 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 10, 2021
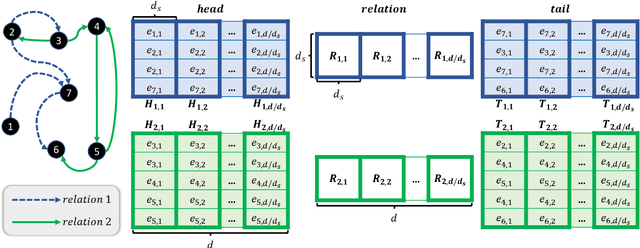
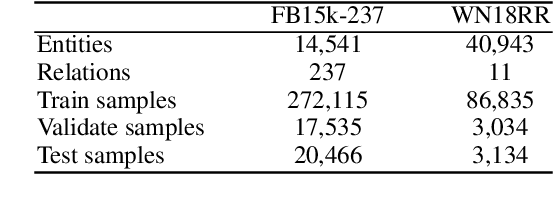
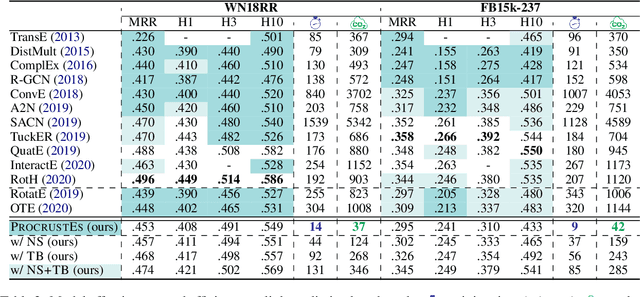
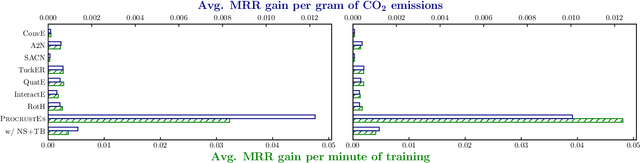
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.
From Quantifying Vagueness To Pan-niftyism
Mar 01, 2021In this short paper, we will introduce a simple model for quantifying philosophical vagueness. There is growing interest in this endeavor to quantify vague concepts of consciousness, agency, etc. We will then discuss some of the implications of this model including the conditions under which the quantification of `nifty' leads to pan-nifty-ism. Understanding this leads to an interesting insight - the reason a framework to quantify consciousness like Integrated Information Theory implies (forms of) panpsychism is because there is favorable structure already implicitly encoded in the construction of the quantification metric.
DSLR: Dynamic to Static LiDAR Scan Reconstruction Using Adversarially Trained Autoencoder
May 26, 2021

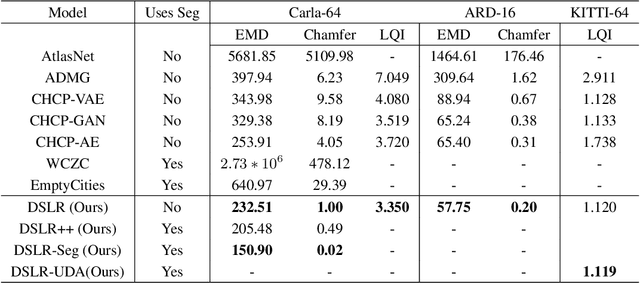
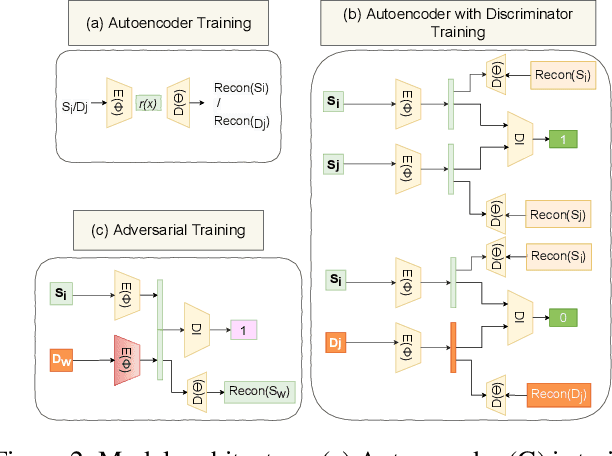
Accurate reconstruction of static environments from LiDAR scans of scenes containing dynamic objects, which we refer to as Dynamic to Static Translation (DST), is an important area of research in Autonomous Navigation. This problem has been recently explored for visual SLAM, but to the best of our knowledge no work has been attempted to address DST for LiDAR scans. The problem is of critical importance due to wide-spread adoption of LiDAR in Autonomous Vehicles. We show that state-of the art methods developed for the visual domain when adapted for LiDAR scans perform poorly. We develop DSLR, a deep generative model which learns a mapping between dynamic scan to its static counterpart through an adversarially trained autoencoder. Our model yields the first solution for DST on LiDAR that generates static scans without using explicit segmentation labels. DSLR cannot always be applied to real world data due to lack of paired dynamic-static scans. Using Unsupervised Domain Adaptation, we propose DSLR-UDA for transfer to real world data and experimentally show that this performs well in real world settings. Additionally, if segmentation information is available, we extend DSLR to DSLR-Seg to further improve the reconstruction quality. DSLR gives the state of the art performance on simulated and real-world datasets and also shows at least 4x improvement. We show that DSLR, unlike the existing baselines, is a practically viable model with its reconstruction quality within the tolerable limits for tasks pertaining to autonomous navigation like SLAM in dynamic environments.
Synthetic Data -- A Privacy Mirage
Dec 11, 2020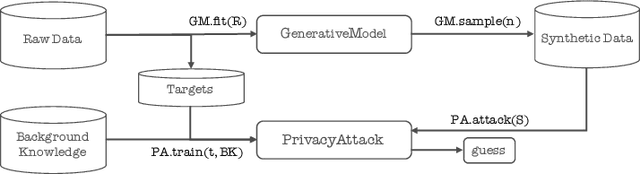
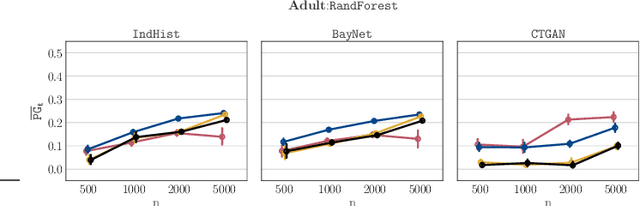
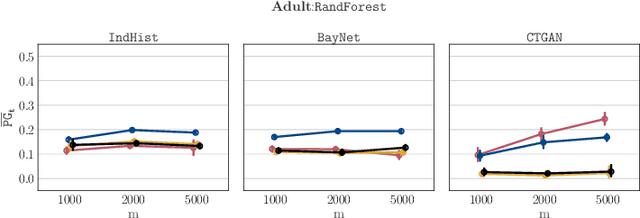
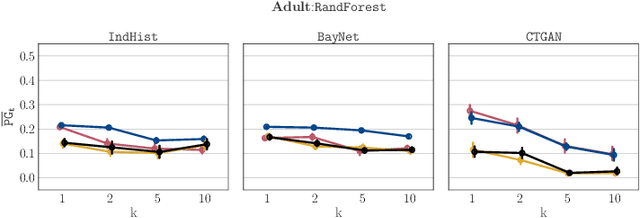
Synthetic datasets drawn from generative models have been advertised as a silver-bullet solution to privacy-preserving data publishing. In this work, we show through an extensive privacy evaluation that such claims do not match reality. First, synthetic data does not prevent attribute inference. Any data characteristics preserved by a generative model for the purpose of data analysis, can simultaneously be used by an adversary to reconstruct sensitive information about individuals. Second, synthetic data does not protect against linkage attacks. We demonstrate that high-dimensional synthetic datasets preserve much more information about the raw data than the features in the model's lower-dimensional approximation. This rich information can be exploited by an adversary even when models are trained under differential privacy. Moreover, we observe that some target records receive substantially less protection than others and that the more complex the generative model, the more difficult it is to predict which targets will remain vulnerable to inference attacks. Finally, we show why generative models are unlikely to ever become an appropriate solution to the problem of privacy-preserving data publishing.
Spatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving
May 26, 2021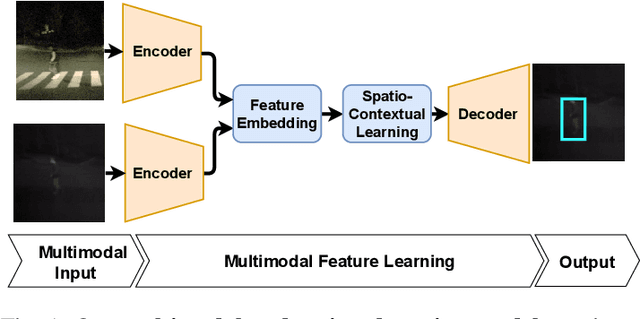
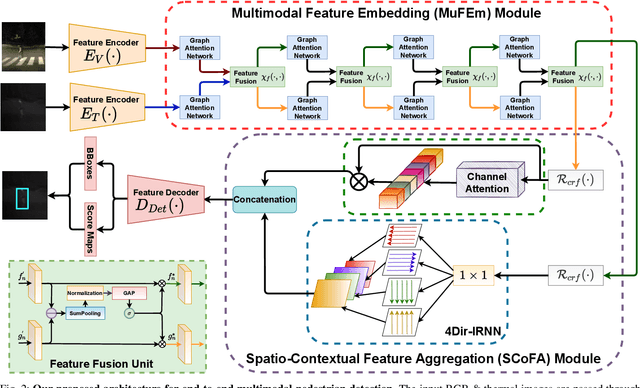


Pedestrian Detection is the most critical module of an Autonomous Driving system. Although a camera is commonly used for this purpose, its quality degrades severely in low-light night time driving scenarios. On the other hand, the quality of a thermal camera image remains unaffected in similar conditions. This paper proposes an end-to-end multimodal fusion model for pedestrian detection using RGB and thermal images. Its novel spatio-contextual deep network architecture is capable of exploiting the multimodal input efficiently. It consists of two distinct deformable ResNeXt-50 encoders for feature extraction from the two modalities. Fusion of these two encoded features takes place inside a multimodal feature embedding module (MuFEm) consisting of several groups of a pair of Graph Attention Network and a feature fusion unit. The output of the last feature fusion unit of MuFEm is subsequently passed to two CRFs for their spatial refinement. Further enhancement of the features is achieved by applying channel-wise attention and extraction of contextual information with the help of four RNNs traversing in four different directions. Finally, these feature maps are used by a single-stage decoder to generate the bounding box of each pedestrian and the score map. We have performed extensive experiments of the proposed framework on three publicly available multimodal pedestrian detection benchmark datasets, namely KAIST, CVC-14, and UTokyo. The results on each of them improved the respective state-of-the-art performance. A short video giving an overview of this work along with its qualitative results can be seen at https://youtu.be/FDJdSifuuCs.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021
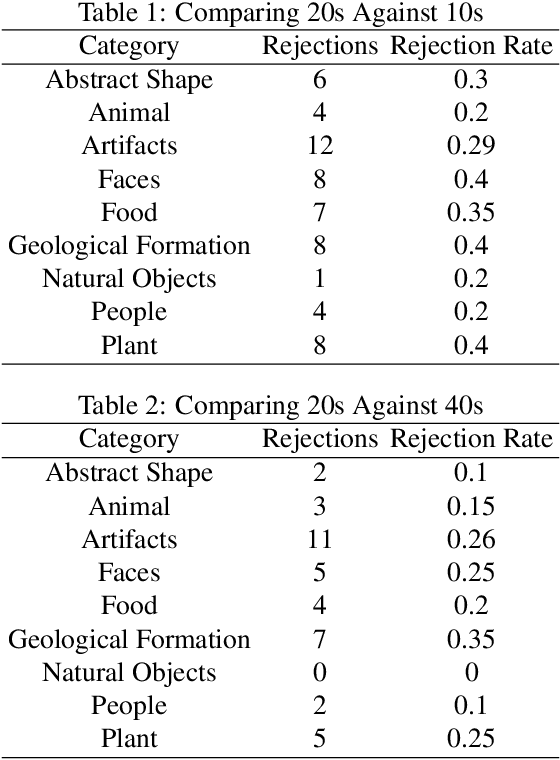


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.
Classification Uncertainty of Deep Neural Networks Based on Gradient Information
Jul 26, 2018
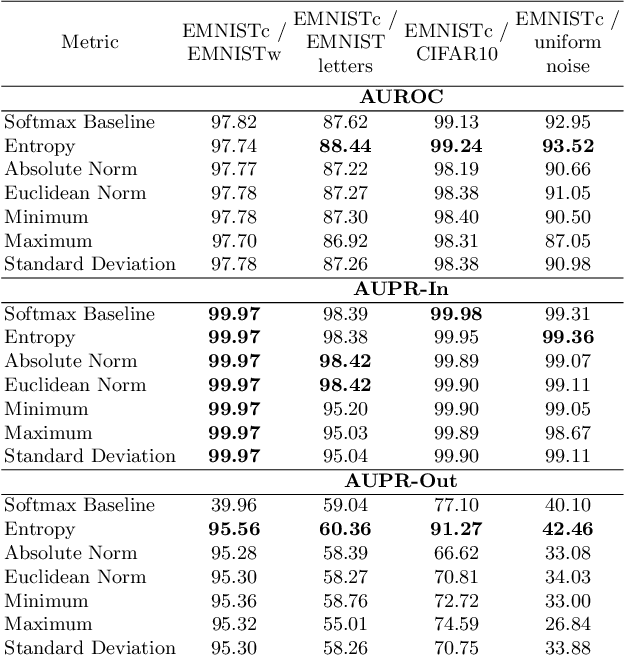

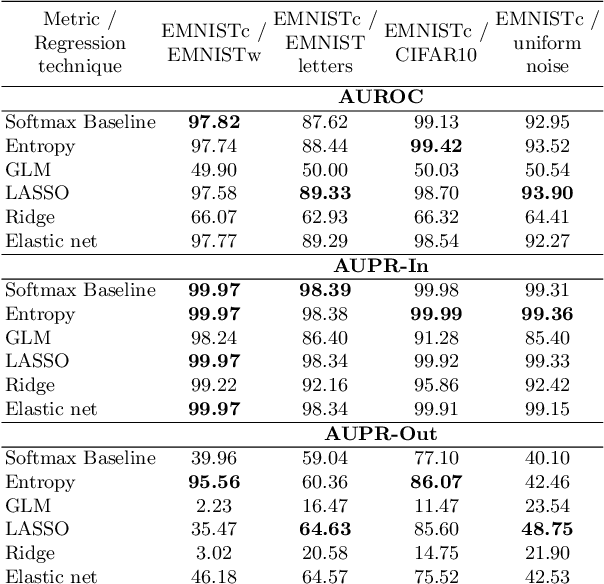
We study the quantification of uncertainty of Convolutional Neural Networks (CNNs) based on gradient metrics. Unlike the classical softmax entropy, such metrics gather information from all layers of the CNN. We show for the EMNIST digits data set that for several such metrics we achieve the same meta classification accuracy -- i.e. the task of classifying predictions as correct or incorrect without knowing the actual label -- as for entropy thresholding. We apply meta classification to unknown concepts (out-of-distribution samples) -- EMNIST/Omniglot letters, CIFAR10 and noise -- and demonstrate that meta classification rates for unknown concepts can be increased when using entropy together with several gradient based metrics as input quantities for a meta classifier. Meta classifiers only trained on the uncertainty metrics of known concepts, i.e. EMNIST digits, usually do not perform equally well for all unknown concepts. If we however allow the meta classifier to be trained on uncertainty metrics for some out-of-distribution samples, meta classification for concepts remote from EMNIST digits (then termed known unknowns) can be improved considerably.
Persistence Homology of TEDtalk: Do Sentence Embeddings Have a Topological Shape?
Mar 25, 2021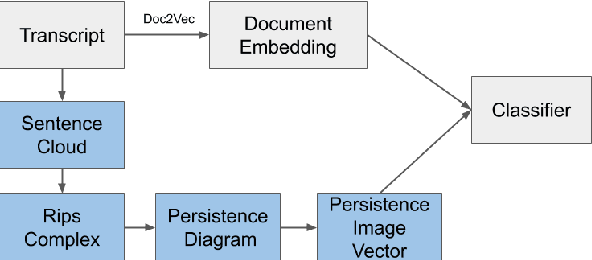
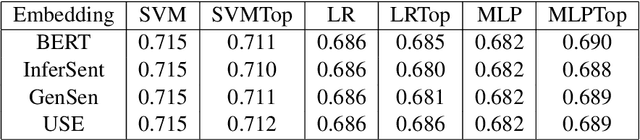
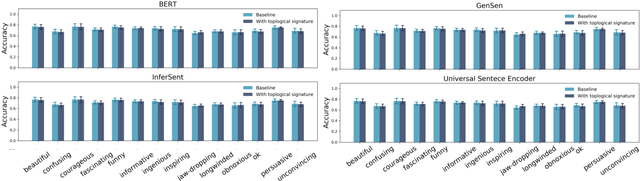
\emph{Topological data analysis} (TDA) has recently emerged as a new technique to extract meaningful discriminitve features from high dimensional data. In this paper, we investigate the possibility of applying TDA to improve the classification accuracy of public speaking rating. We calculated \emph{persistence image vectors} for the sentence embeddings of TEDtalk data and feed this vectors as additional inputs to our machine learning models. We have found a negative result that this topological information does not improve the model accuracy significantly. In some cases, it makes the accuracy slightly worse than the original one. From our results, we could not conclude that the topological shapes of the sentence embeddings can help us train a better model for public speaking rating.
GistNet: a Geometric Structure Transfer Network for Long-Tailed Recognition
May 01, 2021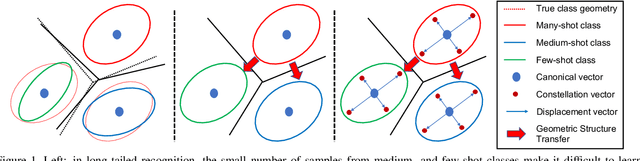
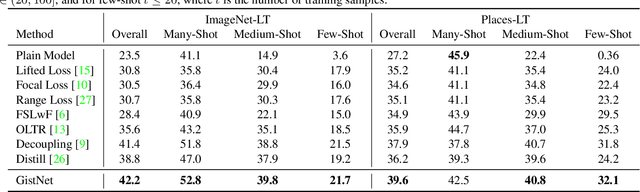
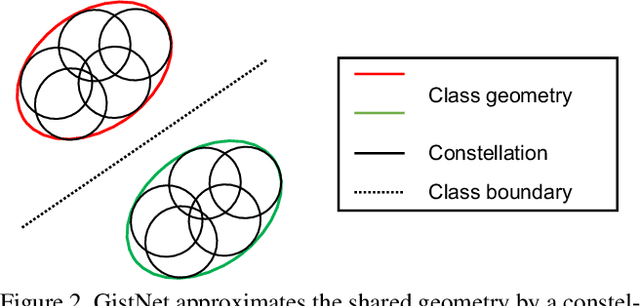

The problem of long-tailed recognition, where the number of examples per class is highly unbalanced, is considered. It is hypothesized that the well known tendency of standard classifier training to overfit to popular classes can be exploited for effective transfer learning. Rather than eliminating this overfitting, e.g. by adopting popular class-balanced sampling methods, the learning algorithm should instead leverage this overfitting to transfer geometric information from popular to low-shot classes. A new classifier architecture, GistNet, is proposed to support this goal, using constellations of classifier parameters to encode the class geometry. A new learning algorithm is then proposed for GeometrIc Structure Transfer (GIST), with resort to a combination of loss functions that combine class-balanced and random sampling to guarantee that, while overfitting to the popular classes is restricted to geometric parameters, it is leveraged to transfer class geometry from popular to few-shot classes. This enables better generalization for few-shot classes without the need for the manual specification of class weights, or even the explicit grouping of classes into different types. Experiments on two popular long-tailed recognition datasets show that GistNet outperforms existing solutions to this problem.
Knowledge-driven Answer Generation for Conversational Search
Apr 14, 2021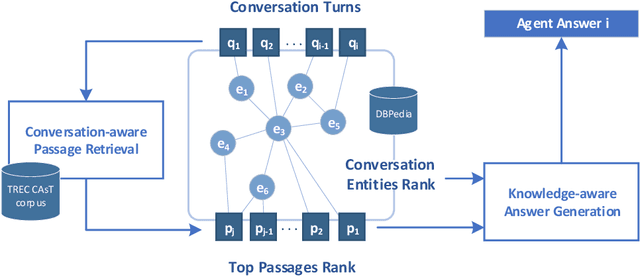
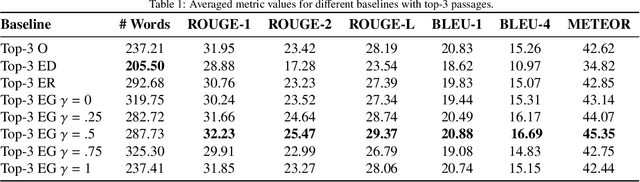
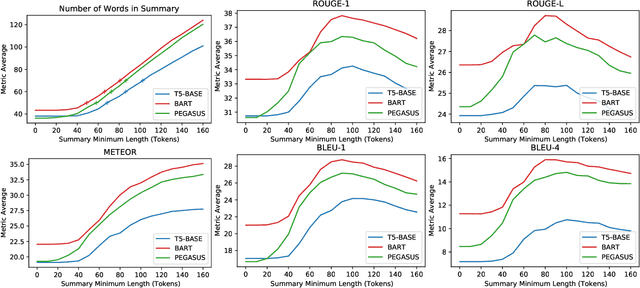

The conversational search paradigm introduces a step change over the traditional search paradigm by allowing users to interact with search agents in a multi-turn and natural fashion. The conversation flows naturally and is usually centered around a target field of knowledge. In this work, we propose a knowledge-driven answer generation approach for open-domain conversational search, where a conversation-wide entities' knowledge graph is used to bias search-answer generation. First, a conversation-specific knowledge graph is extracted from the top passages retrieved with a Transformer-based re-ranker. The entities knowledge-graph is then used to bias a search-answer generator Transformer towards information rich and concise answers. This conversation specific bias is computed by identifying the most relevant passages according to the most salient entities of that particular conversation. Experiments show that the proposed approach successfully exploits entities knowledge along the conversation, and outperforms a set of baselines on the search-answer generation task.