 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SBNet: Segmentation-based Network for Natural Language-based Vehicle Search
Apr 22, 2021


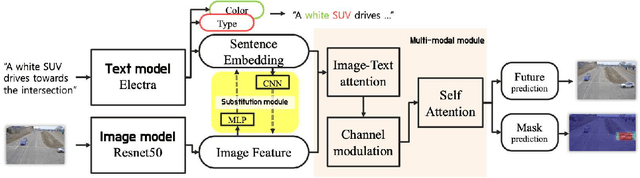
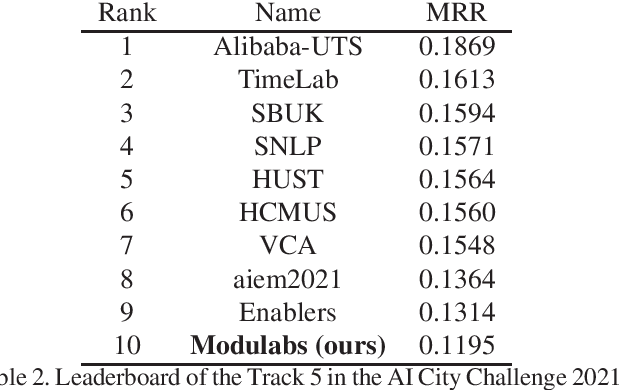
Natural language-based vehicle retrieval is a task to find a target vehicle within a given image based on a natural language description as a query. This technology can be applied to various areas including police searching for a suspect vehicle. However, it is challenging due to the ambiguity of language descriptions and the difficulty of processing multi-modal data. To tackle this problem, we propose a deep neural network called SBNet that performs natural language-based segmentation for vehicle retrieval. We also propose two task-specific modules to improve performance: a substitution module that helps features from different domains to be embedded in the same space and a future prediction module that learns temporal information. SBnet has been trained using the CityFlow-NL dataset that contains 2,498 tracks of vehicles with three unique natural language descriptions each and tested 530 unique vehicle tracks and their corresponding query sets. SBNet achieved a significant improvement over the baseline in the natural language-based vehicle tracking track in the AI City Challenge 2021.
On the Impact of Knowledge-based Linguistic Annotations in the Quality of Scientific Embeddings
Apr 13, 2021
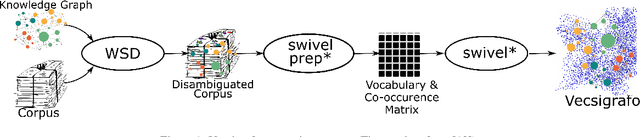
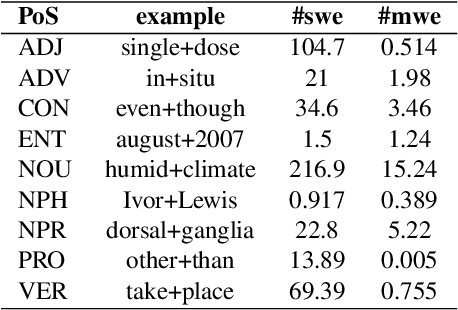
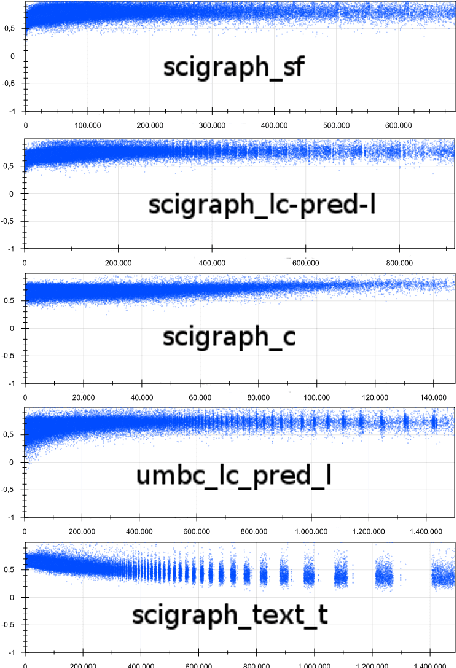
In essence, embedding algorithms work by optimizing the distance between a word and its usual context in order to generate an embedding space that encodes the distributional representation of words. In addition to single words or word pieces, other features which result from the linguistic analysis of text, including lexical, grammatical and semantic information, can be used to improve the quality of embedding spaces. However, until now we did not have a precise understanding of the impact that such individual annotations and their possible combinations may have in the quality of the embeddings. In this paper, we conduct a comprehensive study on the use of explicit linguistic annotations to generate embeddings from a scientific corpus and quantify their impact in the resulting representations. Our results show how the effect of such annotations in the embeddings varies depending on the evaluation task. In general, we observe that learning embeddings using linguistic annotations contributes to achieve better evaluation results.
Zero-Shot Text-to-Image Generation
Feb 24, 2021
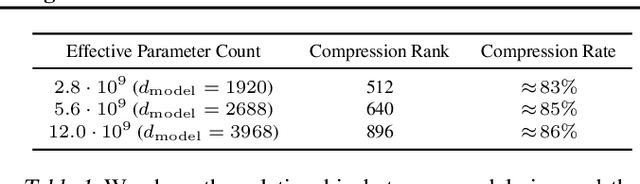


Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.
An Extension of BIM Using AI: a Multi Working-Machines Pathfinding Solution
May 14, 2021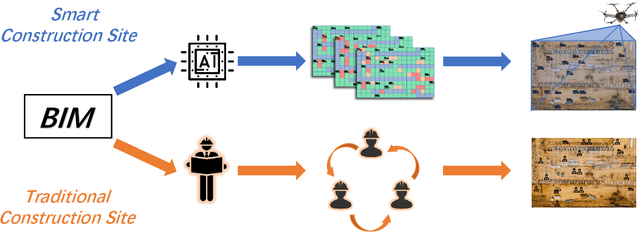
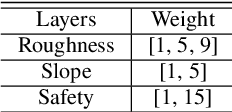
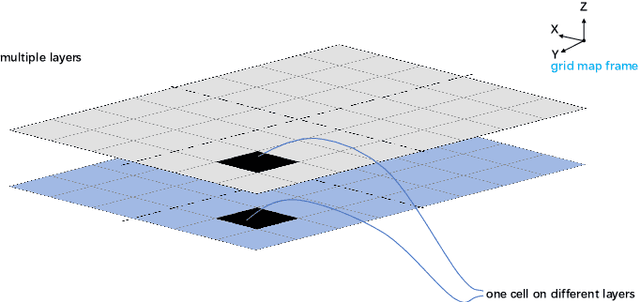
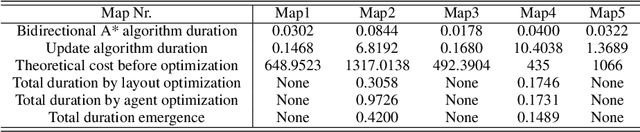
Multi working-machines pathfinding solution enables more mobile machines simultaneously to work inside of a working site so that the productivity can be expected to increase evolutionary. To date, the potential cooperation conflicts among construction machinery limit the amount of construction machinery investment in a concrete working site. To solve the cooperation problem, civil engineers optimize the working site from a logistic perspective while computer scientists improve pathfinding algorithms' performance on the given benchmark maps. In the practical implementation of a construction site, it is sensible to solve the problem with a hybrid solution; therefore, in our study, we proposed an algorithm based on a cutting-edge multi-pathfinding algorithm to enable the massive number of machines cooperation and offer the advice to modify the unreasonable part of the working site in the meantime. Using the logistic information from BIM, such as unloading and loading point, we added a pathfinding solution for multi machines to improve the whole construction fleet's productivity. In the previous study, the experiments were limited to no more than ten participants, and the computational time to gather the solution was not given; thus, we publish our pseudo-code, our tested map, and benchmark our results. Our algorithm's most extensive feature is that it can quickly replan the path to overcome the emergency on a construction site.
See, Hear, Read: Leveraging Multimodality with Guided Attention for Abstractive Text Summarization
May 20, 2021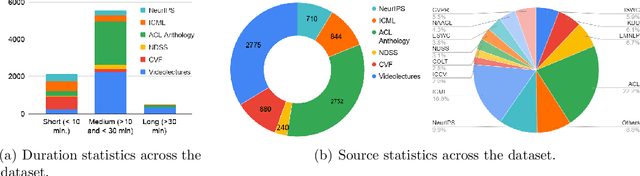
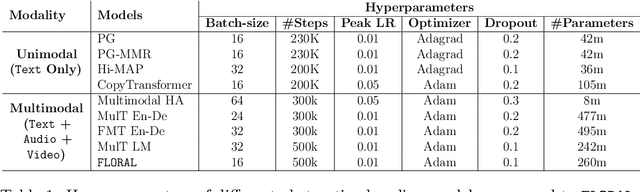
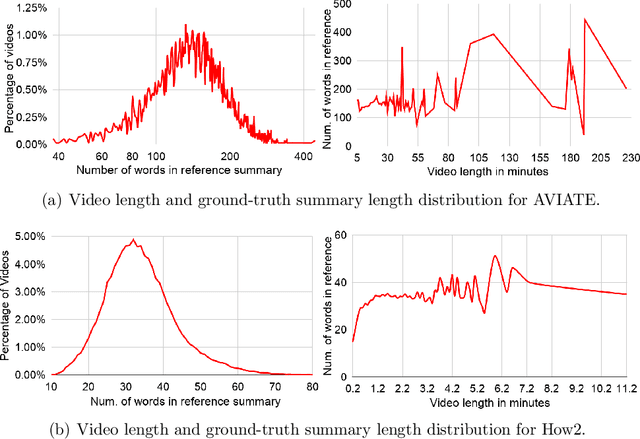
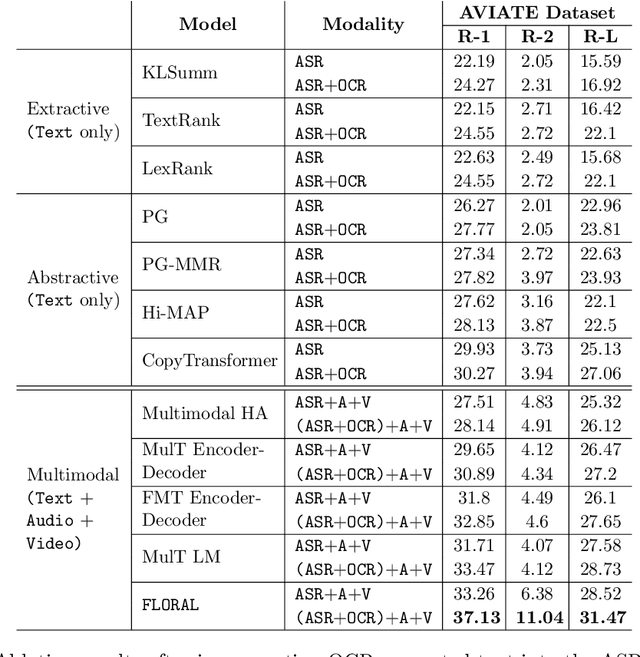
In recent years, abstractive text summarization with multimodal inputs has started drawing attention due to its ability to accumulate information from different source modalities and generate a fluent textual summary. However, existing methods use short videos as the visual modality and short summary as the ground-truth, therefore, perform poorly on lengthy videos and long ground-truth summary. Additionally, there exists no benchmark dataset to generalize this task on videos of varying lengths. In this paper, we introduce AVIATE, the first large-scale dataset for abstractive text summarization with videos of diverse duration, compiled from presentations in well-known academic conferences like NDSS, ICML, NeurIPS, etc. We use the abstract of corresponding research papers as the reference summaries, which ensure adequate quality and uniformity of the ground-truth. We then propose {\name}, a factorized multi-modal Transformer based decoder-only language model, which inherently captures the intra-modal and inter-modal dynamics within various input modalities for the text summarization task. {\name} utilizes an increasing number of self-attentions to capture multimodality and performs significantly better than traditional encoder-decoder based networks. Extensive experiments illustrate that {\name} achieves significant improvement over the baselines in both qualitative and quantitative evaluations on the existing How2 dataset for short videos and newly introduced AVIATE dataset for videos with diverse duration, beating the best baseline on the two datasets by $1.39$ and $2.74$ ROUGE-L points respectively.
Demographic Aware Probabilistic Medical Knowledge Graph Embeddings of Electronic Medical Records
Apr 03, 2021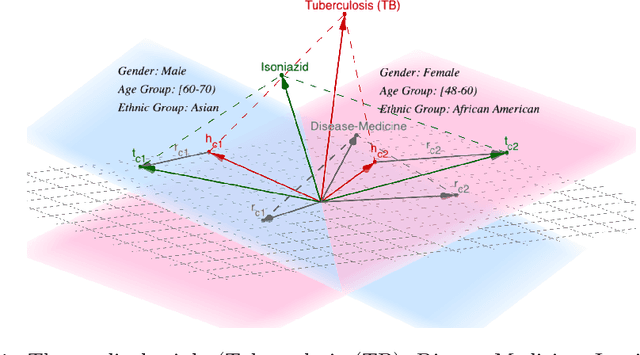
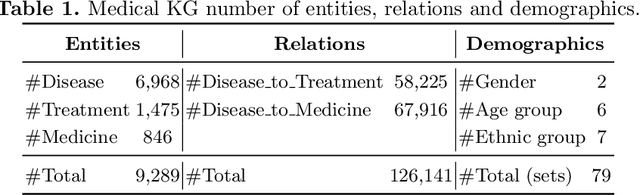
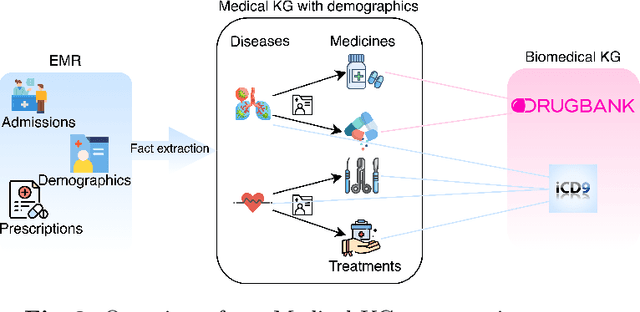
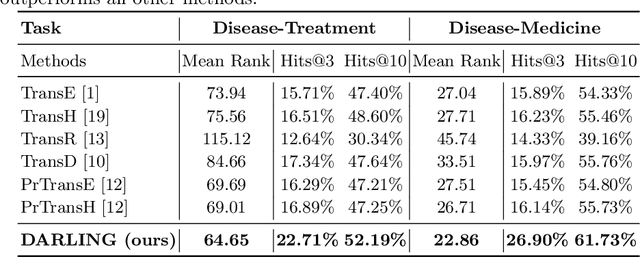
Medical knowledge graphs (KGs) constructed from Electronic Medical Records (EMR) contain abundant information about patients and medical entities. The utilization of KG embedding models on these data has proven to be efficient for different medical tasks. However, existing models do not properly incorporate patient demographics and most of them ignore the probabilistic features of the medical KG. In this paper, we propose DARLING (Demographic Aware pRobabiListic medIcal kNowledge embeddinG), a demographic-aware medical KG embedding framework that explicitly incorporates demographics in the medical entities space by associating patient demographics with a corresponding hyperplane. Our framework leverages the probabilistic features within the medical entities for learning their representations through demographic guidance. We evaluate DARLING through link prediction for treatments and medicines, on a medical KG constructed from EMR data, and illustrate its superior performance compared to existing KG embedding models.
Attribute-Modulated Generative Meta Learning for Zero-Shot Classification
Apr 22, 2021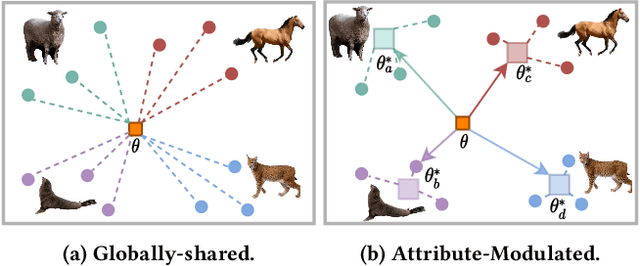

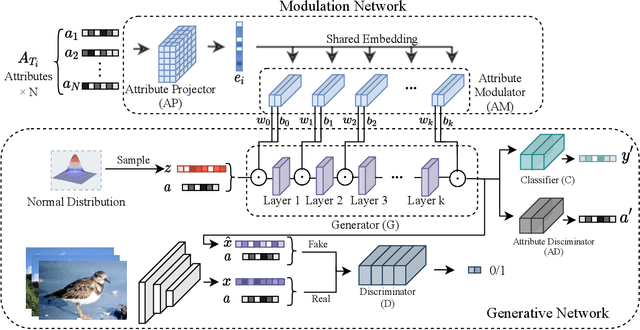
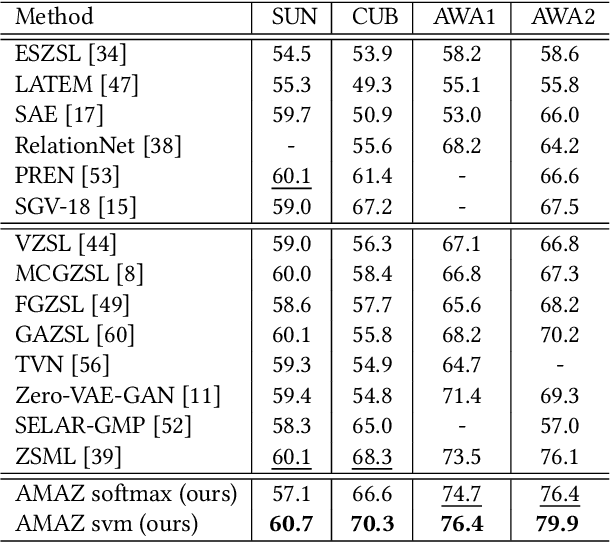
Zero-shot learning (ZSL) aims to transfer knowledge from seen classes to semantically related unseen classes, which are absent during training. The promising strategies for ZSL are to synthesize visual features of unseen classes conditioned on semantic side information and to incorporate meta-learning to eliminate the model's inherent bias towards seen classes. Existing meta generative approaches pursue a common model shared across task distributions; in contrast, we aim to construct a generative network adaptive to task characteristics. To this end, we propose the Attribute-Modulated generAtive meta-model for Zero-shot learning (AMAZ). Our model consists of an attribute-aware modulation network and an attribute-augmented generative network. Given unseen classes, the modulation network adaptively modulates the generator by applying task-specific transformations so that the generative network can adapt to highly diverse tasks. Our empirical evaluations on four widely-used benchmarks show that AMAZ improves state-of-the-art methods by 3.8% and 5.1% in ZSL and generalized ZSL settings, respectively, demonstrating the superiority of our method.
Building Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021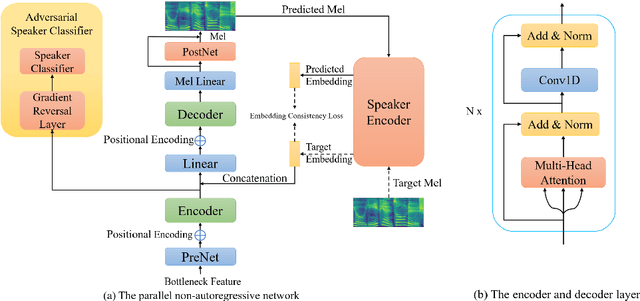

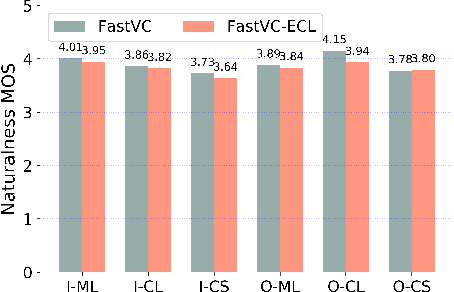
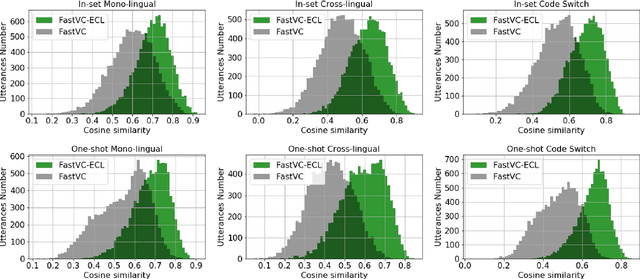
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.
LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
Apr 22, 2021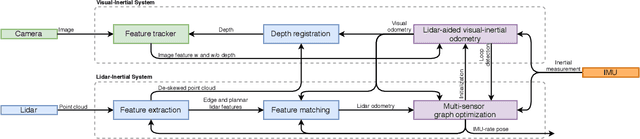
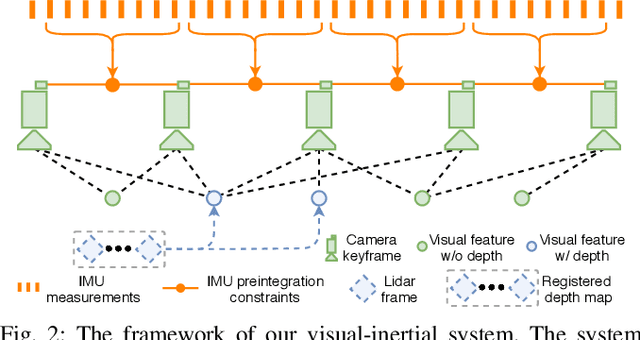
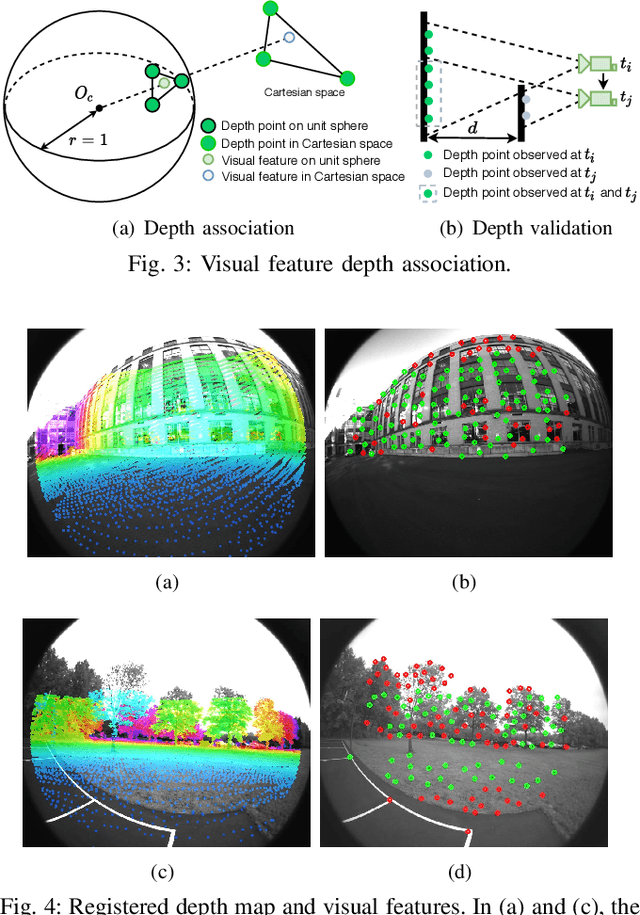
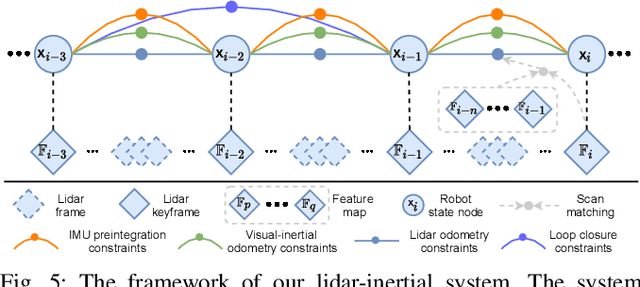
We propose a framework for tightly-coupled lidar-visual-inertial odometry via smoothing and mapping, LVI-SAM, that achieves real-time state estimation and map-building with high accuracy and robustness. LVI-SAM is built atop a factor graph and is composed of two sub-systems: a visual-inertial system (VIS) and a lidar-inertial system (LIS). The two sub-systems are designed in a tightly-coupled manner, in which the VIS leverages LIS estimation to facilitate initialization. The accuracy of the VIS is improved by extracting depth information for visual features using lidar measurements. In turn, the LIS utilizes VIS estimation for initial guesses to support scan-matching. Loop closures are first identified by the VIS and further refined by the LIS. LVI-SAM can also function when one of the two sub-systems fails, which increases its robustness in both texture-less and feature-less environments. LVI-SAM is extensively evaluated on datasets gathered from several platforms over a variety of scales and environments. Our implementation is available at https://git.io/lvi-sam
First and Second Order Dynamics in a Hierarchical SOM system for Action Recognition
Apr 13, 2021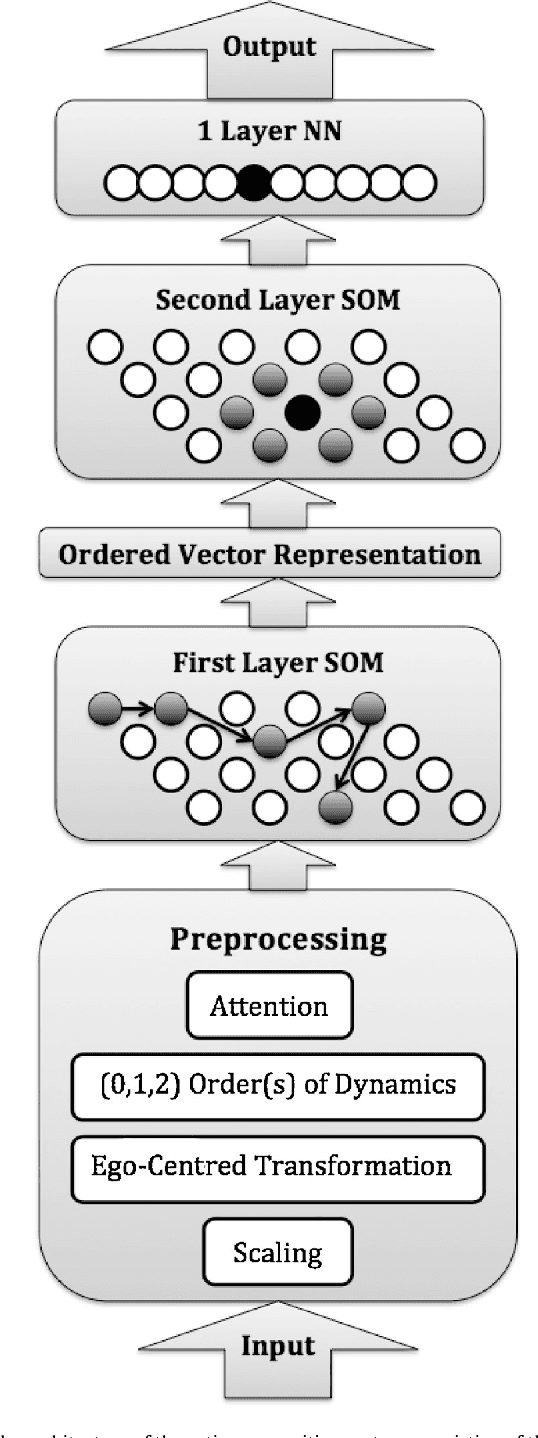
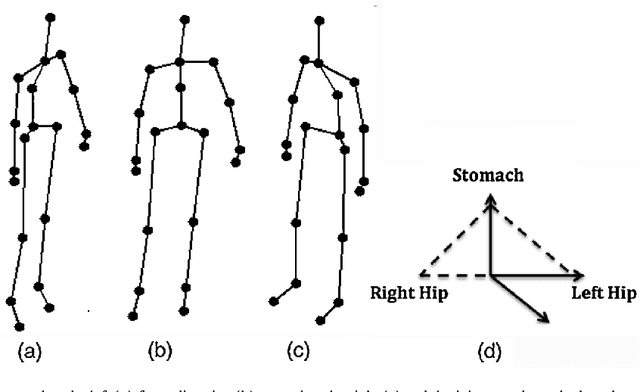
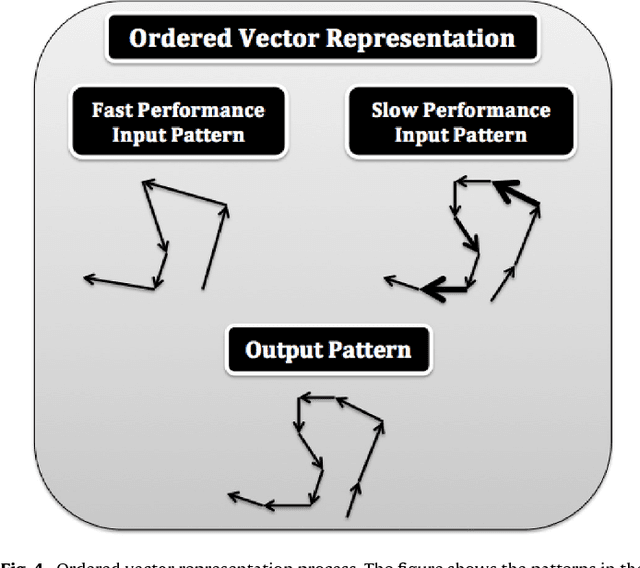
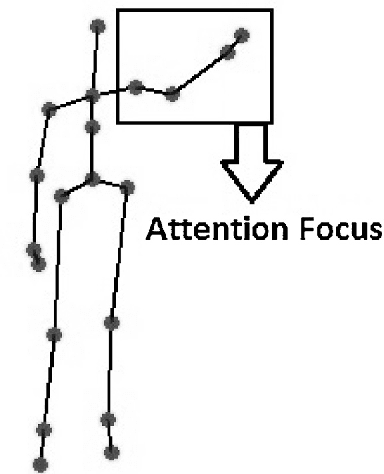
Human recognition of the actions of other humans is very efficient and is based on patterns of movements. Our theoretical starting point is that the dynamics of the joint movements is important to action categorization. On the basis of this theory, we present a novel action recognition system that employs a hierarchy of Self-Organizing Maps together with a custom supervised neural network that learns to categorize actions. The system preprocesses the input from a Kinect like 3D camera to exploit the information not only about joint positions, but also their first and second order dynamics. We evaluate our system in two experiments with publicly available data sets, and compare its performance to the performance with less sophisticated preprocessing of the input. The results show that including the dynamics of the actions improves the performance. We also apply an attention mechanism that focuses on the parts of the body that are the most involved in performing the actions.