 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Latent Correlation Representation Learning for Brain Tumor Segmentation with Missing MRI Modalities
Apr 20, 2021
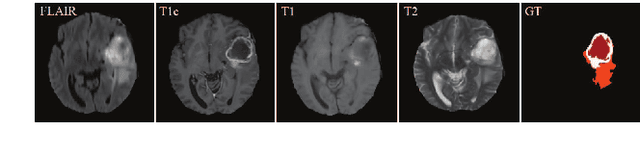
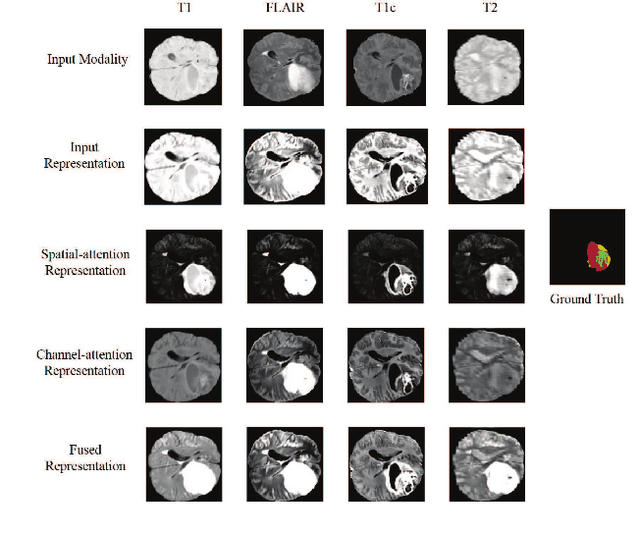
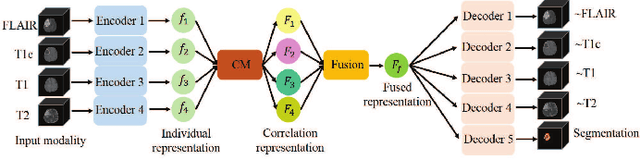
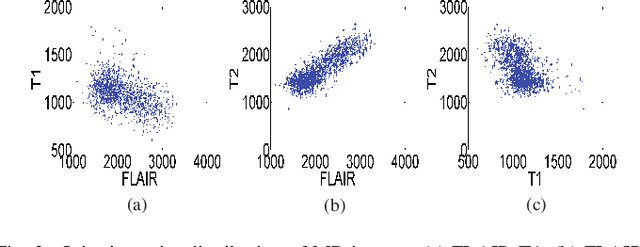
Magnetic Resonance Imaging (MRI) is a widely used imaging technique to assess brain tumor. Accurately segmenting brain tumor from MR images is the key to clinical diagnostics and treatment planning. In addition, multi-modal MR images can provide complementary information for accurate brain tumor segmentation. However, it's common to miss some imaging modalities in clinical practice. In this paper, we present a novel brain tumor segmentation algorithm with missing modalities. Since it exists a strong correlation between multi-modalities, a correlation model is proposed to specially represent the latent multi-source correlation. Thanks to the obtained correlation representation, the segmentation becomes more robust in the case of missing modality. First, the individual representation produced by each encoder is used to estimate the modality independent parameter. Then, the correlation model transforms all the individual representations to the latent multi-source correlation representations. Finally, the correlation representations across modalities are fused via attention mechanism into a shared representation to emphasize the most important features for segmentation. We evaluate our model on BraTS 2018 and BraTS 2019 dataset, it outperforms the current state-of-the-art methods and produces robust results when one or more modalities are missing.
* 12 pages, 10 figures, accepted by IEEE Transactions on Image Processing (8 April 2021). arXiv admin note: text overlap with arXiv:2003.08870, arXiv:2102.03111
Active Reinforcement Learning: Observing Rewards at a Cost
Nov 24, 2020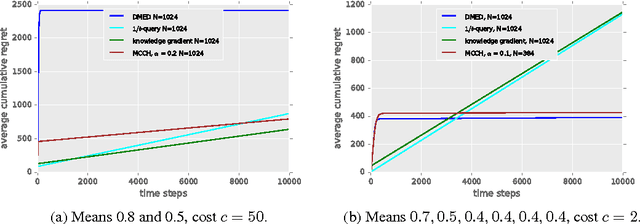
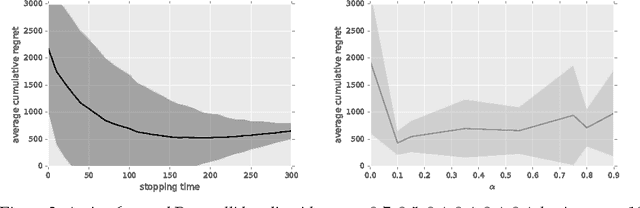
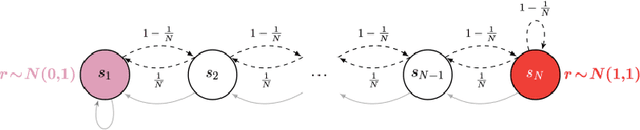
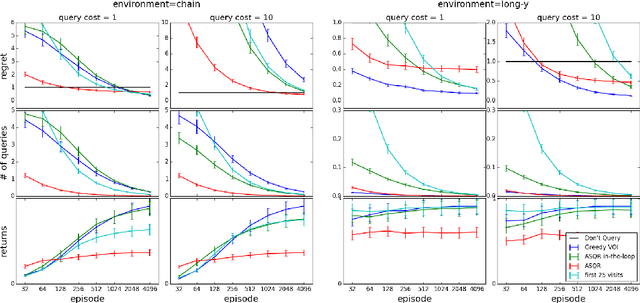
Active reinforcement learning (ARL) is a variant on reinforcement learning where the agent does not observe the reward unless it chooses to pay a query cost c > 0. The central question of ARL is how to quantify the long-term value of reward information. Even in multi-armed bandits, computing the value of this information is intractable and we have to rely on heuristics. We propose and evaluate several heuristic approaches for ARL in multi-armed bandits and (tabular) Markov decision processes, and discuss and illustrate some challenging aspects of the ARL problem.
FIXME: Enhance Software Reliability with Hybrid Approaches in Cloud
Feb 17, 2021
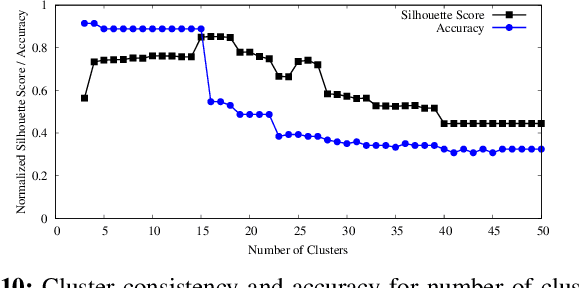

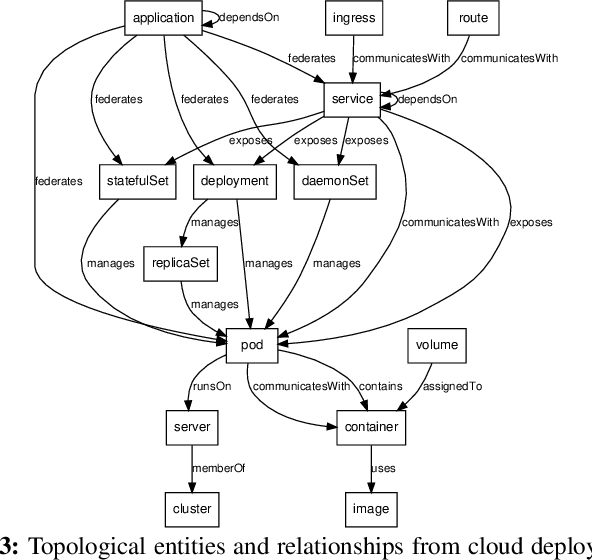
With the promise of reliability in cloud, more enterprises are migrating to cloud. The process of continuous integration/deployment (CICD) in cloud connects developers who need to deliver value faster and more transparently with site reliability engineers (SREs) who need to manage applications reliably. SREs feed back development issues to developers, and developers commit fixes and trigger CICD to redeploy. The release cycle is more continuous than ever, thus the code to production is faster and more automated. To provide this higher level agility, the cloud platforms become more complex in the face of flexibility with deeper layers of virtualization. However, reliability does not come for free with all these complexities. Software engineers and SREs need to deal with wider information spectrum from virtualized layers. Therefore, providing correlated information with true positive evidences is critical to identify the root cause of issues quickly in order to reduce mean time to recover (MTTR), performance metrics for SREs. Similarity, knowledge, or statistics driven approaches have been effective, but with increasing data volume and types, an individual approach is limited to correlate semantic relations of different data sources. In this paper, we introduce FIXME to enhance software reliability with hybrid diagnosis approaches for enterprises. Our evaluation results show using hybrid diagnosis approach is about 17% better in precision. The results are helpful for both practitioners and researchers to develop hybrid diagnosis in the highly dynamic cloud environment.
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020
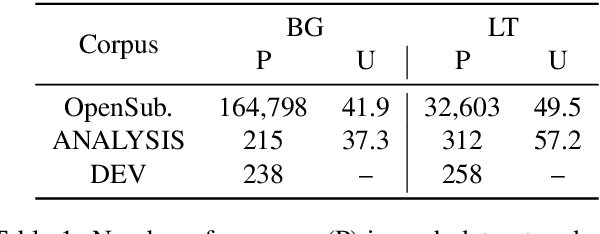
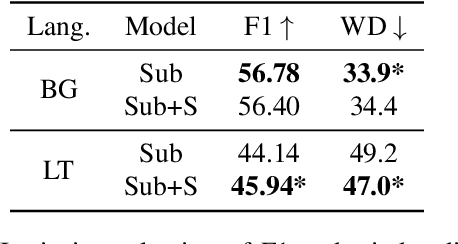

In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Distill on the Go: Online knowledge distillation in self-supervised learning
Apr 20, 2021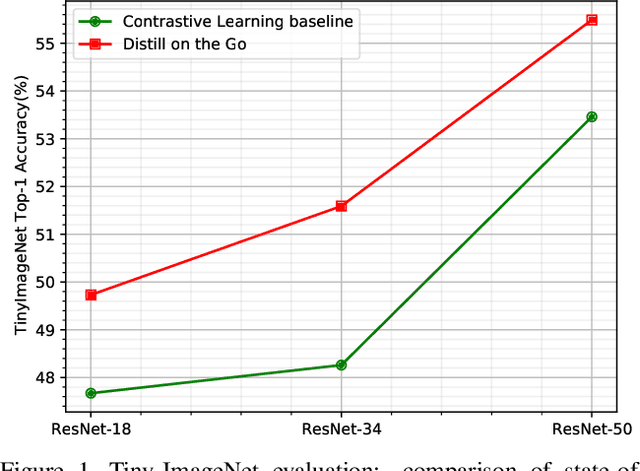
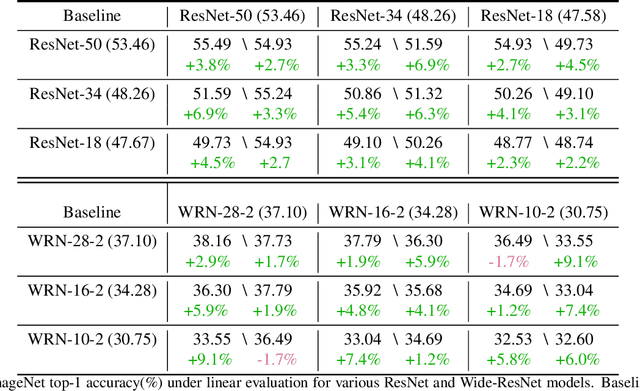
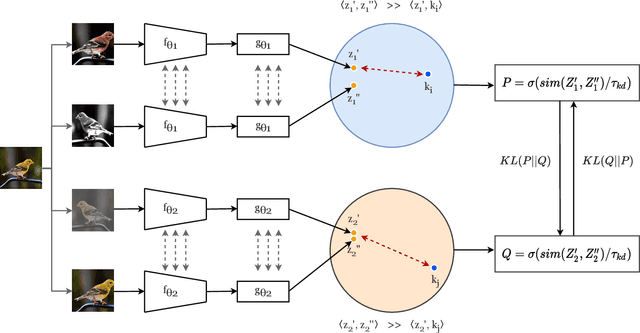
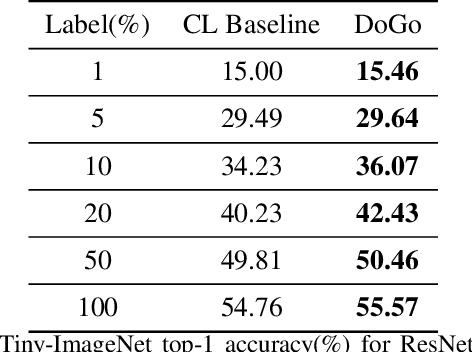
Self-supervised learning solves pretext prediction tasks that do not require annotations to learn feature representations. For vision tasks, pretext tasks such as predicting rotation, solving jigsaw are solely created from the input data. Yet, predicting this known information helps in learning representations useful for downstream tasks. However, recent works have shown that wider and deeper models benefit more from self-supervised learning than smaller models. To address the issue of self-supervised pre-training of smaller models, we propose Distill-on-the-Go (DoGo), a self-supervised learning paradigm using single-stage online knowledge distillation to improve the representation quality of the smaller models. We employ deep mutual learning strategy in which two models collaboratively learn from each other to improve one another. Specifically, each model is trained using self-supervised learning along with distillation that aligns each model's softmax probabilities of similarity scores with that of the peer model. We conduct extensive experiments on multiple benchmark datasets, learning objectives, and architectures to demonstrate the potential of our proposed method. Our results show significant performance gain in the presence of noisy and limited labels and generalization to out-of-distribution data.
BeamLearning: an end-to-end Deep Learning approach for the angular localization of sound sources using raw multichannel acoustic pressure data
Apr 27, 2021Sound sources localization using multichannel signal processing has been a subject of active research for decades. In recent years, the use of deep learning in audio signal processing has allowed to drastically improve performances for machine hearing. This has motivated the scientific community to also develop machine learning strategies for source localization applications. In this paper, we present BeamLearning, a multi-resolution deep learning approach that allows to encode relevant information contained in unprocessed time domain acoustic signals captured by microphone arrays. The use of raw data aims at avoiding simplifying hypothesis that most traditional model-based localization methods rely on. Benefits of its use are shown for realtime sound source 2D-localization tasks in reverberating and noisy environments. Since supervised machine learning approaches require large-sized, physically realistic, precisely labelled datasets, we also developed a fast GPU-based computation of room impulse responses using fractional delays for image source models. A thorough analysis of the network representation and extensive performance tests are carried out using the BeamLearning network with synthetic and experimental datasets. Obtained results demonstrate that the BeamLearning approach significantly outperforms the wideband MUSIC and SRP-PHAT methods in terms of localization accuracy and computational efficiency in presence of heavy measurement noise and reverberation.
The Time-SIFT method : detecting 3-D changes from archival photogrammetric analysis with almost exclusively image information
Jul 25, 2018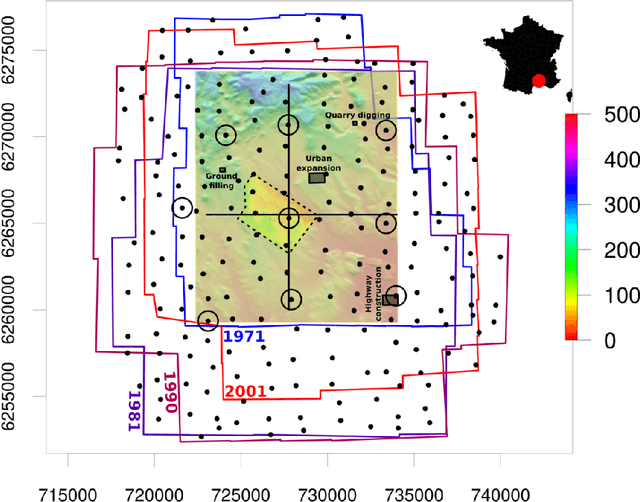
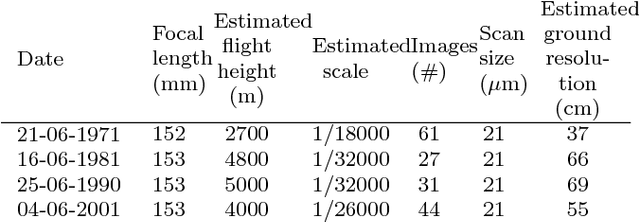
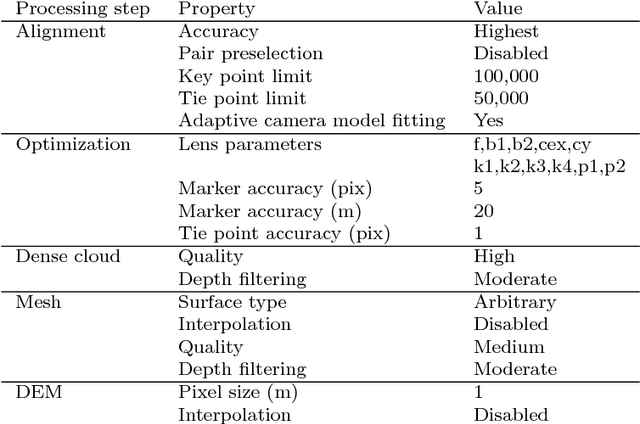
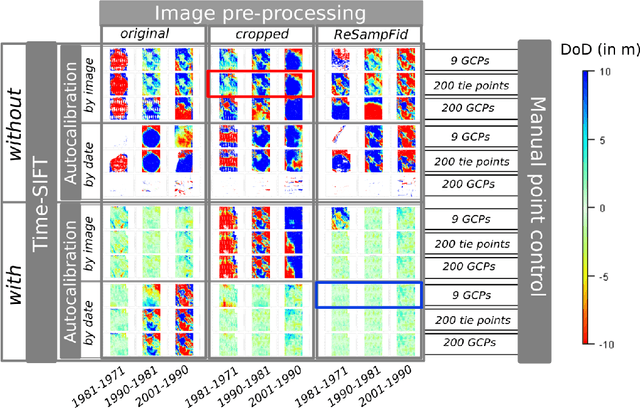
Archival aerial imagery is a source of worldwide very high resolution data for documenting paste 3-D changes. However, external information is required so that accurate 3-D models can be computed from archival aerial imagery. In this research, we propose and test a new method, termed Time-SIFT (Scale Invariant Feature Transform), which allows for computing coherent multi-temporal Digital Elevation Models (DEMs) with almost exclusively image information. This method is based on the invariance properties of the SIFT-like methods which are at the root of the Structure from Motion (SfM) algorithms. On a test site of 170 km2, we applied SfM algorithms to a unique image block with all the images of four different dates covering forty years. We compared this method to more classical methods based on the use of affordable additional data such as ground control points collected in recent orthophotos. We did extensive tests to determine which processing choices were most impacting on the final result. With these tests, we aimed at evaluating the potential of the proposed Time-SIFT method for the detection and mapping of 3-D changes. Our study showed that the Time-SIFT method was the prime criteria that allowed for computing informative DEMs of difference with almost exclusively image information and limited photogrammetric expertise and human intervention. Due to the fact that the proposed Time-SIFT method can be automatically applied with exclusively image information, our results pave the way to a systematic processing of the archival aerial imagery on very large spatio-temporal windows, and should hence greatly help the unlocking of archival aerial imagery for the documenting of past 3-D changes.
TextGNN: Improving Text Encoder via Graph Neural Network in Sponsored Search
Feb 09, 2021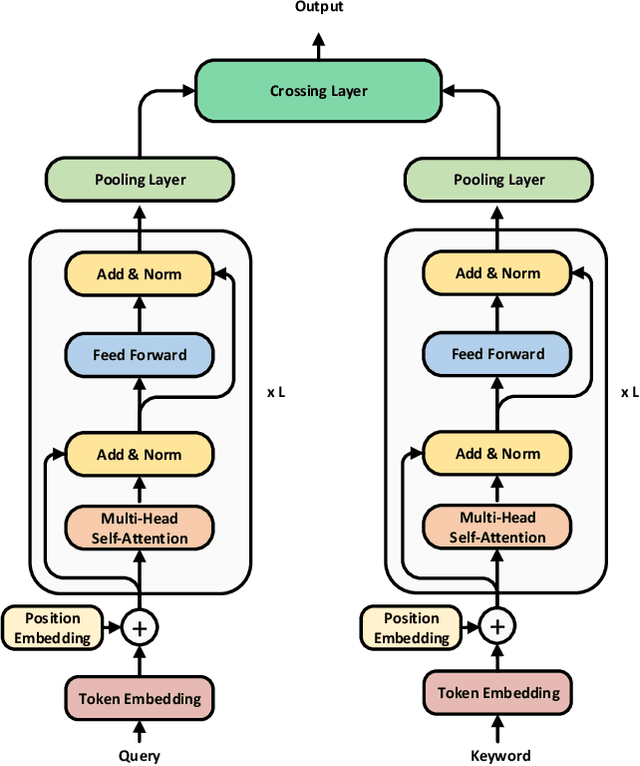
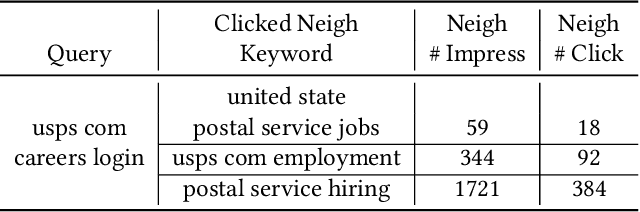
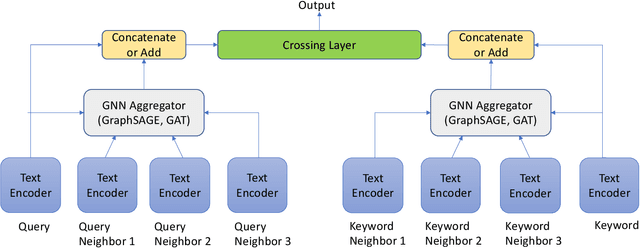
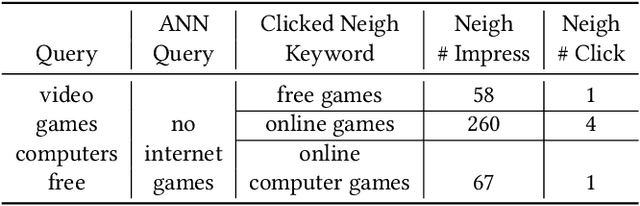
Text encoders based on C-DSSM or transformers have demonstrated strong performance in many Natural Language Processing (NLP) tasks. Low latency variants of these models have also been developed in recent years in order to apply them in the field of sponsored search which has strict computational constraints. However these models are not the panacea to solve all the Natural Language Understanding (NLU) challenges as the pure semantic information in the data is not sufficient to fully identify the user intents. We propose the TextGNN model that naturally extends the strong twin tower structured encoders with the complementary graph information from user historical behaviors, which serves as a natural guide to help us better understand the intents and hence generate better language representations. The model inherits all the benefits of twin tower models such as C-DSSM and TwinBERT so that it can still be used in the low latency environment while achieving a significant performance gain than the strong encoder-only counterpart baseline models in both offline evaluations and online production system. In offline experiments, the model achieves a 0.14% overall increase in ROC-AUC with a 1% increased accuracy for long-tail low-frequency Ads, and in the online A/B testing, the model shows a 2.03% increase in Revenue Per Mille with a 2.32% decrease in Ad defect rate.
Does enhanced shape bias improve neural network robustness to common corruptions?
Apr 20, 2021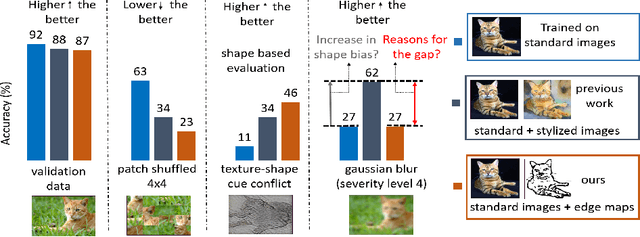
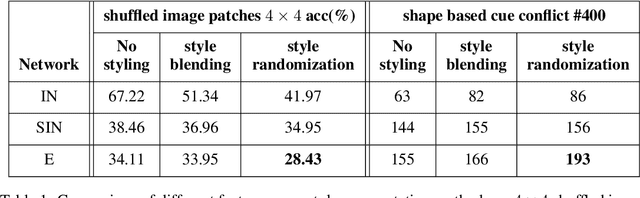

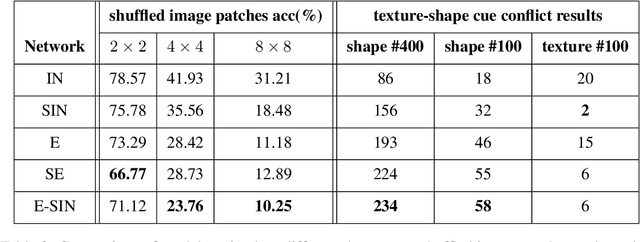
Convolutional neural networks (CNNs) learn to extract representations of complex features, such as object shapes and textures to solve image recognition tasks. Recent work indicates that CNNs trained on ImageNet are biased towards features that encode textures and that these alone are sufficient to generalize to unseen test data from the same distribution as the training data but often fail to generalize to out-of-distribution data. It has been shown that augmenting the training data with different image styles decreases this texture bias in favor of increased shape bias while at the same time improving robustness to common corruptions, such as noise and blur. Commonly, this is interpreted as shape bias increasing corruption robustness. However, this relationship is only hypothesized. We perform a systematic study of different ways of composing inputs based on natural images, explicit edge information, and stylization. While stylization is essential for achieving high corruption robustness, we do not find a clear correlation between shape bias and robustness. We conclude that the data augmentation caused by style-variation accounts for the improved corruption robustness and increased shape bias is only a byproduct.
Cognitive Indoor Positioning and Tracking using Multipath Channel Information
Oct 19, 2016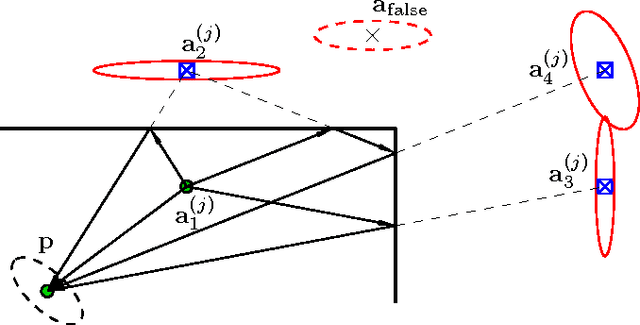
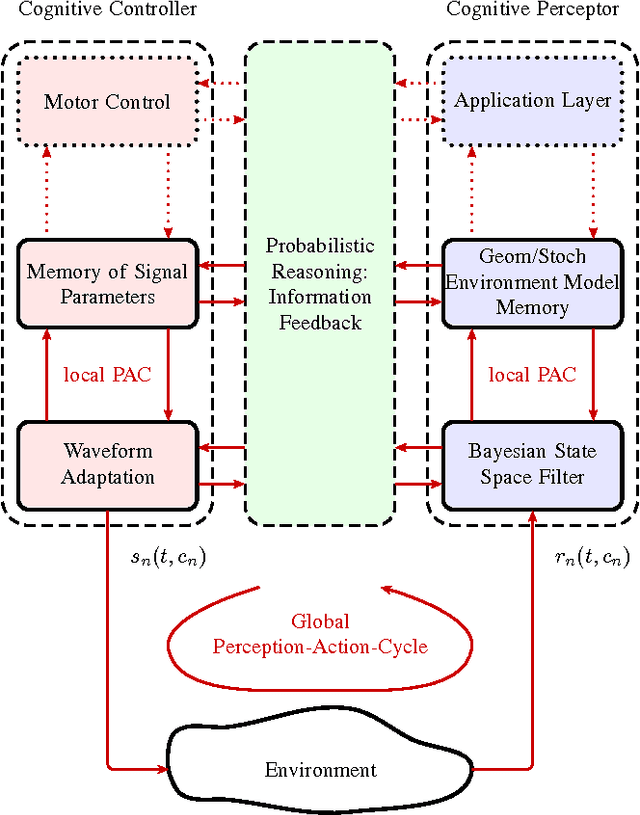
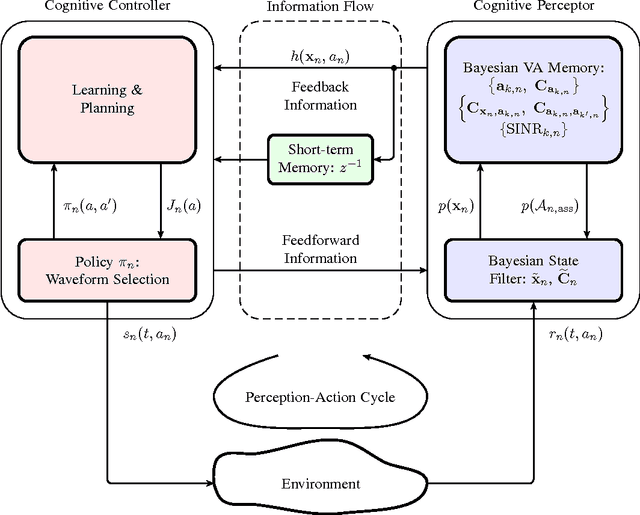
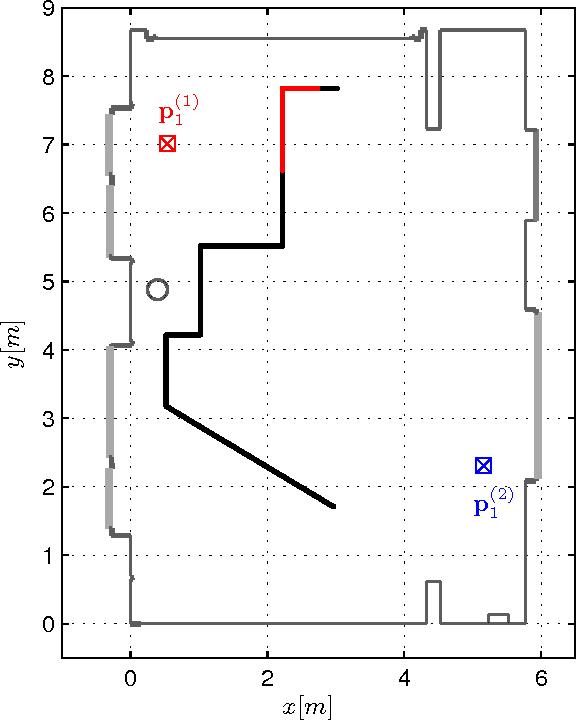
This paper presents a robust and accurate positioning system that adapts its behavior to the surrounding environment like the visual brain, mimicking its capability of filtering out clutter and focusing attention on activity and relevant information. Especially in indoor environments, which are characterized by harsh multipath propagation, it is still elusive to achieve the needed level of accuracy robustly under the constraint of reasonable infrastructural needs. In such environments it is essential to separate relevant from irrelevant information and attain an appropriate uncertainty model for measurements that are used for positioning.