 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MonoGRNet: A General Framework for Monocular 3D Object Detection
Apr 18, 2021
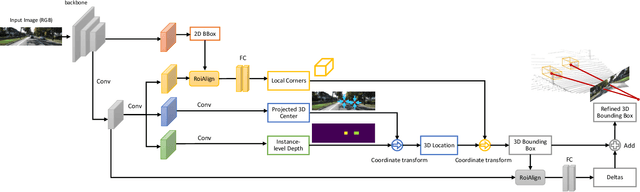
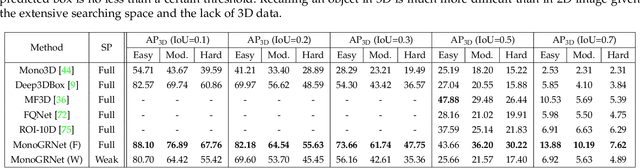
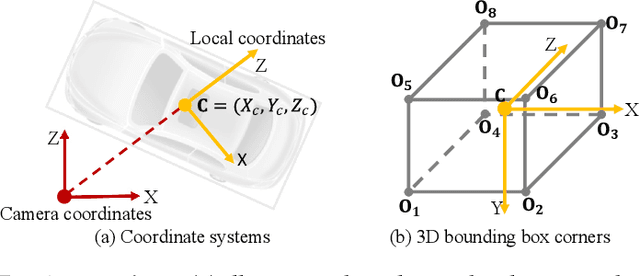
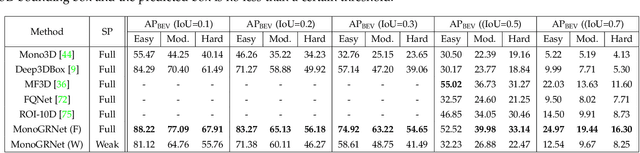
Detecting and localizing objects in the real 3D space, which plays a crucial role in scene understanding, is particularly challenging given only a monocular image due to the geometric information loss during imagery projection. We propose MonoGRNet for the amodal 3D object detection from a monocular image via geometric reasoning in both the observed 2D projection and the unobserved depth dimension. MonoGRNet decomposes the monocular 3D object detection task into four sub-tasks including 2D object detection, instance-level depth estimation, projected 3D center estimation and local corner regression. The task decomposition significantly facilitates the monocular 3D object detection, allowing the target 3D bounding boxes to be efficiently predicted in a single forward pass, without using object proposals, post-processing or the computationally expensive pixel-level depth estimation utilized by previous methods. In addition, MonoGRNet flexibly adapts to both fully and weakly supervised learning, which improves the feasibility of our framework in diverse settings. Experiments are conducted on KITTI, Cityscapes and MS COCO datasets. Results demonstrate the promising performance of our framework in various scenarios.
UniParma at SemEval-2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
Apr 09, 2021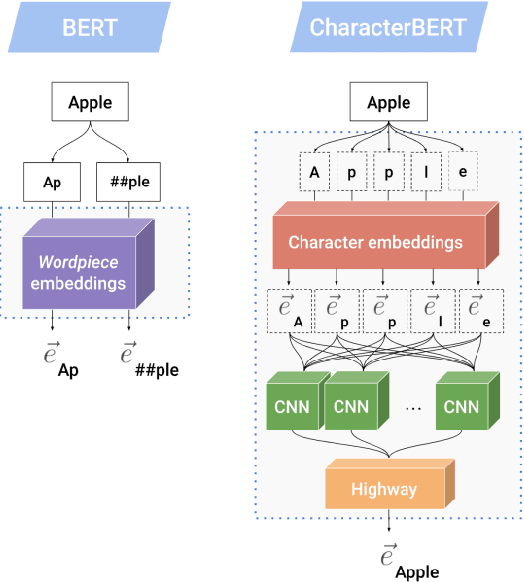

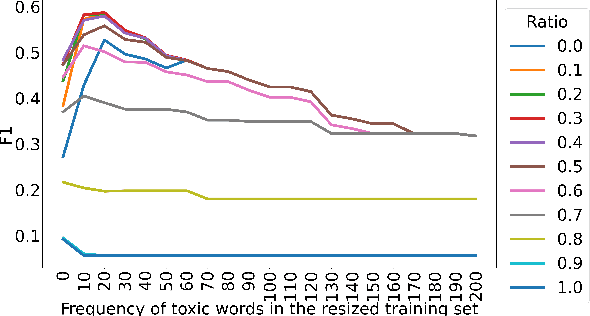
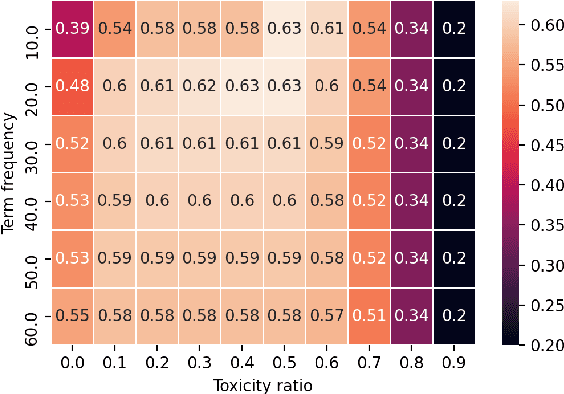
With the ever-increasing availability of digital information, toxic content is also on the rise. Therefore, the detection of this type of language is of paramount importance. We tackle this problem utilizing a combination of a state-of-the-art pre-trained language model (CharacterBERT) and a traditional bag-of-words technique. Since the content is full of toxic words that have not been written according to their dictionary spelling, attendance to individual characters is crucial. Therefore, we use CharacterBERT to extract features based on the word characters. It consists of a CharacterCNN module that learns character embeddings from the context. These are, then, fed into the well-known BERT architecture. The bag-of-words method, on the other hand, further improves upon that by making sure that some frequently used toxic words get labeled accordingly. With a 4 percent difference from the first team, our system ranked 36th in the competition. The code is available for further re-search and reproduction of the results.
Response to NITRD, NCO, NSF Request for Information on "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan"
Nov 05, 2019We present a response to the 2018 Request for Information (RFI) from the NITRD, NCO, NSF regarding the "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan." Through this document, we provide a response to the question of whether and how the National Artificial Intelligence Research and Development Strategic Plan (NAIRDSP) should be updated from the perspective of Fermilab, America's premier national laboratory for High Energy Physics (HEP). We believe the NAIRDSP should be extended in light of the rapid pace of development and innovation in the field of Artificial Intelligence (AI) since 2016, and present our recommendations below. AI has profoundly impacted many areas of human life, promising to dramatically reshape society --- e.g., economy, education, science --- in the coming years. We are still early in this process. It is critical to invest now in this technology to ensure it is safe and deployed ethically. Science and society both have a strong need for accuracy, efficiency, transparency, and accountability in algorithms, making investments in scientific AI particularly valuable. Thus far the US has been a leader in AI technologies, and we believe as a national Laboratory it is crucial to help maintain and extend this leadership. Moreover, investments in AI will be important for maintaining US leadership in the physical sciences.
Learning Discrete Representations via Information Maximizing Self-Augmented Training
Jun 14, 2017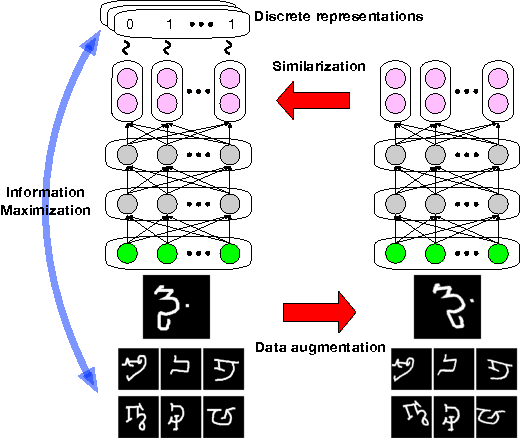
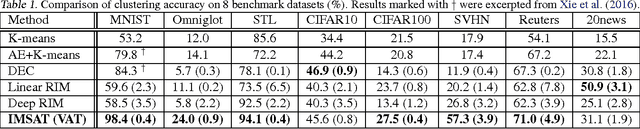


Learning discrete representations of data is a central machine learning task because of the compactness of the representations and ease of interpretation. The task includes clustering and hash learning as special cases. Deep neural networks are promising to be used because they can model the non-linearity of data and scale to large datasets. However, their model complexity is huge, and therefore, we need to carefully regularize the networks in order to learn useful representations that exhibit intended invariance for applications of interest. To this end, we propose a method called Information Maximizing Self-Augmented Training (IMSAT). In IMSAT, we use data augmentation to impose the invariance on discrete representations. More specifically, we encourage the predicted representations of augmented data points to be close to those of the original data points in an end-to-end fashion. At the same time, we maximize the information-theoretic dependency between data and their predicted discrete representations. Extensive experiments on benchmark datasets show that IMSAT produces state-of-the-art results for both clustering and unsupervised hash learning.
RL-IoT: Towards IoT Interoperability via Reinforcement Learning
May 03, 2021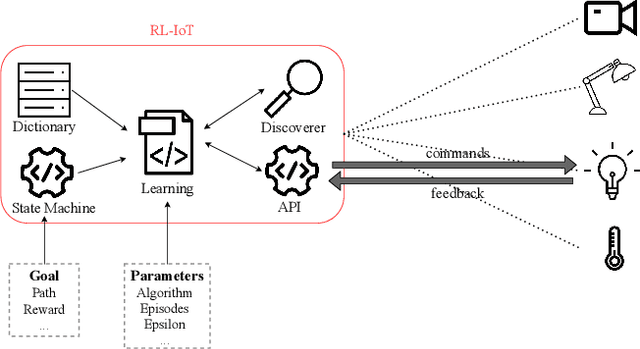



Our life is getting filled by Internet of Things (IoT) devices. These devices often rely on closed or poorly documented protocols, with unknown formats and semantics. Learning how to interact with such devices in an autonomous manner is key for interoperability and automatic verification of their capabilities. In this paper, we propose RL-IoT -- a system that explores how to automatically interact with possibly unknown IoT devices. We leverage reinforcement learning (RL) to understand the semantics of protocol messages and to control the device to reach a given goal, while minimizing the number of interactions. We assume only to know a database of possible IoT protocol messages, whose semantics are however unknown. RL-IoT exchanges messages with the target IoT device, learning those commands that are useful to reach the given goal. Our results show that RL-IoT is able to solve simple and complex tasks. With properly tuned parameters, RL-IoT learns how to perform actions with the target device, a Yeelight smart bulb for our case study, completing non-trivial patterns with as few as 400 interactions. RL-IoT opens the opportunity to use RL to automatically explore how to interact with IoT protocols with limited information, and paving the road for interoperable systems.
Machine Learning based Lie Detector applied to a Collected and Annotated Dataset
Apr 26, 2021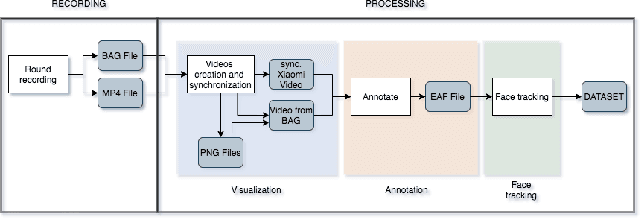



Lie detection is considered a concern for everyone in their day to day life given its impact on human interactions. Hence, people are normally not only pay attention to what their interlocutors are saying but also try to inspect their visual appearances, including faces, to find any signs that indicate whether the person is telling the truth or not. Unfortunately to date, the automatic lie detection, which may help us to understand this lying characteristics are still fairly limited. Mainly due to lack of a lie dataset and corresponding evaluations. In this work, we have collected a dataset that contains annotated images and 3D information of different participants faces during a card game that incentivise the lying. Using our collected dataset, we evaluated several types of machine learning based lie detector through generalize, personal and cross lie lie experiments. In these experiments, we showed the superiority of deep learning based model in recognizing the lie with best accuracy of 57\% for generalized task and 63\% when dealing with a single participant. Finally, we also highlight the limitation of the deep learning based lie detector when dealing with different types of lie tasks.
End-to-End Information Extraction without Token-Level Supervision
Jul 16, 2017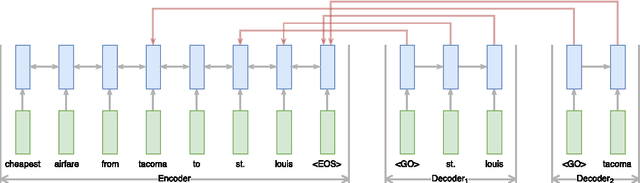
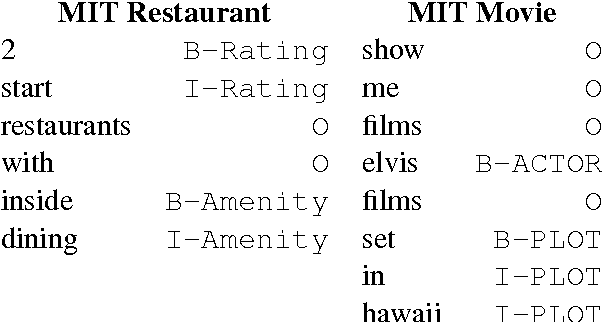

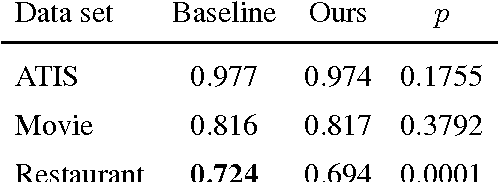
Most state-of-the-art information extraction approaches rely on token-level labels to find the areas of interest in text. Unfortunately, these labels are time-consuming and costly to create, and consequently, not available for many real-life IE tasks. To make matters worse, token-level labels are usually not the desired output, but just an intermediary step. End-to-end (E2E) models, which take raw text as input and produce the desired output directly, need not depend on token-level labels. We propose an E2E model based on pointer networks, which can be trained directly on pairs of raw input and output text. We evaluate our model on the ATIS data set, MIT restaurant corpus and the MIT movie corpus and compare to neural baselines that do use token-level labels. We achieve competitive results, within a few percentage points of the baselines, showing the feasibility of E2E information extraction without the need for token-level labels. This opens up new possibilities, as for many tasks currently addressed by human extractors, raw input and output data are available, but not token-level labels.
Design a Technology Based on the Fusion of Genetic Algorithm, Neural network and Fuzzy logic
Feb 16, 2021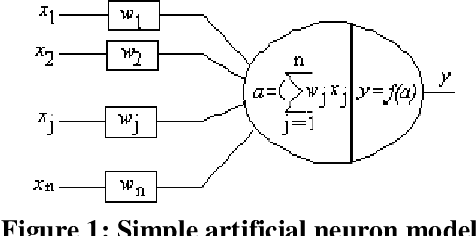
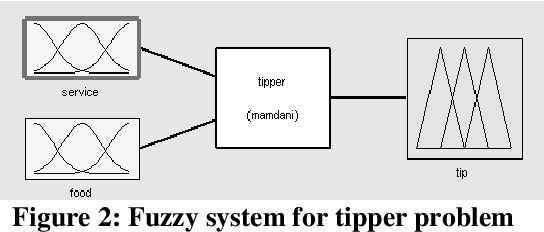
This paper describes the design and development of a prototype technique for artificial intelligence based on the fusion of genetic algorithm, neural network and fuzzy logic. It starts by establishing a relationship between the neural network and fuzzy logic. Then, it combines the genetic algorithm with them. Information fusions are at the confidence level, where matching scores can be reported and discussed. The technique is called the Genetic Neuro-Fuzzy (GNF). It can be used for high accuracy real-time environments.
Automatic Breast Lesion Detection in Ultrafast DCE-MRI Using Deep Learning
Feb 07, 2021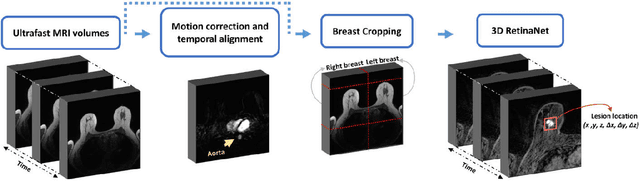
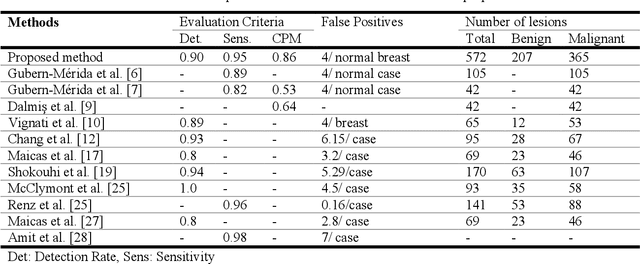

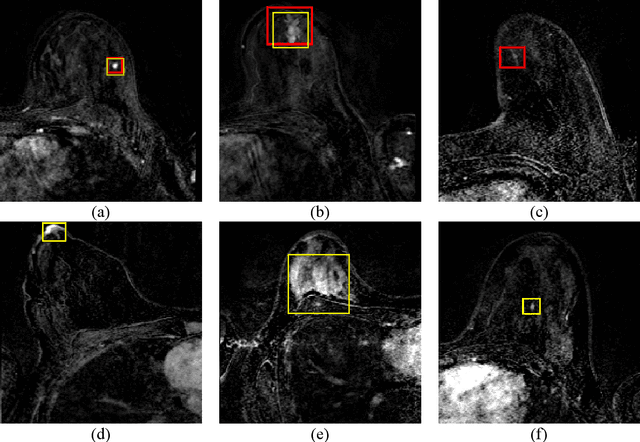
Purpose: We propose a deep learning-based computer-aided detection (CADe) method to detect breast lesions in ultrafast DCE-MRI sequences. This method uses both the three-dimensional spatial information and temporal information obtained from the early-phase of the dynamic acquisition.Methods: The proposed CADe method, based on a modified 3D RetinaNet model, operates on ultrafast T1 weighted sequences, which are preprocessed for motion compensation, temporal normalization, and are cropped before passing into the model. The model is optimized to enable the detection of relatively small breast lesions in a screening setting, focusing on detection of lesions that are harder to differentiate from confounding structures inside the breast.Results: The method was developed based on a dataset consisting of 489 ultrafast MRI studies obtained from 462 patients containing a total of 572 lesions (365 malignant, 207 benign) and achieved a detection rate, sensitivity, and detection rate of benign lesions of 0.90, 0.95, and 0.86 at 4 false positives per normal breast with a 10-fold cross-validation, respectively.Conclusions: The deep learning architecture used for the proposed CADe application can efficiently detect benign and malignant lesions on ultrafast DCE-MRI. Furthermore, utilizing the less visible hard-to detect-lesions in training improves the learning process and, subsequently, detection of malignant breast lesions.
OSKDet: Towards Orientation-sensitive Keypoint Localization for Rotated Object Detection
Apr 18, 2021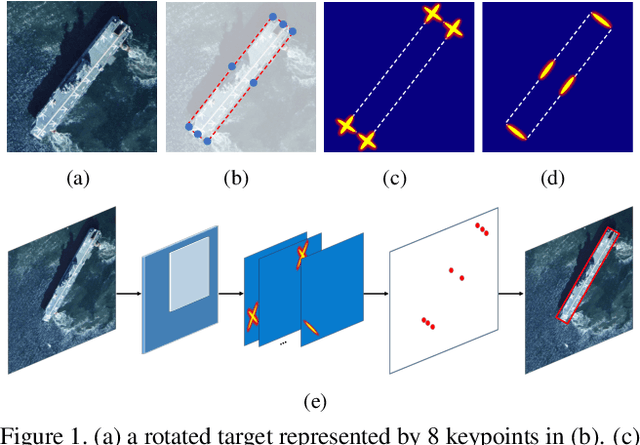

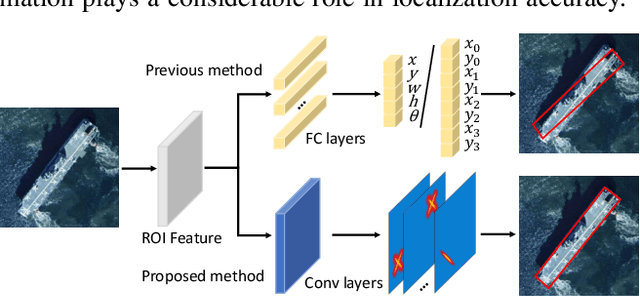
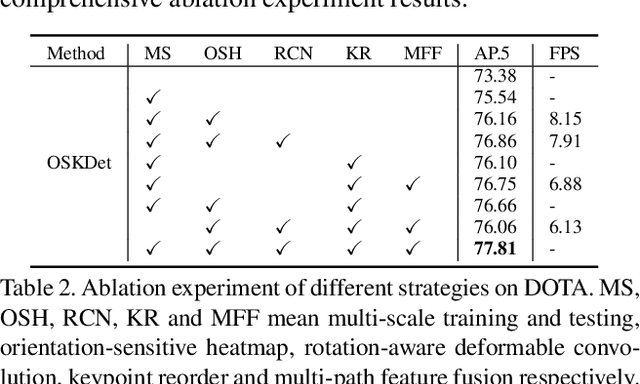
Rotated object detection is a challenging issue of computer vision field. Loss of spatial information and confusion of parametric order have been the bottleneck for rotated detection accuracy. In this paper, we propose an orientation-sensitive keypoint based rotated detector OSKDet. We adopt a set of keypoints to characterize the target and predict the keypoint heatmap on ROI to form a rotated target. By proposing the orientation-sensitive heatmap, OSKDet could learn the shape and direction of rotated target implicitly and has stronger modeling capabilities for target representation, which improves the localization accuracy and acquires high quality detection results. To extract highly effective features at border areas, we design a rotation-aware deformable convolution module. Furthermore, we explore a new keypoint reorder algorithm and feature fusion module based on the angle distribution to eliminate the confusion of keypoint order. Experimental results on several public benchmarks show the state-of-the-art performance of OSKDet. Specifically, we achieve an AP of 77.81% on DOTA, 89.91% on HRSC2016, and 97.18% on UCAS-AOD, respectively.