 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Honest-but-Curious Nets: Sensitive Attributes of Private Inputs can be Secretly Coded into the Entropy of Classifiers' Outputs
May 25, 2021
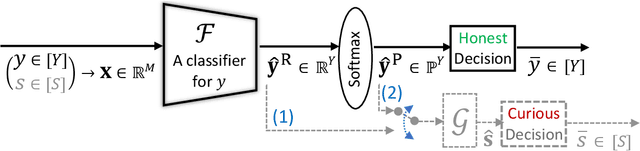
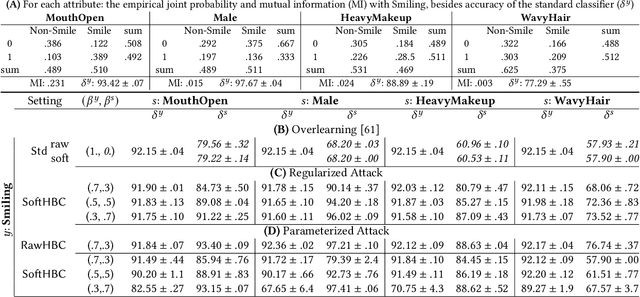
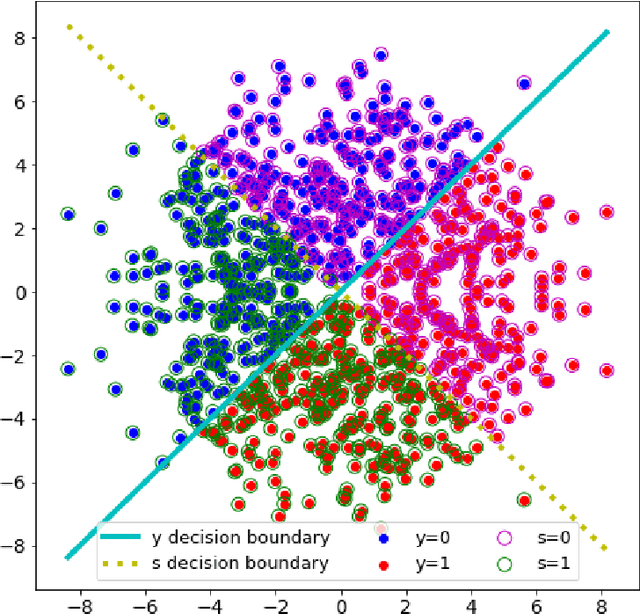
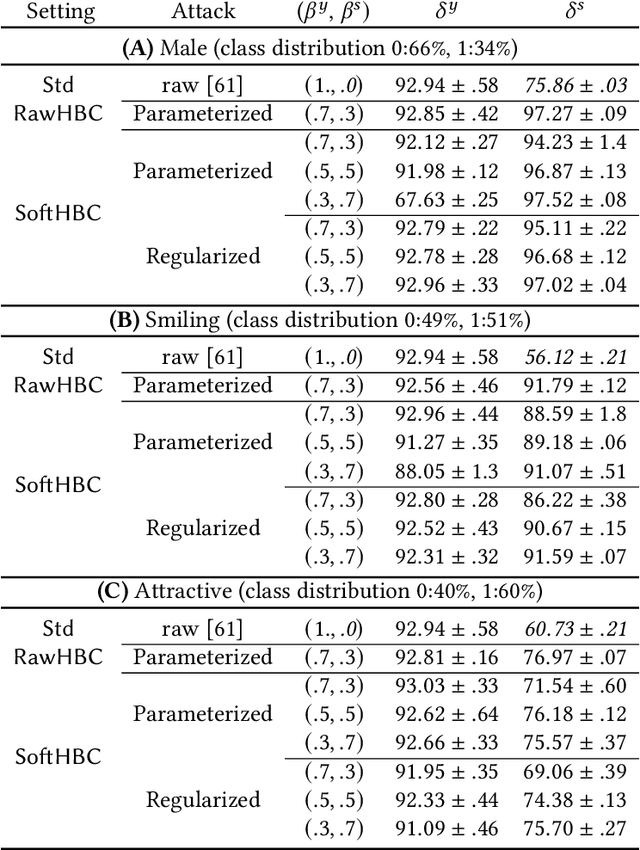
It is known that deep neural networks, trained for the classification of a non-sensitive target attribute, can reveal sensitive attributes of their input data; through features of different granularity extracted by the classifier. We, taking a step forward, show that deep classifiers can be trained to secretly encode a sensitive attribute of users' input data, at inference time, into the classifier's outputs for the target attribute. An attack that works even if users have a white-box view of the classifier, and can keep all internal representations hidden except for the classifier's estimation of the target attribute. We introduce an information-theoretical formulation of such adversaries and present efficient empirical implementations for training honest-but-curious (HBC) classifiers based on this formulation: deep models that can be accurate in predicting the target attribute, but also can utilize their outputs to secretly encode a sensitive attribute. Our evaluations on several tasks in real-world datasets show that a semi-trusted server can build a classifier that is not only perfectly honest but also accurately curious. Our work highlights a vulnerability that can be exploited by malicious machine learning service providers to attack their user's privacy in several seemingly safe scenarios; such as encrypted inferences, computations at the edge, or private knowledge distillation. We conclude by showing the difficulties in distinguishing between standard and HBC classifiers and discussing potential proactive defenses against this vulnerability of deep classifiers.
An Improved Attention for Visual Question Answering
Nov 04, 2020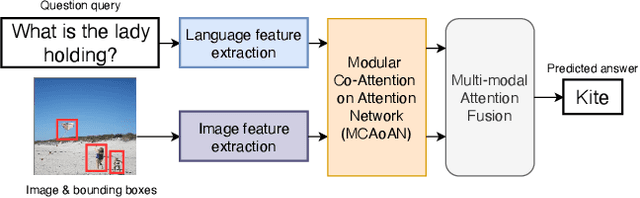
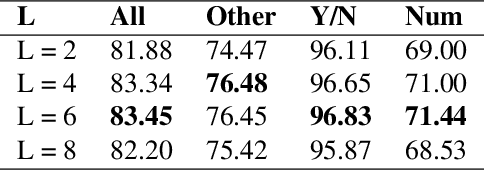
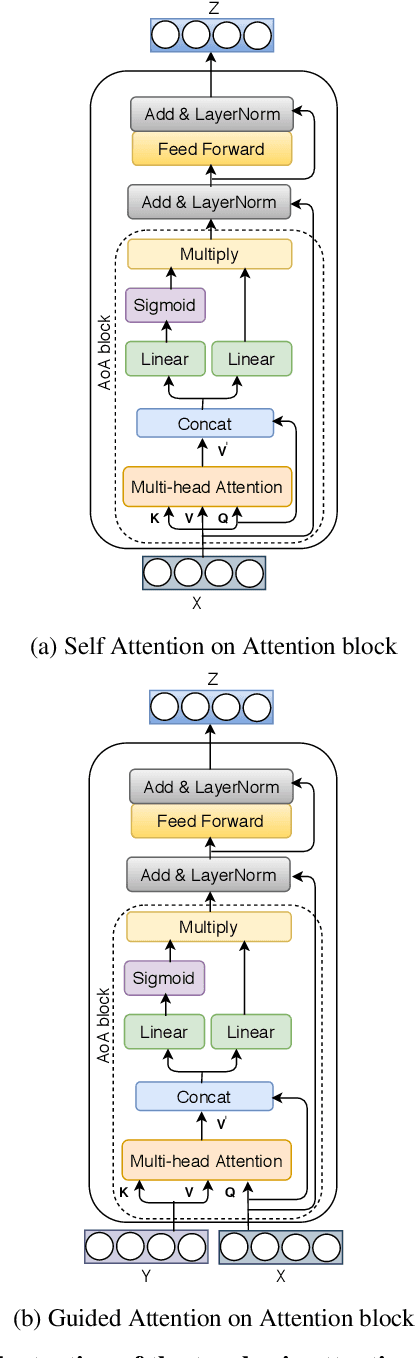

We consider the problem of Visual Question Answering (VQA). Given an image and a free-form, open-ended, question, expressed in natural language, the goal of VQA system is to provide accurate answer to this question with respect to the image. The task is challenging because it requires simultaneous and intricate understanding of both visual and textual information. Attention, which captures intra- and inter-modal dependencies, has emerged as perhaps the most widely used mechanism for addressing these challenges. In this paper, we propose an improved attention-based architecture to solve VQA. We incorporate an Attention on Attention (AoA) module within encoder-decoder framework, which is able to determine the relation between attention results and queries. Attention module generates weighted average for each query. On the other hand, AoA module first generates an information vector and an attention gate using attention results and current context; and then adds another attention to generate final attended information by multiplying the two. We also propose multimodal fusion module to combine both visual and textual information. The goal of this fusion module is to dynamically decide how much information should be considered from each modality. Extensive experiments on VQA-v2 benchmark dataset show that our method achieves the state-of-the-art performance.
Schematic Memory Persistence and Transience for Efficient and Robust Continual Learning
May 05, 2021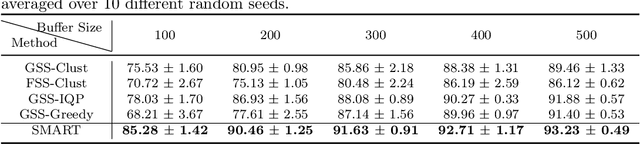
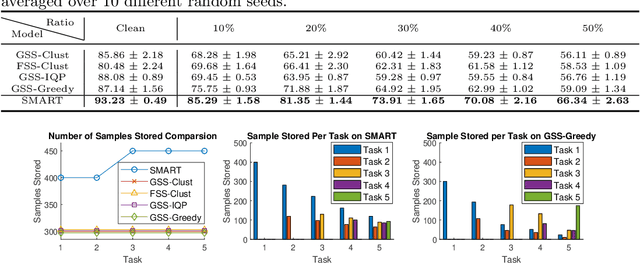
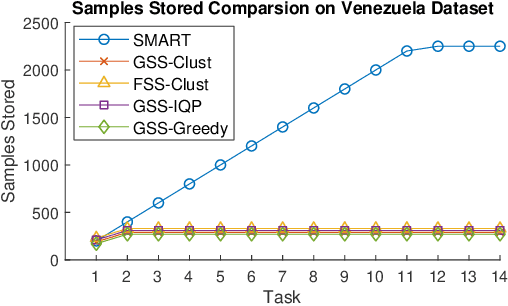
Continual learning is considered a promising step towards next-generation Artificial Intelligence (AI), where deep neural networks (DNNs) make decisions by continuously learning a sequence of different tasks akin to human learning processes. It is still quite primitive, with existing works focusing primarily on avoiding (catastrophic) forgetting. However, since forgetting is inevitable given bounded memory and unbounded task loads, 'how to reasonably forget' is a problem continual learning must address in order to reduce the performance gap between AIs and humans, in terms of 1) memory efficiency, 2) generalizability, and 3) robustness when dealing with noisy data. To address this, we propose a novel ScheMAtic memory peRsistence and Transience (SMART) framework for continual learning with external memory that builds on recent advances in neuroscience. The efficiency and generalizability are enhanced by a novel long-term forgetting mechanism and schematic memory, using sparsity and 'backward positive transfer' constraints with theoretical guarantees on the error bound. Robust enhancement is achieved using a novel short-term forgetting mechanism inspired by background information-gated learning. Finally, an extensive experimental analysis on both benchmark and real-world datasets demonstrates the effectiveness and efficiency of our model.
A High Accuracy Image Hashing and Random Forest Classifier for Crack Detection in Concrete Surface Images
Jun 10, 2021
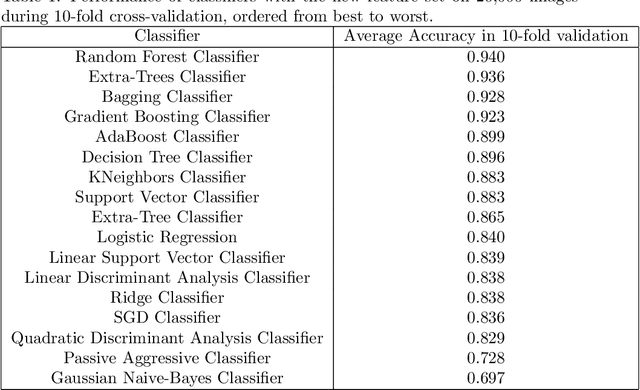
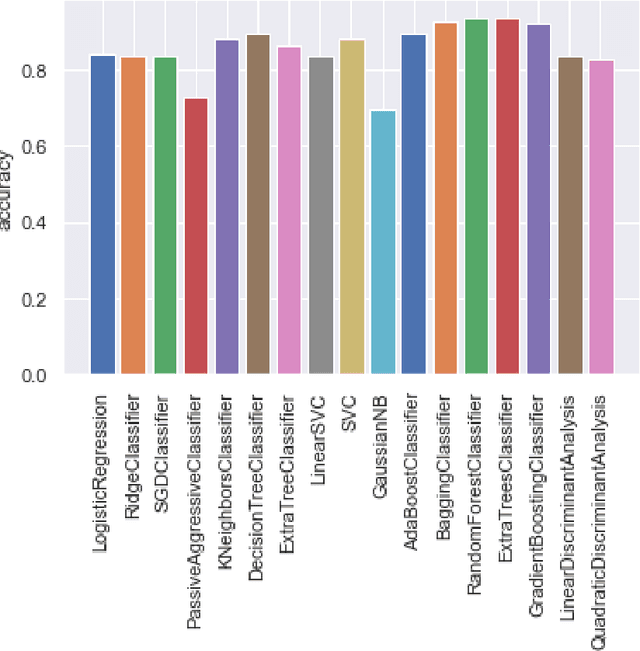
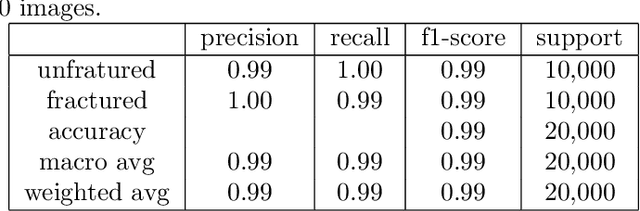
Automatic detection of cracks in concrete surfaces based on image processing is a clear trend in modern civil engineering applications. Most infrastructure is made of concrete and cracks reveal degradation of the structural integrity of the facilities, which can lead to extreme structural failures. There are many approaches to overcome the difficulties in image-based crack detection, ranging from the pre-processing of the input image to the proper adjustment of efficient classifiers, passing through the essential feature selection step. This paper is related to the process of constructing features from images to allow a classifier to find the boundaries between images with and without cracks. The most common approaches to feature extraction are the convolutional techniques to extract relevant positional information from images and the filters for edge detection or background removal. Here we apply hashing techniques for the first time used for features extraction in this problem. The study of the classification capacity of hashes is carried out by comparing 5 different hash algorithms, 2 of which are based on wavelets. The effect of applying the z-transform on the images before calculating the hashes was also studied, which totals the study of 10 new features for this problem. A comparative study of 17 different algorithms from the scikit-learn library was carried out. The results show that 9 of the 10 features are relevant to the problem, as well as that the accuracy of the classifiers varied between 0.697 for the Naive-Bayes Gaussian classifier and 0.99 for the Random Forest (RF) classifier. The feature extraction algorithm developed in this work and the RF classifier algorithm is suitable for embedded applications, for example in inspection drones, as long as they are highly accurate and computationally light, both in terms of memory and processing time.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020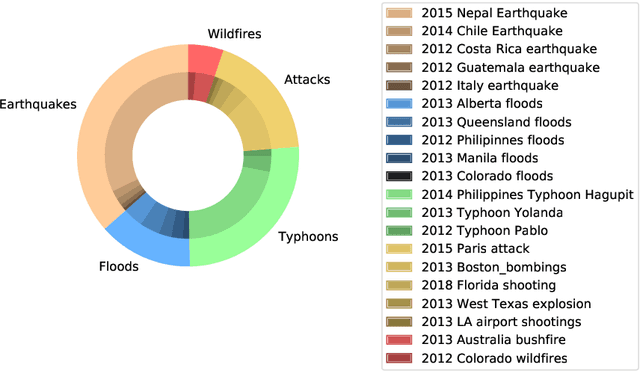

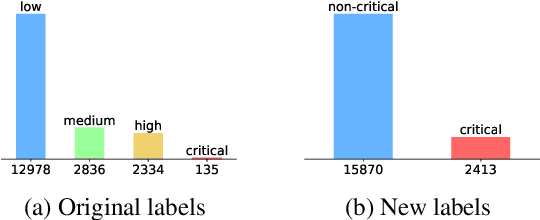
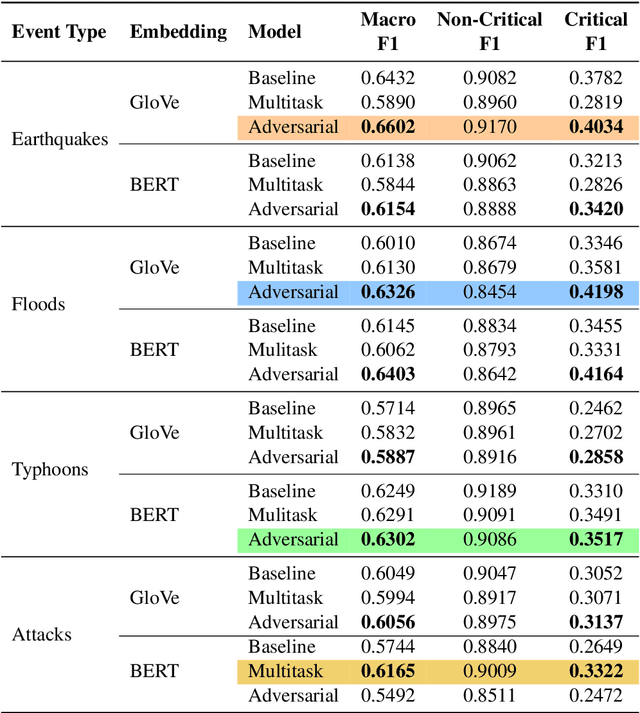
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.
Multi-Modal Loop Closing in Unstructured Planetary Environments with Visually Enriched Submaps
May 05, 2021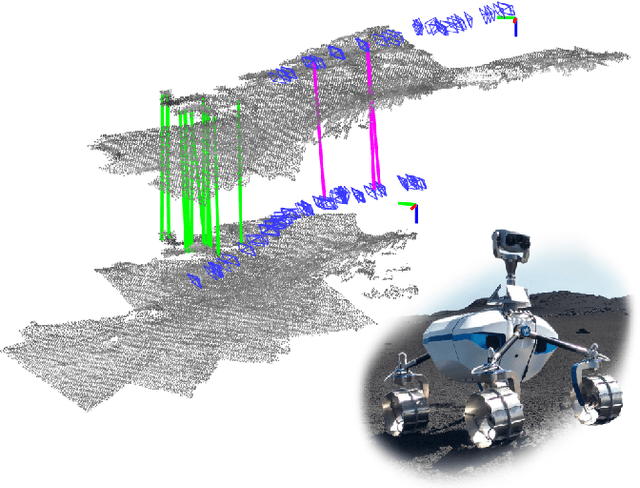
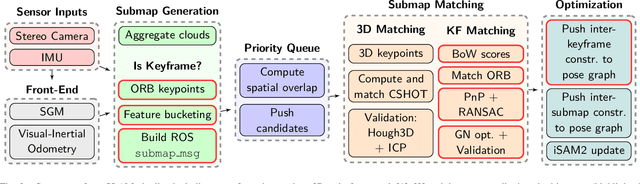

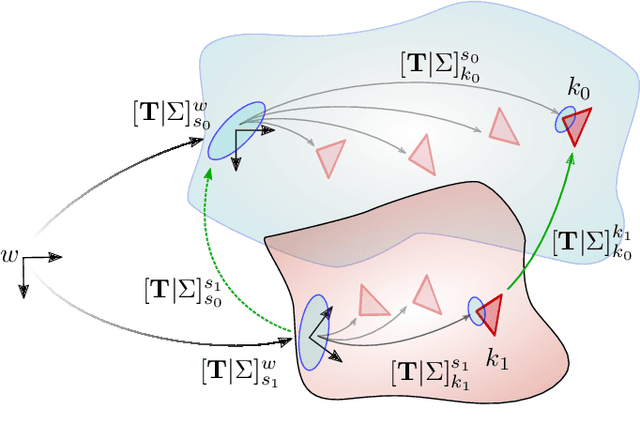
Future planetary missions will rely on rovers that can autonomously explore and navigate in unstructured environments. An essential element is the ability to recognize places that were already visited or mapped. In this work we leverage the ability of stereo cameras to provide both visual and depth information, guiding the search and validation of loop closures from a multi-modal perspective. We propose to augment submaps that are created by aggregating stereo point clouds, with visual keyframes. Point clouds matches are found by comparing CSHOT descriptors and validated by clustering while visual matches are established by comparing keyframes using Bag-of-Words (BoW) and ORB descriptors. The relative transformations resulting from both keyframe and point cloud matches are then fused to provide pose constraints between submaps in our graph-based SLAM framework. Using the LRU rover, we performed several tests in both an indoor laboratory environment as well as a challenging planetary analog environment on Mount Etna, Italy. These environments consist of areas where either keyframes or point clouds alone fail to provide adequate matches, thus demonstrating the benefit of the proposed multi-modal approach.
Extracting Predictive Information from Heterogeneous Data Streams using Gaussian Processes
Jul 11, 2018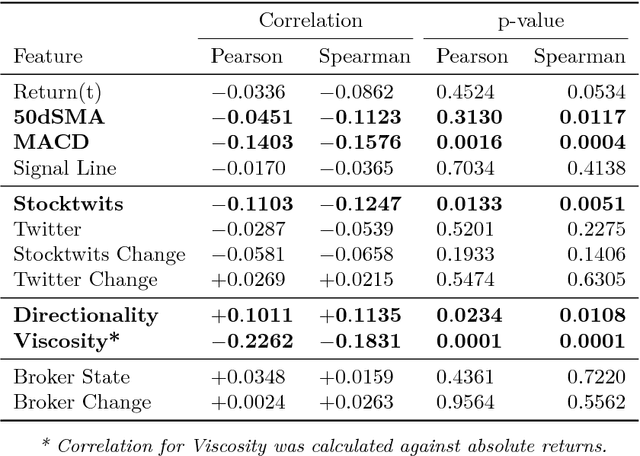
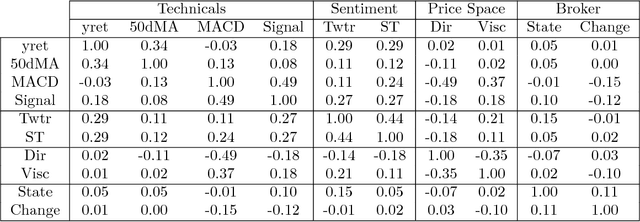
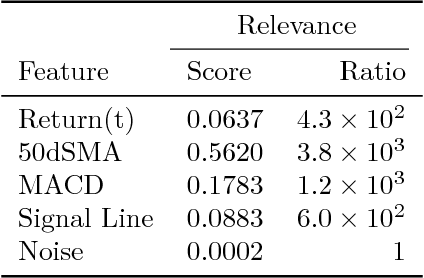
Financial markets are notoriously complex environments, presenting vast amounts of noisy, yet potentially informative data. We consider the problem of forecasting financial time series from a wide range of information sources using online Gaussian Processes with Automatic Relevance Determination (ARD) kernels. We measure the performance gain, quantified in terms of Normalised Root Mean Square Error (NRMSE), Median Absolute Deviation (MAD) and Pearson correlation, from fusing each of four separate data domains: time series technicals, sentiment analysis, options market data and broker recommendations. We show evidence that ARD kernels produce meaningful feature rankings that help retain salient inputs and reduce input dimensionality, providing a framework for sifting through financial complexity. We measure the performance gain from fusing each domain's heterogeneous data streams into a single probabilistic model. In particular our findings highlight the critical value of options data in mapping out the curvature of price space and inspire an intuitive, novel direction for research in financial prediction.
A Novel Falling-Ball Algorithm for Image Segmentation
May 12, 2021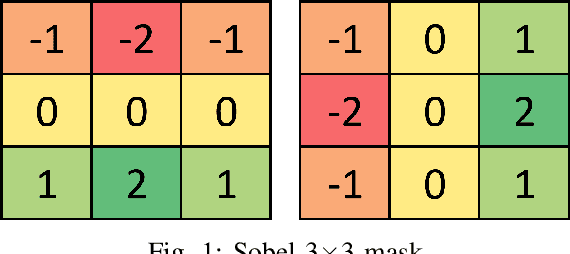
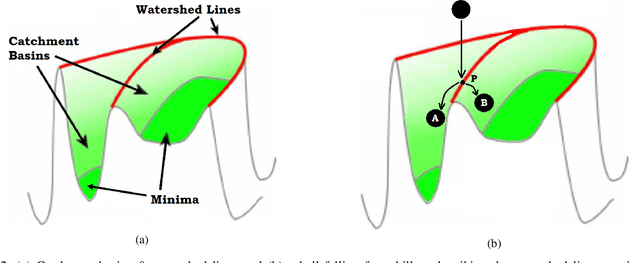
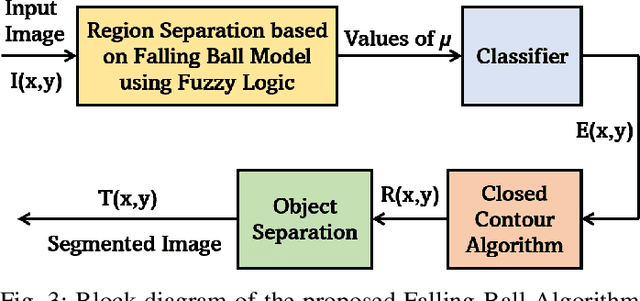
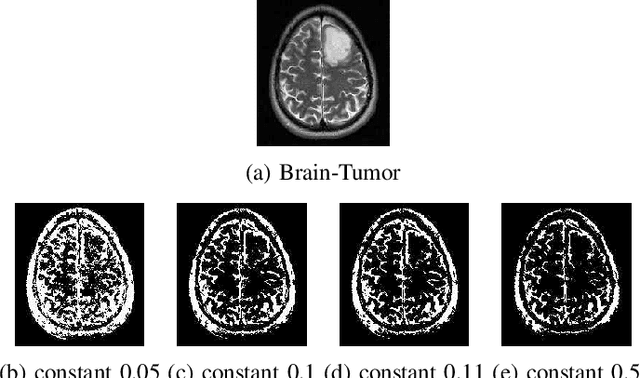
Image segmentation refers to the separation of objects from the background, and has been one of the most challenging aspects of digital image processing. Practically it is impossible to design a segmentation algorithm which has 100% accuracy, and therefore numerous segmentation techniques have been proposed in the literature, each with certain limitations. In this paper, a novel Falling-Ball algorithm is presented, which is a region-based segmentation algorithm, and an alternative to watershed transform (based on waterfall model). The proposed algorithm detects the catchment basins by assuming that a ball falling from hilly terrains will stop in a catchment basin. Once catchment basins are identified, the association of each pixel with one of the catchment basin is obtained using multi-criterion fuzzy logic. Edges are constructed by dividing image into different catchment basins with the help of a membership function. Finally closed contour algorithm is applied to find closed regions and objects within closed regions are segmented using intensity information. The performance of the proposed algorithm is evaluated both objectively as well as subjectively. Simulation results show that the proposed algorithms gives superior performance over conventional Sobel edge detection methods and the watershed segmentation algorithm. For comparative analysis, various comparison methods are used for demonstrating the superiority of proposed methods over existing segmentation methods.
A Deep Learning Approach to Mapping Irrigation: IrrMapper-U-Net
Mar 04, 2021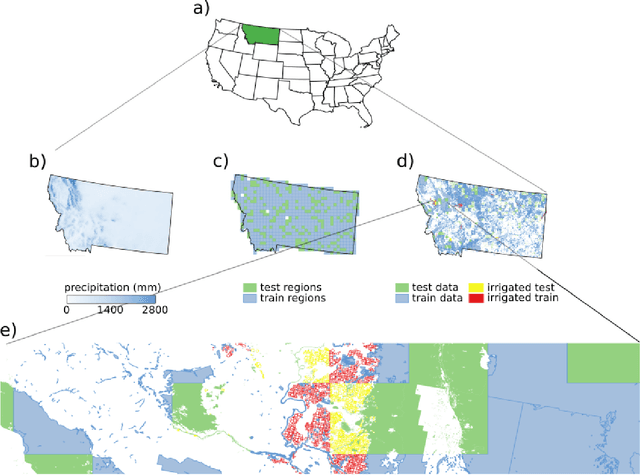
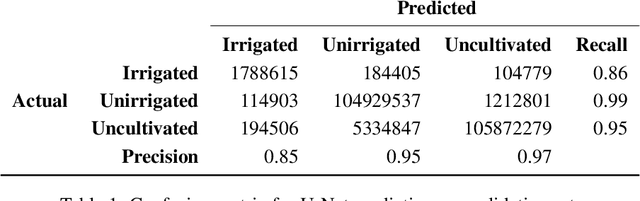
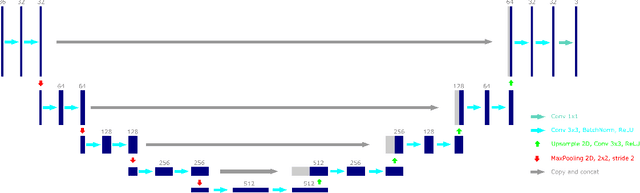

Accurate maps of irrigation are essential for understanding and managing water resources. We present a new method of mapping irrigation and demonstrate its accuracy for the state of Montana from years 2000-2019. The method is based off of an ensemble of convolutional neural networks that use reflectance information from Landsat imagery to classify irrigated pixels, that we call IrrMapper-U-Net. The methodology does not rely on extensive feature engineering and does not condition the classification with land use information from existing geospatial datasets. The ensemble does not need exhaustive hyperparameter tuning and the analysis pipeline is lightweight enough to be implemented on a personal computer. Furthermore, the proposed methodology provides an estimate of the uncertainty associated with classification. We evaluated our methodology and the resulting irrigation maps using a highly accurate novel spatially-explicit ground truth data set, using county-scale USDA surveys of irrigation extent, and using cadastral surveys. We found that that our method outperforms other methods of mapping irrigation in Montana in terms of overall accuracy and precision. We found that our method agrees better statewide with the USDA National Agricultural Statistics Survey estimates of irrigated area compared to other methods, and has far fewer errors of commission in rainfed agriculture areas. The method learns to mask clouds and ignore Landsat 7 scan-line failures without supervision, reducing the need for preprocessing data. This methodology has the potential to be applied across the entire United States and for the complete Landsat record.
An unsupervised deep learning framework for medical image denoising
Mar 11, 2021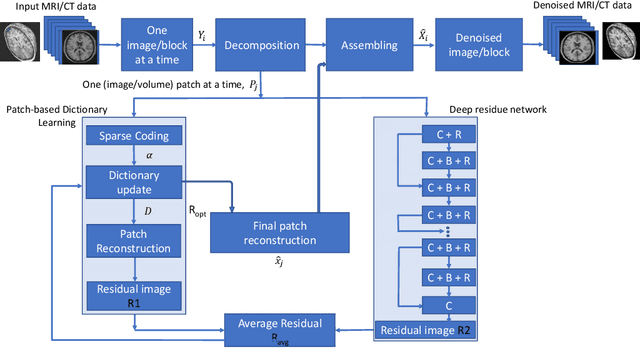

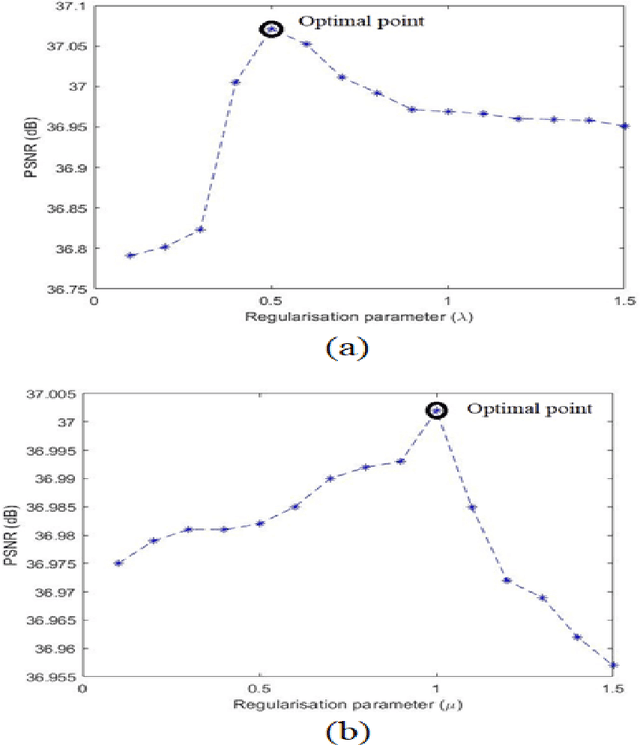
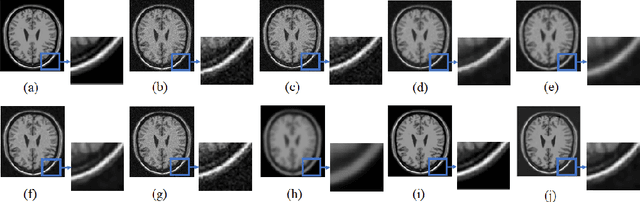
Medical image acquisition is often intervented by unwanted noise that corrupts the information content. This paper introduces an unsupervised medical image denoising technique that learns noise characteristics from the available images and constructs denoised images. It comprises of two blocks of data processing, viz., patch-based dictionaries that indirectly learn the noise and residual learning (RL) that directly learns the noise. The model is generalized to account for both 2D and 3D images considering different medical imaging instruments. The images are considered one-by-one from the stack of MRI/CT images as well as the entire stack is considered, and decomposed into overlapping image/volume patches. These patches are given to the patch-based dictionary learning to learn noise characteristics via sparse representation while given to the RL part to directly learn the noise properties. K-singular value decomposition (K-SVD) algorithm for sparse representation is used for training patch-based dictionaries. On the other hand, residue in the patches is trained using the proposed deep residue network. Iterating on these two parts, an optimum noise characterization for each image/volume patch is captured and in turn it is subtracted from the available respective image/volume patch. The obtained denoised image/volume patches are finally assembled to a denoised image or 3D stack. We provide an analysis of the proposed approach with other approaches. Experiments on MRI/CT datasets are run on a GPU-based supercomputer and the comparative results show that the proposed algorithm preserves the critical information in the images as well as improves the visual quality of the images.