 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx
Apr 12, 2021
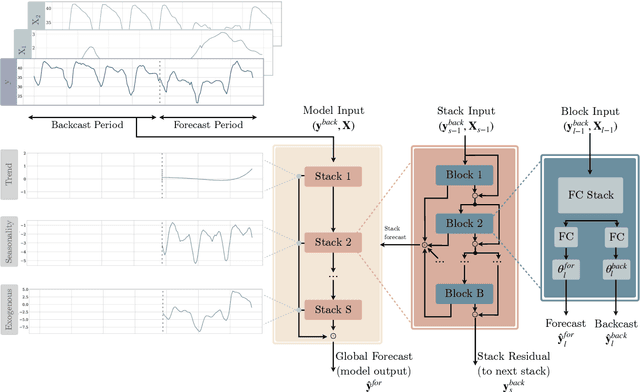

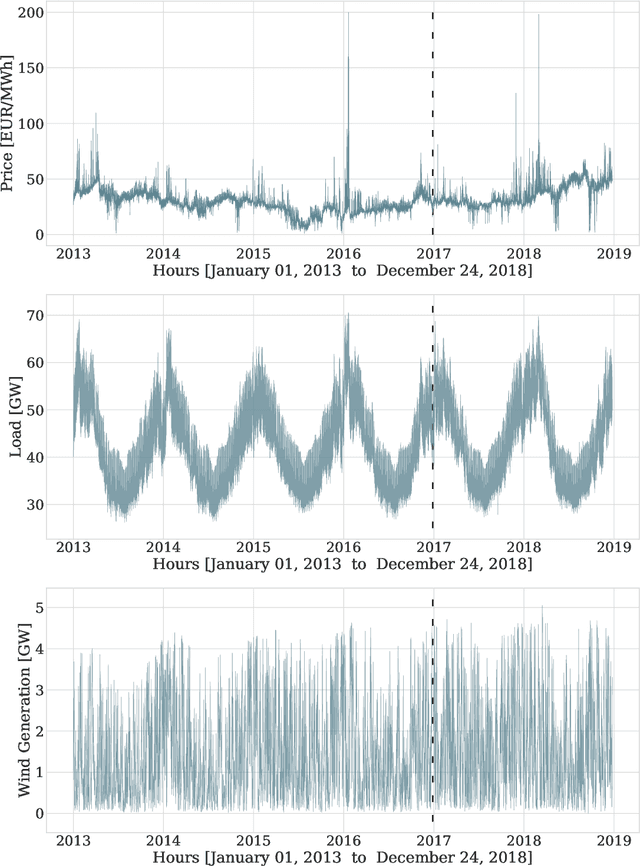

We extend the \emph{neural basis expansion analysis} (NBEATS) to incorporate exogenous factors. The resulting method, called NBEATSx, improves on a well performing deep learning model, extending its capabilities by including exogenous variables and allowing it to integrate multiple sources of useful information. To showcase the utility of the NBEATSx model, we conduct a comprehensive study of its application to electricity price forecasting (EPF) tasks across a broad range of years and markets. We observe state-of-the-art performance, significantly improving the forecast accuracy by nearly 20\% over the original NBEATS model, and by up to 5\% over other well established statistical and machine learning methods specialized for these tasks. Additionally, the proposed neural network has an interpretable configuration that can structurally decompose time series, visualizing the relative impact of trend and seasonal components and revealing the modeled processes' interactions with exogenous factors.
An Improved Attention for Visual Question Answering
Nov 04, 2020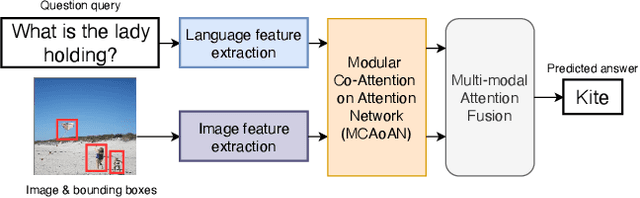
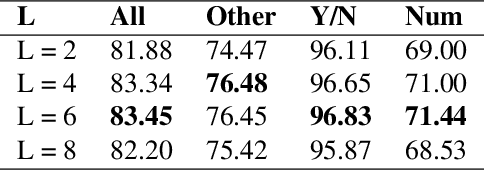
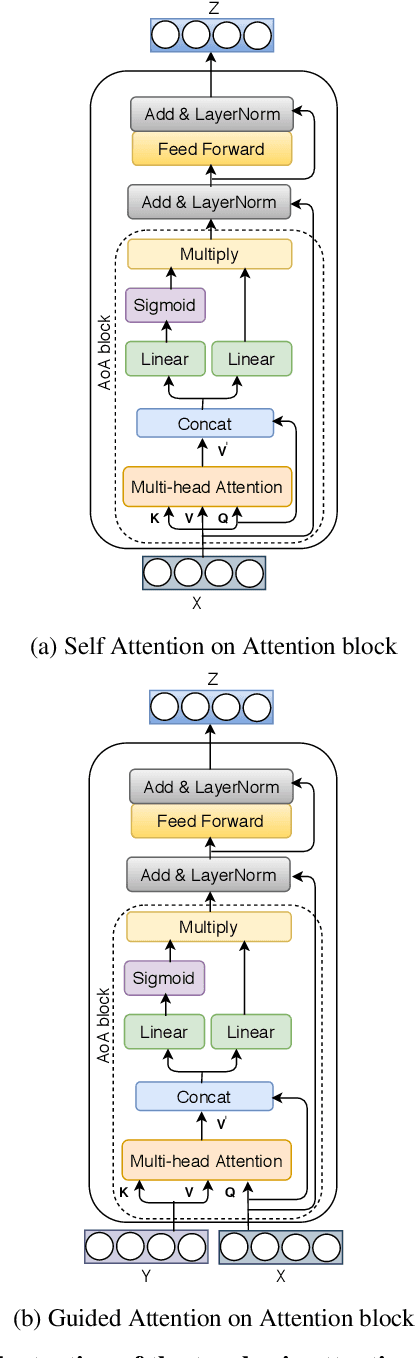

We consider the problem of Visual Question Answering (VQA). Given an image and a free-form, open-ended, question, expressed in natural language, the goal of VQA system is to provide accurate answer to this question with respect to the image. The task is challenging because it requires simultaneous and intricate understanding of both visual and textual information. Attention, which captures intra- and inter-modal dependencies, has emerged as perhaps the most widely used mechanism for addressing these challenges. In this paper, we propose an improved attention-based architecture to solve VQA. We incorporate an Attention on Attention (AoA) module within encoder-decoder framework, which is able to determine the relation between attention results and queries. Attention module generates weighted average for each query. On the other hand, AoA module first generates an information vector and an attention gate using attention results and current context; and then adds another attention to generate final attended information by multiplying the two. We also propose multimodal fusion module to combine both visual and textual information. The goal of this fusion module is to dynamically decide how much information should be considered from each modality. Extensive experiments on VQA-v2 benchmark dataset show that our method achieves the state-of-the-art performance.
Hypergraph Pre-training with Graph Neural Networks
May 23, 2021

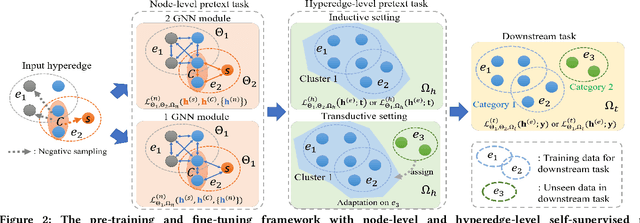
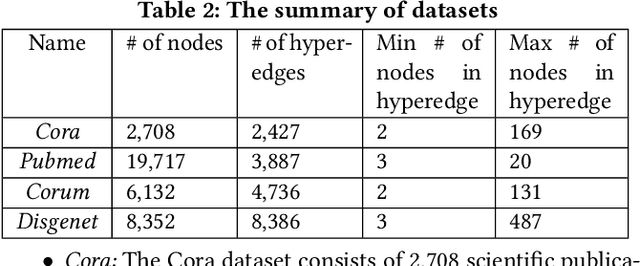
Despite the prevalence of hypergraphs in a variety of high-impact applications, there are relatively few works on hypergraph representation learning, most of which primarily focus on hyperlink prediction, often restricted to the transductive learning setting. Among others, a major hurdle for effective hypergraph representation learning lies in the label scarcity of nodes and/or hyperedges. To address this issue, this paper presents an end-to-end, bi-level pre-training strategy with Graph Neural Networks for hypergraphs. The proposed framework named HyperGene bears three distinctive advantages. First, it is capable of ingesting the labeling information when available, but more importantly, it is mainly designed in the self-supervised fashion which significantly broadens its applicability. Second, at the heart of the proposed HyperGene are two carefully designed pretexts, one on the node level and the other on the hyperedge level, which enable us to encode both the local and the global context in a mutually complementary way. Third, the proposed framework can work in both transductive and inductive settings. When applying the two proposed pretexts in tandem, it can accelerate the adaptation of the knowledge from the pre-trained model to downstream applications in the transductive setting, thanks to the bi-level nature of the proposed method. The extensive experimental results demonstrate that: (1) HyperGene achieves up to 5.69% improvements in hyperedge classification, and (2) improves pre-training efficiency by up to 42.80% on average.
Comparison of remote experiments using crowdsourcing and laboratory experiments on speech intelligibility
Apr 17, 2021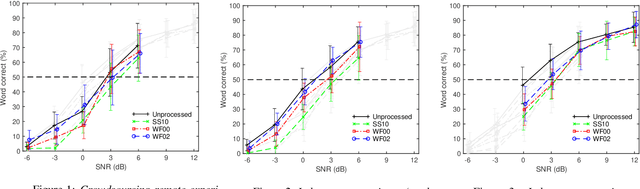
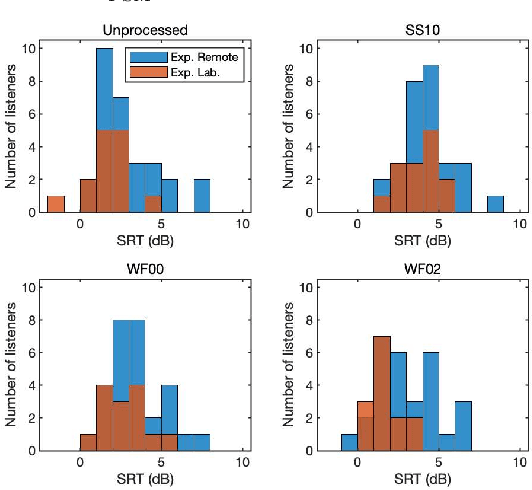
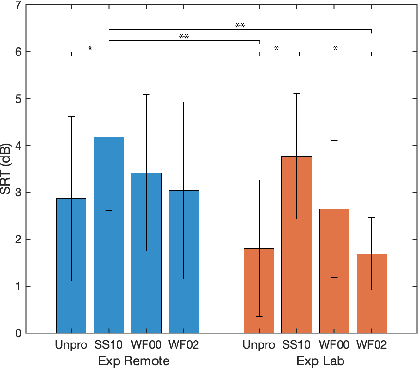
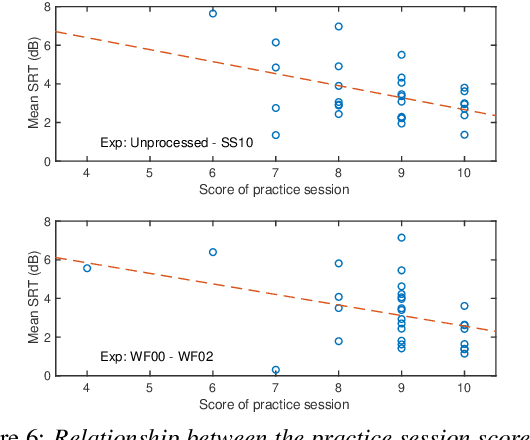
Many subjective experiments have been performed to develop objective speech intelligibility measures, but the novel coronavirus outbreak has made it very difficult to conduct experiments in a laboratory. One solution is to perform remote testing using crowdsourcing; however, because we cannot control the listening conditions, it is unclear whether the results are entirely reliable. In this study, we compared speech intelligibility scores obtained in remote and laboratory experiments. The results showed that the mean and standard deviation (SD) of the remote experiments' speech reception threshold (SRT) were higher than those of the laboratory experiments. However, the variance in the SRTs across the speech-enhancement conditions revealed similarities, implying that remote testing results may be as useful as laboratory experiments to develop an objective measure. We also show that the practice session scores correlate with the SRT values. This is a priori information before performing the main tests and would be useful for data screening to reduce the variability of the SRT distribution.
An Ensemble Classification Algorithm Based on Information Entropy for Data Streams
Aug 11, 2017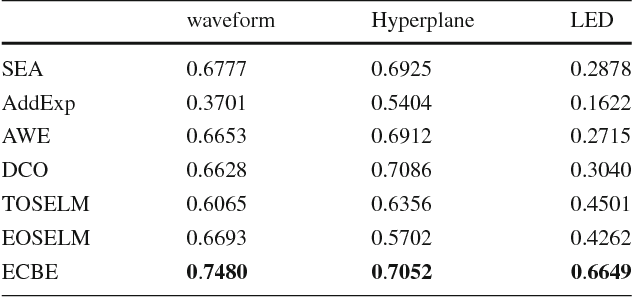
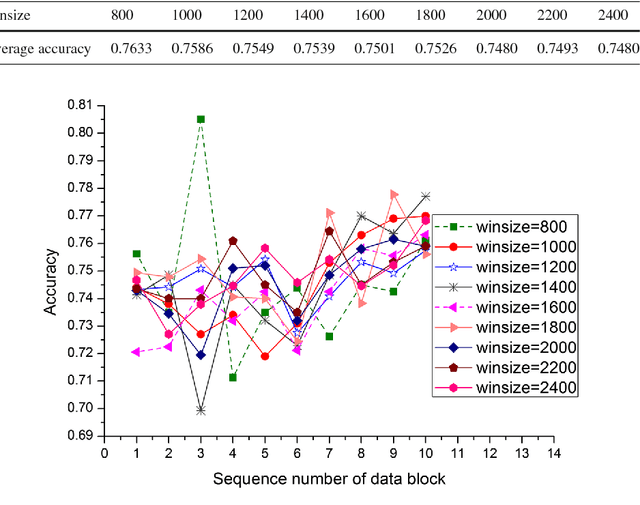
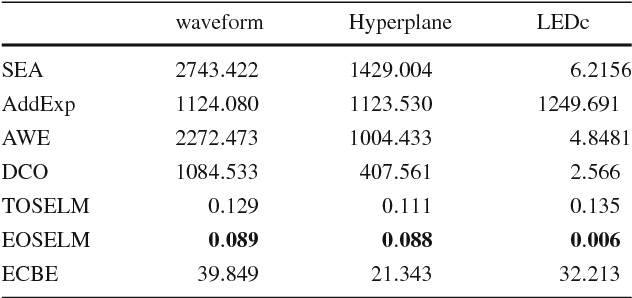
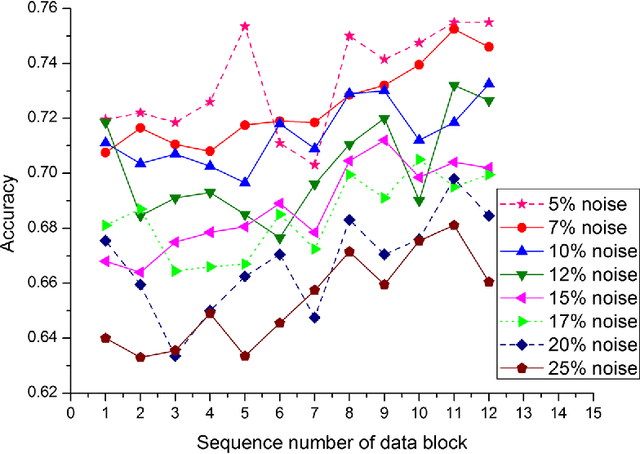
Data stream mining problem has caused widely concerns in the area of machine learning and data mining. In some recent studies, ensemble classification has been widely used in concept drift detection, however, most of them regard classification accuracy as a criterion for judging whether concept drift happening or not. Information entropy is an important and effective method for measuring uncertainty. Based on the information entropy theory, a new algorithm using information entropy to evaluate a classification result is developed. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. When the concept in data streams changing, the classifiers' weight below a threshold value will be abandoned to adapt to a new concept in one time. In the experimental analysis section, six databases and four proposed algorithms are executed. The results show that the proposed method can not only handle concept drift effectively, but also have a better classification accuracy and time performance than the contrastive algorithms.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020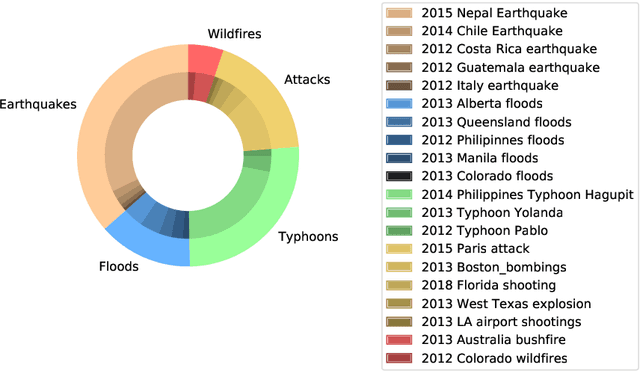

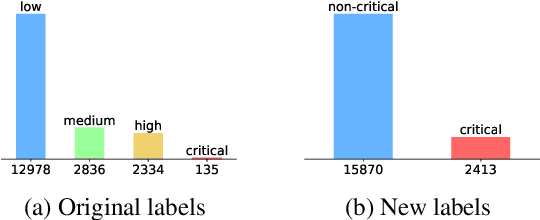
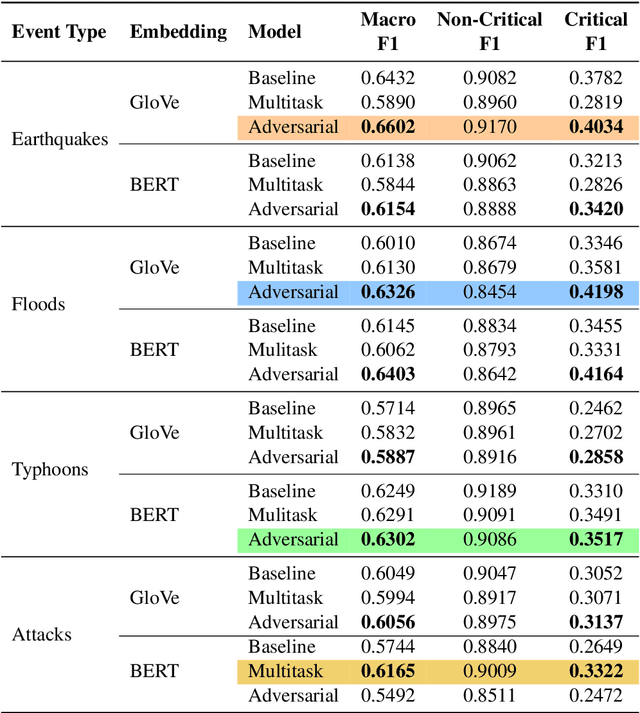
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.
What is Multimodality?
Mar 10, 2021


The last years have shown rapid developments in the field of multimodal machine learning, combining e.g., vision, text or speech. In this position paper we explain how the field uses outdated definitions of multimodality that prove unfit for the machine learning era. We propose a new task-relative definition of (multi)modality in the context of multimodal machine learning that focuses on representations and information that are relevant for a given machine learning task. With our new definition of multimodality we aim to provide a missing foundation for multimodal research, an important component of language grounding and a crucial milestone towards NLU.
GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks
Mar 16, 2021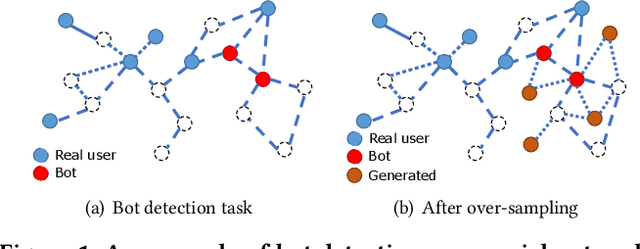
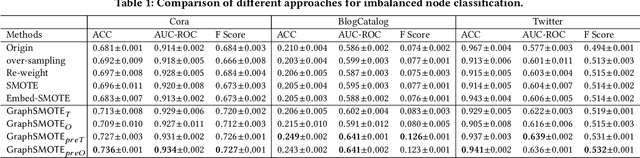
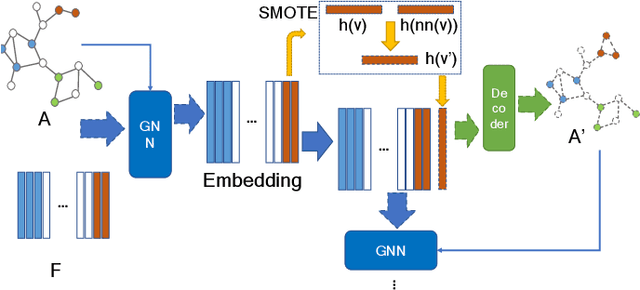
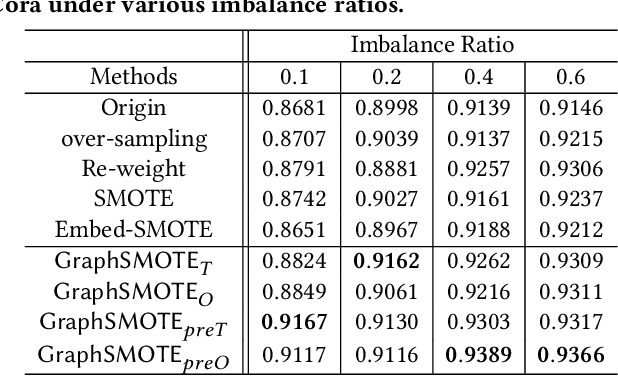
Node classification is an important research topic in graph learning. Graph neural networks (GNNs) have achieved state-of-the-art performance of node classification. However, existing GNNs address the problem where node samples for different classes are balanced; while for many real-world scenarios, some classes may have much fewer instances than others. Directly training a GNN classifier in this case would under-represent samples from those minority classes and result in sub-optimal performance. Therefore, it is very important to develop GNNs for imbalanced node classification. However, the work on this is rather limited. Hence, we seek to extend previous imbalanced learning techniques for i.i.d data to the imbalanced node classification task to facilitate GNN classifiers. In particular, we choose to adopt synthetic minority over-sampling algorithms, as they are found to be the most effective and stable. This task is non-trivial, as previous synthetic minority over-sampling algorithms fail to provide relation information for newly synthesized samples, which is vital for learning on graphs. Moreover, node attributes are high-dimensional. Directly over-sampling in the original input domain could generates out-of-domain samples, which may impair the accuracy of the classifier. We propose a novel framework, GraphSMOTE, in which an embedding space is constructed to encode the similarity among the nodes. New samples are synthesize in this space to assure genuineness. In addition, an edge generator is trained simultaneously to model the relation information, and provide it for those new samples. This framework is general and can be easily extended into different variations. The proposed framework is evaluated using three different datasets, and it outperforms all baselines with a large margin.
Identifying the Limits of Cross-Domain Knowledge Transfer for Pretrained Models
Apr 17, 2021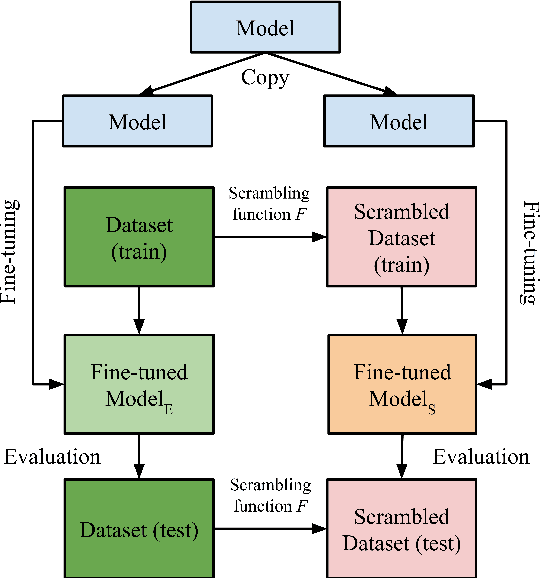

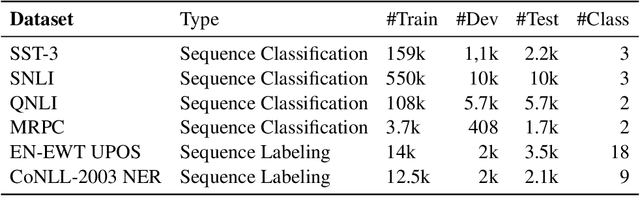
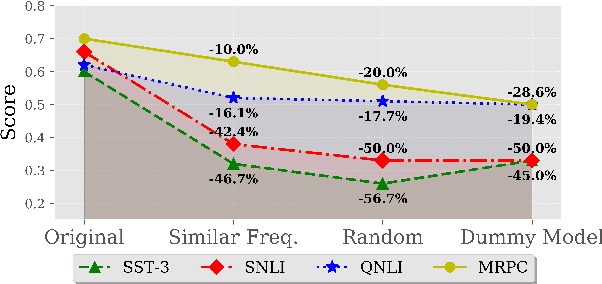
There is growing evidence that pretrained language models improve task-specific fine-tuning not just for the languages seen in pretraining, but also for new languages and even non-linguistic data. What is the nature of this surprising cross-domain transfer? We offer a partial answer via a systematic exploration of how much transfer occurs when models are denied any information about word identity via random scrambling. In four classification tasks and two sequence labeling tasks, we evaluate baseline models, LSTMs using GloVe embeddings, and BERT. We find that only BERT shows high rates of transfer into our scrambled domains, and for classification but not sequence labeling tasks. Our analyses seek to explain why transfer succeeds for some tasks but not others, to isolate the separate contributions of pretraining versus fine-tuning, and to quantify the role of word frequency. These findings help explain where and why cross-domain transfer occurs, which can guide future studies and practical fine-tuning efforts.
3D/2D regularized CNN feature hierarchy for Hyperspectral image classification
Apr 25, 2021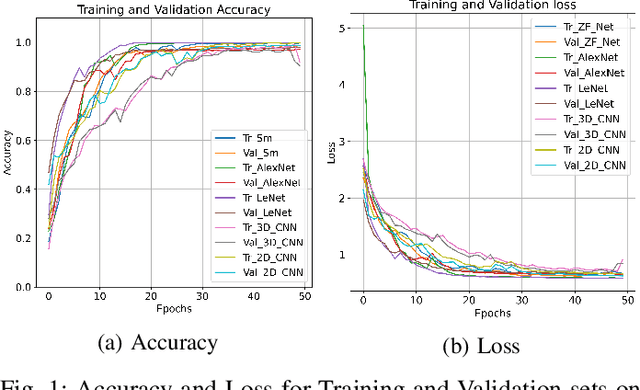
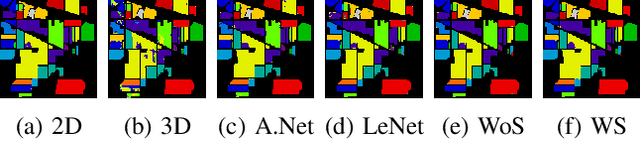
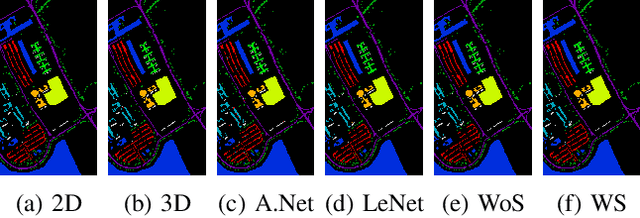
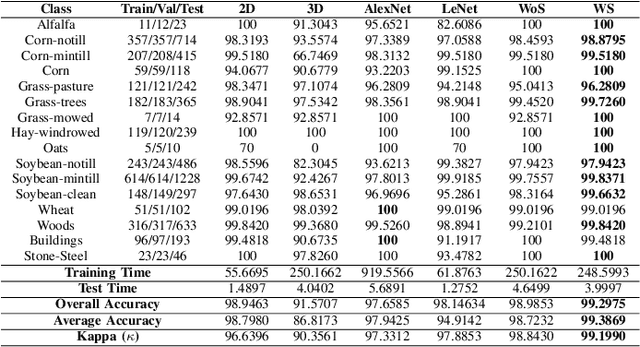
Convolutional Neural Networks (CNN) have been rigorously studied for Hyperspectral Image Classification (HSIC) and are known to be effective in exploiting joint spatial-spectral information with the expense of lower generalization performance and learning speed due to the hard labels and non-uniform distribution over labels. Several regularization techniques have been used to overcome the aforesaid issues. However, sometimes models learn to predict the samples extremely confidently which is not good from a generalization point of view. Therefore, this paper proposed an idea to enhance the generalization performance of a hybrid CNN for HSIC using soft labels that are a weighted average of the hard labels and uniform distribution over ground labels. The proposed method helps to prevent CNN from becoming over-confident. We empirically show that in improving generalization performance, label smoothing also improves model calibration which significantly improves beam-search. Several publicly available Hyperspectral datasets are used to validate the experimental evaluation which reveals improved generalization performance, statistical significance, and computational complexity as compared to the state-of-the-art models. The code will be made available at https://github.com/mahmad00.