 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning non-parametric Markov networks with mutual information
Aug 08, 2017

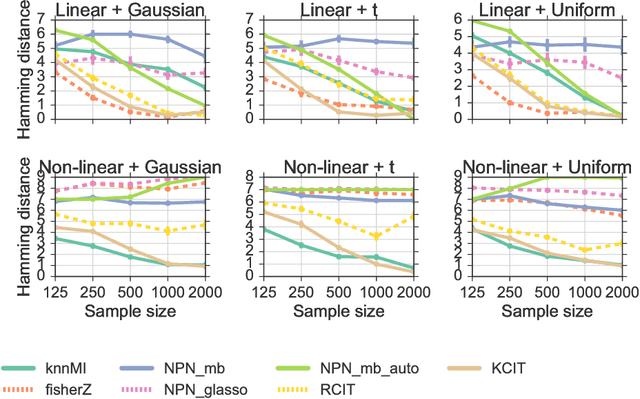
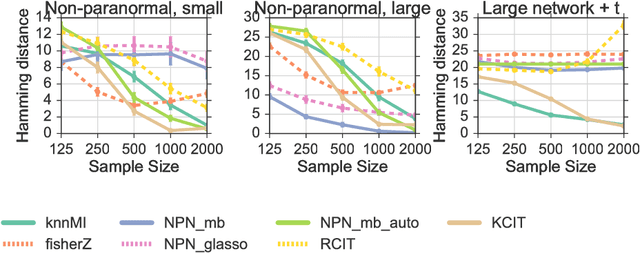
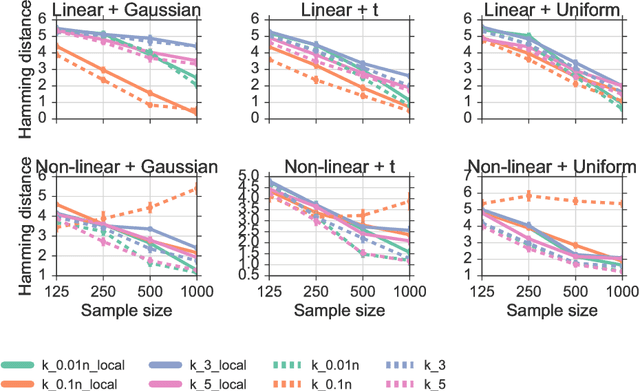
We propose a method for learning Markov network structures for continuous data without invoking any assumptions about the distribution of the variables. The method makes use of previous work on a non-parametric estimator for mutual information which is used to create a non-parametric test for multivariate conditional independence. This independence test is then combined with an efficient constraint-based algorithm for learning the graph structure. The performance of the method is evaluated on several synthetic data sets and it is shown to learn considerably more accurate structures than competing methods when the dependencies between the variables involve non-linearities.
Control of Stochastic Quantum Dynamics with Differentiable Programming
Jan 04, 2021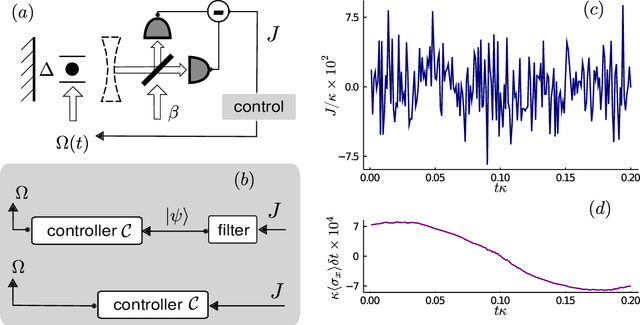
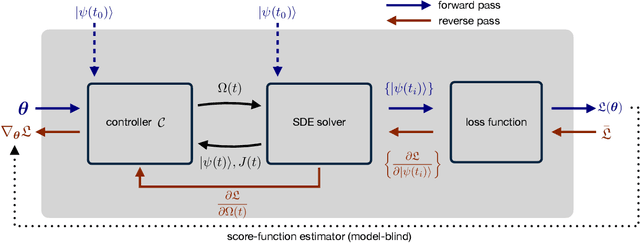
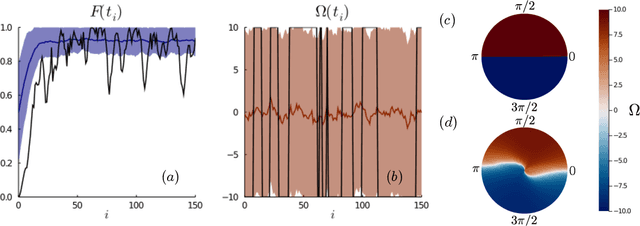
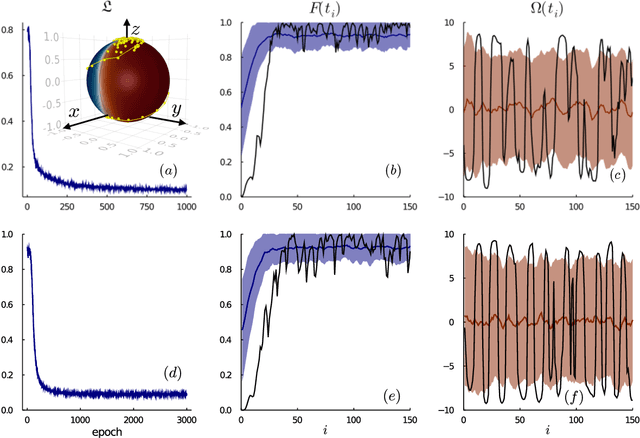
Controlling stochastic dynamics of a quantum system is an indispensable task in fields such as quantum information processing and metrology. Yet, there is no general ready-made approach to design efficient control strategies. Here, we propose a framework for the automated design of control schemes based on differentiable programming ($\partial \mathrm{P}$). We apply this approach to state preparation and stabilization of a qubit subjected to homodyne detection. To this end, we formulate the control task as an optimization problem where the loss function quantifies the distance from the target state and we employ neural networks (NNs) as controllers. The system's time evolution is governed by a stochastic differential equation (SDE). To implement efficient training, we backpropagate the gradient information from the loss function through the SDE solver using adjoint sensitivity methods. As a first example, we feed the quantum state to the controller and focus on different methods to obtain gradients. As a second example, we directly feed the homodyne detection signal to the controller. The instantaneous value of the homodyne current contains only very limited information on the actual state of the system, covered in unavoidable photon-number fluctuations. Despite the resulting poor signal-to-noise ratio, we can train our controller to prepare and stabilize the qubit to a target state with a mean fidelity around 85%. We also compare the solutions found by the NN to a hand-crafted control strategy.
Asymptotic Risk of Overparameterized Likelihood Models: Double Descent Theory for Deep Neural Networks
Mar 15, 2021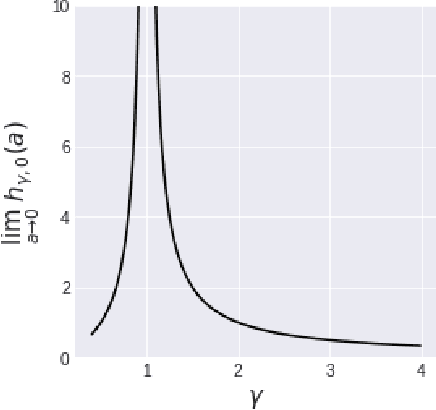
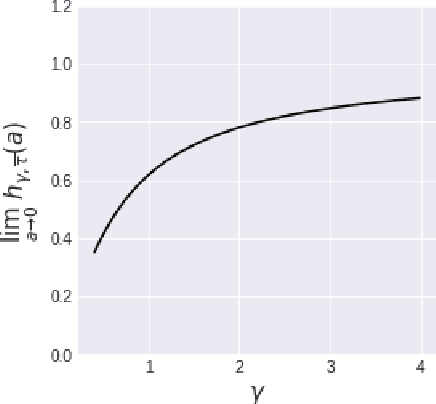
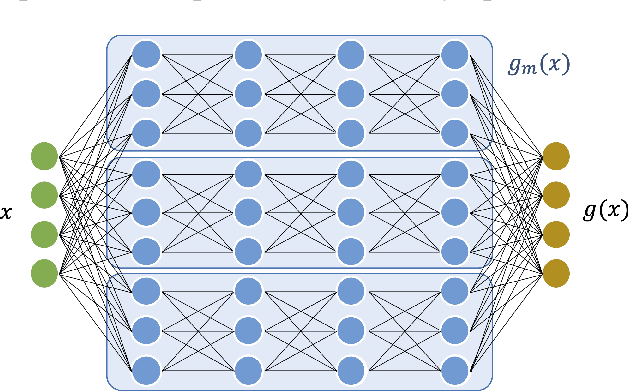
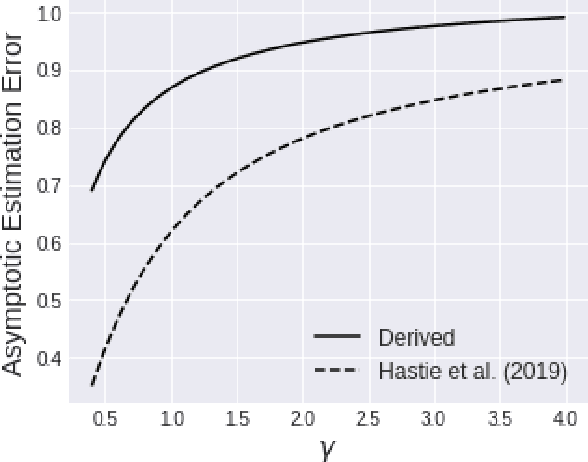
We investigate the asymptotic risk of a general class of overparameterized likelihood models, including deep models. The recent empirical success of large-scale models has motivated several theoretical studies to investigate a scenario wherein both the number of samples, $n$, and parameters, $p$, diverge to infinity and derive an asymptotic risk at the limit. However, these theorems are only valid for linear-in-feature models, such as generalized linear regression, kernel regression, and shallow neural networks. Hence, it is difficult to investigate a wider class of nonlinear models, including deep neural networks with three or more layers. In this study, we consider a likelihood maximization problem without the model constraints and analyze the upper bound of an asymptotic risk of an estimator with penalization. Technically, we combine a property of the Fisher information matrix with an extended Marchenko-Pastur law and associate the combination with empirical process techniques. The derived bound is general, as it describes both the double descent and the regularized risk curves, depending on the penalization. Our results are valid without the linear-in-feature constraints on models and allow us to derive the general spectral distributions of a Fisher information matrix from the likelihood. We demonstrate that several explicit models, such as parallel deep neural networks, ensemble learning, and residual networks, are in agreement with our theory. This result indicates that even large and deep models have a small asymptotic risk if they exhibit a specific structure, such as divisibility. To verify this finding, we conduct a real-data experiment with parallel deep neural networks. Our results expand the applicability of the asymptotic risk analysis, and may also contribute to the understanding and application of deep learning.
Sentiment and Emotion Classification of Epidemic Related Bilingual data from Social Media
May 04, 2021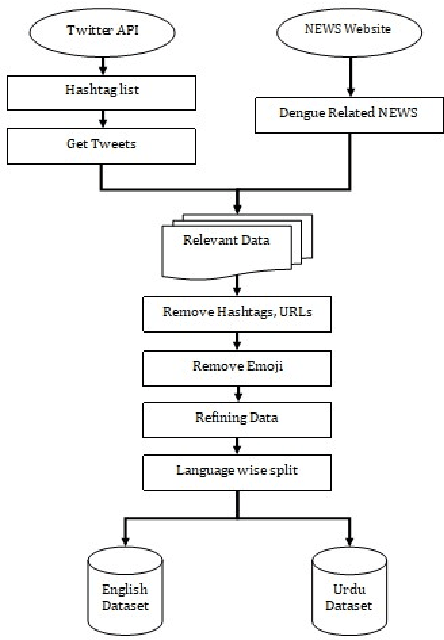
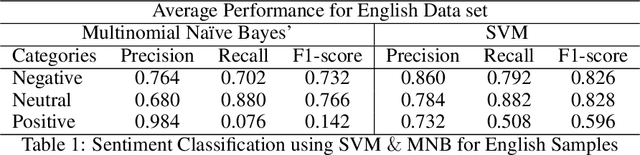
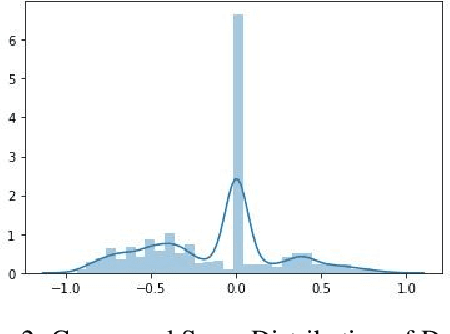
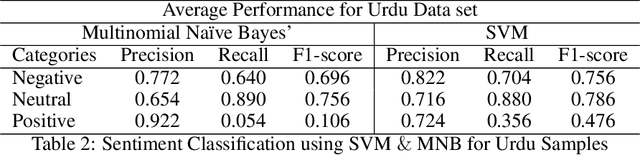
In recent years, sentiment analysis and emotion classification are two of the most abundantly used techniques in the field of Natural Language Processing (NLP). Although sentiment analysis and emotion classification are used commonly in applications such as analyzing customer reviews, the popularity of candidates contesting in elections, and comments about various sporting events; however, in this study, we have examined their application for epidemic outbreak detection. Early outbreak detection is the key to deal with epidemics effectively, however, the traditional ways of outbreak detection are time-consuming which inhibits prompt response from the respective departments. Social media platforms such as Twitter, Facebook, Instagram, etc. allow the users to express their thoughts related to different aspects of life, and therefore, serve as a substantial source of information in such situations. The proposed study exploits the bilingual (Urdu and English) data from Twitter and NEWS websites related to the dengue epidemic in Pakistan, and sentiment analysis and emotion classification are performed to acquire deep insights from the data set for gaining a fair idea related to an epidemic outbreak. Machine learning and deep learning algorithms have been used to train and implement the models for the execution of both tasks. The comparative performance of each model has been evaluated using accuracy, precision, recall, and f1-measure.
LINE: Large-scale Information Network Embedding
Mar 12, 2015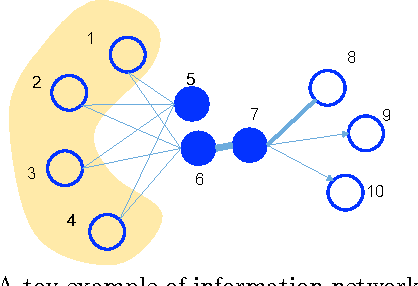

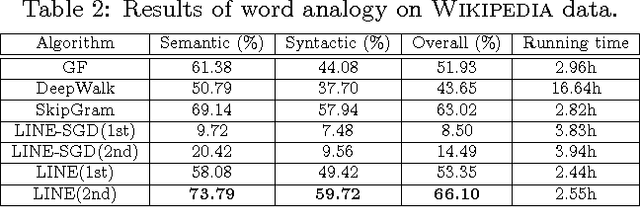
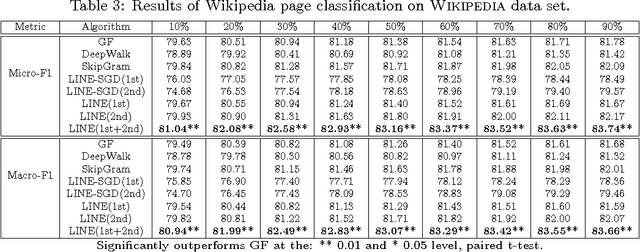
This paper studies the problem of embedding very large information networks into low-dimensional vector spaces, which is useful in many tasks such as visualization, node classification, and link prediction. Most existing graph embedding methods do not scale for real world information networks which usually contain millions of nodes. In this paper, we propose a novel network embedding method called the "LINE," which is suitable for arbitrary types of information networks: undirected, directed, and/or weighted. The method optimizes a carefully designed objective function that preserves both the local and global network structures. An edge-sampling algorithm is proposed that addresses the limitation of the classical stochastic gradient descent and improves both the effectiveness and the efficiency of the inference. Empirical experiments prove the effectiveness of the LINE on a variety of real-world information networks, including language networks, social networks, and citation networks. The algorithm is very efficient, which is able to learn the embedding of a network with millions of vertices and billions of edges in a few hours on a typical single machine. The source code of the LINE is available online.
Traffic Scenario Clustering by Iterative Optimisation of Self-Supervised Networks Using a Random Forest Activation Pattern Similarity
May 17, 2021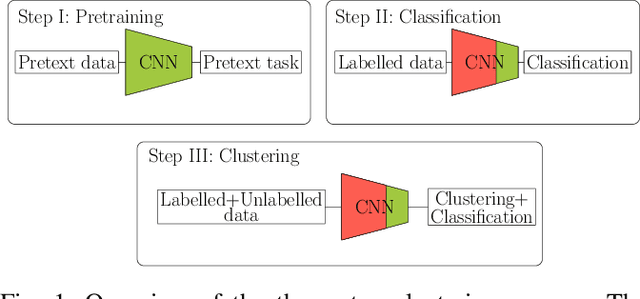
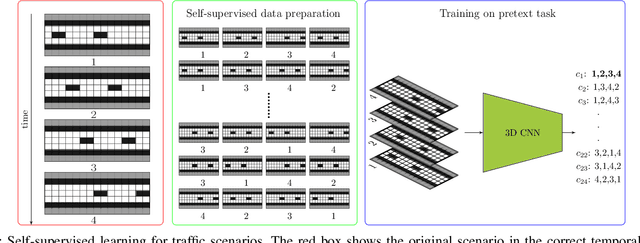
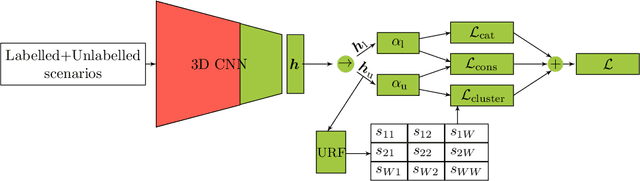
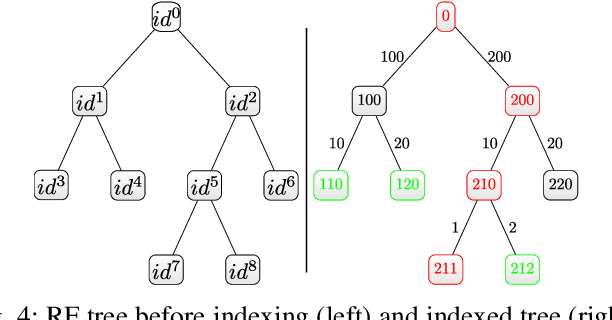
Traffic scenario categorisation is an essential component of automated driving, for e.\,g., in motion planning algorithms and their validation. Finding new relevant scenarios without handcrafted steps reduce the required resources for the development of autonomous driving dramatically. In this work, a method is proposed to address this challenge by introducing a clustering technique based on a novel data-adaptive similarity measure, called Random Forest Activation Pattern (RFAP) similarity. The RFAP similarity is generated using a tree encoding scheme in a Random Forest algorithm. The clustering method proposed in this work takes into account that there are labelled scenarios available and the information from the labelled scenarios can help to guide the clustering of unlabelled scenarios. It consists of three steps. First, a self-supervised Convolutional Neural Network~(CNN) is trained on all available traffic scenarios using a defined self-supervised objective. Second, the CNN is fine-tuned for classification of the labelled scenarios. Third, using the labelled and unlabelled scenarios an iterative optimisation procedure is performed for clustering. In the third step at each epoch of the iterative optimisation, the CNN is used as a feature generator for an unsupervised Random Forest. The trained forest, in turn, provides the RFAP similarity to adapt iteratively the feature generation process implemented by the CNN. Extensive experiments and ablation studies have been done on the highD dataset. The proposed method shows superior performance compared to baseline clustering techniques.
Leaking Sensitive Financial Accounting Data in Plain Sight using Deep Autoencoder Neural Networks
Dec 13, 2020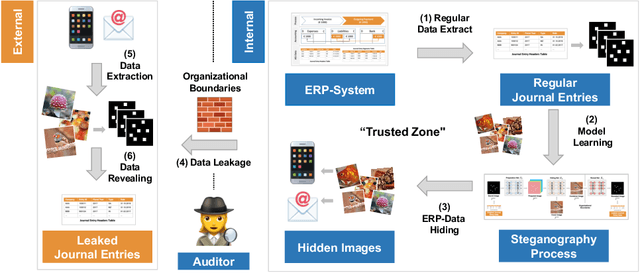
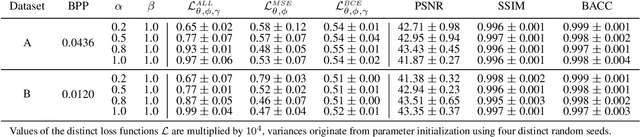
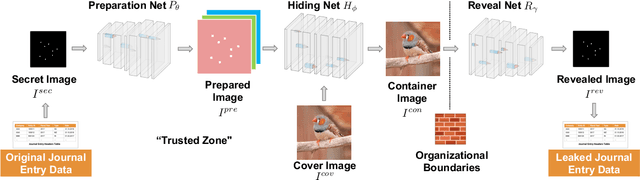
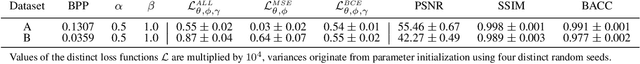
Nowadays, organizations collect vast quantities of sensitive information in `Enterprise Resource Planning' (ERP) systems, such as accounting relevant transactions, customer master data, or strategic sales price information. The leakage of such information poses a severe threat for companies as the number of incidents and the reputational damage to those experiencing them continue to increase. At the same time, discoveries in deep learning research revealed that machine learning models could be maliciously misused to create new attack vectors. Understanding the nature of such attacks becomes increasingly important for the (internal) audit and fraud examination practice. The creation of such an awareness holds in particular for the fraudulent data leakage using deep learning-based steganographic techniques that might remain undetected by state-of-the-art `Computer Assisted Audit Techniques' (CAATs). In this work, we introduce a real-world `threat model' designed to leak sensitive accounting data. In addition, we show that a deep steganographic process, constituted by three neural networks, can be trained to hide such data in unobtrusive `day-to-day' images. Finally, we provide qualitative and quantitative evaluations on two publicly available real-world payment datasets.
Decentralized Inference with Graph Neural Networks in Wireless Communication Systems
Apr 19, 2021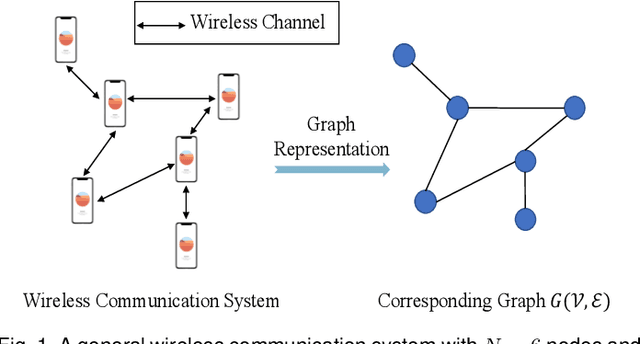
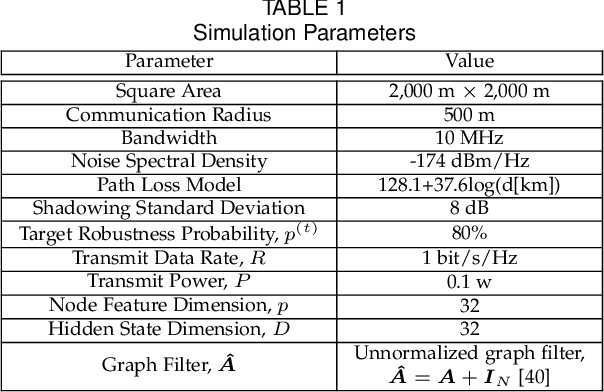

Graph neural network (GNN) is an efficient neural network model for graph data and is widely used in different fields, including wireless communications. Different from other neural network models, GNN can be implemented in a decentralized manner with information exchanges among neighbors, making it a potentially powerful tool for decentralized control in wireless communication systems. The main bottleneck, however, is wireless channel impairments that deteriorate the prediction robustness of GNN. To overcome this obstacle, we analyze and enhance the robustness of the decentralized GNN in different wireless communication systems in this paper. Specifically, using a GNN binary classifier as an example, we first develop a methodology to verify whether the predictions are robust. Then, we analyze the performance of the decentralized GNN binary classifier in both uncoded and coded wireless communication systems. To remedy imperfect wireless transmission and enhance the prediction robustness, we further propose novel retransmission mechanisms for the above two communication systems, respectively. Through simulations on the synthetic graph data, we validate our analysis, verify the effectiveness of the proposed retransmission mechanisms, and provide some insights for practical implementation.
Weight-Based Exploration for Unmanned Aerial Teams Searching for Multiple Survivors
Dec 21, 2020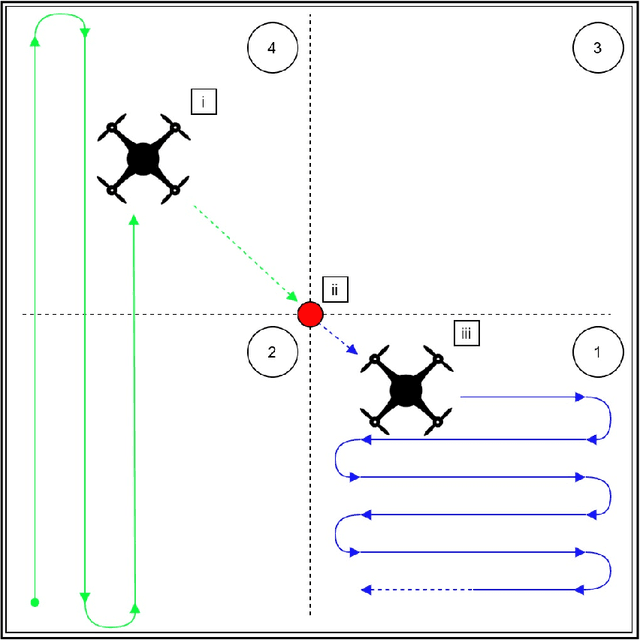
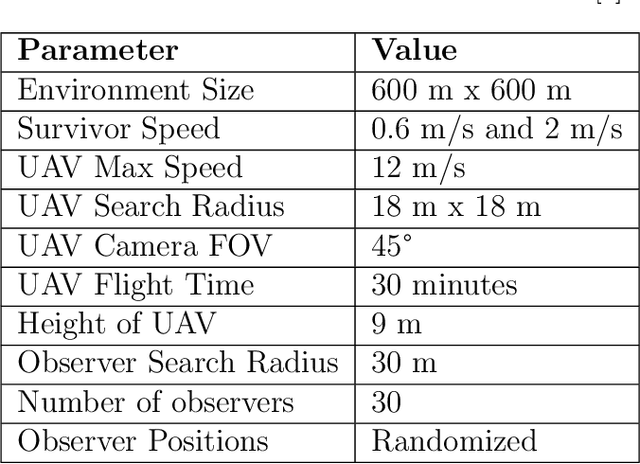
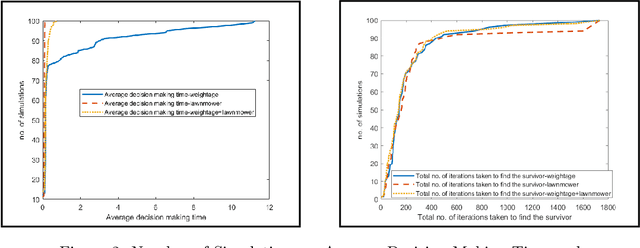
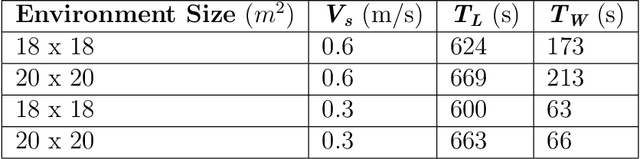
During floods, reaching survivors in the shortest possible time is a priority for rescue teams. Given their ability to explore difficult terrain in short spans of time, Unmanned Aerial Vehicles (UAVs) have become an increasingly valuable aid to search and rescue operations. Traditionally, UAVs utilize exhaustive lawnmower exploration patterns to locate stranded survivors, without any information regarding the survivor's whereabouts. In real life disaster scenarios however, on-ground observers provide valuable information to the rescue effort, such as the survivor's last known location and heading. In earlier work, a Weight Based Exploration (WBE) model, which utilizes this information to generate a prioritized list of waypoints to aid the UAV in its search mission, was proposed. This approach was shown to be effective for a single UAV locating a single survivor. In this paper, we extend the WBE model to a team of UAVs locating multiple survivors. The model initially partitions the search environment amongst the UAVs using Voronoi cells. The UAVs then utilize the WBE model to locate survivors in their partitions. We test this model with varying survivor locations and headings. We demonstrate the scalability of the model developed by testing the model with aerial teams comprising several UAVs.
Cyclic Co-Learning of Sounding Object Visual Grounding and Sound Separation
Apr 05, 2021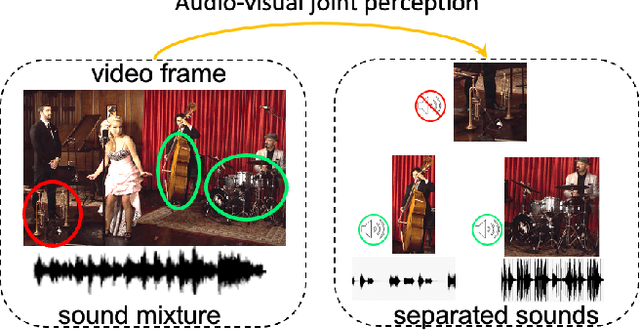
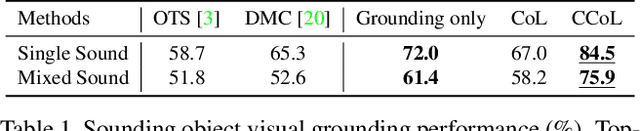
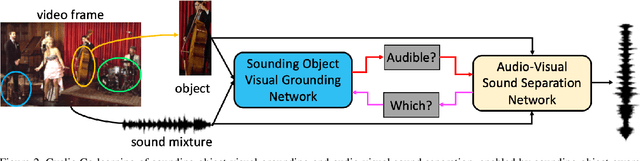
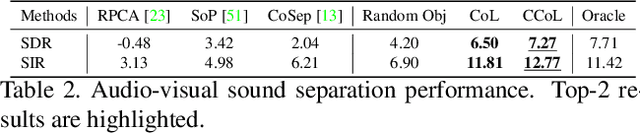
There are rich synchronized audio and visual events in our daily life. Inside the events, audio scenes are associated with the corresponding visual objects; meanwhile, sounding objects can indicate and help to separate their individual sounds in the audio track. Based on this observation, in this paper, we propose a cyclic co-learning (CCoL) paradigm that can jointly learn sounding object visual grounding and audio-visual sound separation in a unified framework. Concretely, we can leverage grounded object-sound relations to improve the results of sound separation. Meanwhile, benefiting from discriminative information from separated sounds, we improve training example sampling for sounding object grounding, which builds a co-learning cycle for the two tasks and makes them mutually beneficial. Extensive experiments show that the proposed framework outperforms the compared recent approaches on both tasks, and they can benefit from each other with our cyclic co-learning.