 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Texture Synthesis by Incorporating Long-range Spatial and Temporal Correlations
Apr 14, 2021


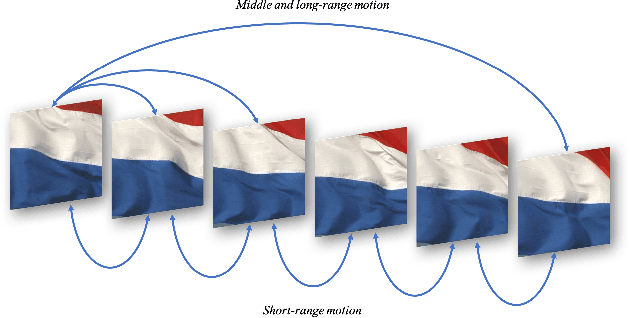

The main challenge of dynamic texture synthesis lies in how to maintain spatial and temporal consistency in synthesized videos. The major drawback of existing dynamic texture synthesis models comes from poor treatment of the long-range texture correlation and motion information. To address this problem, we incorporate a new loss term, called the Shifted Gram loss, to capture the structural and long-range correlation of the reference texture video. Furthermore, we introduce a frame sampling strategy to exploit long-period motion across multiple frames. With these two new techniques, the application scope of existing texture synthesis models can be extended. That is, they can synthesize not only homogeneous but also structured dynamic texture patterns. Thorough experimental results are provided to demonstrate that our proposed dynamic texture synthesis model offers state-of-the-art visual performance.
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
May 28, 2021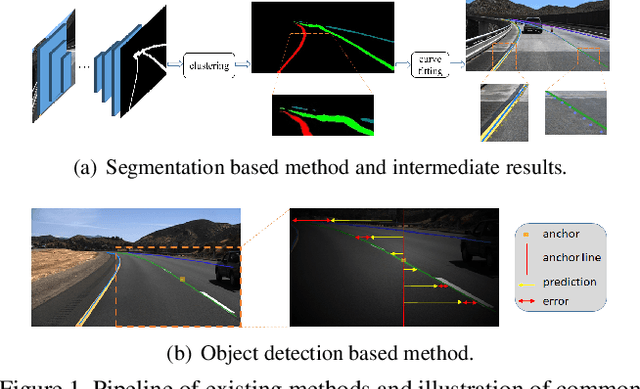
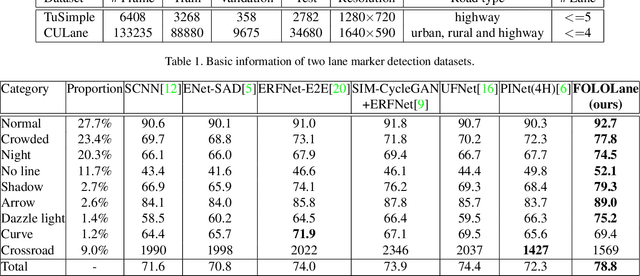
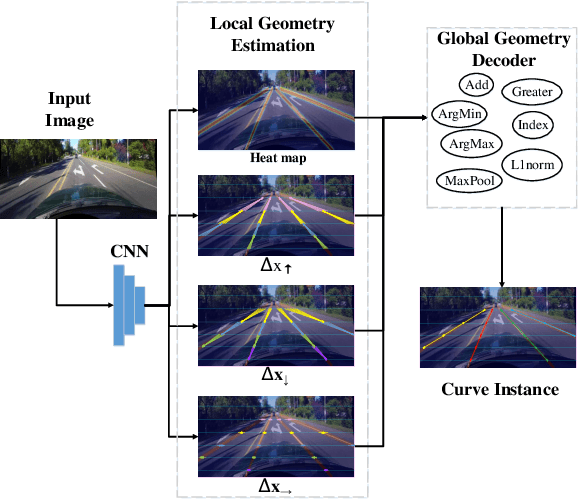

Mainstream lane marker detection methods are implemented by predicting the overall structure and deriving parametric curves through post-processing. Complex lane line shapes require high-dimensional output of CNNs to model global structures, which further increases the demand for model capacity and training data. In contrast, the locality of a lane marker has finite geometric variations and spatial coverage. We propose a novel lane marker detection solution, FOLOLane, that focuses on modeling local patterns and achieving prediction of global structures in a bottom-up manner. Specifically, the CNN models lowcomplexity local patterns with two separate heads, the first one predicts the existence of key points, and the second refines the location of key points in the local range and correlates key points of the same lane line. The locality of the task is consistent with the limited FOV of the feature in CNN, which in turn leads to more stable training and better generalization. In addition, an efficiency-oriented decoding algorithm was proposed as well as a greedy one, which achieving 36% runtime gains at the cost of negligible performance degradation. Both of the two decoders integrated local information into the global geometry of lane markers. In the absence of a complex network architecture design, the proposed method greatly outperforms all existing methods on public datasets while achieving the best state-of-the-art results and real-time processing simultaneously.
Study of Robust Distributed Diffusion RLS Algorithms with Side Information for Adaptive Networks
Feb 04, 2019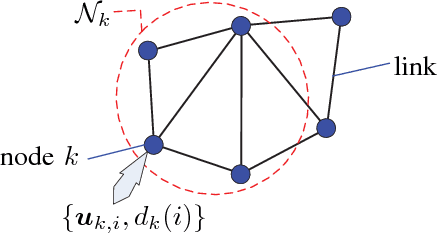
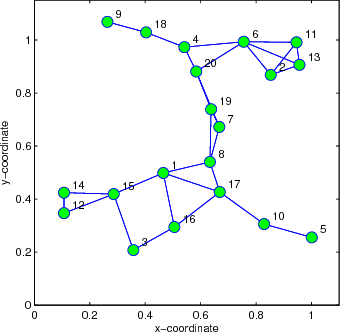
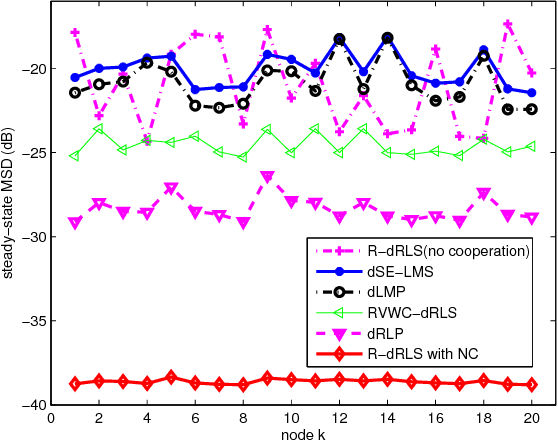
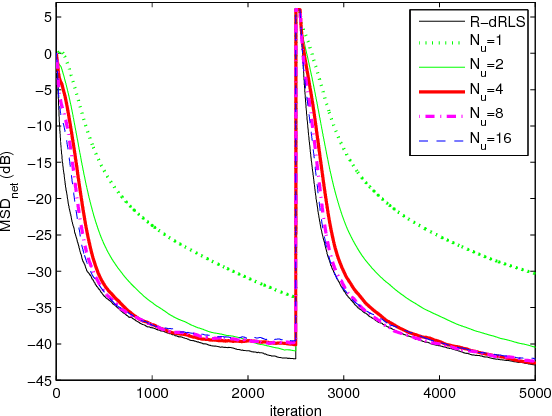
This work develops robust diffusion recursive least squares algorithms to mitigate the performance degradation often experienced in networks of agents in the presence of impulsive noise. The first algorithm minimizes an exponentially weighted least-squares cost function subject to a time-dependent constraint on the squared norm of the intermediate update at each node. A recursive strategy for computing the constraint is proposed using side information from the neighboring nodes to further improve the robustness. We also analyze the mean-square convergence behavior of the proposed algorithm. The second proposed algorithm is a modification of the first one based on the dichotomous coordinate descent iterations. It has a performance similar to that of the former, however its complexity is significantly lower especially when input regressors of agents have a shift structure and it is well suited to practical implementation. Simulations show the superiority of the proposed algorithms over previously reported techniques in various impulsive noise scenarios.
NeurT-FDR: Controlling FDR by Incorporating Feature Hierarchy
Jan 24, 2021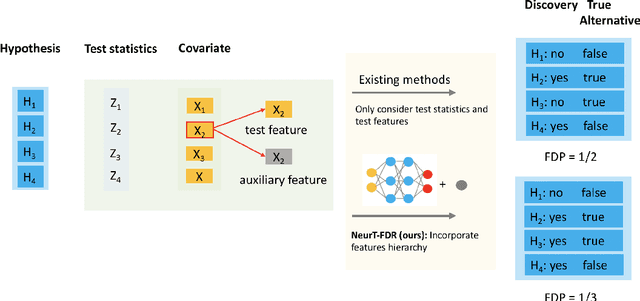
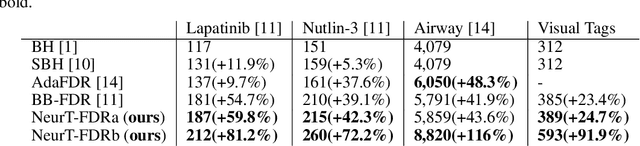
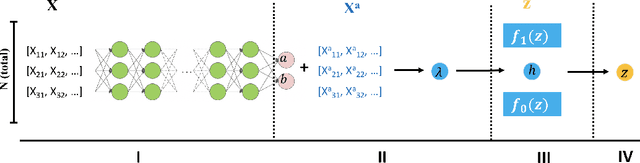
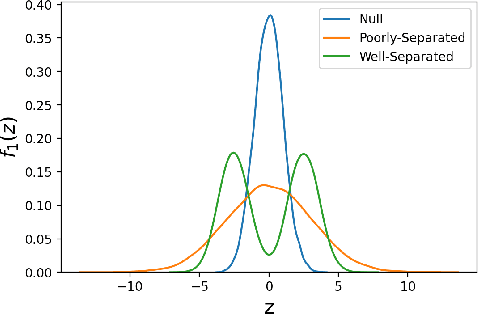
Controlling false discovery rate (FDR) while leveraging the side information of multiple hypothesis testing is an emerging research topic in modern data science. Existing methods rely on the test-level covariates while ignoring possible hierarchy among the covariates. This strategy may not be optimal for complex large-scale problems, where hierarchical information often exists among those test-level covariates. We propose NeurT-FDR which boosts statistical power and controls FDR for multiple hypothesis testing while leveraging the hierarchy among test-level covariates. Our method parametrizes the test-level covariates as a neural network and adjusts the feature hierarchy through a regression framework, which enables flexible handling of high-dimensional features as well as efficient end-to-end optimization. We show that NeurT-FDR has strong FDR guarantees and makes substantially more discoveries in synthetic and real datasets compared to competitive baselines.
Exploring the Intrinsic Probability Distribution for Hyperspectral Anomaly Detection
May 14, 2021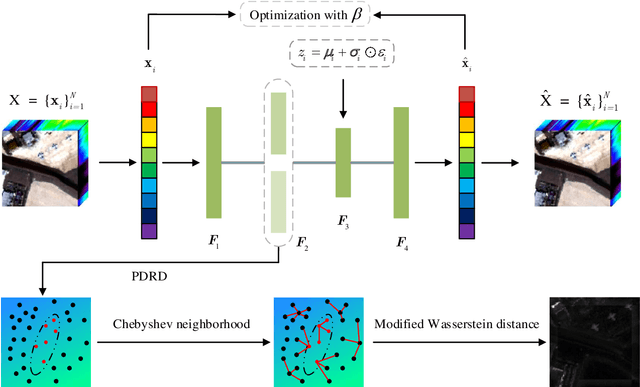
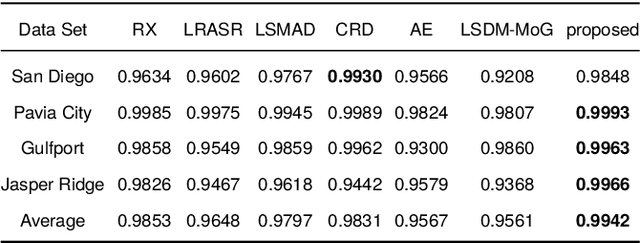

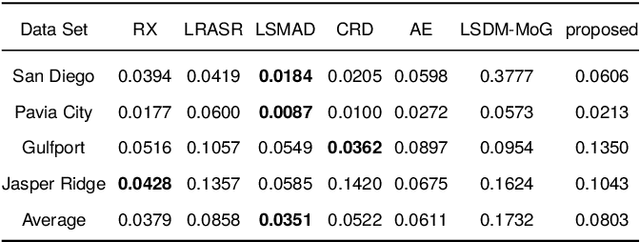
In recent years, neural network-based anomaly detection methods have attracted considerable attention in the hyperspectral remote sensing domain due to the powerful reconstruction ability compared with traditional methods. However, actual probability distribution statistics hidden in the latent space are not discovered by exploiting the reconstruction error because the probability distribution of anomalies is not explicitly modeled. To address the issue, we propose a novel probability distribution representation detector (PDRD) that explores the intrinsic distribution of both the background and the anomalies in original data for hyperspectral anomaly detection in this paper. First, we represent the hyperspectral data with multivariate Gaussian distributions from a probabilistic perspective. Then, we combine the local statistics with the obtained distributions to leverage the spatial information. Finally, the difference between the corresponding distributions of the test pixel and the average expectation of the pixels in the Chebyshev neighborhood is measured by computing the modified Wasserstein distance to acquire the detection map. We conduct the experiments on four real data sets to evaluate the performance of our proposed method. Experimental results demonstrate the accuracy and efficiency of our proposed method compared to the state-of-the-art detection methods.
Machine-learned 3D Building Vectorization from Satellite Imagery
Apr 13, 2021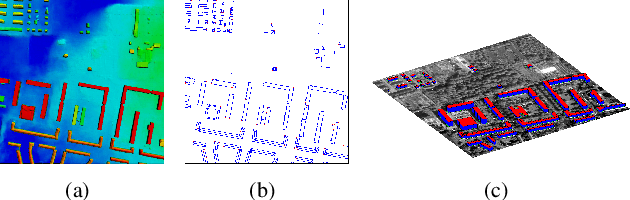
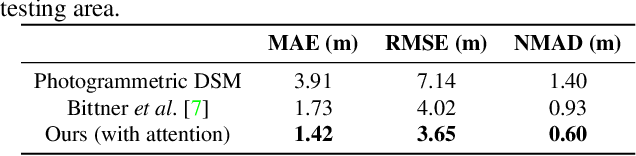
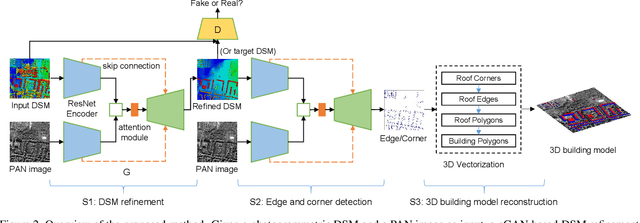
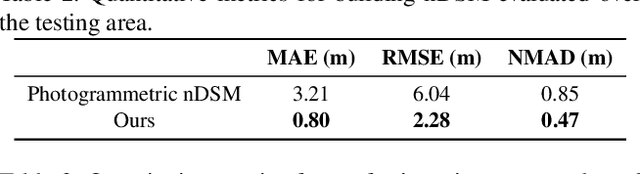
We propose a machine learning based approach for automatic 3D building reconstruction and vectorization. Taking a single-channel photogrammetric digital surface model (DSM) and panchromatic (PAN) image as input, we first filter out non-building objects and refine the building shapes of input DSM with a conditional generative adversarial network (cGAN). The refined DSM and the input PAN image are then used through a semantic segmentation network to detect edges and corners of building roofs. Later, a set of vectorization algorithms are proposed to build roof polygons. Finally, the height information from the refined DSM is added to the polygons to obtain a fully vectorized level of detail (LoD)-2 building model. We verify the effectiveness of our method on large-scale satellite images, where we obtain state-of-the-art performance.
High-level Features for Resource Economy and Fast Learning in Skill Transfer
Jun 18, 2021Abstraction is an important aspect of intelligence which enables agents to construct robust representations for effective decision making. In the last decade, deep networks are proven to be effective due to their ability to form increasingly complex abstractions. However, these abstractions are distributed over many neurons, making the re-use of a learned skill costly. Previous work either enforced formation of abstractions creating a designer bias, or used a large number of neural units without investigating how to obtain high-level features that may more effectively capture the source task. For avoiding designer bias and unsparing resource use, we propose to exploit neural response dynamics to form compact representations to use in skill transfer. For this, we consider two competing methods based on (1) maximum information compression principle and (2) the notion that abstract events tend to generate slowly changing signals, and apply them to the neural signals generated during task execution. To be concrete, in our simulation experiments, we either apply principal component analysis (PCA) or slow feature analysis (SFA) on the signals collected from the last hidden layer of a deep network while it performs a source task, and use these features for skill transfer in a new target task. We compare the generalization performance of these alternatives with the baselines of skill transfer with full layer output and no-transfer settings. Our results show that SFA units are the most successful for skill transfer. SFA as well as PCA, incur less resources compared to usual skill transfer, whereby many units formed show a localized response reflecting end-effector-obstacle-goal relations. Finally, SFA units with lowest eigenvalues resembles symbolic representations that highly correlate with high-level features such as joint angles which might be thought of precursors for fully symbolic systems.
Verification of Size Invariance in DNN Activations using Concept Embeddings
May 14, 2021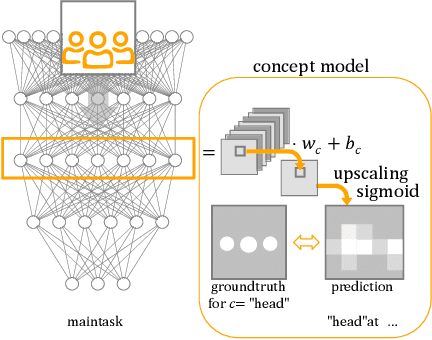
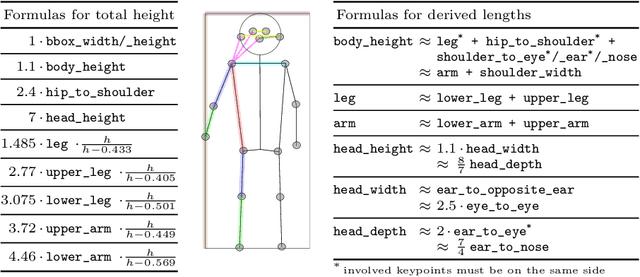
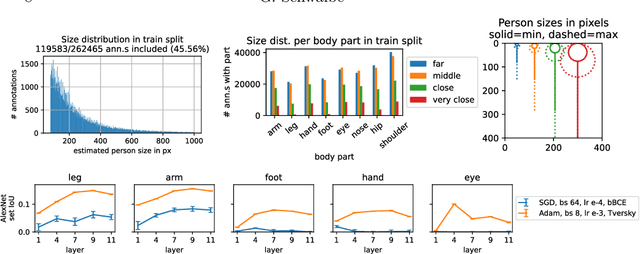
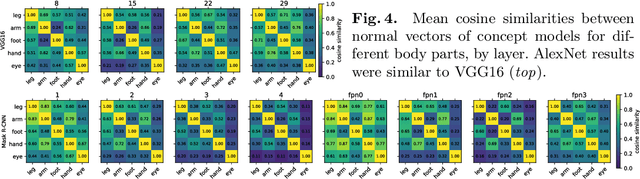
The benefits of deep neural networks (DNNs) have become of interest for safety critical applications like medical ones or automated driving. Here, however, quantitative insights into the DNN inner representations are mandatory. One approach to this is concept analysis, which aims to establish a mapping between the internal representation of a DNN and intuitive semantic concepts. Such can be sub-objects like human body parts that are valuable for validation of pedestrian detection. To our knowledge, concept analysis has not yet been applied to large object detectors, specifically not for sub-parts. Therefore, this work first suggests a substantially improved version of the Net2Vec approach (arXiv:1801.03454) for post-hoc segmentation of sub-objects. Its practical applicability is then demonstrated on a new concept dataset by two exemplary assessments of three standard networks, including the larger Mask R-CNN model (arXiv:1703.06870): (1) the consistency of body part similarity, and (2) the invariance of internal representations of body parts with respect to the size in pixels of the depicted person. The findings show that the representation of body parts is mostly size invariant, which may suggest an early intelligent fusion of information in different size categories.
Semi-supervised Optimal Transport with Self-paced Ensemble for Cross-hospital Sepsis Early Detection
Jun 18, 2021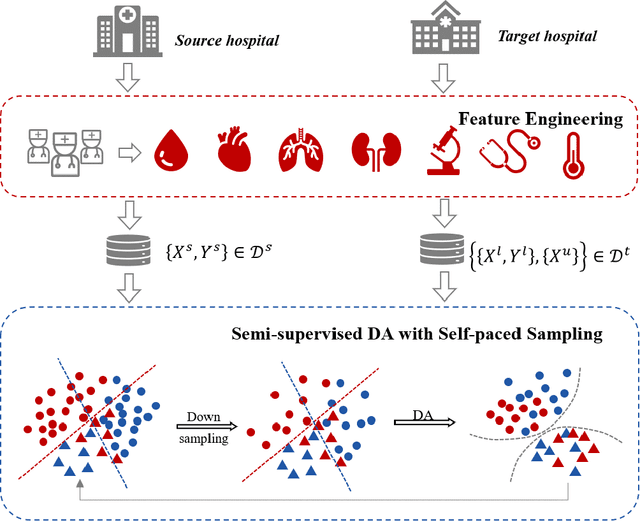


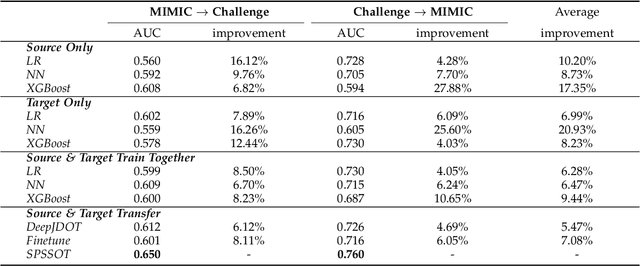
The utilization of computer technology to solve problems in medical scenarios has attracted considerable attention in recent years, which still has great potential and space for exploration. Among them, machine learning has been widely used in the prediction, diagnosis and even treatment of Sepsis. However, state-of-the-art methods require large amounts of labeled medical data for supervised learning. In real-world applications, the lack of labeled data will cause enormous obstacles if one hospital wants to deploy a new Sepsis detection system. Different from the supervised learning setting, we need to use known information (e.g., from another hospital with rich labeled data) to help build a model with acceptable performance, i.e., transfer learning. In this paper, we propose a semi-supervised optimal transport with self-paced ensemble framework for Sepsis early detection, called SPSSOT, to transfer knowledge from the other that has rich labeled data. In SPSSOT, we first extract the same clinical indicators from the source domain (e.g., hospital with rich labeled data) and the target domain (e.g., hospital with little labeled data), then we combine the semi-supervised domain adaptation based on optimal transport theory with self-paced under-sampling to avoid a negative transfer possibly caused by covariate shift and class imbalance. On the whole, SPSSOT is an end-to-end transfer learning method for Sepsis early detection which can automatically select suitable samples from two domains respectively according to the number of iterations and align feature space of two domains. Extensive experiments on two open clinical datasets demonstrate that comparing with other methods, our proposed SPSSOT, can significantly improve the AUC values with only 1% labeled data in the target domain in two transfer learning scenarios, MIMIC $rightarrow$ Challenge and Challenge $rightarrow$ MIMIC.
HindSight: A Graph-Based Vision Model Architecture For Representing Part-Whole Hierarchies
Apr 08, 2021
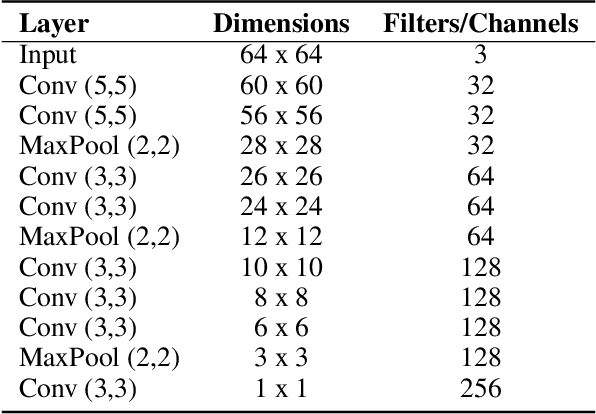
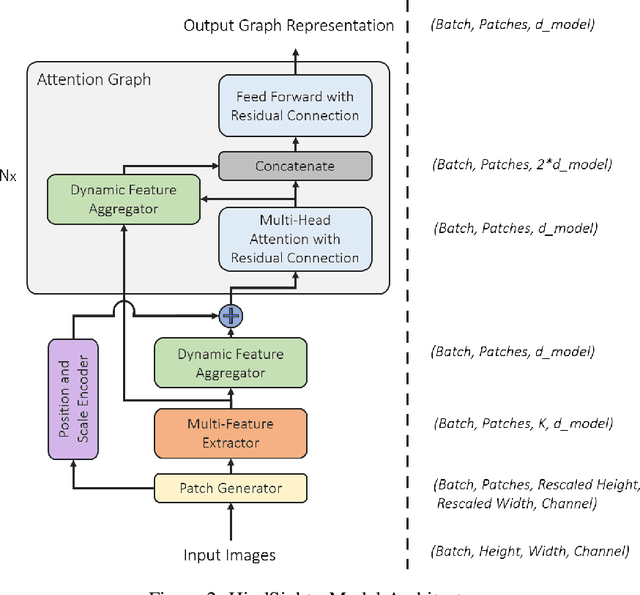

This paper presents a model architecture for encoding the representations of part-whole hierarchies in images in form of a graph. The idea is to divide the image into patches of different levels and then treat all of these patches as nodes for a fully connected graph. A dynamic feature extraction module is used to extract feature representations from these patches in each graph iteration. This enables us to learn a rich graph representation of the image that encompasses the inherent part-whole hierarchical information. Utilizing proper self-supervised training techniques, such a model can be trained as a general purpose vision encoder model which can then be used for various vision related downstream tasks (e.g., Image Classification, Object Detection, Image Captioning, etc.).