 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PLGRIM: Hierarchical Value Learning for Large-scale Exploration in Unknown Environments
Feb 10, 2021
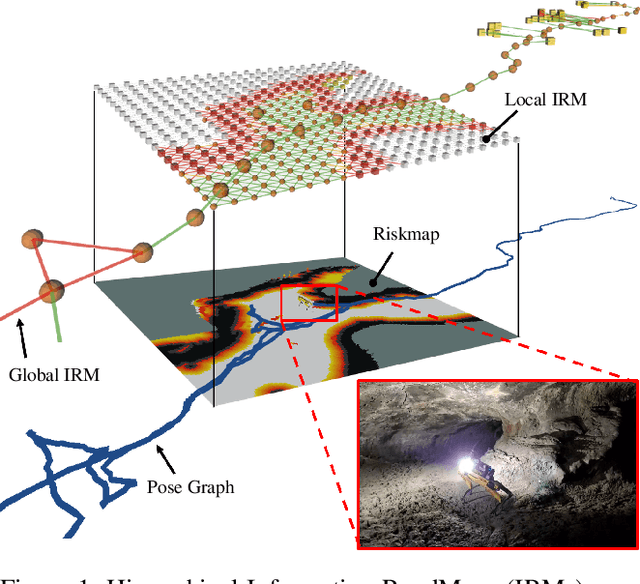
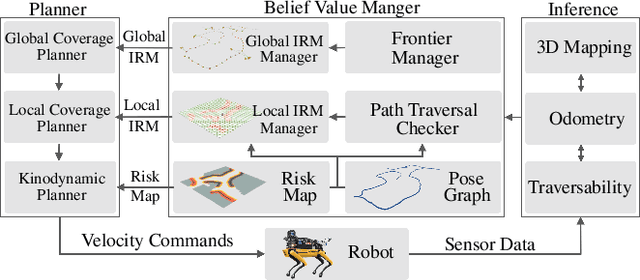
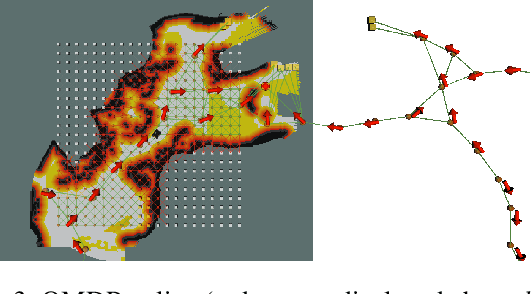
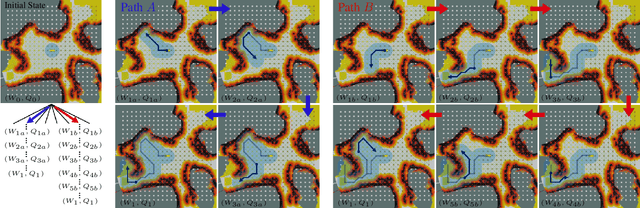
In order for a robot to explore an unknown environment autonomously, it must account for uncertainty in sensor measurements, hazard assessment, localization, and motion execution. Making decisions for maximal reward in a stochastic setting requires learning values and constructing policies over a belief space, i.e., probability distribution of the robot-world state. Value learning over belief spaces suffer from computational challenges in high-dimensional spaces, such as large spatial environments and long temporal horizons for exploration. At the same time, it should be adaptive and resilient to disturbances at run time in order to ensure the robot's safety, as required in many real-world applications. This work proposes a scalable value learning framework, PLGRIM (Probabilistic Local and Global Reasoning on Information roadMaps), that bridges the gap between (i) local, risk-aware resiliency and (ii) global, reward-seeking mission objectives. By leveraging hierarchical belief space planners with information-rich graph structures, PLGRIM can address large-scale exploration problems while providing locally near-optimal coverage plans. PLGRIM is a step toward enabling belief space planners on physical robots operating in unknown and complex environments. We validate our proposed framework with a high-fidelity dynamic simulation in diverse environments and with physical hardware, Boston Dynamics' Spot robot, in a lava tube.
Introducing the Talk Markup Language (TalkML):Adding a little social intelligence to industrial speech interfaces
May 24, 2021



Virtual Personal Assistants like Siri have great potential but such developments hit the fundamental problem of how to make computational devices that understand human speech. Natural language understanding is one of the more disappointing failures of AI research and it seems there is something we computer scientists don't get about the nature of language. Of course philosophers and linguists think quite differently about language and this paper describes how we have taken ideas from other disciplines and implemented them. The background to the work is to take seriously the notion of language as action and look at what people actually do with language using the techniques of Conversation Analysis. The observation has been that human communication is (behind the scenes) about the management of social relations as well as the (foregrounded) passing of information. To claim this is one thing but to implement it requires a mechanism. The mechanism described here is based on the notion of language being intentional - we think intentionally, talk about them and recognise them in others - and cooperative in that we are compelled to help out. The way we are compelled points to a solution to the ever present problem of keeping the human on topic. The approach has led to a recent success in which we significantly improve user satisfaction independent of task completion. Talk Markup Language (TalkML) is a draft alternative to VoiceXML that, we propose, greatly simplifies the scripting of interaction by providing default behaviours for no input and not recognised speech events.
DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data
May 05, 2021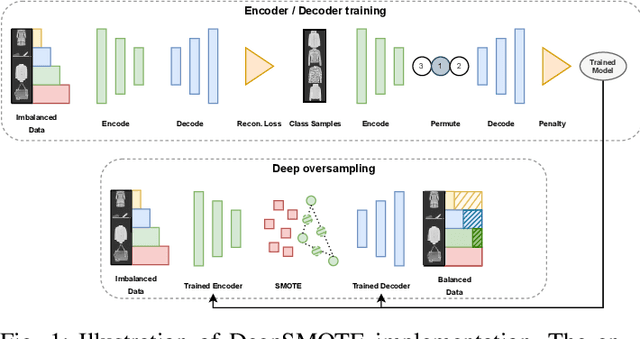

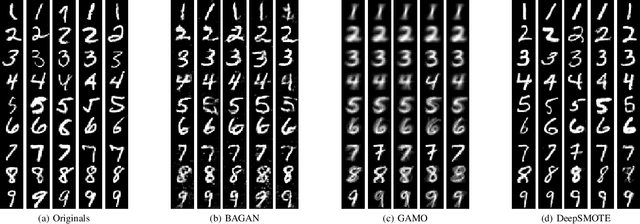

Despite over two decades of progress, imbalanced data is still considered a significant challenge for contemporary machine learning models. Modern advances in deep learning have magnified the importance of the imbalanced data problem. The two main approaches to address this issue are based on loss function modifications and instance resampling. Instance sampling is typically based on Generative Adversarial Networks (GANs), which may suffer from mode collapse. Therefore, there is a need for an oversampling method that is specifically tailored to deep learning models, can work on raw images while preserving their properties, and is capable of generating high quality, artificial images that can enhance minority classes and balance the training set. We propose DeepSMOTE - a novel oversampling algorithm for deep learning models. It is simple, yet effective in its design. It consists of three major components: (i) an encoder/decoder framework; (ii) SMOTE-based oversampling; and (iii) a dedicated loss function that is enhanced with a penalty term. An important advantage of DeepSMOTE over GAN-based oversampling is that DeepSMOTE does not require a discriminator, and it generates high-quality artificial images that are both information-rich and suitable for visual inspection. DeepSMOTE code is publicly available at: https://github.com/dd1github/DeepSMOTE
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021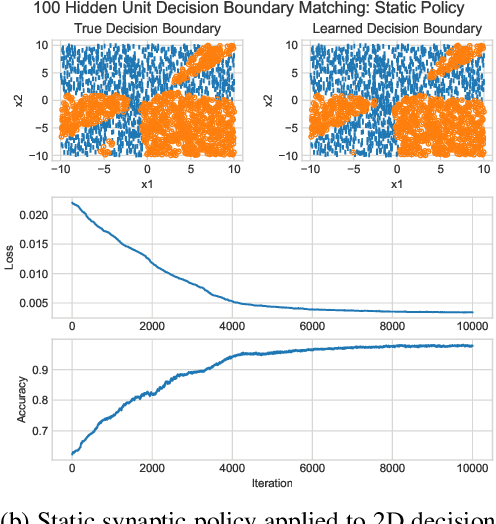
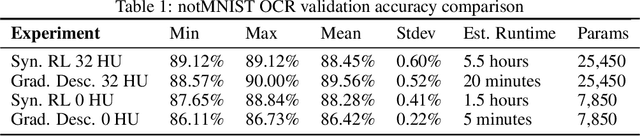
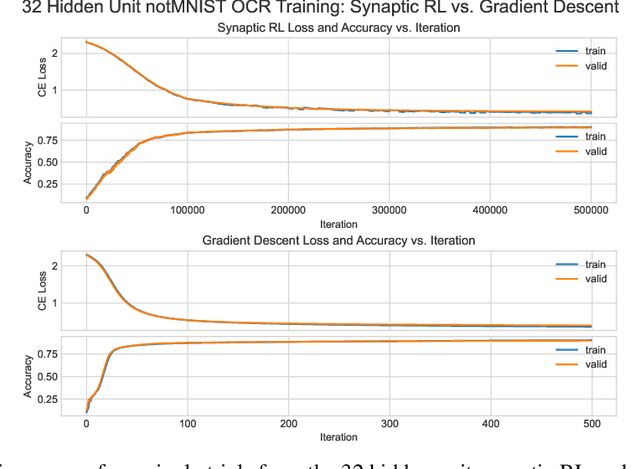
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.
Pose-driven Attention-guided Image Generation for Person Re-Identification
Apr 28, 2021
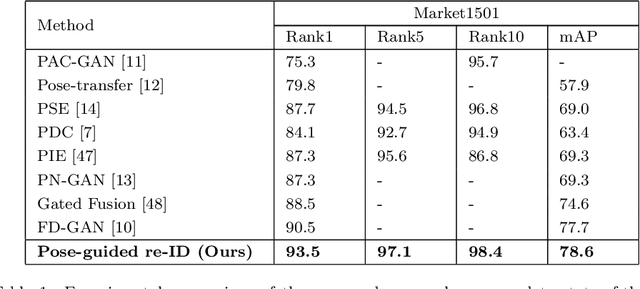
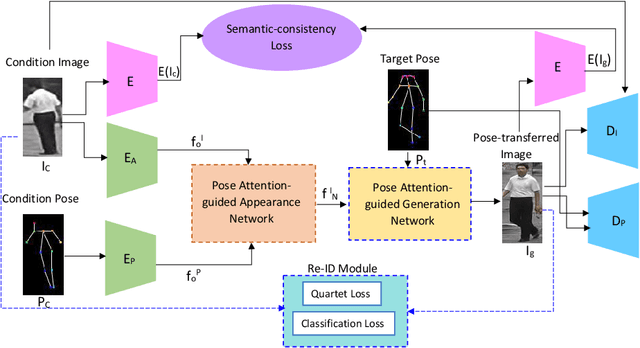
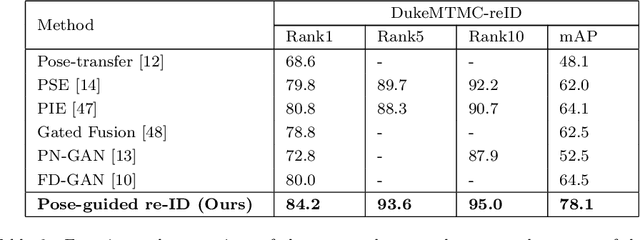
Person re-identification (re-ID) concerns the matching of subject images across different camera views in a multi camera surveillance system. One of the major challenges in person re-ID is pose variations across the camera network, which significantly affects the appearance of a person. Existing development data lack adequate pose variations to carry out effective training of person re-ID systems. To solve this issue, in this paper we propose an end-to-end pose-driven attention-guided generative adversarial network, to generate multiple poses of a person. We propose to attentively learn and transfer the subject pose through an attention mechanism. A semantic-consistency loss is proposed to preserve the semantic information of the person during pose transfer. To ensure fine image details are realistic after pose translation, an appearance discriminator is used while a pose discriminator is used to ensure the pose of the transferred images will exactly be the same as the target pose. We show that by incorporating the proposed approach in a person re-identification framework, realistic pose transferred images and state-of-the-art re-identification results can be achieved.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 02, 2021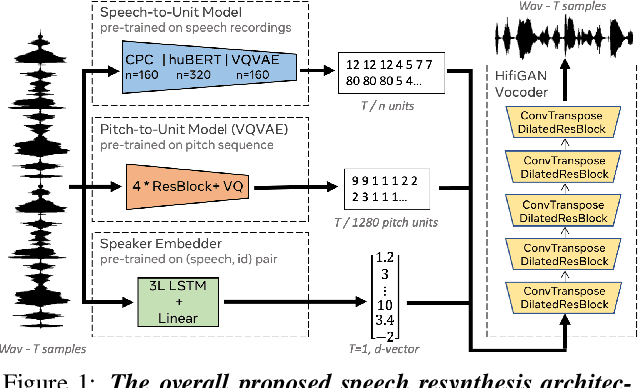
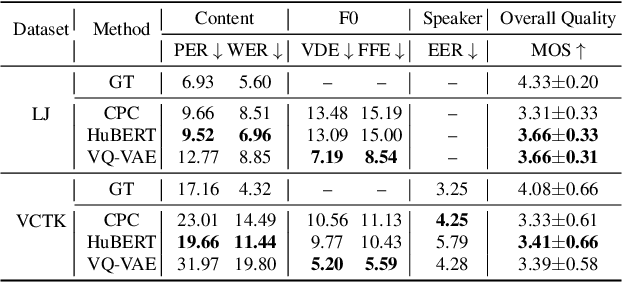
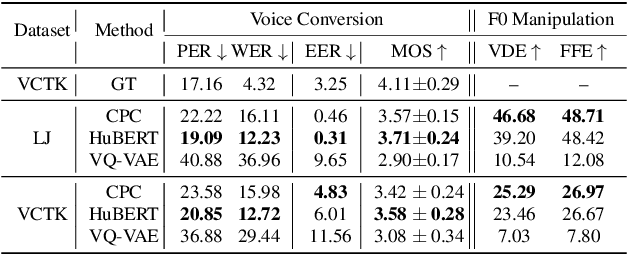
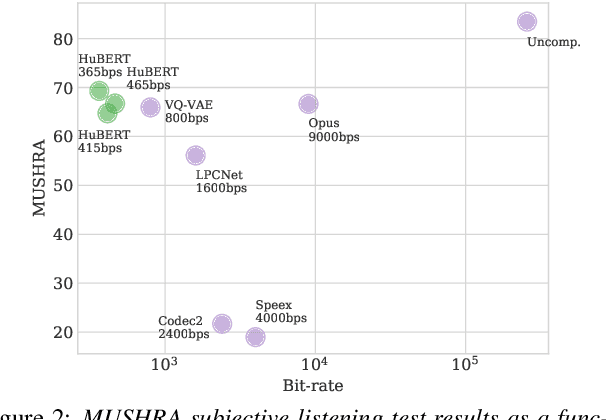
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
Surrogate assisted active subspace and active subspace assisted surrogate -- A new paradigm for high dimensional structural reliability analysis
May 12, 2021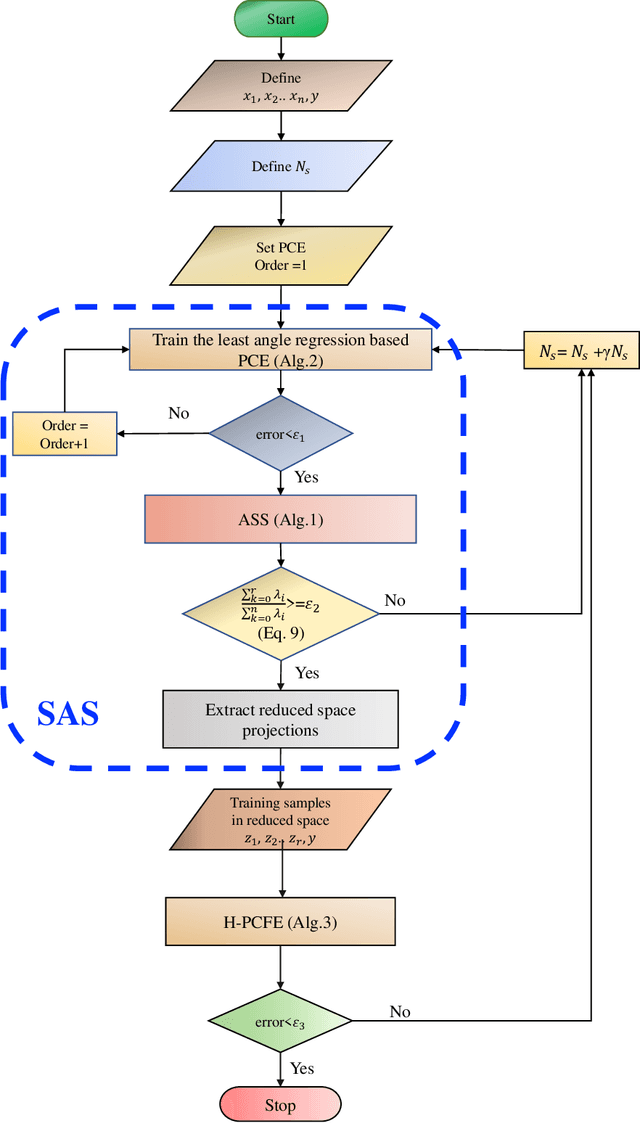
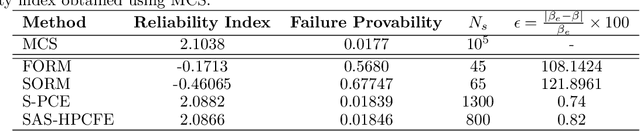
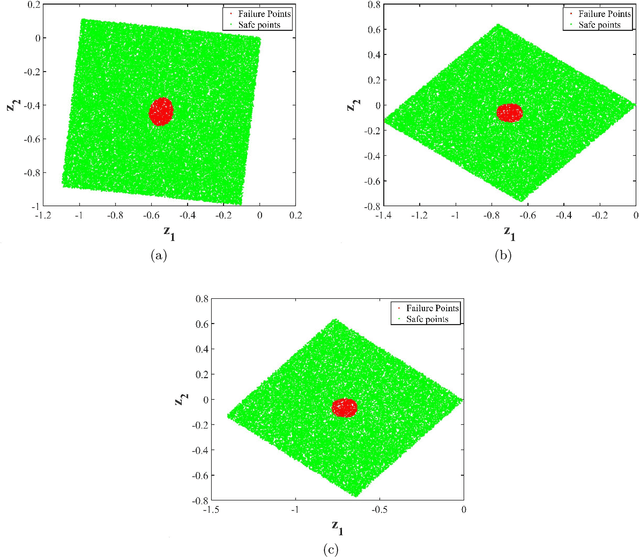
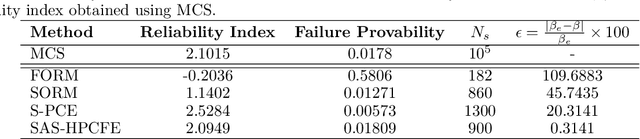
Performing reliability analysis on complex systems is often computationally expensive. In particular, when dealing with systems having high input dimensionality, reliability estimation becomes a daunting task. A popular approach to overcome the problem associated with time-consuming and expensive evaluations is building a surrogate model. However, these computationally efficient models often suffer from the curse of dimensionality. Hence, training a surrogate model for high-dimensional problems is not straightforward. Henceforth, this paper presents a framework for solving high-dimensional reliability analysis problems. The basic premise is to train the surrogate model on a low-dimensional manifold, discovered using the active subspace algorithm. However, learning the low-dimensional manifold using active subspace is non-trivial as it requires information on the gradient of the response variable. To address this issue, we propose using sparse learning algorithms in conjunction with the active subspace algorithm; the resulting algorithm is referred to as the sparse active subspace (SAS) algorithm. We project the high-dimensional inputs onto the identified low-dimensional manifold identified using SAS. A high-fidelity surrogate model is used to map the inputs on the low-dimensional manifolds to the output response. We illustrate the efficacy of the proposed framework by using three benchmark reliability analysis problems from the literature. The results obtained indicate the accuracy and efficiency of the proposed approach compared to already established reliability analysis methods in the literature.
Geometric Deep Learning on Anatomical Meshes for the Prediction of Alzheimer's Disease
Apr 20, 2021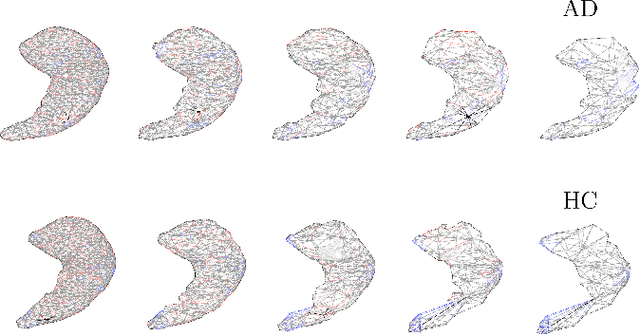
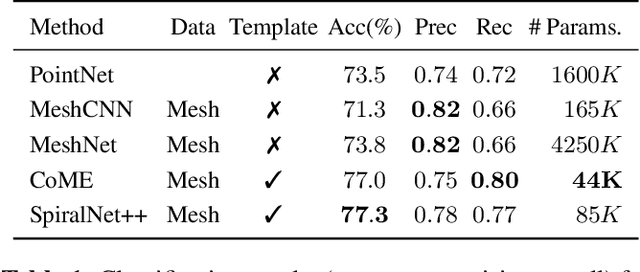
Geometric deep learning can find representations that are optimal for a given task and therefore improve the performance over pre-defined representations. While current work has mainly focused on point representations, meshes also contain connectivity information and are therefore a more comprehensive characterization of the underlying anatomical surface. In this work, we evaluate four recent geometric deep learning approaches that operate on mesh representations. These approaches can be grouped into template-free and template-based approaches, where the template-based methods need a more elaborate pre-processing step with the definition of a common reference template and correspondences. We compare the different networks for the prediction of Alzheimer's disease based on the meshes of the hippocampus. Our results show advantages for template-based methods in terms of accuracy, number of learnable parameters, and training speed. While the template creation may be limiting for some applications, neuroimaging has a long history of building templates with automated tools readily available. Overall, working with meshes is more involved than working with simplistic point clouds, but they also offer new avenues for designing geometric deep learning architectures.
Multistage BiCross Encoder: Team GATE Entry for MLIA Multilingual Semantic Search Task 2
Jan 15, 2021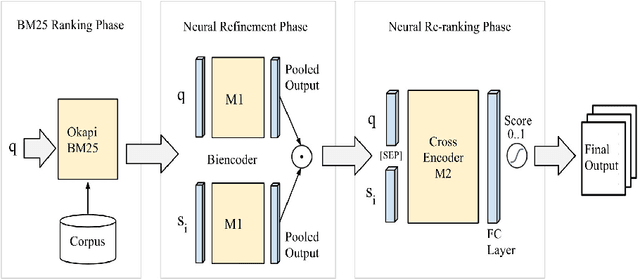
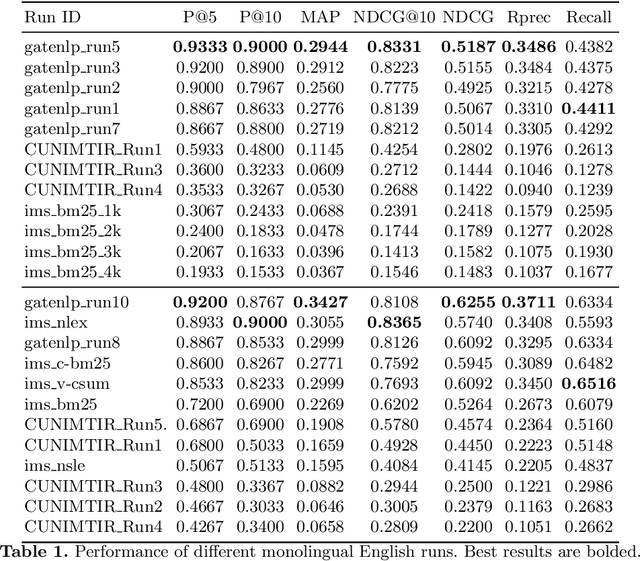
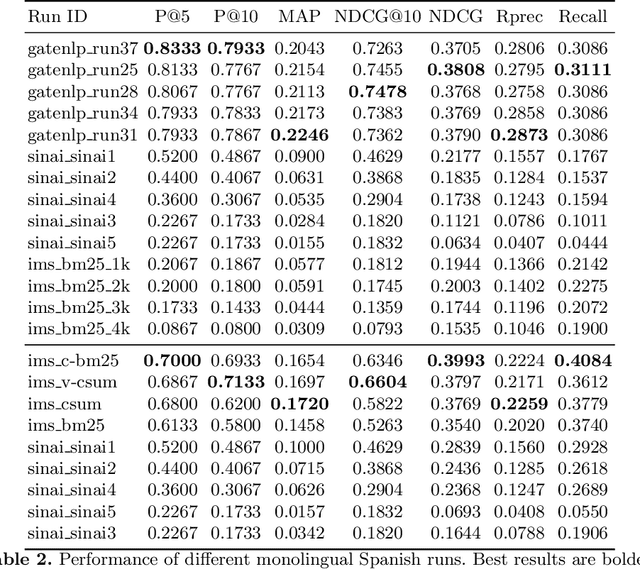
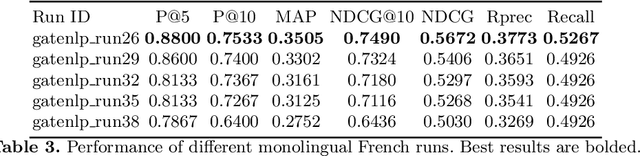
The Coronavirus (COVID-19) pandemic has led to a rapidly growing `infodemic' online. Thus, the accurate retrieval of reliable relevant data from millions of documents about COVID-19 has become urgently needed for the general public as well as for other stakeholders. The COVID-19 Multilingual Information Access (MLIA) initiative is a joint effort to ameliorate exchange of COVID-19 related information by developing applications and services through research and community participation. In this work, we present a search system called Multistage BiCross Encoder, developed by team GATE for the MLIA task 2 Multilingual Semantic Search. Multistage BiCross-Encoder is a sequential three stage pipeline which uses the Okapi BM25 algorithm and a transformer based bi-encoder and cross-encoder to effectively rank the documents with respect to the query. The results of round 1 show that our models achieve state-of-the-art performance for all ranking metrics for both monolingual and bilingual runs.
Text-Aware Predictive Monitoring of Business Processes
Apr 20, 2021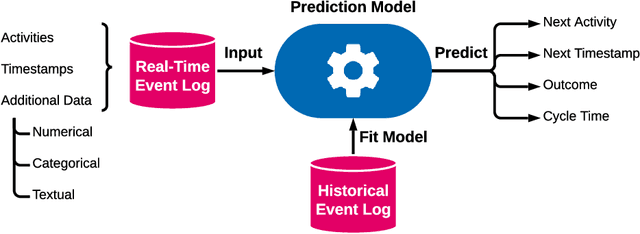

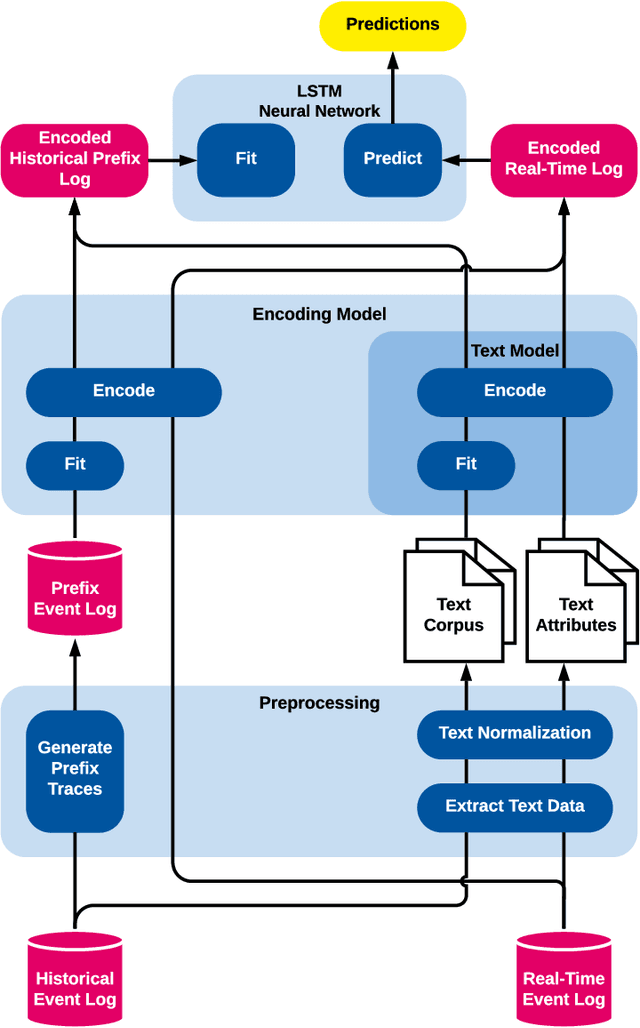
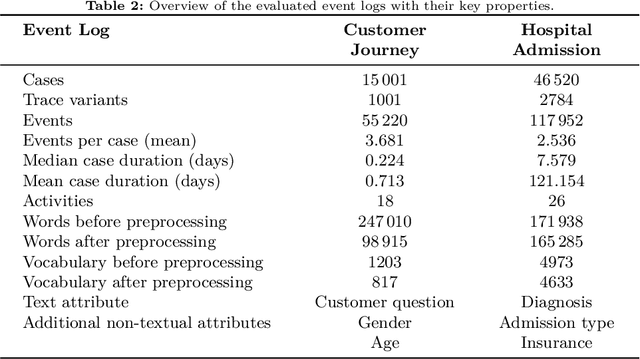
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.