 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021

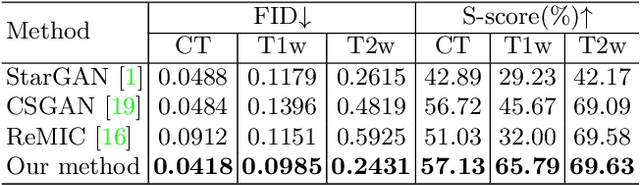
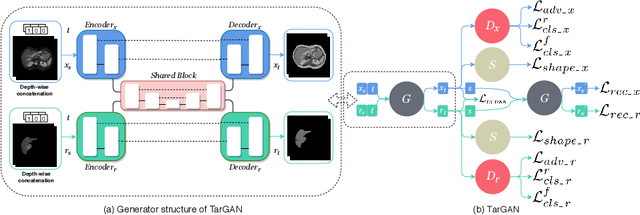
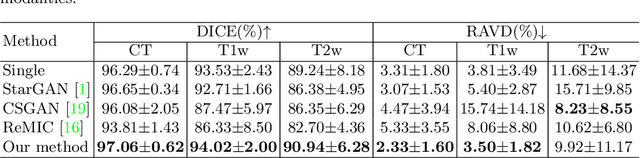
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.
Invertible Denoising Network: A Light Solution for Real Noise Removal
Apr 21, 2021


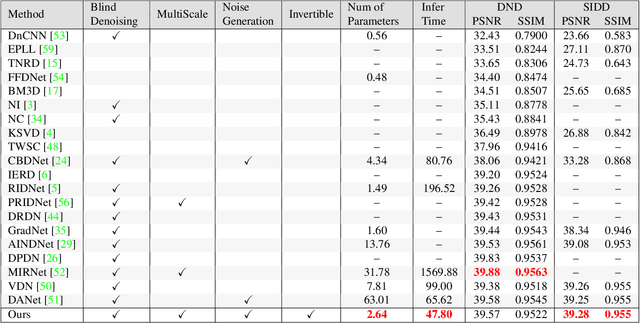
Invertible networks have various benefits for image denoising since they are lightweight, information-lossless, and memory-saving during back-propagation. However, applying invertible models to remove noise is challenging because the input is noisy, and the reversed output is clean, following two different distributions. We propose an invertible denoising network, InvDN, to address this challenge. InvDN transforms the noisy input into a low-resolution clean image and a latent representation containing noise. To discard noise and restore the clean image, InvDN replaces the noisy latent representation with another one sampled from a prior distribution during reversion. The denoising performance of InvDN is better than all the existing competitive models, achieving a new state-of-the-art result for the SIDD dataset while enjoying less run time. Moreover, the size of InvDN is far smaller, only having 4.2% of the number of parameters compared to the most recently proposed DANet. Further, via manipulating the noisy latent representation, InvDN is also able to generate noise more similar to the original one. Our code is available at: https://github.com/Yang-Liu1082/InvDN.git.
A Framework of Explanation Generation toward Reliable Autonomous Robots
May 06, 2021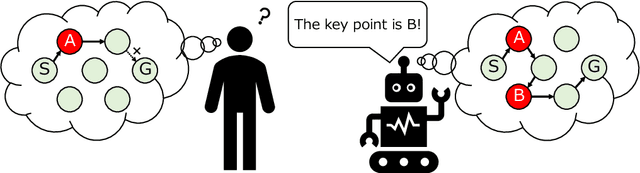

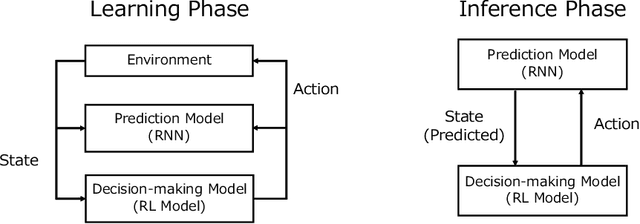
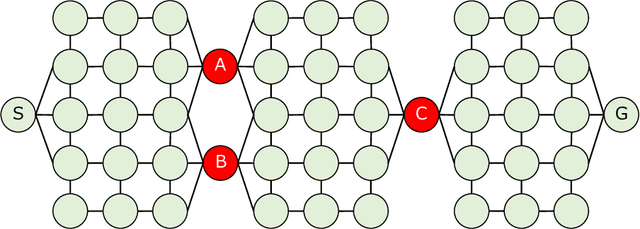
To realize autonomous collaborative robots, it is important to increase the trust that users have in them. Toward this goal, this paper proposes an algorithm which endows an autonomous agent with the ability to explain the transition from the current state to the target state in a Markov decision process (MDP). According to cognitive science, to generate an explanation that is acceptable to humans, it is important to present the minimum information necessary to sufficiently understand an event. To meet this requirement, this study proposes a framework for identifying important elements in the decision-making process using a prediction model for the world and generating explanations based on these elements. To verify the ability of the proposed method to generate explanations, we conducted an experiment using a grid environment. It was inferred from the result of a simulation experiment that the explanation generated using the proposed method was composed of the minimum elements important for understanding the transition from the current state to the target state. Furthermore, subject experiments showed that the generated explanation was a good summary of the process of state transition, and that a high evaluation was obtained for the explanation of the reason for an action.
Text-Aware Predictive Monitoring of Business Processes
Apr 21, 2021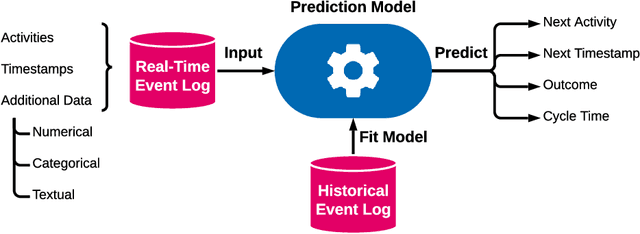

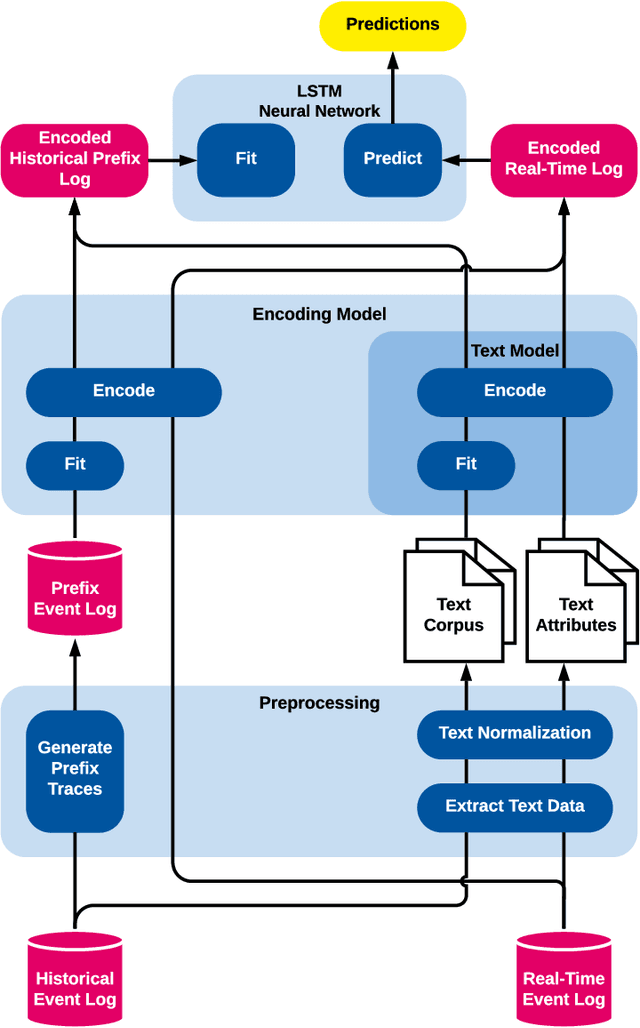
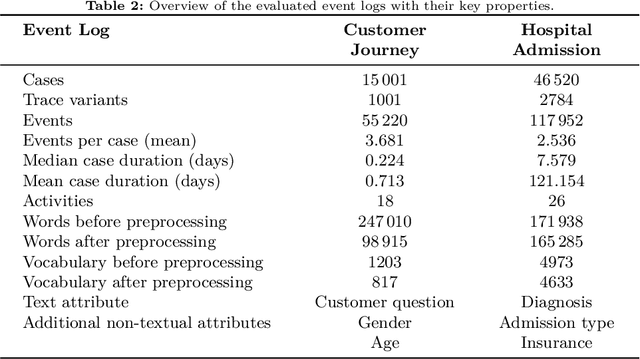
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
Post-Hoc Domain Adaptation via Guided Data Homogenization
Apr 08, 2021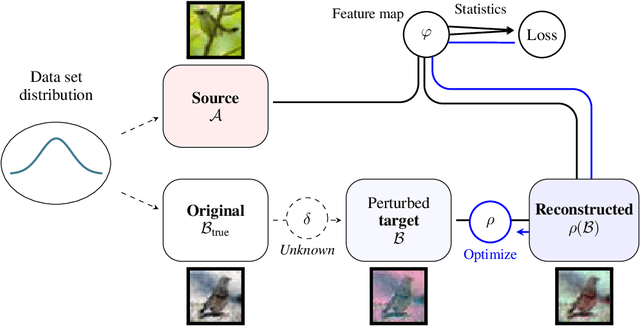
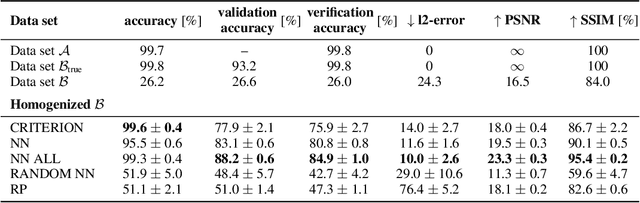

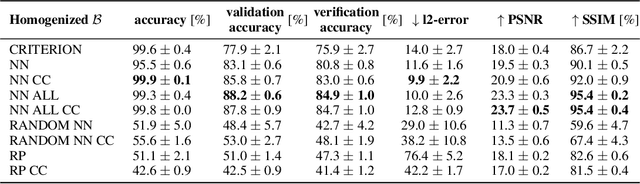
Addressing shifts in data distributions is an important prerequisite for the deployment of deep learning models to real-world settings. A general approach to this problem involves the adjustment of models to a new domain through transfer learning. However, in many cases, this is not applicable in a post-hoc manner to deployed models and further parameter adjustments jeopardize safety certifications that were established beforehand. In such a context, we propose to deal with changes in the data distribution via guided data homogenization which shifts the burden of adaptation from the model to the data. This approach makes use of information about the training data contained implicitly in the deep learning model to learn a domain transfer function. This allows for a targeted deployment of models to unknown scenarios without changing the model itself. We demonstrate the potential of data homogenization through experiments on the CIFAR-10 and MNIST data sets.
Needmining: Designing Digital Support to Elicit Needs from Social Media
Jan 14, 2021


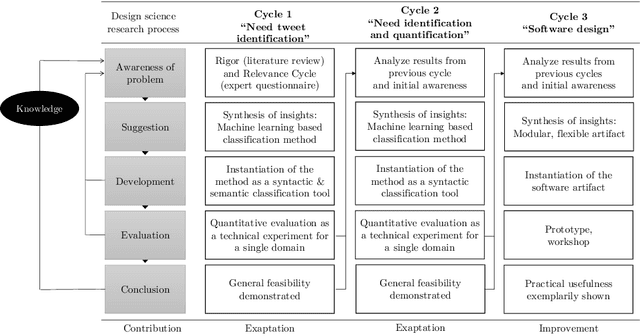
Today's businesses face a high pressure to innovate in order to succeed in highly competitive markets. Successful innovations, though, typically require the identification and analysis of customer needs. While traditional, established need elicitation methods are time-proven and have demonstrated their capabilities to deliver valuable insights, they lack automation and scalability and, thus, are expensive and time-consuming. In this article, we propose an approach to automatically identify and quantify customer needs by utilizing a novel data source: Users voluntarily and publicly expose information about themselves via social media, as for instance Facebook or Twitter. These posts may contain valuable information about the needs, wants, and demands of their authors. We apply a Design Science Research (DSR) methodology to add design knowledge and artifacts for the digitalization of innovation processes, in particular to provide digital support for the elicitation of customer needs. We want to investigate whether automated, speedy, and scalable need elicitation from social media is feasible. We concentrate on Twitter as a data source and on e-mobility as an application domain. In a first design cycle we conceive, implement and evaluate a method to demonstrate the feasibility of identifying those social media posts that actually express customer needs. In a second cycle, we build on this artifact to additionally quantify the need information elicited, and prove its feasibility. Third, we integrate both developed methods into an end-user software artifact and test usability in an industrial use case. Thus, we add new methods for need elicitation to the body of knowledge, and introduce concrete tooling for innovation management in practice.
A Novel Falling-Ball Algorithm for Image Segmentation
May 06, 2021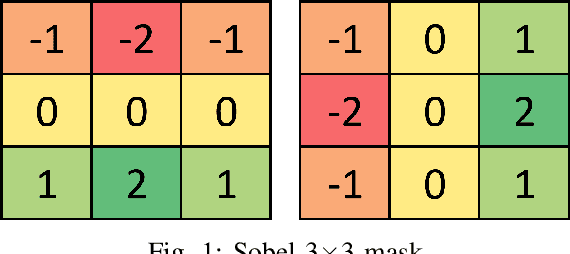
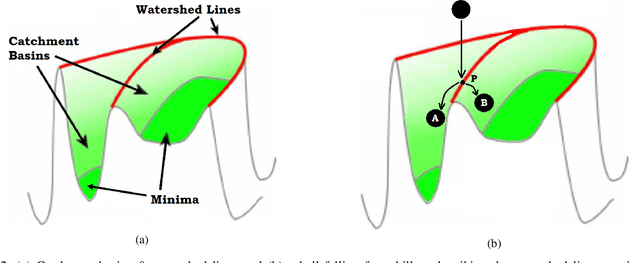
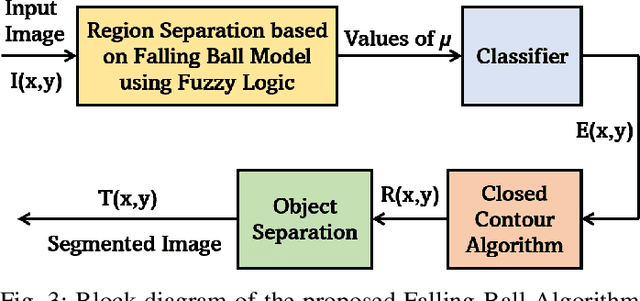
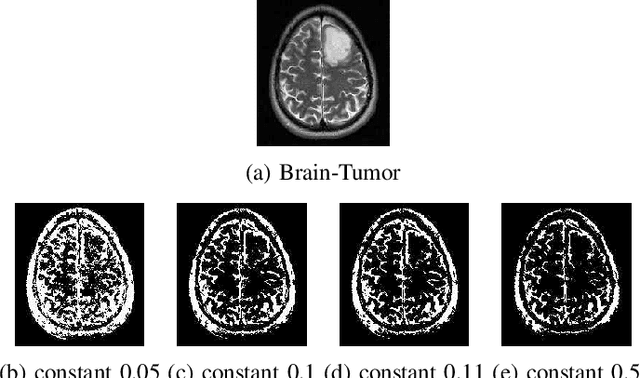
Image segmentation refers to the separation of objects from the background, and has been one of the most challenging aspects of digital image processing. Practically it is impossible to design a segmentation algorithm which has 100% accuracy, and therefore numerous segmentation techniques have been proposed in the literature, each with certain limitations. In this paper, a novel Falling-Ball algorithm is presented, which is a region-based segmentation algorithm, and an alternative to watershed transform (based on waterfall model). The proposed algorithm detects the catchment basins by assuming that a ball falling from hilly terrains will stop in a catchment basin. Once catchment basins are identified, the association of each pixel with one of the catchment basin is obtained using multi-criterion fuzzy logic. Edges are constructed by dividing image into different catchment basins with the help of a membership function. Finally closed contour algorithm is applied to find closed regions and objects within closed regions are segmented using intensity information. The performance of the proposed algorithm is evaluated both objectively as well as subjectively. Simulation results show that the proposed algorithms gives superior performance over conventional Sobel edge detection methods and the watershed segmentation algorithm. For comparative analysis, various comparison methods are used for demonstrating the superiority of proposed methods over existing segmentation methods.
Scalable and Adaptive Graph Neural Networks with Self-Label-Enhanced training
Apr 29, 2021
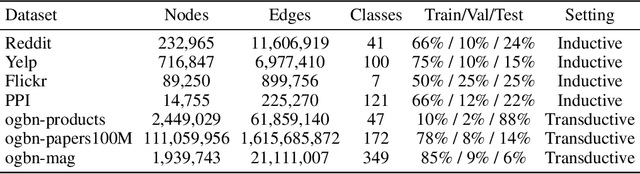
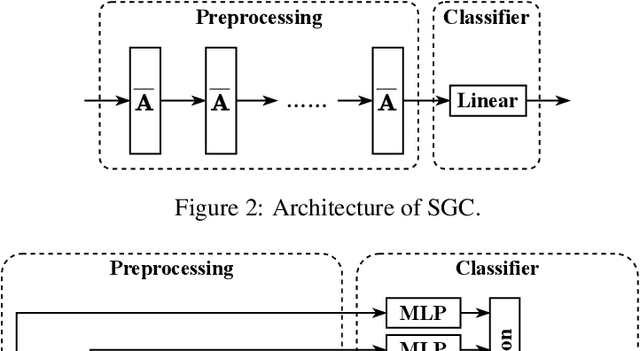
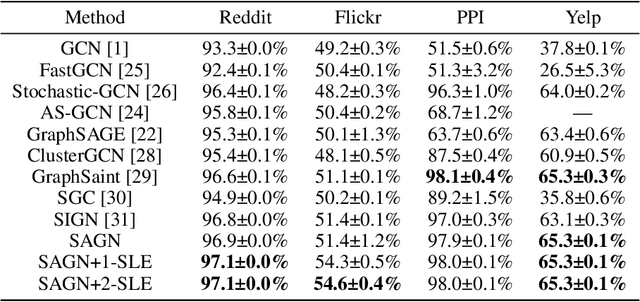
It is hard to directly implement Graph Neural Networks (GNNs) on large scaled graphs. Besides of existed neighbor sampling techniques, scalable methods decoupling graph convolutions and other learnable transformations into preprocessing and post classifier allow normal minibatch training. By replacing redundant concatenation operation with attention mechanism in SIGN, we propose Scalable and Adaptive Graph Neural Networks (SAGN). SAGN can adaptively gather neighborhood information among different hops. To further improve scalable models on semi-supervised learning tasks, we propose Self-Label-Enhance (SLE) framework combining self-training approach and label propagation in depth. We add base model with a scalable node label module. Then we iteratively train models and enhance train set in several stages. To generate input of node label module, we directly apply label propagation based on one-hot encoded label vectors without inner random masking. We find out that empirically the label leakage has been effectively alleviated after graph convolutions. The hard pseudo labels in enhanced train set participate in label propagation with true labels. Experiments on both inductive and transductive datasets demonstrate that, compared with other sampling-based and sampling-free methods, SAGN achieves better or comparable results and SLE can further improve performance.
Inadequacy of Linear Methods for Minimal Sensor Placement and Feature Selection in Nonlinear Systems; a New Approach Using Secants
Jan 27, 2021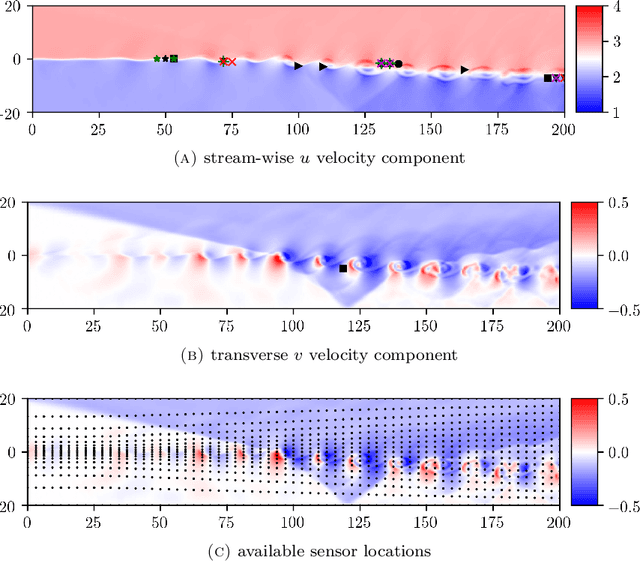

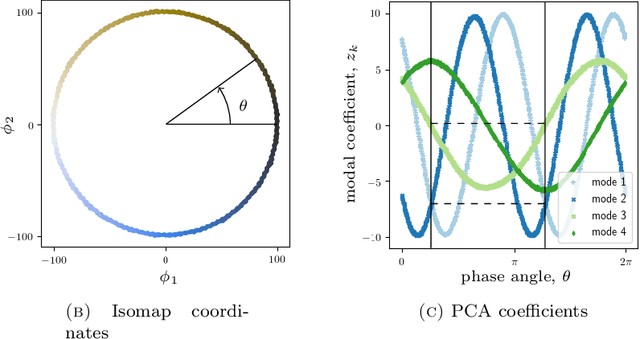
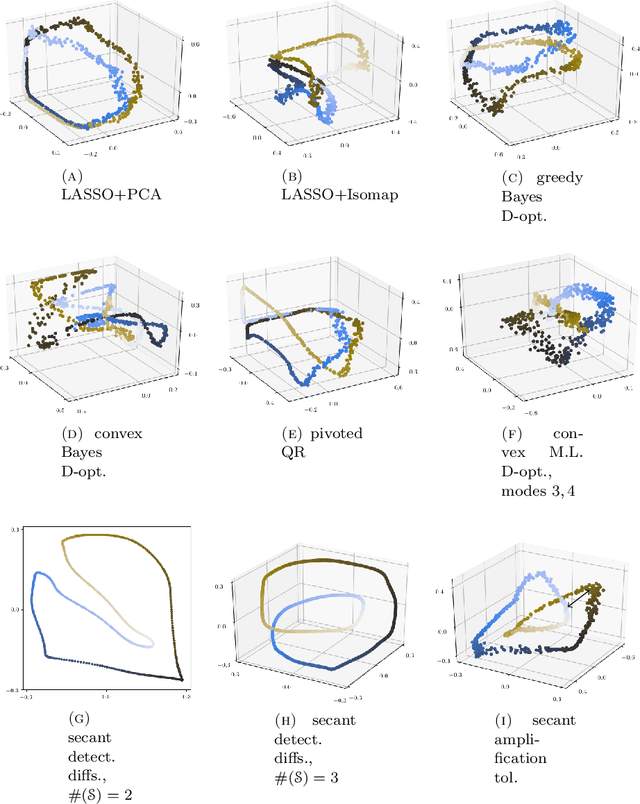
Sensor placement and feature selection are critical steps in engineering, modeling, and data science that share a common mathematical theme: the selected measurements should enable solution of an inverse problem. Most real-world systems of interest are nonlinear, yet the majority of available techniques for feature selection and sensor placement rely on assumptions of linearity or simple statistical models. We show that when these assumptions are violated, standard techniques can lead to costly over-sensing without guaranteeing that the desired information can be recovered from the measurements. In order to remedy these problems, we introduce a novel data-driven approach for sensor placement and feature selection for a general type of nonlinear inverse problem based on the information contained in secant vectors between data points. Using the secant-based approach, we develop three efficient greedy algorithms that each provide different types of robust, near-minimal reconstruction guarantees. We demonstrate them on two problems where linear techniques consistently fail: sensor placement to reconstruct a fluid flow formed by a complicated shock-mixing layer interaction and selecting fundamental manifold learning coordinates on a torus.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation
May 24, 2021

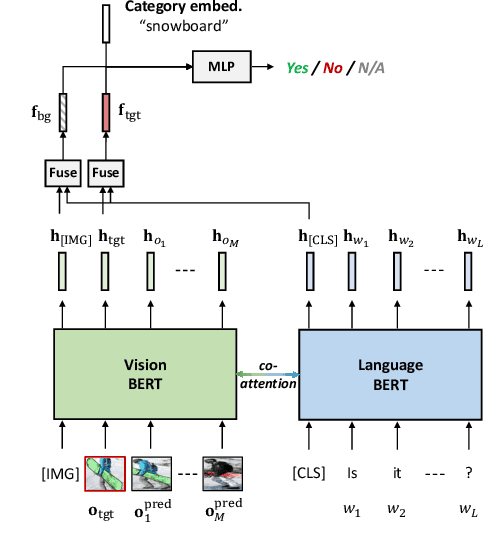
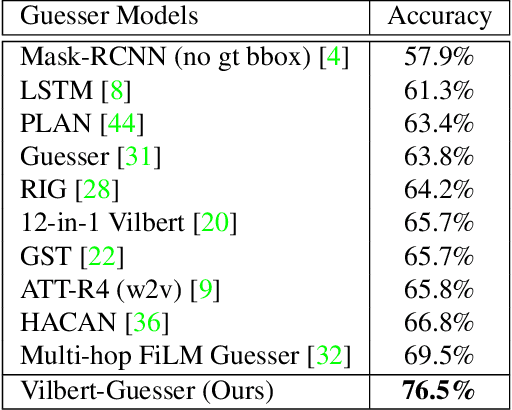
GuessWhat?! is a two-player visual dialog guessing game where player A asks a sequence of yes/no questions (Questioner) and makes a final guess (Guesser) about a target object in an image, based on answers from player B (Oracle). Based on this dialog history between the Questioner and the Oracle, a Guesser makes a final guess of the target object. Previous baseline Oracle model encodes no visual information in the model, and it cannot fully understand complex questions about color, shape, relationships and so on. Most existing work for Guesser encode the dialog history as a whole and train the Guesser models from scratch on the GuessWhat?! dataset. This is problematic since language encoder tend to forget long-term history and the GuessWhat?! data is sparse in terms of learning visual grounding of objects. Previous work for Questioner introduces state tracking mechanism into the model, but it is learned as a soft intermediates without any prior vision-linguistic insights. To bridge these gaps, in this paper we propose Vilbert-based Oracle, Guesser and Questioner, which are all built on top of pretrained vision-linguistic model, Vilbert. We introduce two-way background/target fusion mechanism into Vilbert-Oracle to account for both intra and inter-object questions. We propose a unified framework for Vilbert-Guesser and Vilbert-Questioner, where state-estimator is introduced to best utilize Vilbert's power on single-turn referring expression comprehension. Experimental results show that our proposed models outperform state-of-the-art models significantly by 7%, 10%, 12% for Oracle, Guesser and End-to-End Questioner respectively.