 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021
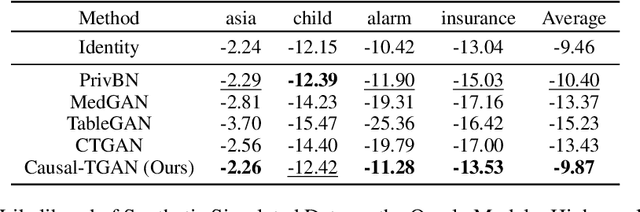
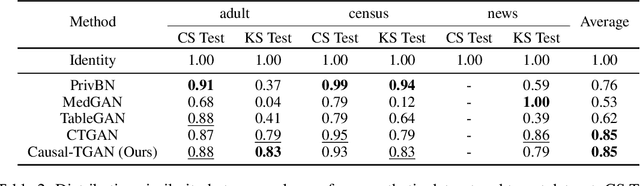
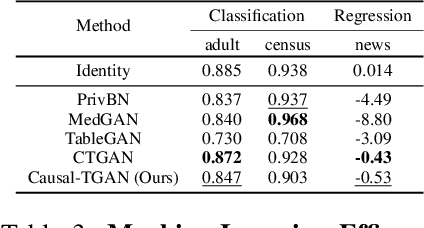
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.
A New Approach to Overgenerating and Scoring Abstractive Summaries
Apr 05, 2021


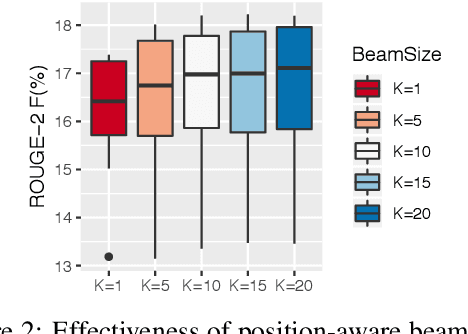
We propose a new approach to generate multiple variants of the target summary with diverse content and varying lengths, then score and select admissible ones according to users' needs. Abstractive summarizers trained on single reference summaries may struggle to produce outputs that achieve multiple desirable properties, i.e., capturing the most important information, being faithful to the original, grammatical and fluent. In this paper, we propose a two-staged strategy to generate a diverse set of candidate summaries from the source text in stage one, then score and select admissible ones in stage two. Importantly, our generator gives a precise control over the length of the summary, which is especially well-suited when space is limited. Our selectors are designed to predict the optimal summary length and put special emphasis on faithfulness to the original text. Both stages can be effectively trained, optimized and evaluated. Our experiments on benchmark summarization datasets suggest that this paradigm can achieve state-of-the-art performance.
Semantic Grouping Network for Video Captioning
Feb 03, 2021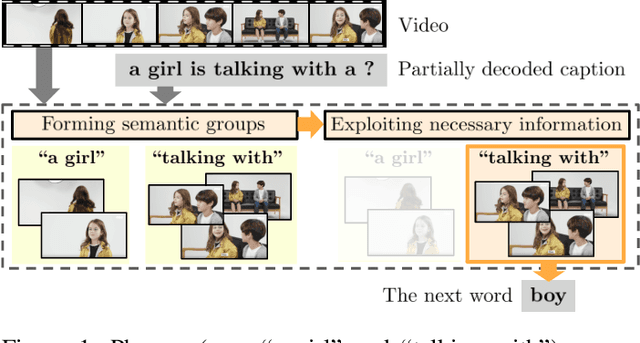
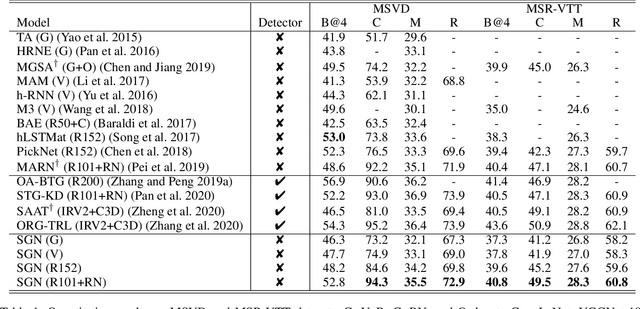

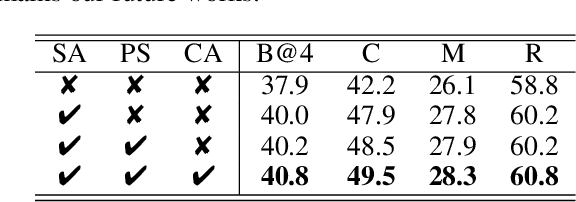
This paper considers a video caption generating network referred to as Semantic Grouping Network (SGN) that attempts (1) to group video frames with discriminating word phrases of partially decoded caption and then (2) to decode those semantically aligned groups in predicting the next word. As consecutive frames are not likely to provide unique information, prior methods have focused on discarding or merging repetitive information based only on the input video. The SGN learns an algorithm to capture the most discriminating word phrases of the partially decoded caption and a mapping that associates each phrase to the relevant video frames - establishing this mapping allows semantically related frames to be clustered, which reduces redundancy. In contrast to the prior methods, the continuous feedback from decoded words enables the SGN to dynamically update the video representation that adapts to the partially decoded caption. Furthermore, a contrastive attention loss is proposed to facilitate accurate alignment between a word phrase and video frames without manual annotations. The SGN achieves state-of-the-art performances by outperforming runner-up methods by a margin of 2.1%p and 2.4%p in a CIDEr-D score on MSVD and MSR-VTT datasets, respectively. Extensive experiments demonstrate the effectiveness and interpretability of the SGN.
A Comparative Study of Using Spatial-Temporal Graph Convolutional Networks for Predicting Availability in Bike Sharing Schemes
Apr 21, 2021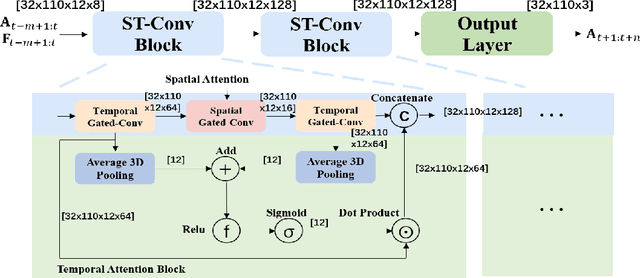
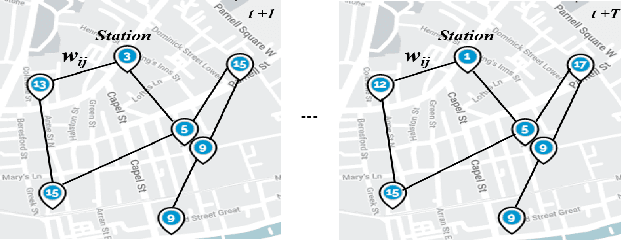
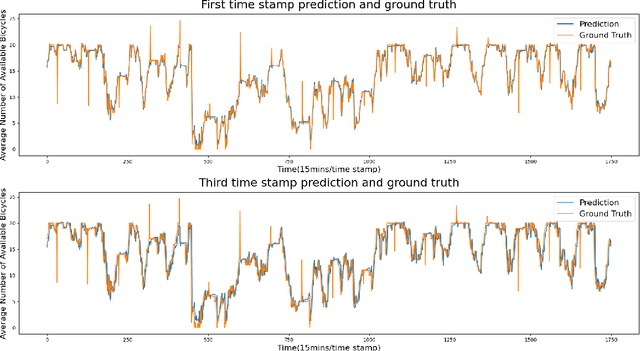
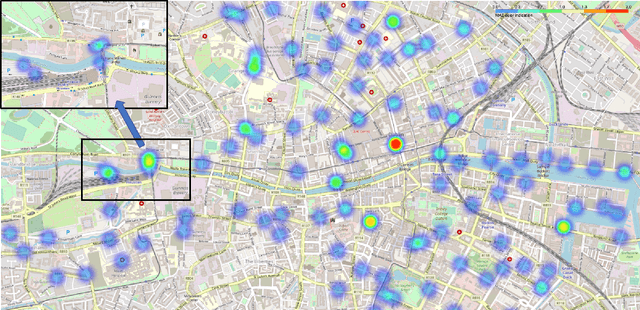
Accurately forecasting transportation demand is crucial for efficient urban traffic guidance, control and management. One solution to enhance the level of prediction accuracy is to leverage graph convolutional networks (GCN), a neural network based modelling approach with the ability to process data contained in graph based structures. As a powerful extension of GCN, a spatial-temporal graph convolutional network (ST-GCN) aims to capture the relationship of data contained in the graphical nodes across both spatial and temporal dimensions, which presents a novel deep learning paradigm for the analysis of complex time-series data that also involves spatial information as present in transportation use cases. In this paper, we present an Attention-based ST-GCN (AST-GCN) for predicting the number of available bikes in bike-sharing systems in cities, where the attention-based mechanism is introduced to further improve the performance of a ST-GCN. Furthermore, we also discuss the impacts of different modelling methods of adjacency matrices on the proposed architecture. Our experimental results are presented using two real-world datasets, Dublinbikes and NYC-Citi Bike, to illustrate the efficacy of our proposed model which outperforms the majority of existing approaches.
Multistage BiCross Encoder: Team GATE Entry for MLIA Multilingual Semantic Search Task 2
Jan 08, 2021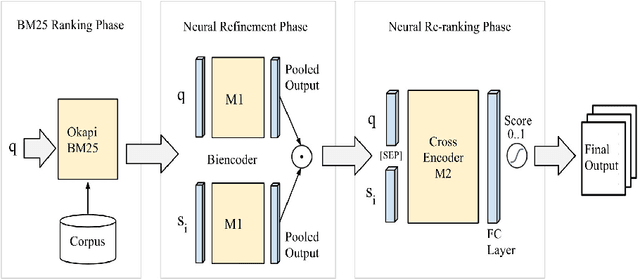
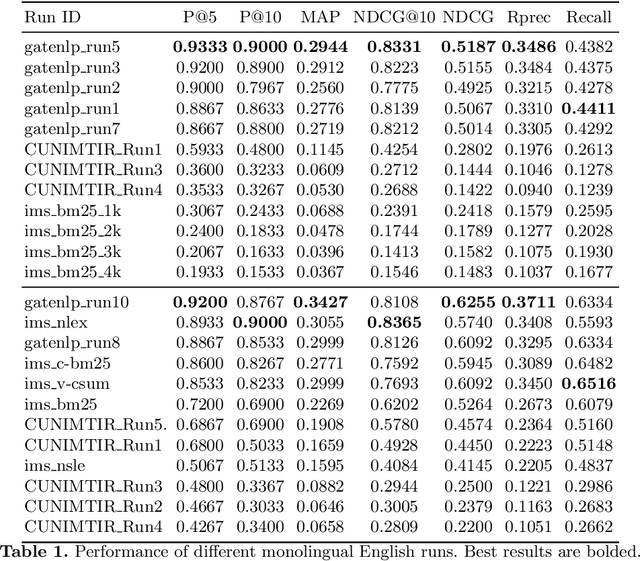
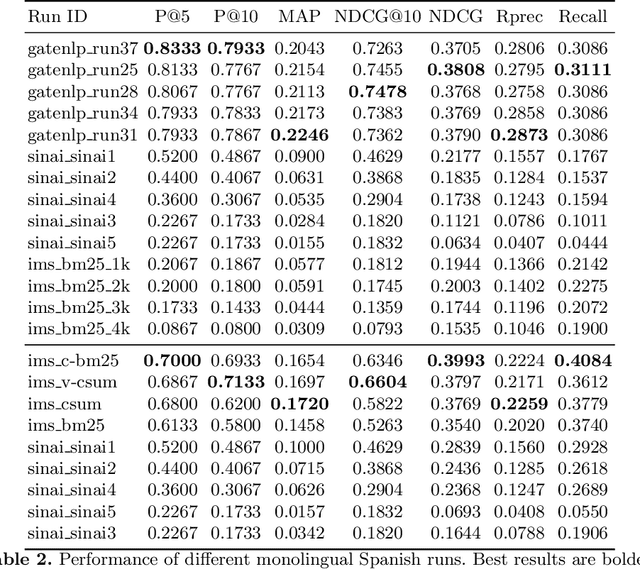
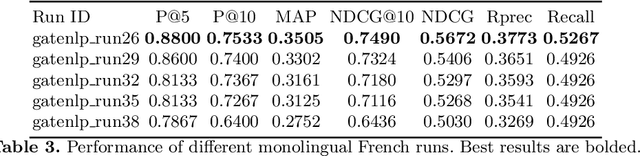
The Coronavirus (COVID-19) pandemic has led to a rapidly growing `infodemic' online. Thus, the accurate retrieval of reliable relevant data from millions of documents about COVID-19 has become urgently needed for the general public as well as for other stakeholders. The COVID-19 Multilingual Information Access (MLIA) initiative is a joint effort to ameliorate exchange of COVID-19 related information by developing applications and services through research and community participation. In this work, we present a search system called Multistage BiCross Encoder, developed by team GATE for the MLIA task 2 Multilingual Semantic Search. Multistage BiCross-Encoder is a sequential three stage pipeline which uses the Okapi BM25 algorithm and a transformer based bi-encoder and cross-encoder to effectively rank the documents with respect to the query. The results of round 1 show that our models achieve state-of-the-art performance for all ranking metrics for both monolingual and bilingual runs.
Drifting Features: Detection and evaluation in the context of automatic RRLs identification in VVV
May 23, 2021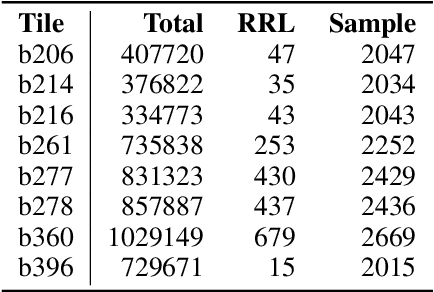
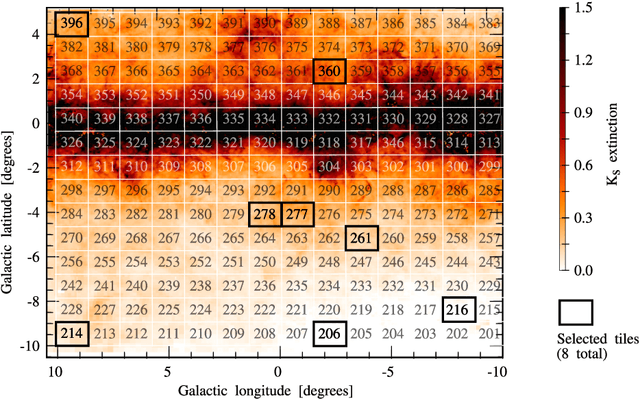
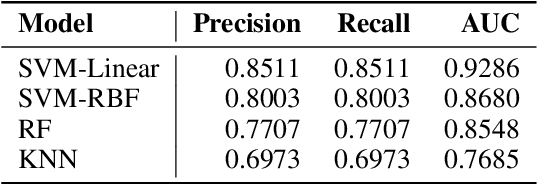
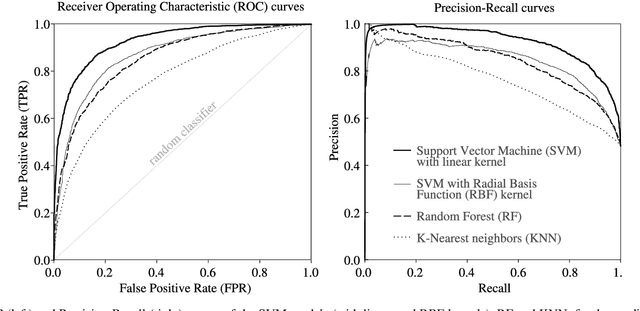
As most of the modern astronomical sky surveys produce data faster than humans can analyze it, Machine Learning (ML) has become a central tool in Astronomy. Modern ML methods can be characterized as highly resistant to some experimental errors. However, small changes on the data over long distances or long periods of time, which cannot be easily detected by statistical methods, can be harmful to these methods. We develop a new strategy to cope with this problem, also using ML methods in an innovative way, to identify these potentially harmful features. We introduce and discuss the notion of Drifting Features, related with small changes in the properties as measured in the data features. We use the identification of RRLs in VVV based on an earlier work and introduce a method for detecting Drifting Features. Our method forces a classifier to learn the tile of origin of diverse sources (mostly stellar 'point sources'), and select the features more relevant to the task of finding candidates to Drifting Features. We show that this method can efficiently identify a reduced set of features that contains useful information about the tile of origin of the sources. For our particular example of detecting RRLs in VVV, we find that Drifting Features are mostly related to color indices. On the other hand, we show that, even if we have a clear set of Drifting Features in our problem, they are mostly insensitive to the identification of RRLs. Drifting Features can be efficiently identified using ML methods. However, in our example, removing Drifting Features does not improve the identification of RRLs.
Multi-Task Learning of Query Intent and Named Entities using Transfer Learning
Apr 28, 2021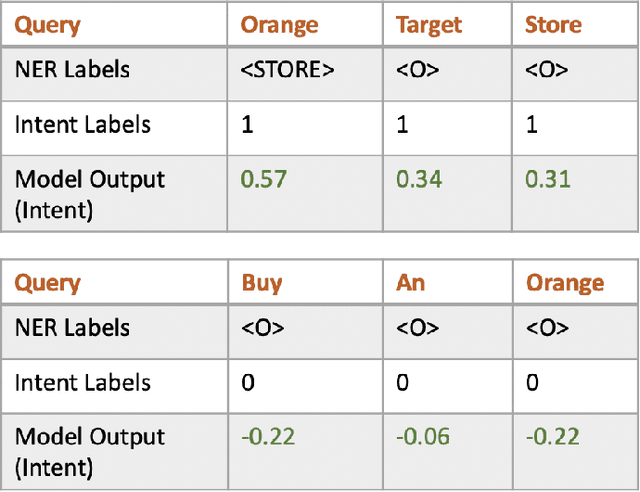

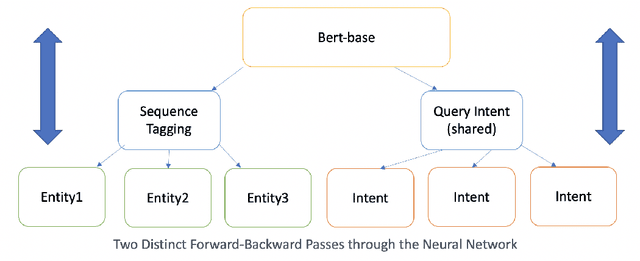
Named entity recognition (NER) has been studied extensively and the earlier algorithms were based on sequence labeling like Hidden Markov Models (HMM) and conditional random fields (CRF). These were followed by neural network based deep learning models. Recently, BERT has shown new state of the art accuracy in sequence labeling tasks like NER. In this short article, we study various approaches to task specific NER. Task specific NER has two components - identifying the intent of a piece of text (like search queries), and then labeling the query with task specific named entities. For example, we consider the task of labeling Target store locations in a search query (which could be entered in a search box or spoken in a device like Alexa or Google Home). Store locations are highly ambiguous and sometimes it is difficult to differentiate between say a location and a non-location. For example, "pickup my order at orange store" has "orange" as the store location, while "buy orange at target" has "orange" as a fruit. We explore this difficulty by doing multi-task learning which we call global to local transfer of information. We jointly learn the query intent (i.e. store lookup) and the named entities by using multiple loss functions in our BERT based model and find interesting results.
Weakly Supervised Multi-Object Tracking and Segmentation
Jan 03, 2021
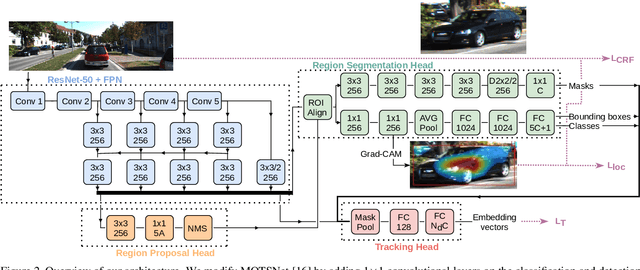
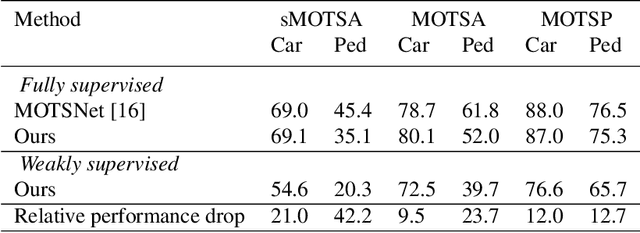
We introduce the problem of weakly supervised Multi-Object Tracking and Segmentation, i.e. joint weakly supervised instance segmentation and multi-object tracking, in which we do not provide any kind of mask annotation. To address it, we design a novel synergistic training strategy by taking advantage of multi-task learning, i.e. classification and tracking tasks guide the training of the unsupervised instance segmentation. For that purpose, we extract weak foreground localization information, provided by Grad-CAM heatmaps, to generate a partial ground truth to learn from. Additionally, RGB image level information is employed to refine the mask prediction at the edges of the objects. We evaluate our method on KITTI MOTS, the most representative benchmark for this task, reducing the performance gap on the MOTSP metric between the fully supervised and weakly supervised approach to just 12% and 12.7% for cars and pedestrians, respectively.
* Accepted at Autonomous Vehicle Vision WACV 2021 Workshop
Limited Data Emotional Voice Conversion Leveraging Text-to-Speech: Two-stage Sequence-to-Sequence Training
Mar 31, 2021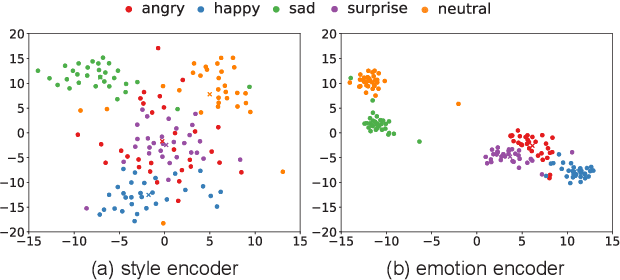
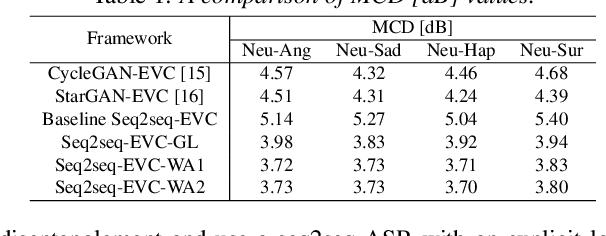
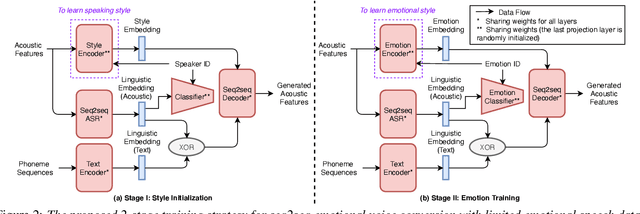
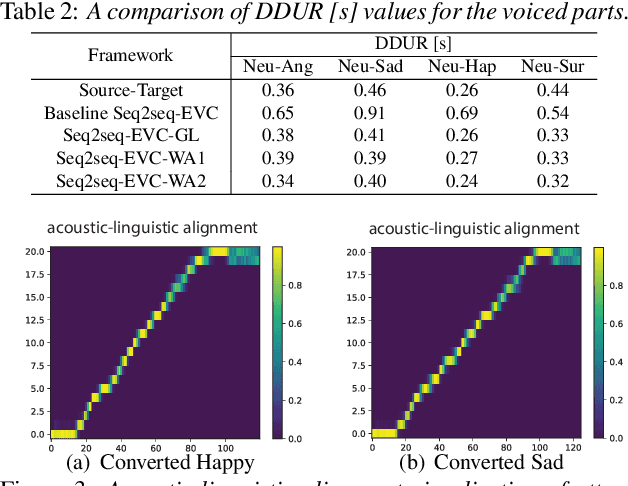
Emotional voice conversion (EVC) aims to change the emotional state of an utterance while preserving the linguistic content and speaker identity. In this paper, we propose a novel 2-stage training strategy for sequence-to-sequence emotional voice conversion with a limited amount of emotional speech data. We note that the proposed EVC framework leverages text-to-speech (TTS) as they share a common goal that is to generate high-quality expressive voice. In stage 1, we perform style initialization with a multi-speaker TTS corpus, to disentangle speaking style and linguistic content. In stage 2, we perform emotion training with a limited amount of emotional speech data, to learn how to disentangle emotional style and linguistic information from the speech. The proposed framework can perform both spectrum and prosody conversion and achieves significant improvement over the state-of-the-art baselines in both objective and subjective evaluation.
Efficient Approximate Solutions to Mutual Information Based Global Feature Selection
Jun 23, 2017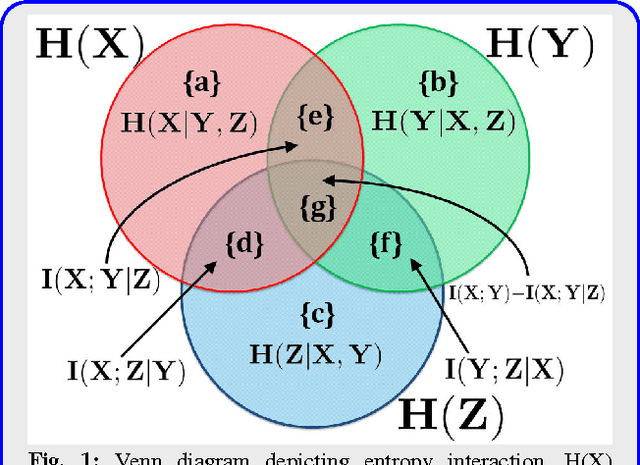
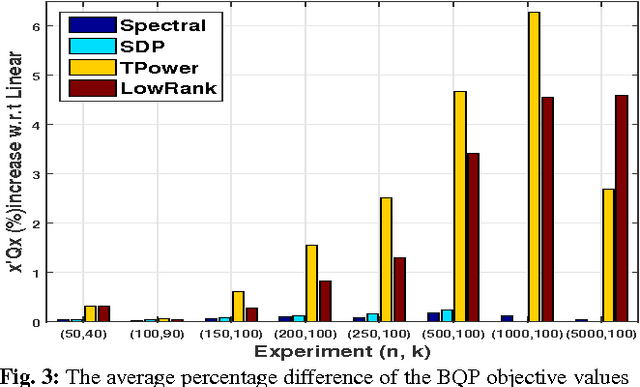
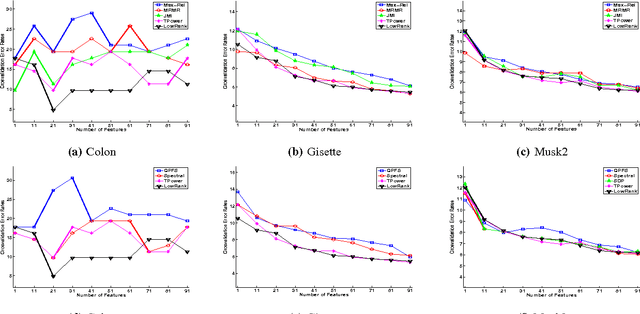
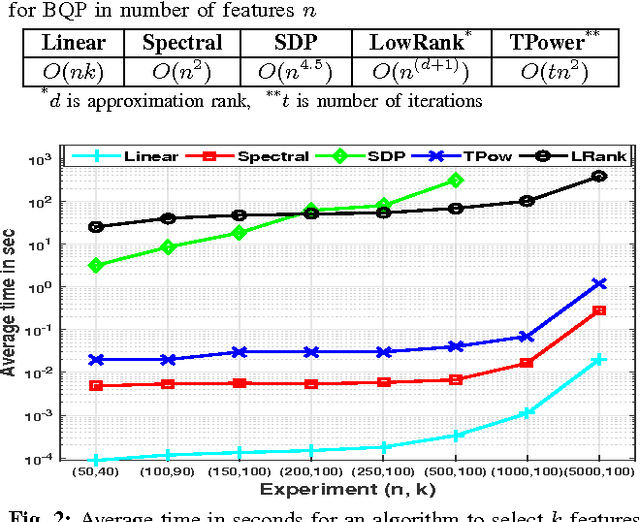
Mutual Information (MI) is often used for feature selection when developing classifier models. Estimating the MI for a subset of features is often intractable. We demonstrate, that under the assumptions of conditional independence, MI between a subset of features can be expressed as the Conditional Mutual Information (CMI) between pairs of features. But selecting features with the highest CMI turns out to be a hard combinatorial problem. In this work, we have applied two unique global methods, Truncated Power Method (TPower) and Low Rank Bilinear Approximation (LowRank), to solve the feature selection problem. These algorithms provide very good approximations to the NP-hard CMI based feature selection problem. We experimentally demonstrate the effectiveness of these procedures across multiple datasets and compare them with existing MI based global and iterative feature selection procedures.