 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021
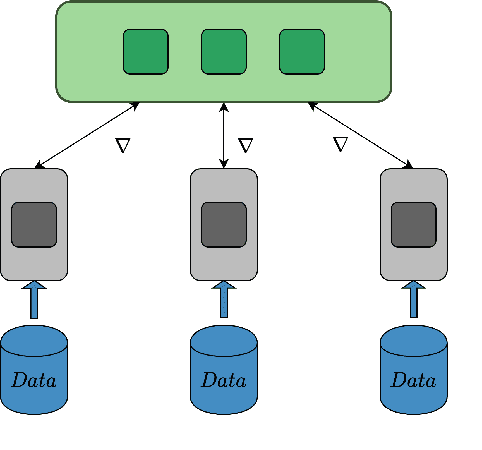
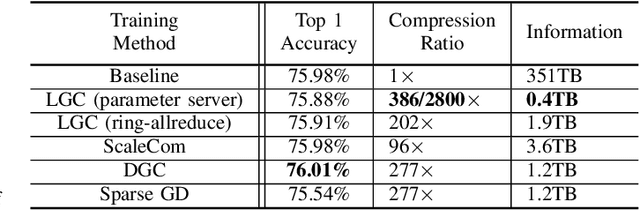
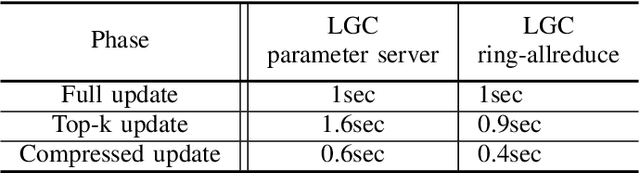
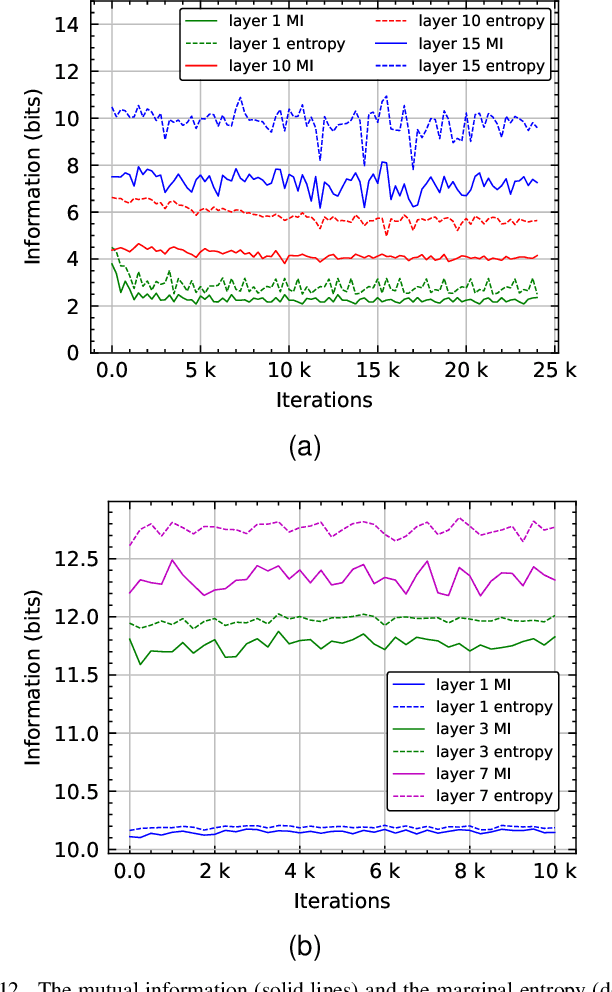
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.
COVID-19 Smart Chatbot Prototype for Patient Monitoring
Mar 11, 2021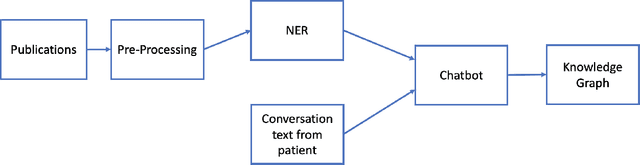
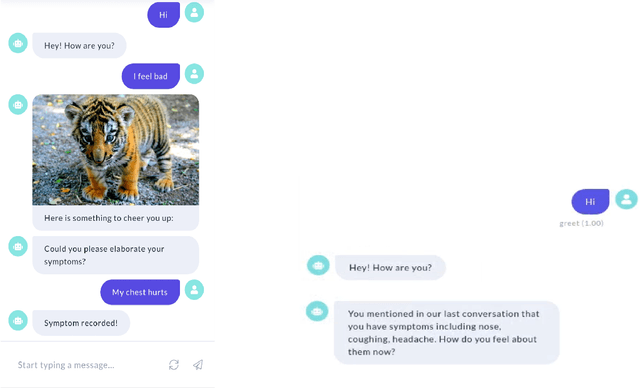
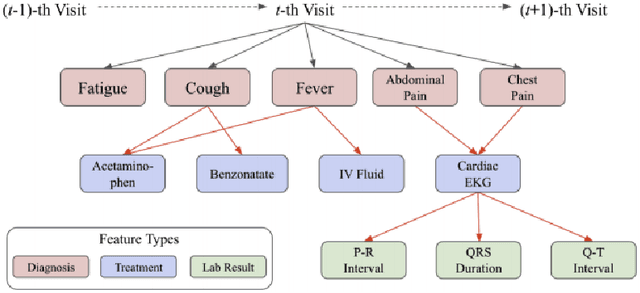
Many COVID-19 patients developed prolonged symptoms after the infection, including fatigue, delirium, and headache. The long-term health impact of these conditions is still not clear. It is necessary to develop a way to follow up with these patients for monitoring their health status to support timely intervention and treatment. In the lack of sufficient human resources to follow up with patients, we propose a novel smart chatbot solution backed with machine learning to collect information (i.e., generating digital diary) in a personalized manner. In this article, we describe the design framework and components of our prototype.
Alignment and stability of embeddings: measurement and inference improvement
Jan 18, 2021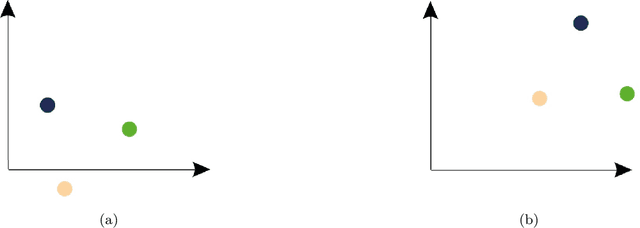
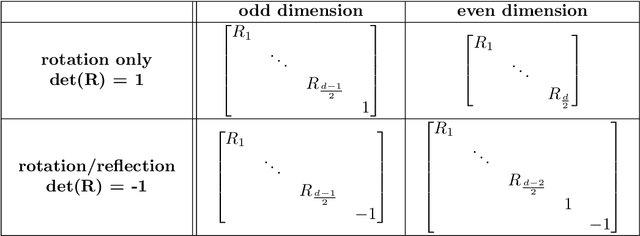

Representation learning (RL) methods learn objects' latent embeddings where information is preserved by distances. Since distances are invariant to certain linear transformations, one may obtain different embeddings while preserving the same information. In dynamic systems, a temporal difference in embeddings may be explained by the stability of the system or by the misalignment of embeddings due to arbitrary transformations. In the literature, embedding alignment has not been defined formally, explored theoretically, or analyzed empirically. Here, we explore the embedding alignment and its parts, provide the first formal definitions, propose novel metrics to measure alignment and stability, and show their suitability through synthetic experiments. Real-world experiments show that both static and dynamic RL methods are prone to produce misaligned embeddings and such misalignment worsens the performance of dynamic network inference tasks. By ensuring alignment, the prediction accuracy raises by up to 90% in static and by 40% in dynamic RL methods.
Unsupervised Cross-Lingual Information Retrieval using Monolingual Data Only
May 02, 2018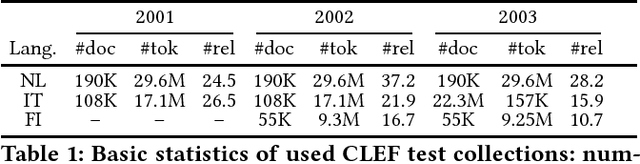
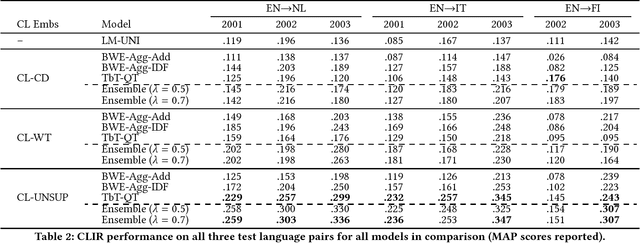
We propose a fully unsupervised framework for ad-hoc cross-lingual information retrieval (CLIR) which requires no bilingual data at all. The framework leverages shared cross-lingual word embedding spaces in which terms, queries, and documents can be represented, irrespective of their actual language. The shared embedding spaces are induced solely on the basis of monolingual corpora in two languages through an iterative process based on adversarial neural networks. Our experiments on the standard CLEF CLIR collections for three language pairs of varying degrees of language similarity (English-Dutch/Italian/Finnish) demonstrate the usefulness of the proposed fully unsupervised approach. Our CLIR models with unsupervised cross-lingual embeddings outperform baselines that utilize cross-lingual embeddings induced relying on word-level and document-level alignments. We then demonstrate that further improvements can be achieved by unsupervised ensemble CLIR models. We believe that the proposed framework is the first step towards development of effective CLIR models for language pairs and domains where parallel data are scarce or non-existent.
GeoWINE: Geolocation based Wiki, Image,News and Event Retrieval
May 04, 2021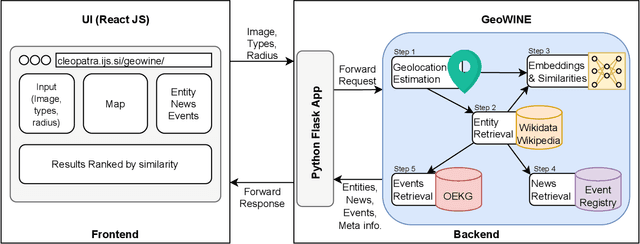

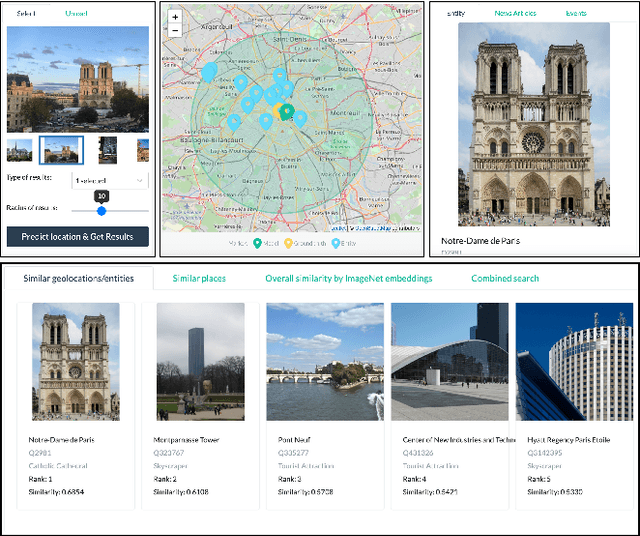
In the context of social media, geolocation inference on news or events has become a very important task. In this paper, we present the GeoWINE (Geolocation-based Wiki-Image-News-Event retrieval) demonstrator, an effective modular system for multimodal retrieval which expects only a single image as input. The GeoWINE system consists of five modules in order to retrieve related information from various sources. The first module is a state-of-the-art model for geolocation estimation of images. The second module performs a geospatial-based query for entity retrieval using the Wikidata knowledge graph. The third module exploits four different image embedding representations, which are used to retrieve most similar entities compared to the input image. The embeddings are derived from the tasks of geolocation estimation, place recognition, ImageNet-based image classification, and their combination. The last two modules perform news and event retrieval from EventRegistry and the Open Event Knowledge Graph (OEKG). GeoWINE provides an intuitive interface for end-users and is insightful for experts for reconfiguration to individual setups. The GeoWINE achieves promising results in entity label prediction for images on Google Landmarks dataset. The demonstrator is publicly available at http://cleopatra.ijs.si/geowine/.
ChaLearn LAP Large Scale Signer Independent Isolated Sign Language Recognition Challenge: Design, Results and Future Research
May 11, 2021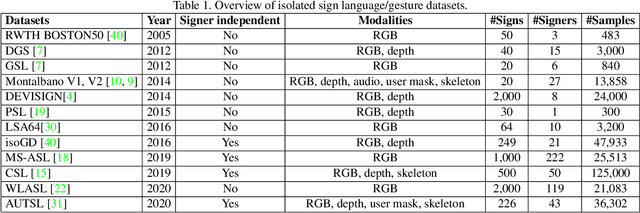

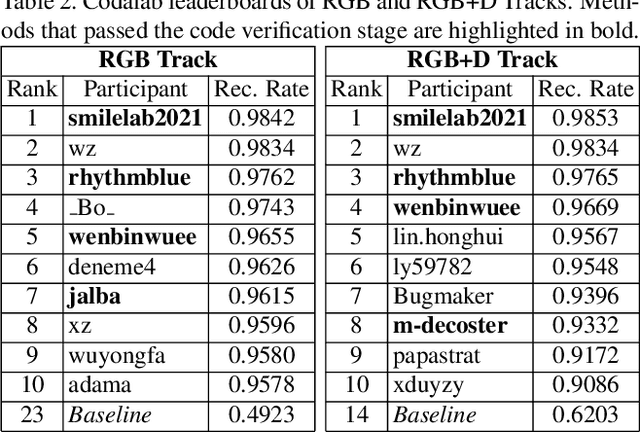
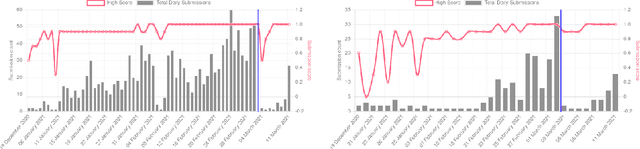
The performances of Sign Language Recognition (SLR) systems have improved considerably in recent years. However, several open challenges still need to be solved to allow SLR to be useful in practice. The research in the field is in its infancy in regards to the robustness of the models to a large diversity of signs and signers, and to fairness of the models to performers from different demographics. This work summarises the ChaLearn LAP Large Scale Signer Independent Isolated SLR Challenge, organised at CVPR 2021 with the goal of overcoming some of the aforementioned challenges. We analyse and discuss the challenge design, top winning solutions and suggestions for future research. The challenge attracted 132 participants in the RGB track and 59 in the RGB+Depth track, receiving more than 1.5K submissions in total. Participants were evaluated using a new large-scale multi-modal Turkish Sign Language (AUTSL) dataset, consisting of 226 sign labels and 36,302 isolated sign video samples performed by 43 different signers. Winning teams achieved more than 96% recognition rate, and their approaches benefited from pose/hand/face estimation, transfer learning, external data, fusion/ensemble of modalities and different strategies to model spatio-temporal information. However, methods still fail to distinguish among very similar signs, in particular those sharing similar hand trajectories.
An Improved Attention for Visual Question Answering
Nov 04, 2020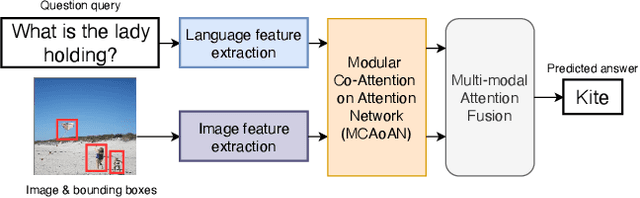
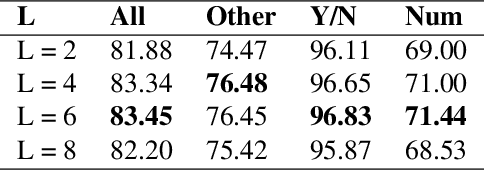
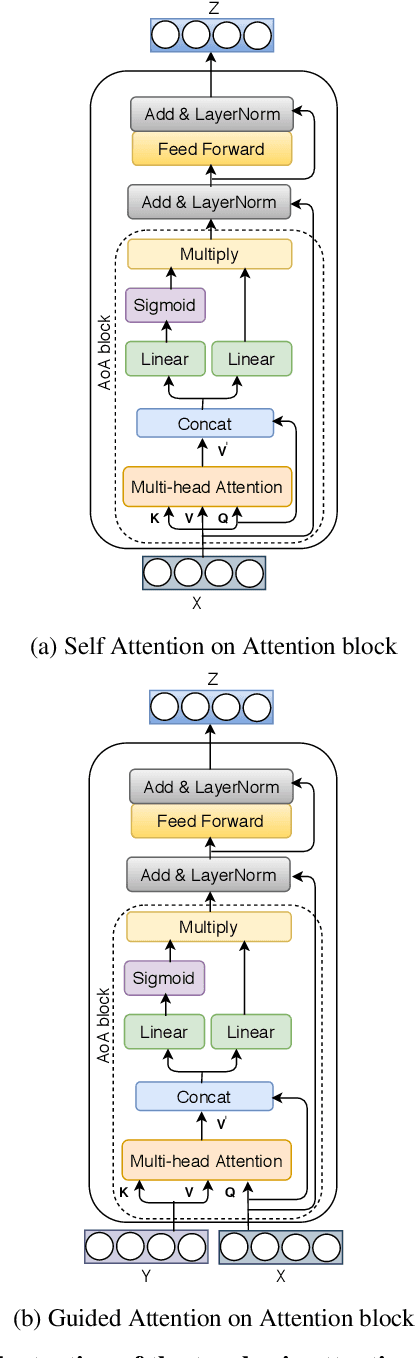

We consider the problem of Visual Question Answering (VQA). Given an image and a free-form, open-ended, question, expressed in natural language, the goal of VQA system is to provide accurate answer to this question with respect to the image. The task is challenging because it requires simultaneous and intricate understanding of both visual and textual information. Attention, which captures intra- and inter-modal dependencies, has emerged as perhaps the most widely used mechanism for addressing these challenges. In this paper, we propose an improved attention-based architecture to solve VQA. We incorporate an Attention on Attention (AoA) module within encoder-decoder framework, which is able to determine the relation between attention results and queries. Attention module generates weighted average for each query. On the other hand, AoA module first generates an information vector and an attention gate using attention results and current context; and then adds another attention to generate final attended information by multiplying the two. We also propose multimodal fusion module to combine both visual and textual information. The goal of this fusion module is to dynamically decide how much information should be considered from each modality. Extensive experiments on VQA-v2 benchmark dataset show that our method achieves the state-of-the-art performance.
Spherical Message Passing for 3D Graph Networks
Feb 09, 2021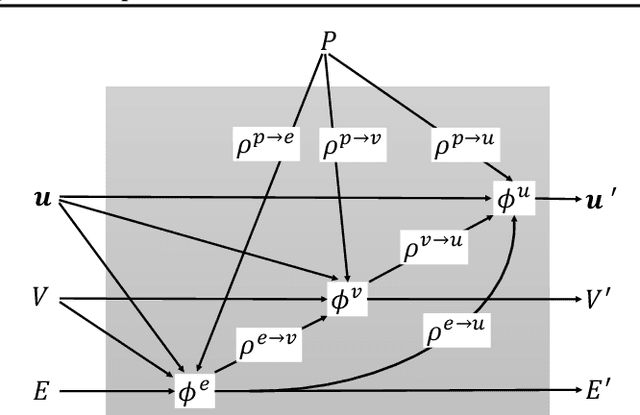
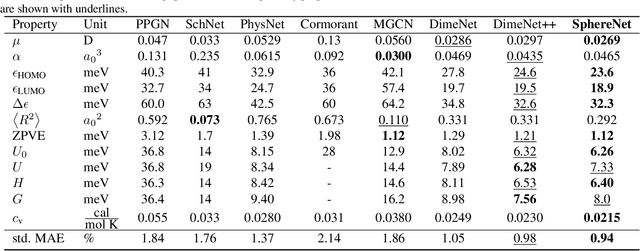
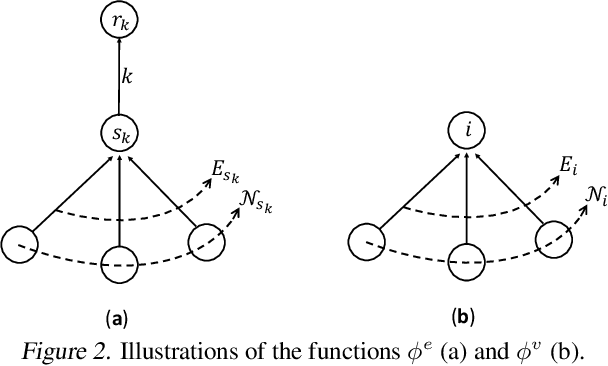
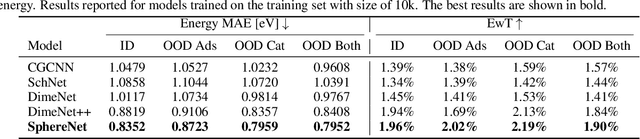
We consider representation learning from 3D graphs in which each node is associated with a spatial position in 3D. This is an under explored area of research, and a principled framework is currently lacking. In this work, we propose a generic framework, known as the 3D graph network (3DGN), to provide a unified interface at different levels of granularity for 3D graphs. Built on 3DGN, we propose the spherical message passing (SMP) as a novel and specific scheme for realizing the 3DGN framework in the spherical coordinate system (SCS). We conduct formal analyses and show that the relative location of each node in 3D graphs is uniquely defined in the SMP scheme. Thus, our SMP represents a complete and accurate architecture for learning from 3D graphs in the SCS. We derive physically-based representations of geometric information and propose the SphereNet for learning representations of 3D graphs. We show that existing 3D deep models can be viewed as special cases of the SphereNet. Experimental results demonstrate that the use of complete and accurate 3D information in 3DGN and SphereNet leads to significant performance improvements in prediction tasks.
Oriented RepPoints for Aerial Object Detection
May 24, 2021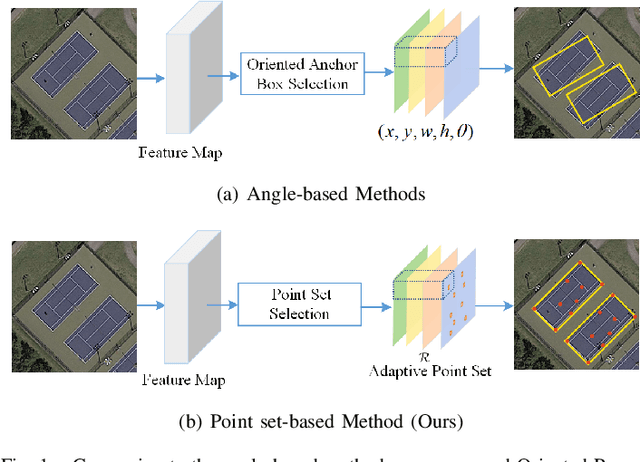

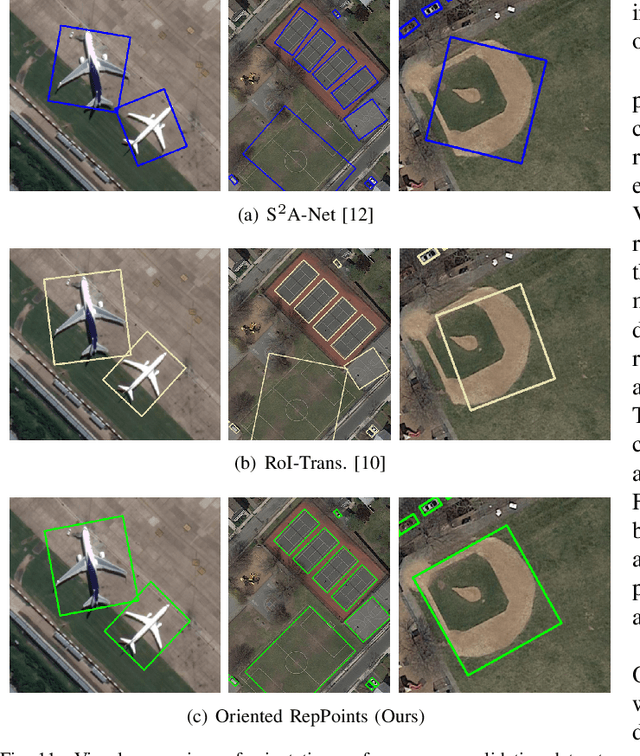

In contrast to the oriented bounding boxes, point set representation has great potential to capture the detailed structure of instances with the arbitrary orientations, large aspect ratios and dense distribution in aerial images. However, the conventional point set-based approaches are handcrafted with the fixed locations using points-to-points supervision, which hurts their flexibility on the fine-grained feature extraction. To address these limitations, in this paper, we propose a novel approach to aerial object detection, named Oriented RepPoints. Specifically, we suggest to employ a set of adaptive points to capture the geometric and spatial information of the arbitrary-oriented objects, which is able to automatically arrange themselves over the object in a spatial and semantic scenario. To facilitate the supervised learning, the oriented conversion function is proposed to explicitly map the adaptive point set into an oriented bounding box. Moreover, we introduce an effective quality assessment measure to select the point set samples for training, which can choose the representative items with respect to their potentials on orientated object detection. Furthermore, we suggest a spatial constraint to penalize the outlier points outside the ground-truth bounding box. In addition to the traditional evaluation metric mAP focusing on overlap ratio, we propose a new metric mAOE to measure the orientation accuracy that is usually neglected in the previous studies on oriented object detection. Experiments on three widely used datasets including DOTA, HRSC2016 and UCAS-AOD demonstrate that our proposed approach is effective.
Short-term forecast of EV charging stations occupancy probability using big data streaming analysis
Apr 26, 2021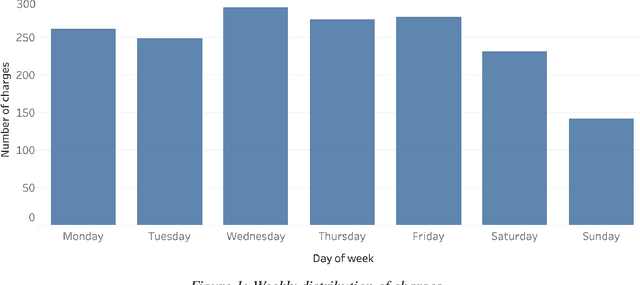
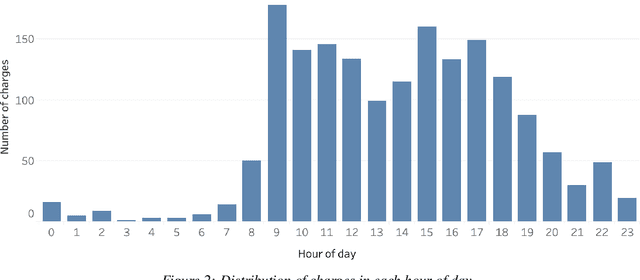
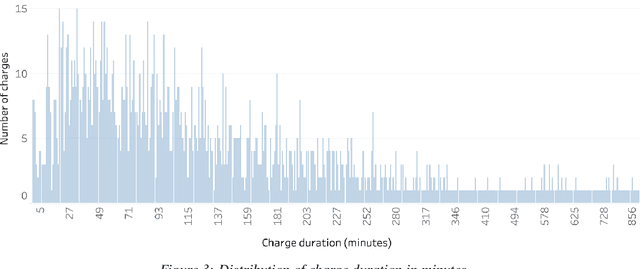
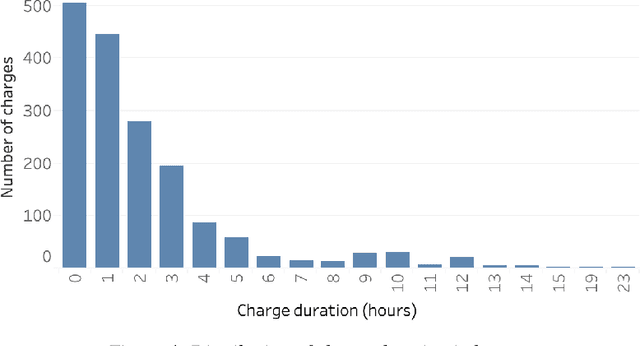
The widespread diffusion of electric mobility requires a contextual expansion of the charging infrastructure. An extended collection and processing of information regarding charging of electric vehicles may turn each electric vehicle charging station into a valuable source of streaming data. Charging point operators may profit from all these data for optimizing their operation and planning activities. In such a scenario, big data and machine learning techniques would allow valorizing real-time data coming from electric vehicle charging stations. This paper presents an architecture able to deal with data streams from a charging infrastructure, with the final aim to forecast electric charging station availability after a set amount of minutes from present time. Both batch data regarding past charges and real-time data streams are used to train a streaming logistic regression model, to take into account recurrent past situations and unexpected actual events. The streaming model performs better than a model trained only using historical data. The results highlight the importance of constantly updating the predictive model parameters in order to adapt to changing conditions and always provide accurate forecasts.