 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Compact and adaptive multiplane images for view synthesis
Feb 19, 2021

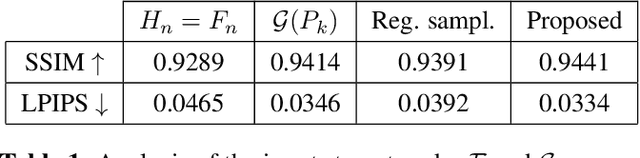
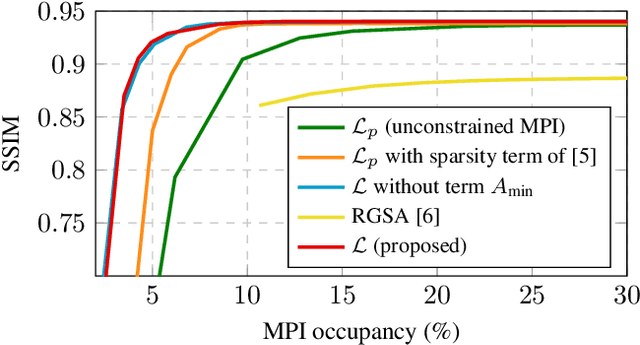
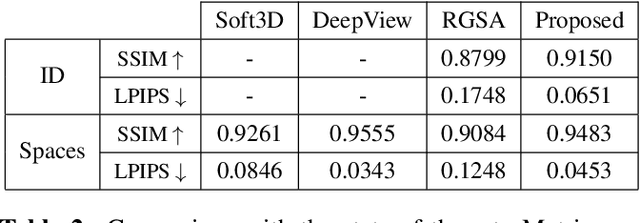
Recently, learning methods have been designed to create Multiplane Images (MPIs) for view synthesis. While MPIs are extremely powerful and facilitate high quality renderings, a great amount of memory is required, making them impractical for many applications. In this paper, we propose a learning method that optimizes the available memory to render compact and adaptive MPIs. Our MPIs avoid redundant information and take into account the scene geometry to determine the depth sampling.
Explaining and Improving BERT Performance on Lexical Semantic Change Detection
Mar 12, 2021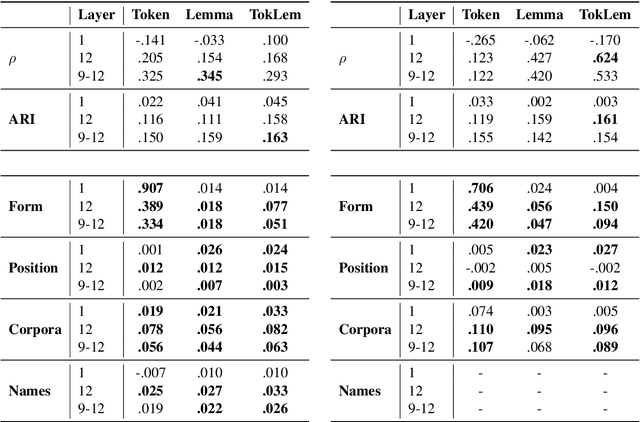
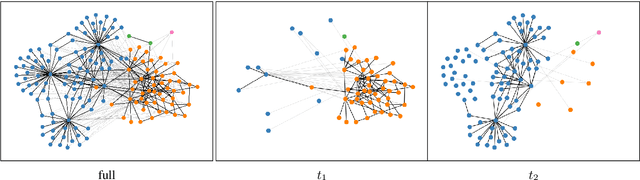
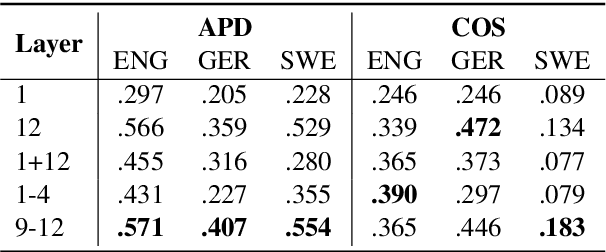
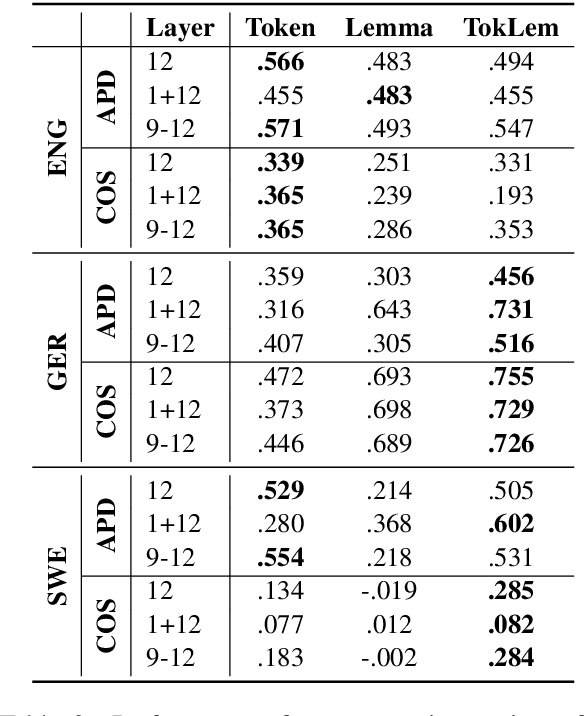
Type- and token-based embedding architectures are still competing in lexical semantic change detection. The recent success of type-based models in SemEval-2020 Task 1 has raised the question why the success of token-based models on a variety of other NLP tasks does not translate to our field. We investigate the influence of a range of variables on clusterings of BERT vectors and show that its low performance is largely due to orthographic information on the target word, which is encoded even in the higher layers of BERT representations. By reducing the influence of orthography we considerably improve BERT's performance.
DPT-FSNet:Dual-path Transformer Based Full-band and Sub-band Fusion Network for Speech Enhancement
Apr 27, 2021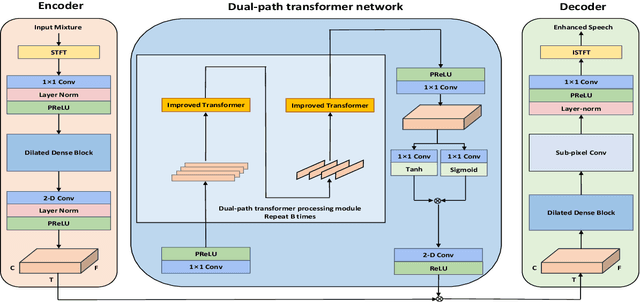
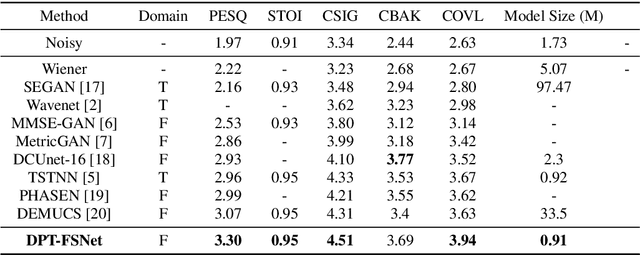

Recently, dual-path networks have achieved promising performance due to their ability to model local and global features of the input sequence. However, previous studies are based on simple time-domain features and do not fully investigate the impact of the input features of the dual-path network on the enhancement performance. In this paper, we propose a dual-path transformer-based full-band and sub-band fusion network (DPT-FSNet) for speech enhancement in the frequency domain. The intra and inter parts of the dual-path transformer network in our model can be seen as sub-band and full-band modeling respectively, which have stronger interpretability as well as more information compared to the features utilized by the time-domain transformer. We conducted experiments on the Voice Bank + DEMAND dataset to evaluate the proposed method. Experimental results show that the proposed method outperforms the current state-of-the-arts in terms of PESQ, STOI, CSIG, COVL. (The PESQ, STOI, CSIG, and COVL scores on the Voice Bank + DEMAND dataset were 3.30, 0.95, 4.51, and 3.94, respectively).
On- Device Information Extraction from Screenshots in form of tags
Jan 11, 2020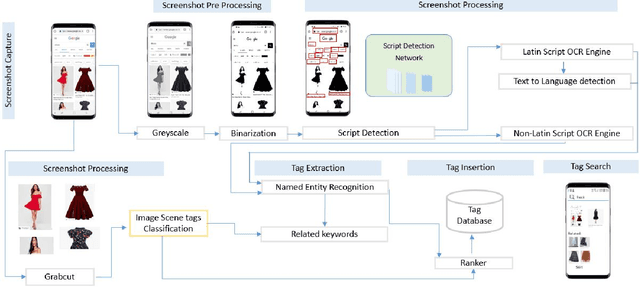

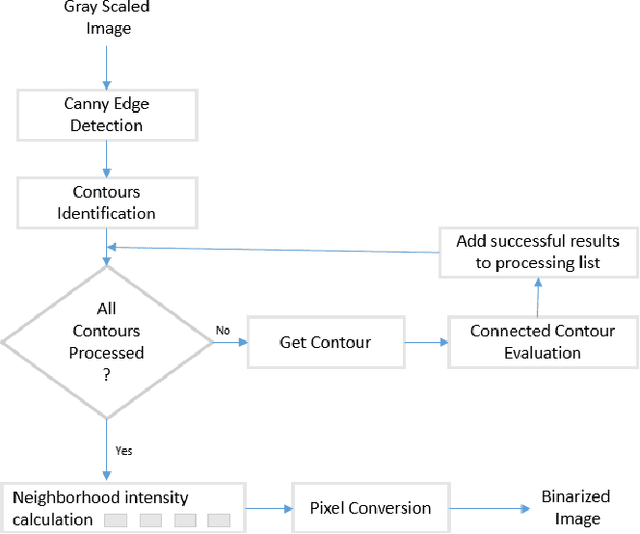
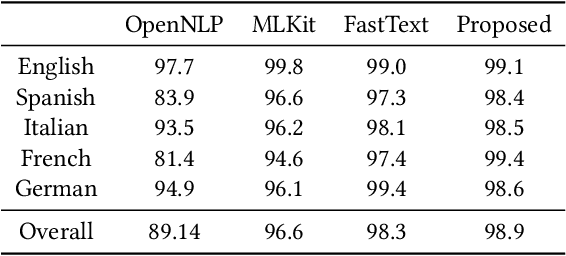
We propose a method to make mobile screenshots easily searchable. In this paper, we present the workflow in which we: 1) preprocessed a collection of screenshots, 2) identified script presentin image, 3) extracted unstructured text from images, 4) identifiedlanguage of the extracted text, 5) extracted keywords from the text, 6) identified tags based on image features, 7) expanded tag set by identifying related keywords, 8) inserted image tags with relevant images after ranking and indexed them to make it searchable on device. We made the pipeline which supports multiple languages and executed it on-device, which addressed privacy concerns. We developed novel architectures for components in the pipeline, optimized performance and memory for on-device computation. We observed from experimentation that the solution developed can reduce overall user effort and improve end user experience while searching, whose results are published.
Motion Vector Extrapolation for Video Object Detection
Apr 18, 2021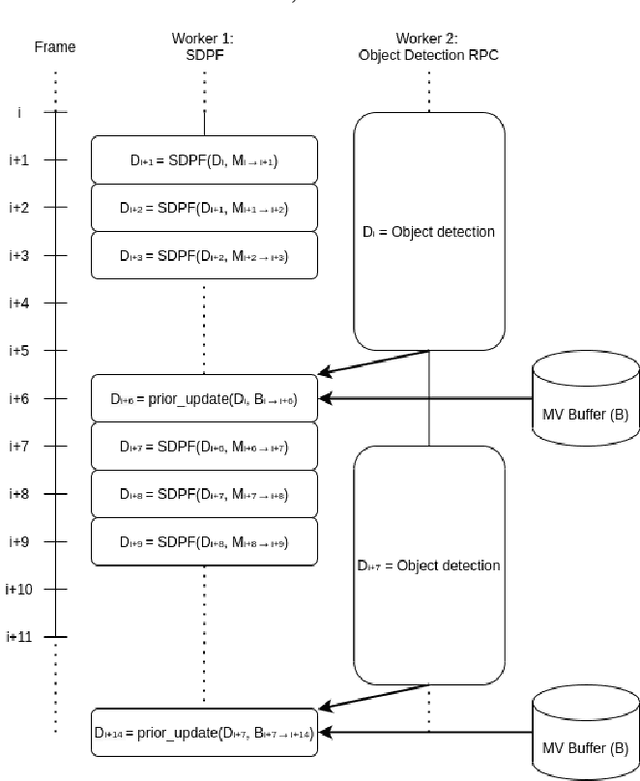
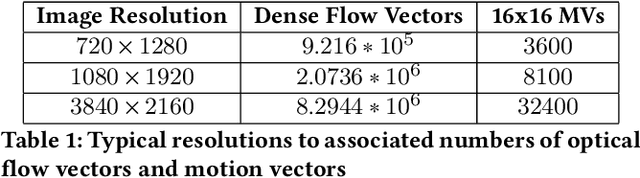
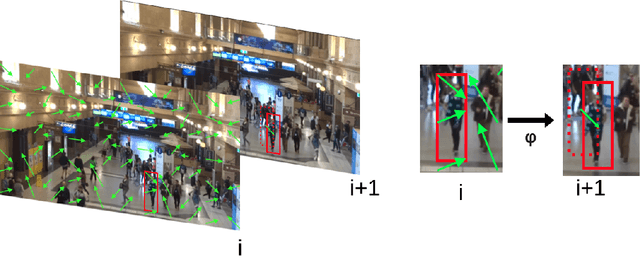
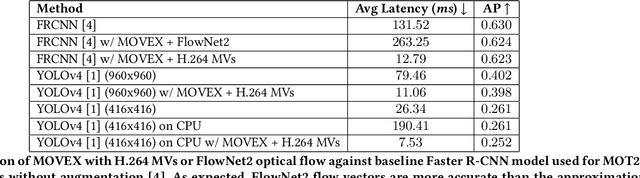
Despite the continued successes of computationally efficient deep neural network architectures for video object detection, performance continually arrives at the great trilemma of speed versus accuracy versus computational resources (pick two). Current attempts to exploit temporal information in video data to overcome this trilemma are bottlenecked by the state-of-the-art in object detection models. We present, a technique which performs video object detection through the use of off-the-shelf object detectors alongside existing optical flow based motion estimation techniques in parallel. Through a set of experiments on the benchmark MOT20 dataset, we demonstrate that our approach significantly reduces the baseline latency of any given object detector without sacrificing any accuracy. Further latency reduction, up to 25x lower than the original latency, can be achieved with minimal accuracy loss. MOVEX enables low latency video object detection on common CPU based systems, thus allowing for high performance video object detection beyond the domain of GPU computing. The code is available at https://github.com/juliantrue/movex.
Texture Based Classification of High Resolution Remotely Sensed Imagery using Weber Local Descriptor
Apr 18, 2021
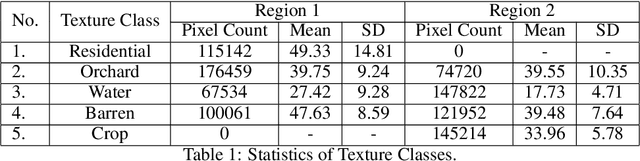
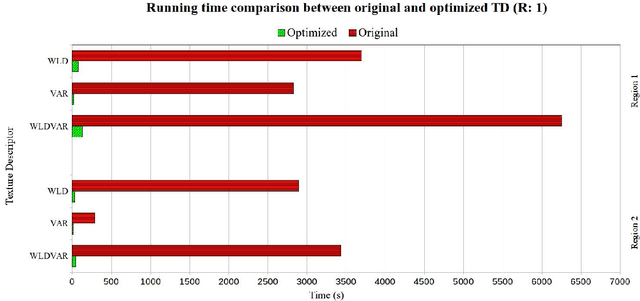
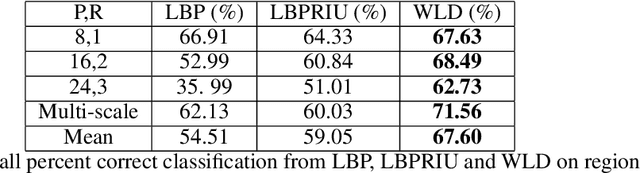
Traditional image classification techniques often produce unsatisfactory results when applied to high spatial resolution data because classes in high resolution images are not spectrally homogeneous. Texture offers an alternative source of information for classifying these images. This paper evaluates a recently developed, computationally simple texture metric called Weber Local Descriptor (WLD) for use in classifying high resolution QuickBird panchromatic data. We compared WLD with state-of-the art texture descriptors (TD) including Local Binary Pattern (LBP) and its rotation-invariant version LBPRIU. We also investigated whether incorporating VAR, a TD that captures brightness variation, would improve the accuracy of LBPRIU and WLD. We found that WLD generally produces more accurate classification results than the other TD we examined, and is also more robust to varying parameters. We have implemented an optimised algorithm for calculating WLD which makes the technique practical in terms of computation time. Overall, our results indicate that WLD is a promising approach for classifying high resolution remote sensing data.
Extracting Predictive Information from Heterogeneous Data Streams using Gaussian Processes
Jul 11, 2018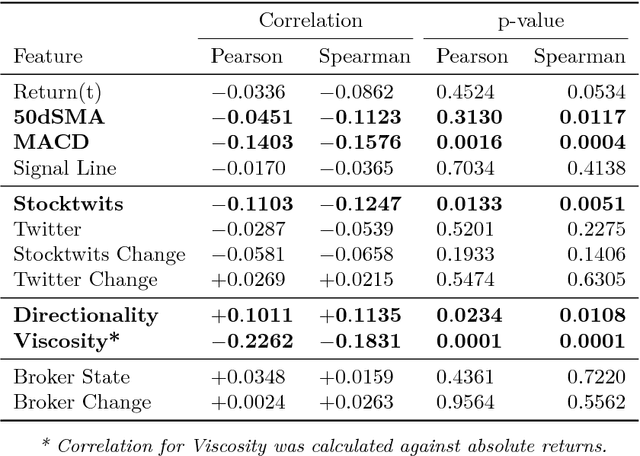
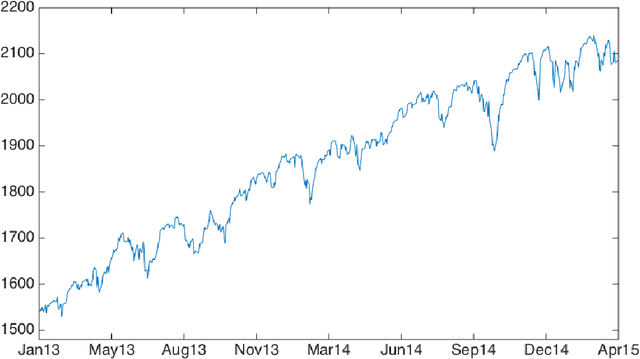
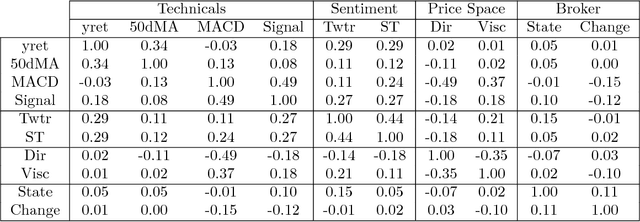
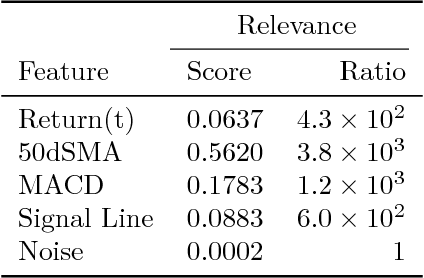
Financial markets are notoriously complex environments, presenting vast amounts of noisy, yet potentially informative data. We consider the problem of forecasting financial time series from a wide range of information sources using online Gaussian Processes with Automatic Relevance Determination (ARD) kernels. We measure the performance gain, quantified in terms of Normalised Root Mean Square Error (NRMSE), Median Absolute Deviation (MAD) and Pearson correlation, from fusing each of four separate data domains: time series technicals, sentiment analysis, options market data and broker recommendations. We show evidence that ARD kernels produce meaningful feature rankings that help retain salient inputs and reduce input dimensionality, providing a framework for sifting through financial complexity. We measure the performance gain from fusing each domain's heterogeneous data streams into a single probabilistic model. In particular our findings highlight the critical value of options data in mapping out the curvature of price space and inspire an intuitive, novel direction for research in financial prediction.
Knowledge-aware Zero-Shot Learning: Survey and Perspective
Feb 26, 2021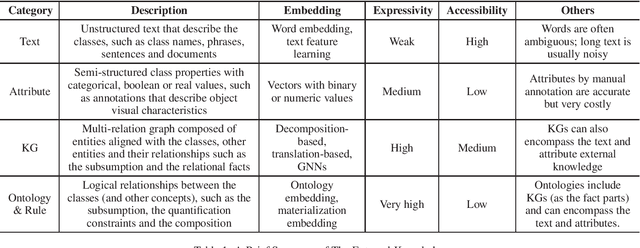
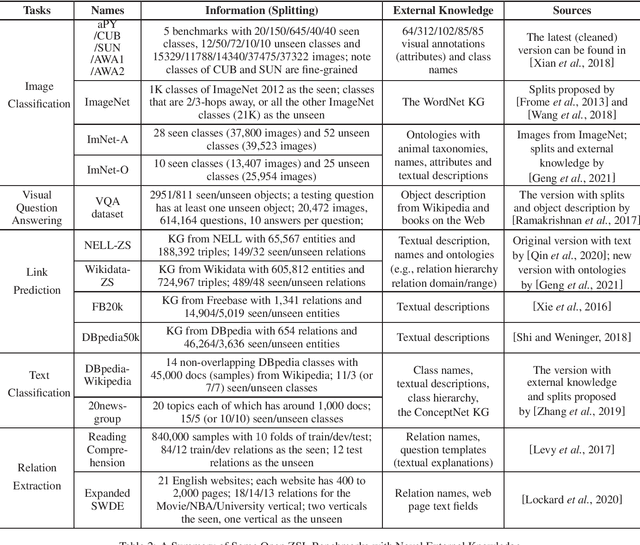
Zero-shot learning (ZSL) which aims at predicting classes that have never appeared during the training using external knowledge (a.k.a. side information) has been widely investigated. In this paper we present a literature review towards ZSL in the perspective of external knowledge, where we categorize the external knowledge, review their methods and compare different external knowledge. With the literature review, we further discuss and outlook the role of symbolic knowledge in addressing ZSL and other machine learning sample shortage issues.
Adaptive Graph Diffusion Networks with Hop-wise Attention
Dec 30, 2020


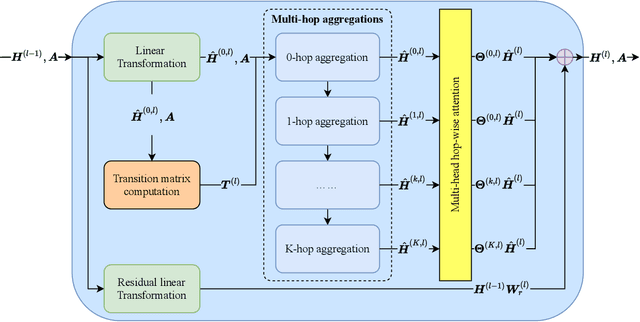
Graph Neural Networks (GNNs) have received much attention recent years and have achieved state-of-the-art performances in many fields. The deeper GNNs can theoretically capture deeper neighborhood information. However, they often suffer from problems of over-fitting and over-smoothing. In order to incorporate deeper information while preserving considerable complexity and generalization ability, we propose Adaptive Graph Diffusion Networks with Hop-wise Attention (AGDNs-HA). We stack multi-hop neighborhood aggregations of different orders into single layer. Then we integrate them with the help of hop-wise attention, which is learnable and adaptive for each node. Experimental results on the standard dataset with semi-supervised node classification task show that our proposed methods achieve significant improvements.
Multi-Aspect Temporal Network Embedding: A Mixture of Hawkes Process View
May 18, 2021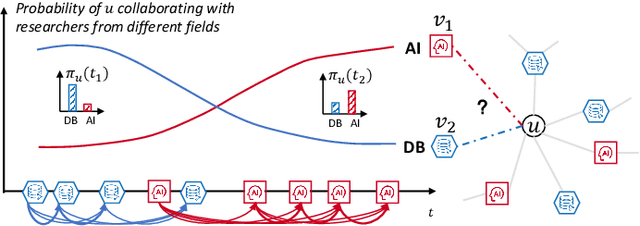
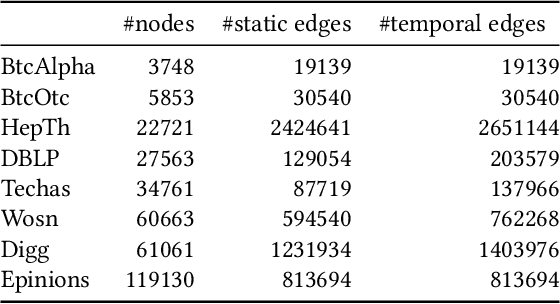
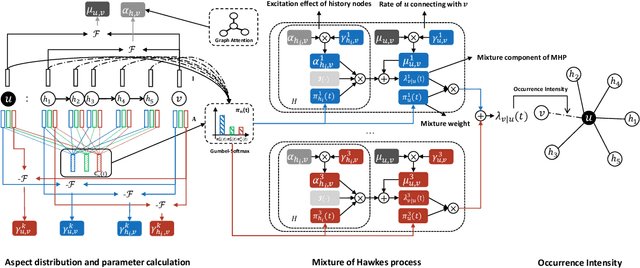
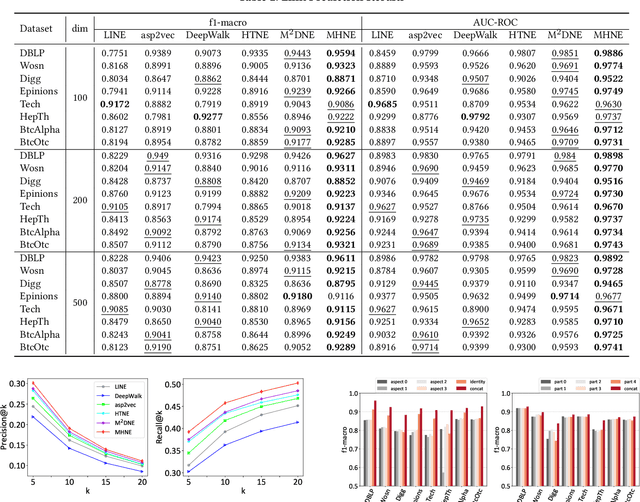
Recent years have witnessed the tremendous research interests in network embedding. Extant works have taken the neighborhood formation as the critical information to reveal the inherent dynamics of network structures, and suggested encoding temporal edge formation sequences to capture the historical influences of neighbors. In this paper, however, we argue that the edge formation can be attributed to a variety of driving factors including the temporal influence, which is better referred to as multiple aspects. As a matter of fact, different node aspects can drive the formation of distinctive neighbors, giving birth to the multi-aspect embedding that relates to but goes beyond a temporal scope. Along this vein, we propose a Mixture of Hawkes-based Temporal Network Embeddings (MHNE) model to capture the aspect-driven neighborhood formation of networks. In MHNE, we encode the multi-aspect embeddings into the mixture of Hawkes processes to gain the advantages in modeling the excitation effects and the latent aspects. Specifically, a graph attention mechanism is used to assign different weights to account for the excitation effects of history events, while a Gumbel-Softmax is plugged in to derive the distribution over the aspects. Extensive experiments on 8 different temporal networks have demonstrated the great performance of the multi-aspect embeddings obtained by MHNE in comparison with the state-of-the-art methods.