 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information entropy as an anthropomorphic concept
Dec 01, 2015
According to E.T. Jaynes and E.P. Wigner, entropy is an anthropomorphic concept in the sense that in a physical system correspond many thermodynamic systems. The physical system can be examined from many points of view each time examining different variables and calculating entropy differently. In this paper we discuss how this concept may be applied in information entropy; how Shannon's definition of entropy can fit in Jayne's and Wigner's statement. This is achieved by generalizing Shannon's notion of information entropy and this is the main contribution of the paper. Then we discuss how entropy under these considerations may be used for the comparison of password complexity and as a measure of diversity useful in the analysis of the behavior of genetic algorithms.
HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection
Apr 01, 2021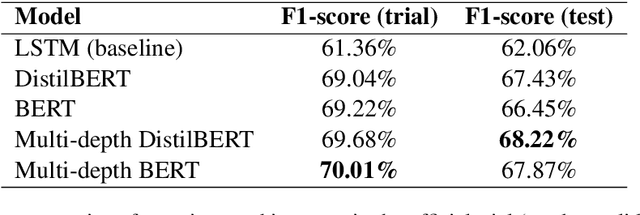
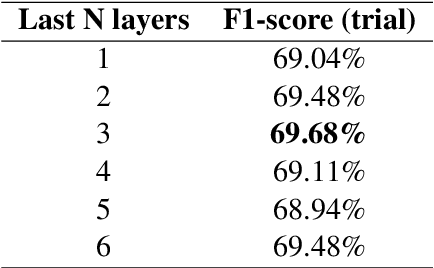

This paper presents our submission to SemEval-2021 Task 5: Toxic Spans Detection. The purpose of this task is to detect the spans that make a text toxic, which is a complex labour for several reasons. Firstly, because of the intrinsic subjectivity of toxicity, and secondly, due to toxicity not always coming from single words like insults or offends, but sometimes from whole expressions formed by words that may not be toxic individually. Following this idea of focusing on both single words and multi-word expressions, we study the impact of using a multi-depth DistilBERT model, which uses embeddings from different layers to estimate the final per-token toxicity. Our quantitative results show that using information from multiple depths boosts the performance of the model. Finally, we also analyze our best model qualitatively.
Pedestrian Trajectory Prediction using Context-Augmented Transformer Networks
Dec 03, 2020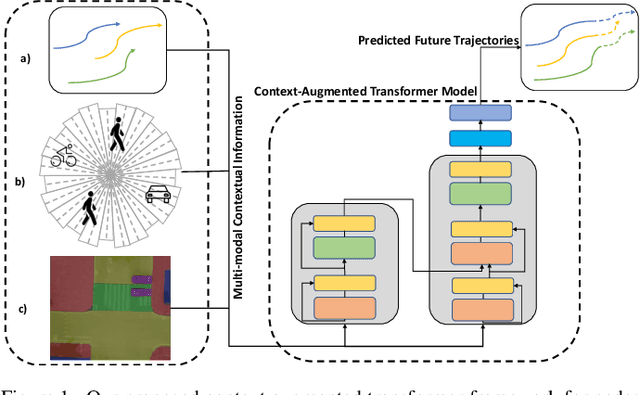

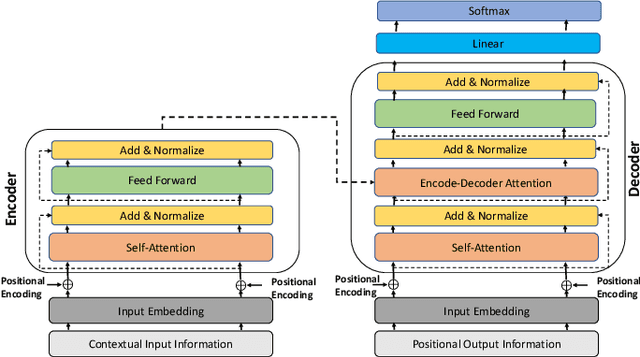

Forecasting the trajectory of pedestrians in shared urban traffic environments is still considered one of the challenging problems facing the development of autonomous vehicles (AVs). In the literature, this problem is often tackled using recurrent neural networks (RNNs). Despite the powerful capabilities of RNNs in capturing the temporal dependency in the pedestrians' motion trajectories, they were argued to be challenged when dealing with longer sequential data. Thus, in this work, we are introducing a framework based on the transformer networks that were shown recently to be more efficient and outperformed RNNs in many sequential-based tasks. We relied on a fusion of the past positional information, agent interactions information and scene physical semantics information as an input to our framework in order to provide a robust trajectory prediction of pedestrians. We have evaluated our framework on two real-life datasets of pedestrians in shared urban traffic environments and it has outperformed the compared baseline approaches in both short-term and long-term prediction horizons.
CDR Based Trajectories: Tentative for Filtering Ping-pong Handover
May 02, 2021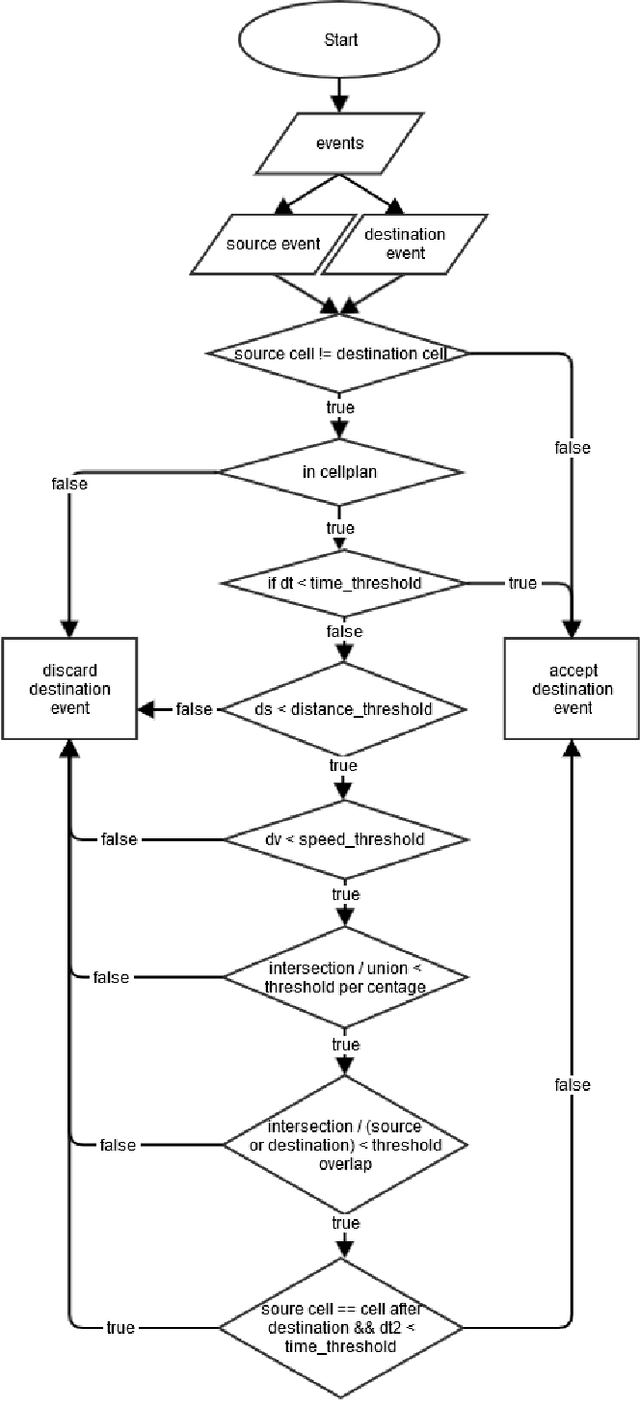
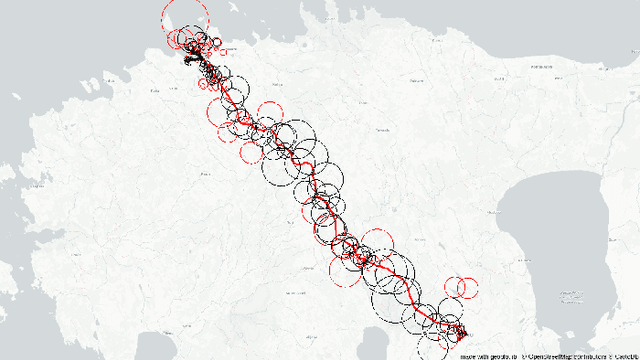
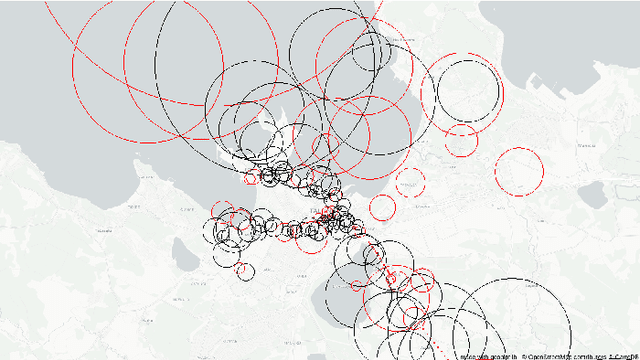
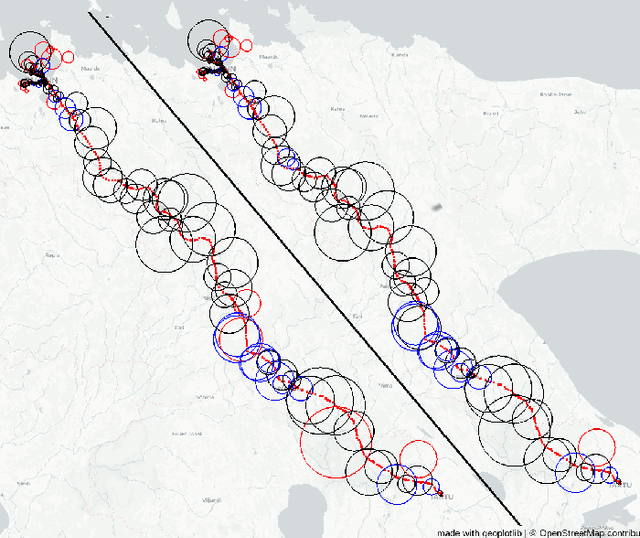
Call Detail Records (CDRs) coupled with the coverage area locations provide the operator with an incredible amount of information on its customers' whereabouts and movement. Due to the non-static and overlapping nature of the antenna coverage area there commonly exist situations where cellphones geographically close to each other can be connected to different antennas due to handover rule - the operator hands over a certain cellphone to another antenna to spread the load between antennas. Hence, this aspect introduces a ping-pong handover phenomena in the trajectories extracted from the CDR data which can be misleading in understanding the mobility pattern. To reconstruct accurate trajectories it is a must to reduce the number of those handovers appearing in the dataset. This letter presents a novel approach for filtering ping-pong handovers from CDR based trajectories. Primarily, the approach is based on anchors model utilizing different features and parameters extracted from the coverage areas and reconstructed trajectories mined from the CDR data. Using this methodology we can significantly reduce the ping-pong handover noise in the trajectories, which gives a more accurate reconstruction of the customers' movement pattern.
Deep Cross-modal Proxy Hashing
Nov 06, 2020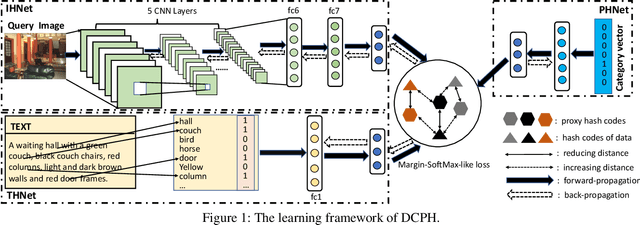
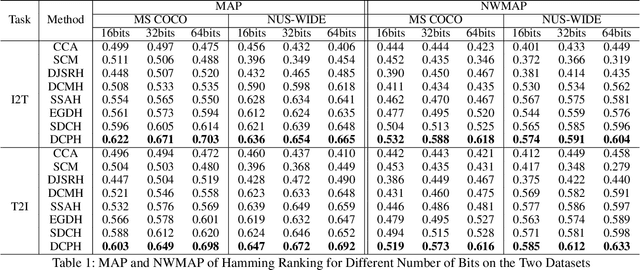
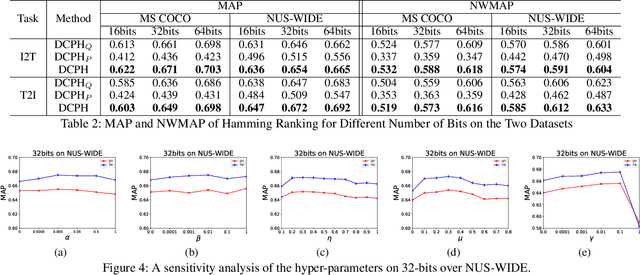
Due to their high retrieval efficiency and low storage cost for cross-modal search task, cross-modal hashing methods have attracted considerable attention. For supervised cross-modal hashing methods, how to make the learned hash codes preserve semantic structure information sufficiently is a key point to further enhance the retrieval performance. As far as we know, almost all supervised cross-modal hashing methods preserve semantic structure information depending on at-least-one similarity definition fully or partly, i.e., it defines two datapoints as similar ones if they share at least one common category otherwise they are dissimilar. Obviously, the at-least-one similarity misses abundant semantic structure information. To tackle this problem, in this paper, we propose a novel Deep Cross-modal Proxy Hashing, called DCPH. Specifically, DCPH first learns a proxy hashing network to generate a discriminative proxy hash code for each category. Then, by utilizing the learned proxy hash code as supervised information, a novel $Margin$-$SoftMax$-$like\ loss$ is proposed without defining the at-least-one similarity between datapoints. By minimizing the novel $Margin$-$SoftMax$-$like\ loss$, the learned hash codes will simultaneously preserve the cross-modal similarity and abundant semantic structure information well. Extensive experiments on two benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in cross-modal retrieval task.
Achieving Adversarial Robustness Requires An Active Teacher
Dec 14, 2020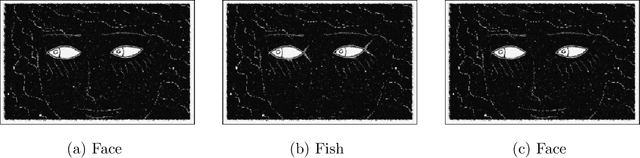
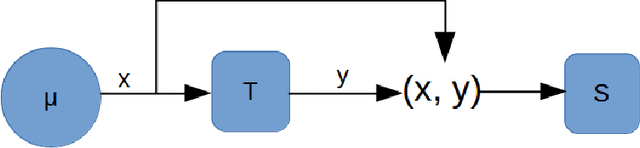
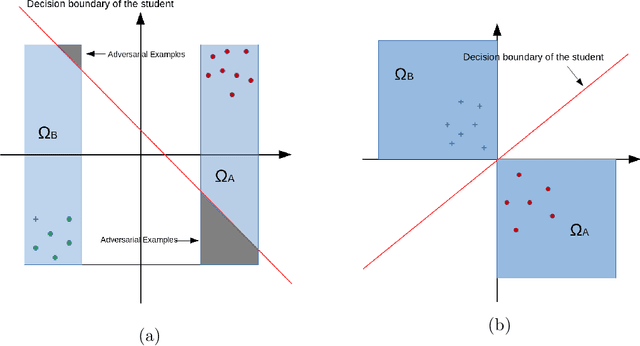
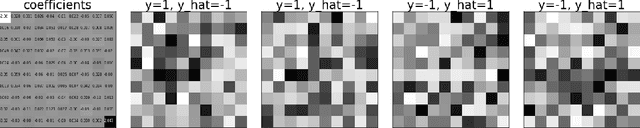
A new understanding of adversarial examples and adversarial robustness is proposed by decoupling the data generator and the label generator (which we call the teacher). In our framework, adversarial robustness is a conditional concept---the student model is not absolutely robust, but robust with respect to the teacher. Based on the new understanding, we claim that adversarial examples exist because the student cannot obtain sufficient information of the teacher from the training data. Various ways of achieving robustness is compared. Theoretical and numerical evidence shows that to efficiently attain robustness, a teacher that actively provides its information to the student may be necessary.
Risk & returns around FOMC press conferences: a novel perspective from computer vision
Jan 15, 2021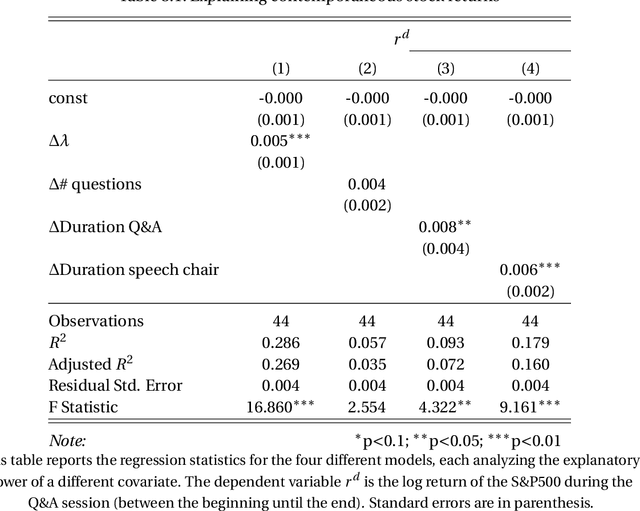
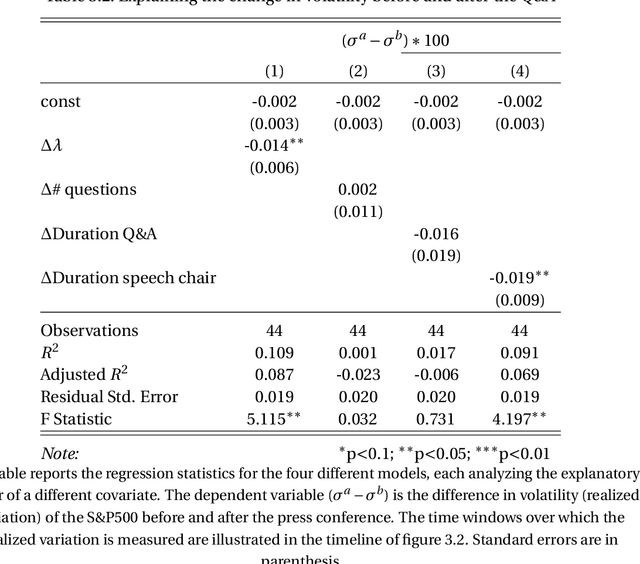

I propose a new tool to characterize the resolution of uncertainty around FOMC press conferences. It relies on the construction of a measure capturing the level of discussion complexity between the Fed Chair and reporters during the Q&A sessions. I show that complex discussions are associated with higher equity returns and a drop in realized volatility. The method creates an attention score by quantifying how much the Chair needs to rely on reading internal documents to be able to answer a question. This is accomplished by building a novel dataset of video images of the press conferences and leveraging recent deep learning algorithms from computer vision. This alternative data provides new information on nonverbal communication that cannot be extracted from the widely analyzed FOMC transcripts. This paper can be seen as a proof of concept that certain videos contain valuable information for the study of financial markets.
REMOD: Relation Extraction for Modeling Online Discourse
Feb 22, 2021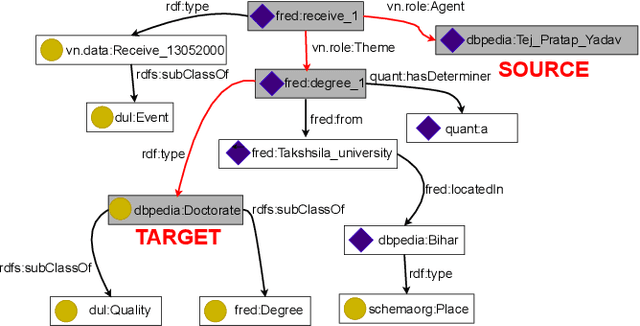
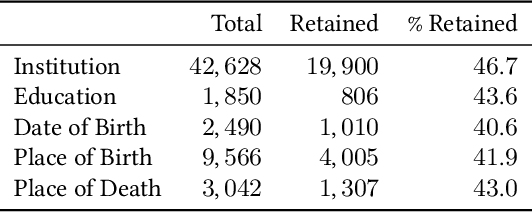
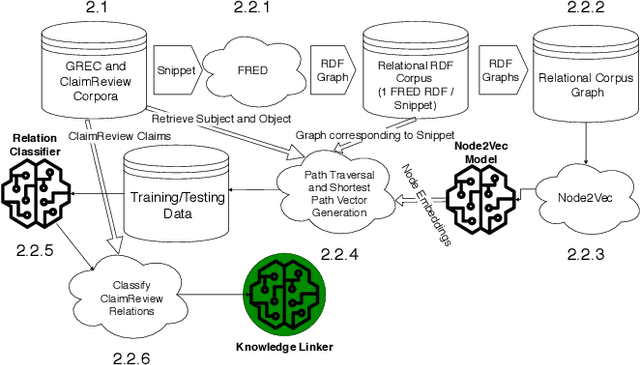

The enormous amount of discourse taking place online poses challenges to the functioning of a civil and informed public sphere. Efforts to standardize online discourse data, such as ClaimReview, are making available a wealth of new data about potentially inaccurate claims, reviewed by third-party fact-checkers. These data could help shed light on the nature of online discourse, the role of political elites in amplifying it, and its implications for the integrity of the online information ecosystem. Unfortunately, the semi-structured nature of much of this data presents significant challenges when it comes to modeling and reasoning about online discourse. A key challenge is relation extraction, which is the task of determining the semantic relationships between named entities in a claim. Here we develop a novel supervised learning method for relation extraction that combines graph embedding techniques with path traversal on semantic dependency graphs. Our approach is based on the intuitive observation that knowledge of the entities along the path between the subject and object of a triple (e.g. Washington,_D.C.}, and United_States_of_America) provides useful information that can be leveraged for extracting its semantic relation (i.e. capitalOf). As an example of a potential application of this technique for modeling online discourse, we show that our method can be integrated into a pipeline to reason about potential misinformation claims.
Synthetic Data -- A Privacy Mirage
Dec 11, 2020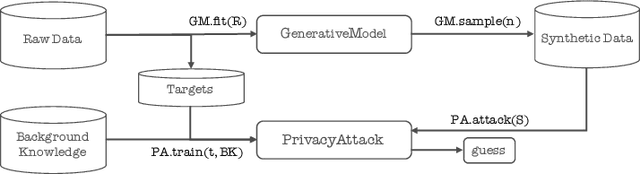
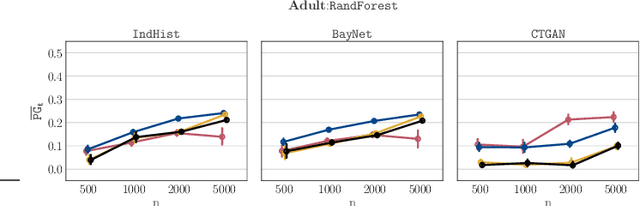
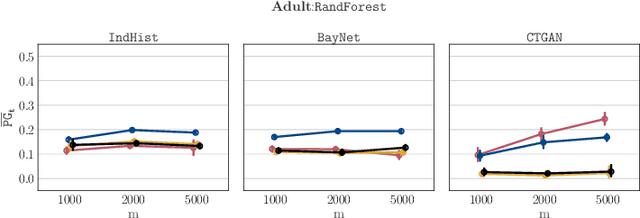
Synthetic datasets drawn from generative models have been advertised as a silver-bullet solution to privacy-preserving data publishing. In this work, we show through an extensive privacy evaluation that such claims do not match reality. First, synthetic data does not prevent attribute inference. Any data characteristics preserved by a generative model for the purpose of data analysis, can simultaneously be used by an adversary to reconstruct sensitive information about individuals. Second, synthetic data does not protect against linkage attacks. We demonstrate that high-dimensional synthetic datasets preserve much more information about the raw data than the features in the model's lower-dimensional approximation. This rich information can be exploited by an adversary even when models are trained under differential privacy. Moreover, we observe that some target records receive substantially less protection than others and that the more complex the generative model, the more difficult it is to predict which targets will remain vulnerable to inference attacks. Finally, we show why generative models are unlikely to ever become an appropriate solution to the problem of privacy-preserving data publishing.
Residual Enhanced Multi-Hypergraph Neural Network
May 02, 2021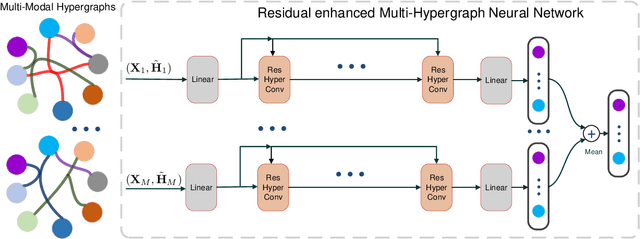

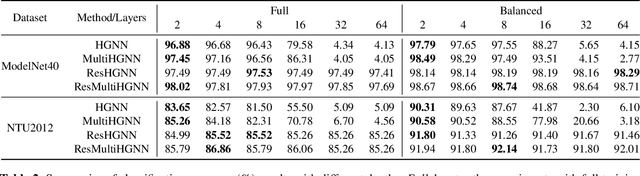
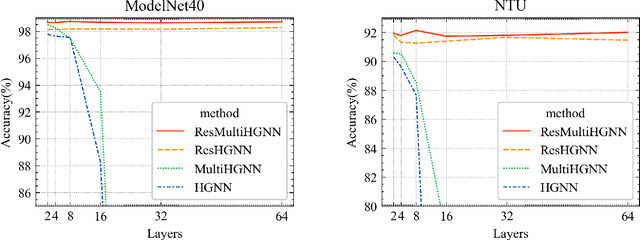
Hypergraphs are a generalized data structure of graphs to model higher-order correlations among entities, which have been successfully adopted into various research domains. Meanwhile, HyperGraph Neural Network (HGNN) is currently the de-facto method for hypergraph representation learning. However, HGNN aims at single hypergraph learning and uses a pre-concatenation approach when confronting multi-modal datasets, which leads to sub-optimal exploitation of the inter-correlations of multi-modal hypergraphs. HGNN also suffers the over-smoothing issue, that is, its performance drops significantly when layers are stacked up. To resolve these issues, we propose the Residual enhanced Multi-Hypergraph Neural Network, which can not only fuse multi-modal information from each hypergraph effectively, but also circumvent the over-smoothing issue associated with HGNN. We conduct experiments on two 3D benchmarks, the NTU and the ModelNet40 datasets, and compare against multiple state-of-the-art methods. Experimental results demonstrate that both the residual hypergraph convolutions and the multi-fusion architecture can improve the performance of the base model and the combined model achieves a new state-of-the-art. Code is available at \url{https://github.com/OneForward/ResMHGNN}.