 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Uncertainty-aware Collaborative Learning Method for Remote Sensing Image Classification Under Multi-Label Noise
May 12, 2021
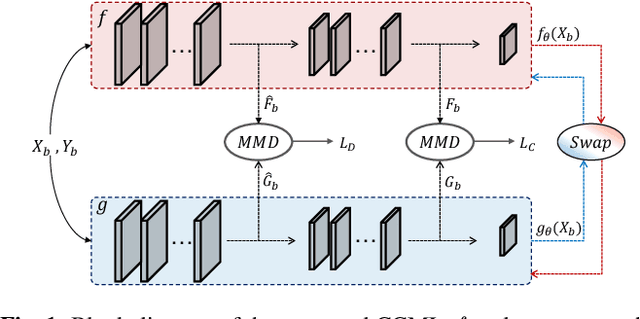
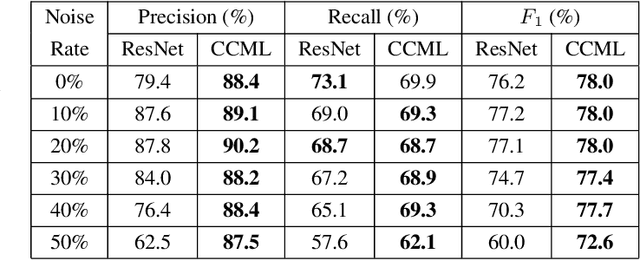
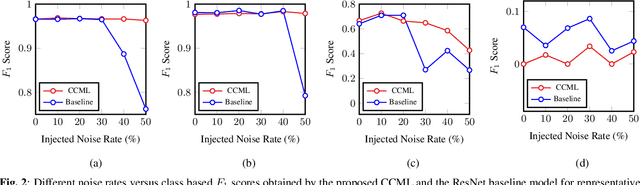
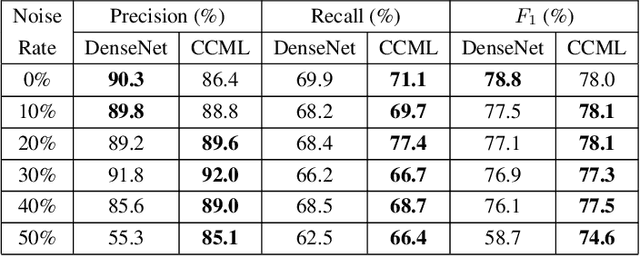
In remote sensing (RS), collecting a large number of reliable training images annotated by multiple land-cover class labels for multi-label classification (MLC) is time-consuming and costly. To address this problem, the publicly available thematic products are often used for annotating RS images with zero-labeling cost. However, in this case the training set can include noisy multi-labels that distort the learning process, resulting in inaccurate predictions. This paper proposes an architect-independent Consensual Collaborative Multi-Label Learning (CCML) method to train deep classifiers under input-dependent (heteroscedastic) multi-label noise in the MLC problems. The proposed CCML identifies, ranks, and corrects noisy multi-label images through four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The group lasso module detects the potentially noisy labels by estimating the label uncertainty based on the aggregation of two collaborative networks. The discrepancy module ensures that the two networks learn diverse features, while obtaining the same predictions. The flipping module corrects the identified noisy labels, and the swap module exchanges the ranking information between the two networks. The experiments conducted on the multi-label RS image archive IR-BigEarthNet confirm the robustness of the proposed CCML under extreme multi-label noise rates.
Spherical Message Passing for 3D Graph Networks
Feb 09, 2021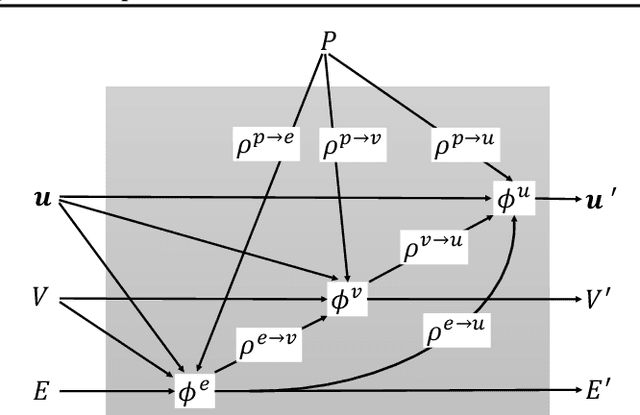
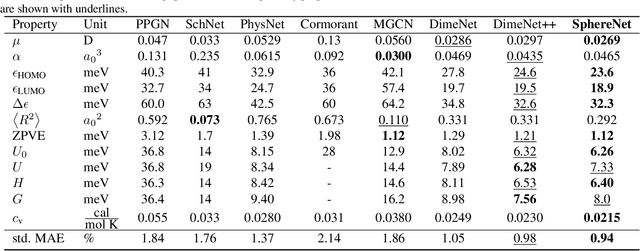
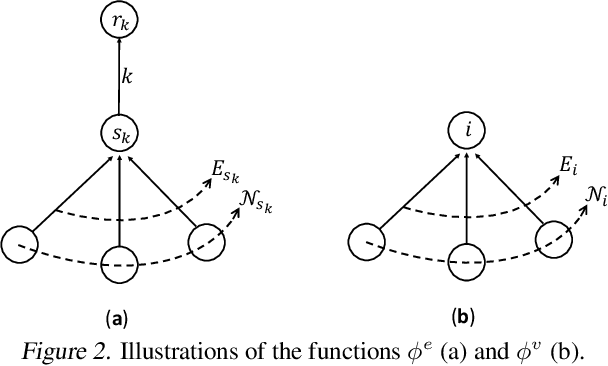
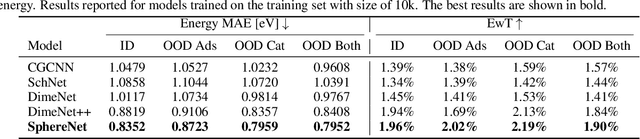
We consider representation learning from 3D graphs in which each node is associated with a spatial position in 3D. This is an under explored area of research, and a principled framework is currently lacking. In this work, we propose a generic framework, known as the 3D graph network (3DGN), to provide a unified interface at different levels of granularity for 3D graphs. Built on 3DGN, we propose the spherical message passing (SMP) as a novel and specific scheme for realizing the 3DGN framework in the spherical coordinate system (SCS). We conduct formal analyses and show that the relative location of each node in 3D graphs is uniquely defined in the SMP scheme. Thus, our SMP represents a complete and accurate architecture for learning from 3D graphs in the SCS. We derive physically-based representations of geometric information and propose the SphereNet for learning representations of 3D graphs. We show that existing 3D deep models can be viewed as special cases of the SphereNet. Experimental results demonstrate that the use of complete and accurate 3D information in 3DGN and SphereNet leads to significant performance improvements in prediction tasks.
A Review of Anonymization for Healthcare Data
Apr 13, 2021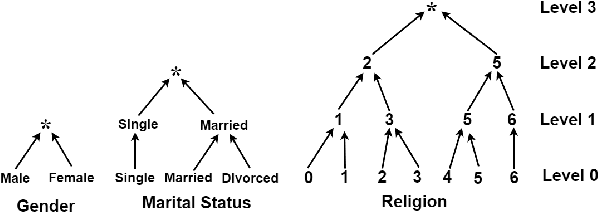
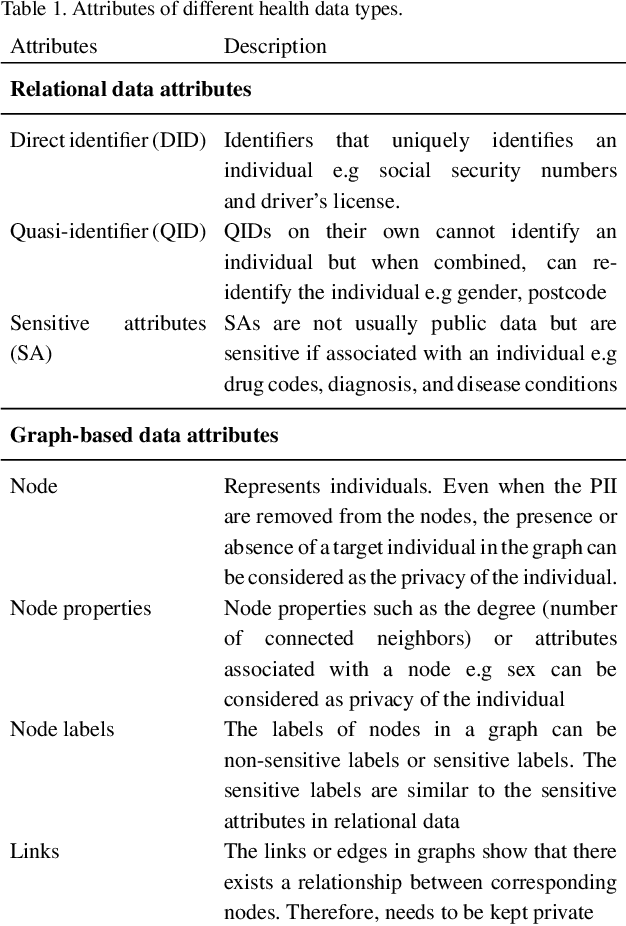
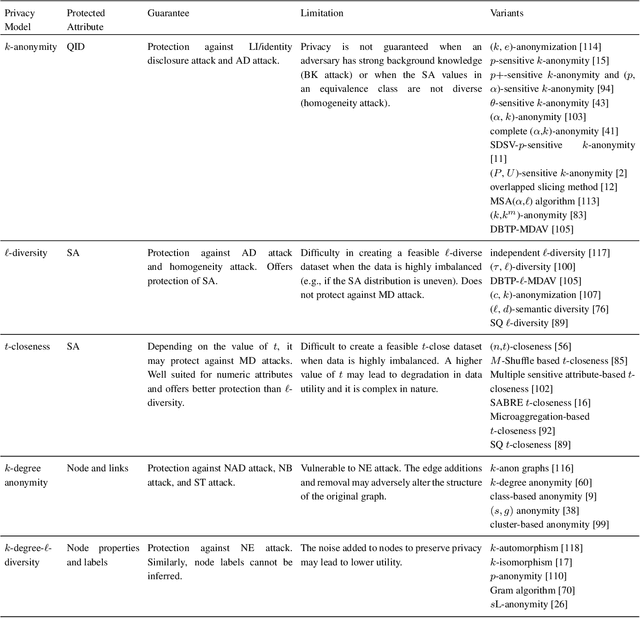
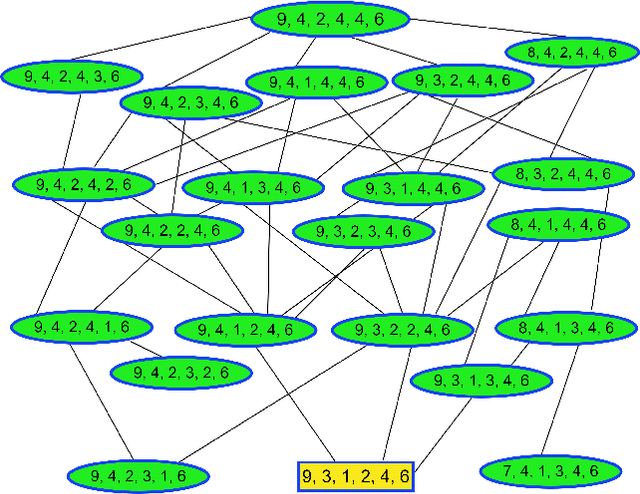
Mining health data can lead to faster medical decisions, improvement in the quality of treatment, disease prevention, reduced cost, and it drives innovative solutions within the healthcare sector. However, health data is highly sensitive and subject to regulations such as the General Data Protection Regulation (GDPR), which aims to ensure patient's privacy. Anonymization or removal of patient identifiable information, though the most conventional way, is the first important step to adhere to the regulations and incorporate privacy concerns. In this paper, we review the existing anonymization techniques and their applicability to various types (relational and graph-based) of health data. Besides, we provide an overview of possible attacks on anonymized data. We illustrate via a reconstruction attack that anonymization though necessary, is not sufficient to address patient privacy and discuss methods for protecting against such attacks. Finally, we discuss tools that can be used to achieve anonymization.
COVID-19 Smart Chatbot Prototype for Patient Monitoring
Mar 11, 2021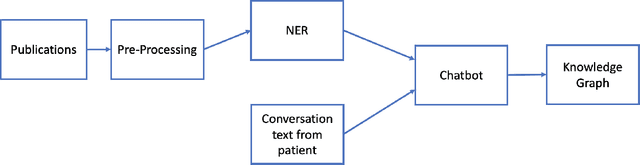
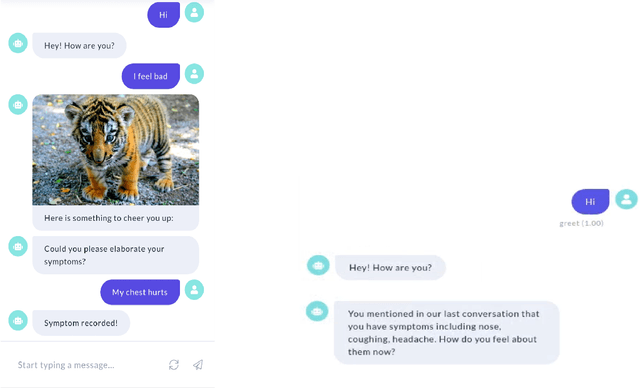
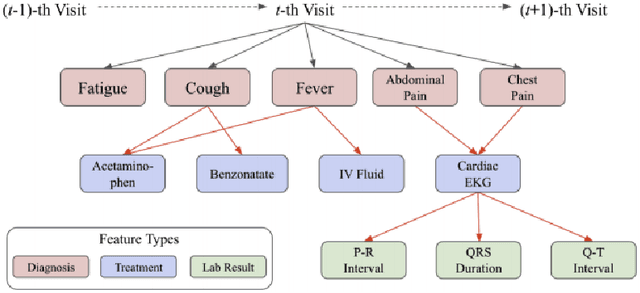
Many COVID-19 patients developed prolonged symptoms after the infection, including fatigue, delirium, and headache. The long-term health impact of these conditions is still not clear. It is necessary to develop a way to follow up with these patients for monitoring their health status to support timely intervention and treatment. In the lack of sufficient human resources to follow up with patients, we propose a novel smart chatbot solution backed with machine learning to collect information (i.e., generating digital diary) in a personalized manner. In this article, we describe the design framework and components of our prototype.
Classifications of the Summative Assessment for Revised Blooms Taxonomy by using Deep Learning
Apr 18, 2021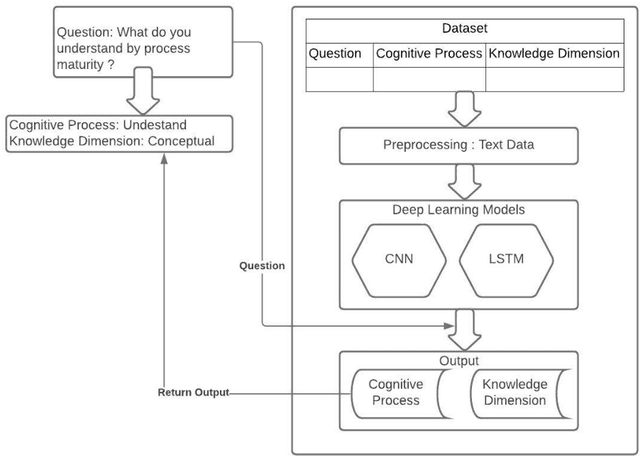
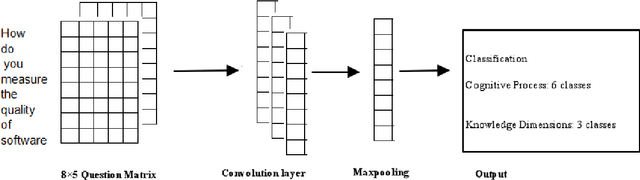
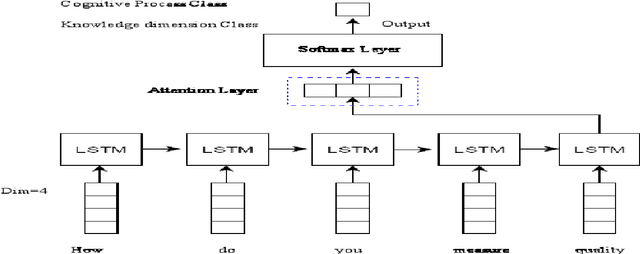
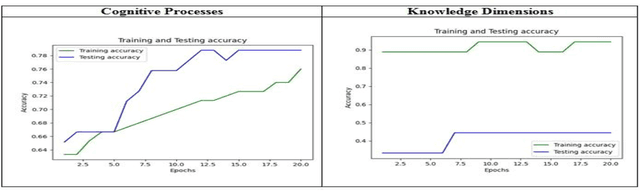
Education is the basic step of understanding the truth and the preparation of the intelligence to reflect. Focused on the rational capacity of the human being the Cognitive process and knowledge dimensions of Revised Blooms Taxonomy helps to differentiate the procedure of studying into six types of various cognitive processes and four types of knowledge dimensions. These types are synchronized in the increasing level of difficulty. In this paper Software Engineering courses of B.Tech Computer Engineering and Information Technology offered by various Universities and Educational Institutes have been investigated for Revised Blooms Taxonomy RBT. Questions are a very useful constituent. Knowledge intelligence and strength of the learners can be tested by applying questions.The fundamental goal of this paper is to create a relative study of the classification of the summative assessment based on Revised Blooms Taxonomy using the Convolutional Neural Networks CNN Long Short-Term Memory LSTM of Deep Learning techniques in an endeavor to attain significant accomplishment and elevated precision levels.
* 8 pages, 7 figures, 2 tables
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021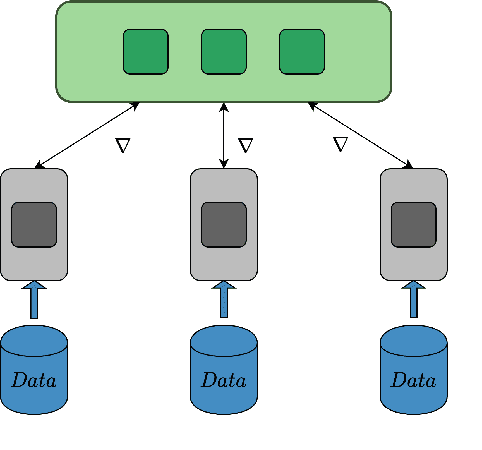
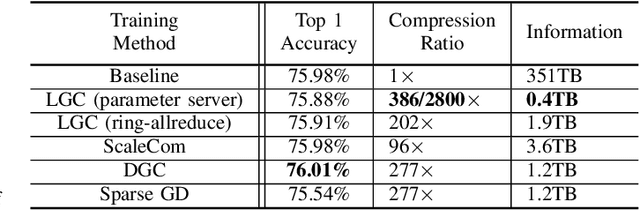
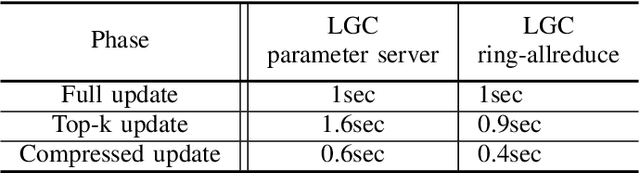
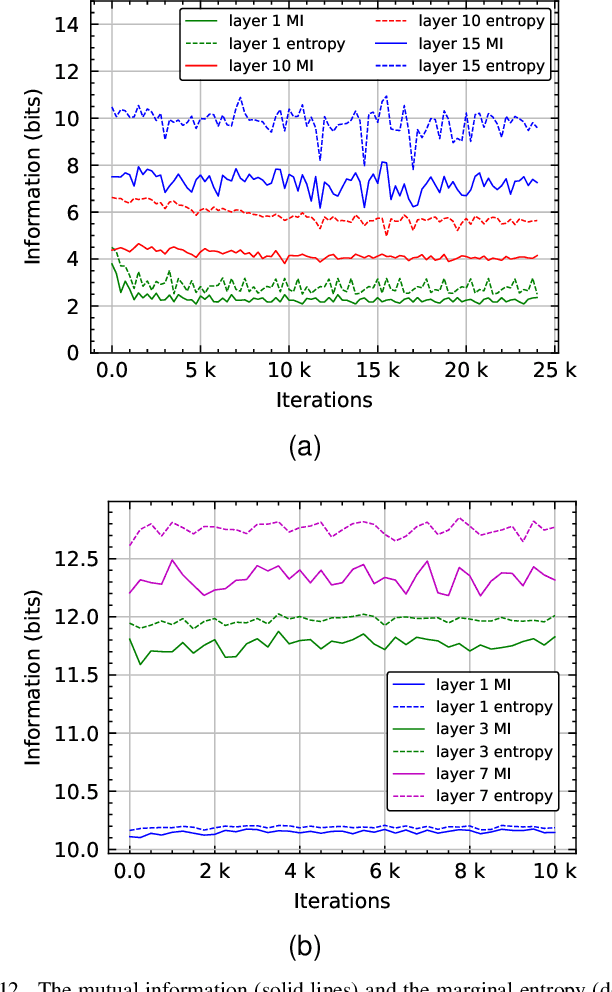
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.
Cascaded Convolutional Neural Network for Automatic Myocardial Infarction Segmentation from Delayed-Enhancement Cardiac MRI
Dec 28, 2020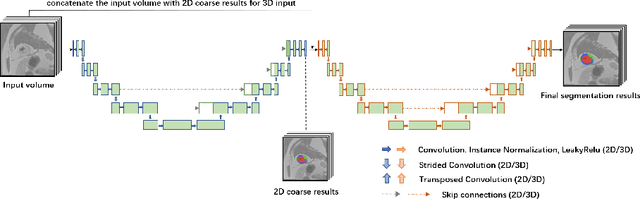
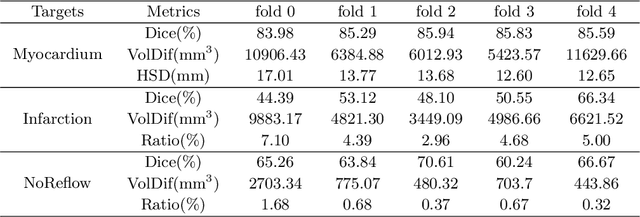
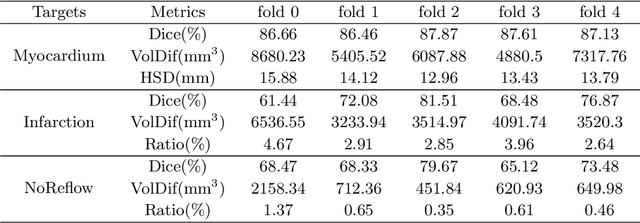
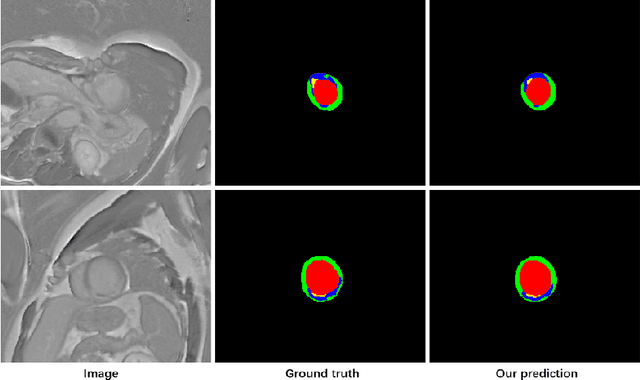
Automatic segmentation of myocardial contours and relevant areas like infraction and no-reflow is an important step for the quantitative evaluation of myocardial infarction. In this work, we propose a cascaded convolutional neural network for automatic myocardial infarction segmentation from delayed-enhancement cardiac MRI. We first use a 2D U-Net to focus on the intra-slice information to perform a preliminary segmentation. After that, we use a 3D U-Net to utilize the volumetric spatial information for a subtle segmentation. Our method is evaluated on the MICCAI 2020 EMIDEC challenge dataset and achieves average Dice score of 0.8786, 0.7124 and 0.7851 for myocardium, infarction and no-reflow respectively, outperforms all the other teams of the segmentation contest.
Dynamic-Deep: ECG Task-Aware Compression
May 30, 2021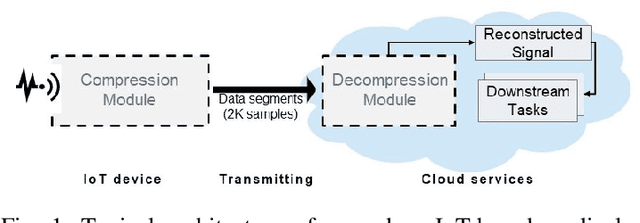
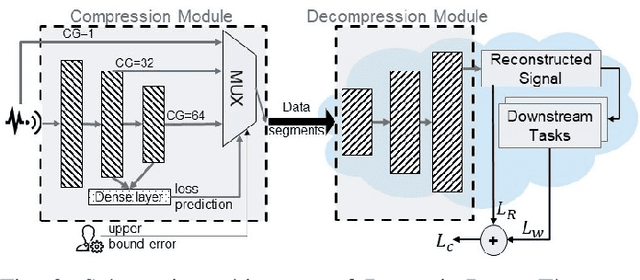
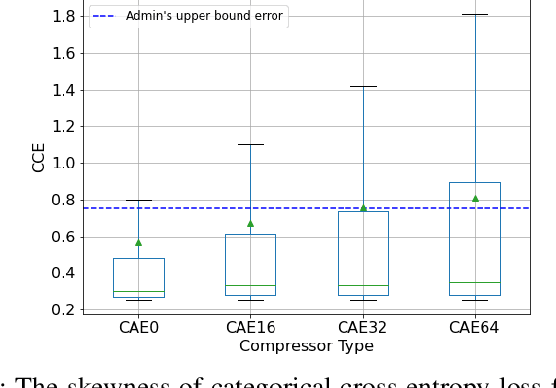
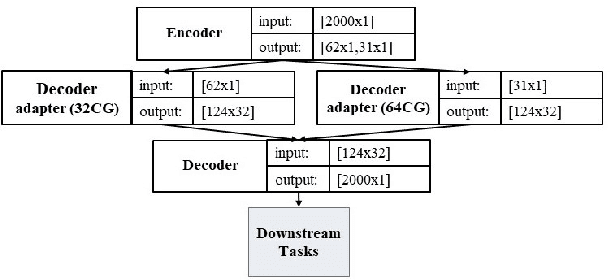
Monitoring medical data, e.g., Electrocardiogram (ECG) signals, is a common application of Internet of Things (IoT) devices. Compression methods are often applied on the massive amounts of sensor data generated before sending it to the Cloud to reduce storage and delivery costs. A lossy compression provides high compression gain (CG) but may reduce the performance of an ECG application (downstream task) due to information loss. Previous works on ECG monitoring focus either on optimizing the signal reconstruction or the task's performance. Instead, we advocate a lossy compression solution that allows configuring a desired performance level on the downstream tasks while maintaining an optimized CG. We propose Dynamic-Deep, a task-aware compression that uses convolutional autoencoders. The compression level is dynamically selected to yield an optimized compression without violating tasks' performance requirements. We conduct an extensive evaluation of our approach on common ECG datasets using two popular ECG applications, which includes heart rate (HR) arrhythmia classification. We demonstrate that Dynamic-Deep improves HR classification F1-score by a factor of 3 and increases CG by up to 83% compared to the previous state-of-the-art (autoencoder-based) compressor. Additionally, Dynamic-Deep has a 67% lower memory footprint. Analyzing Dynamic-Deep on the Google Cloud Platform, we observe a 97% reduction in cloud costs compared to a no compression solution. To the best of our knowledge, Dynamic-Deep is the first proposal to focus on balancing the need for high performance of cloud-based downstream tasks and the desire to achieve optimized compression in IoT ECG monitoring settings.
Machine Learning Interpretability Meets TLS Fingerprinting
Nov 12, 2020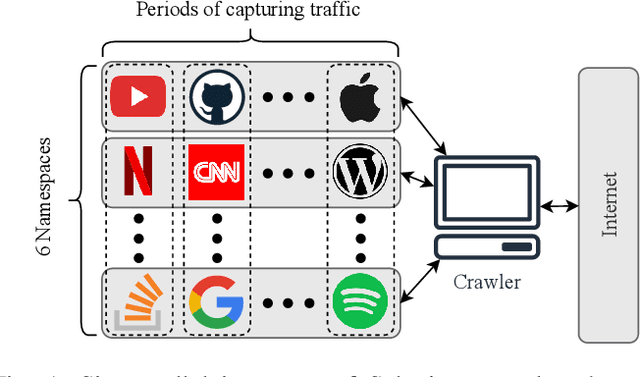
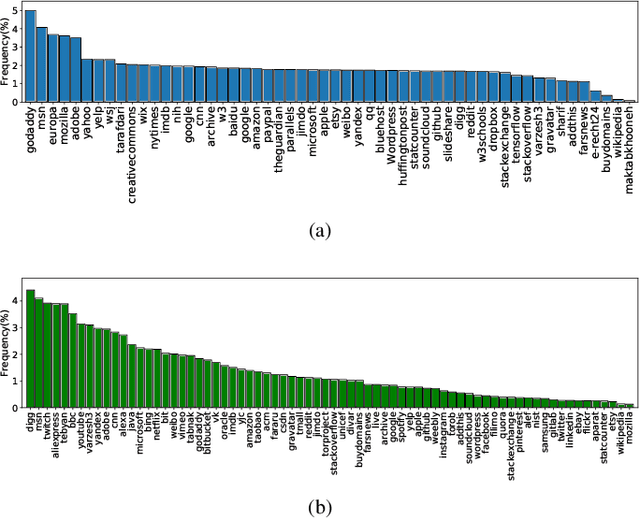
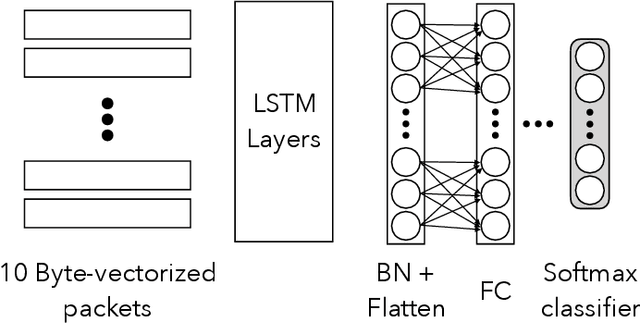
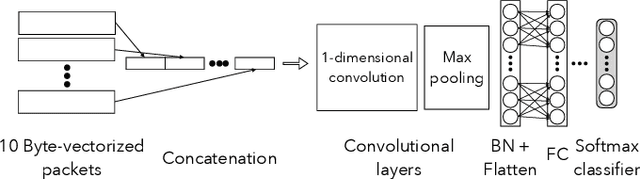
Protecting users' privacy over the Internet is of great importance. However, due to the increasing complexity of network protocols and components, it becomes harder and harder to maintain. Therefore, investigating and understanding how data is leaked from the information transport platform/protocols can lead us to a more secure environment. In this paper, we propose an iterative framework to find the most vulnerable information fields in a network protocol systematically. To this end, focusing on the Transport Layer Security (TLS) protocol, we perform different machine-learning-based fingerprinting attacks by collecting data from more than 70 domains (websites) to understand how and where this information leakage occurs in the TLS protocol. Then, by employing the interpretation techniques developed in the machine learning community, and using our framework, we find the most vulnerable information fields in the TLS protocol. Our findings demonstrate that the TLS handshake (which is mainly unencrypted), the TLS record length appears in the TLS application data header, and the initialization vector (IV) field are among the most critical leaker parts in this protocol, respectively.
Roof Damage Assessment from Automated 3D Building Models
Jun 04, 2021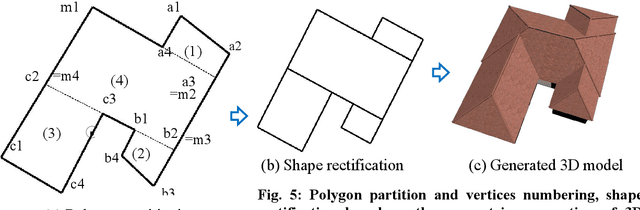

The 3D building modelling is important in urban planning and related domains that draw upon the content of 3D models of urban scenes. Such 3D models can be used to visualize city images at multiple scales from individual buildings to entire cities prior to and after a change has occurred. This ability is of great importance in day-to-day work and special projects undertaken by planners, geo-designers, and architects. In this research, we implemented a novel approach to 3D building models for such matter, which included the integration of geographic information systems (GIS) and 3D Computer Graphics (3DCG) components that generate 3D house models from building footprints (polygons), and the automated generation of simple and complex roof geometries for rapid roof area damage reporting. These polygons (footprints) are usually orthogonal. A complicated orthogonal polygon can be partitioned into a set of rectangles. The proposed GIS and 3DCG integrated system partitions orthogonal building polygons into a set of rectangles and places rectangular roofs and box-shaped building bodies on these rectangles. Since technicians are drawing these polygons manually with digitizers, depending on aerial photos, not all building polygons are precisely orthogonal. But, when placing a set of boxes as building bodies for creating the buildings, there may be gaps or overlaps between these boxes if building polygons are not precisely orthogonal. In our proposal, after approximately orthogonal building polygons are partitioned and rectified into a set of mutually orthogonal rectangles, each rectangle knows which rectangle is adjacent to and which edge of the rectangle is adjacent to, which will avoid unwanted intersection of windows and doors when building bodies combined.