 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transforming Multi-Conditioned Generation from Meaning Representation
Jan 12, 2021


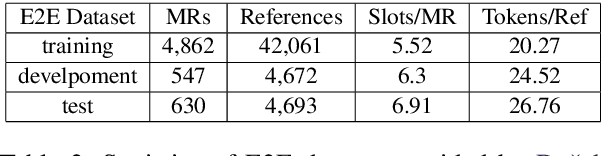

In task-oriented conversation systems, natural language generation systems that generate sentences with specific information related to conversation flow are useful. Our study focuses on language generation by considering various information representing the meaning of utterances as multiple conditions of generation. NLG from meaning representations, the conditions for sentence meaning, generally goes through two steps: sentence planning and surface realization. However, we propose a simple one-stage framework to generate utterances directly from MR (Meaning Representation). Our model is based on GPT2 and generates utterances with flat conditions on slot and value pairs, which does not need to determine the structure of the sentence. We evaluate several systems in the E2E dataset with 6 automatic metrics. Our system is a simple method, but it demonstrates comparable performance to previous systems in automated metrics. In addition, using only 10\% of the data set without any other techniques, our model achieves comparable performance, and shows the possibility of performing zero-shot generation and expanding to other datasets.
Automated User Experience Testing through Multi-Dimensional Performance Impact Analysis
Apr 08, 2021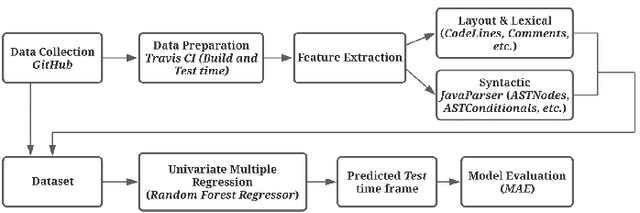
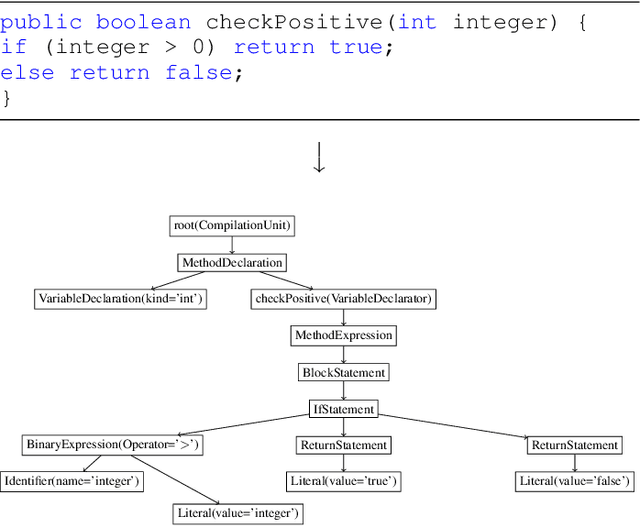
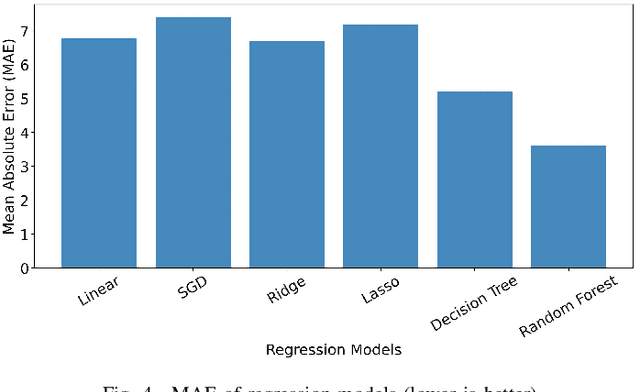
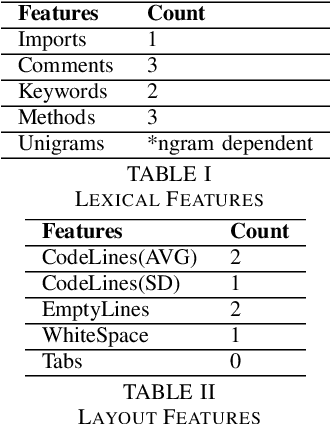
Although there are many automated software testing suites, they usually focus on unit, system, and interface testing. However, especially software updates such as new security features have the potential to diminish user experience. In this paper, we propose a novel automated user experience testing methodology that learns how code changes impact the time unit and system tests take, and extrapolate user experience changes based on this information. Such a tool can be integrated into existing continuous integration pipelines, and it provides software teams immediate user experience feedback. We construct a feature set from lexical, layout, and syntactic characteristics of the code, and using Abstract Syntax Tree-Based Embeddings, we can calculate the approximate semantic distance to feed into a machine learning algorithm. In our experiments, we use several regression methods to estimate the time impact of software updates. Our open-source tool achieved 3.7% mean absolute error rate with a random forest regressor.
Directed-Info GAIL: Learning Hierarchical Policies from Unsegmented Demonstrations using Directed Information
Sep 29, 2018
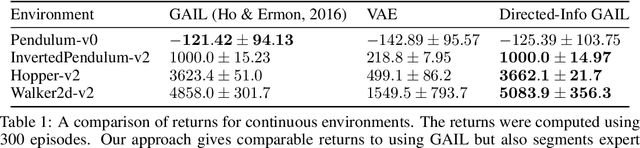
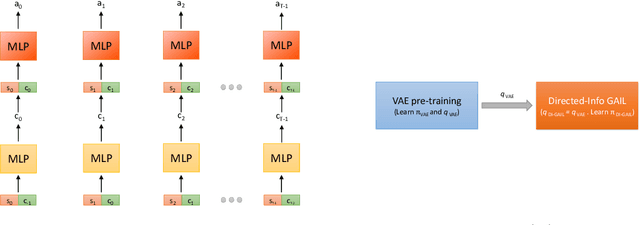

The use of imitation learning to learn a single policy for a complex task that has multiple modes or hierarchical structure can be challenging. In fact, previous work has shown that when the modes are known, learning separate policies for each mode or sub-task can greatly improve the performance of imitation learning. In this work, we discover the interaction between sub-tasks from their resulting state-action trajectory sequences using a directed graphical model. We propose a new algorithm based on the generative adversarial imitation learning framework which automatically learns sub-task policies from unsegmented demonstrations. Our approach maximizes the directed information flow in the graphical model between sub-task latent variables and their generated trajectories. We also show how our approach connects with the existing Options framework, which is commonly used to learn hierarchical policies.
OAAE: Adversarial Autoencoders for Novelty Detection in Multi-modal Normality Case via Orthogonalized Latent Space
Jan 07, 2021
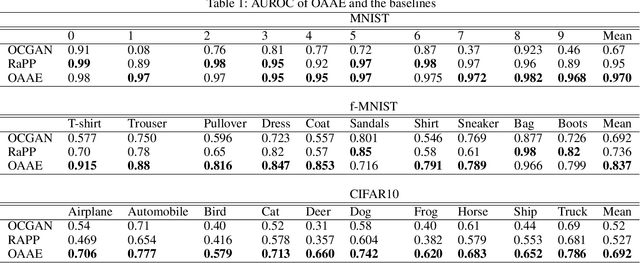
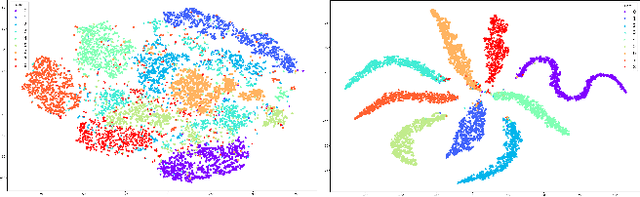
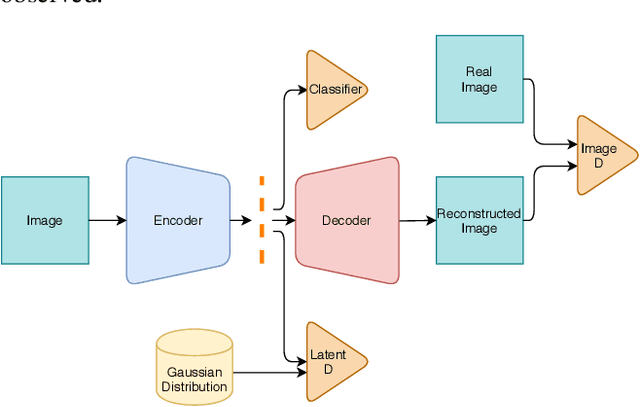
Novelty detection using deep generative models such as autoencoder, generative adversarial networks mostly takes image reconstruction error as novelty score function. However, image data, high dimensional as it is, contains a lot of different features other than class information which makes models hard to detect novelty data. The problem gets harder in multi-modal normality case. To address this challenge, we propose a new way of measuring novelty score in multi-modal normality cases using orthogonalized latent space. Specifically, we employ orthogonal low-rank embedding in the latent space to disentangle the features in the latent space using mutual class information. With the orthogonalized latent space, novelty score is defined by the change of each latent vector. Proposed algorithm was compared to state-of-the-art novelty detection algorithms using GAN such as RaPP and OCGAN, and experimental results show that ours outperforms those algorithms.
FatNet: A Feature-attentive Network for 3D Point Cloud Processing
Apr 07, 2021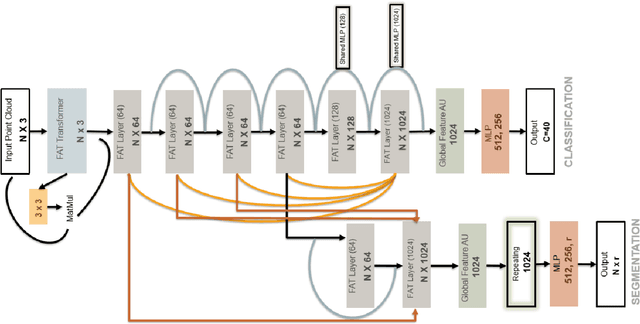
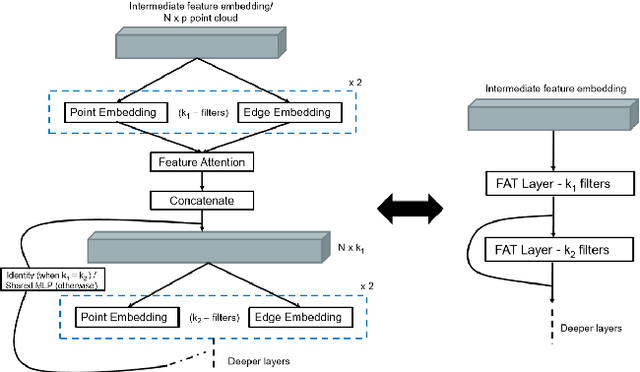
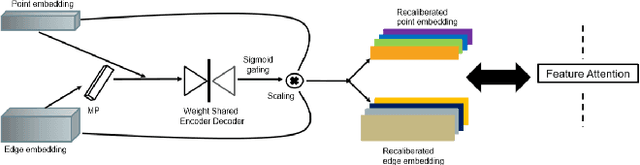
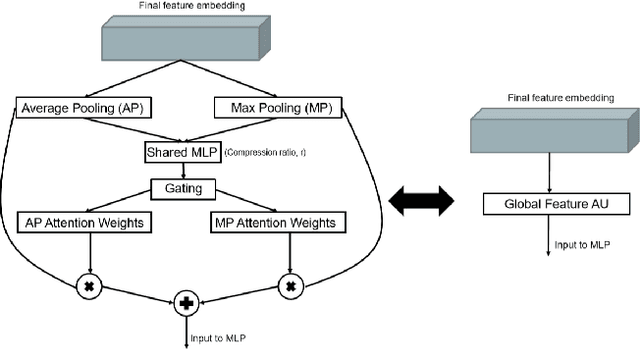
The application of deep learning to 3D point clouds is challenging due to its lack of order. Inspired by the point embeddings of PointNet and the edge embeddings of DGCNNs, we propose three improvements to the task of point cloud analysis. First, we introduce a novel feature-attentive neural network layer, a FAT layer, that combines both global point-based features and local edge-based features in order to generate better embeddings. Second, we find that applying the same attention mechanism across two different forms of feature map aggregation, max pooling and average pooling, gives better performance than either alone. Third, we observe that residual feature reuse in this setting propagates information more effectively between the layers, and makes the network easier to train. Our architecture achieves state-of-the-art results on the task of point cloud classification, as demonstrated on the ModelNet40 dataset, and an extremely competitive performance on the ShapeNet part segmentation challenge.
Covid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks
May 20, 2021
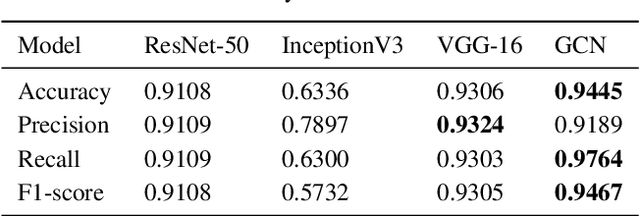
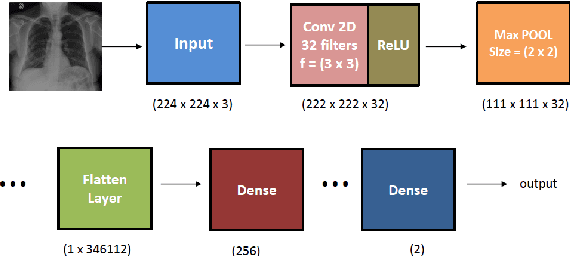
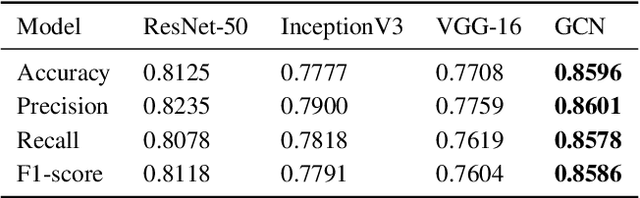
The novel corona virus (Covid-19) has introduced significant challenges due to its rapid spreading nature through respiratory transmission. As a result, there is a huge demand for Artificial Intelligence (AI) based quick disease diagnosis methods as an alternative to high demand tests such as Polymerase Chain Reaction (PCR). Chest X-ray (CXR) Image analysis is such cost-effective radiography technique due to resource availability and quick screening. But, a sufficient and systematic data collection that is required by complex deep leaning (DL) models is more difficult and hence there are recent efforts that utilize transfer learning to address this issue. Still these transfer learnt models suffer from lack of generalization and increased bias to the training dataset resulting poor performance for unseen data. Limited correlation of the transferred features from the pre-trained model to a specific medical imaging domain like X-ray and overfitting on fewer data can be reasons for this circumstance. In this work, we propose a novel Graph Convolution Neural Network (GCN) that is capable of identifying bio-markers of Covid-19 pneumonia from CXR images and meta information about patients. The proposed method exploits important relational knowledge between data instances and their features using graph representation and applies convolution to learn the graph data which is not possible with conventional convolution on Euclidean domain. The results of extensive experiments of proposed model on binary (Covid vs normal) and three class (Covid, normal, other pneumonia) classification problems outperform different benchmark transfer learnt models, hence overcoming the aforementioned drawbacks.
Improving the Lexical Ability of Pretrained Language Models for Unsupervised Neural Machine Translation
Mar 18, 2021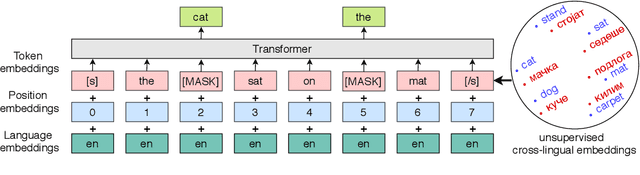
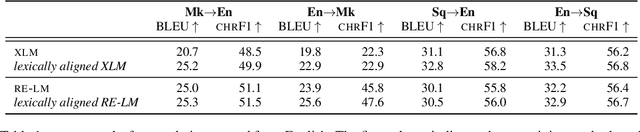
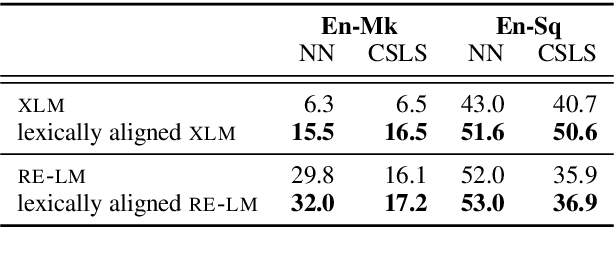
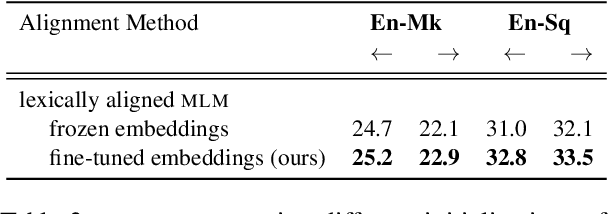
Successful methods for unsupervised neural machine translation (UNMT) employ cross-lingual pretraining via self-supervision, often in the form of a masked language modeling or a sequence generation task, which requires the model to align the lexical- and high-level representations of the two languages. While cross-lingual pretraining works for similar languages with abundant corpora, it performs poorly in low-resource, distant languages. Previous research has shown that this is because the representations are not sufficiently aligned. In this paper, we enhance the bilingual masked language model pretraining with lexical-level information by using type-level cross-lingual subword embeddings. Empirical results demonstrate improved performance both on UNMT (up to 4.5 BLEU) and bilingual lexicon induction using our method compared to an established UNMT baseline.
Monitoring Object Detection Abnormalities via Data-Label and Post-Algorithm Abstractions
Mar 29, 2021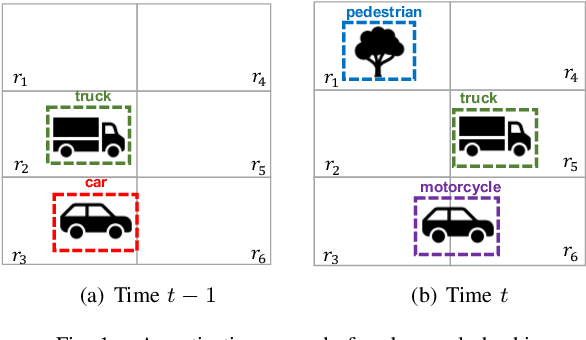
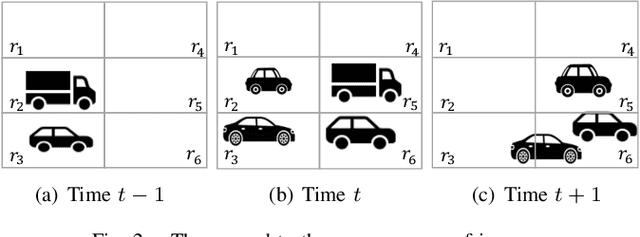
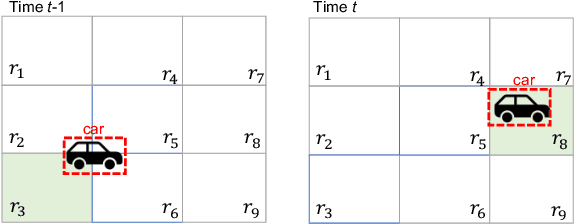
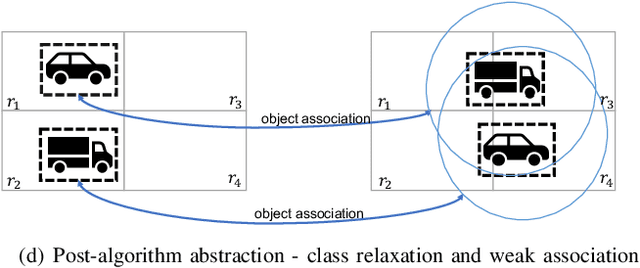
While object detection modules are essential functionalities for any autonomous vehicle, the performance of such modules that are implemented using deep neural networks can be, in many cases, unreliable. In this paper, we develop abstraction-based monitoring as a logical framework for filtering potentially erroneous detection results. Concretely, we consider two types of abstraction, namely data-label abstraction and post-algorithm abstraction. Operated on the training dataset, the construction of data-label abstraction iterates each input, aggregates region-wise information over its associated labels, and stores the vector under a finite history length. Post-algorithm abstraction builds an abstract transformer for the tracking algorithm. Elements being associated together by the abstract transformer can be checked against consistency over their original values. We have implemented the overall framework to a research prototype and validated it using publicly available object detection datasets.
Natural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Apr 16, 2021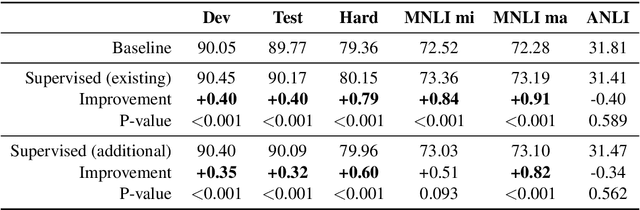
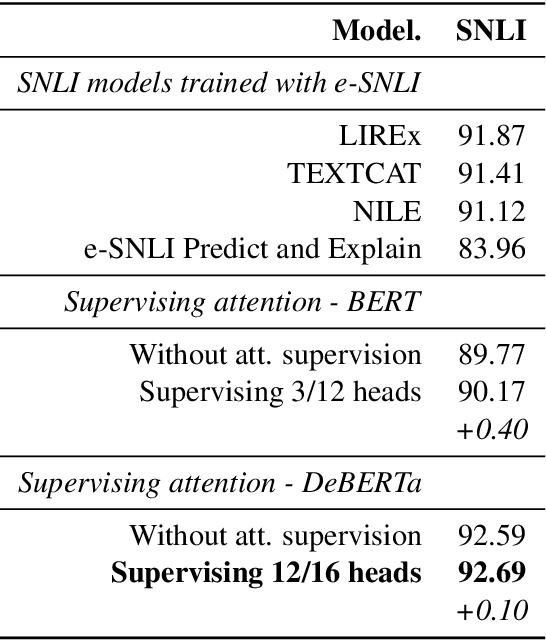
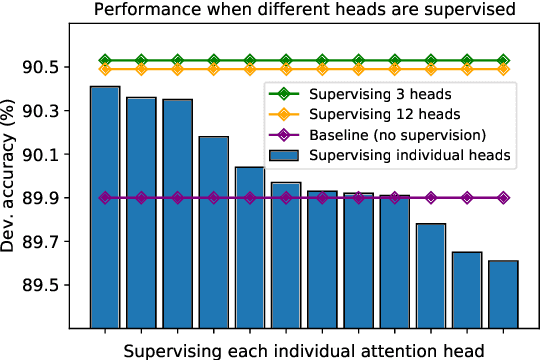
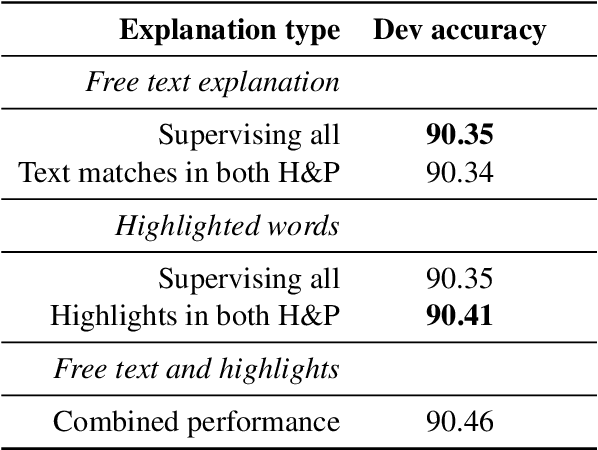
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.
UKPGAN: Unsupervised KeyPoint GANeration
Nov 24, 2020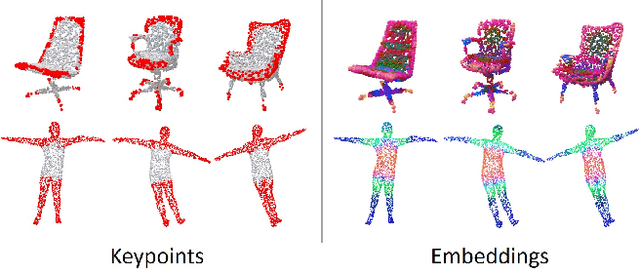
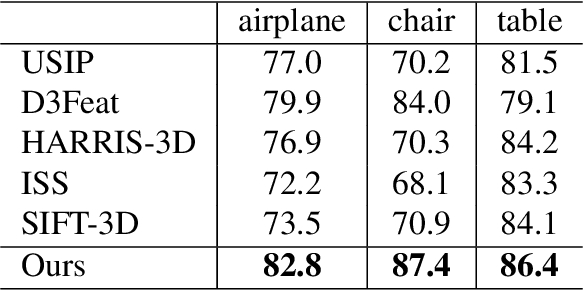
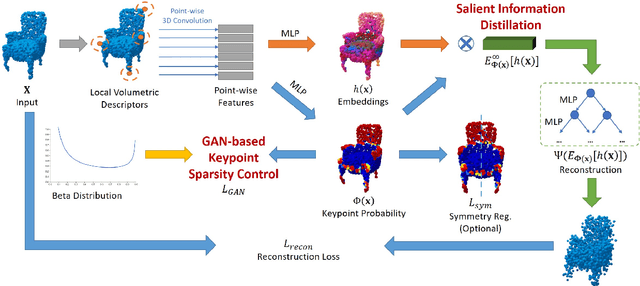
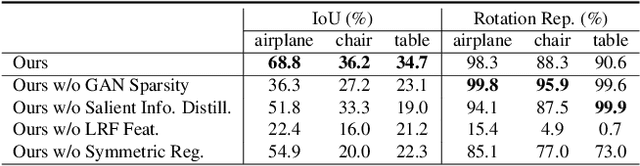
Keypoint detection is an essential component for the object registration and alignment. However, previous works mainly focused on how to register keypoints under arbitrary rigid transformations. Differently, in this work, we reckon keypoints under an information compression scheme to represent the whole object. Based on this, we propose UKPGAN, an unsupervised 3D keypoint detector where keypoints are detected so that they could reconstruct the original object shape. Two modules: GAN-based keypoint sparsity control and salient information distillation modules are proposed to locate those important keypoints. Extensive experiments show that our keypoints preserve the semantic information of objects and align well with human annotated part and keypoint labels. Furthermore, we show that UKPGAN can be applied to either rigid objects or non-rigid SMPL human bodies under arbitrary pose deformations. As a keypoint detector, our model is stable under both rigid and non-rigid transformations, with local reference frame estimation. Our code is available on https://github.com/qq456cvb/UKPGAN.