 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 05, 2021
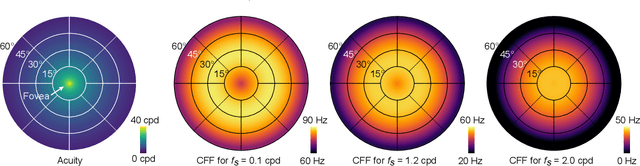
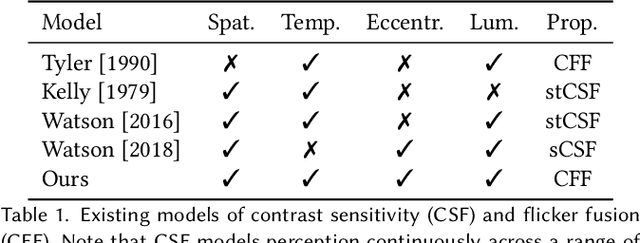

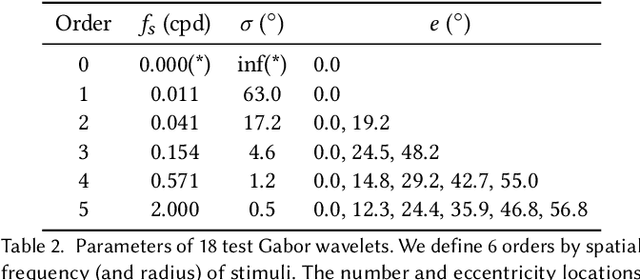
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Weakly Supervised Pseudo-Label assisted Learning for ALS Point Cloud Semantic Segmentation
May 05, 2021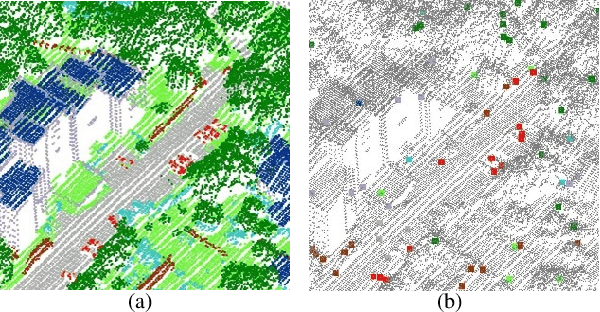
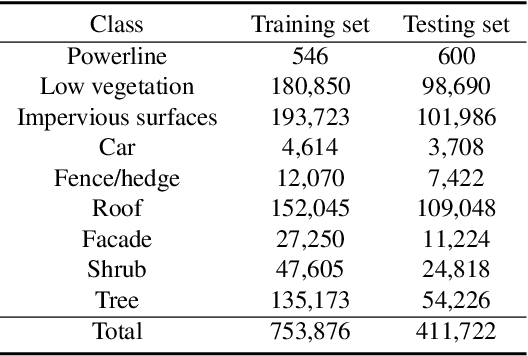
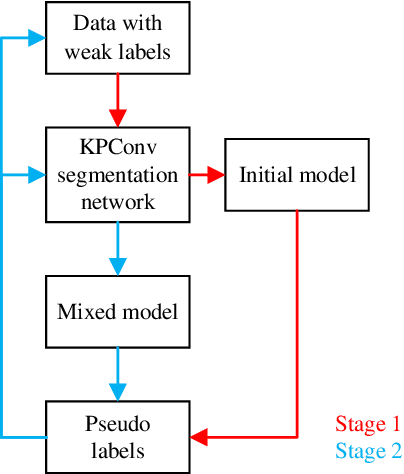
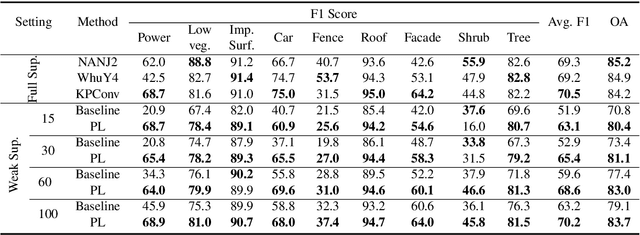
Competitive point cloud semantic segmentation results usually rely on a large amount of labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for three-dimensional point cloud data. Thus, obtaining accurate results with limited ground truth as training data is considerably important. As a simple and effective method, pseudo labels can use information from unlabeled data for training neural networks. In this study, we propose a pseudo-label-assisted point cloud segmentation method with very few sparsely sampled labels that are normally randomly selected for each class. An adaptive thresholding strategy was proposed to generate a pseudo-label based on the prediction probability. Pseudo-label learning is an iterative process, and pseudo labels were updated solely on ground-truth weak labels as the model converged to improve the training efficiency. Experiments using the ISPRS 3D sematic labeling benchmark dataset indicated that our proposed method achieved an equally competitive result compared to that using a full supervision scheme with only up to 2$\unicode{x2030}$ of labeled points from the original training set, with an overall accuracy of 83.7% and an average F1 score of 70.2%.
Exploring Current User Web Search Behaviours in Analysis Tasks to be Supported in Conversational Search
Apr 09, 2021

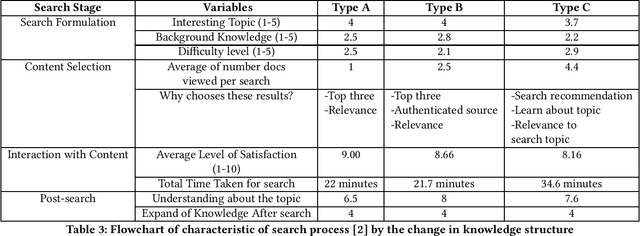

Conversational search presents opportunities to support users in their search activities to improve the effectiveness and efficiency of search while reducing their cognitive load. Limitations of the potential competency of conversational agents restrict the situations for which conversational search agents can replace human intermediaries. It is thus more interesting, initially at least, to investigate opportunities for conversational interaction to support less complex information retrieval tasks, such as typical web search, which do not require human-level intelligence in the conversational agent. In order to move towards the development of a system to enable conversational search of this type, we need to understand their required capabilities. To progress our understanding of these, we report a study examining the behaviour of users when using a standard web search engine, designed to enable us to identify opportunities to support their search activities using a conversational agent.
Asymptotic Freeness of Layerwise Jacobians Caused by Invariance of Multilayer Perceptron: The Haar Orthogonal Case
Mar 24, 2021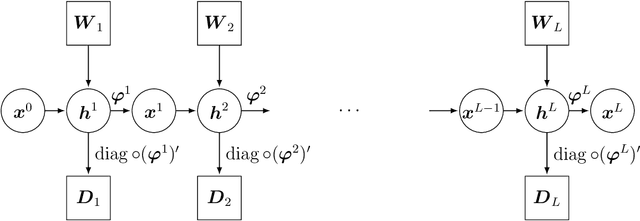
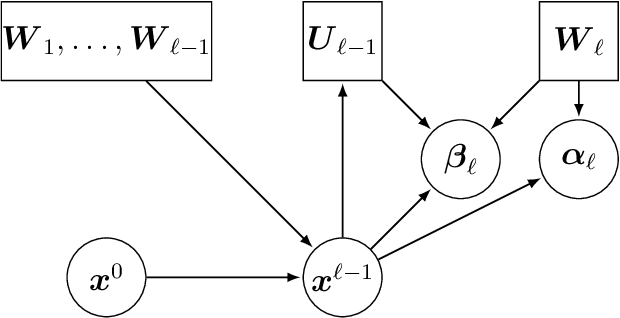
Free Probability Theory (FPT) provides rich knowledge for handling mathematical difficulties caused by random matrices that appear in researches of deep neural networks (DNNs), such as the dynamical isometry, Fisher information matrix, and training dynamics. FPT suits these researches because the DNN's parameter-Jacobian and input-Jacobian are polynomials of layerwise Jacobians. However, the critical assumption, that is, the layerwise Jacobian's asymptotic freeness, has not been proven completely so far. The asymptotic freeness assumption has foundamental roles in these researches to propagate spectral distributions through the layers. In the present work, we prove the asymptotic freeness of layerwise Jacobian of multilayer perceptrons with Haar distributed orthogonal matrices, which are essential for achieving dynamical isometry.
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
May 12, 2021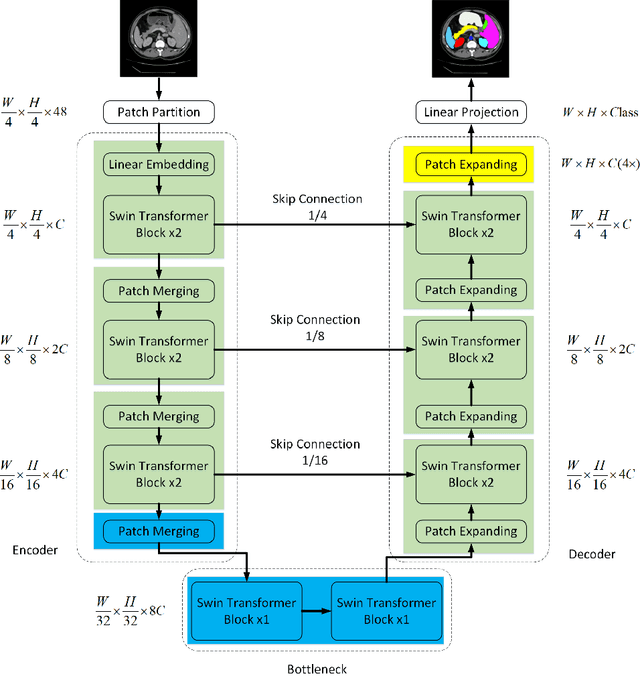
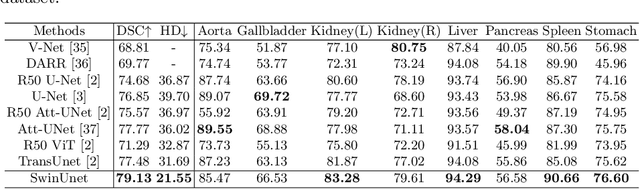
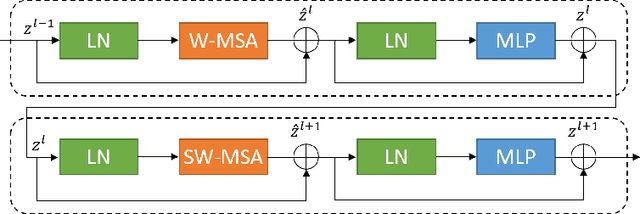
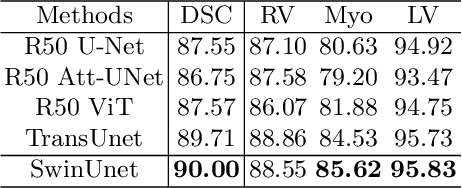
In the past few years, convolutional neural networks (CNNs) have achieved milestones in medical image analysis. Especially, the deep neural networks based on U-shaped architecture and skip-connections have been widely applied in a variety of medical image tasks. However, although CNN has achieved excellent performance, it cannot learn global and long-range semantic information interaction well due to the locality of the convolution operation. In this paper, we propose Swin-Unet, which is an Unet-like pure Transformer for medical image segmentation. The tokenized image patches are fed into the Transformer-based U-shaped Encoder-Decoder architecture with skip-connections for local-global semantic feature learning. Specifically, we use hierarchical Swin Transformer with shifted windows as the encoder to extract context features. And a symmetric Swin Transformer-based decoder with patch expanding layer is designed to perform the up-sampling operation to restore the spatial resolution of the feature maps. Under the direct down-sampling and up-sampling of the inputs and outputs by 4x, experiments on multi-organ and cardiac segmentation tasks demonstrate that the pure Transformer-based U-shaped Encoder-Decoder network outperforms those methods with full-convolution or the combination of transformer and convolution. The codes and trained models will be publicly available at https://github.com/HuCaoFighting/Swin-Unet.
Roof Damage Assessment from Automated 3D Building Models
Jun 04, 2021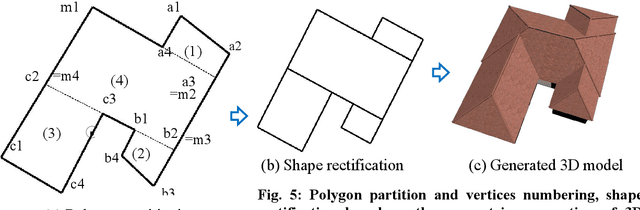

The 3D building modelling is important in urban planning and related domains that draw upon the content of 3D models of urban scenes. Such 3D models can be used to visualize city images at multiple scales from individual buildings to entire cities prior to and after a change has occurred. This ability is of great importance in day-to-day work and special projects undertaken by planners, geo-designers, and architects. In this research, we implemented a novel approach to 3D building models for such matter, which included the integration of geographic information systems (GIS) and 3D Computer Graphics (3DCG) components that generate 3D house models from building footprints (polygons), and the automated generation of simple and complex roof geometries for rapid roof area damage reporting. These polygons (footprints) are usually orthogonal. A complicated orthogonal polygon can be partitioned into a set of rectangles. The proposed GIS and 3DCG integrated system partitions orthogonal building polygons into a set of rectangles and places rectangular roofs and box-shaped building bodies on these rectangles. Since technicians are drawing these polygons manually with digitizers, depending on aerial photos, not all building polygons are precisely orthogonal. But, when placing a set of boxes as building bodies for creating the buildings, there may be gaps or overlaps between these boxes if building polygons are not precisely orthogonal. In our proposal, after approximately orthogonal building polygons are partitioned and rectified into a set of mutually orthogonal rectangles, each rectangle knows which rectangle is adjacent to and which edge of the rectangle is adjacent to, which will avoid unwanted intersection of windows and doors when building bodies combined.
Knowledge Grounded Conversational Symptom Detection with Graph Memory Networks
Jan 24, 2021
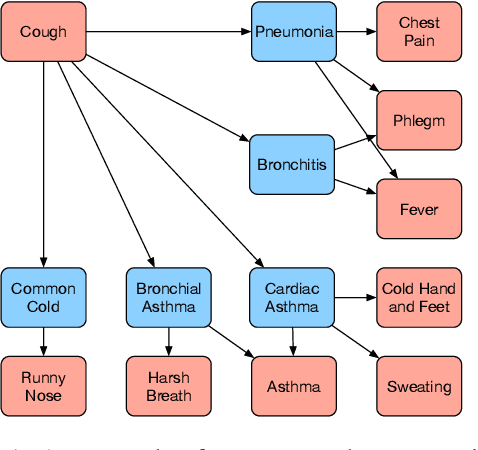

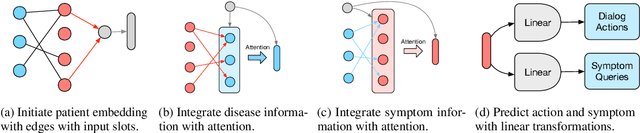
In this work, we propose a novel goal-oriented dialog task, automatic symptom detection. We build a system that can interact with patients through dialog to detect and collect clinical symptoms automatically, which can save a doctor's time interviewing the patient. Given a set of explicit symptoms provided by the patient to initiate a dialog for diagnosing, the system is trained to collect implicit symptoms by asking questions, in order to collect more information for making an accurate diagnosis. After getting the reply from the patient for each question, the system also decides whether current information is enough for a human doctor to make a diagnosis. To achieve this goal, we propose two neural models and a training pipeline for the multi-step reasoning task. We also build a knowledge graph as additional inputs to further improve model performance. Experiments show that our model significantly outperforms the baseline by 4%, discovering 67% of implicit symptoms on average with a limited number of questions.
A Novel Uncertainty-aware Collaborative Learning Method for Remote Sensing Image Classification Under Multi-Label Noise
May 12, 2021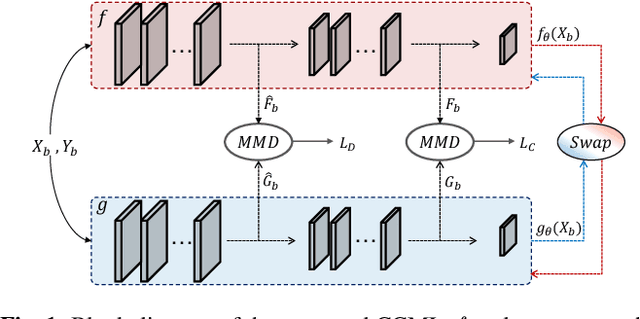
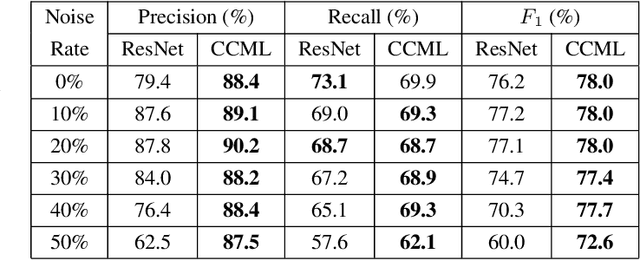
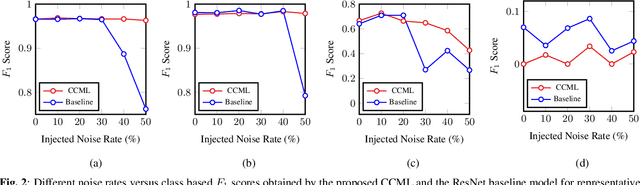
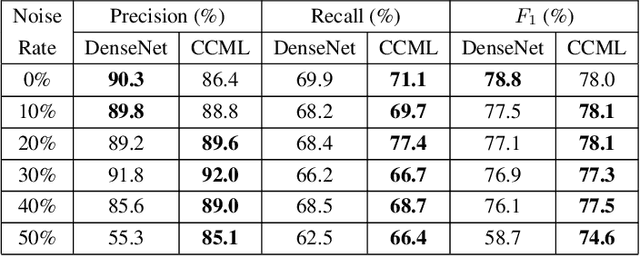
In remote sensing (RS), collecting a large number of reliable training images annotated by multiple land-cover class labels for multi-label classification (MLC) is time-consuming and costly. To address this problem, the publicly available thematic products are often used for annotating RS images with zero-labeling cost. However, in this case the training set can include noisy multi-labels that distort the learning process, resulting in inaccurate predictions. This paper proposes an architect-independent Consensual Collaborative Multi-Label Learning (CCML) method to train deep classifiers under input-dependent (heteroscedastic) multi-label noise in the MLC problems. The proposed CCML identifies, ranks, and corrects noisy multi-label images through four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The group lasso module detects the potentially noisy labels by estimating the label uncertainty based on the aggregation of two collaborative networks. The discrepancy module ensures that the two networks learn diverse features, while obtaining the same predictions. The flipping module corrects the identified noisy labels, and the swap module exchanges the ranking information between the two networks. The experiments conducted on the multi-label RS image archive IR-BigEarthNet confirm the robustness of the proposed CCML under extreme multi-label noise rates.
Dynamic-Deep: ECG Task-Aware Compression
May 30, 2021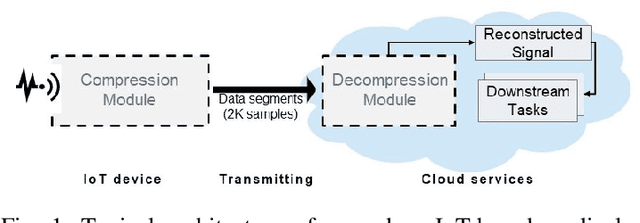
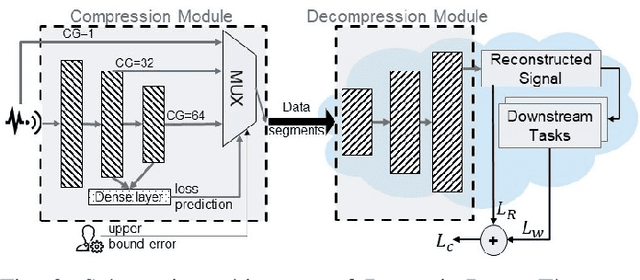
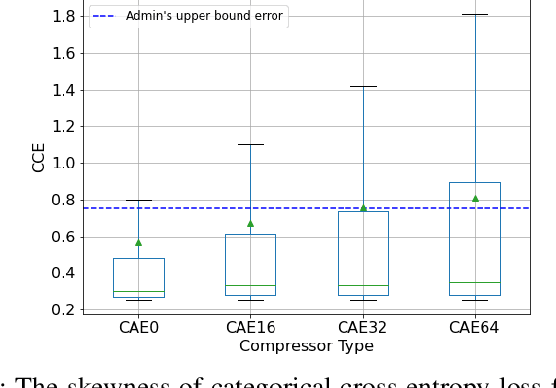
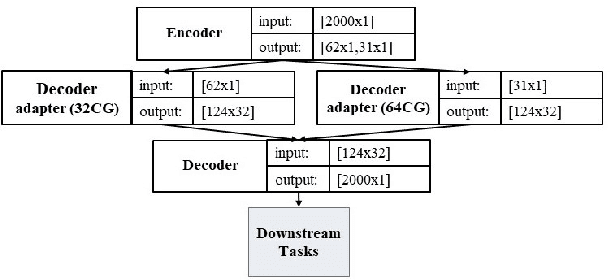
Monitoring medical data, e.g., Electrocardiogram (ECG) signals, is a common application of Internet of Things (IoT) devices. Compression methods are often applied on the massive amounts of sensor data generated before sending it to the Cloud to reduce storage and delivery costs. A lossy compression provides high compression gain (CG) but may reduce the performance of an ECG application (downstream task) due to information loss. Previous works on ECG monitoring focus either on optimizing the signal reconstruction or the task's performance. Instead, we advocate a lossy compression solution that allows configuring a desired performance level on the downstream tasks while maintaining an optimized CG. We propose Dynamic-Deep, a task-aware compression that uses convolutional autoencoders. The compression level is dynamically selected to yield an optimized compression without violating tasks' performance requirements. We conduct an extensive evaluation of our approach on common ECG datasets using two popular ECG applications, which includes heart rate (HR) arrhythmia classification. We demonstrate that Dynamic-Deep improves HR classification F1-score by a factor of 3 and increases CG by up to 83% compared to the previous state-of-the-art (autoencoder-based) compressor. Additionally, Dynamic-Deep has a 67% lower memory footprint. Analyzing Dynamic-Deep on the Google Cloud Platform, we observe a 97% reduction in cloud costs compared to a no compression solution. To the best of our knowledge, Dynamic-Deep is the first proposal to focus on balancing the need for high performance of cloud-based downstream tasks and the desire to achieve optimized compression in IoT ECG monitoring settings.
A Joint Power Splitting, Active and Passive Beamforming Optimization Framework for IRS Assisted MIMO SWIPT System
May 30, 2021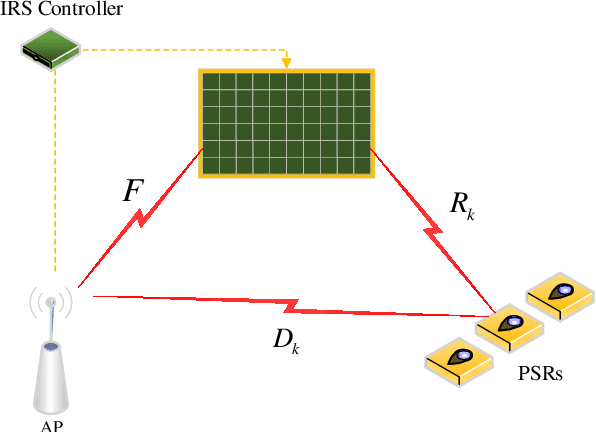
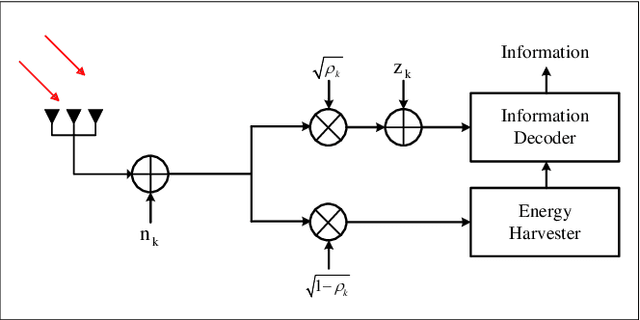
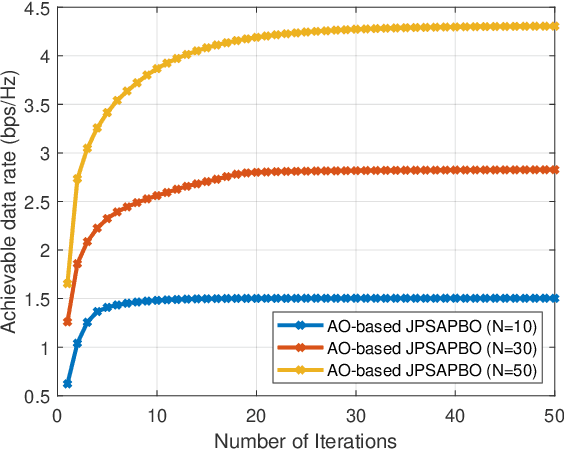
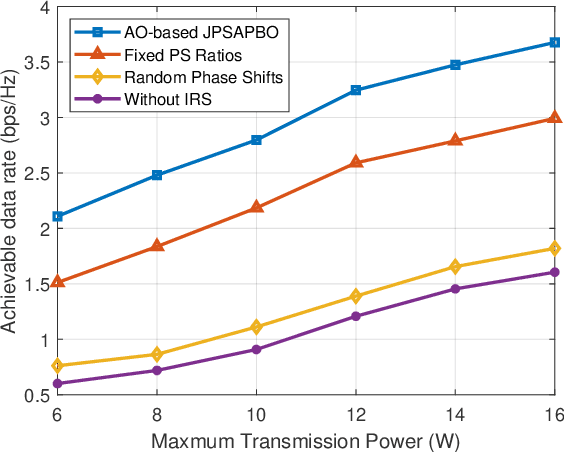
This paper considers an intelligent reflecting surface (IRS) assisted multi-input multi-output (MIMO) power splitting (PS) based simultaneous wireless information and power transfer (SWIPT) system with multiple PS receivers (PSRs). The objective is to maximize the achievable data rate of the system by jointly optimizing the PS ratios at the PSRs, the active transmit beamforming (ATB) at the access point (AP), and the passive reflective beamforming (PRB) at the IRS, while the constraints on maximum transmission power at the AP, the reflective phase shift of each element at the IRS, the individual minimum harvested energy requirement of each PSR, and the domain of PS ratio of each PSR are all satisfied. For this unsolved problem, however, since the optimization variables are intricately coupled and the constraints are conflicting, the formulated problem is non-convex, and cannot be addressed by employing exist approaches directly. To this end, we propose a joint optimization framework to solve this problem. Particularly, we reformulate it as an equivalent form by employing the Lagrangian dual transform and the fractional programming transform, and decompose the transformed problem into several sub-problems. Then, we propose an alternate optimization algorithm by capitalizing on the dual sub-gradient method, the successive convex approximation method, and the penalty-based majorization-minimization approach, to solve the sub-problems iteratively, and obtain the optimal solutions in nearly closed-forms. Numerical simulation results verify the effectiveness of the IRS in SWIPT system and indicate that the proposed algorithm offers a substantial performance gain.