 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed support-vector-machine over dynamic balanced directed networks
Apr 01, 2021



In this paper, we consider the binary classification problem via distributed Support-Vector-Machines (SVM), where the idea is to train a network of agents, with limited share of data, to cooperatively learn the SVM classifier for the global database. Agents only share processed information regarding the classifier parameters and the gradient of the local loss functions instead of their raw data. In contrast to the existing work, we propose a continuous-time algorithm that incorporates network topology changes in discrete jumps. This hybrid nature allows us to remove chattering that arises because of the discretization of the underlying CT process. We show that the proposed algorithm converges to the SVM classifier over time-varying weight balanced directed graphs by using arguments from the matrix perturbation theory.
Back to the Basics: A Quantitative Analysis of Statistical and Graph-Based Term Weighting Schemes for Keyword Extraction
Apr 16, 2021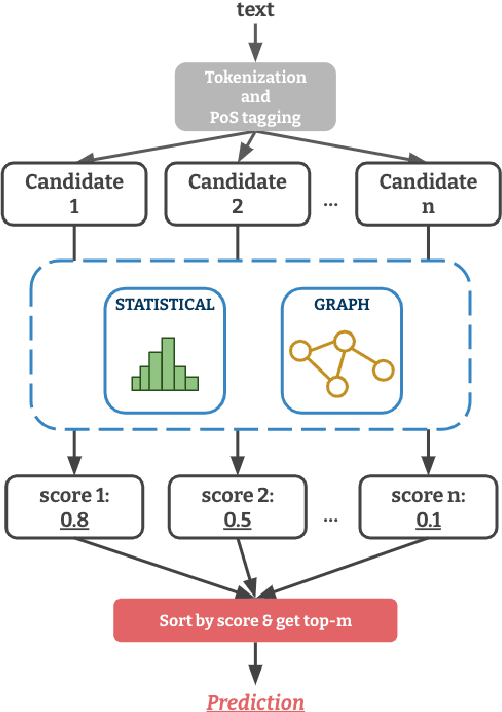
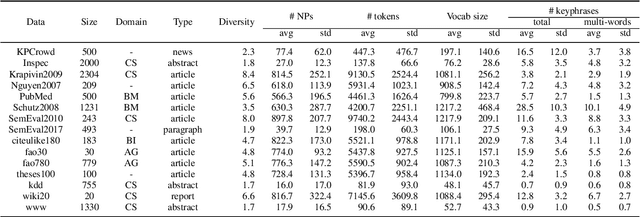
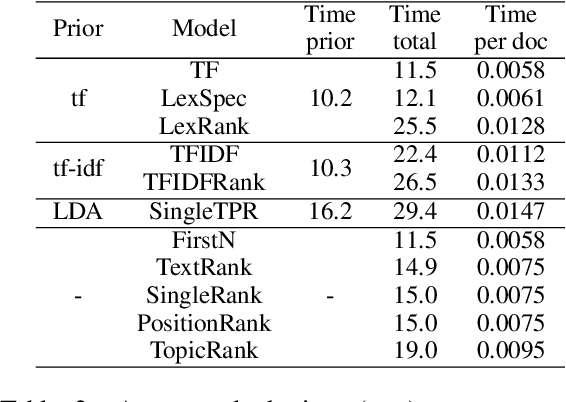
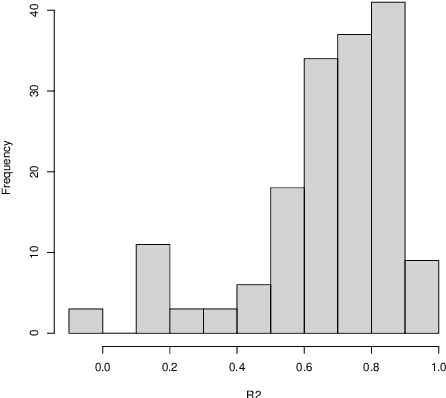
Term weighting schemes are widely used in Natural Language Processing and Information Retrieval. In particular, term weighting is the basis for keyword extraction. However, there are relatively few evaluation studies that shed light about the strengths and shortcomings of each weighting scheme. In fact, in most cases researchers and practitioners resort to the well-known tf-idf as default, despite the existence of other suitable alternatives, including graph-based models. In this paper, we perform an exhaustive and large-scale empirical comparison of both statistical and graph-based term weighting methods in the context of keyword extraction. Our analysis reveals some interesting findings such as the advantages of the less-known lexical specificity with respect to tf-idf, or the qualitative differences between statistical and graph-based methods. Finally, based on our findings we discuss and devise some suggestions for practitioners. We release our code at https://github.com/asahi417/kex .
DaLAJ - a dataset for linguistic acceptability judgments for Swedish: Format, baseline, sharing
May 14, 2021

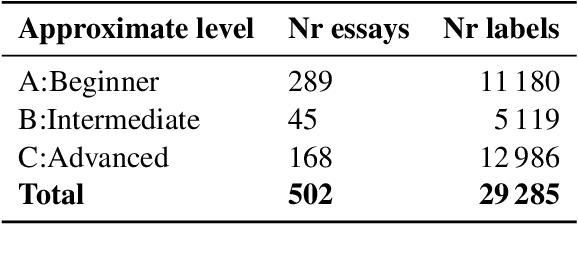
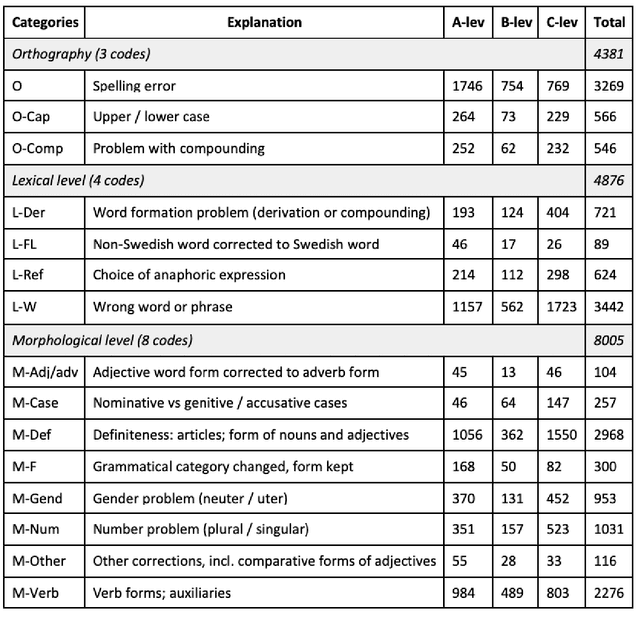
We present DaLAJ 1.0, a Dataset for Linguistic Acceptability Judgments for Swedish, comprising 9 596 sentences in its first version; and the initial experiment using it for the binary classification task. DaLAJ is based on the SweLL second language learner data, consisting of essays at different levels of proficiency. To make sure the dataset can be freely available despite the GDPR regulations, we have sentence-scrambled learner essays and removed part of the metadata about learners, keeping for each sentence only information about the mother tongue and the level of the course where the essay has been written. We use the normalized version of learner language as the basis for the DaLAJ sentences, and keep only one error per sentence. We repeat the same sentence for each individual correction tag used in the sentence. For DaLAJ 1.0 we have used four error categories (out of 35 available in SweLL), all connected to lexical or word-building choices. Our baseline results for the binary classification show an accuracy of 58% for DaLAJ 1.0 using BERT embeddings. The dataset is included in the SwedishGlue (Swe. SuperLim) benchmark. Below, we describe the format of the dataset, first experiments, our insights and the motivation for the chosen approach to data sharing.
Saliency-Aware Class-Agnostic Food Image Segmentation
Feb 13, 2021
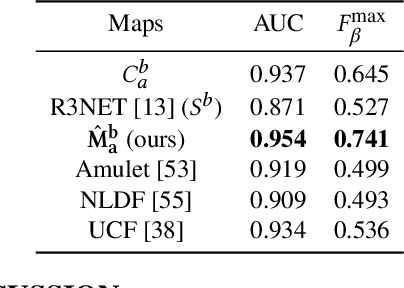
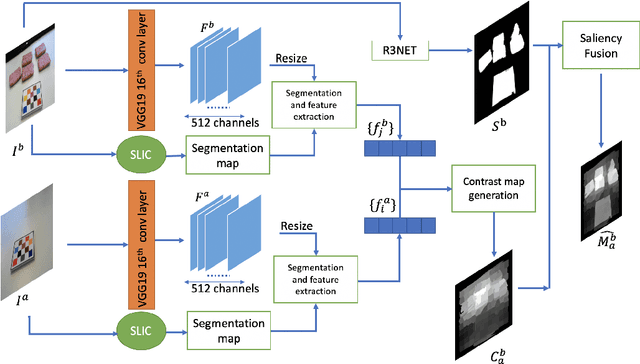
Advances in image-based dietary assessment methods have allowed nutrition professionals and researchers to improve the accuracy of dietary assessment, where images of food consumed are captured using smartphones or wearable devices. These images are then analyzed using computer vision methods to estimate energy and nutrition content of the foods. Food image segmentation, which determines the regions in an image where foods are located, plays an important role in this process. Current methods are data dependent, thus cannot generalize well for different food types. To address this problem, we propose a class-agnostic food image segmentation method. Our method uses a pair of eating scene images, one before start eating and one after eating is completed. Using information from both the before and after eating images, we can segment food images by finding the salient missing objects without any prior information about the food class. We model a paradigm of top down saliency which guides the attention of the human visual system (HVS) based on a task to find the salient missing objects in a pair of images. Our method is validated on food images collected from a dietary study which showed promising results.
Are GAN generated images easy to detect? A critical analysis of the state-of-the-art
Apr 06, 2021
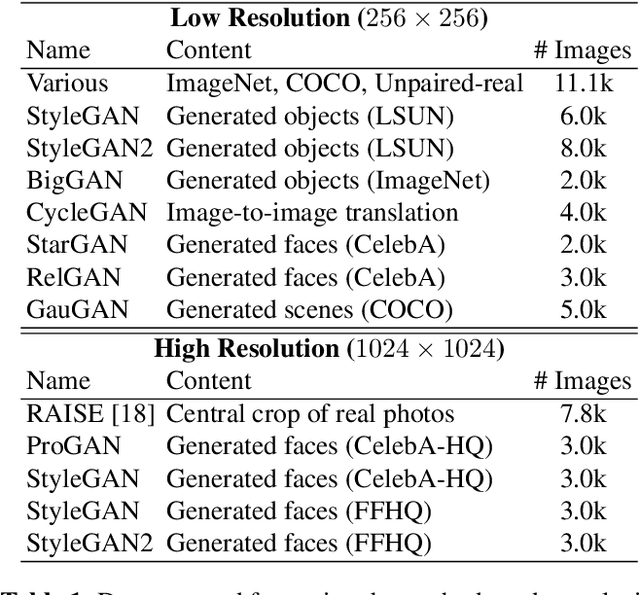

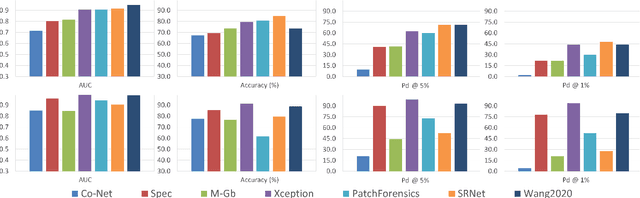
The advent of deep learning has brought a significant improvement in the quality of generated media. However, with the increased level of photorealism, synthetic media are becoming hardly distinguishable from real ones, raising serious concerns about the spread of fake or manipulated information over the Internet. In this context, it is important to develop automated tools to reliably and timely detect synthetic media. In this work, we analyze the state-of-the-art methods for the detection of synthetic images, highlighting the key ingredients of the most successful approaches, and comparing their performance over existing generative architectures. We will devote special attention to realistic and challenging scenarios, like media uploaded on social networks or generated by new and unseen architectures, analyzing the impact of suitable augmentation and training strategies on the detectors' generalization ability.
Evaluating Actuators in a Purely Information-Theory Based Reward Model
Apr 10, 2018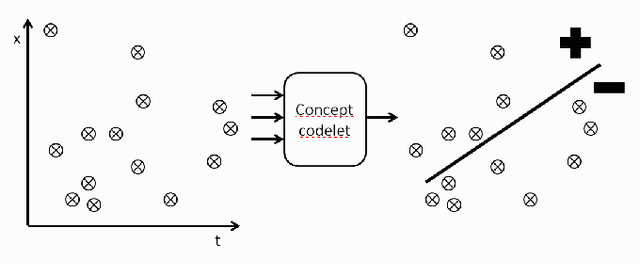
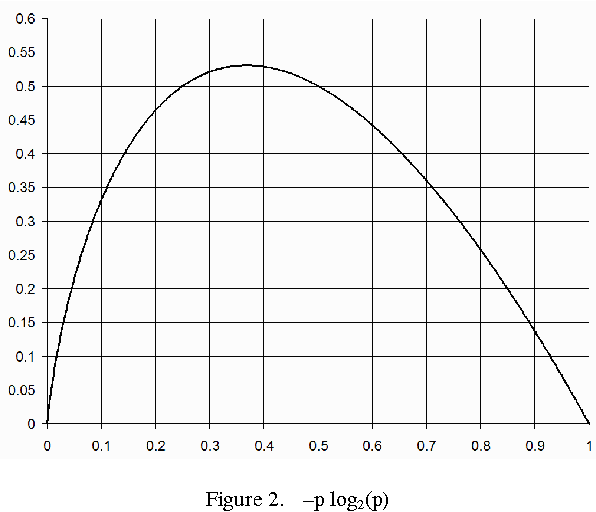
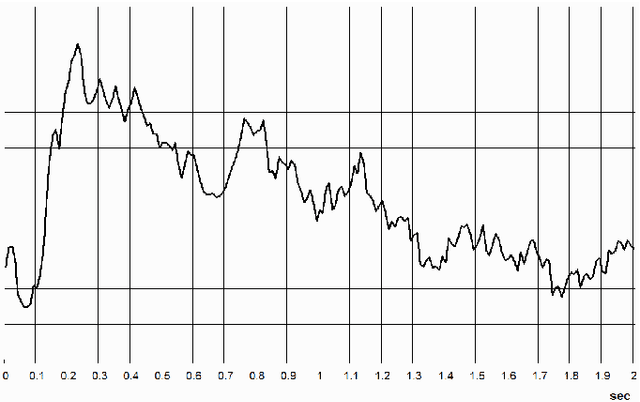
AGINAO builds its cognitive engine by applying self-programming techniques to create a hierarchy of interconnected codelets - the tiny pieces of code executed on a virtual machine. These basic processing units are evaluated for their applicability and fitness with a notion of reward calculated from self-information gain of binary partitioning of the codelet's input state-space. This approach, however, is useless for the evaluation of actuators. Instead, a model is proposed in which actuators are evaluated by measuring the impact that an activation of an effector, and consequently the feedback from the robot sensors, has on average reward received by the processing units.
* IEEE SSCI 2013, Singapore
Hybrid Device-to-Device and Device-to-Vehicle Networks for Energy-Efficient Emergency Communication
May 14, 2021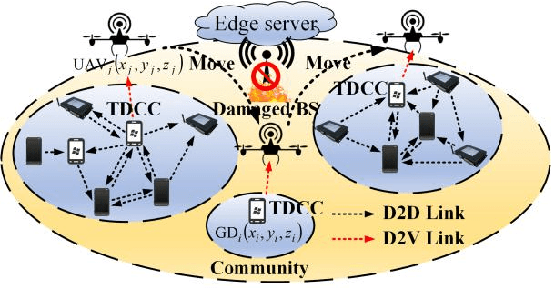

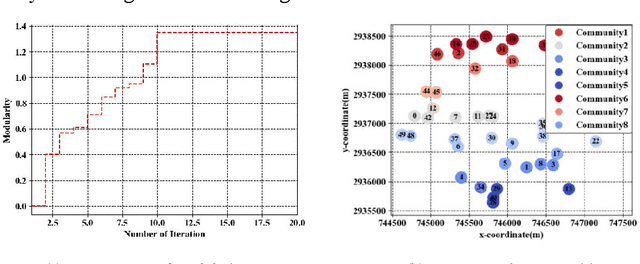

Considering the energy-efficient emergency response, subject to a given set of constraints on emergency communication networks (ECN), this article proposes a hybrid device-to-device (D2D) and device-to-vehicle (D2V) network for collecting and transmitting emergency information. First, we establish the D2D network from the perspective of complex networks by jointly determining the optimal network partition (ONP) and the temporary data caching centers (TDCC), and thus emergency data can be forwarded and cached in TDCCs. Second, based on the distribution of TDCCs, the D2V network is established by unmanned aerial vehicles (UAV)-based waypoint and motion planning, which saves the time for wireless transmission and aerial moving. Finally, the amount of time for emergency response and the total energy consumption are simultaneously minimized by a multiobjective evolutionary algorithm based on decomposition (MOEA/D), subject to a given set of minimum signal-to-interference- plus-noise ratio (SINR), number of UAVs, transmit power, and energy constraints. Simulation results show that the proposed method significantly improves response efficiency and reasonably controls the energy, thus overcoming limitations of existing ECNs. Therefore, this network effectively solves the key problem in the rescue system and makes great contributions to post-disaster decision-making.
Multi-modal Sarcasm Detection and Humor Classification in Code-mixed Conversations
May 20, 2021
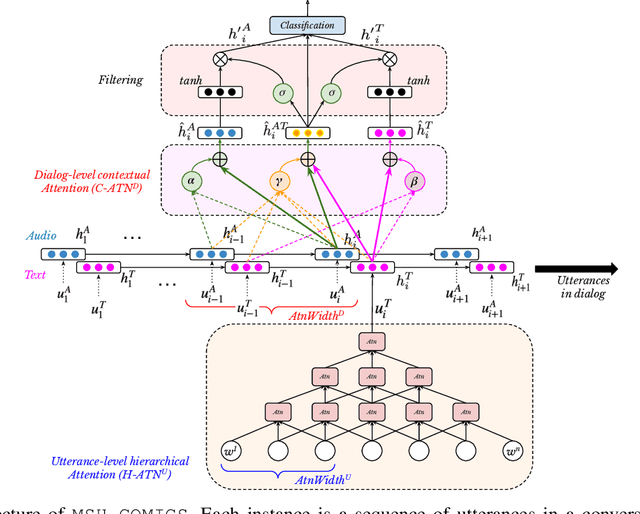


Sarcasm detection and humor classification are inherently subtle problems, primarily due to their dependence on the contextual and non-verbal information. Furthermore, existing studies in these two topics are usually constrained in non-English languages such as Hindi, due to the unavailability of qualitative annotated datasets. In this work, we make two major contributions considering the above limitations: (1) we develop a Hindi-English code-mixed dataset, MaSaC, for the multi-modal sarcasm detection and humor classification in conversational dialog, which to our knowledge is the first dataset of its kind; (2) we propose MSH-COMICS, a novel attention-rich neural architecture for the utterance classification. We learn efficient utterance representation utilizing a hierarchical attention mechanism that attends to a small portion of the input sentence at a time. Further, we incorporate dialog-level contextual attention mechanism to leverage the dialog history for the multi-modal classification. We perform extensive experiments for both the tasks by varying multi-modal inputs and various submodules of MSH-COMICS. We also conduct comparative analysis against existing approaches. We observe that MSH-COMICS attains superior performance over the existing models by > 1 F1-score point for the sarcasm detection and 10 F1-score points in humor classification. We diagnose our model and perform thorough analysis of the results to understand the superiority and pitfalls.
A Load Balanced Recommendation Approach
May 20, 2021
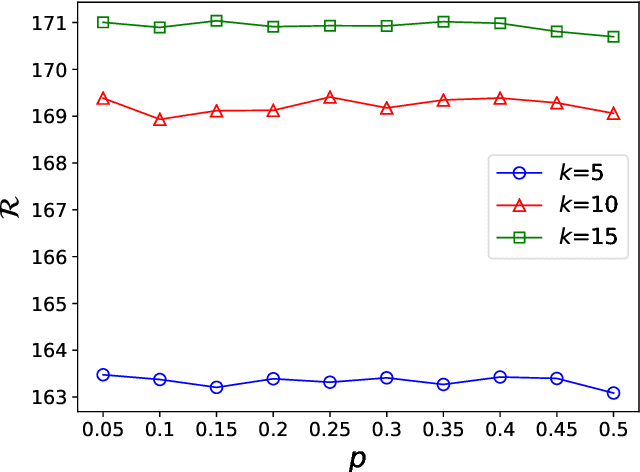
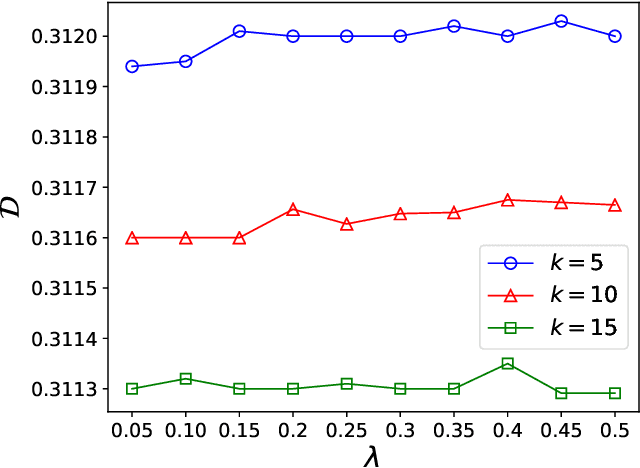
Recommender systems (RSs) are software tools and algorithms developed to alleviate the problem of information overload, which makes it difficult for a user to make right decisions. Two main paradigms toward the recommendation problem are collaborative filtering and content-based filtering, which try to recommend the best items using ratings and content available. These methods typically face infamous problems including cold-start, diversity, scalability, and great computational expense. We argue that the uptake of deep learning and reinforcement learning methods is also questionable due to their computational complexities and uninterpretability. In this paper, we approach the recommendation problem from a new prospective. We borrow ideas from cluster head selection algorithms in wireless sensor networks and adapt them to the recommendation problem. In particular, we propose Load Balanced Recommender System (LBRS), which uses a probabilistic scheme for item recommendation. Furthermore, we factor in the importance of items in the recommendation process, which significantly improves the recommendation accuracy. We also introduce a method that considers a heterogeneity among items, in order to balance the similarity and diversity trade-off. Finally, we propose a new metric for diversity, which emphasizes the importance of diversity not only from an intra-list perspective, but also from a between-list point of view. With experiments in a simulation study performed on RecSim, we show that LBRS is effective and can outperform baseline methods.
RadarScenes: A Real-World Radar Point Cloud Data Set for Automotive Applications
Apr 06, 2021
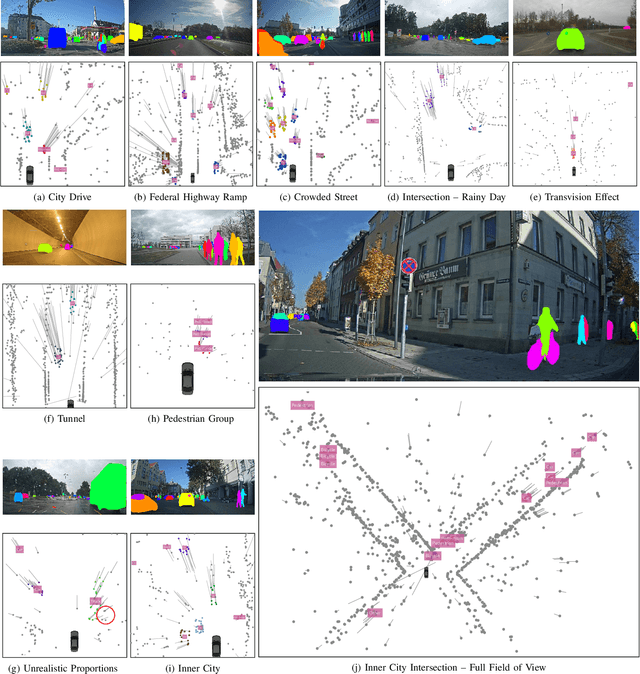
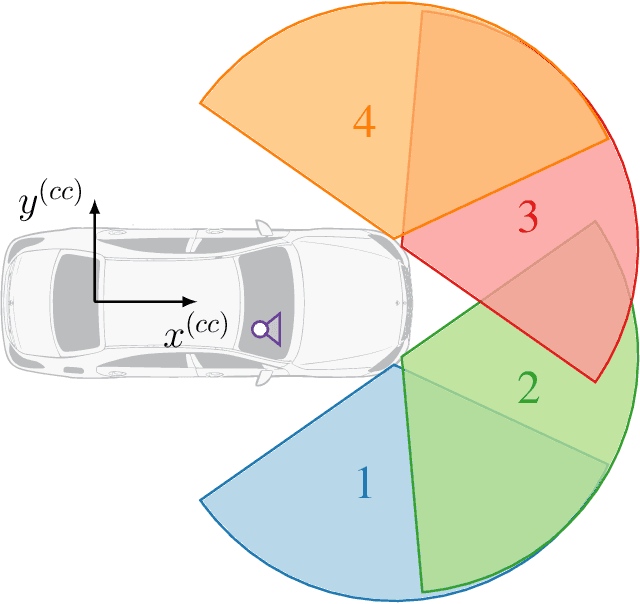
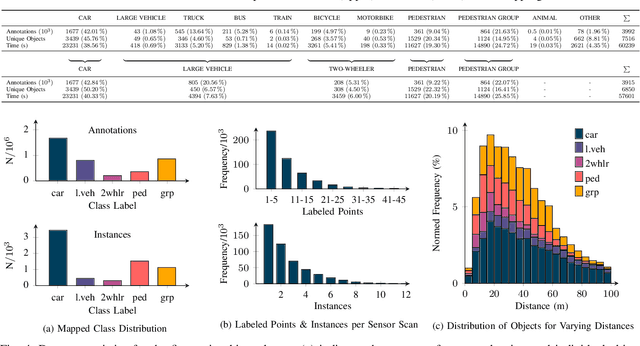
A new automotive radar data set with measurements and point-wise annotations from more than four hours of driving is presented. Data provided by four series radar sensors mounted on one test vehicle were recorded and the individual detections of dynamic objects were manually grouped to clusters and labeled afterwards. The purpose of this data set is to enable the development of novel (machine learning-based) radar perception algorithms with the focus on moving road users. Images of the recorded sequences were captured using a documentary camera. For the evaluation of future object detection and classification algorithms, proposals for score calculation are made so that researchers can evaluate their algorithms on a common basis. Additional information as well as download instructions can be found on the website of the data set: www.radar-scenes.com.