 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proceedings of the NeurIPS 2020 Workshop on Machine Learning for the Developing World: Improving Resilience
Jan 12, 2021
These are the proceedings of the 4th workshop on Machine Learning for the Developing World (ML4D), held as part of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS) on Saturday, December 12th 2020.
Surface Detection for Sketched Single Photon Lidar
May 14, 2021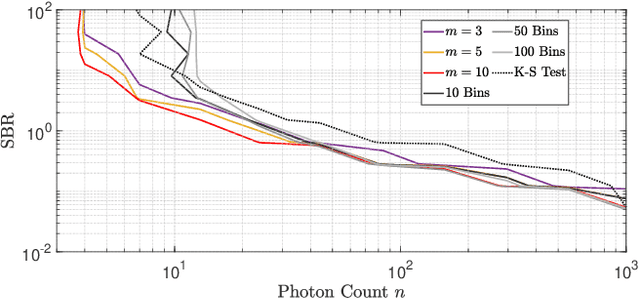
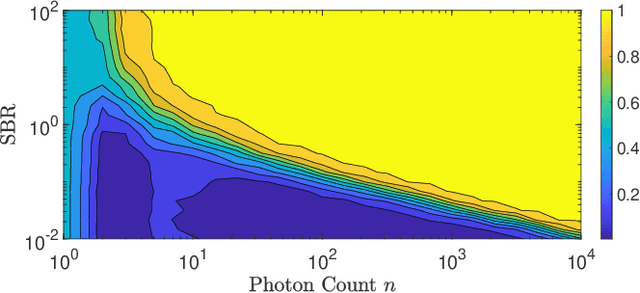
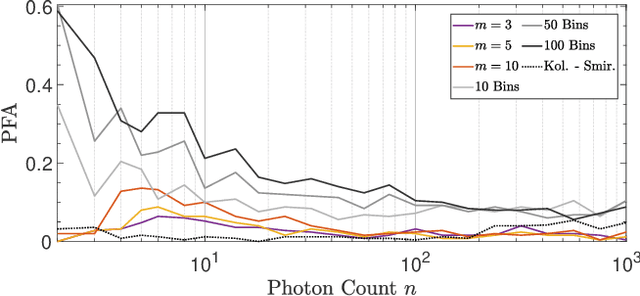

Single-photon lidar devices are able to collect an ever-increasing amount of time-stamped photons in small time periods due to increasingly larger arrays, generating a memory and computational bottleneck on the data processing side. Recently, a sketching technique was introduced to overcome this bottleneck which compresses the amount of information to be stored and processed. The size of the sketch scales with the number of underlying parameters of the time delay distribution and not, fundamentally, with either the number of detected photons or the time-stamp resolution. In this paper, we propose a detection algorithm based solely on a small sketch that determines if there are surfaces or objects in the scene or not. If a surface is detected, the depth and intensity of a single object can be computed in closed-form directly from the sketch. The computational load of the proposed detection algorithm depends solely on the size of the sketch, in contrast to previous algorithms that depend at least linearly in the number of collected photons or histogram bins, paving the way for fast, accurate and memory efficient lidar estimation. Our experiments demonstrate the memory and statistical efficiency of the proposed algorithm both on synthetic and real lidar datasets.
Saliency-Aware Class-Agnostic Food Image Segmentation
Feb 13, 2021
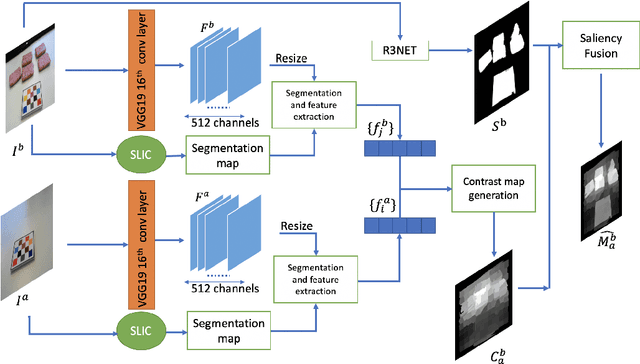
Advances in image-based dietary assessment methods have allowed nutrition professionals and researchers to improve the accuracy of dietary assessment, where images of food consumed are captured using smartphones or wearable devices. These images are then analyzed using computer vision methods to estimate energy and nutrition content of the foods. Food image segmentation, which determines the regions in an image where foods are located, plays an important role in this process. Current methods are data dependent, thus cannot generalize well for different food types. To address this problem, we propose a class-agnostic food image segmentation method. Our method uses a pair of eating scene images, one before start eating and one after eating is completed. Using information from both the before and after eating images, we can segment food images by finding the salient missing objects without any prior information about the food class. We model a paradigm of top down saliency which guides the attention of the human visual system (HVS) based on a task to find the salient missing objects in a pair of images. Our method is validated on food images collected from a dietary study which showed promising results.
Privacy-Preserving Constrained Domain Generalization for Medical Image Classification
May 14, 2021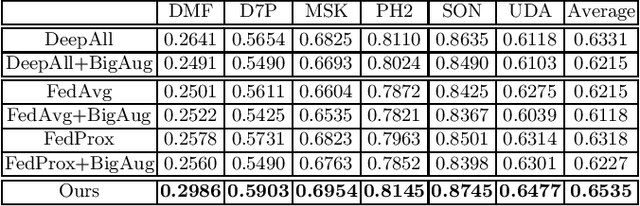
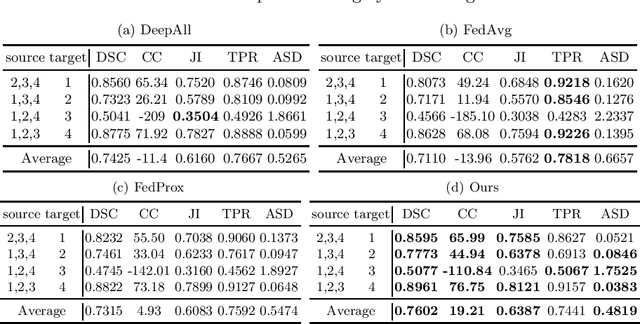
Deep neural networks (DNN) have demonstrated unprecedented success for medical imaging applications. However, due to the issue of limited dataset availability and the strict legal and ethical requirements for patient privacy protection, the broad applications of medical imaging classification driven by DNN with large-scale training data have been largely hindered. For example, when training the DNN from one domain (e.g., with data only from one hospital), the generalization capability to another domain (e.g., data from another hospital) could be largely lacking. In this paper, we aim to tackle this problem by developing the privacy-preserving constrained domain generalization method, aiming to improve the generalization capability under the privacy-preserving condition. In particular, We propose to improve the information aggregation process on the centralized server-side with a novel gradient alignment loss, expecting that the trained model can be better generalized to the "unseen" but related medical images. The rationale and effectiveness of our proposed method can be explained by connecting our proposed method with the Maximum Mean Discrepancy (MMD) which has been widely adopted as the distribution distance measurement. Experimental results on two challenging medical imaging classification tasks indicate that our method can achieve better cross-domain generalization capability compared to the state-of-the-art federated learning methods.
Semantic XAI for contextualized demand forecasting explanations
Apr 01, 2021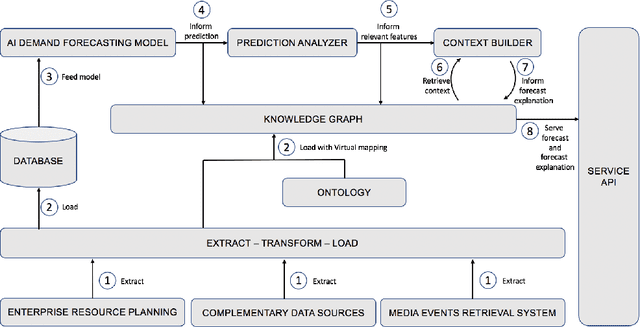
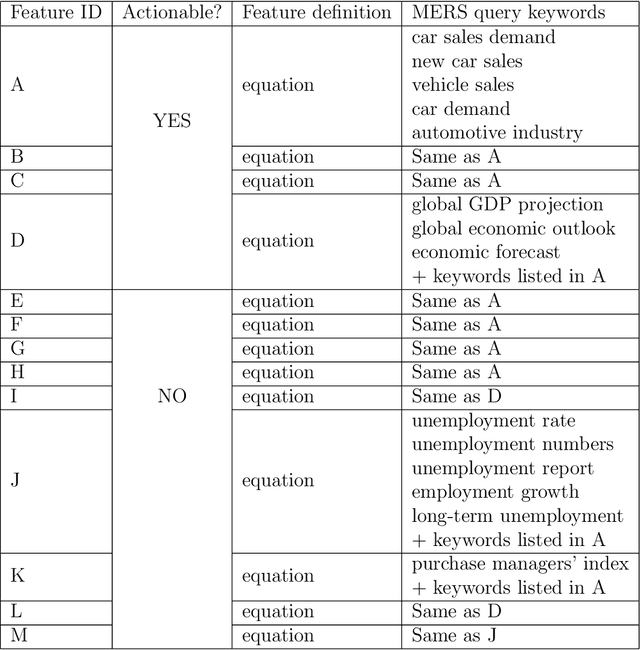
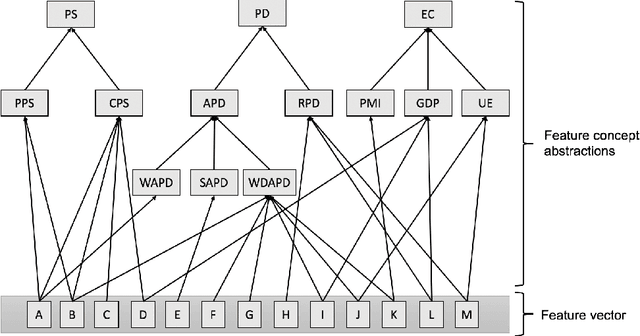
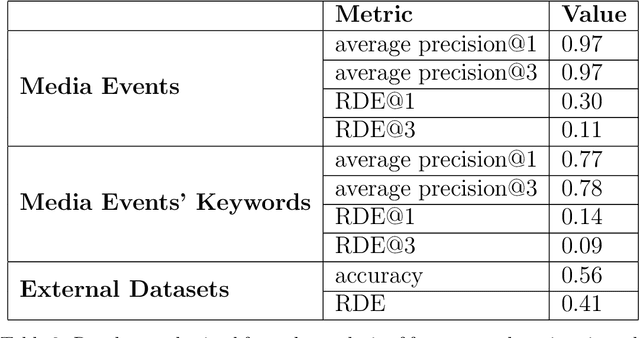
The paper proposes a novel architecture for explainable AI based on semantic technologies and AI. We tailor the architecture for the domain of demand forecasting and validate it on a real-world case study. The provided explanations combine concepts describing features relevant to a particular forecast, related media events, and metadata regarding external datasets of interest. The knowledge graph provides concepts that convey feature information at a higher abstraction level. By using them, explanations do not expose sensitive details regarding the demand forecasting models. The explanations also emphasize actionable dimensions where suitable. We link domain knowledge, forecasted values, and forecast explanations in a Knowledge Graph. The ontology and dataset we developed for this use case are publicly available for further research.
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 07, 2021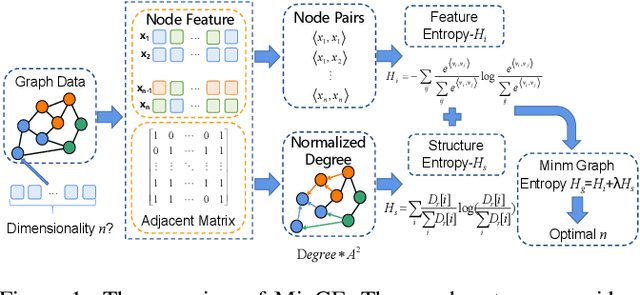
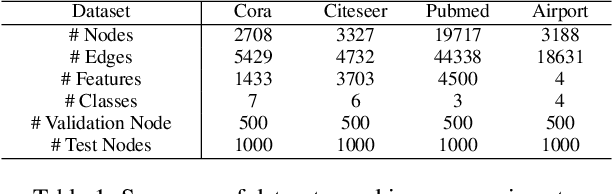
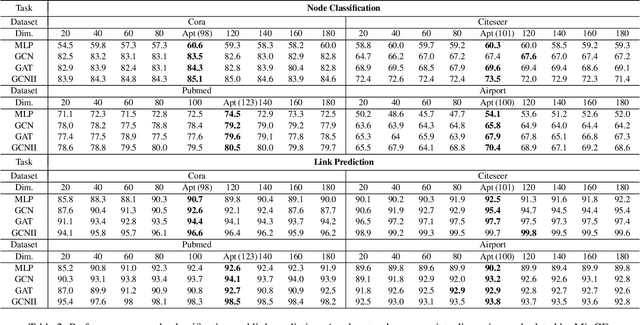
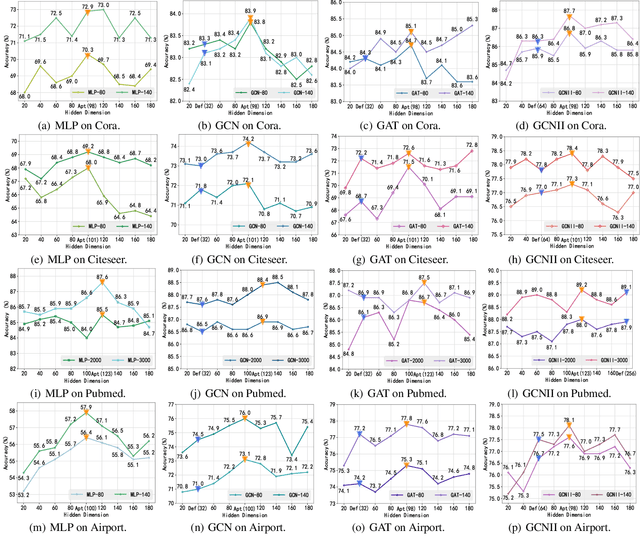
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
Balancing Suspense and Surprise: Timely Decision Making with Endogenous Information Acquisition
Oct 24, 2016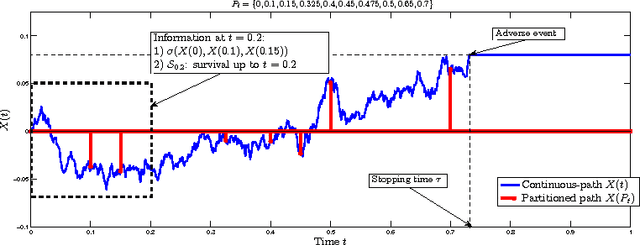
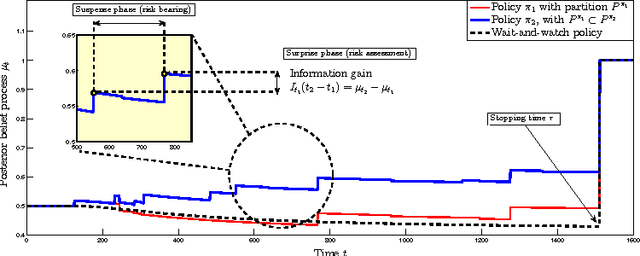
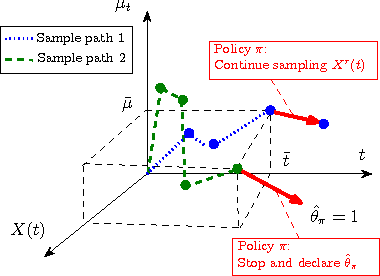
We develop a Bayesian model for decision-making under time pressure with endogenous information acquisition. In our model, the decision maker decides when to observe (costly) information by sampling an underlying continuous-time stochastic process (time series) that conveys information about the potential occurrence or non-occurrence of an adverse event which will terminate the decision-making process. In her attempt to predict the occurrence of the adverse event, the decision-maker follows a policy that determines when to acquire information from the time series (continuation), and when to stop acquiring information and make a final prediction (stopping). We show that the optimal policy has a rendezvous structure, i.e. a structure in which whenever a new information sample is gathered from the time series, the optimal "date" for acquiring the next sample becomes computable. The optimal interval between two information samples balances a trade-off between the decision maker's surprise, i.e. the drift in her posterior belief after observing new information, and suspense, i.e. the probability that the adverse event occurs in the time interval between two information samples. Moreover, we characterize the continuation and stopping regions in the decision-maker's state-space, and show that they depend not only on the decision-maker's beliefs, but also on the context, i.e. the current realization of the time series.
An Information-Theoretic Analysis of Thompson Sampling
Jun 08, 2015We provide an information-theoretic analysis of Thompson sampling that applies across a broad range of online optimization problems in which a decision-maker must learn from partial feedback. This analysis inherits the simplicity and elegance of information theory and leads to regret bounds that scale with the entropy of the optimal-action distribution. This strengthens preexisting results and yields new insight into how information improves performance.
Collaborative Spatial-Temporal Modeling for Language-Queried Video Actor Segmentation
May 14, 2021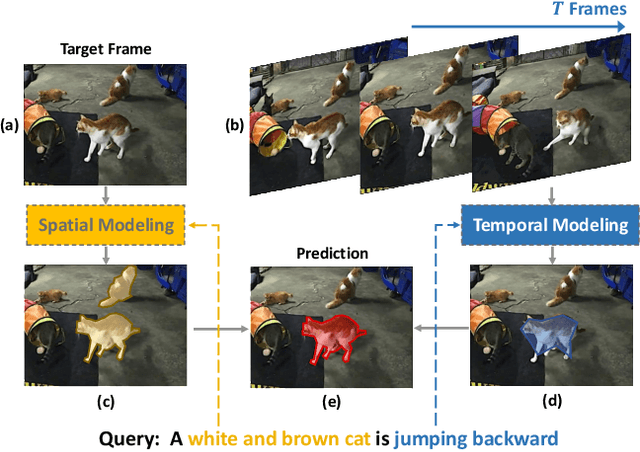
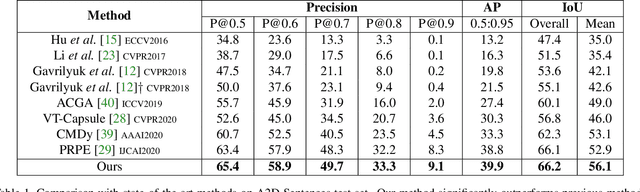
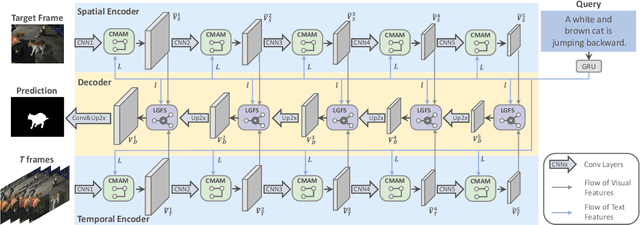
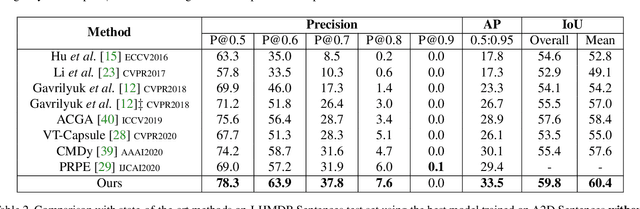
Language-queried video actor segmentation aims to predict the pixel-level mask of the actor which performs the actions described by a natural language query in the target frames. Existing methods adopt 3D CNNs over the video clip as a general encoder to extract a mixed spatio-temporal feature for the target frame. Though 3D convolutions are amenable to recognizing which actor is performing the queried actions, it also inevitably introduces misaligned spatial information from adjacent frames, which confuses features of the target frame and yields inaccurate segmentation. Therefore, we propose a collaborative spatial-temporal encoder-decoder framework which contains a 3D temporal encoder over the video clip to recognize the queried actions, and a 2D spatial encoder over the target frame to accurately segment the queried actors. In the decoder, a Language-Guided Feature Selection (LGFS) module is proposed to flexibly integrate spatial and temporal features from the two encoders. We also propose a Cross-Modal Adaptive Modulation (CMAM) module to dynamically recombine spatial- and temporal-relevant linguistic features for multimodal feature interaction in each stage of the two encoders. Our method achieves new state-of-the-art performance on two popular benchmarks with less computational overhead than previous approaches.
Distributed support-vector-machine over dynamic balanced directed networks
Apr 01, 2021


In this paper, we consider the binary classification problem via distributed Support-Vector-Machines (SVM), where the idea is to train a network of agents, with limited share of data, to cooperatively learn the SVM classifier for the global database. Agents only share processed information regarding the classifier parameters and the gradient of the local loss functions instead of their raw data. In contrast to the existing work, we propose a continuous-time algorithm that incorporates network topology changes in discrete jumps. This hybrid nature allows us to remove chattering that arises because of the discretization of the underlying CT process. We show that the proposed algorithm converges to the SVM classifier over time-varying weight balanced directed graphs by using arguments from the matrix perturbation theory.