 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal EigenPAC for dyslexia diagnosis
Apr 13, 2021
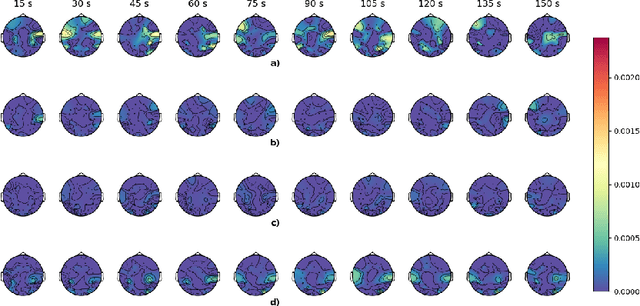
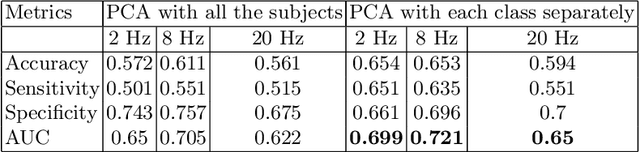
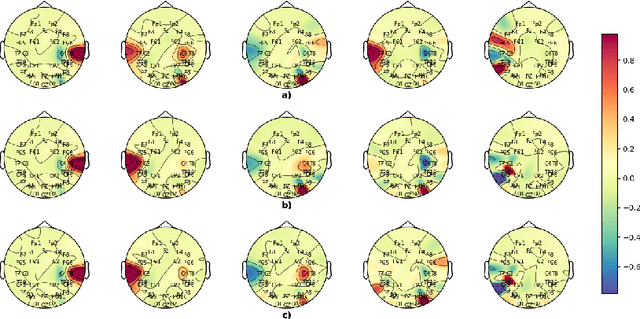
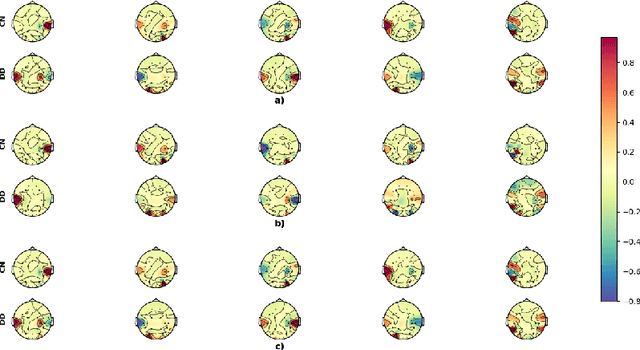
Electroencephalography signals allow to explore the functional activity of the brain cortex in a non-invasive way. However, the analysis of these signals is not straightforward due to the presence of different artifacts and the very low signal-to-noise ratio. Cross-Frequency Coupling (CFC) methods provide a way to extract information from EEG, related to the synchronization among frequency bands. However, CFC methods are usually applied in a local way, computing the interaction between phase and amplitude at the same electrode. In this work we show a method to compute PAC features among electrodes to study the functional connectivity. Moreover, this has been applied jointly with Principal Component Analysis to explore patterns related to Dyslexia in 7-years-old children. The developed methodology reveals the temporal evolution of PAC-based connectivity. Directions of greatest variance computed by PCA are called eigenPACs here, since they resemble the classical \textit{eigenfaces} representation. The projection of PAC data onto the eigenPACs provide a set of features that has demonstrates their discriminative capability, specifically in the Beta-Gamma bands.
Comprehensive Multi-Modal Interactions for Referring Image Segmentation
Apr 21, 2021
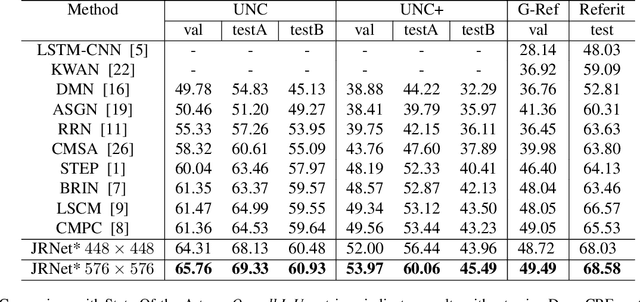
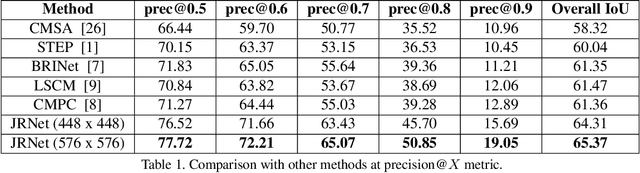
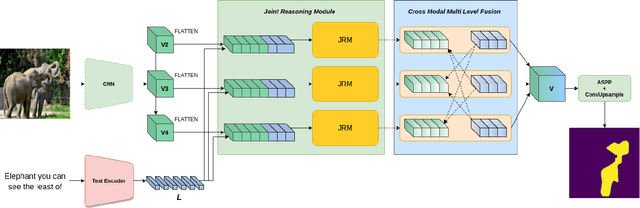
We investigate Referring Image Segmentation (RIS), which outputs a segmentation map corresponding to the given natural language description. To solve RIS efficiently, we need to understand each word's relationship with other words, each region in the image to other regions, and cross-modal alignment between linguistic and visual domains. Recent methods model these three types of interactions sequentially. We argue that such a modular approach limits these methods' performance, and joint simultaneous reasoning can help resolve ambiguities. To this end, we propose a Joint Reasoning (JRM) module and a novel Cross-Modal Multi-Level Fusion (CMMLF) module for tackling this task. JRM effectively models the referent's multi-modal context by jointly reasoning over visual and linguistic modalities (performing word-word, image region-region, word-region interactions in a single module). CMMLF module further refines the segmentation masks by exchanging contextual information across visual hierarchy through linguistic features acting as a bridge. We present thorough ablation studies and validate our approach's performance on four benchmark datasets, and show that the proposed method outperforms the existing state-of-the-art methods on all four datasets by significant margins.
Crossover Learning for Fast Online Video Instance Segmentation
Apr 13, 2021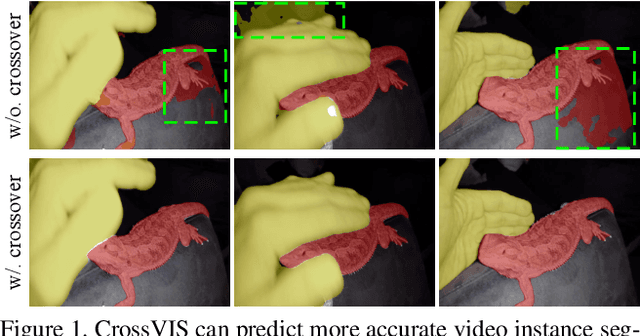
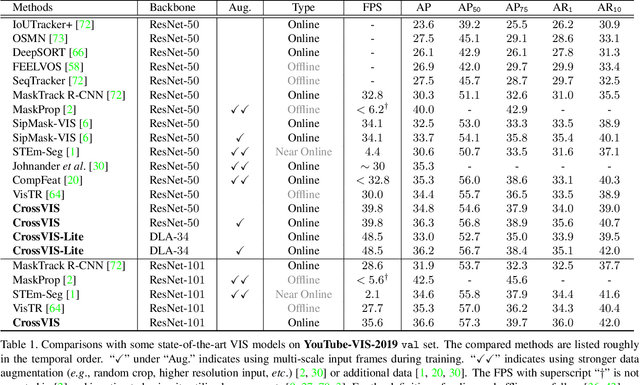
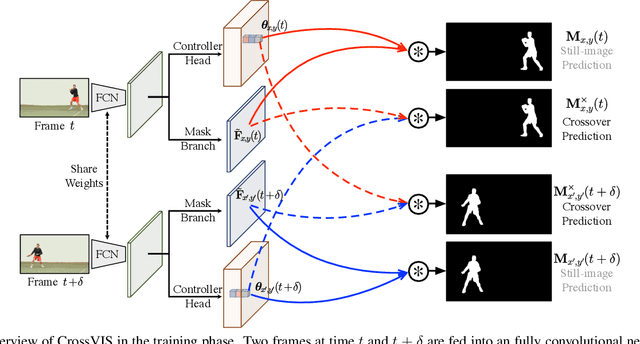
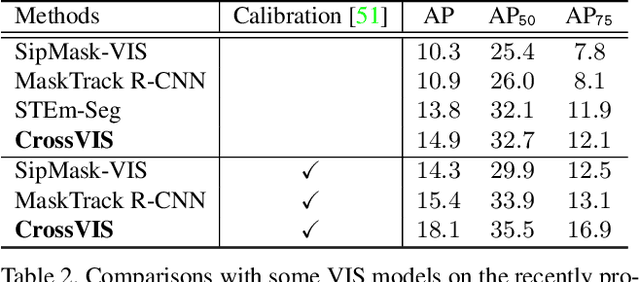
Modeling temporal visual context across frames is critical for video instance segmentation (VIS) and other video understanding tasks. In this paper, we propose a fast online VIS model named CrossVIS. For temporal information modeling in VIS, we present a novel crossover learning scheme that uses the instance feature in the current frame to pixel-wisely localize the same instance in other frames. Different from previous schemes, crossover learning does not require any additional network parameters for feature enhancement. By integrating with the instance segmentation loss, crossover learning enables efficient cross-frame instance-to-pixel relation learning and brings cost-free improvement during inference. Besides, a global balanced instance embedding branch is proposed for more accurate and more stable online instance association. We conduct extensive experiments on three challenging VIS benchmarks, \ie, YouTube-VIS-2019, OVIS, and YouTube-VIS-2021 to evaluate our methods. To our knowledge, CrossVIS achieves state-of-the-art performance among all online VIS methods and shows a decent trade-off between latency and accuracy. Code will be available to facilitate future research.
Unsupervised Disentanglement of Linear-Encoded Facial Semantics
Mar 30, 2021
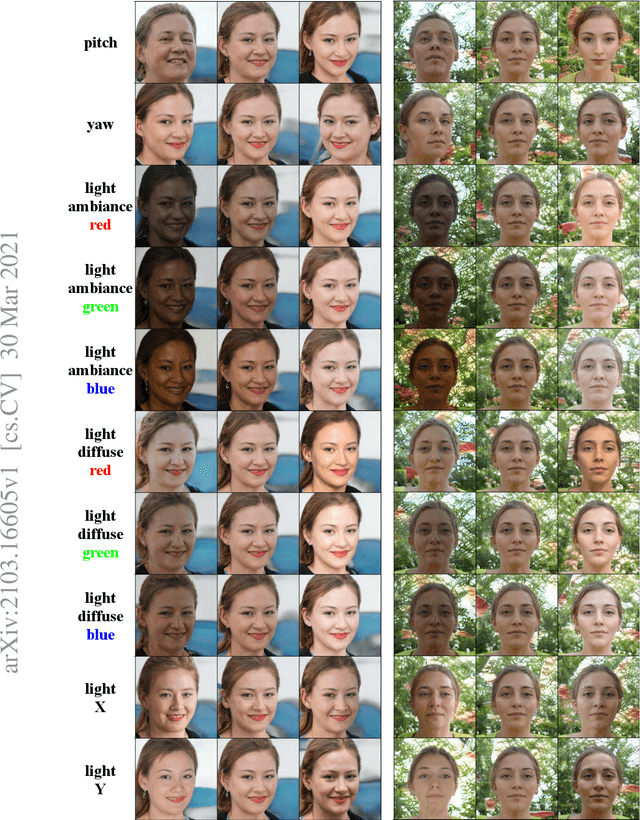
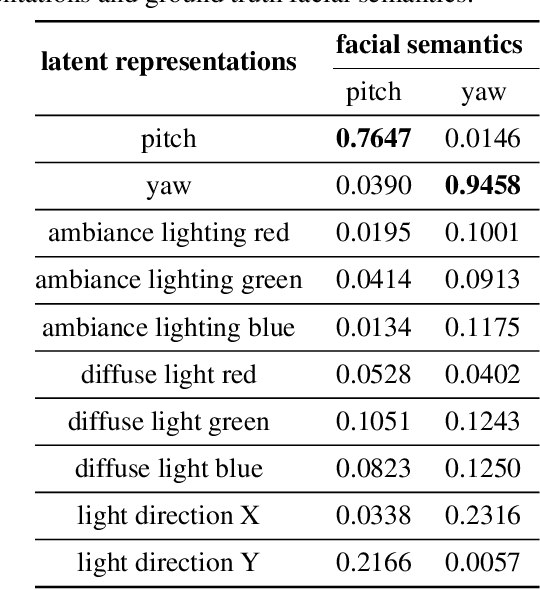
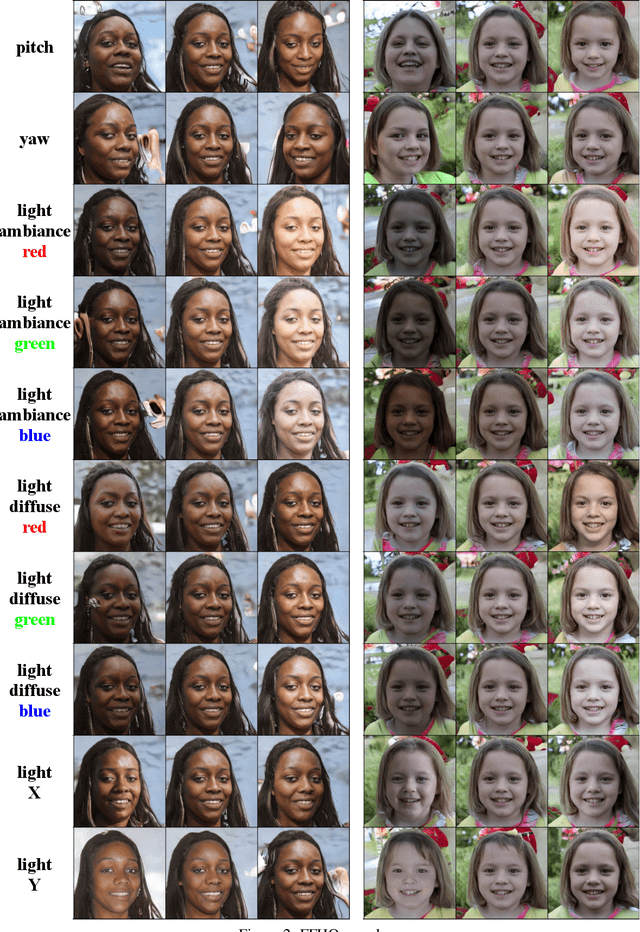
We propose a method to disentangle linear-encoded facial semantics from StyleGAN without external supervision. The method derives from linear regression and sparse representation learning concepts to make the disentangled latent representations easily interpreted as well. We start by coupling StyleGAN with a stabilized 3D deformable facial reconstruction method to decompose single-view GAN generations into multiple semantics. Latent representations are then extracted to capture interpretable facial semantics. In this work, we make it possible to get rid of labels for disentangling meaningful facial semantics. Also, we demonstrate that the guided extrapolation along the disentangled representations can help with data augmentation, which sheds light on handling unbalanced data. Finally, we provide an analysis of our learned localized facial representations and illustrate that the semantic information is encoded, which surprisingly complies with human intuition. The overall unsupervised design brings more flexibility to representation learning in the wild.
Cognitive Indoor Positioning and Tracking using Multipath Channel Information
Oct 19, 2016
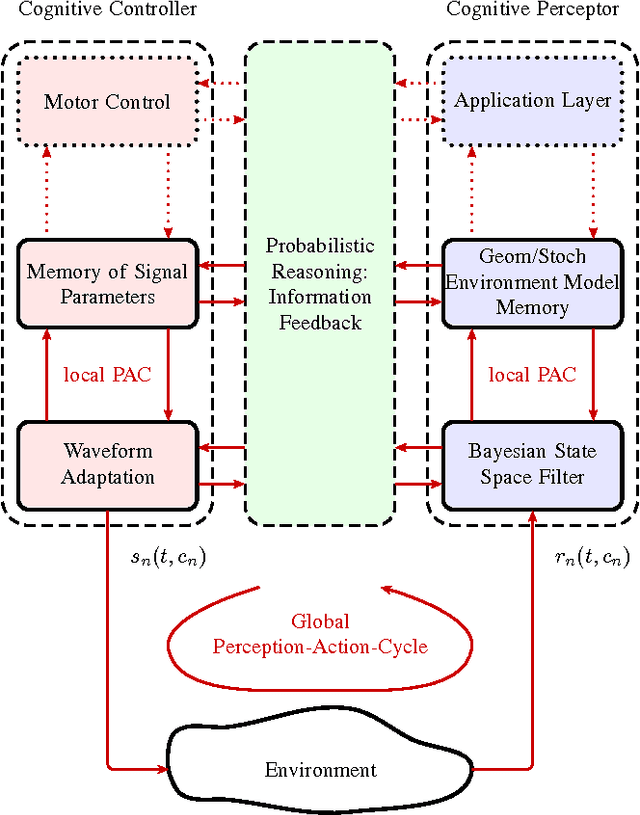
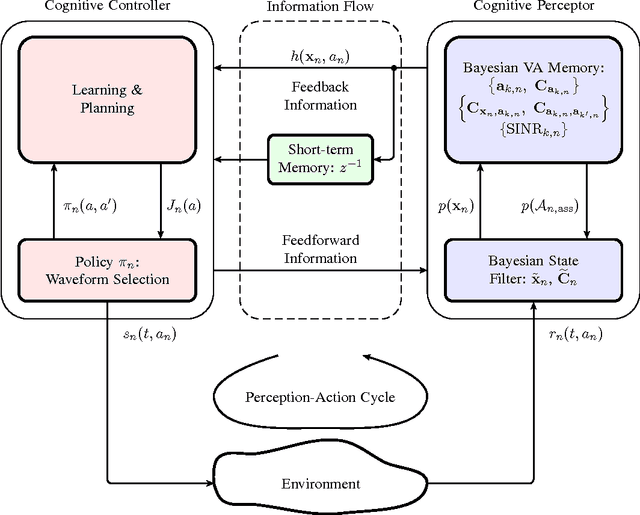
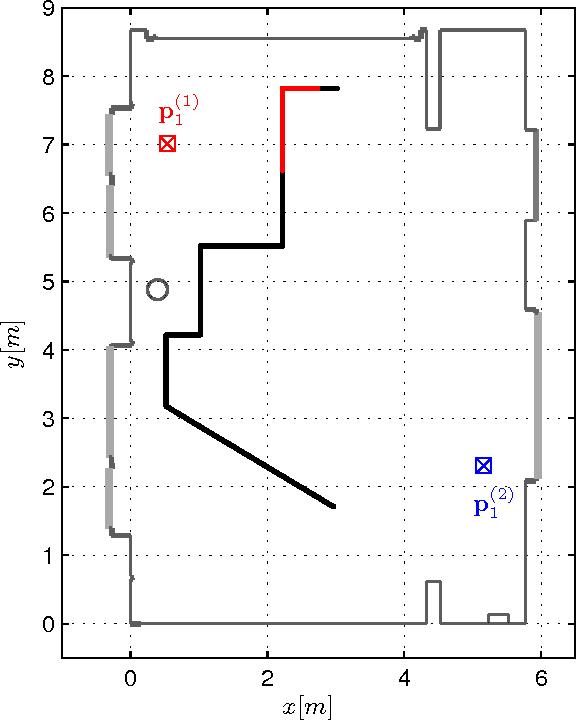
This paper presents a robust and accurate positioning system that adapts its behavior to the surrounding environment like the visual brain, mimicking its capability of filtering out clutter and focusing attention on activity and relevant information. Especially in indoor environments, which are characterized by harsh multipath propagation, it is still elusive to achieve the needed level of accuracy robustly under the constraint of reasonable infrastructural needs. In such environments it is essential to separate relevant from irrelevant information and attain an appropriate uncertainty model for measurements that are used for positioning.
When FastText Pays Attention: Efficient Estimation of Word Representations using Constrained Positional Weighting
Apr 21, 2021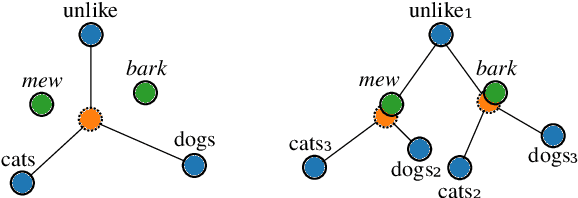
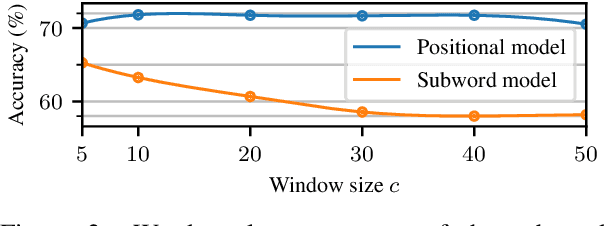
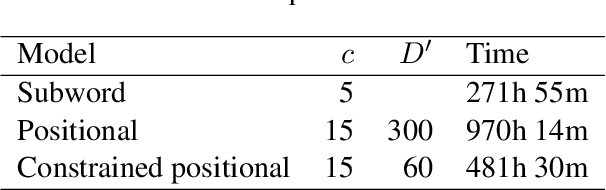
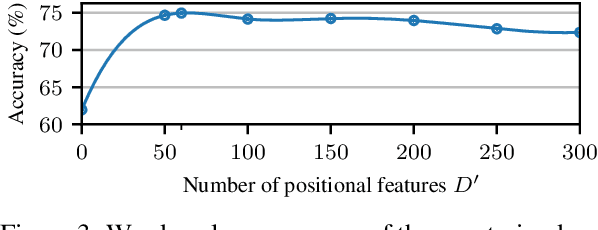
Since the seminal work of Mikolov et al. (2013a) and Bojanowski et al. (2017), word representations of shallow log-bilinear language models have found their way into many NLP applications. Mikolov et al. (2018) introduced a positional log-bilinear language model, which has characteristics of an attention-based language model and which has reached state-of-the-art performance on the intrinsic word analogy task. However, the positional model has never been evaluated on qualitative criteria or extrinsic tasks and its speed is impractical. We outline the similarities between the attention mechanism and the positional model, and we propose a constrained positional model, which adapts the sparse attention mechanism of Dai et al. (2018). We evaluate the positional and constrained positional models on three novel qualitative criteria and on the extrinsic language modeling task of Botha and Blunsom (2014). We show that the positional and constrained positional models contain interpretable information about word order and outperform the subword model of Bojanowski et al. (2017) on language modeling. We also show that the constrained positional model outperforms the positional model on language modeling and is twice as fast.
Depth as Attention for Face Representation Learning
Jan 03, 2021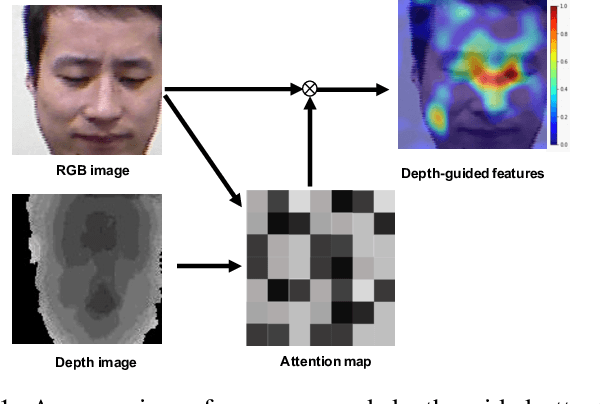
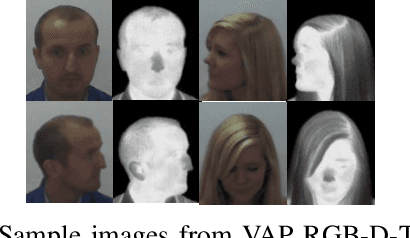
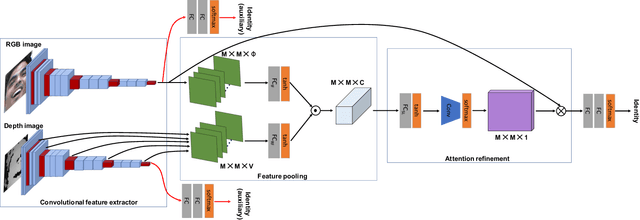
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
Thief, Beware of What Get You There: Towards Understanding Model Extraction Attack
Apr 13, 2021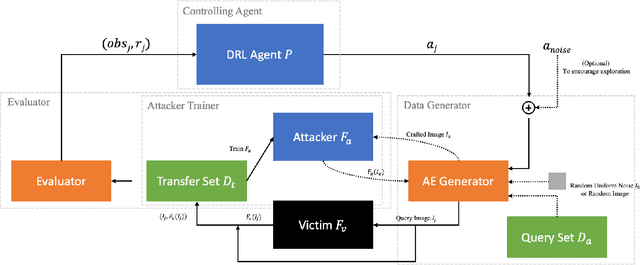
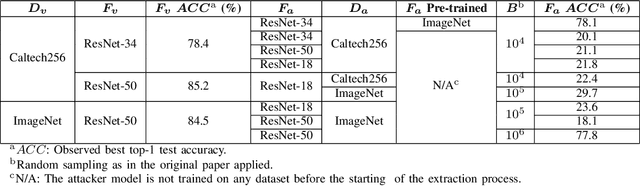
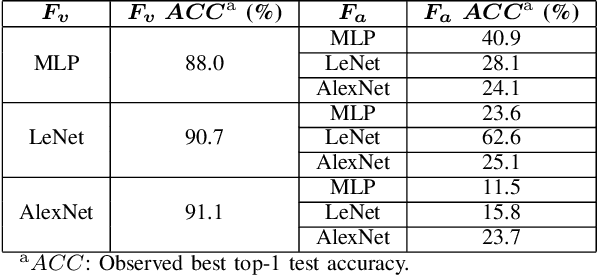
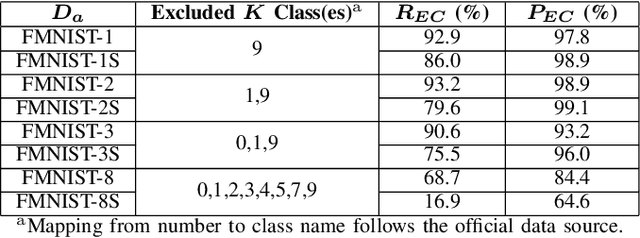
Model extraction increasingly attracts research attentions as keeping commercial AI models private can retain a competitive advantage. In some scenarios, AI models are trained proprietarily, where neither pre-trained models nor sufficient in-distribution data is publicly available. Model extraction attacks against these models are typically more devastating. Therefore, in this paper, we empirically investigate the behaviors of model extraction under such scenarios. We find the effectiveness of existing techniques significantly affected by the absence of pre-trained models. In addition, the impacts of the attacker's hyperparameters, e.g. model architecture and optimizer, as well as the utilities of information retrieved from queries, are counterintuitive. We provide some insights on explaining the possible causes of these phenomena. With these observations, we formulate model extraction attacks into an adaptive framework that captures these factors with deep reinforcement learning. Experiments show that the proposed framework can be used to improve existing techniques, and show that model extraction is still possible in such strict scenarios. Our research can help system designers to construct better defense strategies based on their scenarios.
Document-Level Event Argument Extraction by Conditional Generation
Apr 13, 2021

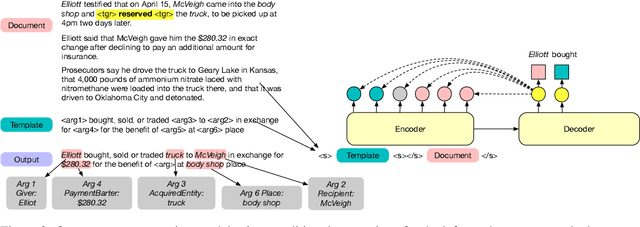
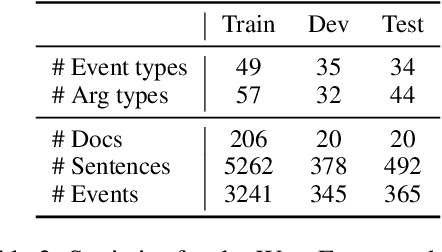
Event extraction has long been treated as a sentence-level task in the IE community. We argue that this setting does not match human information-seeking behavior and leads to incomplete and uninformative extraction results. We propose a document-level neural event argument extraction model by formulating the task as conditional generation following event templates. We also compile a new document-level event extraction benchmark dataset WikiEvents which includes complete event and coreference annotation. On the task of argument extraction, we achieve an absolute gain of 7.6% F1 and 5.7% F1 over the next best model on the RAMS and WikiEvents datasets respectively. On the more challenging task of informative argument extraction, which requires implicit coreference reasoning, we achieve a 9.3% F1 gain over the best baseline. To demonstrate the portability of our model, we also create the first end-to-end zero-shot event extraction framework and achieve 97% of fully supervised model's trigger extraction performance and 82% of the argument extraction performance given only access to 10 out of the 33 types on ACE.
Privacy and Trust Redefined in Federated Machine Learning
Mar 30, 2021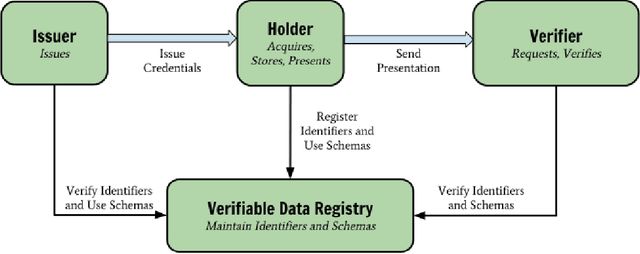
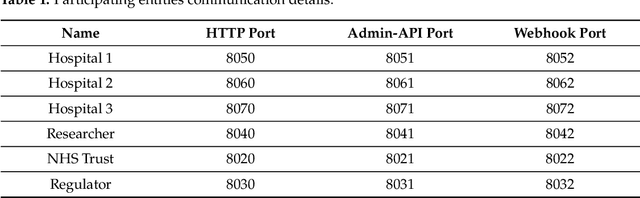
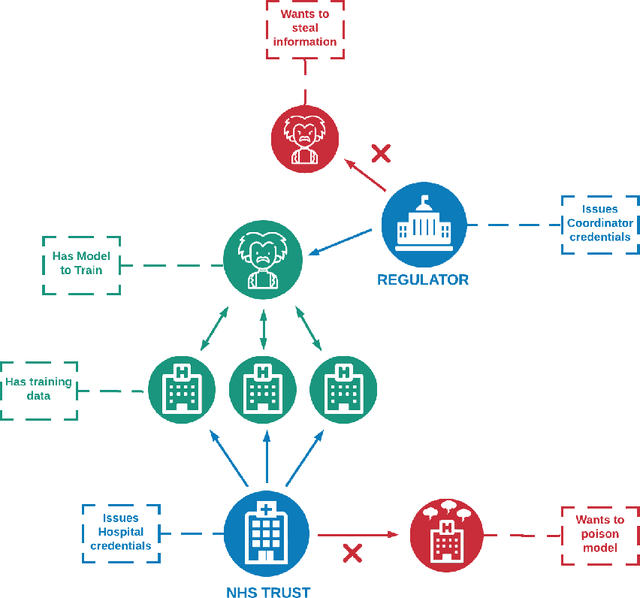
A common privacy issue in traditional machine learning is that data needs to be disclosed for the training procedures. In situations with highly sensitive data such as healthcare records, accessing this information is challenging and often prohibited. Luckily, privacy-preserving technologies have been developed to overcome this hurdle by distributing the computation of the training and ensuring the data privacy to their owners. The distribution of the computation to multiple participating entities introduces new privacy complications and risks. In this paper, we present a privacy-preserving decentralised workflow that facilitates trusted federated learning among participants. Our proof-of-concept defines a trust framework instantiated using decentralised identity technologies being developed under Hyperledger projects Aries/Indy/Ursa. Only entities in possession of Verifiable Credentials issued from the appropriate authorities are able to establish secure, authenticated communication channels authorised to participate in a federated learning workflow related to mental health data.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://doi.org/10.3390/make3020017