 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SAFEval: Summarization Asks for Fact-based Evaluation
Mar 23, 2021
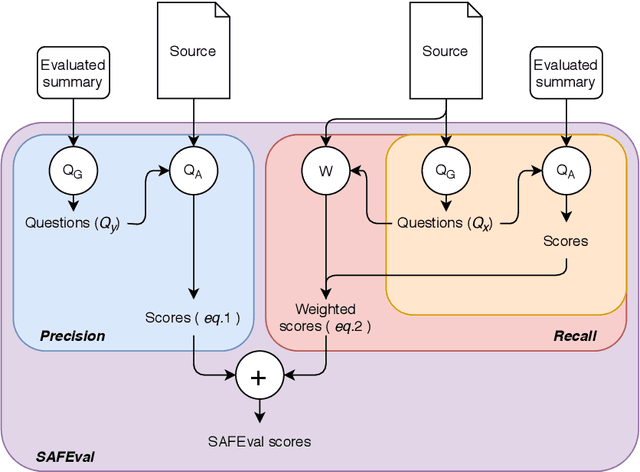
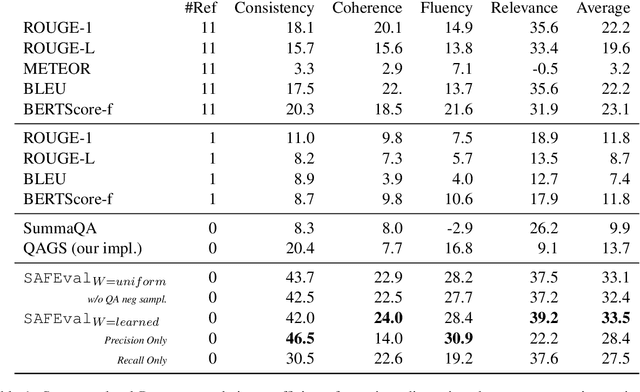

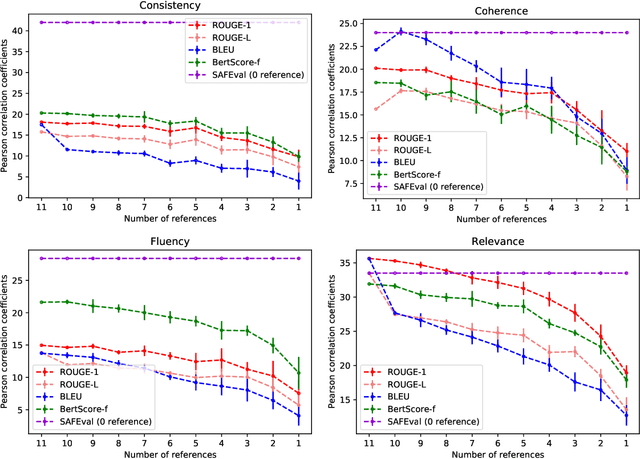
Summarization evaluation remains an open research problem: current metrics such as ROUGE are known to be limited and to correlate poorly with human judgments. To alleviate this issue, recent work has proposed evaluation metrics which rely on question answering models to assess whether a summary contains all the relevant information in its source document. Though promising, the proposed approaches have so far failed to correlate better than ROUGE with human judgments. In this paper, we extend previous approaches and propose a unified framework, named SAFEval. In contrast to established metrics such as ROUGE or BERTScore, SAFEval does not require any ground-truth reference. Nonetheless, SAFEval substantially improves the correlation with human judgments over four evaluation dimensions (consistency, coherence, fluency, and relevance), as shown in the extensive experiments we report.
Single Image Super-Resolution with Dilated Convolution based Multi-Scale Information Learning Inception Module
Jul 22, 2017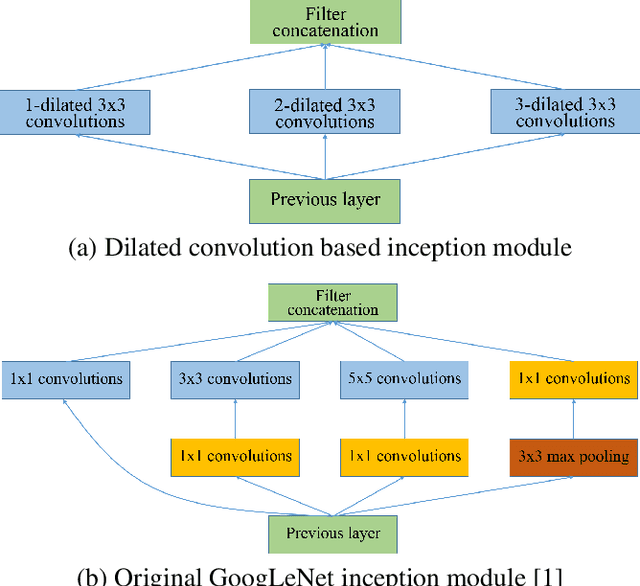
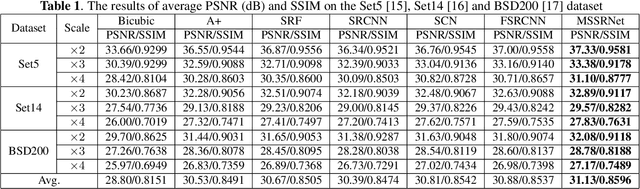
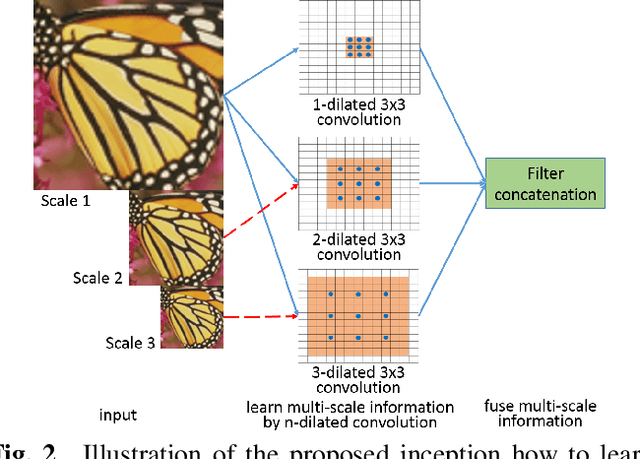

Traditional works have shown that patches in a natural image tend to redundantly recur many times inside the image, both within the same scale, as well as across different scales. Make full use of these multi-scale information can improve the image restoration performance. However, the current proposed deep learning based restoration methods do not take the multi-scale information into account. In this paper, we propose a dilated convolution based inception module to learn multi-scale information and design a deep network for single image super-resolution. Different dilated convolution learns different scale feature, then the inception module concatenates all these features to fuse multi-scale information. In order to increase the reception field of our network to catch more contextual information, we cascade multiple inception modules to constitute a deep network to conduct single image super-resolution. With the novel dilated convolution based inception module, the proposed end-to-end single image super-resolution network can take advantage of multi-scale information to improve image super-resolution performance. Experimental results show that our proposed method outperforms many state-of-the-art single image super-resolution methods.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021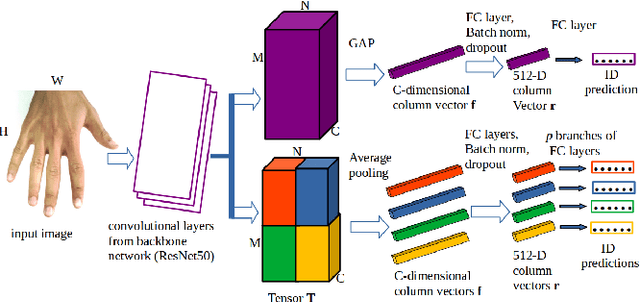

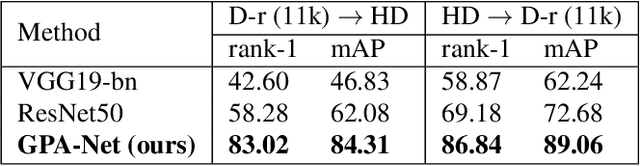

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.
Fixpoint Approximation of Strategic Abilities under Imperfect Information
Mar 13, 2017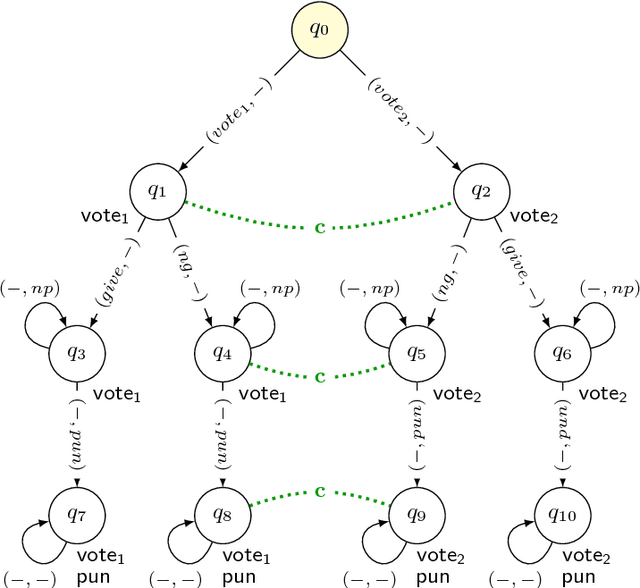
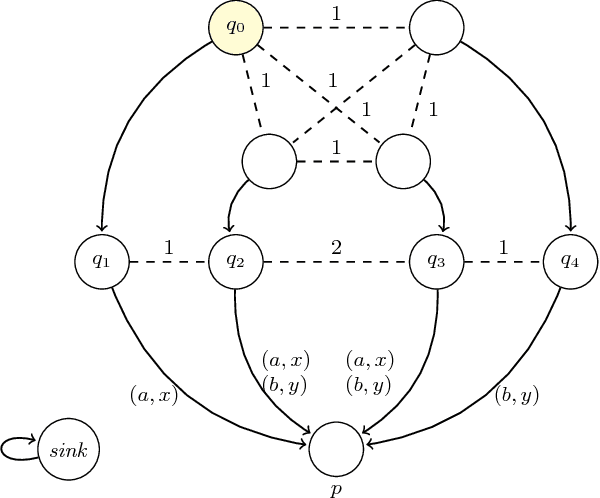
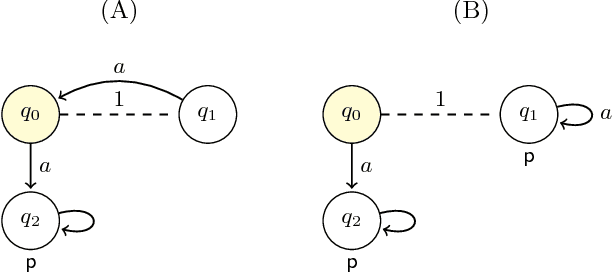
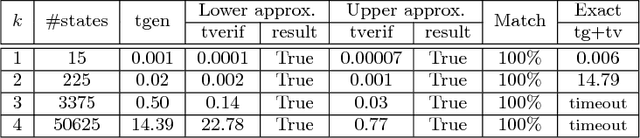
Model checking of strategic ability under imperfect information is known to be hard. The complexity results range from NP-completeness to undecidability, depending on the precise setup of the problem. No less importantly, fixpoint equivalences do not generally hold for imperfect information strategies, which seriously hampers incremental synthesis of winning strategies. In this paper, we propose translations of ATLir formulae that provide lower and upper bounds for their truth values, and are cheaper to verify than the original specifications. That is, if the expression is verified as true then the corresponding formula of ATLir should also hold in the given model. We begin by showing where the straightforward approach does not work. Then, we propose how it can be modified to obtain guaranteed lower bounds. To this end, we alter the next-step operator in such a way that traversing one's indistinguishability relation is seen as atomic activity. Most interestingly, the lower approximation is provided by a fixpoint expression that uses a nonstandard variant of the next-step ability operator. We show the correctness of the translations, establish their computational complexity, and validate the approach by experiments with a scalable scenario of Bridge play.
Local Memory Attention for Fast Video Semantic Segmentation
Jan 05, 2021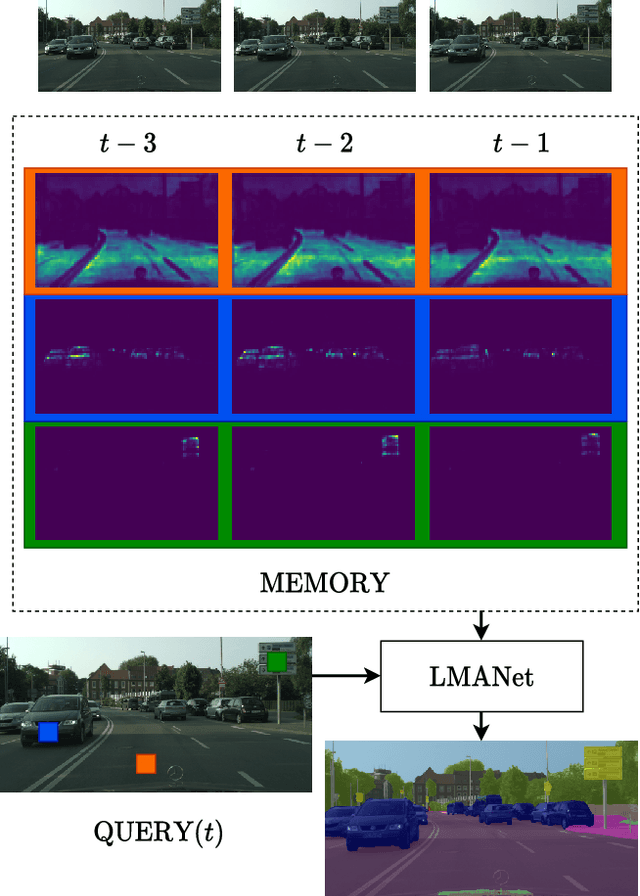
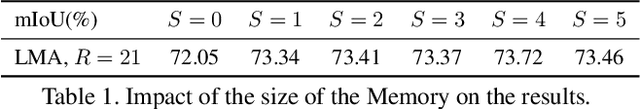
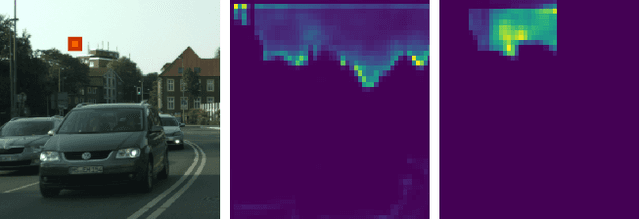

We propose a novel neural network module that transforms an existing single-frame semantic segmentation model into a video semantic segmentation pipeline. In contrast to prior works, we strive towards a simple and general module that can be integrated into virtually any single-frame architecture. Our approach aggregates a rich representation of the semantic information in past frames into a memory module. Information stored in the memory is then accessed through an attention mechanism. This provides temporal appearance cues from prior frames, which are then fused with an encoding of the current frame through a second attention-based module. The segmentation decoder processes the fused representation to predict the final semantic segmentation. We integrate our approach into two popular semantic segmentation networks: ERFNet and PSPNet. We observe an improvement in segmentation performance on Cityscapes by 1.7% and 2.1% in mIoU respectively, while increasing inference time of ERFNet by only 1.5ms.
Concentration Inequalities for Two-Sample Rank Processes with Application to Bipartite Ranking
Apr 07, 2021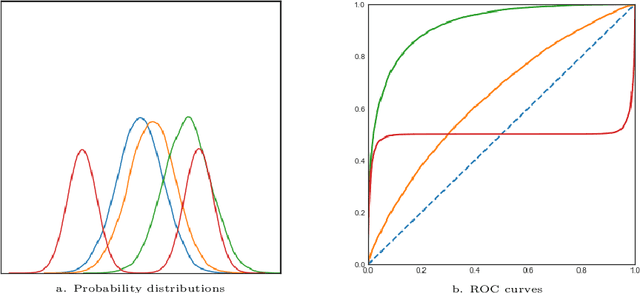
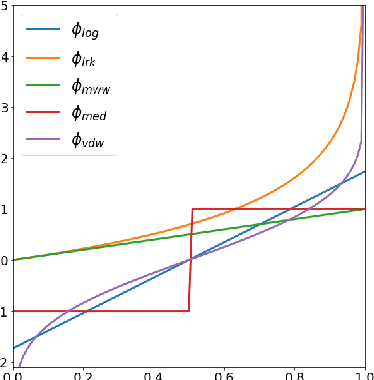
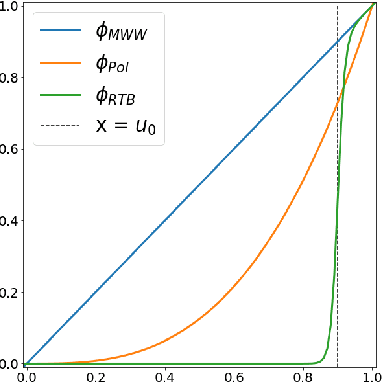
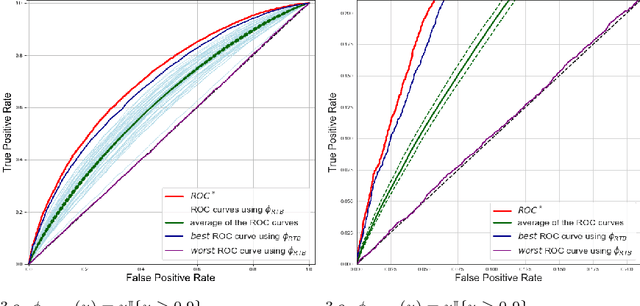
The ROC curve is the gold standard for measuring the performance of a test/scoring statistic regarding its capacity to discriminate between two statistical populations in a wide variety of applications, ranging from anomaly detection in signal processing to information retrieval, through medical diagnosis. Most practical performance measures used in scoring/ranking applications such as the AUC, the local AUC, the p-norm push, the DCG and others, can be viewed as summaries of the ROC curve. In this paper, the fact that most of these empirical criteria can be expressed as two-sample linear rank statistics is highlighted and concentration inequalities for collections of such random variables, referred to as two-sample rank processes here, are proved, when indexed by VC classes of scoring functions. Based on these nonasymptotic bounds, the generalization capacity of empirical maximizers of a wide class of ranking performance criteria is next investigated from a theoretical perspective. It is also supported by empirical evidence through convincing numerical experiments.
Effect of depth order on iterative nested named entity recognition models
Apr 02, 2021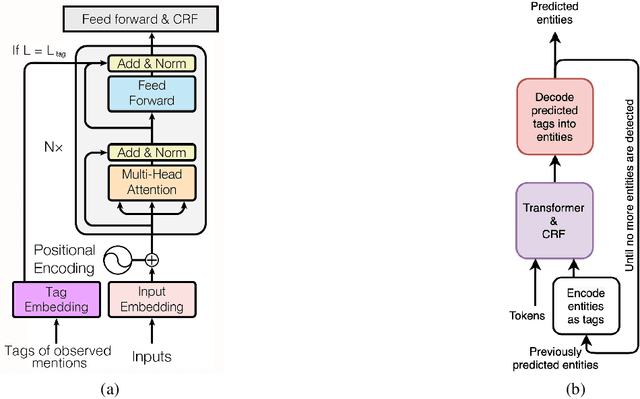
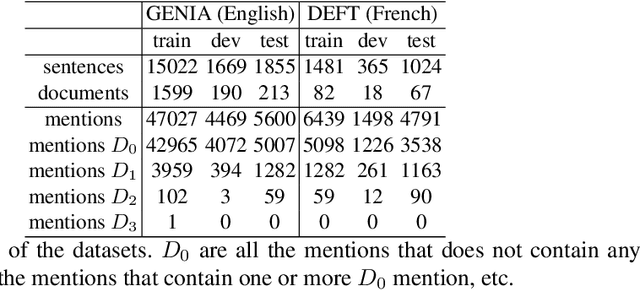
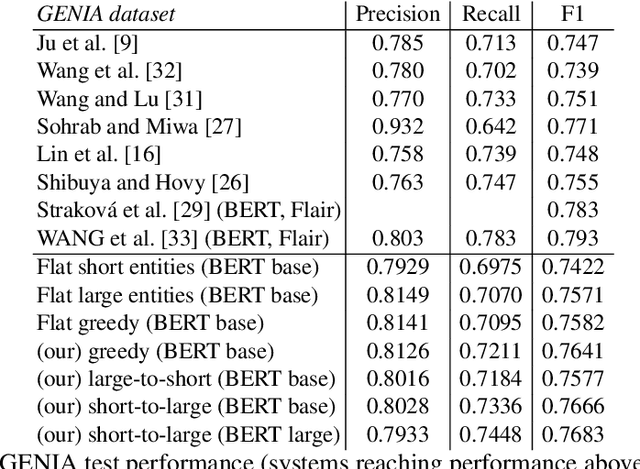
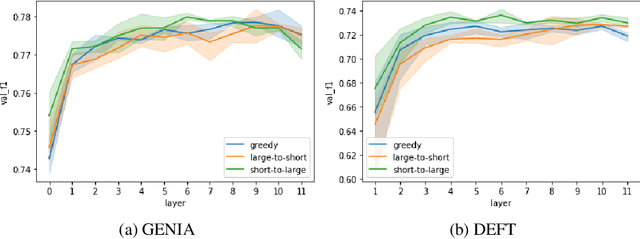
This paper studies the effect of the order of depth of mention on nested named entity recognition (NER) models. NER is an essential task in the extraction of biomedical information, and nested entities are common since medical concepts can assemble to form larger entities. Conventional NER systems only predict disjointed entities. Thus, iterative models for nested NER use multiple predictions to enumerate all entities, imposing a predefined order from largest to smallest or smallest to largest. We design an order-agnostic iterative model and a procedure to choose a custom order during training and prediction. To accommodate for this task, we propose a modification of the Transformer architecture to take into account the entities predicted in the previous steps. We provide a set of experiments to study the model's capabilities and the effects of the order on performance. Finally, we show that the smallest to largest order gives the best results.
AXM-Net: Cross-Modal Context Sharing Attention Network for Person Re-ID
Jan 19, 2021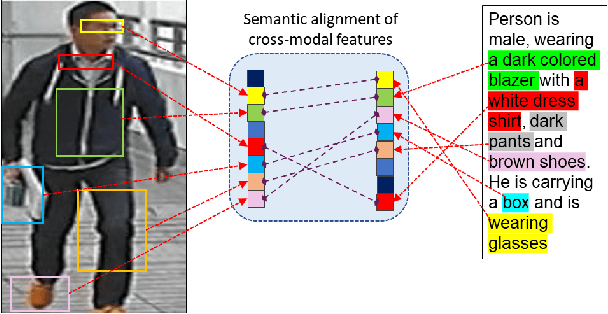
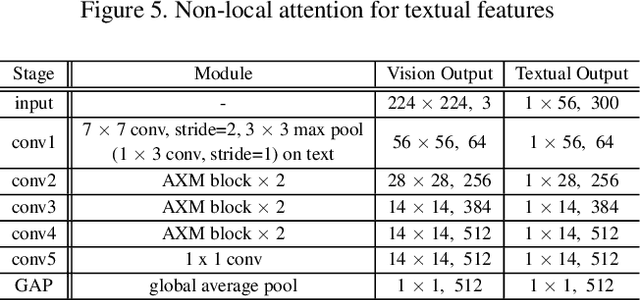
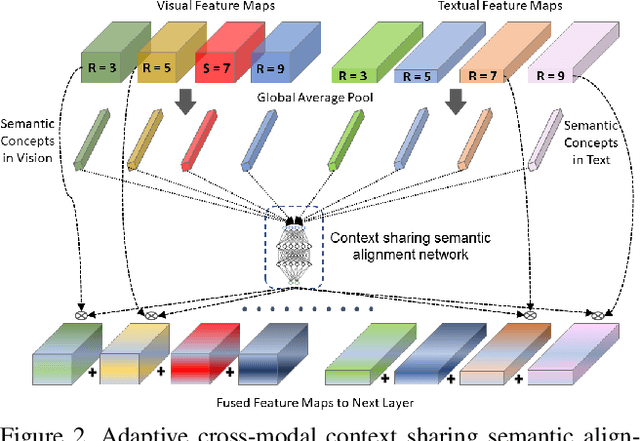
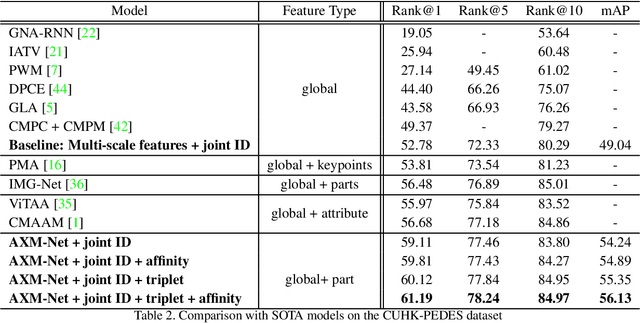
Cross-modal person re-identification (Re-ID) is critical for modern video surveillance systems. The key challenge is to align inter-modality representations according to semantic information present for a person and ignore background information. In this work, we present AXM-Net, a novel CNN based architecture designed for learning semantically aligned visual and textual representations. The underlying building block consists of multiple streams of feature maps coming from visual and textual modalities and a novel learnable context sharing semantic alignment network. We also propose complementary intra modal attention learning mechanisms to focus on more fine-grained local details in the features along with a cross-modal affinity loss for robust feature matching. Our design is unique in its ability to implicitly learn feature alignments from data. The entire AXM-Net can be trained in an end-to-end manner. We report results on both person search and cross-modal Re-ID tasks. Extensive experimentation validates the proposed framework and demonstrates its superiority by outperforming the current state-of-the-art methods by a significant margin.
Generating Ten BCI Commands Using Four Simple Motor Imageries
May 30, 2021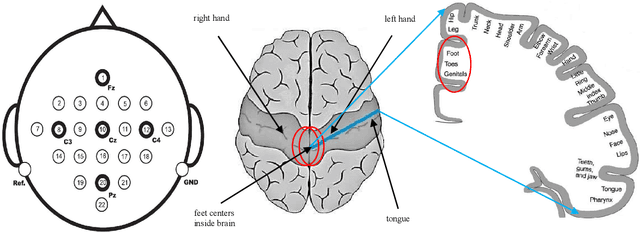
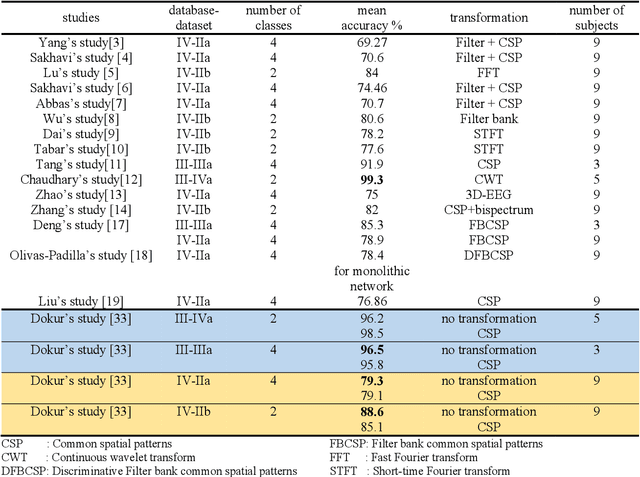
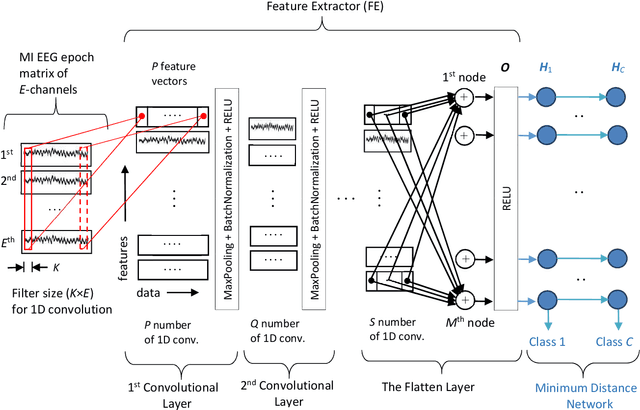
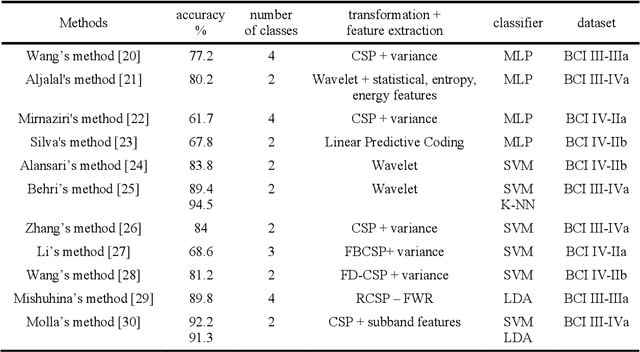
The brain computer interface (BCI) systems are utilized for transferring information among humans and computers by analyzing electroencephalogram (EEG) recordings.The process of mentally previewing a motor movement without generating the corporal output can be described as motor imagery (MI).In this emerging research field, the number of commands is also limited in relation to the number of MI tasks; in the current literature, mostly two or four commands (classes) are studied. As a solution to this problem, it is recommended to use mental tasks as well as MI tasks. Unfortunately, the use of this approach reduces the classification performance of MI EEG signals. The fMRI analyses show that the resources in the brain associated with the motor imagery can be activated independently. It is assumed that the brain activity induced by the MI of the combination of body parts corresponds to the superposition of the activities generated during each body parts's simple MI. In this study, in order to create more than four BCI commands, we suggest to generate combined MI EEG signals artificially by using left hand, right hand, tongue, and feet motor imageries in pairs. A maximum of ten different BCI commands can be generated by using four motor imageries in pairs.This study aims to achieve high classification performances for BCI commands produced from four motor imageries by implementing a small-sized deep neural network (DNN).The presented method is evaluated on the four-class datasets of BCI Competitions III and IV, and an average classification performance of 81.8% is achieved for ten classes. The above assumption is also validated on a different dataset which consists of simple and combined MI EEG signals acquired in real time. Trained with the artificially generated combined MI EEG signals, DivFE resulted in an average of 76.5% success rate for the combined MI EEG signals acquired in real-time.
A Framework for Unsupervised Classificiation and Data Mining of Tweets about Cyber Vulnerabilities
Apr 23, 2021


Many cyber network defense tools rely on the National Vulnerability Database (NVD) to provide timely information on known vulnerabilities that exist within systems on a given network. However, recent studies have indicated that the NVD is not always up to date, with known vulnerabilities being discussed publicly on social media platforms, like Twitter and Reddit, months before they are published to the NVD. To that end, we present a framework for unsupervised classification to filter tweets for relevance to cyber security. We consider and evaluate two unsupervised machine learning techniques for inclusion in our framework, and show that zero-shot classification using a Bidirectional and Auto-Regressive Transformers (BART) model outperforms the other technique with 83.52% accuracy and a F1 score of 83.88, allowing for accurate filtering of tweets without human intervention or labelled data for training. Additionally, we discuss different insights that can be derived from these cyber-relevant tweets, such as trending topics of tweets and the counts of Twitter mentions for Common Vulnerabilities and Exposures (CVEs), that can be used in an alert or report to augment current NVD-based risk assessment tools.