 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Surrogate assisted active subspace and active subspace assisted surrogate -- A new paradigm for high dimensional structural reliability analysis
May 11, 2021
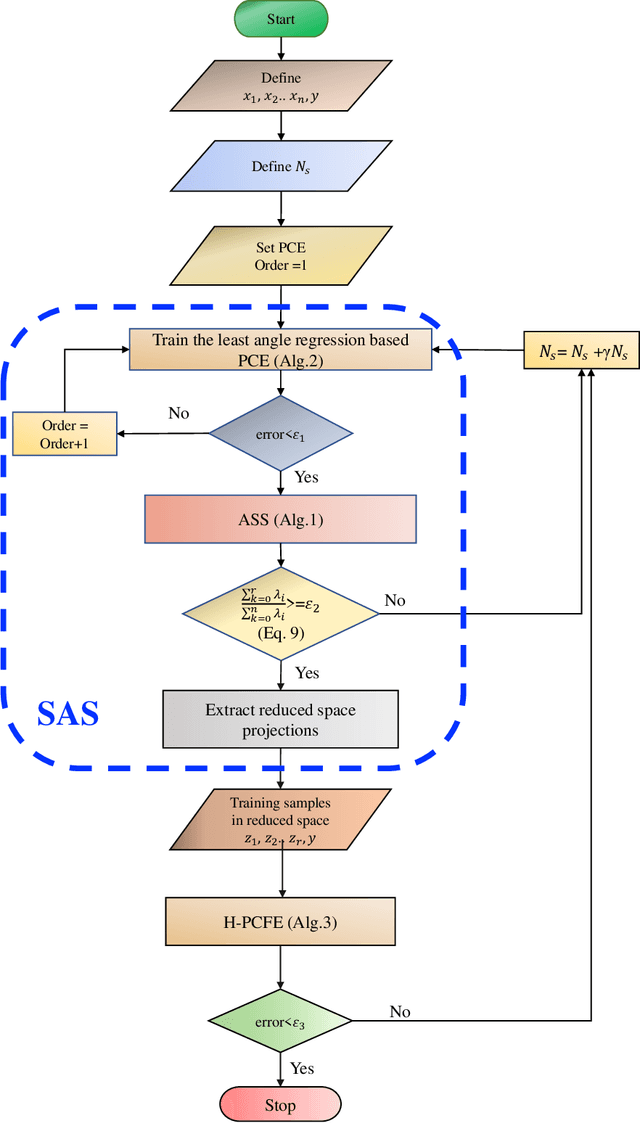
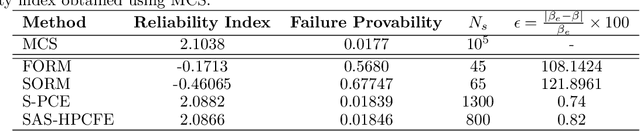
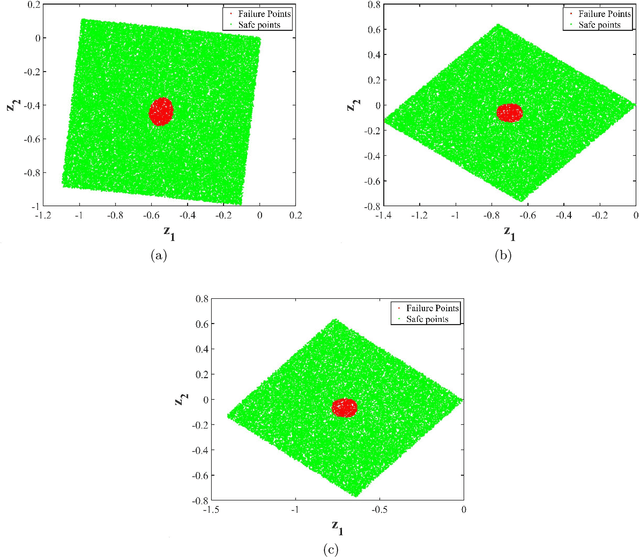
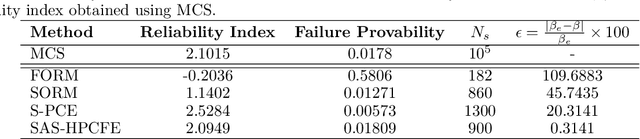
Performing reliability analysis on complex systems is often computationally expensive. In particular, when dealing with systems having high input dimensionality, reliability estimation becomes a daunting task. A popular approach to overcome the problem associated with time-consuming and expensive evaluations is building a surrogate model. However, these computationally efficient models often suffer from the curse of dimensionality. Hence, training a surrogate model for high-dimensional problems is not straightforward. Henceforth, this paper presents a framework for solving high-dimensional reliability analysis problems. The basic premise is to train the surrogate model on a low-dimensional manifold, discovered using the active subspace algorithm. However, learning the low-dimensional manifold using active subspace is non-trivial as it requires information on the gradient of the response variable. To address this issue, we propose using sparse learning algorithms in conjunction with the active subspace algorithm; the resulting algorithm is referred to as the sparse active subspace (SAS) algorithm. We project the high-dimensional inputs onto the identified low-dimensional manifold identified using SAS. A high-fidelity surrogate model is used to map the inputs on the low-dimensional manifolds to the output response. We illustrate the efficacy of the proposed framework by using three benchmark reliability analysis problems from the literature. The results obtained indicate the accuracy and efficiency of the proposed approach compared to already established reliability analysis methods in the literature.
A Multi-Task Deep Learning Framework for Building Footprint Segmentation
Apr 19, 2021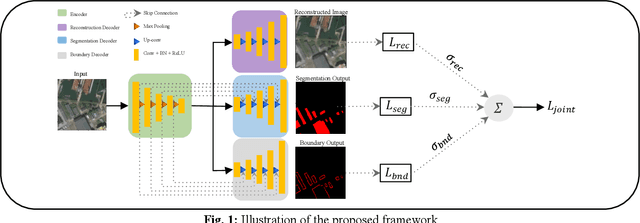
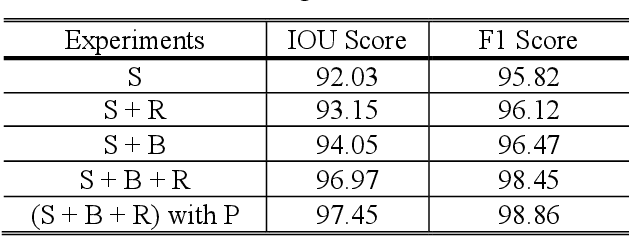

The task of building footprint segmentation has been well-studied in the context of remote sensing (RS) as it provides valuable information in many aspects, however, difficulties brought by the nature of RS images such as variations in the spatial arrangements and in-consistent constructional patterns require studying further, since it often causes poorly classified segmentation maps. We address this need by designing a joint optimization scheme for the task of building footprint delineation and introducing two auxiliary tasks; image reconstruction and building footprint boundary segmentation with the intent to reveal the common underlying structure to advance the classification accuracy of a single task model under the favor of auxiliary tasks. In particular, we propose a deep multi-task learning (MTL) based unified fully convolutional framework which operates in an end-to-end manner by making use of joint loss function with learnable loss weights considering the homoscedastic uncertainty of each task loss. Experimental results conducted on the SpaceNet6 dataset demonstrate the potential of the proposed MTL framework as it improves the classification accuracy considerably compared to single-task and lesser compounded tasks.
DFENet: A Novel Dimension Fusion Edge Guided Network for Brain MRI Segmentation
May 17, 2021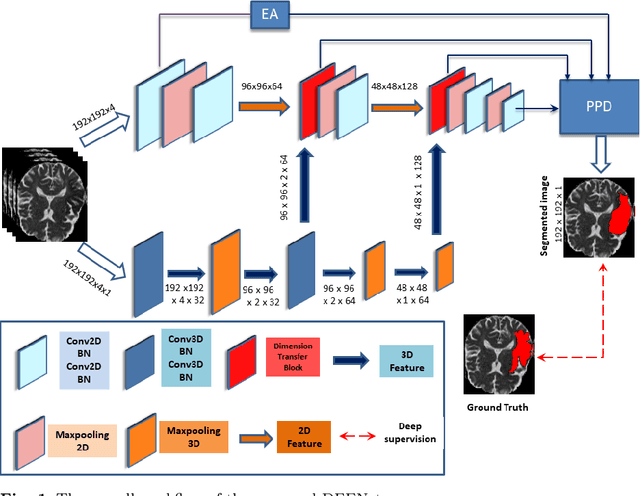
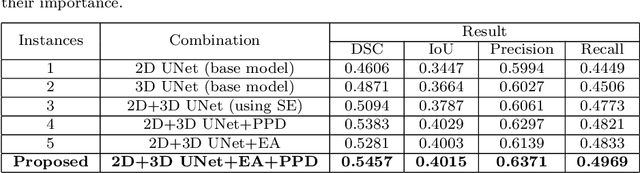
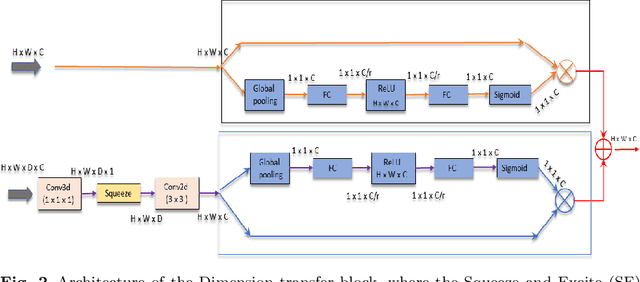
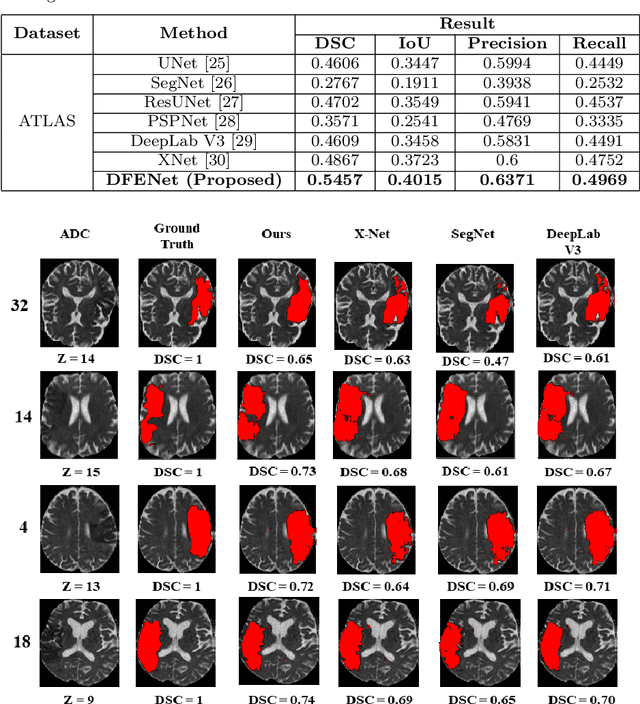
The rapid increment of morbidity of brain stroke in the last few years have been a driving force towards fast and accurate segmentation of stroke lesions from brain MRI images. With the recent development of deep-learning, computer-aided and segmentation methods of ischemic stroke lesions have been useful for clinicians in early diagnosis and treatment planning. However, most of these methods suffer from inaccurate and unreliable segmentation results because of their inability to capture sufficient contextual features from the MRI volumes. To meet these requirements, 3D convolutional neural networks have been proposed, which, however, suffer from huge computational requirements. To mitigate these problems, we propose a novel Dimension Fusion Edge-guided network (DFENet) that can meet both of these requirements by fusing the features of 2D and 3D CNNs. Unlike other methods, our proposed network uses a parallel partial decoder (PPD) module for aggregating and upsampling selected features, rich in important contextual information. Additionally, we use an edge-guidance and enhanced mixing loss for constantly supervising and improvising the learning process of the network. The proposed method is evaluated on publicly available Anatomical Tracings of Lesions After Stroke (ATLAS) dataset, resulting in mean DSC, IoU, Precision and Recall values of 0.5457, 0.4015, 0.6371, and 0.4969 respectively. The results, when compared to other state-of-the-art methods, outperforms them by a significant margin. Therefore, the proposed model is robust, accurate, superior to the existing methods, and can be relied upon for biomedical applications.
A Hybrid Decomposition-based Multi-objective Evolutionary Algorithm for the Multi-Point Dynamic Aggregation Problem
May 11, 2021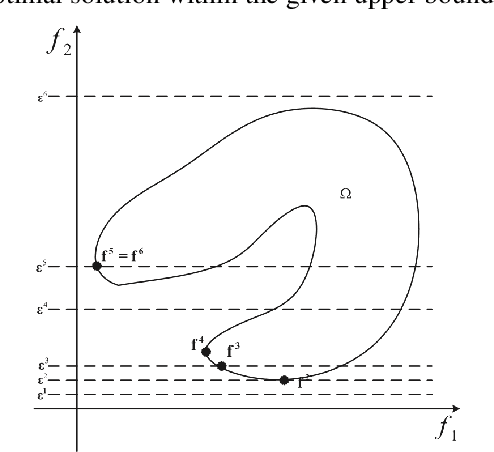
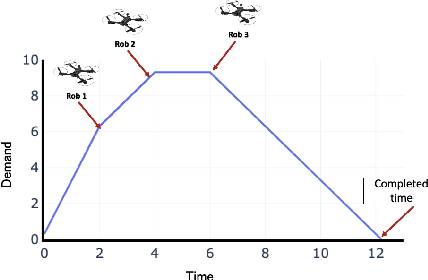


An emerging optimisation problem from the real-world applications, named the multi-point dynamic aggregation (MPDA) problem, has become one of the active research topics of the multi-robot system. This paper focuses on a multi-objective MPDA problem which is to design an execution plan of the robots to minimise the number of robots and the maximal completion time of all the tasks. The strongly-coupled relationships among robots and tasks, the redundancy of the MPDA encoding, and the variable-size decision space of the MO-MPDA problem posed extra challenges for addressing the problem effectively. To address the above issues, we develop a hybrid decomposition-based multi-objective evolutionary algorithm (HDMOEA) using $ \varepsilon $-constraint method. It selects the maximal completion time of all tasks as the main objective, and converted the other objective into constraints. HDMOEA decomposes a MO-MPDA problem into a series of scalar constrained optimization subproblems by assigning each subproblem with an upper bound robot number. All the subproblems are optimized simultaneously with the transferring knowledge from other subproblems. Besides, we develop a hybrid population initialisation mechanism to enhance the quality of initial solutions, and a reproduction mechanism to transmit effective information and tackle the encoding redundancy. Experimental results show that the proposed HDMOEA method significantly outperforms the state-of-the-art methods in terms of several most-used metrics.
Virtual Normal: Enforcing Geometric Constraints for Accurate and Robust Depth Prediction
Mar 09, 2021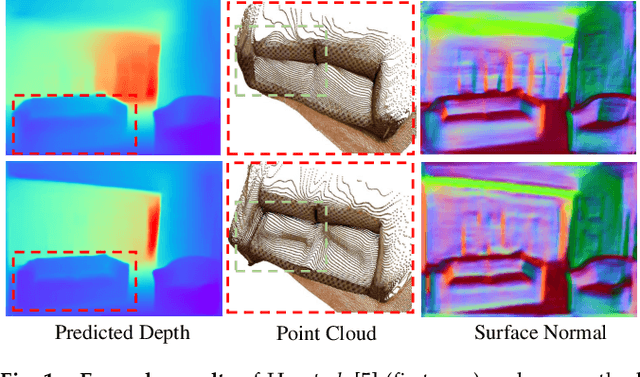
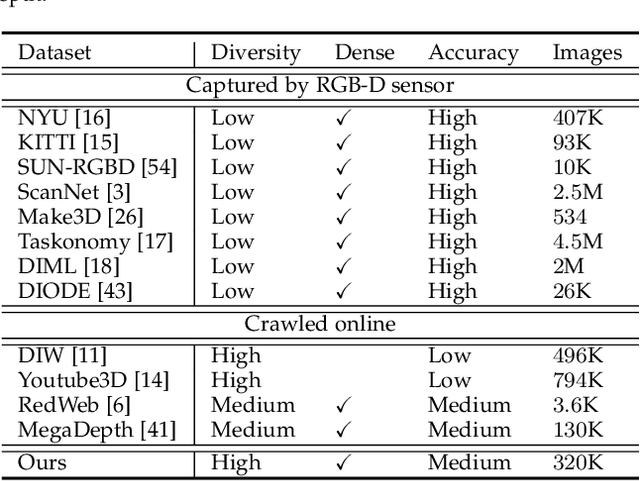
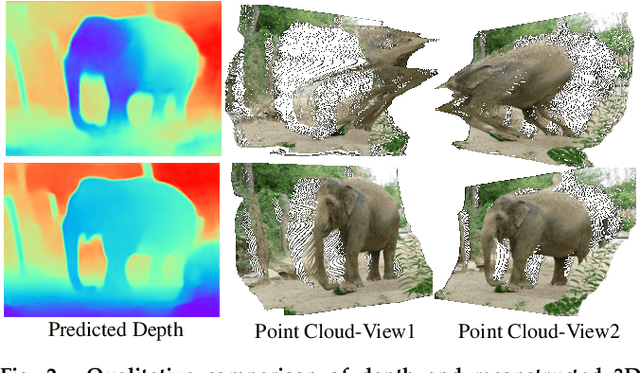
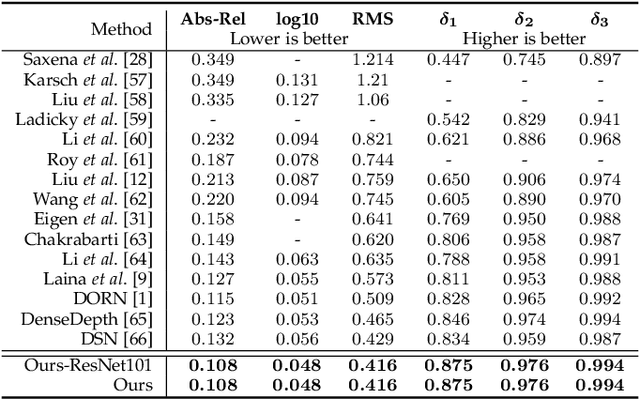
Monocular depth prediction plays a crucial role in understanding 3D scene geometry. Although recent methods have achieved impressive progress in terms of evaluation metrics such as the pixel-wise relative error, most methods neglect the geometric constraints in the 3D space. In this work, we show the importance of the high-order 3D geometric constraints for depth prediction. By designing a loss term that enforces a simple geometric constraint, namely, virtual normal directions determined by randomly sampled three points in the reconstructed 3D space, we significantly improve the accuracy and robustness of monocular depth estimation. Significantly, the virtual normal loss can not only improve the performance of learning metric depth, but also disentangle the scale information and enrich the model with better shape information. Therefore, when not having access to absolute metric depth training data, we can use virtual normal to learn a robust affine-invariant depth generated on diverse scenes. In experiments, We show state-of-the-art results of learning metric depth on NYU Depth-V2 and KITTI. From the high-quality predicted depth, we are now able to recover good 3D structures of the scene such as the point cloud and surface normal directly, eliminating the necessity of relying on additional models as was previously done. To demonstrate the excellent generalizability of learning affine-invariant depth on diverse data with the virtual normal loss, we construct a large-scale and diverse dataset for training affine-invariant depth, termed Diverse Scene Depth dataset (DiverseDepth), and test on five datasets with the zero-shot test setting. Code is available at: https://git.io/Depth
Quantum Machine Learning for Power System Stability Assessment
Apr 10, 2021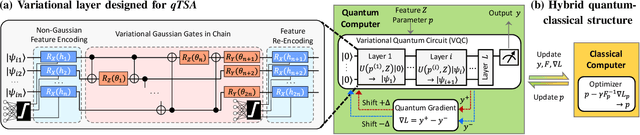
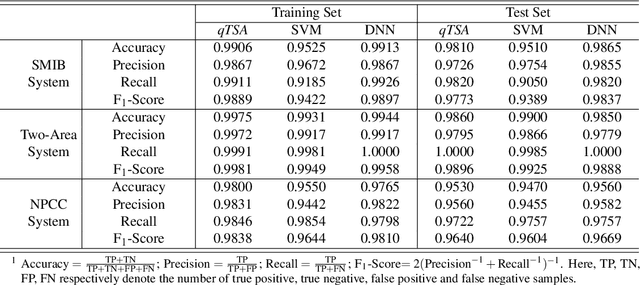
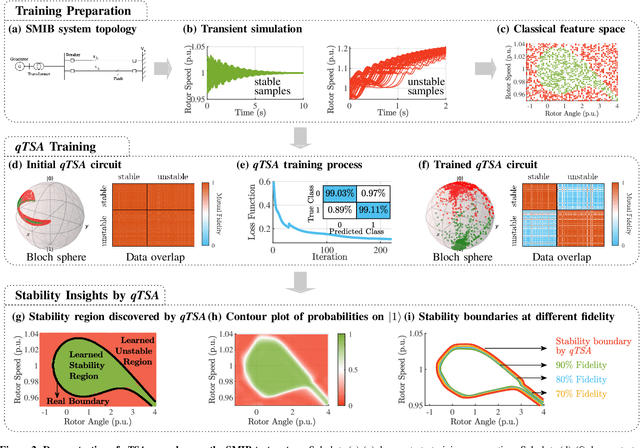
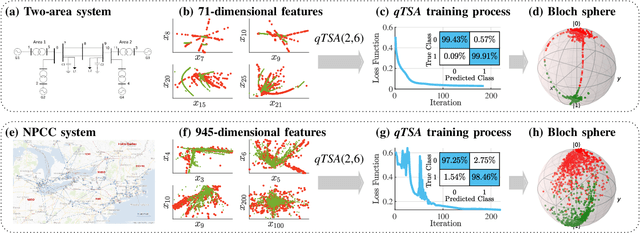
Transient stability assessment (TSA), a cornerstone for resilient operations of today's interconnected power grids, is a grand challenge yet to be addressed since the genesis of electric power systems. This paper is a confluence of quantum computing, data science and machine learning to potentially resolve the aforementioned challenge caused by high dimensionality, non-linearity and uncertainty. We devise a quantum TSA (qTSA) method, a low-depth, high expressibility quantum neural network, to enable scalable and efficient data-driven transient stability prediction for bulk power systems. qTSA renders the intractable TSA straightforward and effortless in the Hilbert space, and provides rich information that enables unprecedentedly resilient and secure power system operations. Extensive experiments on quantum simulators and real quantum computers verify the accuracy, noise-resilience, scalability and universality of qTSA. qTSA underpins a solid foundation of a quantum-enabled, ultra-resilient power grid which will benefit the people as well as various commercial and industrial sectors.
Applications of Deep Learning Techniques for Automated Multiple Sclerosis Detection Using Magnetic Resonance Imaging: A Review
May 11, 2021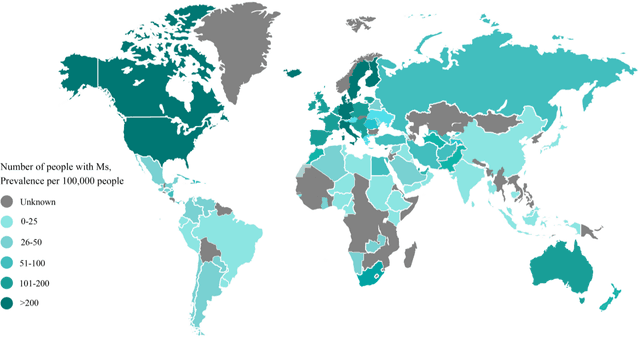
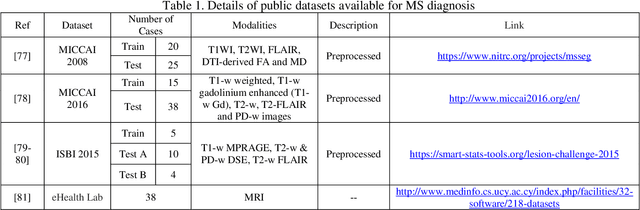
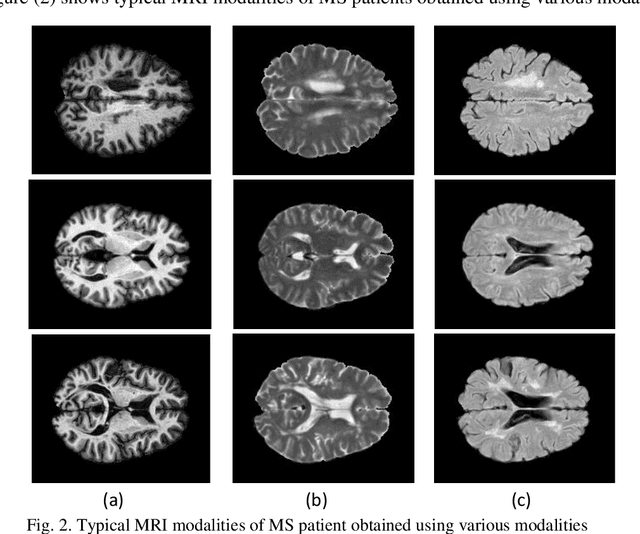
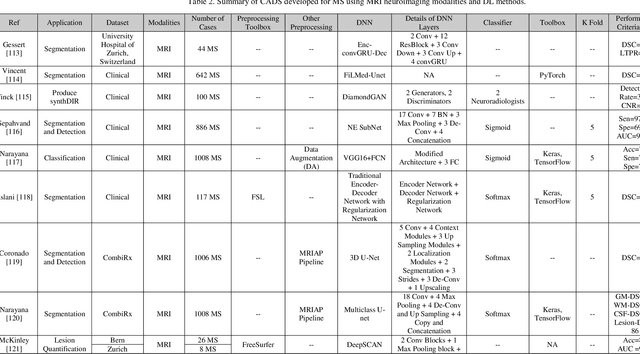
Multiple Sclerosis (MS) is a type of brain disease which causes visual, sensory, and motor problems for people with a detrimental effect on the functioning of the nervous system. In order to diagnose MS, multiple screening methods have been proposed so far; among them, magnetic resonance imaging (MRI) has received considerable attention among physicians. MRI modalities provide physicians with fundamental information about the structure and function of the brain, which is crucial for the rapid diagnosis of MS lesions. Diagnosing MS using MRI is time-consuming, tedious, and prone to manual errors. Hence, computer aided diagnosis systems (CADS) based on artificial intelligence (AI) methods have been proposed in recent years for accurate diagnosis of MS using MRI neuroimaging modalities. In the AI field, automated MS diagnosis is being conducted using (i) conventional machine learning and (ii) deep learning (DL) techniques. The conventional machine learning approach is based on feature extraction and selection by trial and error. In DL, these steps are performed by the DL model itself. In this paper, a complete review of automated MS diagnosis methods performed using DL techniques with MRI neuroimaging modalities are discussed. Also, each work is thoroughly reviewed and discussed. Finally, the most important challenges and future directions in the automated MS diagnosis using DL techniques coupled with MRI modalities are presented in detail.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020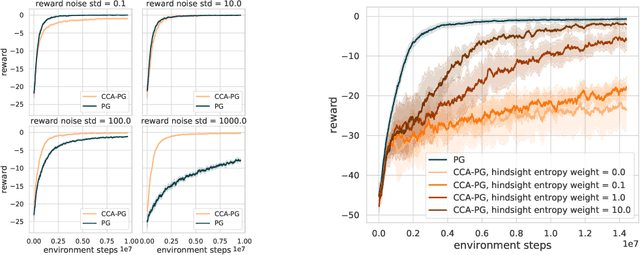
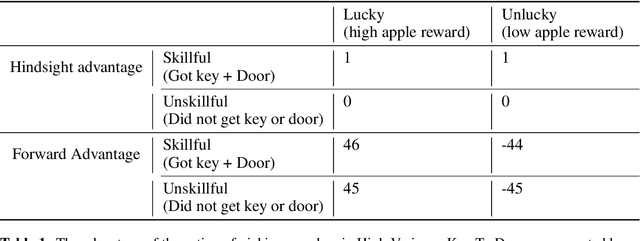

Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
Multi-hierarchical Convolutional Network for Efficient Remote Photoplethysmograph Signal and Heart Rate Estimation from Face Video Clips
Apr 06, 2021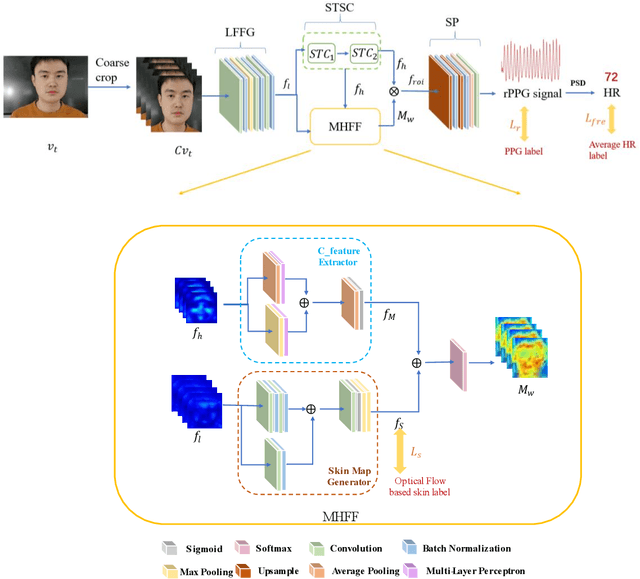
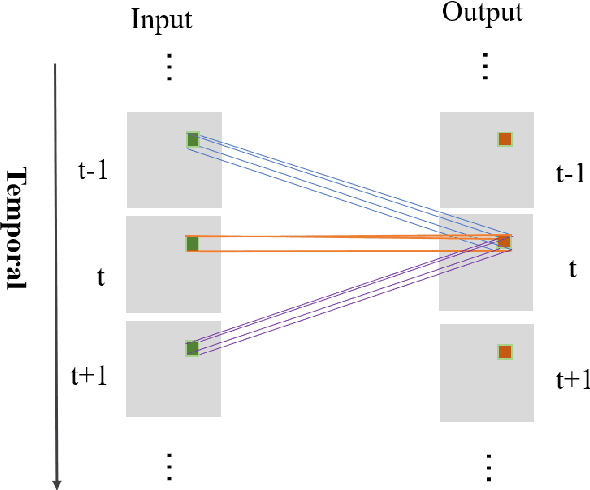
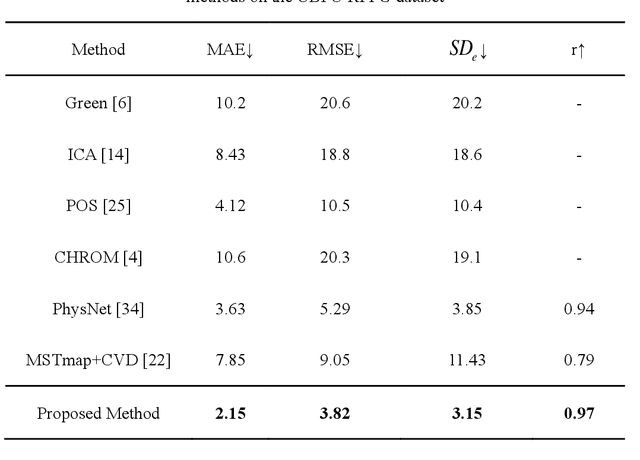
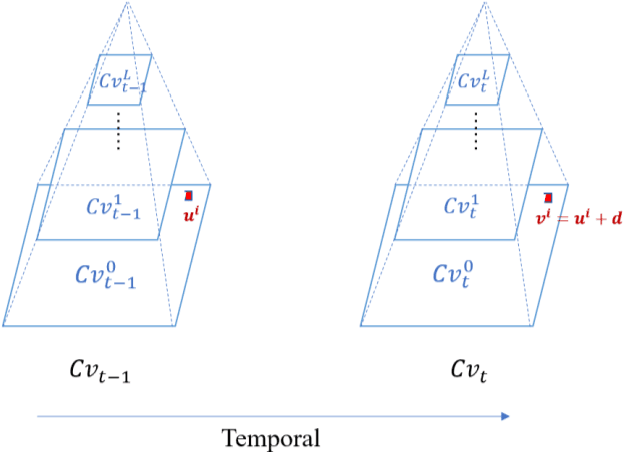
Heart beat rhythm and heart rate (HR) are important physiological parameters of the human body. This study presents an efficient multi-hierarchical spatio-temporal convolutional network that can quickly estimate remote physiological (rPPG) signal and HR from face video clips. First, the facial color distribution characteristics are extracted using a low-level face feature Generation (LFFG) module. Then, the three-dimensional (3D) spatio-temporal stack convolution module (STSC) and multi-hierarchical feature fusion module (MHFF) are used to strengthen the spatio-temporal correlation of multi-channel features. In the MHFF, sparse optical flow is used to capture the tiny motion information of faces between frames and generate a self-adaptive region of interest (ROI) skin mask. Finally, the signal prediction module (SP) is used to extract the estimated rPPG signal. The experimental results on the three datasets show that the proposed network outperforms the state-of-the-art methods.
Learning non-parametric Markov networks with mutual information
Aug 08, 2017
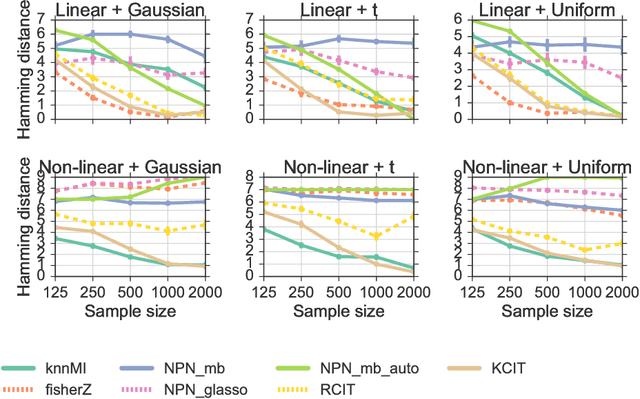
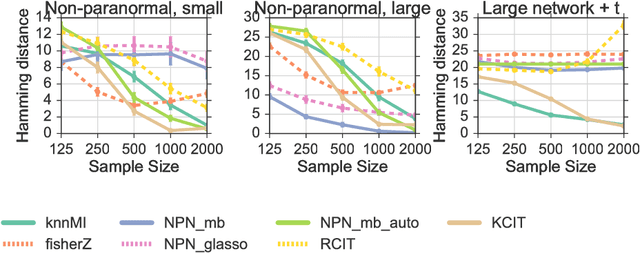
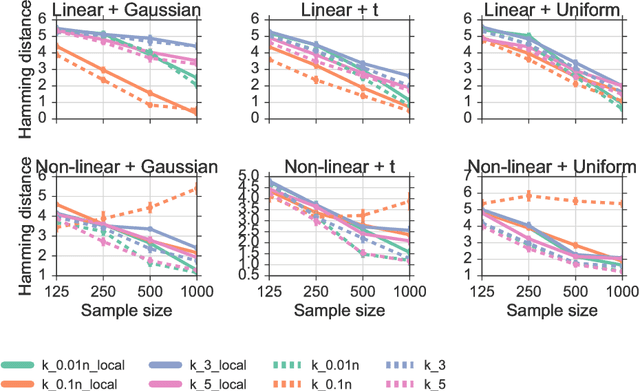
We propose a method for learning Markov network structures for continuous data without invoking any assumptions about the distribution of the variables. The method makes use of previous work on a non-parametric estimator for mutual information which is used to create a non-parametric test for multivariate conditional independence. This independence test is then combined with an efficient constraint-based algorithm for learning the graph structure. The performance of the method is evaluated on several synthetic data sets and it is shown to learn considerably more accurate structures than competing methods when the dependencies between the variables involve non-linearities.