 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cascade Image Matting with Deformable Graph Refinement
May 06, 2021
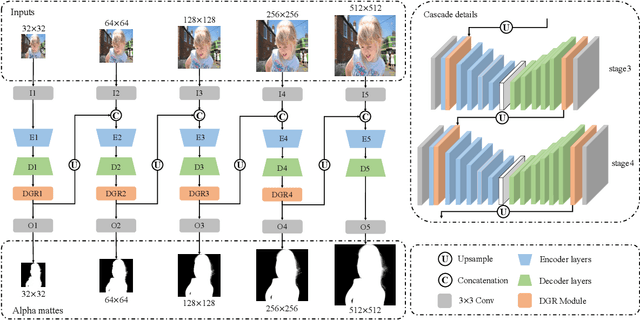
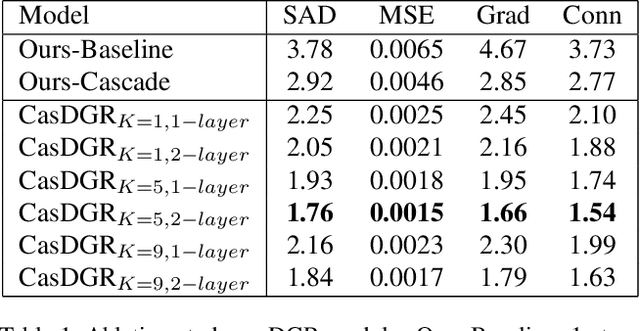
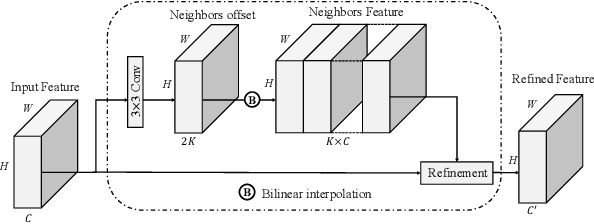
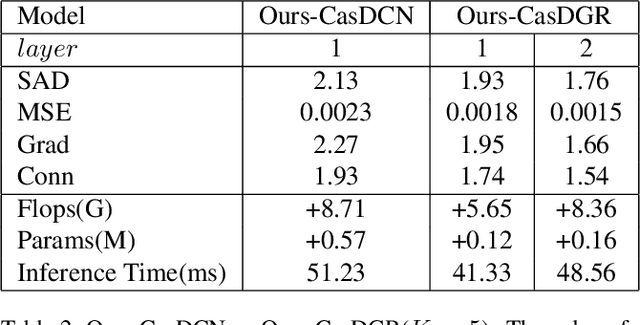
Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.
Knodle: Modular Weakly Supervised Learning with PyTorch
Apr 23, 2021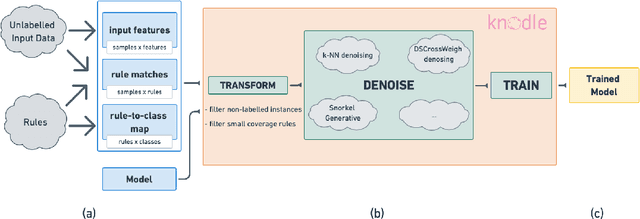

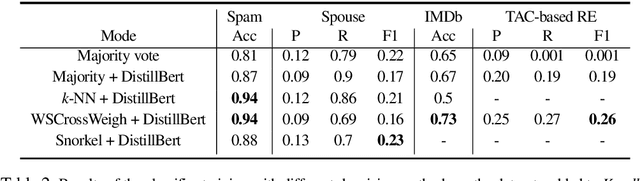
Methods for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task, or integrated with a specific model architecture. In this work, we propose a software framework Knodle that provides a modularization for separating weak data annotations, powerful deep learning models, and methods for improving weakly supervised training. This modularization gives the training process access to fine-grained information such as data set characteristics, matches of heuristic rules, or elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at the correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those methods that harness the interplay of neural networks and weakly labeled data.
Self-supervised Representation Learning with Relative Predictive Coding
Mar 28, 2021
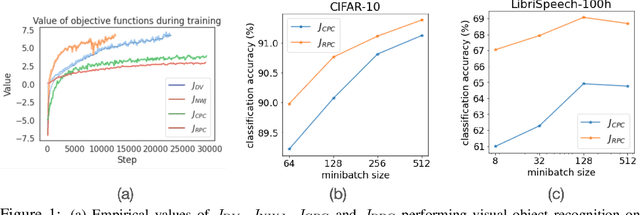
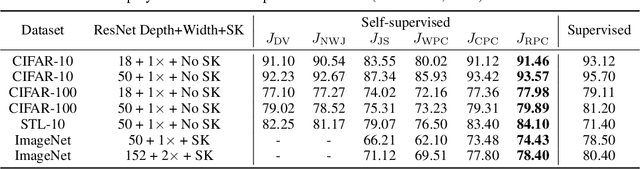
This paper introduces Relative Predictive Coding (RPC), a new contrastive representation learning objective that maintains a good balance among training stability, minibatch size sensitivity, and downstream task performance. The key to the success of RPC is two-fold. First, RPC introduces the relative parameters to regularize the objective for boundedness and low variance. Second, RPC contains no logarithm and exponential score functions, which are the main cause of training instability in prior contrastive objectives. We empirically verify the effectiveness of RPC on benchmark vision and speech self-supervised learning tasks. Lastly, we relate RPC with mutual information (MI) estimation, showing RPC can be used to estimate MI with low variance.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021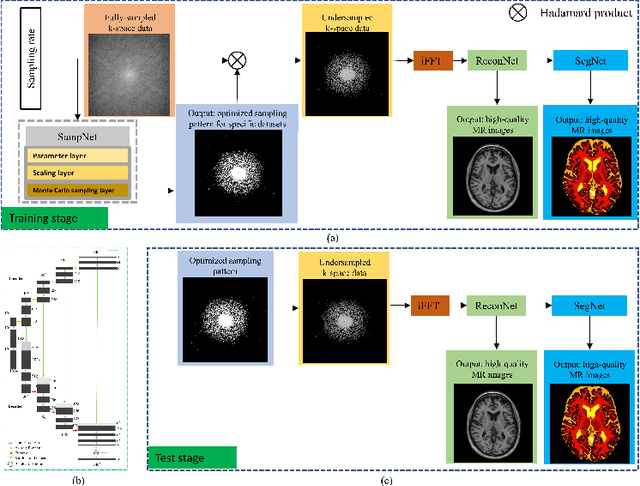
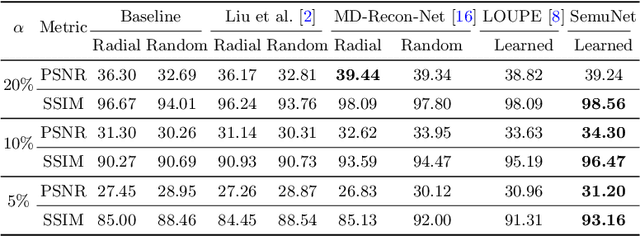
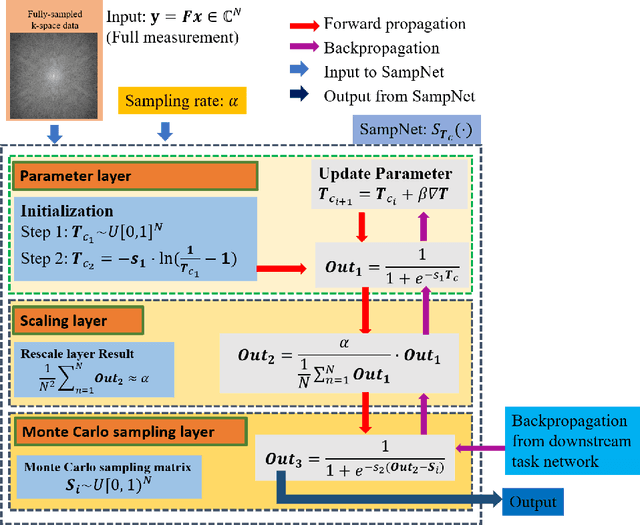
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.
Informative Gene Selection for Microarray Classification via Adaptive Elastic Net with Conditional Mutual Information
Jun 13, 2018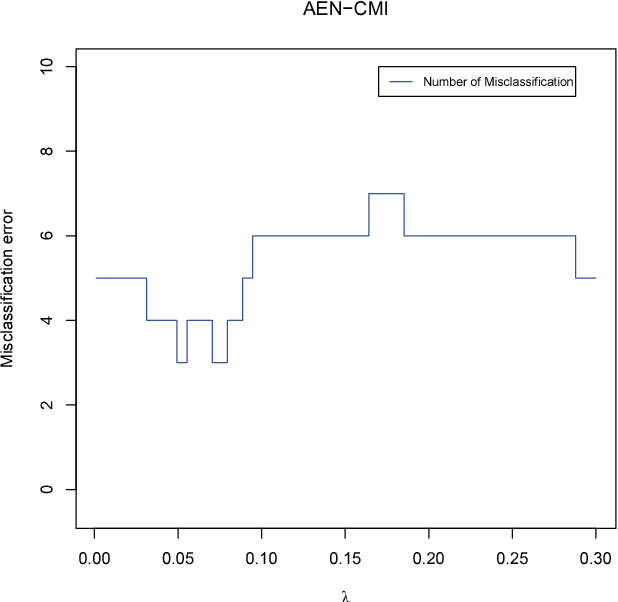

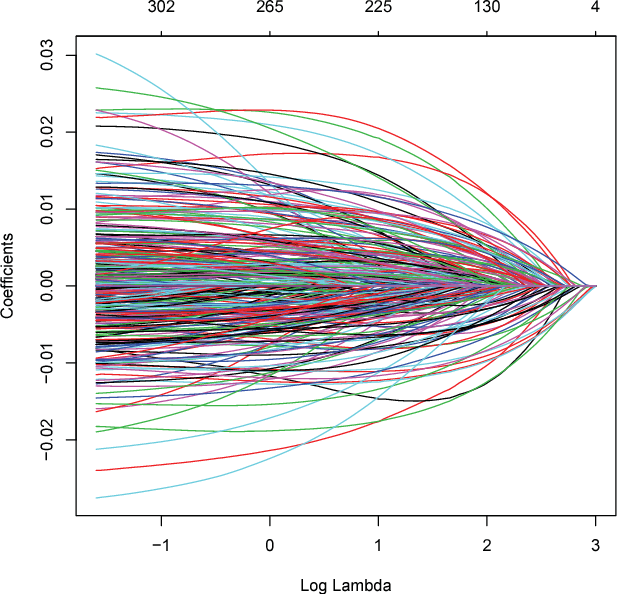

Due to the advantage of achieving a better performance under weak regularization, elastic net has attracted wide attention in statistics, machine learning, bioinformatics, and other fields. In particular, a variation of the elastic net, adaptive elastic net (AEN), integrates the adaptive grouping effect. In this paper, we aim to develop a new algorithm: Adaptive Elastic Net with Conditional Mutual Information (AEN-CMI) that further improves AEN by incorporating conditional mutual information into the gene selection process. We apply this new algorithm to screen significant genes for two kinds of cancers: colon cancer and leukemia. Compared with other algorithms including Support Vector Machine, Classic Elastic Net and Adaptive Elastic Net, the proposed algorithm, AEN-CMI, obtains the best classification performance using the least number of genes.
Local Relation Learning for Face Forgery Detection
May 06, 2021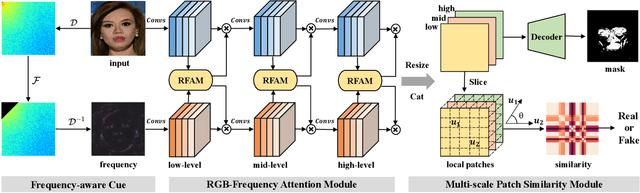
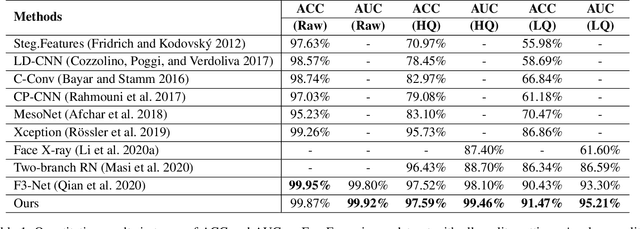
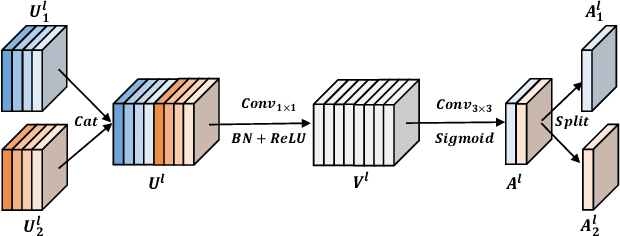
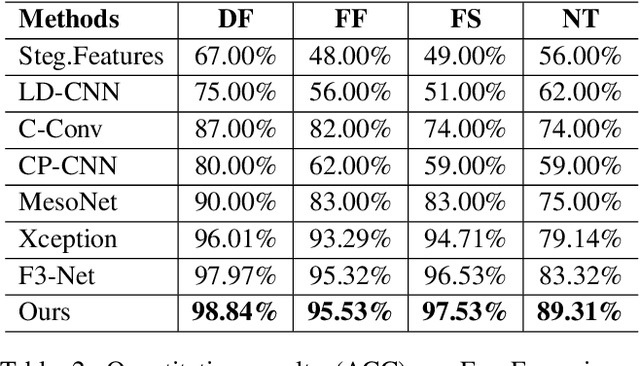
With the rapid development of facial manipulation techniques, face forgery detection has received considerable attention in digital media forensics due to security concerns. Most existing methods formulate face forgery detection as a classification problem and utilize binary labels or manipulated region masks as supervision. However, without considering the correlation between local regions, these global supervisions are insufficient to learn a generalized feature and prone to overfitting. To address this issue, we propose a novel perspective of face forgery detection via local relation learning. Specifically, we propose a Multi-scale Patch Similarity Module (MPSM), which measures the similarity between features of local regions and forms a robust and generalized similarity pattern. Moreover, we propose an RGB-Frequency Attention Module (RFAM) to fuse information in both RGB and frequency domains for more comprehensive local feature representation, which further improves the reliability of the similarity pattern. Extensive experiments show that the proposed method consistently outperforms the state-of-the-arts on widely-used benchmarks. Furthermore, detailed visualization shows the robustness and interpretability of our method.
GaitSet: Cross-view Gait Recognition through Utilizing Gait as a Deep Set
Feb 05, 2021
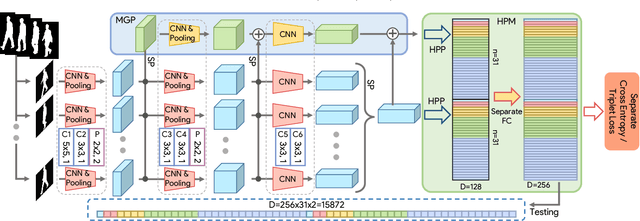
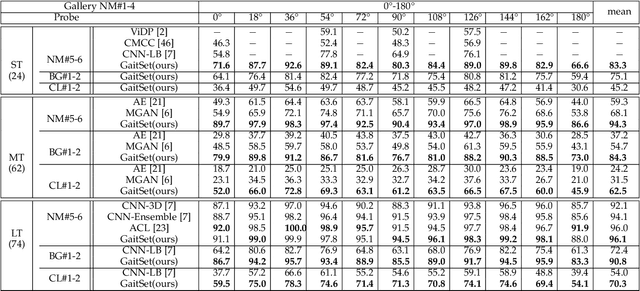
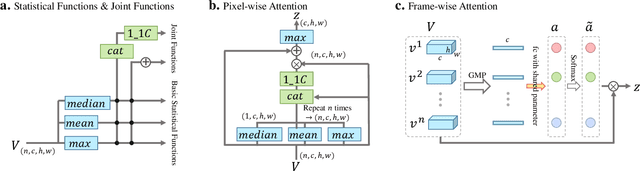
Gait is a unique biometric feature that can be recognized at a distance; thus, it has broad applications in crime prevention, forensic identification, and social security. To portray a gait, existing gait recognition methods utilize either a gait template which makes it difficult to preserve temporal information, or a gait sequence that maintains unnecessary sequential constraints and thus loses the flexibility of gait recognition. In this paper, we present a novel perspective that utilizes gait as a deep set, which means that a set of gait frames are integrated by a global-local fused deep network inspired by the way our left- and right-hemisphere processes information to learn information that can be used in identification. Based on this deep set perspective, our method is immune to frame permutations, and can naturally integrate frames from different videos that have been acquired under different scenarios, such as diverse viewing angles, different clothes, or different item-carrying conditions. Experiments show that under normal walking conditions, our single-model method achieves an average rank-1 accuracy of 96.1% on the CASIA-B gait dataset and an accuracy of 87.9% on the OU-MVLP gait dataset. Under various complex scenarios, our model also exhibits a high level of robustness. It achieves accuracies of 90.8% and 70.3% on CASIA-B under bag-carrying and coat-wearing walking conditions respectively, significantly outperforming the best existing methods. Moreover, the proposed method maintains a satisfactory accuracy even when only small numbers of frames are available in the test samples; for example, it achieves 85.0% on CASIA-B even when using only 7 frames. The source code has been released at https://github.com/AbnerHqC/GaitSet.
SGG: Learning to Select, Guide, and Generate for Keyphrase Generation
May 06, 2021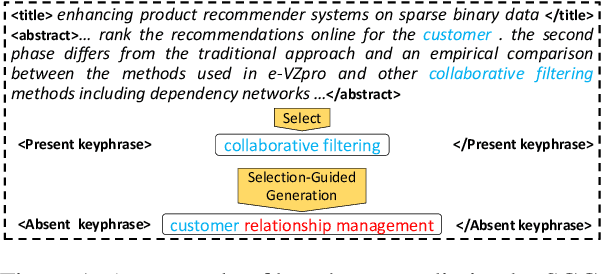
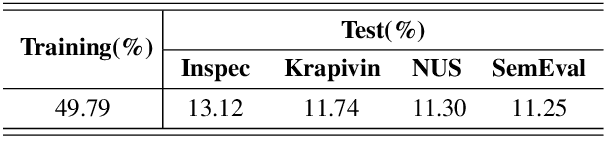
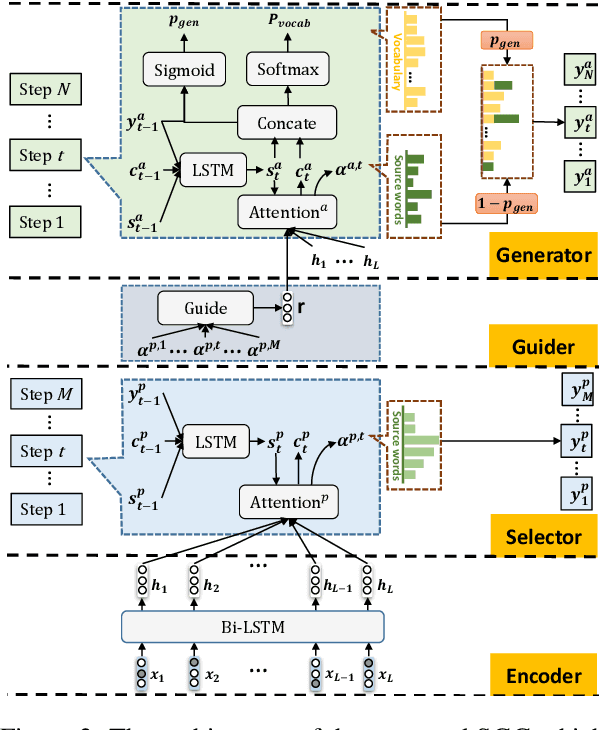
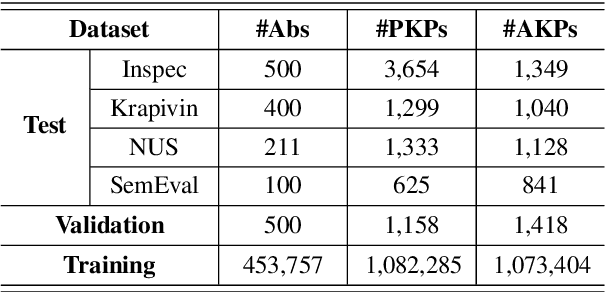
Keyphrases, that concisely summarize the high-level topics discussed in a document, can be categorized into present keyphrase which explicitly appears in the source text, and absent keyphrase which does not match any contiguous subsequence but is highly semantically related to the source. Most existing keyphrase generation approaches synchronously generate present and absent keyphrases without explicitly distinguishing these two categories. In this paper, a Select-Guide-Generate (SGG) approach is proposed to deal with present and absent keyphrase generation separately with different mechanisms. Specifically, SGG is a hierarchical neural network which consists of a pointing-based selector at low layer concentrated on present keyphrase generation, a selection-guided generator at high layer dedicated to absent keyphrase generation, and a guider in the middle to transfer information from selector to generator. Experimental results on four keyphrase generation benchmarks demonstrate the effectiveness of our model, which significantly outperforms the strong baselines for both present and absent keyphrases generation. Furthermore, we extend SGG to a title generation task which indicates its extensibility in natural language generation tasks.
Deep Two-Stage High-Resolution Image Inpainting
Apr 27, 2021
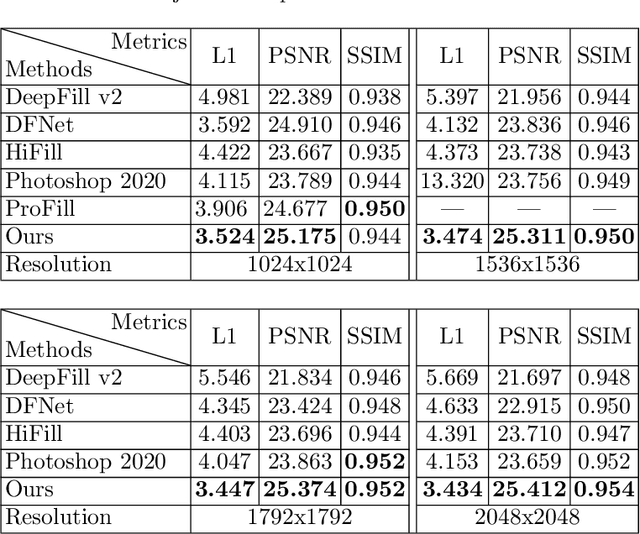
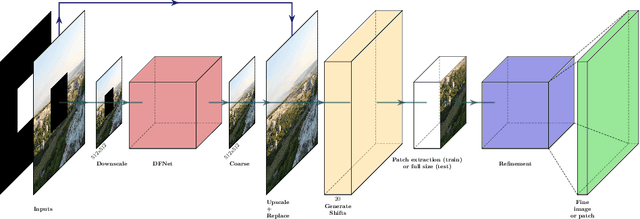
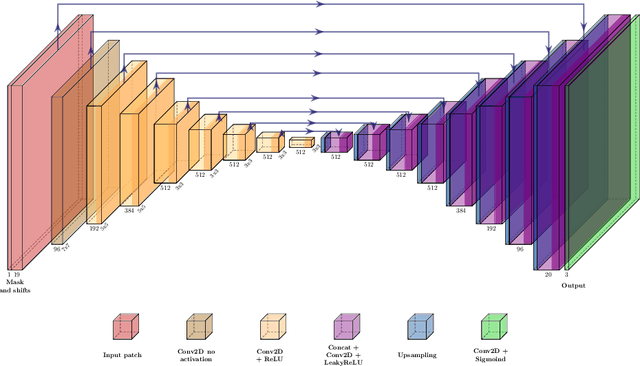
In recent years, the field of image inpainting has developed rapidly, learning based approaches show impressive results in the task of filling missing parts in an image. But most deep methods are strongly tied to the resolution of the images on which they were trained. A slight resolution increase leads to serious artifacts and unsatisfactory filling quality. These methods are therefore unsuitable for interactive image processing. In this article, we propose a method that solves the problem of inpainting arbitrary-size images. We also describe a way to better restore texture fragments in the filled area. For this, we propose to use information from neighboring pixels by shifting the original image in four directions. Moreover, this approach can work with existing inpainting models, making them almost resolution independent without the need for retraining. We also created a GIMP plugin that implements our technique. The plugin, code, and model weights are available at https://github.com/a-mos/High_Resolution_Image_Inpainting.
Point Cloud Audio Processing
May 06, 2021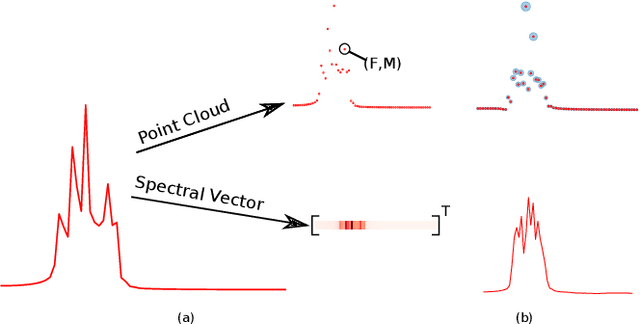
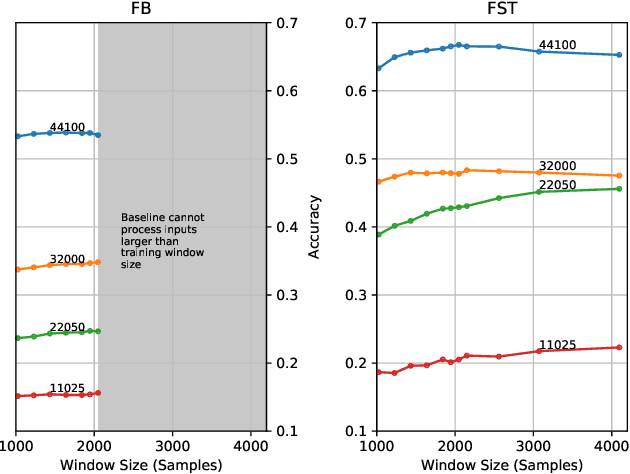
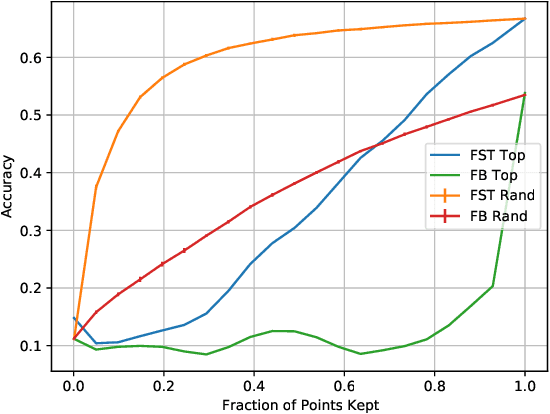
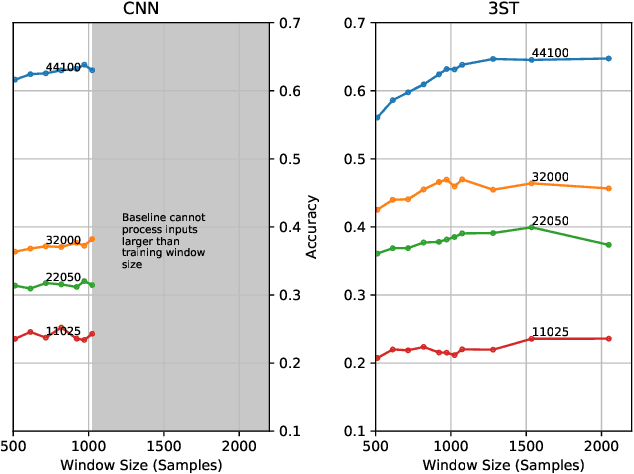
Most audio processing pipelines involve transformations that act on fixed-dimensional input representations of audio. For example, when using the Short Time Fourier Transform (STFT) the DFT size specifies a fixed dimension for the input representation. As a consequence, most audio machine learning models are designed to process fixed-size vector inputs which often prohibits the repurposing of learned models on audio with different sampling rates or alternative representations. We note, however, that the intrinsic spectral information in the audio signal is invariant to the choice of the input representation or the sampling rate. Motivated by this, we introduce a novel way of processing audio signals by treating them as a collection of points in feature space, and we use point cloud machine learning models that give us invariance to the choice of representation parameters, such as DFT size or the sampling rate. Additionally, we observe that these methods result in smaller models, and allow us to significantly subsample the input representation with minimal effects to a trained model performance.