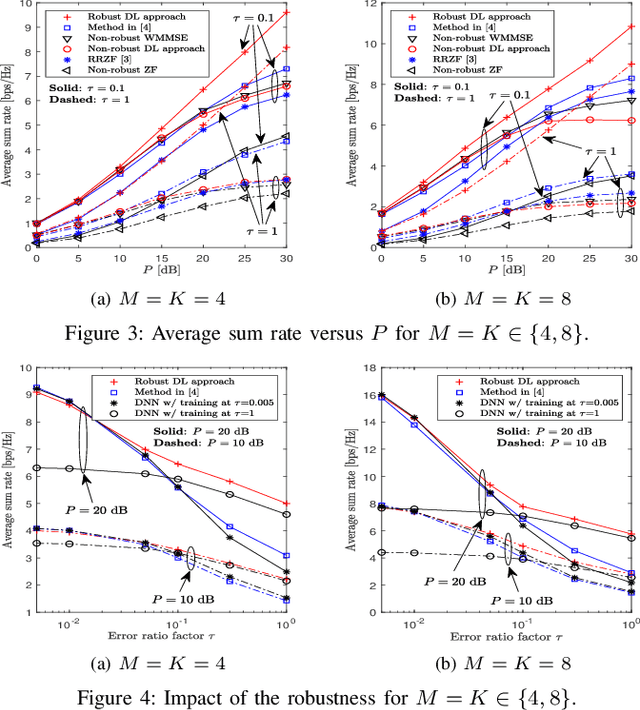
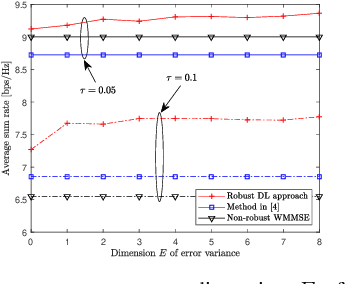
This paper investigates a learning solution for robust beamforming optimization in downlink multi-user systems. A base station (BS) identifies efficient multi-antenna transmission strategies only with imperfect channel state information (CSI) and its stochastic features. To this end, we propose a robust training algorithm where a deep neural network (DNN), which only accepts estimates and statistical knowledge of the perfect CSI, is optimized to fit to real-world propagation environment. Consequently, the trained DNN can provide efficient robust beamforming solutions based only on imperfect observations of the actual CSI. Numerical results validate the advantages of the proposed learning approach compared to conventional schemes.
Unsupervised Multi-Source Domain Adaptation for Person Re-Identification
Apr 27, 2021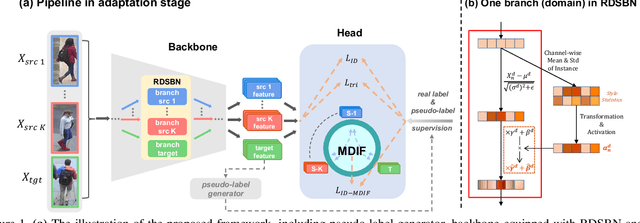

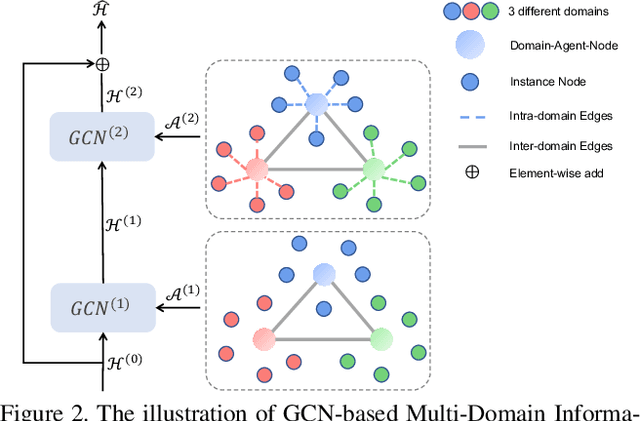
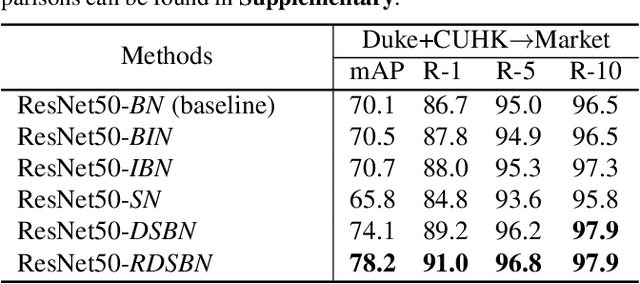
Unsupervised domain adaptation (UDA) methods for person re-identification (re-ID) aim at transferring re-ID knowledge from labeled source data to unlabeled target data. Although achieving great success, most of them only use limited data from a single-source domain for model pre-training, making the rich labeled data insufficiently exploited. To make full use of the valuable labeled data, we introduce the multi-source concept into UDA person re-ID field, where multiple source datasets are used during training. However, because of domain gaps, simply combining different datasets only brings limited improvement. In this paper, we try to address this problem from two perspectives, \ie{} domain-specific view and domain-fusion view. Two constructive modules are proposed, and they are compatible with each other. First, a rectification domain-specific batch normalization (RDSBN) module is explored to simultaneously reduce domain-specific characteristics and increase the distinctiveness of person features. Second, a graph convolutional network (GCN) based multi-domain information fusion (MDIF) module is developed, which minimizes domain distances by fusing features of different domains. The proposed method outperforms state-of-the-art UDA person re-ID methods by a large margin, and even achieves comparable performance to the supervised approaches without any post-processing techniques.
CFPNet-M: A Light-Weight Encoder-Decoder Based Network for Multimodal Biomedical Image Real-Time Segmentation
May 10, 2021
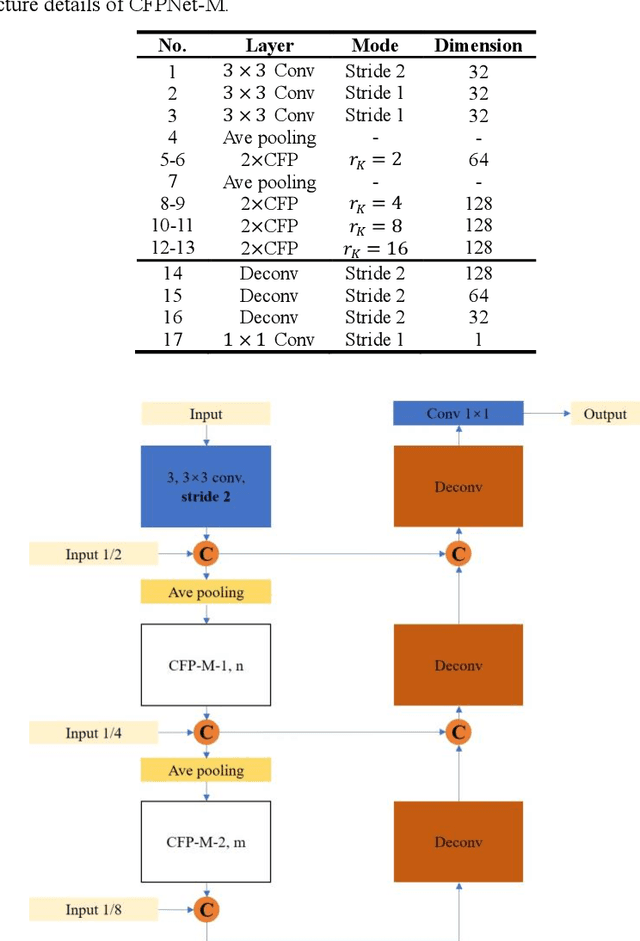
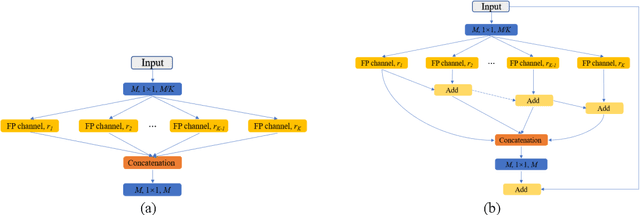

Currently, developments of deep learning techniques are providing instrumental to identify, classify, and quantify patterns in medical images. Segmentation is one of the important applications in medical image analysis. In this regard, U-Net is the predominant approach to medical image segmentation tasks. However, we found that those U-Net based models have limitations in several aspects, for example, millions of parameters in the U-Net consuming considerable computation resource and memory, lack of global information, and missing some tough objects. Therefore, we applied two modifications to improve the U-Net model: 1) designed and added the dilated channel-wise CNN module, 2) simplified the U shape network. Based on these two modifications, we proposed a novel light-weight architecture -- Channel-wise Feature Pyramid Network for Medicine (CFPNet-M). To evaluate our method, we selected five datasets with different modalities: thermography, electron microscopy, endoscopy, dermoscopy, and digital retinal images. And we compared its performance with several models having different parameter scales. This paper also involves our previous studies of DC-UNet and some commonly used light-weight neural networks. We applied the Tanimoto similarity instead of the Jaccard index for gray-level image measurements. By comparison, CFPNet-M achieves comparable segmentation results on all five medical datasets with only 0.65 million parameters, which is about 2% of U-Net, and 8.8 MB memory. Meanwhile, the inference speed can reach 80 FPS on a single RTX 2070Ti GPU with the 256 by 192 pixels input size.
Realtime Mobile Bandwidth and Handoff Predictions in 4G/5G Networks
Apr 27, 2021
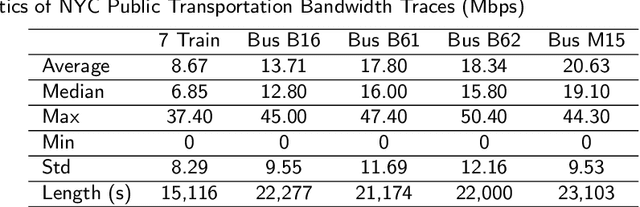
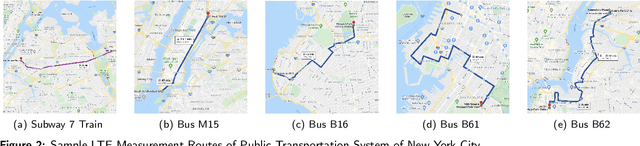

Mobile apps are increasingly relying on high-throughput and low-latency content delivery, while the available bandwidth on wireless access links is inherently time-varying. The handoffs between base stations and access modes due to user mobility present additional challenges to deliver a high level of user Quality-of-Experience (QoE). The ability to predict the available bandwidth and the upcoming handoffs will give applications valuable leeway to make proactive adjustments to avoid significant QoE degradation. In this paper, we explore the possibility and accuracy of realtime mobile bandwidth and handoff predictions in 4G/LTE and 5G networks. Towards this goal, we collect long consecutive traces with rich bandwidth, channel, and context information from public transportation systems. We develop Recurrent Neural Network models to mine the temporal patterns of bandwidth evolution in fixed-route mobility scenarios. Our models consistently outperform the conventional univariate and multivariate bandwidth prediction models. For 4G \& 5G co-existing networks, we propose a new problem of handoff prediction between 4G and 5G, which is important for low-latency applications like self-driving strategy in realistic 5G scenarios. We develop classification and regression based prediction models, which achieve more than 80\% accuracy in predicting 4G and 5G handoffs in a recent 5G dataset.
GAGE: Geometry Preserving Attributed Graph Embeddings
Nov 03, 2020


Node representation learning is the task of extracting concise and informative feature embeddings of certain entities that are connected in a network. Many real world network datasets include information about both node connectivity and certain node attributes, in the form of features or time-series data. Modern representation learning techniques utilize both connectivity and attribute information of the nodes to produce embeddings in an unsupervised manner. In this context, deriving embeddings that preserve the geometry of the network and the attribute vectors would be highly desirable, as they would reflect both the topological neighborhood structure and proximity in feature space. While this is fairly straightforward to maintain when only observing the connectivity or attributed information of the network, preserving the geometry of both types of information is challenging. A novel tensor factorization approach for node embedding in attributed networks that preserves the distances of both the connections and the attributes is proposed in this paper, along with an effective and lightweight algorithm to tackle the learning task. Judicious experiments with multiple state-of-art baselines suggest that the proposed algorithm offers significant performance improvements in node classification and link prediction tasks.
Focal points and their implications for Möbius Transforms and Dempster-Shafer Theory
Dec 05, 2020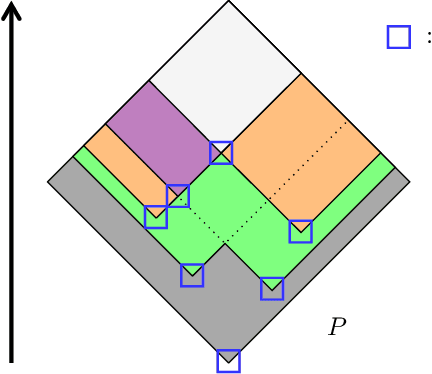
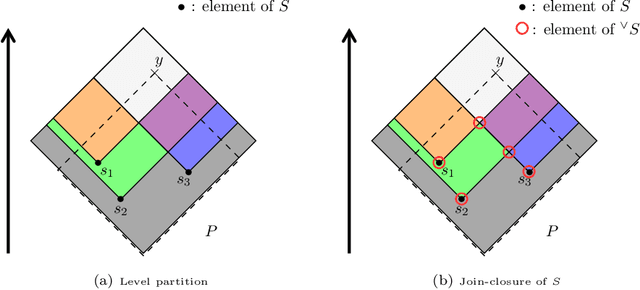
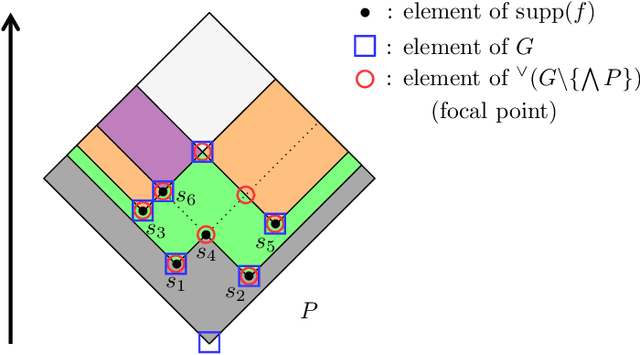
Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a much higher computational burden. A lot of work has been done to reduce the time complexity of information fusion with Dempster's rule, which is a pointwise multiplication of two zeta transforms, and optimal general algorithms have been found to get the complete definition of these transforms. Yet, it is shown in this paper that the zeta transform and its inverse, the M\"obius transform, can be exactly simplified, fitting the quantity of information contained in belief functions. Beyond that, this simplification actually works for any function on any partially ordered set. It relies on a new notion that we call focal point and that constitutes the smallest domain on which both the zeta and M\"obius transforms can be defined. We demonstrate the interest of these general results for DST, not only for the reduction in complexity of most transformations between belief representations and their fusion, but also for theoretical purposes. Indeed, we provide a new generalization of the conjunctive decomposition of evidence and formulas uncovering how each decomposition weight is tied to the corresponding mass function.
Topological Regularization for Graph Neural Networks Augmentation
Apr 03, 2021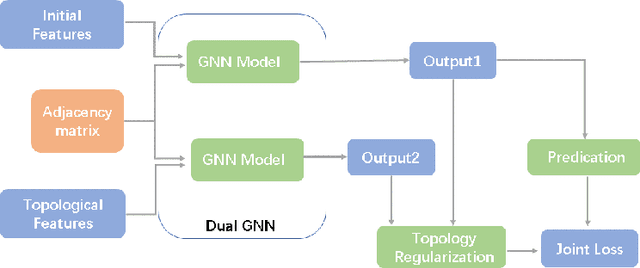
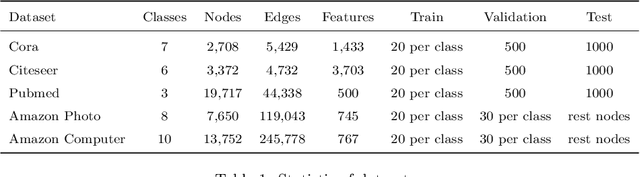
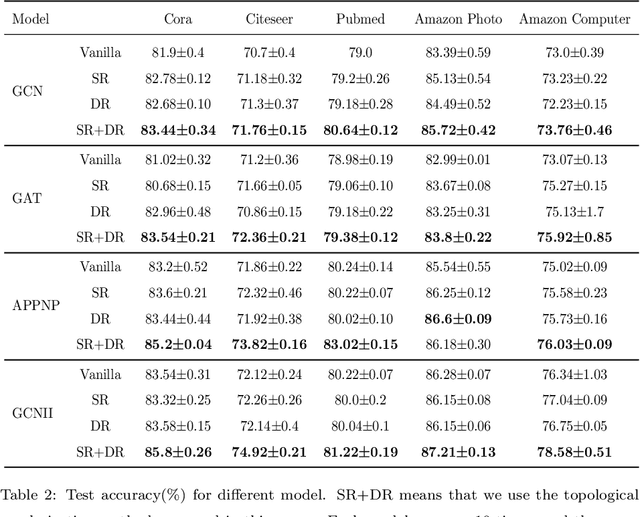
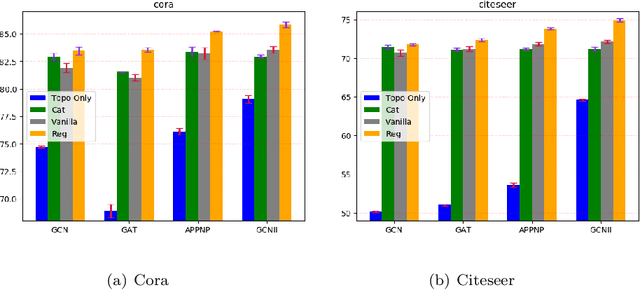
The complexity and non-Euclidean structure of graph data hinder the development of data augmentation methods similar to those in computer vision. In this paper, we propose a feature augmentation method for graph nodes based on topological regularization, in which topological structure information is introduced into end-to-end model. Specifically, we first obtain topology embedding of nodes through unsupervised representation learning method based on random walk. Then, the topological embedding as additional features and the original node features are input into a dual graph neural network for propagation, and two different high-order neighborhood representations of nodes are obtained. On this basis, we propose a regularization technique to bridge the differences between the two different node representations, eliminate the adverse effects caused by the topological features of graphs directly used, and greatly improve the performance. We have carried out extensive experiments on a large number of datasets to prove the effectiveness of our model.
The Time-SIFT method : detecting 3-D changes from archival photogrammetric analysis with almost exclusively image information
Jul 25, 2018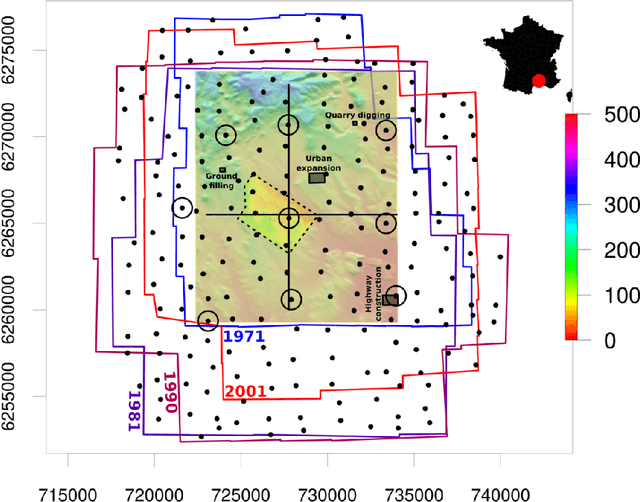
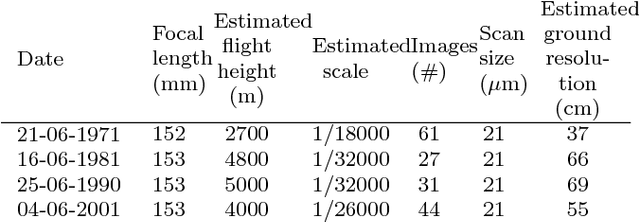
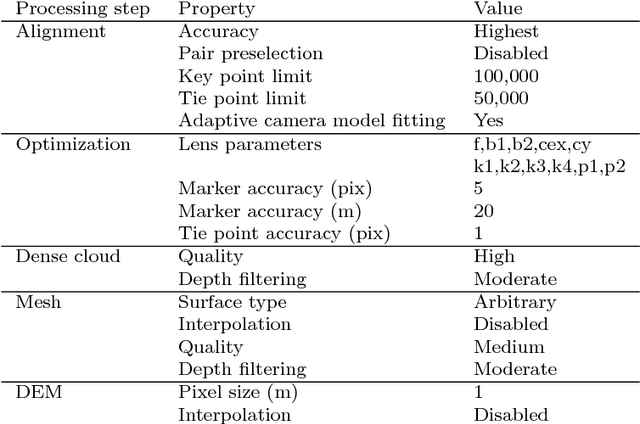
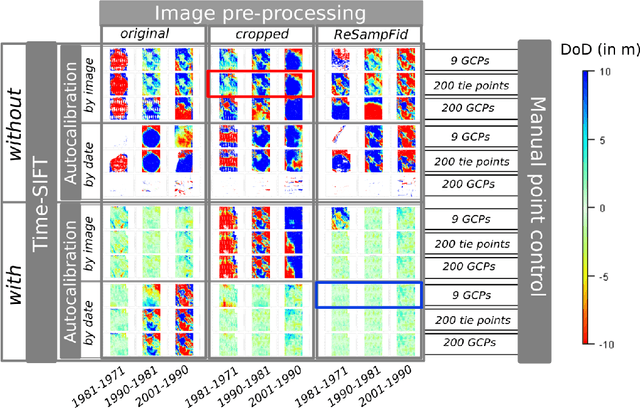
Archival aerial imagery is a source of worldwide very high resolution data for documenting paste 3-D changes. However, external information is required so that accurate 3-D models can be computed from archival aerial imagery. In this research, we propose and test a new method, termed Time-SIFT (Scale Invariant Feature Transform), which allows for computing coherent multi-temporal Digital Elevation Models (DEMs) with almost exclusively image information. This method is based on the invariance properties of the SIFT-like methods which are at the root of the Structure from Motion (SfM) algorithms. On a test site of 170 km2, we applied SfM algorithms to a unique image block with all the images of four different dates covering forty years. We compared this method to more classical methods based on the use of affordable additional data such as ground control points collected in recent orthophotos. We did extensive tests to determine which processing choices were most impacting on the final result. With these tests, we aimed at evaluating the potential of the proposed Time-SIFT method for the detection and mapping of 3-D changes. Our study showed that the Time-SIFT method was the prime criteria that allowed for computing informative DEMs of difference with almost exclusively image information and limited photogrammetric expertise and human intervention. Due to the fact that the proposed Time-SIFT method can be automatically applied with exclusively image information, our results pave the way to a systematic processing of the archival aerial imagery on very large spatio-temporal windows, and should hence greatly help the unlocking of archival aerial imagery for the documenting of past 3-D changes.
Semantic Grouping Network for Video Captioning
Feb 01, 2021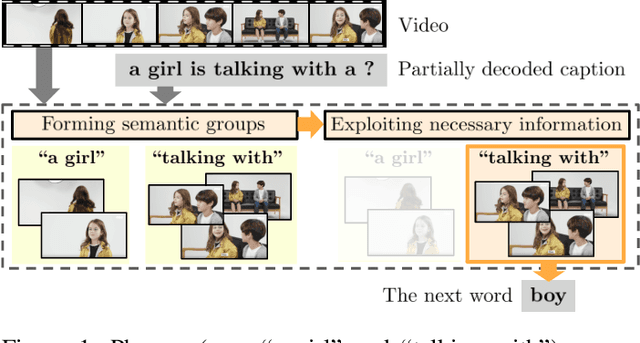
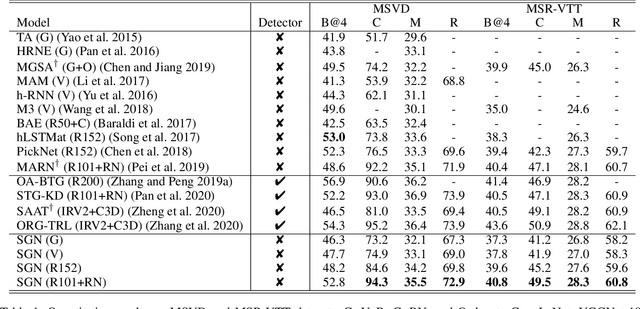

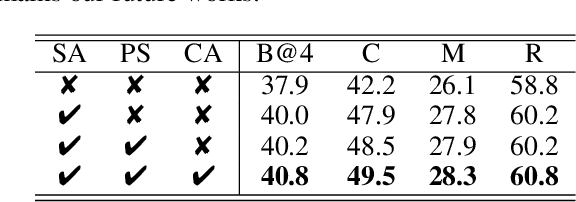
This paper considers a video caption generating network referred to as Semantic Grouping Network (SGN) that attempts (1) to group video frames with discriminating word phrases of partially decoded caption and then (2) to decode those semantically aligned groups in predicting the next word. As consecutive frames are not likely to provide unique information, prior methods have focused on discarding or merging repetitive information based only on the input video. The SGN learns an algorithm to capture the most discriminating word phrases of the partially decoded caption and a mapping that associates each phrase to the relevant video frames - establishing this mapping allows semantically related frames to be clustered, which reduces redundancy. In contrast to the prior methods, the continuous feedback from decoded words enables the SGN to dynamically update the video representation that adapts to the partially decoded caption. Furthermore, a contrastive attention loss is proposed to facilitate accurate alignment between a word phrase and video frames without manual annotations. The SGN achieves state-of-the-art performances by outperforming runner-up methods by a margin of 2.1%p and 2.4%p in a CIDEr-D score on MSVD and MSR-VTT datasets, respectively. Extensive experiments demonstrate the effectiveness and interpretability of the SGN.
Text analysis in financial disclosures
Jan 06, 2021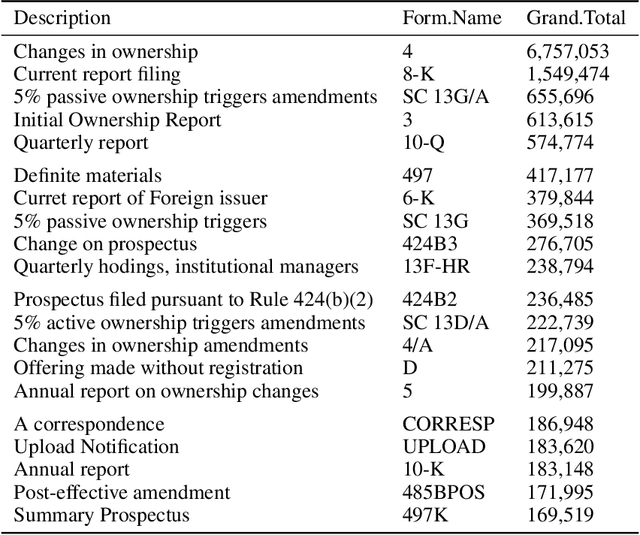
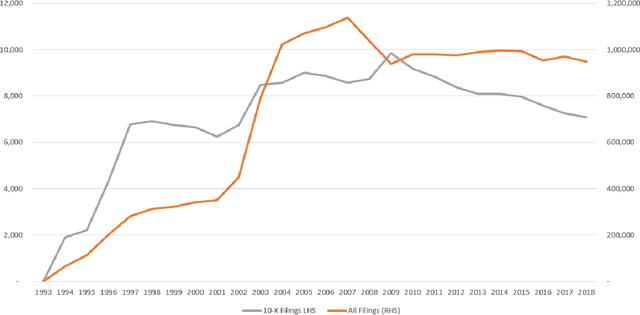
Financial disclosure analysis and Knowledge extraction is an important financial analysis problem. Prevailing methods depend predominantly on quantitative ratios and techniques, which suffer from limitations like window dressing and past focus. Most of the information in a firm's financial disclosures is in unstructured text and contains valuable information about its health. Humans and machines fail to analyze it satisfactorily due to the enormous volume and unstructured nature, respectively. Researchers have started analyzing text content in disclosures recently. This paper covers the previous work in unstructured data analysis in Finance and Accounting. It also explores the state of art methods in computational linguistics and reviews the current methodologies in Natural Language Processing (NLP). Specifically, it focuses on research related to text source, linguistic attributes, firm attributes, and mathematical models employed in the text analysis approach. This work contributes to disclosure analysis methods by highlighting the limitations of the current focus on sentiment metrics and highlighting broader future research areas