 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Person Extreme Motion Prediction with Cross-Interaction Attention
May 20, 2021
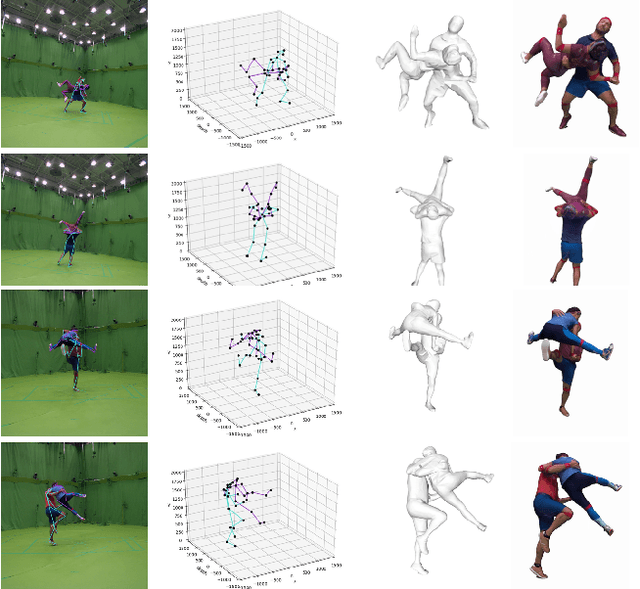

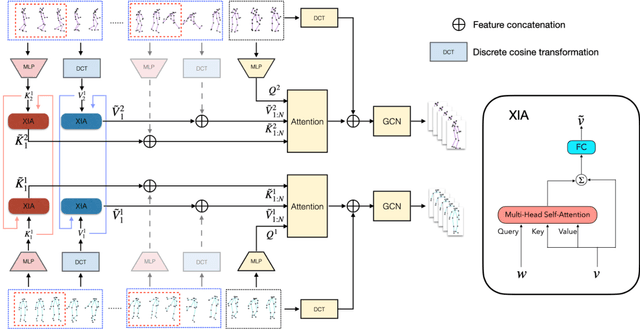
Human motion prediction aims to forecast future human poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been tackled for single humans in isolation. In this paper we explore this problem from a novel perspective, involving humans performing collaborative tasks. We assume that the input of our system are two sequences of past skeletons for two interacting persons, and we aim to predict the future motion for each of them. For this purpose, we devise a novel cross interaction attention mechanism that exploits historical information of both persons and learns to predict cross dependencies between self poses and the poses of the other person in spite of their spatial or temporal distance. Since no dataset to train such interactive situations is available, we have captured ExPI (Extreme Pose Interaction), a new lab-based person interaction dataset of professional dancers performing acrobatics. ExPI contains 115 sequences with 30k frames and 60k instances with annotated 3D body poses and shapes. We thoroughly evaluate our cross-interaction network on this dataset and show that both in short-term and long-term predictions, it consistently outperforms baselines that independently reason for each person. We plan to release our code jointly with the dataset and the train/test splits to spur future research on the topic.
Network Architecture Search for Face Enhancement
May 13, 2021
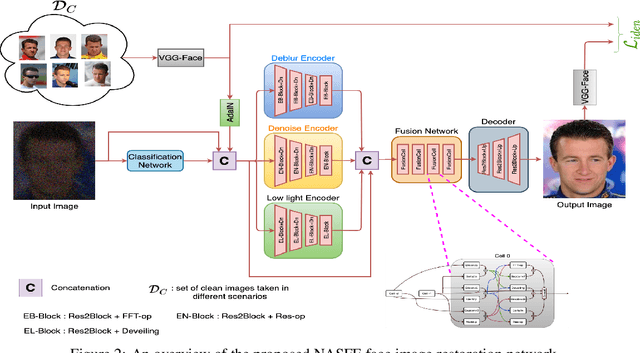
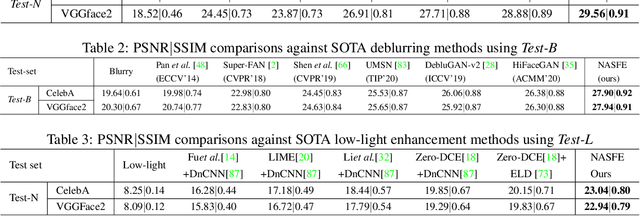
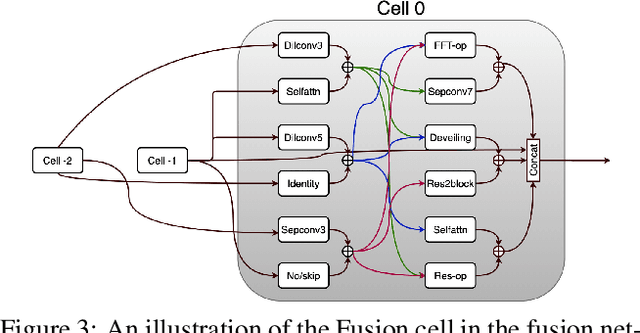
Various factors such as ambient lighting conditions, noise, motion blur, etc. affect the quality of captured face images. Poor quality face images often reduce the performance of face analysis and recognition systems. Hence, it is important to enhance the quality of face images collected in such conditions. We present a multi-task face restoration network, called Network Architecture Search for Face Enhancement (NASFE), which can enhance poor quality face images containing a single degradation (i.e. noise or blur) or multiple degradations (noise+blur+low-light). During training, NASFE uses clean face images of a person present in the degraded image to extract the identity information in terms of features for restoring the image. Furthermore, the network is guided by an identity-loss so that the identity in-formation is maintained in the restored image. Additionally, we propose a network architecture search-based fusion network in NASFE which fuses the task-specific features that are extracted using the task-specific encoders. We introduce FFT-op and deveiling operators in the fusion network to efficiently fuse the task-specific features. Comprehensive experiments on synthetic and real images demonstrate that the proposed method outperforms many recent state-of-the-art face restoration and enhancement methods in terms of quantitative and visual performance.
Evaluating e-Government Services in Kurdistan Institution for Strategic Studies and Scientific Research Using the EGOVSAT Model
May 06, 2021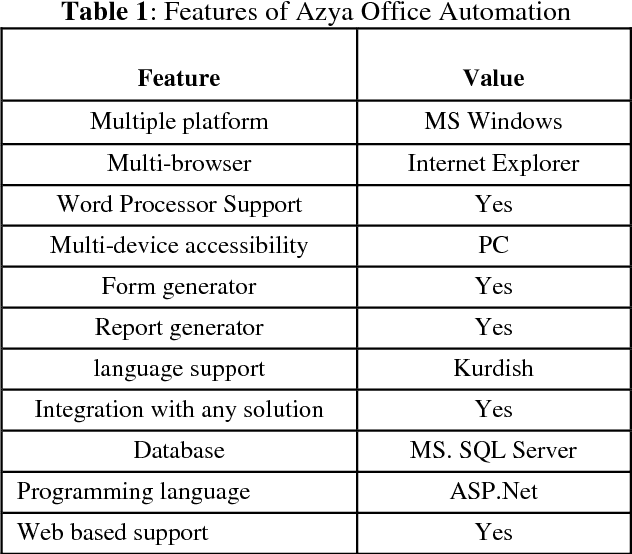
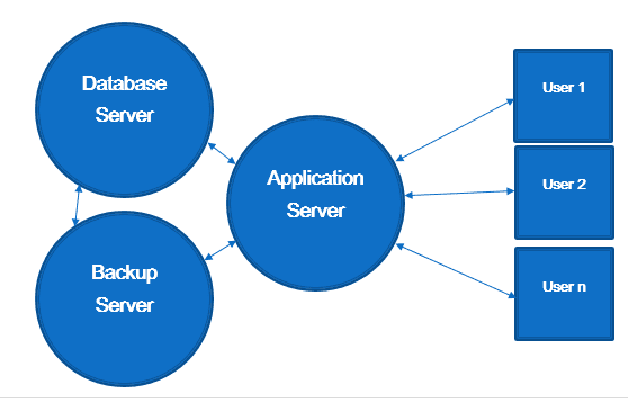
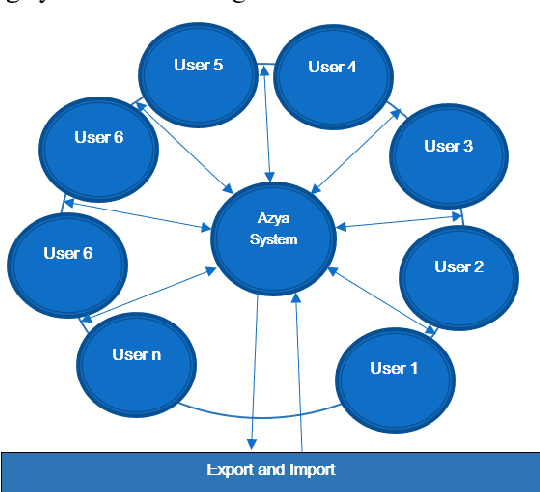
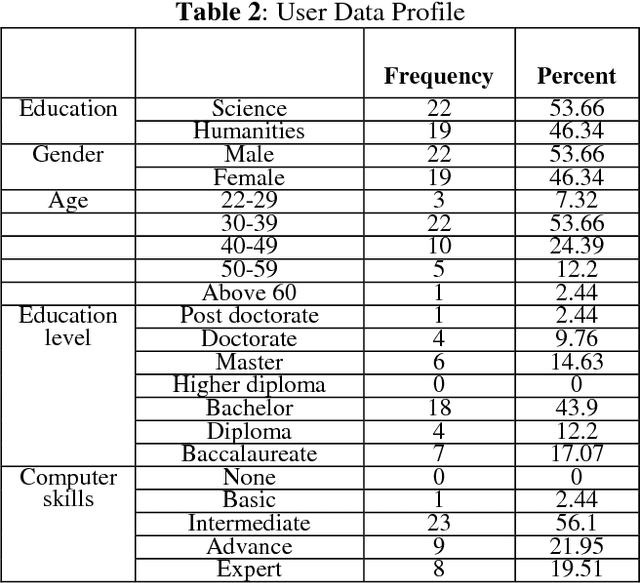
Office automation is an initiative used to digitally deliver services to citizens, private and public sectors. It is used to digitally collect, store, create, and manipulate office information as a need of accomplishing basic tasks. Azya Office Automation has been implemented as a pilot project in Kurdistan Institution for Strategic Studies and Scientific Research (KISSR) since 2013. The efficiency of governance in Kurdistan Institution for Strategic Studies and Scientific Research has been improved, thanks to its implementation. The aims of this research paper is to evaluate user satisfaction of this software and identify its significant predictors using EGOVSAT Model. The user satisfaction of this model encompasses five main parts, which are utility, reliability, efficiency, customization, and flexibility. For that purpose, a detailed survey is conducted to measure the level of user satisfaction. A total of sixteen questions have distributed among forty one users of the software in KISSR. In order to evaluate the software, three measurement have been used which are reliability test, regression analysis and correlation analysis. The results indicate that the software is successful to a decent extent based on user satisfaction feedbacks obtained by using EGOVSAT Model.
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017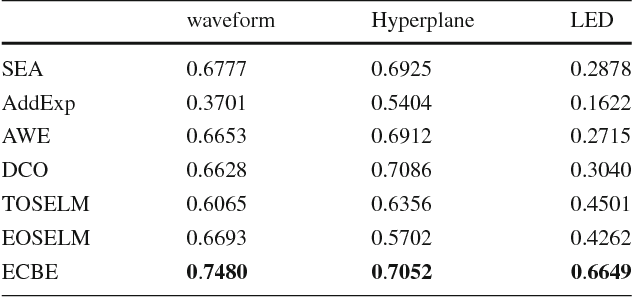
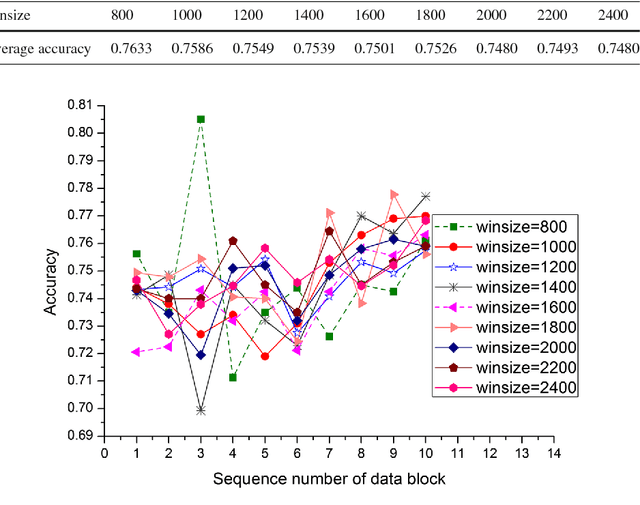
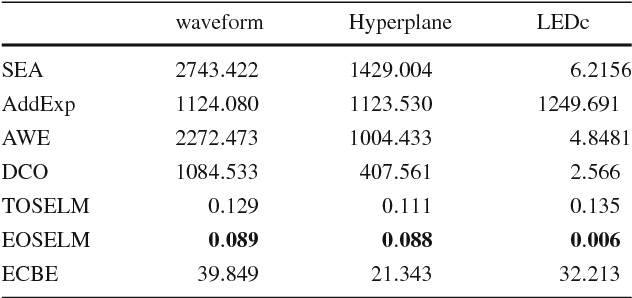
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.
FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
May 20, 2021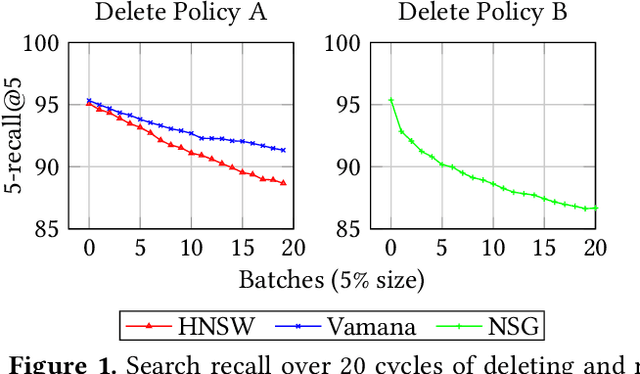
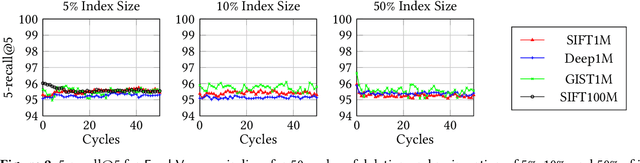
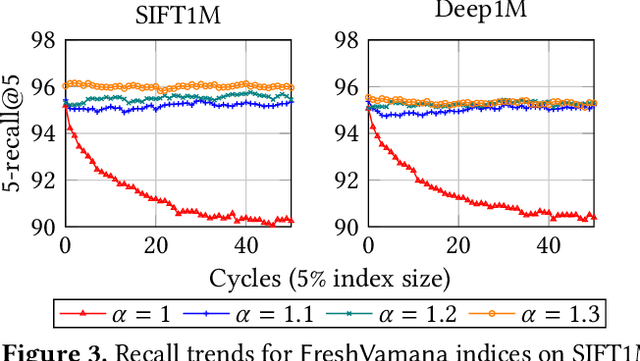
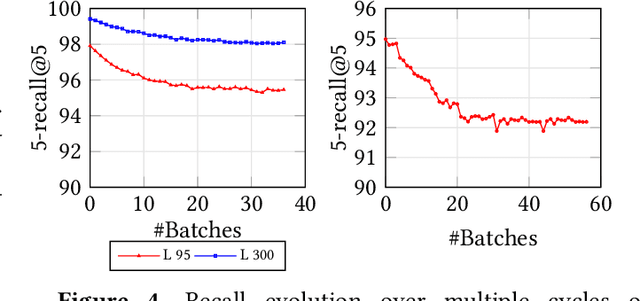
Approximate nearest neighbor search (ANNS) is a fundamental building block in information retrieval with graph-based indices being the current state-of-the-art and widely used in the industry. Recent advances in graph-based indices have made it possible to index and search billion-point datasets with high recall and millisecond-level latency on a single commodity machine with an SSD. However, existing graph algorithms for ANNS support only static indices that cannot reflect real-time changes to the corpus required by many key real-world scenarios (e.g. index of sentences in documents, email, or a news index). To overcome this drawback, the current industry practice for manifesting updates into such indices is to periodically re-build these indices, which can be prohibitively expensive. In this paper, we present the first graph-based ANNS index that reflects corpus updates into the index in real-time without compromising on search performance. Using update rules for this index, we design FreshDiskANN, a system that can index over a billion points on a workstation with an SSD and limited memory, and support thousands of concurrent real-time inserts, deletes and searches per second each, while retaining $>95\%$ 5-recall@5. This represents a 5-10x reduction in the cost of maintaining freshness in indices when compared to existing methods.
OpinionRank: Extracting Ground Truth Labels from Unreliable Expert Opinions with Graph-Based Spectral Ranking
Feb 11, 2021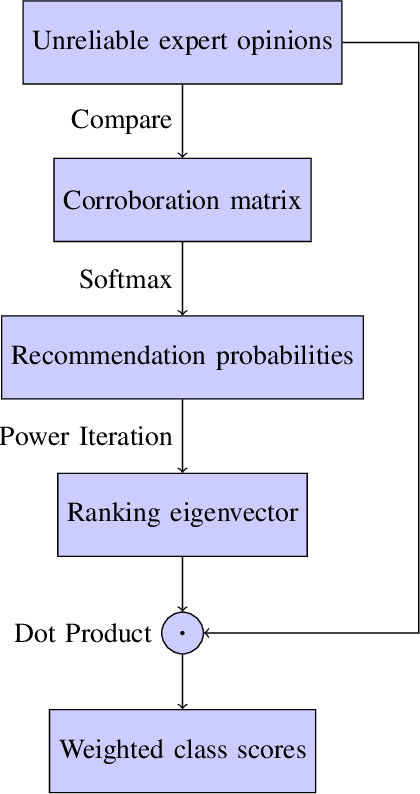
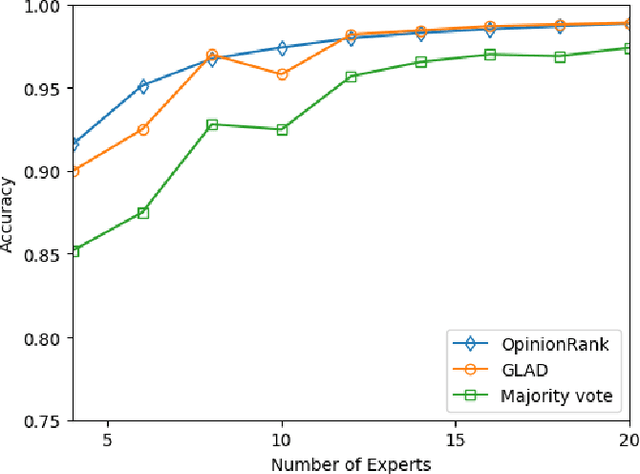
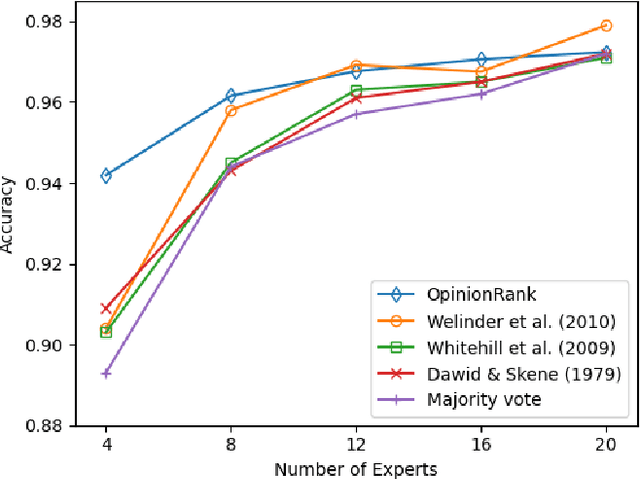
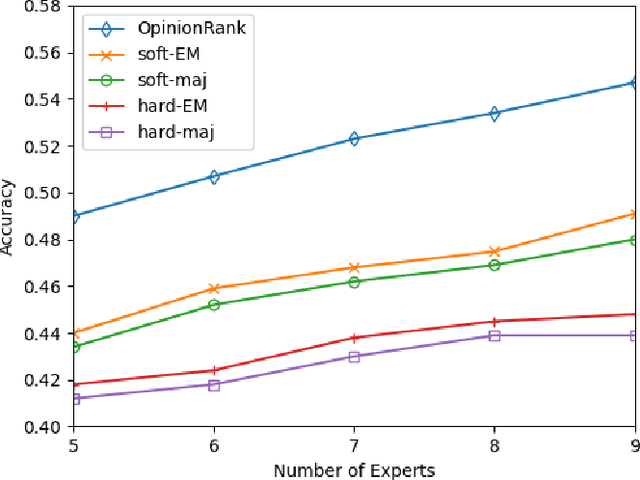
As larger and more comprehensive datasets become standard in contemporary machine learning, it becomes increasingly more difficult to obtain reliable, trustworthy label information with which to train sophisticated models. To address this problem, crowdsourcing has emerged as a popular, inexpensive, and efficient data mining solution for performing distributed label collection. However, crowdsourced annotations are inherently untrustworthy, as the labels are provided by anonymous volunteers who may have varying, unreliable expertise. Worse yet, some participants on commonly used platforms such as Amazon Mechanical Turk may be adversarial, and provide intentionally incorrect label information without the end user's knowledge. We discuss three conventional models of the label generation process, describing their parameterizations and the model-based approaches used to solve them. We then propose OpinionRank, a model-free, interpretable, graph-based spectral algorithm for integrating crowdsourced annotations into reliable labels for performing supervised or semi-supervised learning. Our experiments show that OpinionRank performs favorably when compared against more highly parameterized algorithms. We also show that OpinionRank is scalable to very large datasets and numbers of label sources, and requires considerably less computational resources than previous approaches.
Knowledge Grounded Conversational Symptom Detection with Graph Memory Networks
Jan 24, 2021
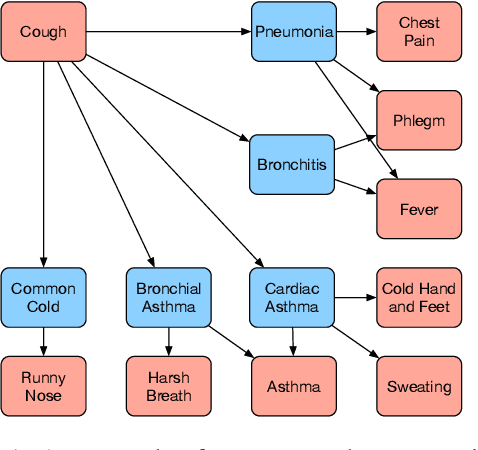

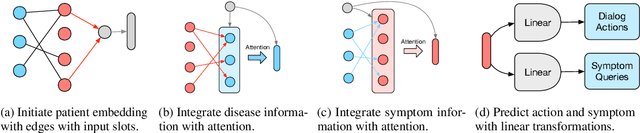
In this work, we propose a novel goal-oriented dialog task, automatic symptom detection. We build a system that can interact with patients through dialog to detect and collect clinical symptoms automatically, which can save a doctor's time interviewing the patient. Given a set of explicit symptoms provided by the patient to initiate a dialog for diagnosing, the system is trained to collect implicit symptoms by asking questions, in order to collect more information for making an accurate diagnosis. After getting the reply from the patient for each question, the system also decides whether current information is enough for a human doctor to make a diagnosis. To achieve this goal, we propose two neural models and a training pipeline for the multi-step reasoning task. We also build a knowledge graph as additional inputs to further improve model performance. Experiments show that our model significantly outperforms the baseline by 4%, discovering 67% of implicit symptoms on average with a limited number of questions.
Boosting Co-teaching with Compression Regularization for Label Noise
Apr 28, 2021
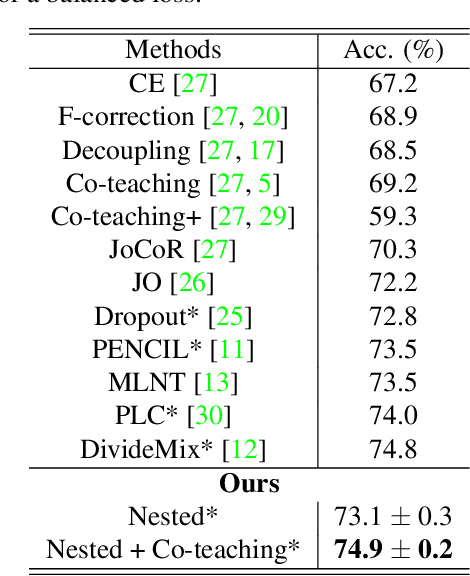
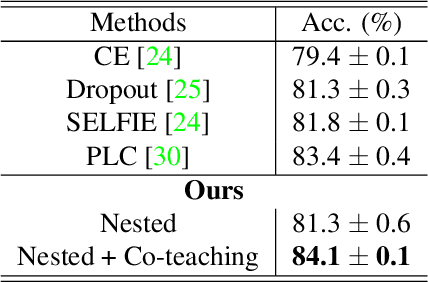
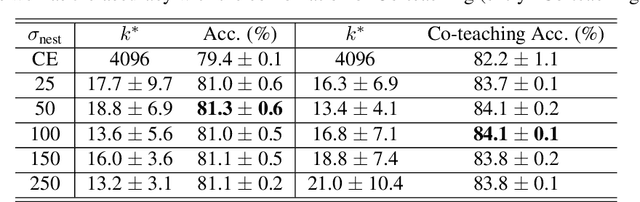
In this paper, we study the problem of learning image classification models in the presence of label noise. We revisit a simple compression regularization named Nested Dropout. We find that Nested Dropout, though originally proposed to perform fast information retrieval and adaptive data compression, can properly regularize a neural network to combat label noise. Moreover, owing to its simplicity, it can be easily combined with Co-teaching to further boost the performance. Our final model remains simple yet effective: it achieves comparable or even better performance than the state-of-the-art approaches on two real-world datasets with label noise which are Clothing1M and ANIMAL-10N. On Clothing1M, our approach obtains 74.9% accuracy which is slightly better than that of DivideMix. On ANIMAL-10N, we achieve 84.1% accuracy while the best public result by PLC is 83.4%. We hope that our simple approach can be served as a strong baseline for learning with label noise. Our implementation is available at https://github.com/yingyichen-cyy/Nested-Co-teaching.
Adaptive Graph Diffusion Networks with Hop-wise Attention
Dec 30, 2020


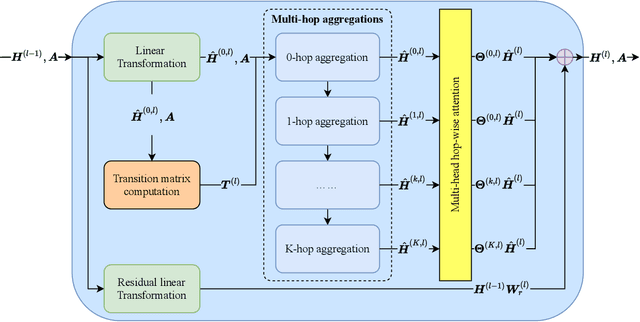
Graph Neural Networks (GNNs) have received much attention recent years and have achieved state-of-the-art performances in many fields. The deeper GNNs can theoretically capture deeper neighborhood information. However, they often suffer from problems of over-fitting and over-smoothing. In order to incorporate deeper information while preserving considerable complexity and generalization ability, we propose Adaptive Graph Diffusion Networks with Hop-wise Attention (AGDNs-HA). We stack multi-hop neighborhood aggregations of different orders into single layer. Then we integrate them with the help of hop-wise attention, which is learnable and adaptive for each node. Experimental results on the standard dataset with semi-supervised node classification task show that our proposed methods achieve significant improvements.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021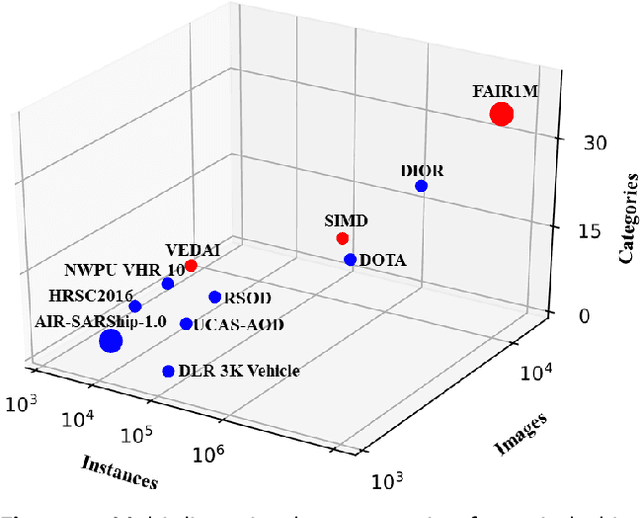
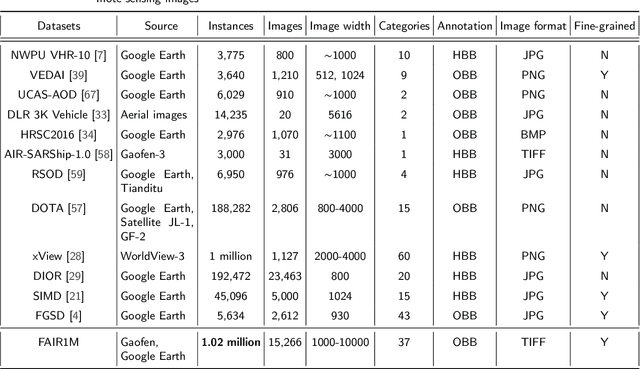
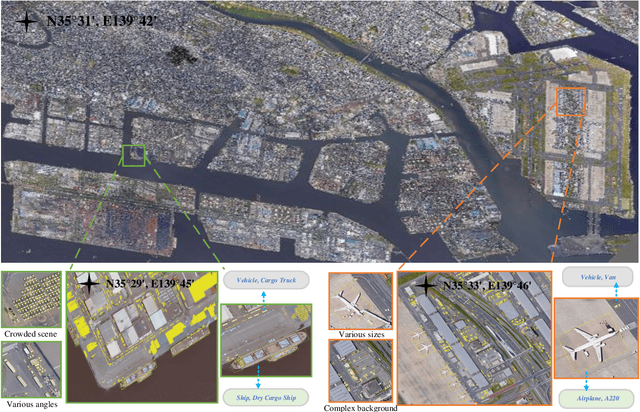
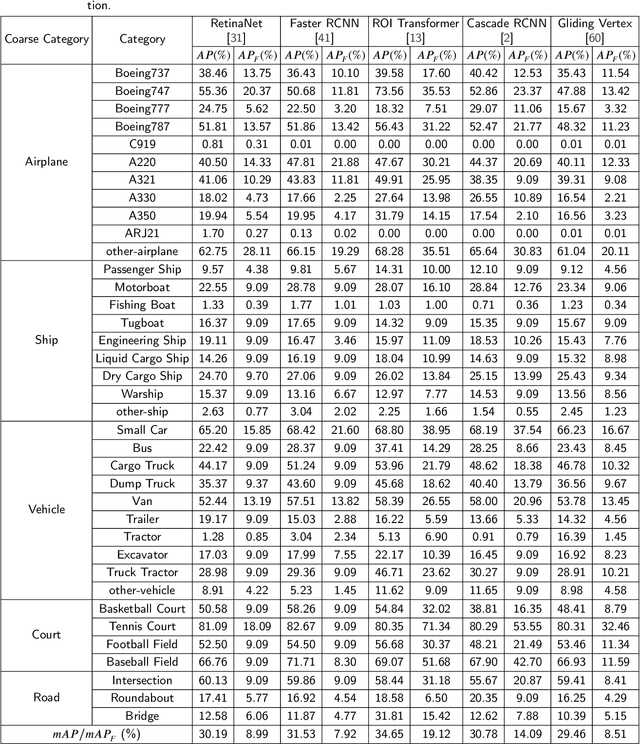
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.