 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KLUE: Korean Language Understanding Evaluation
May 21, 2021
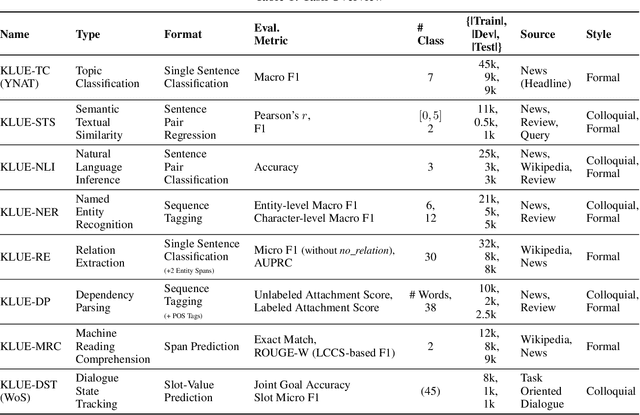
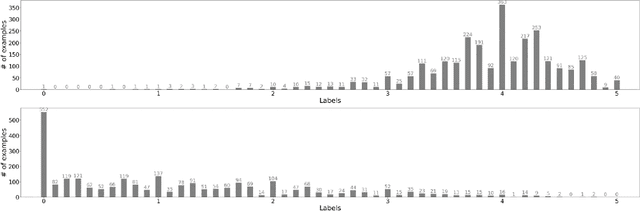
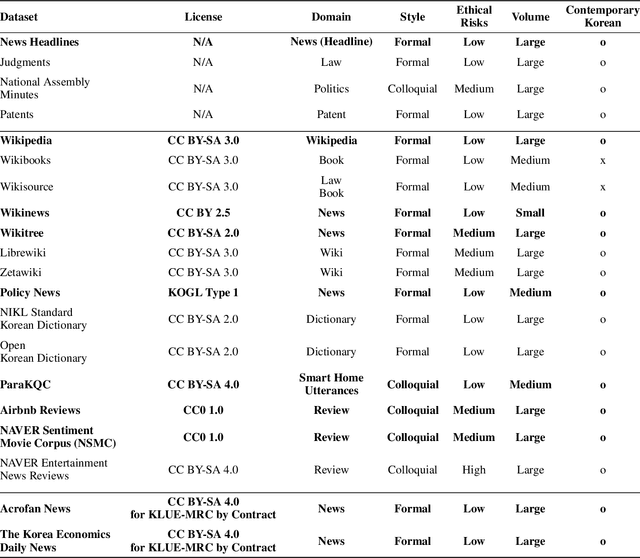
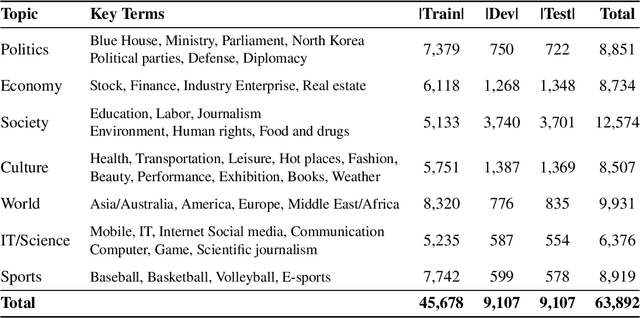
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at <a class="link-external link-https" href="https://klue-benchmark.com/">this URL</a>.
Relational Learning and Feature Extraction by Querying over Heterogeneous Information Networks
Jul 25, 2017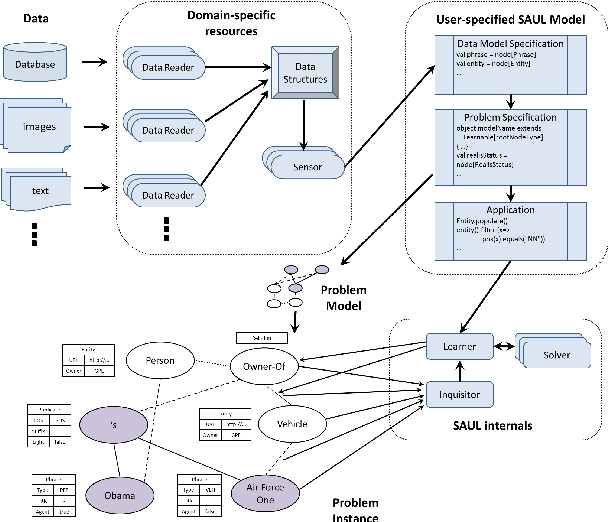
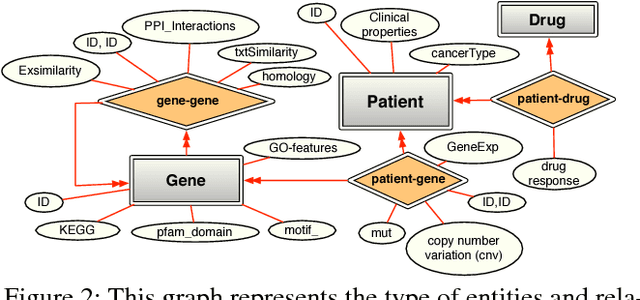
Many real world systems need to operate on heterogeneous information networks that consist of numerous interacting components of different types. Examples include systems that perform data analysis on biological information networks; social networks; and information extraction systems processing unstructured data to convert raw text to knowledge graphs. Many previous works describe specialized approaches to perform specific types of analysis, mining and learning on such networks. In this work, we propose a unified framework consisting of a data model -a graph with a first order schema along with a declarative language for constructing, querying and manipulating such networks in ways that facilitate relational and structured machine learning. In particular, we provide an initial prototype for a relational and graph traversal query language where queries are directly used as relational features for structured machine learning models. Feature extraction is performed by making declarative graph traversal queries. Learning and inference models can directly operate on this relational representation and augment it with new data and knowledge that, in turn, is integrated seamlessly into the relational structure to support new predictions. We demonstrate this system's capabilities by showcasing tasks in natural language processing and computational biology domains.
Accurate 3D Facial Geometry Prediction by Multi-Task, Multi-Modal, and Multi-Representation Landmark Refinement Network
Apr 16, 2021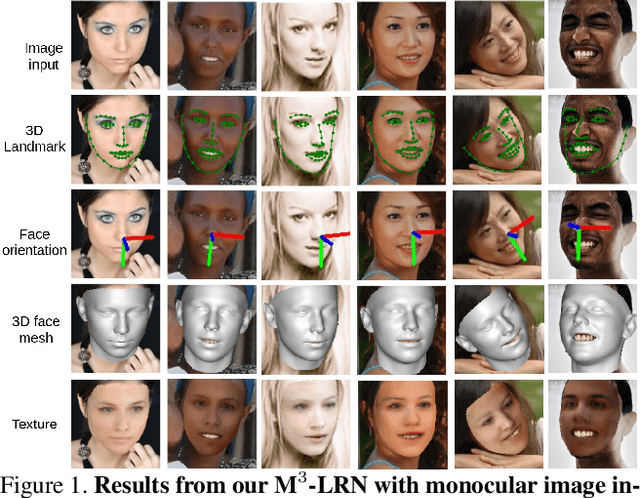
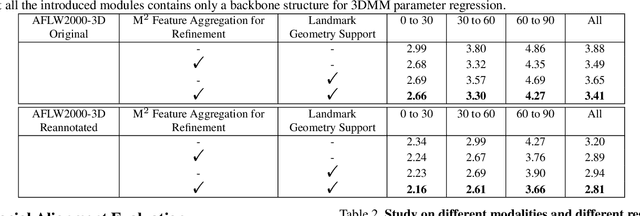
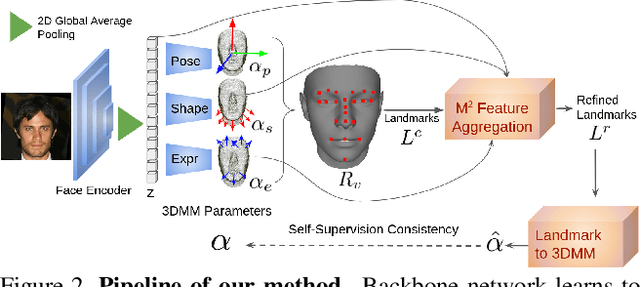
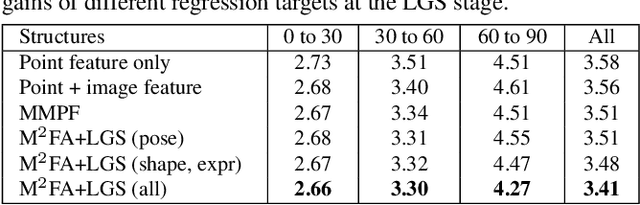
This work focuses on complete 3D facial geometry prediction, including 3D facial alignment via 3D face modeling and face orientation estimation using the proposed multi-task, multi-modal, and multi-representation landmark refinement network (M$^3$-LRN). Our focus is on the important facial attributes, 3D landmarks, and we fully utilize their embedded information to guide 3D facial geometry learning. We first propose a multi-modal and multi-representation feature aggregation for landmark refinement. Next, we are the first to study 3DMM regression from sparse 3D landmarks and utilize multi-representation advantage to attain better geometry prediction. We attain the state of the art from extensive experiments on all tasks of learning 3D facial geometry. We closely validate contributions of each modality and representation. Our results are robust across cropped faces, underwater scenarios, and extreme poses. Specially we adopt only simple and widely used network operations in M$^3$-LRN and attain a near 20\% improvement on face orientation estimation over the current best performance. See our project page here.
Explaining Ridesharing: Selection of Explanations for Increasing User Satisfaction
May 26, 2021
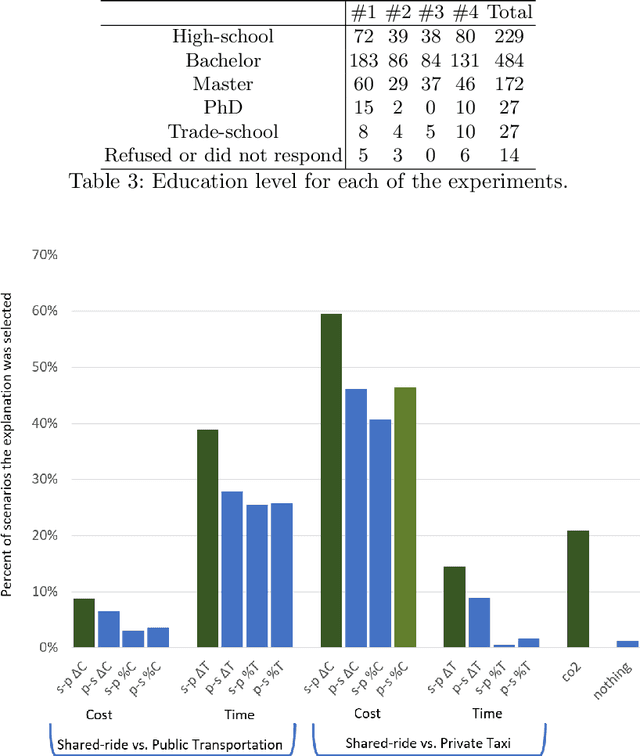
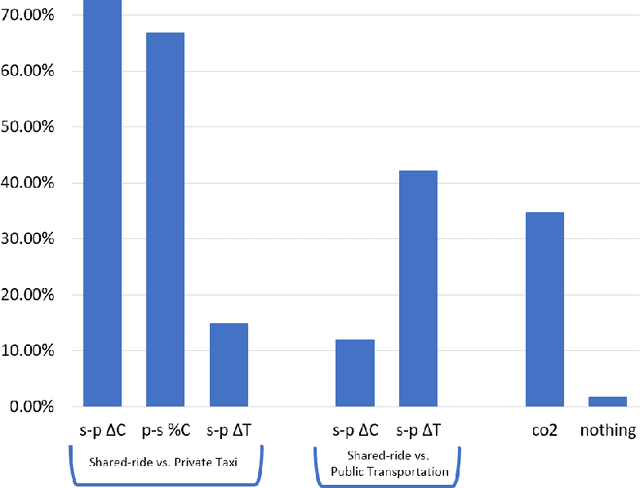

Transportation services play a crucial part in the development of modern smart cities. In particular, on-demand ridesharing services, which group together passengers with similar itineraries, are already operating in several metropolitan areas. These services can be of significant social and environmental benefit, by reducing travel costs, road congestion and CO2 emissions. Unfortunately, despite their advantages, not many people opt to use these ridesharing services. We believe that increasing the user satisfaction from the service will cause more people to utilize it, which, in turn, will improve the quality of the service, such as the waiting time, cost, travel time, and service availability. One possible way for increasing user satisfaction is by providing appropriate explanations comparing the alternative modes of transportation, such as a private taxi ride and public transportation. For example, a passenger may be more satisfied from a shared-ride if she is told that a private taxi ride would have cost her 50% more. Therefore, the problem is to develop an agent that provides explanations that will increase the user satisfaction. We model our environment as a signaling game and show that a rational agent, which follows the perfect Bayesian equilibrium, must reveal all of the information regarding the possible alternatives to the passenger. In addition, we develop a machine learning based agent that, when given a shared-ride along with its possible alternatives, selects the explanations that are most likely to increase user satisfaction. Using feedback from humans we show that our machine learning based agent outperforms the rational agent and an agent that randomly chooses explanations, in terms of user satisfaction.
Improving the Lexical Ability of Pretrained Language Models for Unsupervised Neural Machine Translation
Mar 18, 2021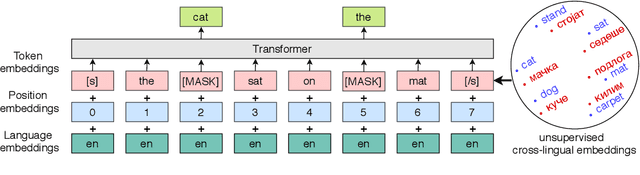
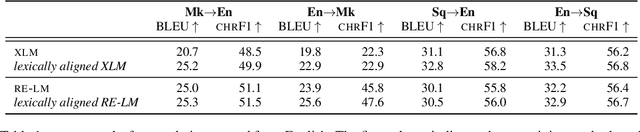
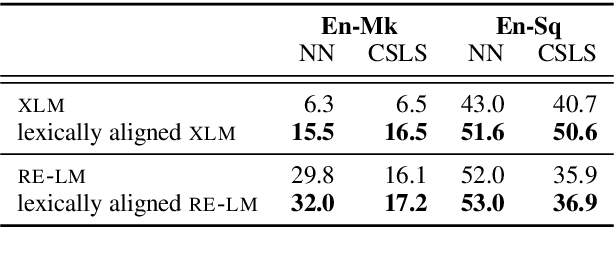
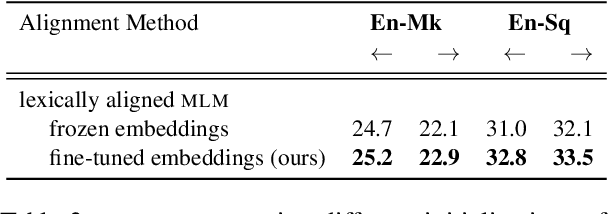
Successful methods for unsupervised neural machine translation (UNMT) employ cross-lingual pretraining via self-supervision, often in the form of a masked language modeling or a sequence generation task, which requires the model to align the lexical- and high-level representations of the two languages. While cross-lingual pretraining works for similar languages with abundant corpora, it performs poorly in low-resource, distant languages. Previous research has shown that this is because the representations are not sufficiently aligned. In this paper, we enhance the bilingual masked language model pretraining with lexical-level information by using type-level cross-lingual subword embeddings. Empirical results demonstrate improved performance both on UNMT (up to 4.5 BLEU) and bilingual lexicon induction using our method compared to an established UNMT baseline.
Single Image Super-Resolution with Dilated Convolution based Multi-Scale Information Learning Inception Module
Jul 22, 2017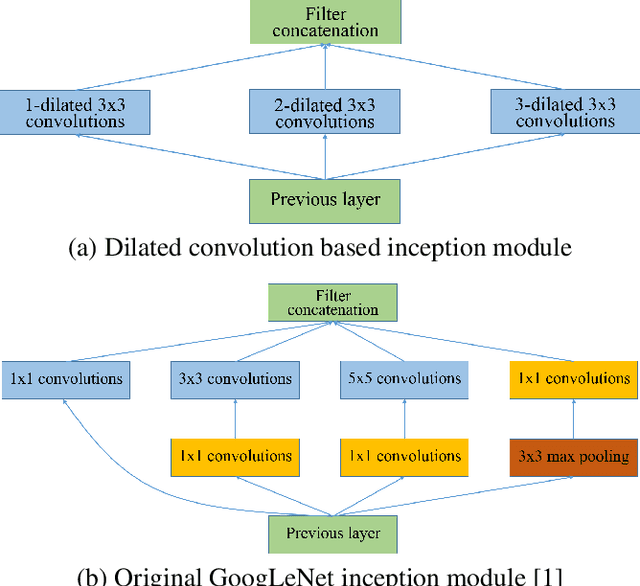
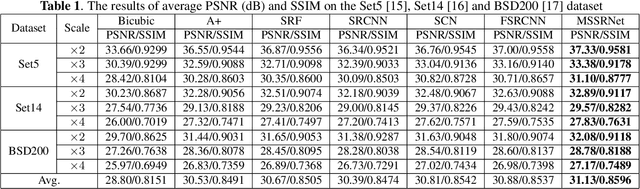
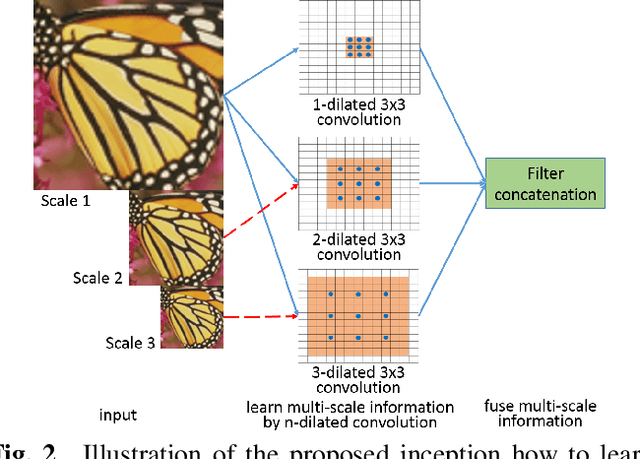

Traditional works have shown that patches in a natural image tend to redundantly recur many times inside the image, both within the same scale, as well as across different scales. Make full use of these multi-scale information can improve the image restoration performance. However, the current proposed deep learning based restoration methods do not take the multi-scale information into account. In this paper, we propose a dilated convolution based inception module to learn multi-scale information and design a deep network for single image super-resolution. Different dilated convolution learns different scale feature, then the inception module concatenates all these features to fuse multi-scale information. In order to increase the reception field of our network to catch more contextual information, we cascade multiple inception modules to constitute a deep network to conduct single image super-resolution. With the novel dilated convolution based inception module, the proposed end-to-end single image super-resolution network can take advantage of multi-scale information to improve image super-resolution performance. Experimental results show that our proposed method outperforms many state-of-the-art single image super-resolution methods.
Nutribullets Hybrid: Multi-document Health Summarization
Apr 08, 2021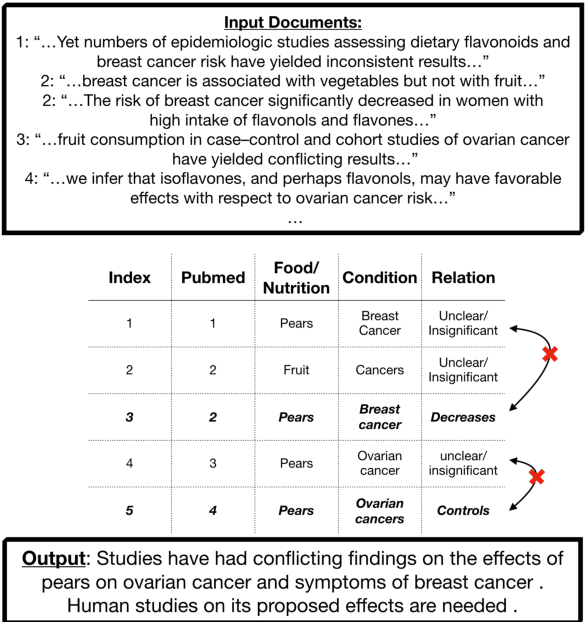

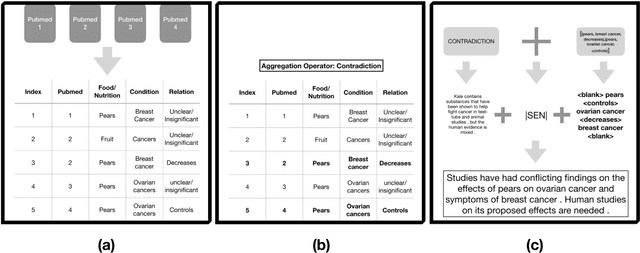

We present a method for generating comparative summaries that highlights similarities and contradictions in input documents. The key challenge in creating such summaries is the lack of large parallel training data required for training typical summarization systems. To this end, we introduce a hybrid generation approach inspired by traditional concept-to-text systems. To enable accurate comparison between different sources, the model first learns to extract pertinent relations from input documents. The content planning component uses deterministic operators to aggregate these relations after identifying a subset for inclusion into a summary. The surface realization component lexicalizes this information using a text-infilling language model. By separately modeling content selection and realization, we can effectively train them with limited annotations. We implemented and tested the model in the domain of nutrition and health -- rife with inconsistencies. Compared to conventional methods, our framework leads to more faithful, relevant and aggregation-sensitive summarization -- while being equally fluent.
Automated User Experience Testing through Multi-Dimensional Performance Impact Analysis
Apr 08, 2021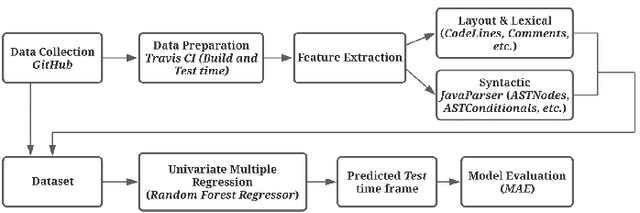
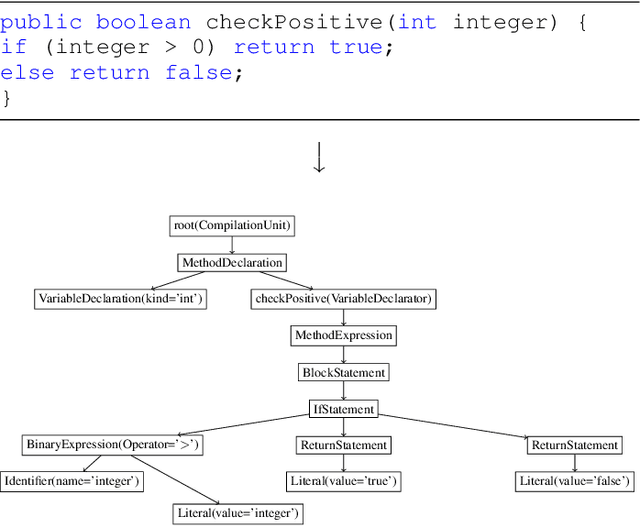
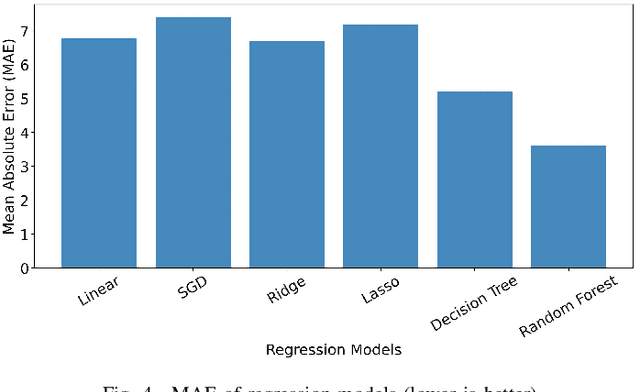
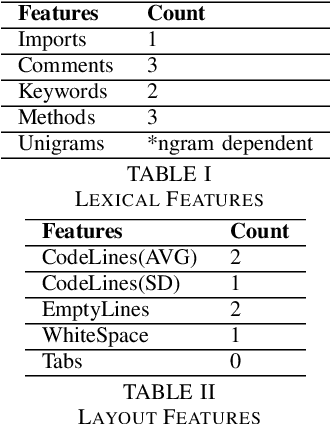
Although there are many automated software testing suites, they usually focus on unit, system, and interface testing. However, especially software updates such as new security features have the potential to diminish user experience. In this paper, we propose a novel automated user experience testing methodology that learns how code changes impact the time unit and system tests take, and extrapolate user experience changes based on this information. Such a tool can be integrated into existing continuous integration pipelines, and it provides software teams immediate user experience feedback. We construct a feature set from lexical, layout, and syntactic characteristics of the code, and using Abstract Syntax Tree-Based Embeddings, we can calculate the approximate semantic distance to feed into a machine learning algorithm. In our experiments, we use several regression methods to estimate the time impact of software updates. Our open-source tool achieved 3.7% mean absolute error rate with a random forest regressor.
Surface Form Competition: Why the Highest Probability Answer Isn't Always Right
Apr 16, 2021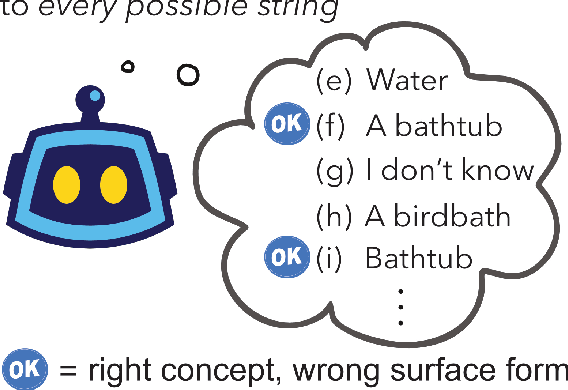
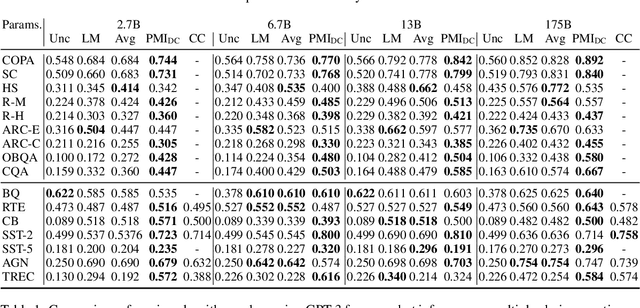


Large language models have shown promising results in zero-shot settings (Brown et al.,2020; Radford et al., 2019). For example, they can perform multiple choice tasks simply by conditioning on a question and selecting the answer with the highest probability. However, ranking by string probability can be problematic due to surface form competition-wherein different surface forms compete for probability mass, even if they represent the same underlying concept, e.g. "computer" and "PC." Since probability mass is finite, this lowers the probability of the correct answer, due to competition from other strings that are valid answers (but not one of the multiple choice options). We introduce Domain Conditional Pointwise Mutual Information, an alternative scoring function that directly compensates for surface form competition by simply reweighing each option according to a term that is proportional to its a priori likelihood within the context of the specific zero-shot task. It achieves consistent gains in zero-shot performance over both calibrated (Zhao et al., 2021) and uncalibrated scoring functions on all GPT-2 and GPT-3 models over a variety of multiple choice datasets.
Monitoring Object Detection Abnormalities via Data-Label and Post-Algorithm Abstractions
Mar 29, 2021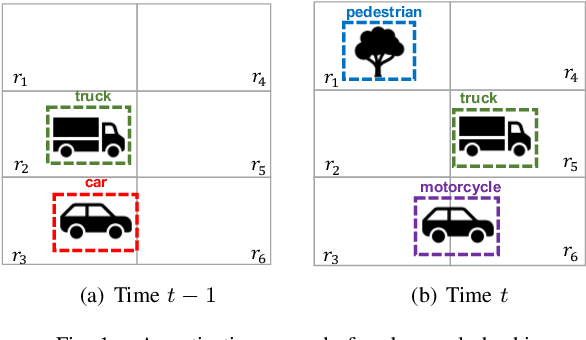
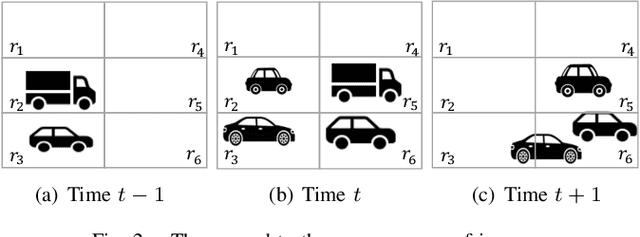
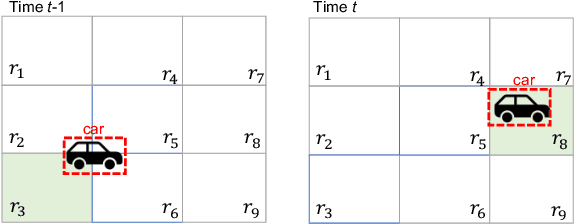
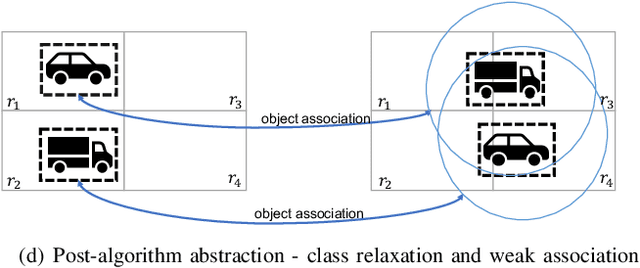
While object detection modules are essential functionalities for any autonomous vehicle, the performance of such modules that are implemented using deep neural networks can be, in many cases, unreliable. In this paper, we develop abstraction-based monitoring as a logical framework for filtering potentially erroneous detection results. Concretely, we consider two types of abstraction, namely data-label abstraction and post-algorithm abstraction. Operated on the training dataset, the construction of data-label abstraction iterates each input, aggregates region-wise information over its associated labels, and stores the vector under a finite history length. Post-algorithm abstraction builds an abstract transformer for the tracking algorithm. Elements being associated together by the abstract transformer can be checked against consistency over their original values. We have implemented the overall framework to a research prototype and validated it using publicly available object detection datasets.