 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accurate Learning of Graph Representations with Graph Multiset Pooling
Feb 23, 2021
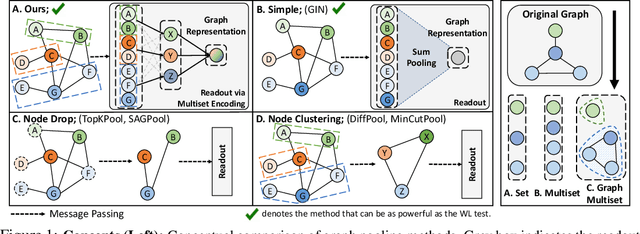
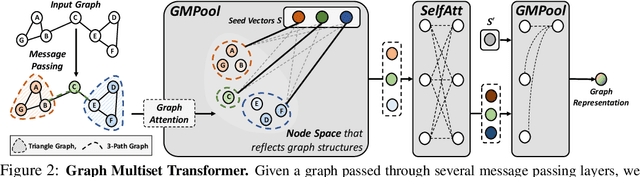
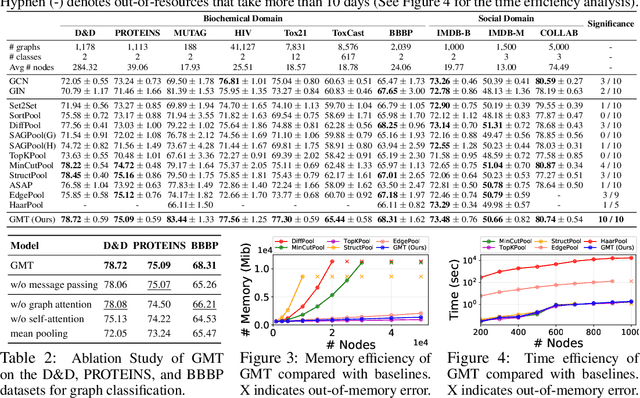
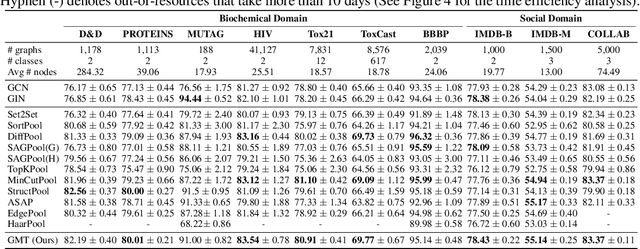
Graph neural networks have been widely used on modeling graph data, achieving impressive results on node classification and link prediction tasks. Yet, obtaining an accurate representation for a graph further requires a pooling function that maps a set of node representations into a compact form. A simple sum or average over all node representations considers all node features equally without consideration of their task relevance, and any structural dependencies among them. Recently proposed hierarchical graph pooling methods, on the other hand, may yield the same representation for two different graphs that are distinguished by the Weisfeiler-Lehman test, as they suboptimally preserve information from the node features. To tackle these limitations of existing graph pooling methods, we first formulate the graph pooling problem as a multiset encoding problem with auxiliary information about the graph structure, and propose a Graph Multiset Transformer (GMT) which is a multi-head attention based global pooling layer that captures the interaction between nodes according to their structural dependencies. We show that GMT satisfies both injectiveness and permutation invariance, such that it is at most as powerful as the Weisfeiler-Lehman graph isomorphism test. Moreover, our methods can be easily extended to the previous node clustering approaches for hierarchical graph pooling. Our experimental results show that GMT significantly outperforms state-of-the-art graph pooling methods on graph classification benchmarks with high memory and time efficiency, and obtains even larger performance gain on graph reconstruction and generation tasks.
R2D2: Relational Text Decoding with Transformers
May 10, 2021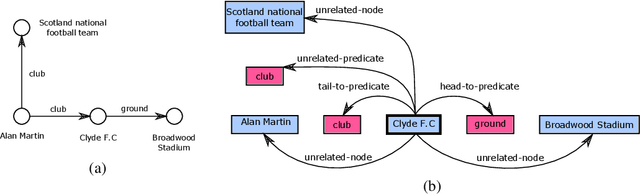
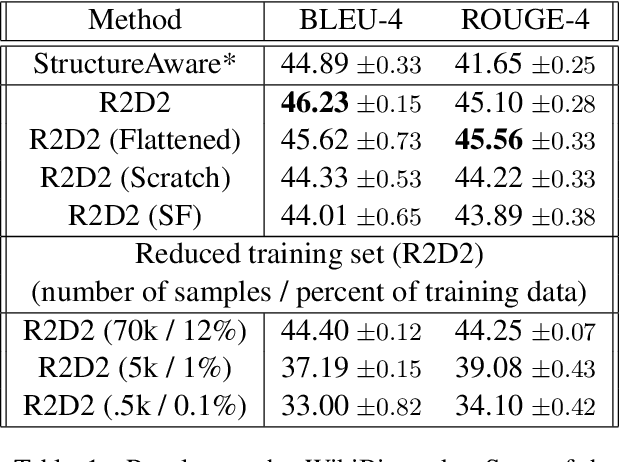
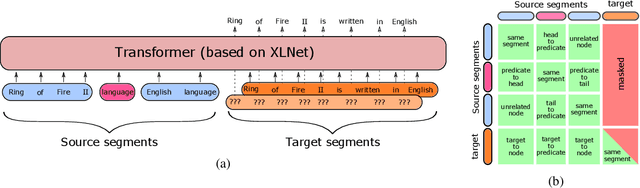
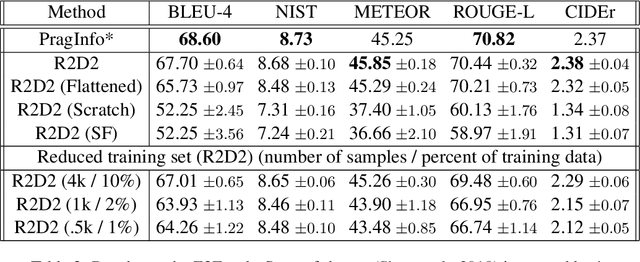
We propose a novel framework for modeling the interaction between graphical structures and the natural language text associated with their nodes and edges. Existing approaches typically fall into two categories. On group ignores the relational structure by converting them into linear sequences and then utilize the highly successful Seq2Seq models. The other side ignores the sequential nature of the text by representing them as fixed-dimensional vectors and apply graph neural networks. Both simplifications lead to information loss. Our proposed method utilizes both the graphical structure as well as the sequential nature of the texts. The input to our model is a set of text segments associated with the nodes and edges of the graph, which are then processed with a transformer encoder-decoder model, equipped with a self-attention mechanism that is aware of the graphical relations between the nodes containing the segments. This also allows us to use BERT-like models that are already trained on large amounts of text. While the proposed model has wide applications, we demonstrate its capabilities on data-to-text generation tasks. Our approach compares favorably against state-of-the-art methods in four tasks without tailoring the model architecture. We also provide an early demonstration in a novel practical application -- generating clinical notes from the medical entities mentioned during clinical visits.
Path-based vs. Distributional Information in Recognizing Lexical Semantic Relations
Nov 02, 2016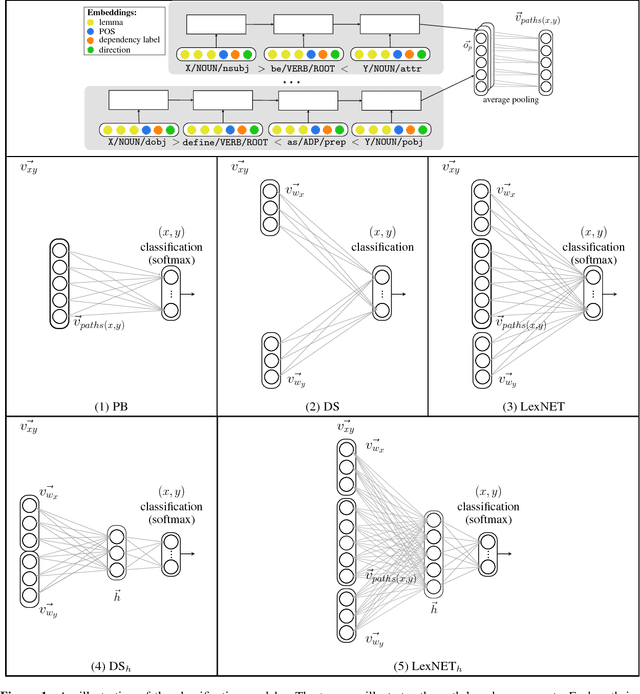


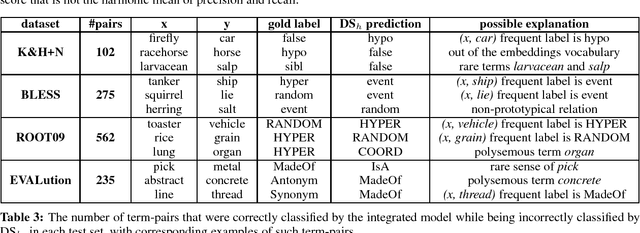
Recognizing various semantic relations between terms is beneficial for many NLP tasks. While path-based and distributional information sources are considered complementary for this task, the superior results the latter showed recently suggested that the former's contribution might have become obsolete. We follow the recent success of an integrated neural method for hypernymy detection (Shwartz et al., 2016) and extend it to recognize multiple relations. The empirical results show that this method is effective in the multiclass setting as well. We further show that the path-based information source always contributes to the classification, and analyze the cases in which it mostly complements the distributional information.
Weighted Least Squares Twin Support Vector Machine with Fuzzy Rough Set Theory for Imbalanced Data Classification
May 03, 2021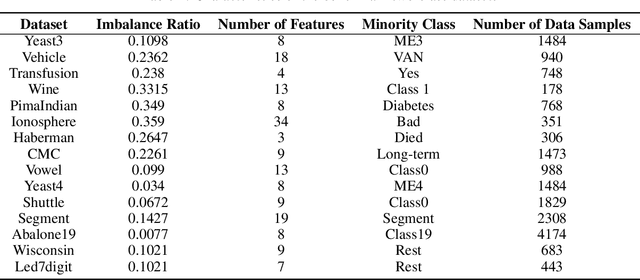
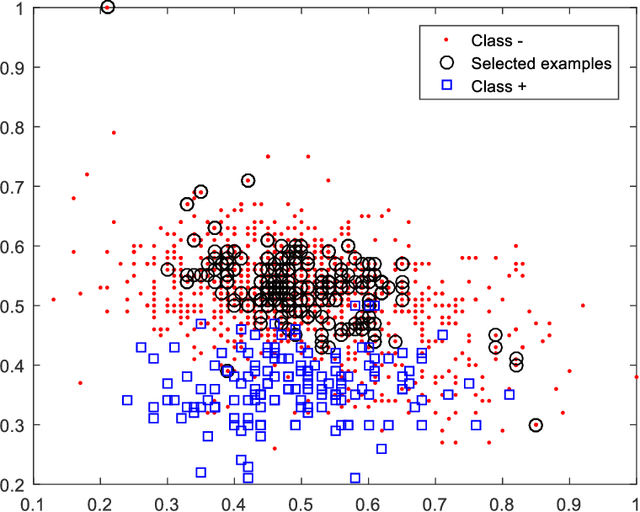

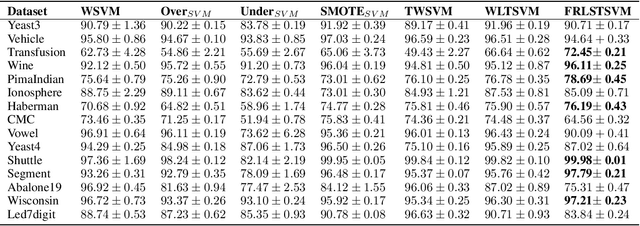
Support vector machines (SVMs) are powerful supervised learning tools developed to solve classification problems. However, SVMs are likely to perform poorly in the classification of imbalanced data. The rough set theory presents a mathematical tool for inference in nondeterministic cases that provides methods for removing irrelevant information from data. In this work, we propose an approach that efficiently used fuzzy rough set theory in weighted least squares twin support vector machine called FRLSTSVM for classification of imbalanced data. The first innovation is introducing a new fuzzy rough set based under-sampling strategy to make the classifier robust in terms of imbalanced data. For constructing the two proximal hyperplanes in FRLSTSVM, data points from the minority class remain unchanged while a subset of data points in the majority class are selected using a new method. In this model, we embedded the weight biases in the LSTSVM formulations to overcome the bias phenomenon in the original twin SVM for the classification of imbalanced data. In order to determine these weights in this formulation, we introduced a new strategy that uses fuzzy rough set theory as the second innovation. Experimental results on famous imbalanced datasets, compared with related traditional SVM-based methods, demonstrate the superiority of our proposed FRLSTSVM model in imbalanced data classification.
Graph Attention Tracking
Nov 23, 2020

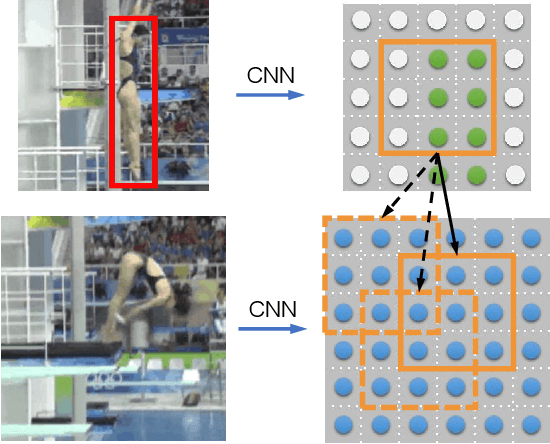
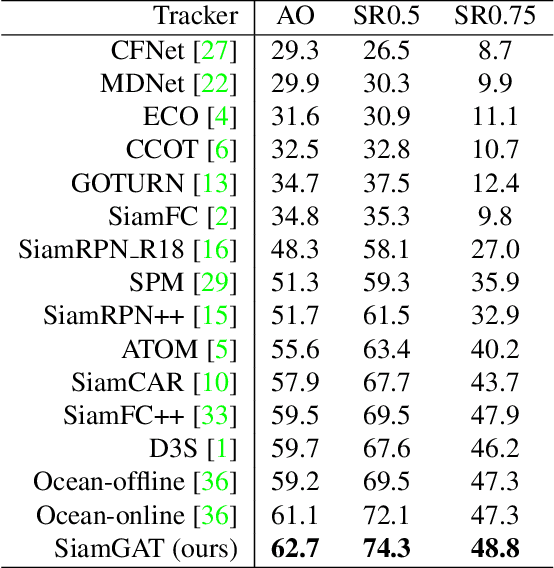
Siamese network based trackers formulate the visual tracking task as a similarity matching problem. Almost all popular Siamese trackers realize the similarity learning via convolutional feature cross-correlation between a target branch and a search branch. However, since the size of target feature region needs to be pre-fixed, these cross-correlation base methods suffer from either reserving much adverse background information or missing a great deal of foreground information. Moreover, the global matching between the target and search region also largely neglects the target structure and part-level information. In this paper, to solve the above issues, we propose a simple target-aware Siamese graph attention network for general object tracking. We propose to establish part-to-part correspondence between the target and the search region with a complete bipartite graph, and apply the graph attention mechanism to propagate target information from the template feature to the search feature. Further, instead of using the pre-fixed region cropping for template-feature-area selection, we investigate a target-aware area selection mechanism to fit the size and aspect ratio variations of different objects. Experiments on challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance. Code is available at: https://git.io/SiamGAT
geoGAT: Graph Model Based on Attention Mechanism for Geographic Text Classification
Jan 13, 2021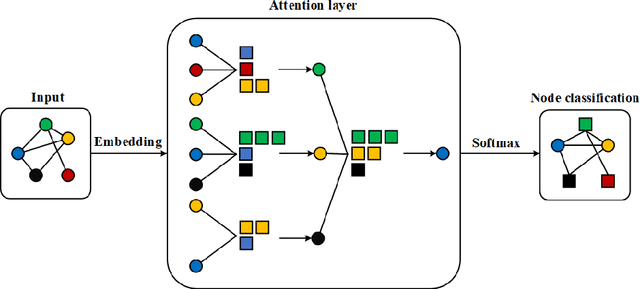

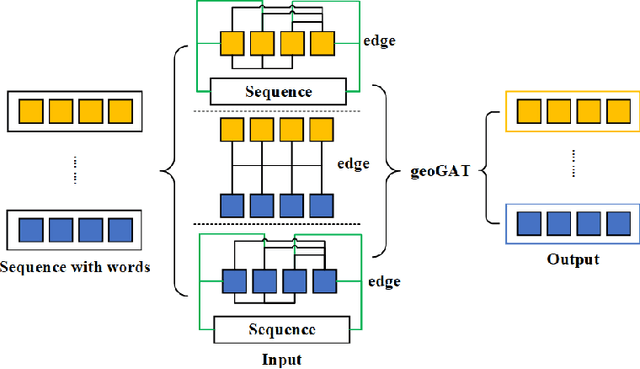
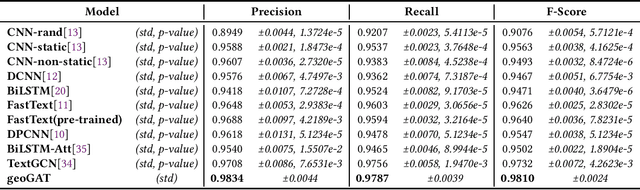
In the area of geographic information processing. There are few researches on geographic text classification. However, the application of this task in Chinese is relatively rare. In our work, we intend to implement a method to extract text containing geographical entities from a large number of network text. The geographic information in these texts is of great practical significance to transportation, urban and rural planning, disaster relief and other fields. We use the method of graph convolutional neural network with attention mechanism to achieve this function. Graph attention networks is an improvement of graph convolutional neural networks. Compared with GCN, the advantage of GAT is that the attention mechanism is proposed to weight the sum of the characteristics of adjacent nodes. In addition, We construct a Chinese dataset containing geographical classification from multiple datasets of Chinese text classification. The Macro-F Score of the geoGAT we used reached 95\% on the new Chinese dataset.
Learning Discrete Representations via Information Maximizing Self-Augmented Training
Jun 14, 2017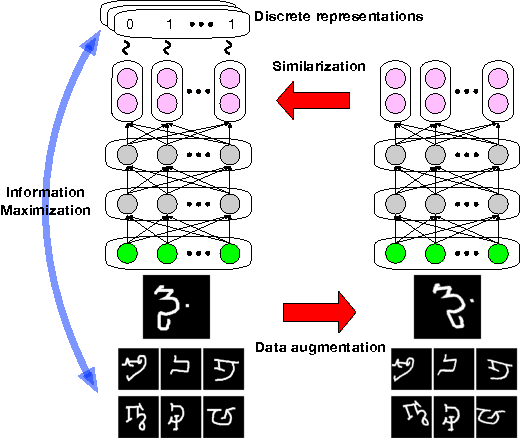
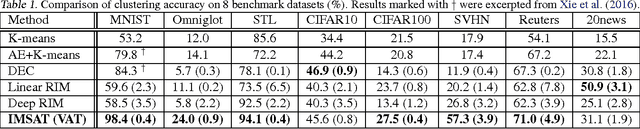


Learning discrete representations of data is a central machine learning task because of the compactness of the representations and ease of interpretation. The task includes clustering and hash learning as special cases. Deep neural networks are promising to be used because they can model the non-linearity of data and scale to large datasets. However, their model complexity is huge, and therefore, we need to carefully regularize the networks in order to learn useful representations that exhibit intended invariance for applications of interest. To this end, we propose a method called Information Maximizing Self-Augmented Training (IMSAT). In IMSAT, we use data augmentation to impose the invariance on discrete representations. More specifically, we encourage the predicted representations of augmented data points to be close to those of the original data points in an end-to-end fashion. At the same time, we maximize the information-theoretic dependency between data and their predicted discrete representations. Extensive experiments on benchmark datasets show that IMSAT produces state-of-the-art results for both clustering and unsupervised hash learning.
Flexible Operations for Natural Language Deduction
Apr 18, 2021
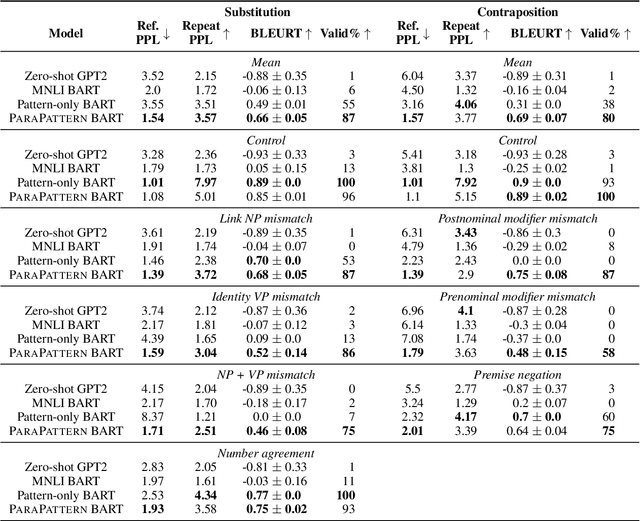
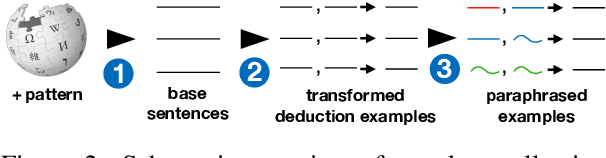
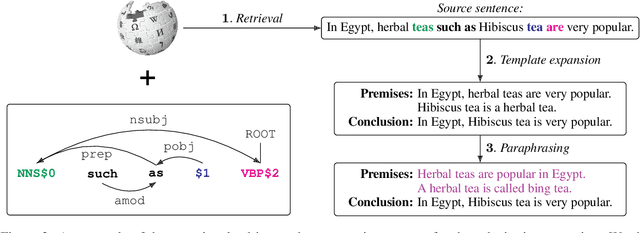
An interpretable system for complex, open-domain reasoning needs an interpretable meaning representation. Natural language is an excellent candidate -- it is both extremely expressive and easy for humans to understand. However, manipulating natural language statements in logically consistent ways is hard. Models have to be precise, yet robust enough to handle variation in how information is expressed. In this paper, we describe ParaPattern, a method for building models to generate logical transformations of diverse natural language inputs without direct human supervision. We use a BART-based model (Lewis et al., 2020) to generate the result of applying a particular logical operation to one or more premise statements. Crucially, we have a largely automated pipeline for scraping and constructing suitable training examples from Wikipedia, which are then paraphrased to give our models the ability to handle lexical variation. We evaluate our models using targeted contrast sets as well as out-of-domain sentence compositions from the QASC dataset (Khot et al., 2020). Our results demonstrate that our operation models are both accurate and flexible.
Response to NITRD, NCO, NSF Request for Information on "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan"
Nov 05, 2019We present a response to the 2018 Request for Information (RFI) from the NITRD, NCO, NSF regarding the "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan." Through this document, we provide a response to the question of whether and how the National Artificial Intelligence Research and Development Strategic Plan (NAIRDSP) should be updated from the perspective of Fermilab, America's premier national laboratory for High Energy Physics (HEP). We believe the NAIRDSP should be extended in light of the rapid pace of development and innovation in the field of Artificial Intelligence (AI) since 2016, and present our recommendations below. AI has profoundly impacted many areas of human life, promising to dramatically reshape society --- e.g., economy, education, science --- in the coming years. We are still early in this process. It is critical to invest now in this technology to ensure it is safe and deployed ethically. Science and society both have a strong need for accuracy, efficiency, transparency, and accountability in algorithms, making investments in scientific AI particularly valuable. Thus far the US has been a leader in AI technologies, and we believe as a national Laboratory it is crucial to help maintain and extend this leadership. Moreover, investments in AI will be important for maintaining US leadership in the physical sciences.
MonoGRNet: A General Framework for Monocular 3D Object Detection
Apr 18, 2021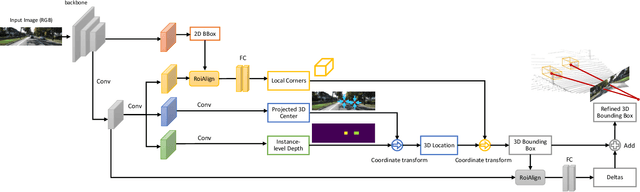
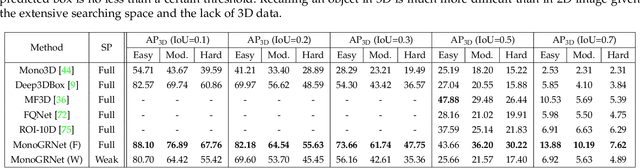
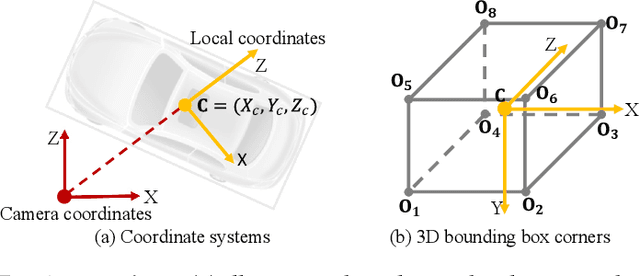
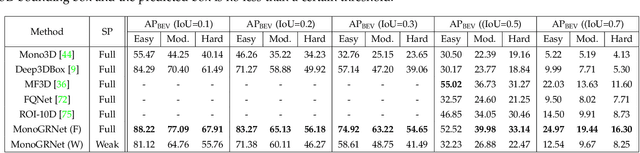
Detecting and localizing objects in the real 3D space, which plays a crucial role in scene understanding, is particularly challenging given only a monocular image due to the geometric information loss during imagery projection. We propose MonoGRNet for the amodal 3D object detection from a monocular image via geometric reasoning in both the observed 2D projection and the unobserved depth dimension. MonoGRNet decomposes the monocular 3D object detection task into four sub-tasks including 2D object detection, instance-level depth estimation, projected 3D center estimation and local corner regression. The task decomposition significantly facilitates the monocular 3D object detection, allowing the target 3D bounding boxes to be efficiently predicted in a single forward pass, without using object proposals, post-processing or the computationally expensive pixel-level depth estimation utilized by previous methods. In addition, MonoGRNet flexibly adapts to both fully and weakly supervised learning, which improves the feasibility of our framework in diverse settings. Experiments are conducted on KITTI, Cityscapes and MS COCO datasets. Results demonstrate the promising performance of our framework in various scenarios.