 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Deep Learning of Object Category using Pose Information
Jan 22, 2017
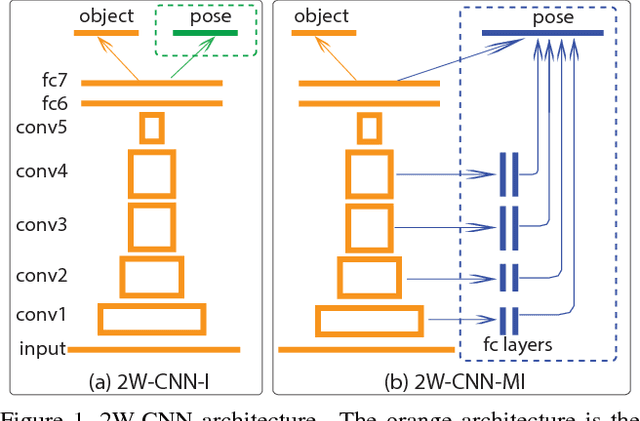


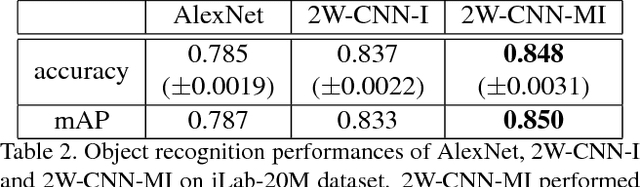
Despite significant recent progress, the best available computer vision algorithms still lag far behind human capabilities, even for recognizing individual discrete objects under various poses, illuminations, and backgrounds. Here we present a new approach to using object pose information to improve deep network learning. While existing large-scale datasets, e.g. ImageNet, do not have pose information, we leverage the newly published turntable dataset, iLab-20M, which has ~22M images of 704 object instances shot under different lightings, camera viewpoints and turntable rotations, to do more controlled object recognition experiments. We introduce a new convolutional neural network architecture, what/where CNN (2W-CNN), built on a linear-chain feedforward CNN (e.g., AlexNet), augmented by hierarchical layers regularized by object poses. Pose information is only used as feedback signal during training, in addition to category information; during test, the feedforward network only predicts category. To validate the approach, we train both 2W-CNN and AlexNet using a fraction of the dataset, and 2W-CNN achieves 6% performance improvement in category prediction. We show mathematically that 2W-CNN has inherent advantages over AlexNet under the stochastic gradient descent (SGD) optimization procedure. Further more, we fine-tune object recognition on ImageNet by using the pretrained 2W-CNN and AlexNet features on iLab-20M, results show that significant improvements have been achieved, compared with training AlexNet from scratch. Moreover, fine-tuning 2W-CNN features performs even better than fine-tuning the pretrained AlexNet features. These results show pretrained features on iLab- 20M generalizes well to natural image datasets, and 2WCNN learns even better features for object recognition than AlexNet.
MRCBert: A Machine Reading ComprehensionApproach for Unsupervised Summarization
May 01, 2021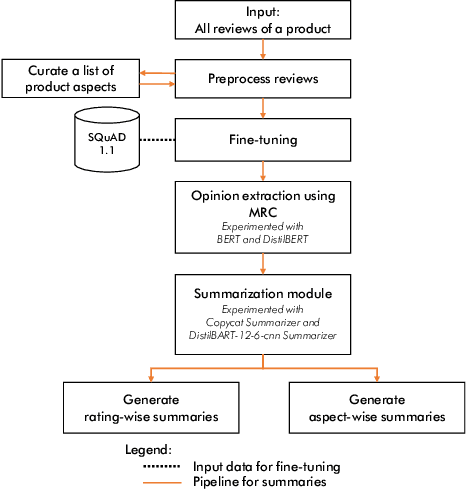

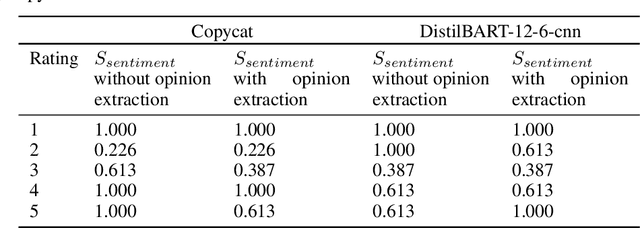
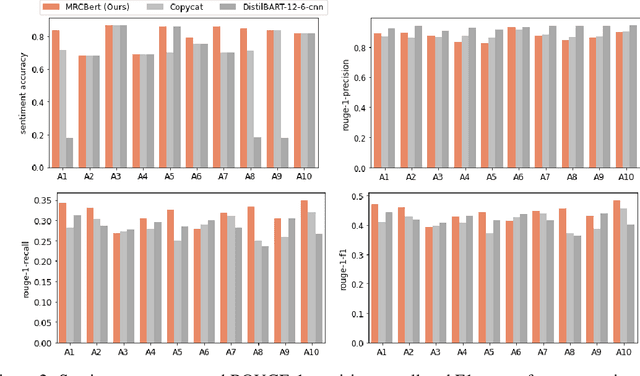
When making an online purchase, it becomes important for the customer to read the product reviews carefully and make a decision based on that. However, reviews can be lengthy, may contain repeated, or sometimes irrelevant information that does not help in decision making. In this paper, we introduce MRCBert, a novel unsupervised method to generate summaries from product reviews. We leverage Machine Reading Comprehension, i.e. MRC, approach to extract relevant opinions and generate both rating-wise and aspect-wise summaries from reviews. Through MRCBert we show that we can obtain reasonable performance using existing models and transfer learning, which can be useful for learning under limited or low resource scenarios. We demonstrated our results on reviews of a product from the Electronics category in the Amazon Reviews dataset. Our approach is unsupervised as it does not require any domain-specific dataset, such as the product review dataset, for training or fine-tuning. Instead, we have used SQuAD v1.1 dataset only to fine-tune BERT for the MRC task. Since MRCBert does not require a task-specific dataset, it can be easily adapted and used in other domains.
How Framelets Enhance Graph Neural Networks
Feb 13, 2021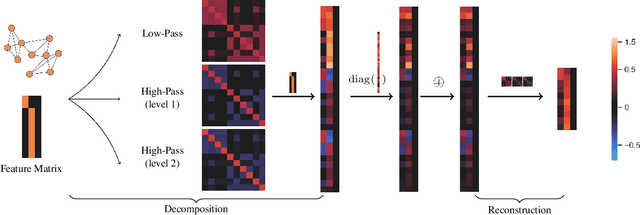
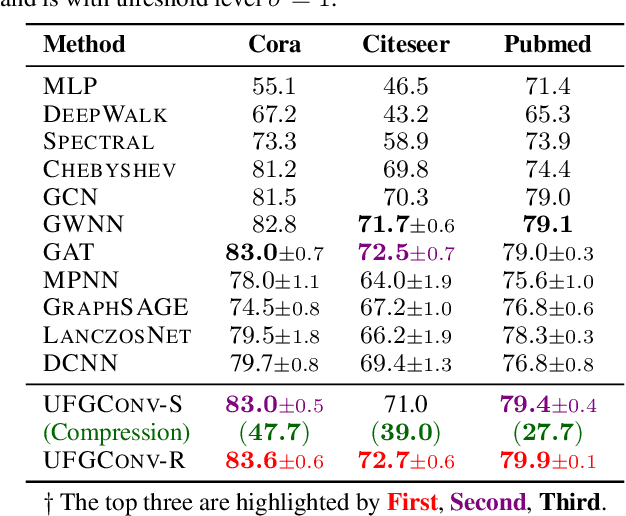
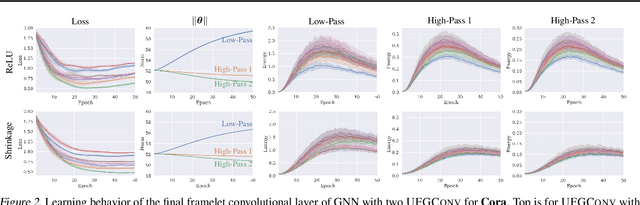
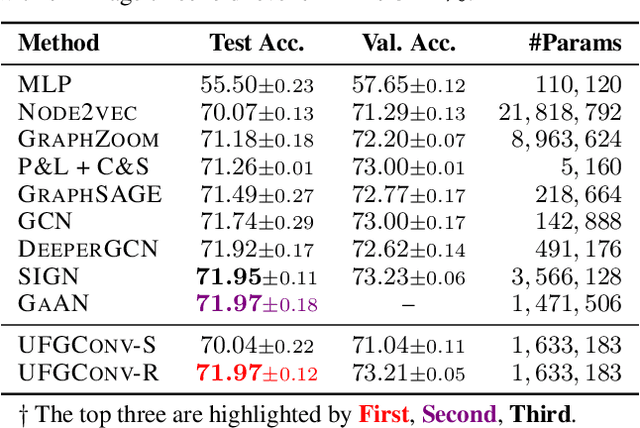
This paper presents a new approach for assembling graph neural networks based on framelet transforms. The latter provides a multi-scale representation for graph-structured data. With the framelet system, we can decompose the graph feature into low-pass and high-pass frequencies as extracted features for network training, which then defines a framelet-based graph convolution. The framelet decomposition naturally induces a graph pooling strategy by aggregating the graph feature into low-pass and high-pass spectra, which considers both the feature values and geometry of the graph data and conserves the total information. The graph neural networks with the proposed framelet convolution and pooling achieve state-of-the-art performance in many types of node and graph prediction tasks. Moreover, we propose shrinkage as a new activation for the framelet convolution, which thresholds the high-frequency information at different scales. Compared to ReLU, shrinkage in framelet convolution improves the graph neural network model in terms of denoising and signal compression: noises in both node and structure can be significantly reduced by accurately cutting off the high-pass coefficients from framelet decomposition, and the signal can be compressed to less than half its original size with the prediction performance well preserved.
Sliced $\mathcal{L}_2$ Distance for Colour Grading
Feb 18, 2021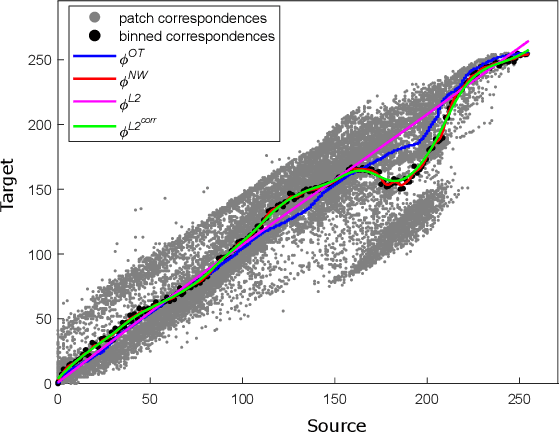
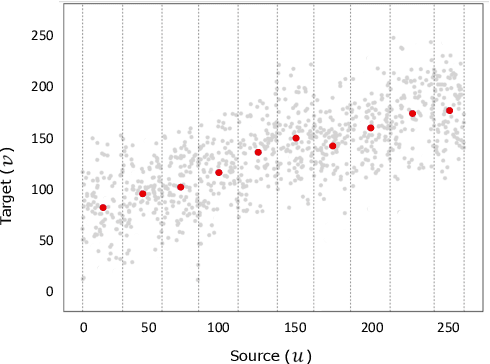
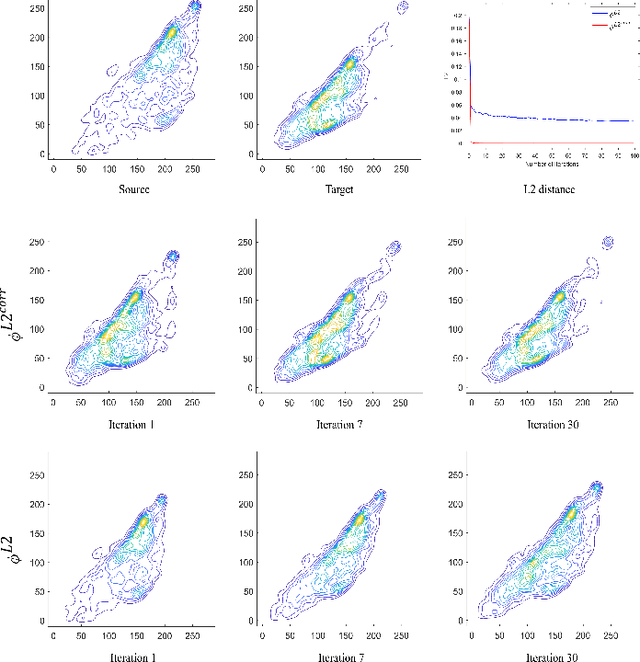
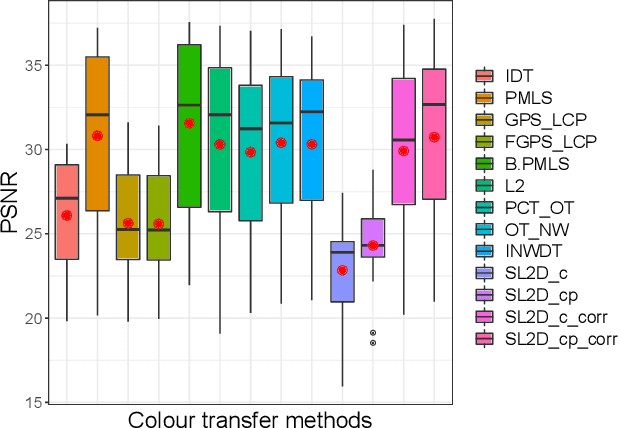
We propose a new method with $\mathcal{L}_2$ distance that maps one $N$-dimensional distribution to another, taking into account available information about correspondences. We solve the high-dimensional problem in 1D space using an iterative projection approach. To show the potentials of this mapping, we apply it to colour transfer between two images that exhibit overlapped scenes. Experiments show quantitative and qualitative competitive results as compared with the state of the art colour transfer methods.
A Picture is Worth a Collaboration: Accumulating Design Knowledge for Computer-Vision-based Hybrid Intelligence Systems
Apr 23, 2021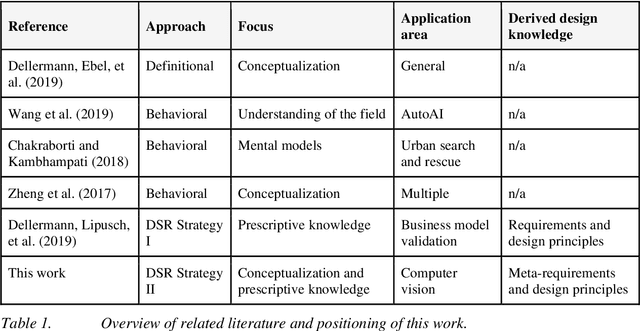
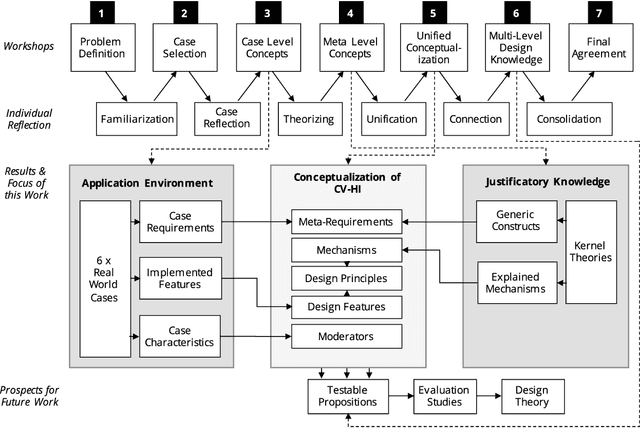
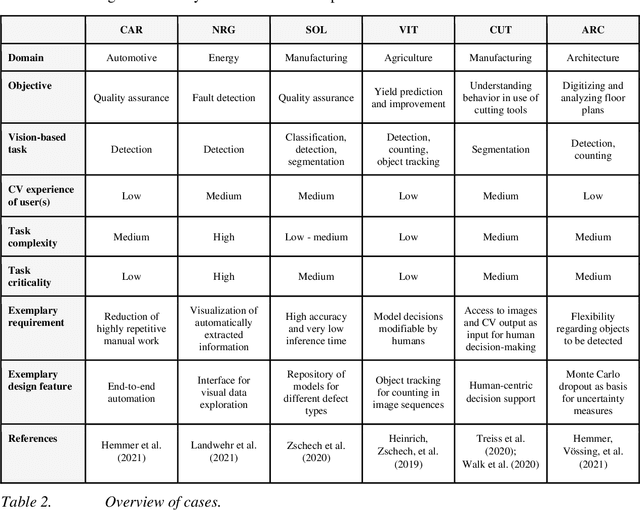
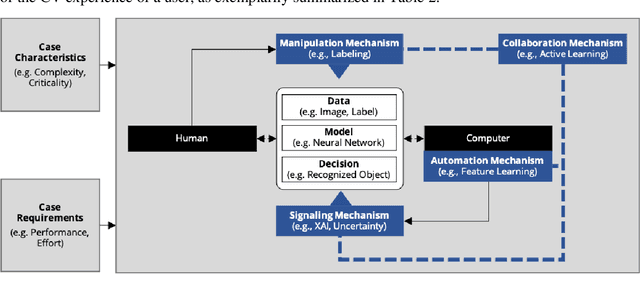
Computer vision (CV) techniques try to mimic human capabilities of visual perception to support labor-intensive and time-consuming tasks like the recognition and localization of critical objects. Nowadays, CV increasingly relies on artificial intelligence (AI) to automatically extract useful information from images that can be utilized for decision support and business process automation. However, the focus of extant research is often exclusively on technical aspects when designing AI-based CV systems while neglecting socio-technical facets, such as trust, control, and autonomy. For this purpose, we consider the design of such systems from a hybrid intelligence (HI) perspective and aim to derive prescriptive design knowledge for CV-based HI systems. We apply a reflective, practice-inspired design science approach and accumulate design knowledge from six comprehensive CV projects. As a result, we identify four design-related mechanisms (i.e., automation, signaling, modification, and collaboration) that inform our derived meta-requirements and design principles. This can serve as a basis for further socio-technical research on CV-based HI systems.
SwingBot: Learning Physical Features from In-hand Tactile Exploration for Dynamic Swing-up Manipulation
Jan 28, 2021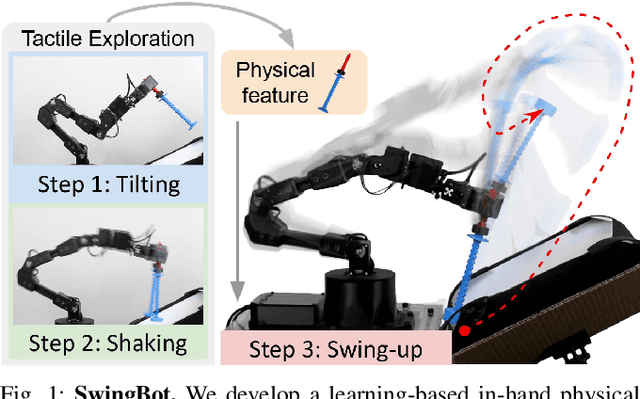
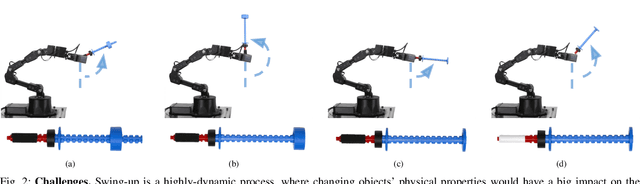
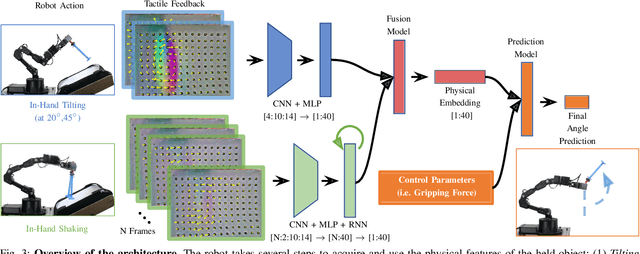
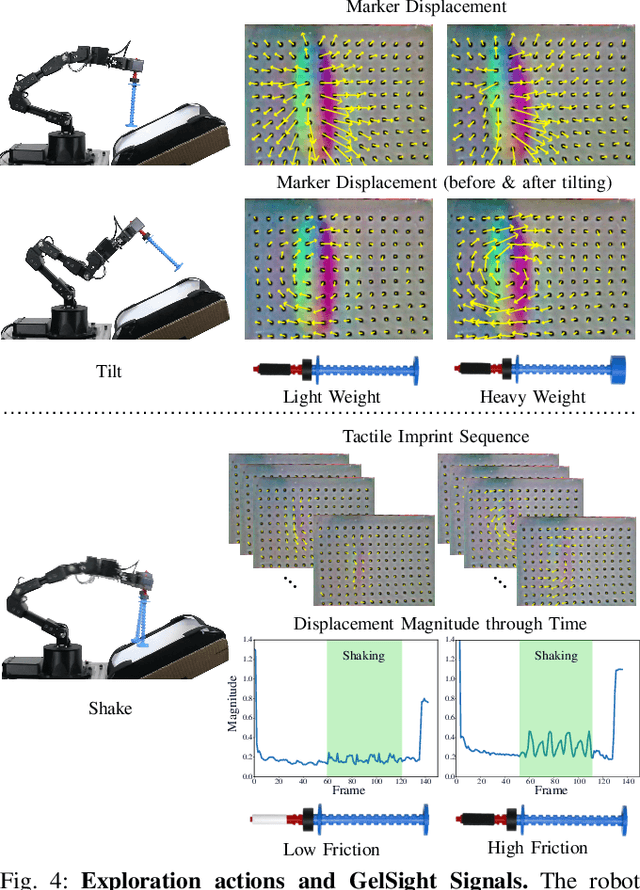
Several robot manipulation tasks are extremely sensitive to variations of the physical properties of the manipulated objects. One such task is manipulating objects by using gravity or arm accelerations, increasing the importance of mass, center of mass, and friction information. We present SwingBot, a robot that is able to learn the physical features of a held object through tactile exploration. Two exploration actions (tilting and shaking) provide the tactile information used to create a physical feature embedding space. With this embedding, SwingBot is able to predict the swing angle achieved by a robot performing dynamic swing-up manipulations on a previously unseen object. Using these predictions, it is able to search for the optimal control parameters for a desired swing-up angle. We show that with the learned physical features our end-to-end self-supervised learning pipeline is able to substantially improve the accuracy of swinging up unseen objects. We also show that objects with similar dynamics are closer to each other on the embedding space and that the embedding can be disentangled into values of specific physical properties.
Persistence Homology of TEDtalk: Do Sentence Embeddings Have a Topological Shape?
Mar 25, 2021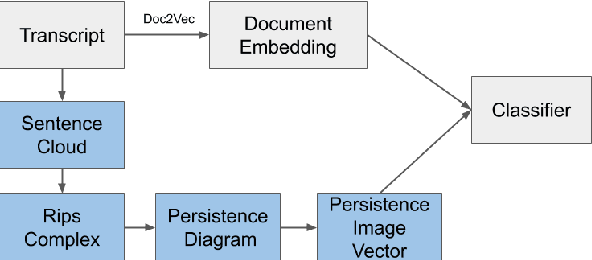
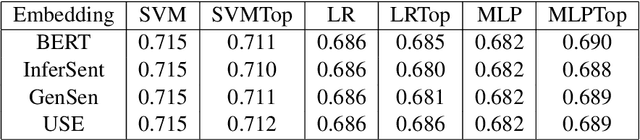
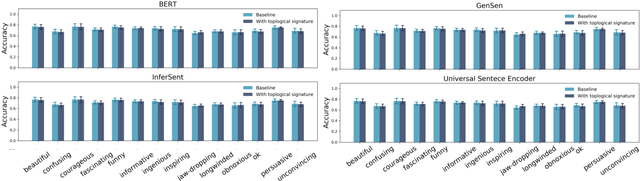
\emph{Topological data analysis} (TDA) has recently emerged as a new technique to extract meaningful discriminitve features from high dimensional data. In this paper, we investigate the possibility of applying TDA to improve the classification accuracy of public speaking rating. We calculated \emph{persistence image vectors} for the sentence embeddings of TEDtalk data and feed this vectors as additional inputs to our machine learning models. We have found a negative result that this topological information does not improve the model accuracy significantly. In some cases, it makes the accuracy slightly worse than the original one. From our results, we could not conclude that the topological shapes of the sentence embeddings can help us train a better model for public speaking rating.
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 10, 2021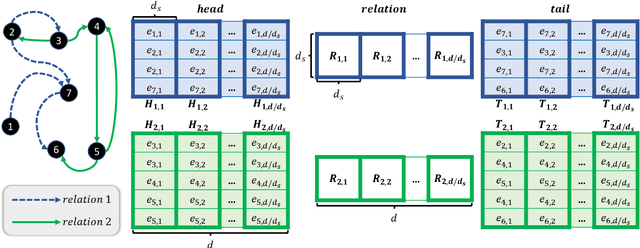
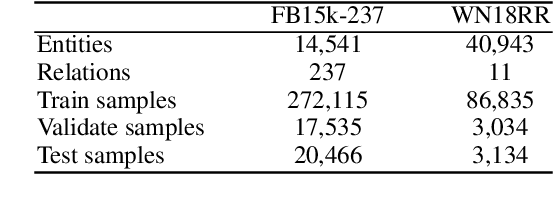
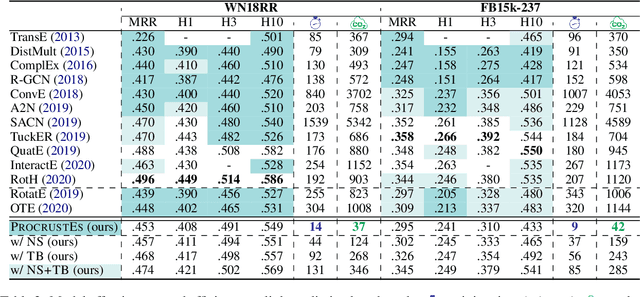
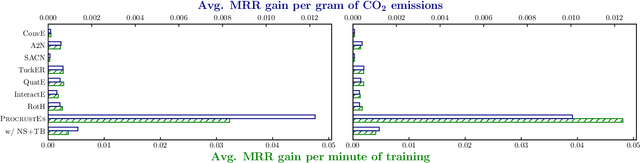
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.
Topology-Preserving 3D Image Segmentation Based On Hyperelastic Regularization
Mar 31, 2021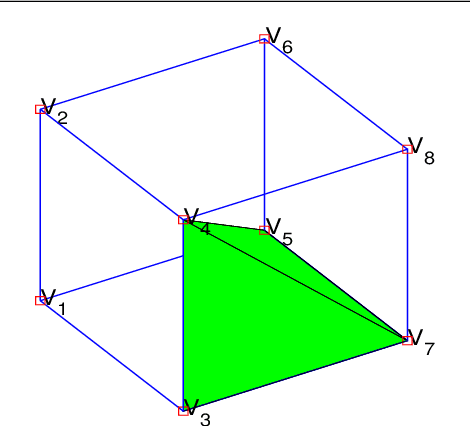
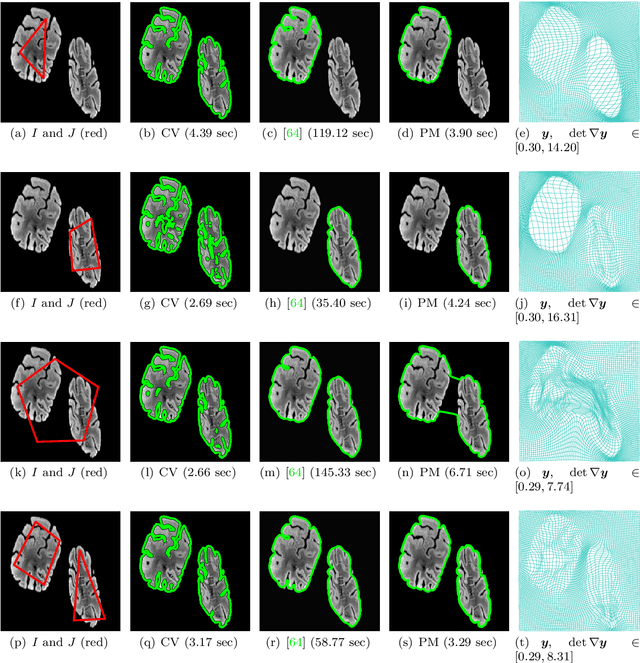
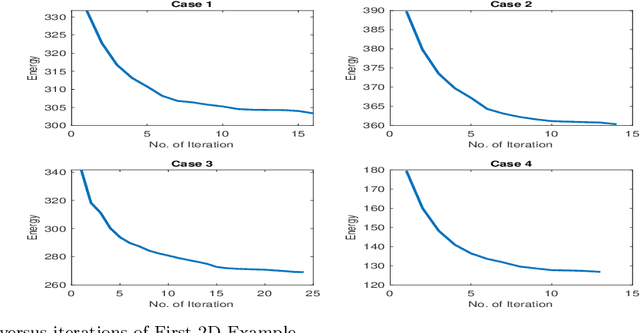
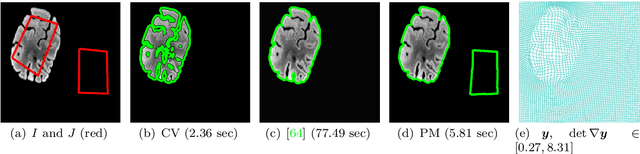
Image segmentation is to extract meaningful objects from a given image. For degraded images due to occlusions, obscurities or noises, the accuracy of the segmentation result can be severely affected. To alleviate this problem, prior information about the target object is usually introduced. In [10], a topology-preserving registration-based segmentation model was proposed, which is restricted to segment 2D images only. In this paper, we propose a novel 3D topology-preserving registration-based segmentation model with the hyperelastic regularization, which can handle both 2D and 3D images. The existence of the solution of the proposed model is established. We also propose a converging iterative scheme to solve the proposed model. Numerical experiments have been carried out on the synthetic and real images, which demonstrate the effectiveness of our proposed model.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.