 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning from pandemics: using extraordinary events can improve disease now-casting models
Jan 17, 2021
Online searches have been used to study different health-related behaviours, including monitoring disease outbreaks. An obvious caveat is that several reasons can motivate individuals to seek online information and models that are blind to people's motivations are of limited use and can even mislead. This is particularly true during extraordinary public health crisis, such as the ongoing pandemic, when fear, curiosity and many other reasons can lead individuals to search for health-related information, masking the disease-driven searches. However, health crisis can also offer an opportunity to disentangle between different drivers and learn about human behavior. Here, we focus on the two pandemics of the 21st century (2009-H1N1 flu and Covid-19) and propose a methodology to discriminate between search patterns linked to general information seeking (media driven) and search patterns possibly more associated with actual infection (disease driven). We show that by learning from such pandemic periods, with high anxiety and media hype, it is possible to select online searches and improve model performance both in pandemic and seasonal settings. Moreover, and despite the common claim that more data is always better, our results indicate that lower volume of the right data can be better than including large volumes of apparently similar data, especially in the long run. Our work provides a general framework that can be applied beyond specific events and diseases, and argues that algorithms can be improved simply by using less (better) data. This has important consequences, for example, to solve the accuracy-explainability trade-off in machine-learning.
HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection
Apr 01, 2021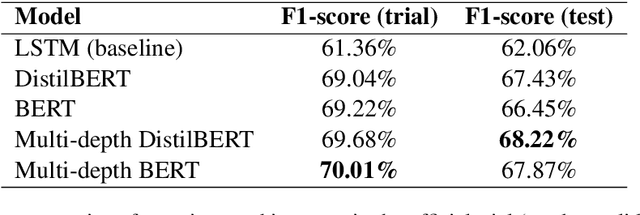
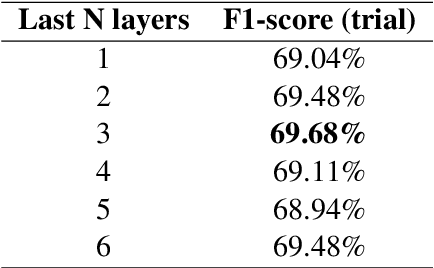

This paper presents our submission to SemEval-2021 Task 5: Toxic Spans Detection. The purpose of this task is to detect the spans that make a text toxic, which is a complex labour for several reasons. Firstly, because of the intrinsic subjectivity of toxicity, and secondly, due to toxicity not always coming from single words like insults or offends, but sometimes from whole expressions formed by words that may not be toxic individually. Following this idea of focusing on both single words and multi-word expressions, we study the impact of using a multi-depth DistilBERT model, which uses embeddings from different layers to estimate the final per-token toxicity. Our quantitative results show that using information from multiple depths boosts the performance of the model. Finally, we also analyze our best model qualitatively.
Residual Enhanced Multi-Hypergraph Neural Network
May 02, 2021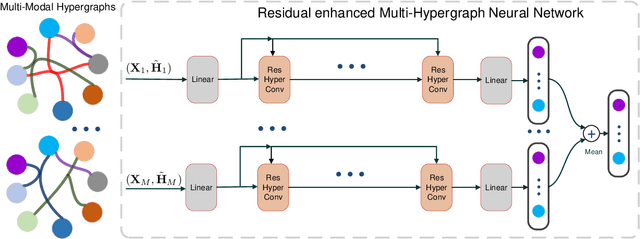

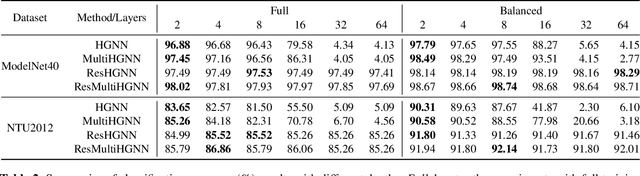
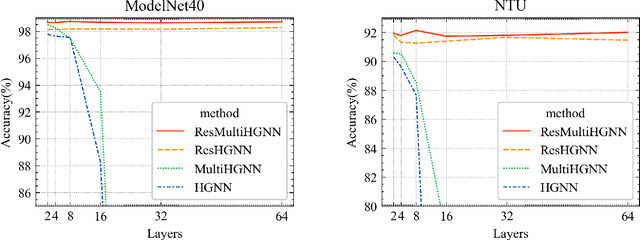
Hypergraphs are a generalized data structure of graphs to model higher-order correlations among entities, which have been successfully adopted into various research domains. Meanwhile, HyperGraph Neural Network (HGNN) is currently the de-facto method for hypergraph representation learning. However, HGNN aims at single hypergraph learning and uses a pre-concatenation approach when confronting multi-modal datasets, which leads to sub-optimal exploitation of the inter-correlations of multi-modal hypergraphs. HGNN also suffers the over-smoothing issue, that is, its performance drops significantly when layers are stacked up. To resolve these issues, we propose the Residual enhanced Multi-Hypergraph Neural Network, which can not only fuse multi-modal information from each hypergraph effectively, but also circumvent the over-smoothing issue associated with HGNN. We conduct experiments on two 3D benchmarks, the NTU and the ModelNet40 datasets, and compare against multiple state-of-the-art methods. Experimental results demonstrate that both the residual hypergraph convolutions and the multi-fusion architecture can improve the performance of the base model and the combined model achieves a new state-of-the-art. Code is available at \url{https://github.com/OneForward/ResMHGNN}.
Deep Kernel Supervised Hashing for Node Classification in Structural Networks
Oct 26, 2020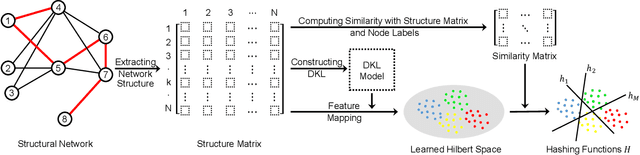

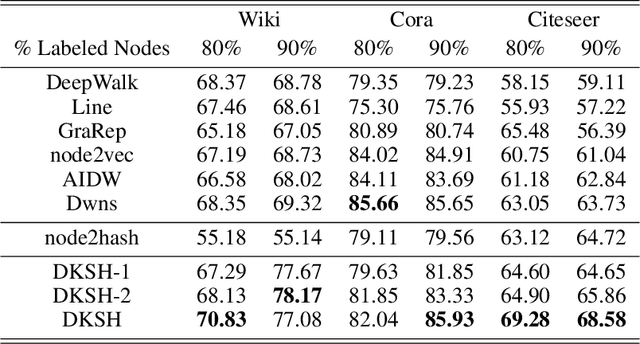
Node classification in structural networks has been proven to be useful in many real world applications. With the development of network embedding, the performance of node classification has been greatly improved. However, nearly all the existing network embedding based methods are hard to capture the actual category features of a node because of the linearly inseparable problem in low-dimensional space; meanwhile they cannot incorporate simultaneously network structure information and node label information into network embedding. To address the above problems, in this paper, we propose a novel Deep Kernel Supervised Hashing (DKSH) method to learn the hashing representations of nodes for node classification. Specifically, a deep multiple kernel learning is first proposed to map nodes into suitable Hilbert space to deal with linearly inseparable problem. Then, instead of only considering structural similarity between two nodes, a novel similarity matrix is designed to merge both network structure information and node label information. Supervised by the similarity matrix, the learned hashing representations of nodes simultaneously preserve the two kinds of information well from the learned Hilbert space. Extensive experiments show that the proposed method significantly outperforms the state-of-the-art baselines over three real world benchmark datasets.
Adaptive Sampling: Algorithmic vs. Human Waypoint Selection
Apr 24, 2021
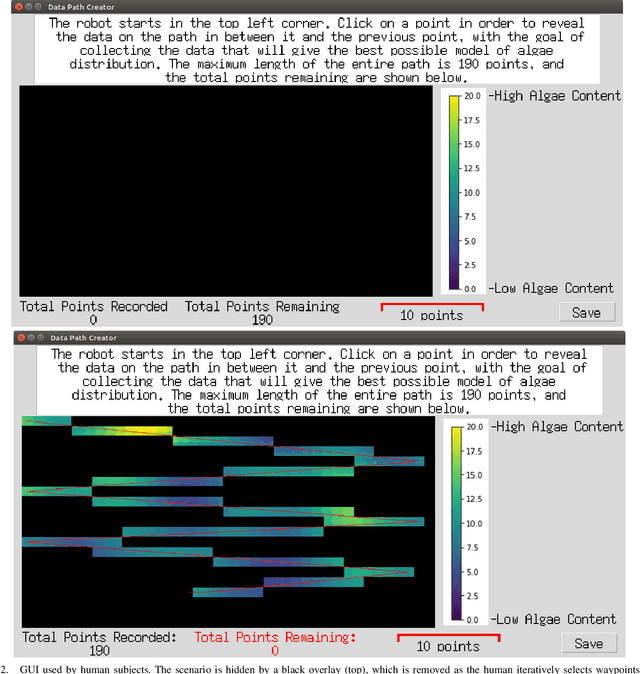
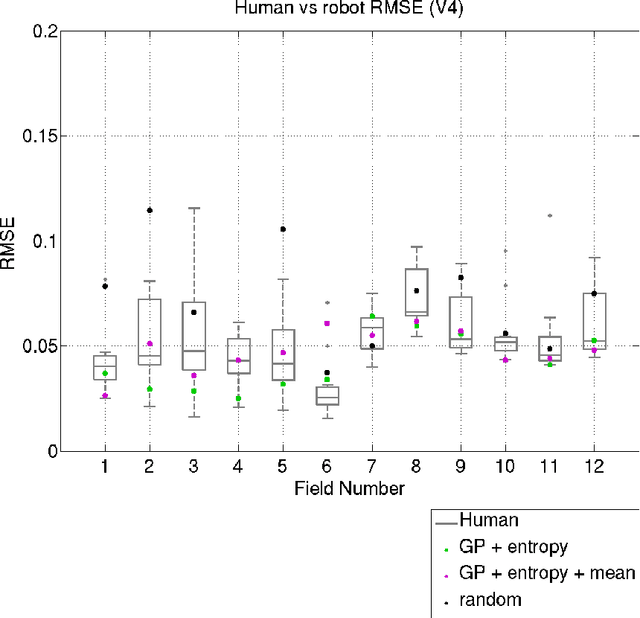
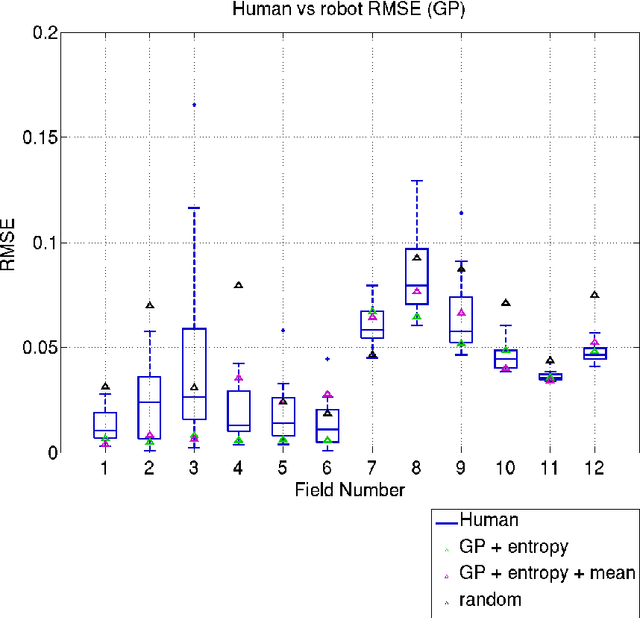
Robots are used for collecting samples from natural environments to create models of, for example, temperature or algae fields in the ocean. Adaptive informative sampling is a proven technique for this kind of spatial field modeling. This paper compares the performance of humans versus adaptive informative sampling algorithms for selecting informative waypoints. The humans and simulated robot are given the same information for selecting waypoints, and both are evaluated on the accuracy of the resulting model. We developed a graphical user interface for selecting waypoints and visualizing samples. Eleven participants iteratively picked waypoints for twelve scenarios. Our simulated robot used Gaussian Process regression with two entropy-based optimization criteria to iteratively choose waypoints. Our results show that the robot can on average perform better than the average human, and approximately as good as the best human, when the model assumptions correspond to the actual field. However, when the model assumptions do not correspond as well to the characteristics of the field, both human and robot performance are no better than random sampling.
Phase Transitions in Transfer Learning for High-Dimensional Perceptrons
Jan 06, 2021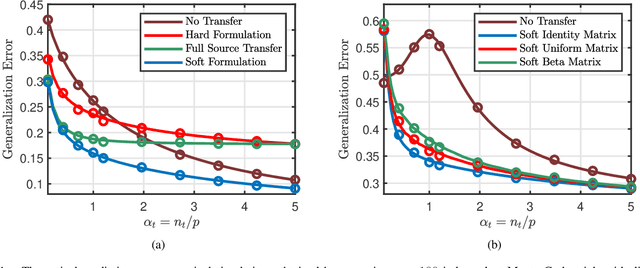
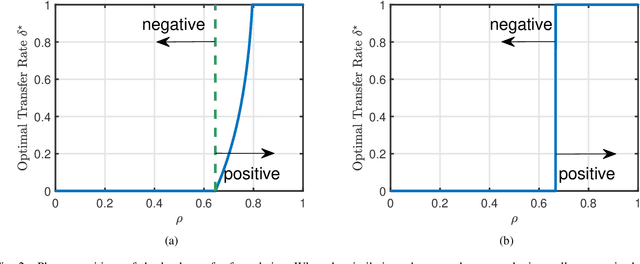
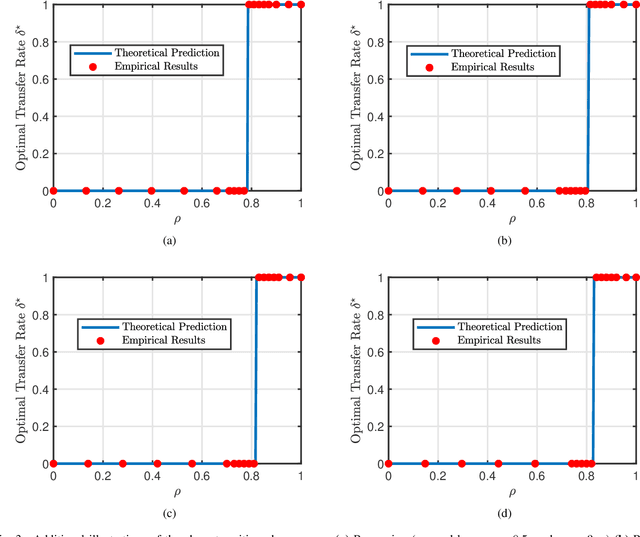

Transfer learning seeks to improve the generalization performance of a target task by exploiting the knowledge learned from a related source task. Central questions include deciding what information one should transfer and when transfer can be beneficial. The latter question is related to the so-called negative transfer phenomenon, where the transferred source information actually reduces the generalization performance of the target task. This happens when the two tasks are sufficiently dissimilar. In this paper, we present a theoretical analysis of transfer learning by studying a pair of related perceptron learning tasks. Despite the simplicity of our model, it reproduces several key phenomena observed in practice. Specifically, our asymptotic analysis reveals a phase transition from negative transfer to positive transfer as the similarity of the two tasks moves past a well-defined threshold.
Efficient human-like semantic representations via the Information Bottleneck principle
Aug 09, 2018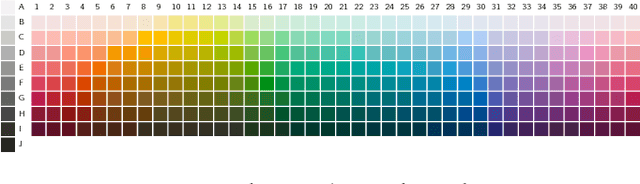

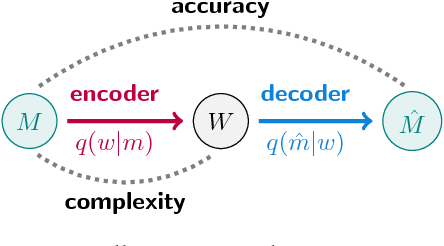
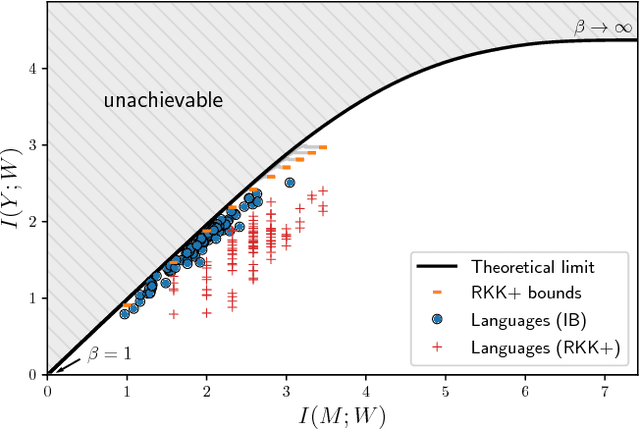
Maintaining efficient semantic representations of the environment is a major challenge both for humans and for machines. While human languages represent useful solutions to this problem, it is not yet clear what computational principle could give rise to similar solutions in machines. In this work we propose an answer to this open question. We suggest that languages compress percepts into words by optimizing the Information Bottleneck (IB) tradeoff between the complexity and accuracy of their lexicons. We present empirical evidence that this principle may give rise to human-like semantic representations, by exploring how human languages categorize colors. We show that color naming systems across languages are near-optimal in the IB sense, and that these natural systems are similar to artificial IB color naming systems with a single tradeoff parameter controlling the cross-language variability. In addition, the IB systems evolve through a sequence of structural phase transitions, demonstrating a possible adaptation process. This work thus identifies a computational principle that characterizes human semantic systems, and that could usefully inform semantic representations in machines.
Training Stacked Denoising Autoencoders for Representation Learning
Feb 16, 2021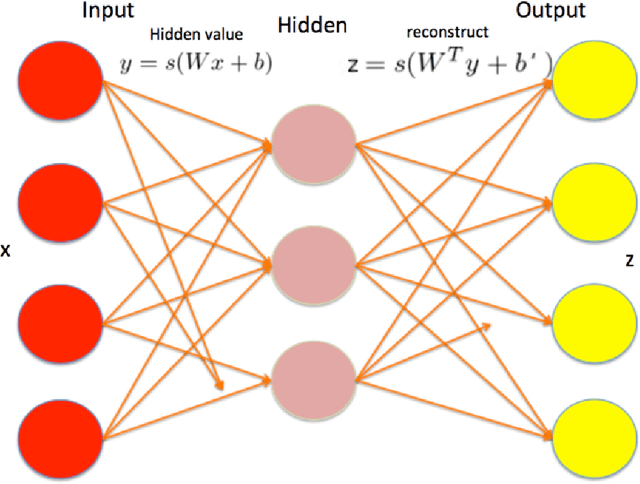
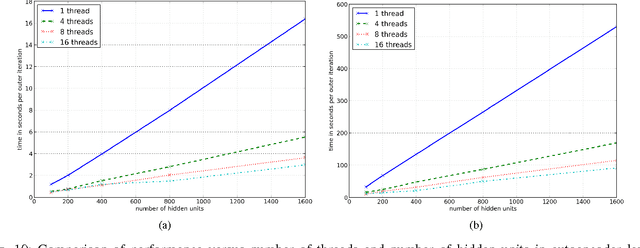
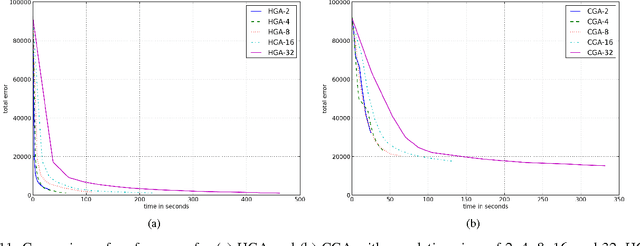
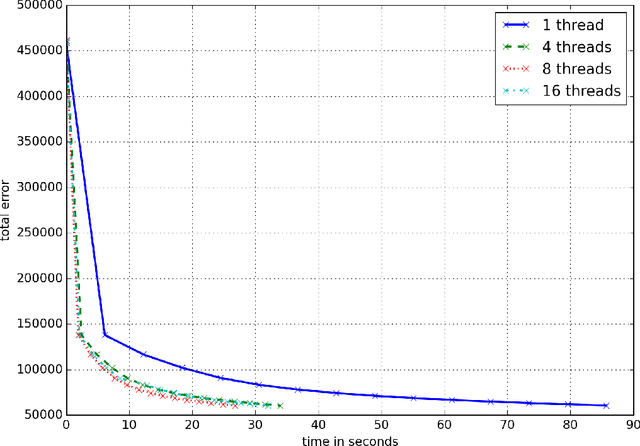
We implement stacked denoising autoencoders, a class of neural networks that are capable of learning powerful representations of high dimensional data. We describe stochastic gradient descent for unsupervised training of autoencoders, as well as a novel genetic algorithm based approach that makes use of gradient information. We analyze the performance of both optimization algorithms and also the representation learning ability of the autoencoder when it is trained on standard image classification datasets.
TE-ESN: Time Encoding Echo State Network for Prediction Based on Irregularly Sampled Time Series Data
May 02, 2021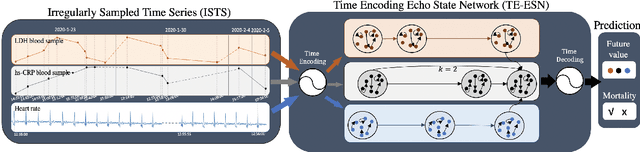

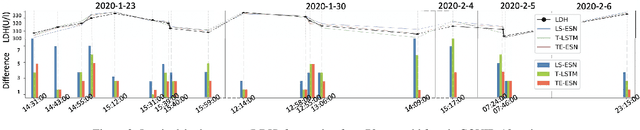
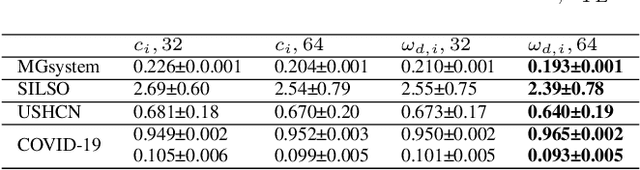
Prediction based on Irregularly Sampled Time Series (ISTS) is of wide concern in the real-world applications. For more accurate prediction, the methods had better grasp more data characteristics. Different from ordinary time series, ISTS is characterised with irregular time intervals of intra-series and different sampling rates of inter-series. However, existing methods have suboptimal predictions due to artificially introducing new dependencies in a time series and biasedly learning relations among time series when modeling these two characteristics. In this work, we propose a novel Time Encoding (TE) mechanism. TE can embed the time information as time vectors in the complex domain. It has the the properties of absolute distance and relative distance under different sampling rates, which helps to represent both two irregularities of ISTS. Meanwhile, we create a new model structure named Time Encoding Echo State Network (TE-ESN). It is the first ESNs-based model that can process ISTS data. Besides, TE-ESN can incorporate long short-term memories and series fusion to grasp horizontal and vertical relations. Experiments on one chaos system and three real-world datasets show that TE-ESN performs better than all baselines and has better reservoir property.
ADePT: Auto-encoder based Differentially Private Text Transformation
Jan 29, 2021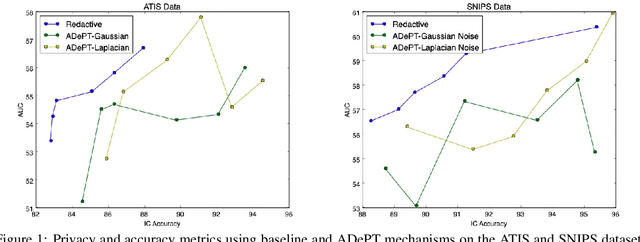

Privacy is an important concern when building statistical models on data containing personal information. Differential privacy offers a strong definition of privacy and can be used to solve several privacy concerns (Dwork et al., 2014). Multiple solutions have been proposed for the differentially-private transformation of datasets containing sensitive information. However, such transformation algorithms offer poor utility in Natural Language Processing (NLP) tasks due to noise added in the process. In this paper, we address this issue by providing a utility-preserving differentially private text transformation algorithm using auto-encoders. Our algorithm transforms text to offer robustness against attacks and produces transformations with high semantic quality that perform well on downstream NLP tasks. We prove the theoretical privacy guarantee of our algorithm and assess its privacy leakage under Membership Inference Attacks(MIA) (Shokri et al., 2017) on models trained with transformed data. Our results show that the proposed model performs better against MIA attacks while offering lower to no degradation in the utility of the underlying transformation process compared to existing baselines.