 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RIS-Aided Cell-Free Massive MIMO: Performance Analysis and Competitiveness
May 06, 2021
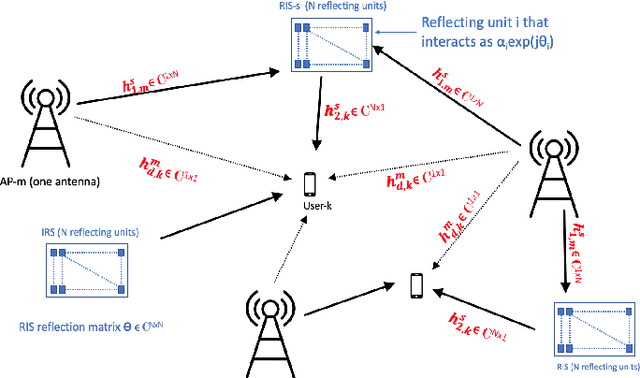
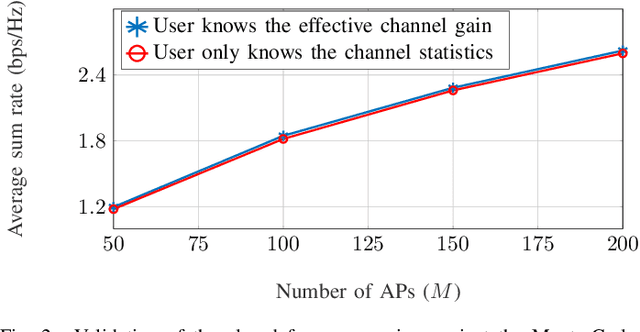
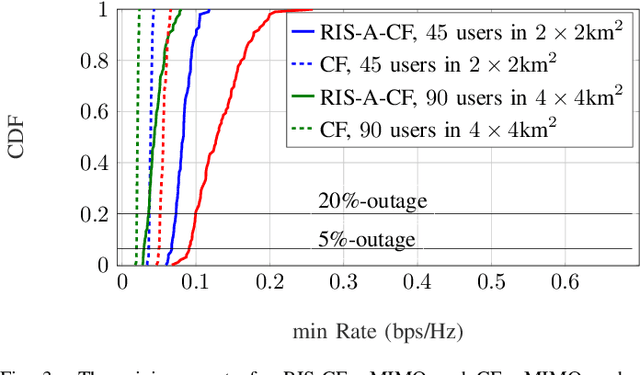
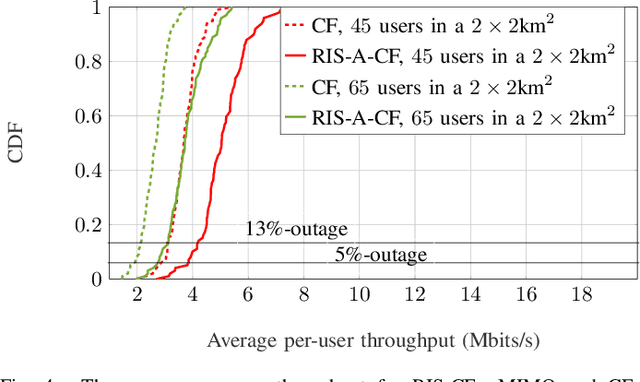
In this paper, we consider and study a cell-free massive MIMO (CF-mMIMO) system aided with reconfigurable intelligent surfaces (RISs), where a large number of access points (APs) cooperate to serve a smaller number of users with the help of RIS technology. We consider imperfect channel state information (CSI), where each AP uses the local channel estimates obtained from the uplink pilots and applies conjugate beamforming for downlink data transmission. Additionally, we consider random beamforming at the RIS during both training and data transmission phases. This allows us to eliminate the need of estimating each RIS assisted link, which has been proven to be a challenging task in literature. We then derive a closed-form expression for the achievable rate and use it to evaluate the system's performance supported with numerical results. We show that the RIS provided array gain improves the system's coverage, and provides nearly a 2-fold increase in the minimum rate and a 1.5-fold increase in the per-user throughput. We also use the results to provide preliminary insights on the number of RISs that need to be used to replace an AP, while achieving similar performance as a typical CF-mMIMO system with dense AP deployment.
Frame-independent vector-cloud neural network for nonlocal constitutive modelling on arbitrary grids
Mar 11, 2021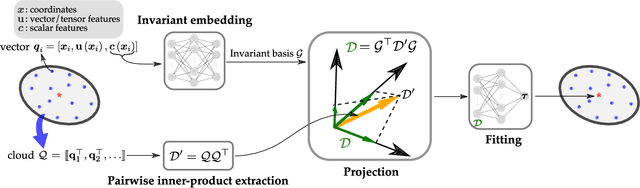
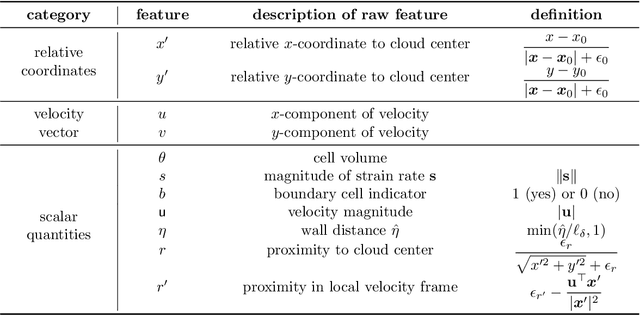
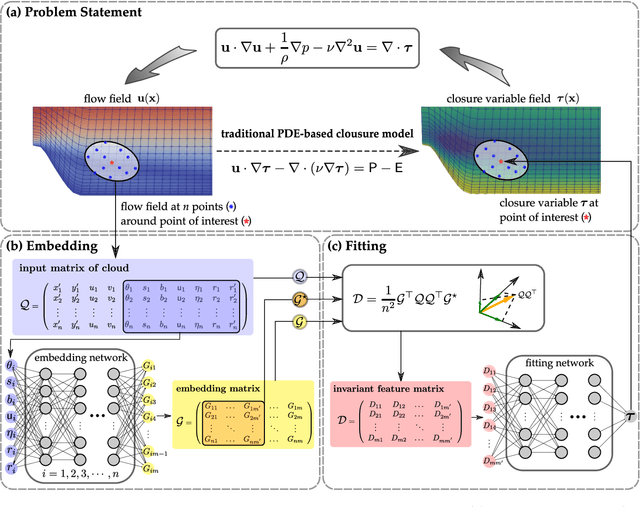

Constitutive models are widely used for modelling complex systems in science and engineering, where first-principle-based, well-resolved simulations are often prohibitively expensive. For example, in fluid dynamics, constitutive models are required to describe nonlocal, unresolved physics such as turbulence and laminar-turbulent transition. In particular, Reynolds stress models for turbulence and intermittency transport equations for laminar-turbulent transition both utilize convection--diffusion partial differential equations (PDEs). However, traditional PDE-based constitutive models can lack robustness and are often too rigid to accommodate diverse calibration data. We propose a frame-independent, nonlocal constitutive model based on a vector-cloud neural network that can be trained with data. The learned constitutive model can predict the closure variable at a point based on the flow information in its neighborhood. Such nonlocal information is represented by a group of points, each having a feature vector attached to it, and thus the input is referred to as vector cloud. The cloud is mapped to the closure variable through a frame-independent neural network, which is invariant both to coordinate translation and rotation and to the ordering of points in the cloud. As such, the network takes any number of arbitrarily arranged grid points as input and thus is suitable for unstructured meshes commonly used in fluid flow simulations. The merits of the proposed network are demonstrated on scalar transport PDEs on a family of parameterized periodic hill geometries. Numerical results show that the vector-cloud neural network is a promising tool not only as nonlocal constitutive models and but also as general surrogate models for PDEs on irregular domains.
Correcting Classification: A Bayesian Framework Using Explanation Feedback to Improve Classification Abilities
Apr 29, 2021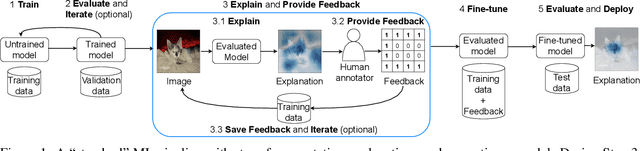
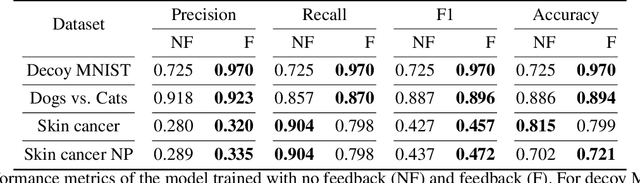

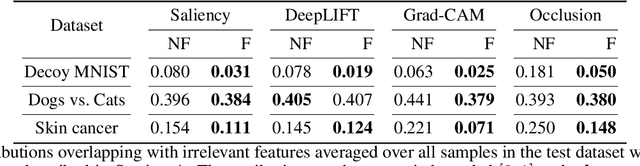
Neural networks (NNs) have shown high predictive performance, however, with shortcomings. Firstly, the reasons behind the classifications are not fully understood. Several explanation methods have been developed, but they do not provide mechanisms for users to interact with the explanations. Explanations are social, meaning they are a transfer of knowledge through interactions. Nonetheless, current explanation methods contribute only to one-way communication. Secondly, NNs tend to be overconfident, providing unreasonable uncertainty estimates on out-of-distribution observations. We overcome these difficulties by training a Bayesian convolutional neural network (CNN) that uses explanation feedback. After training, the model presents explanations of training sample classifications to an annotator. Based on the provided information, the annotator can accept or reject the explanations by providing feedback. Our proposed method utilizes this feedback for fine-tuning to correct the model such that the explanations and classifications improve. We use existing CNN architectures to demonstrate the method's effectiveness on one toy dataset (decoy MNIST) and two real-world datasets (Dogs vs. Cats and ISIC skin cancer). The experiments indicate that few annotated explanations and fine-tuning epochs are needed to improve the model and predictive performance, making the model more trustworthy and understandable.
DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
May 19, 2021
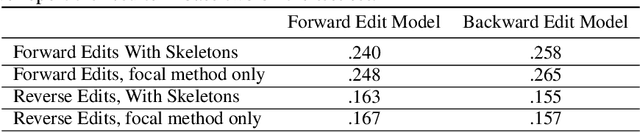


The joint task of bug localization and program repair is an integral part of the software development process. In this work we present DeepDebug, an approach to automated debugging using large, pretrained transformers. We begin by training a bug-creation model on reversed commit data for the purpose of generating synthetic bugs. We apply these synthetic bugs toward two ends. First, we directly train a backtranslation model on all functions from 200K repositories. Next, we focus on 10K repositories for which we can execute tests, and create buggy versions of all functions in those repositories that are covered by passing tests. This provides us with rich debugging information such as stack traces and print statements, which we use to finetune our model which was pretrained on raw source code. Finally, we strengthen all our models by expanding the context window beyond the buggy function itself, and adding a skeleton consisting of that function's parent class, imports, signatures, docstrings, and method bodies, in order of priority. On the QuixBugs benchmark, we increase the total number of fixes found by over 50%, while also decreasing the false positive rate from 35% to 5% and decreasing the timeout from six hours to one minute. On our own benchmark of executable tests, our model fixes 68% of all bugs on its first attempt without using traces, and after adding traces it fixes 75% on first attempt. We will open-source our framework and validation set for evaluating on executable tests.
Invertible Denoising Network: A Light Solution for Real Noise Removal
Apr 21, 2021


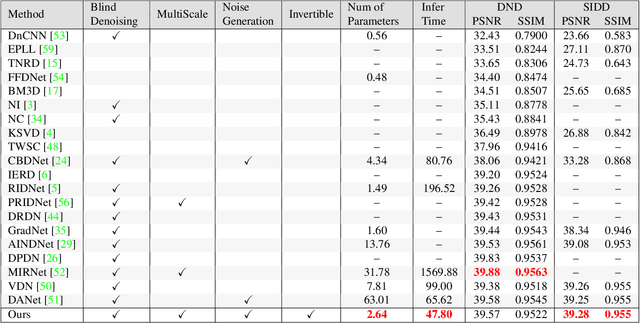
Invertible networks have various benefits for image denoising since they are lightweight, information-lossless, and memory-saving during back-propagation. However, applying invertible models to remove noise is challenging because the input is noisy, and the reversed output is clean, following two different distributions. We propose an invertible denoising network, InvDN, to address this challenge. InvDN transforms the noisy input into a low-resolution clean image and a latent representation containing noise. To discard noise and restore the clean image, InvDN replaces the noisy latent representation with another one sampled from a prior distribution during reversion. The denoising performance of InvDN is better than all the existing competitive models, achieving a new state-of-the-art result for the SIDD dataset while enjoying less run time. Moreover, the size of InvDN is far smaller, only having 4.2% of the number of parameters compared to the most recently proposed DANet. Further, via manipulating the noisy latent representation, InvDN is also able to generate noise more similar to the original one. Our code is available at: https://github.com/Yang-Liu1082/InvDN.git.
Text-Aware Predictive Monitoring of Business Processes
Apr 21, 2021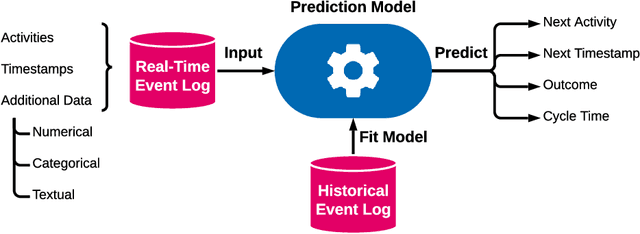

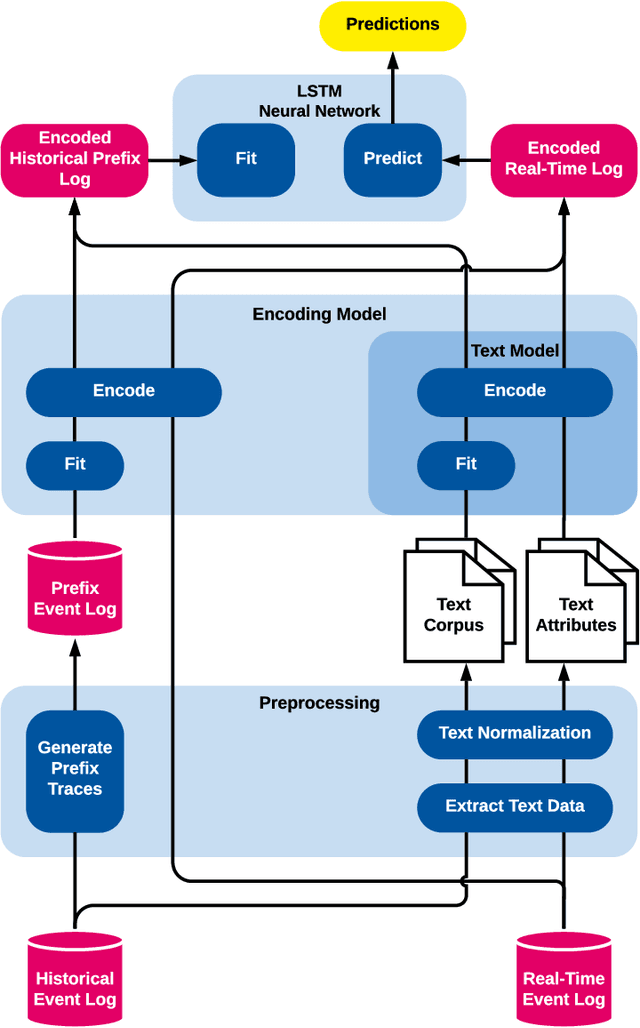
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
May 06, 2021


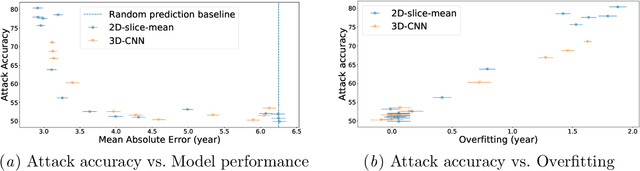
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.
Active learning for medical code assignment
Apr 12, 2021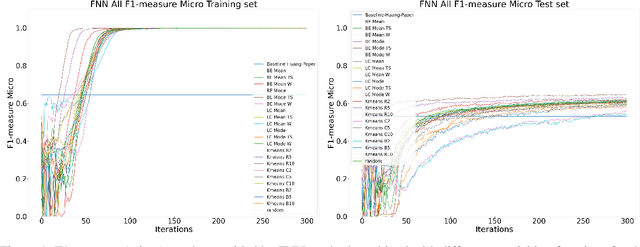
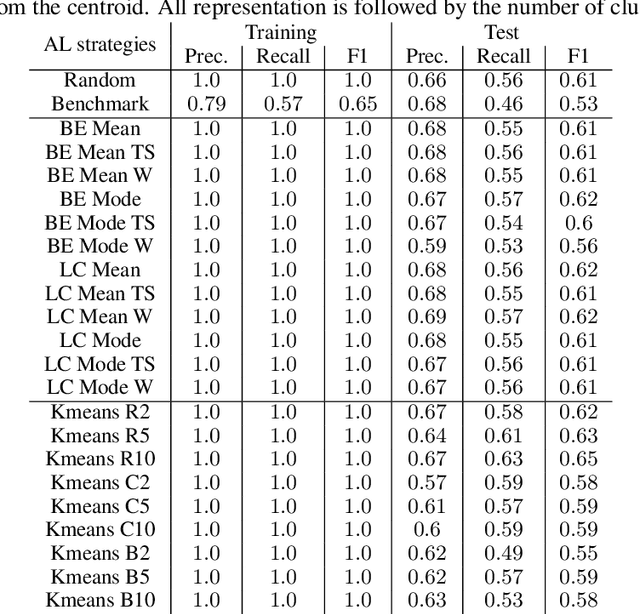
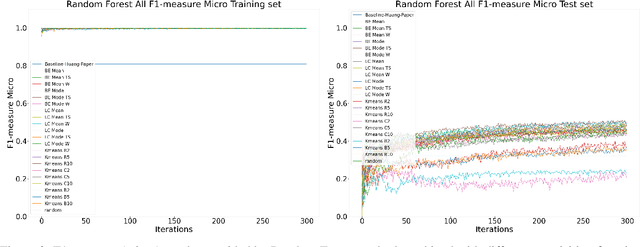
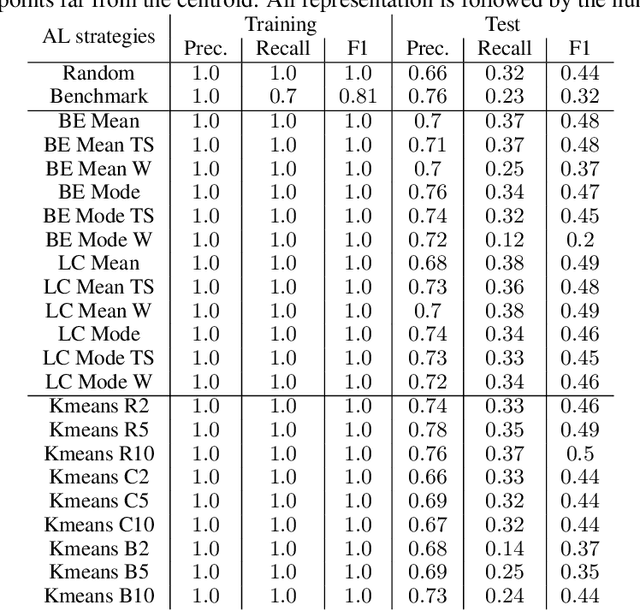
Machine Learning (ML) is widely used to automatically extract meaningful information from Electronic Health Records (EHR) to support operational, clinical, and financial decision-making. However, ML models require a large number of annotated examples to provide satisfactory results, which is not possible in most healthcare scenarios due to the high cost of clinician-labeled data. Active Learning (AL) is a process of selecting the most informative instances to be labeled by an expert to further train a supervised algorithm. We demonstrate the effectiveness of AL in multi-label text classification in the clinical domain. In this context, we apply a set of well-known AL methods to help automatically assign ICD-9 codes on the MIMIC-III dataset. Our results show that the selection of informative instances provides satisfactory classification with a significantly reduced training set (8.3\% of the total instances). We conclude that AL methods can significantly reduce the manual annotation cost while preserving model performance.
Towards Efficient Graph Convolutional Networks for Point Cloud Handling
Apr 12, 2021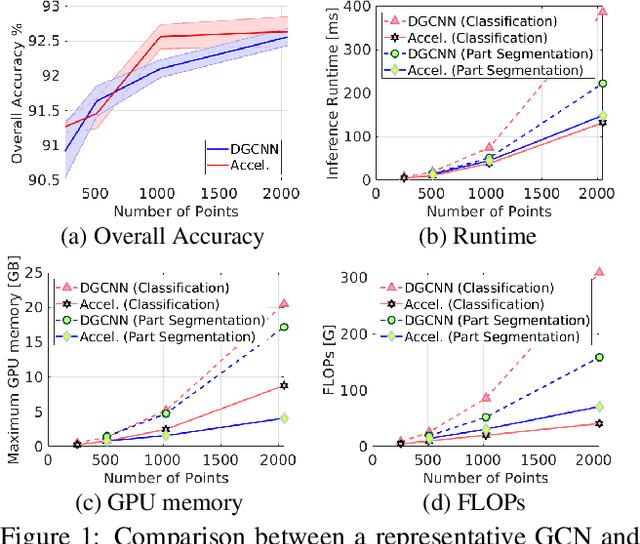
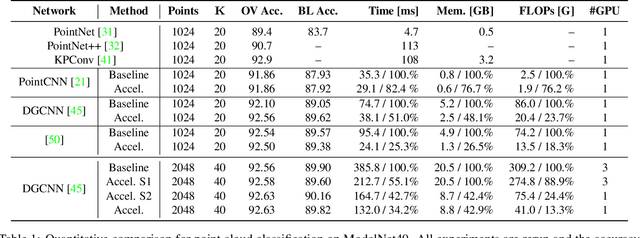
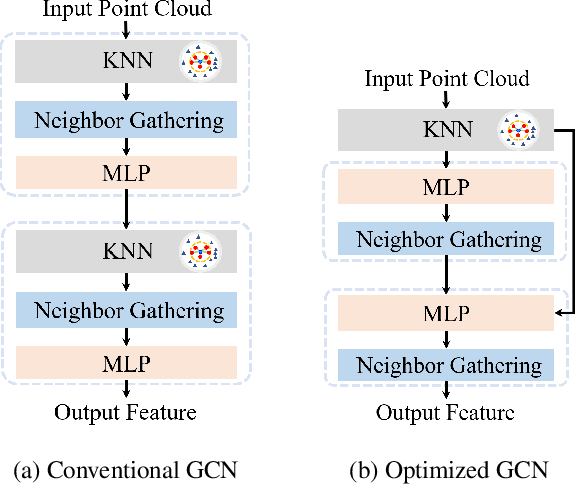

In this paper, we aim at improving the computational efficiency of graph convolutional networks (GCNs) for learning on point clouds. The basic graph convolution that is typically composed of a $K$-nearest neighbor (KNN) search and a multilayer perceptron (MLP) is examined. By mathematically analyzing the operations there, two findings to improve the efficiency of GCNs are obtained. (1) The local geometric structure information of 3D representations propagates smoothly across the GCN that relies on KNN search to gather neighborhood features. This motivates the simplification of multiple KNN searches in GCNs. (2) Shuffling the order of graph feature gathering and an MLP leads to equivalent or similar composite operations. Based on those findings, we optimize the computational procedure in GCNs. A series of experiments show that the optimized networks have reduced computational complexity, decreased memory consumption, and accelerated inference speed while maintaining comparable accuracy for learning on point clouds. Code will be available at \url{https://github.com/ofsoundof/EfficientGCN.git}.
Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning
May 19, 2021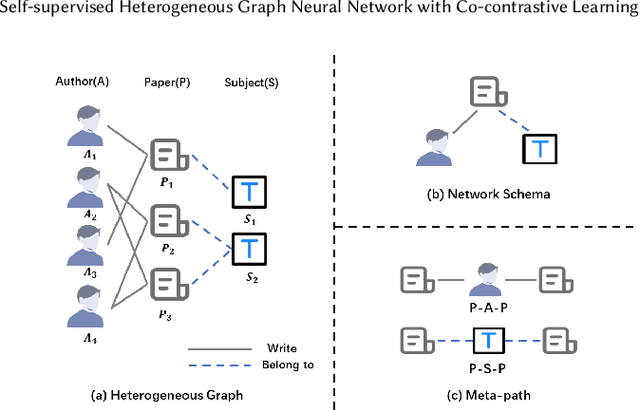
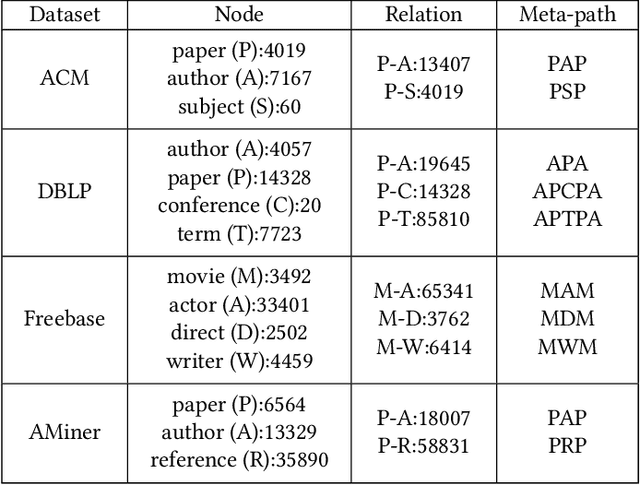
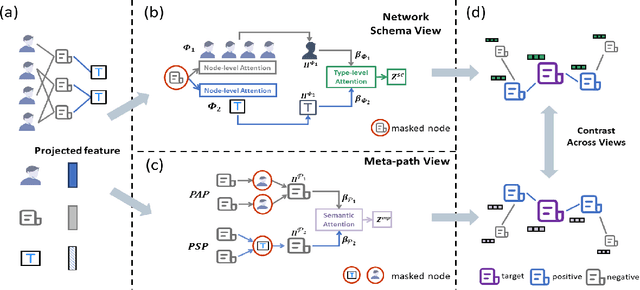
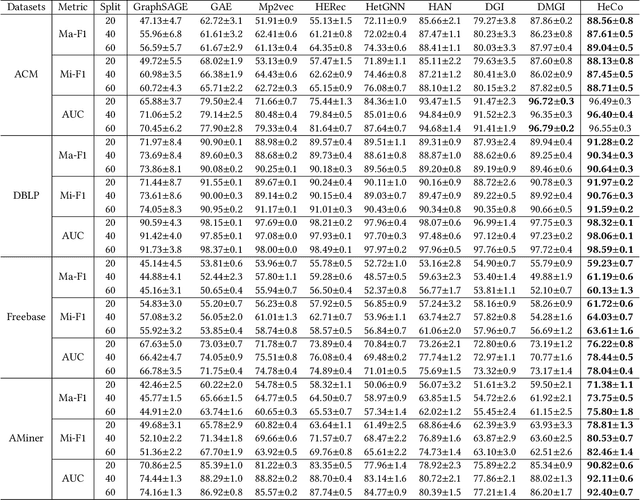
Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-viewcontrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, two extensions of HeCo are designed to generate harder negative samples with high quality, which further boosts the performance of HeCo. Extensive experiments conducted on a variety of real-world networks show the superior performance of the proposed methods over the state-of-the-arts.