 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Image Restoration and Fusion Based on Dynamic Degradation
Apr 30, 2021

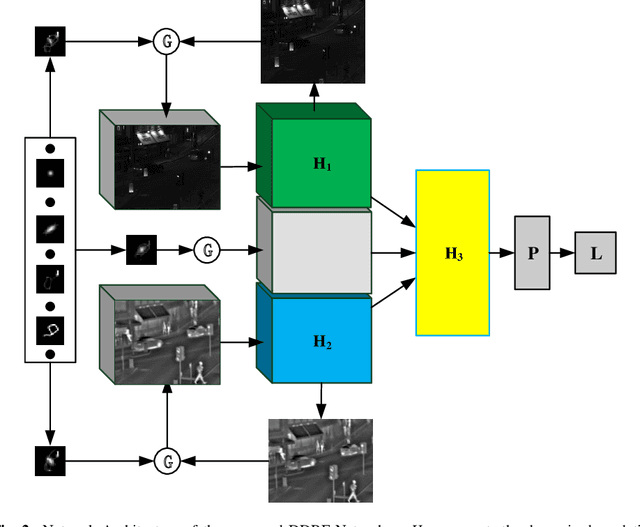


The deep-learning-based image restoration and fusion methods have achieved remarkable results. However, the existing restoration and fusion methods paid little research attention to the robustness problem caused by dynamic degradation. In this paper, we propose a novel dynamic image restoration and fusion neural network, termed as DDRF-Net, which is capable of solving two problems, i.e., static restoration and fusion, dynamic degradation. In order to solve the static fusion problem of existing methods, dynamic convolution is introduced to learn dynamic restoration and fusion weights. In addition, a dynamic degradation kernel is proposed to improve the robustness of image restoration and fusion. Our network framework can effectively combine image degradation with image fusion tasks, provide more detailed information for image fusion tasks through image restoration loss, and optimize image restoration tasks through image fusion loss. Therefore, the stumbling blocks of deep learning in image fusion, e.g., static fusion weight and specifically designed network architecture, are greatly mitigated. Extensive experiments show that our method is more superior compared with the state-of-the-art methods.
Unsupervised Lane-Change Identification for On-Ramp Merge Analysis in Naturalistic Driving Data
Apr 12, 2021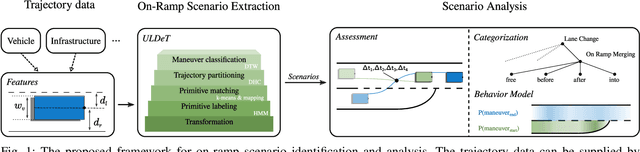
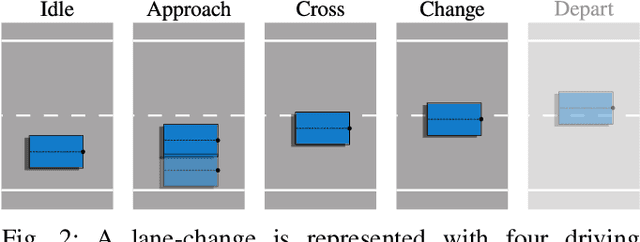
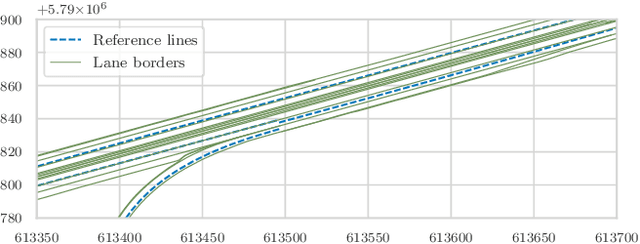
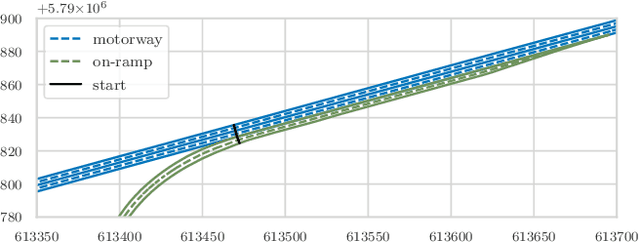
Connected and Automated Vehicles (CAVs) are envisioned to transform the future industrial and private transportation sectors. Due to the complexity of the systems, functional verification and validation of safety aspects are essential before the technology merges into the public domain. In recent years, a scenario-driven approach has gained acceptance for CAVs emphasizing the requirement of a solid data basis of scenarios. The large-scale research facility Test Bed Lower Saxony (TFNDS) enables the provision of substantial information for a database of scenarios on motorways. For that purpose, however, the scenarios of interest must be identified and categorized in the collected trajectory data. This work addresses this problem and proposes a framework for on-ramp scenario identification that also enables for scenario categorization and assessment. The efficacy of the framework is shown with a dataset collected on the TFNDS.
Combining Privileged Information to Improve Context-Aware Recommender Systems
Nov 07, 2015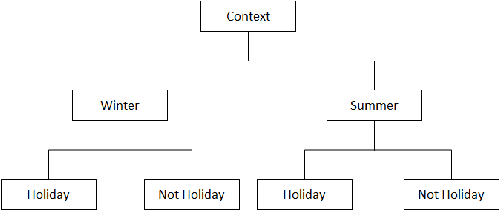
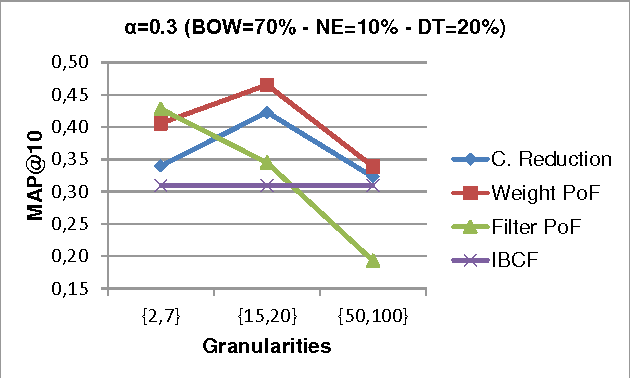
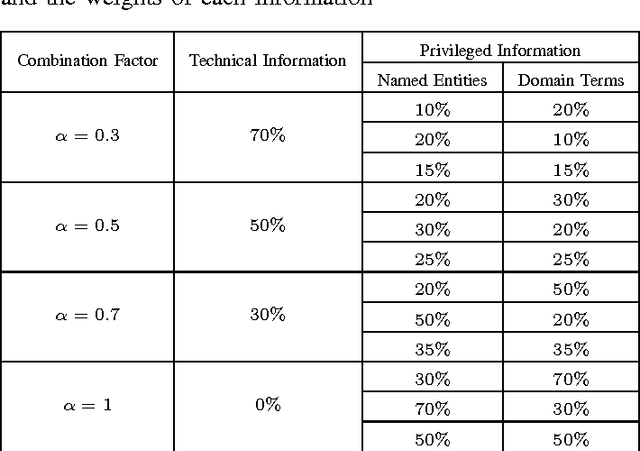
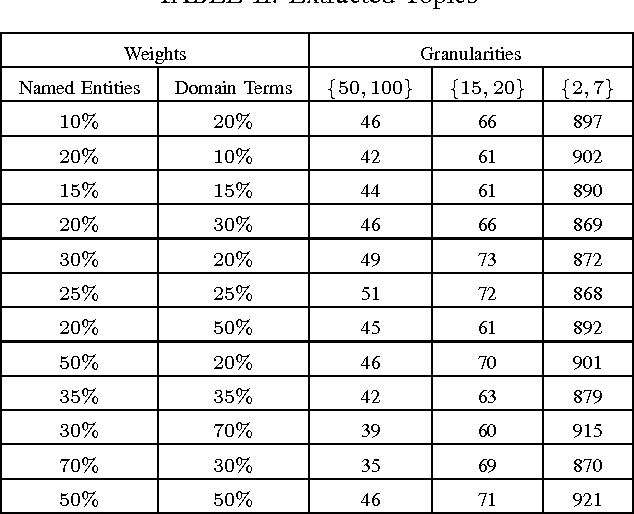
A recommender system is an information filtering technology which can be used to predict preference ratings of items (products, services, movies, etc) and/or to output a ranking of items that are likely to be of interest to the user. Context-aware recommender systems (CARS) learn and predict the tastes and preferences of users by incorporating available contextual information in the recommendation process. One of the major challenges in context-aware recommender systems research is the lack of automatic methods to obtain contextual information for these systems. Considering this scenario, in this paper, we propose to use contextual information from topic hierarchies of the items (web pages) to improve the performance of context-aware recommender systems. The topic hierarchies are constructed by an extension of the LUPI-based Incremental Hierarchical Clustering method that considers three types of information: traditional bag-of-words (technical information), and the combination of named entities (privileged information I) with domain terms (privileged information II). We evaluated the contextual information in four context-aware recommender systems. Different weights were assigned to each type of information. The empirical results demonstrated that topic hierarchies with the combination of the two kinds of privileged information can provide better recommendations.
Extracting Adverse Drug Events from Clinical Notes
Apr 21, 2021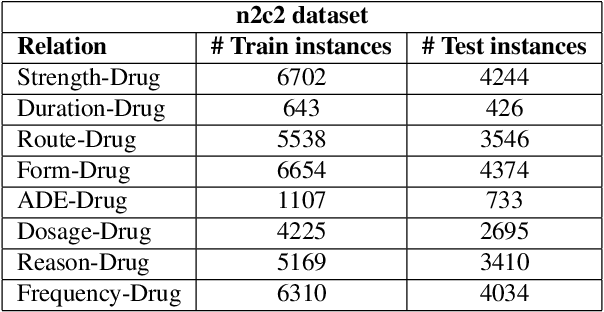
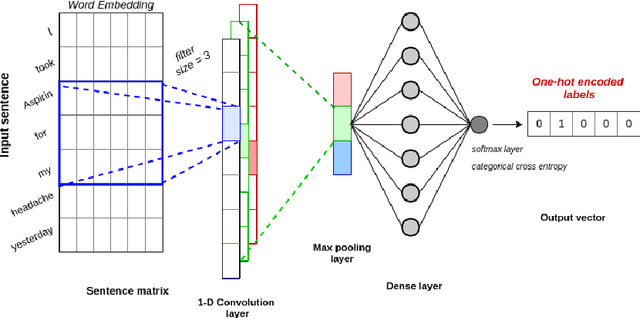
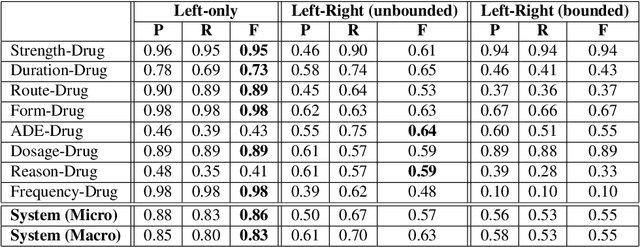
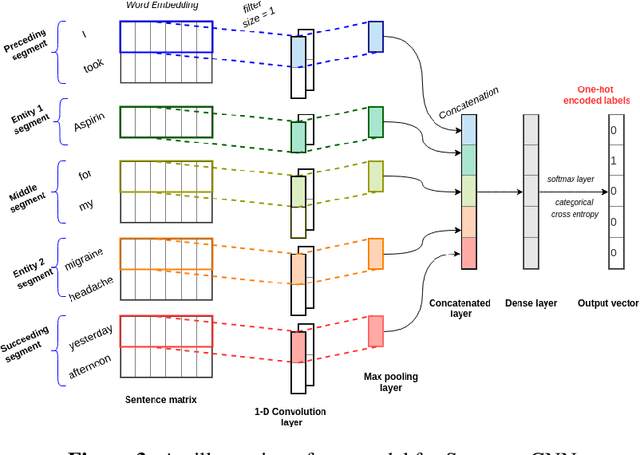
Adverse drug events (ADEs) are unexpected incidents caused by the administration of a drug or medication. To identify and extract these events, we require information about not just the drug itself but attributes describing the drug (e.g., strength, dosage), the reason why the drug was initially prescribed, and any adverse reaction to the drug. This paper explores the relationship between a drug and its associated attributes using relation extraction techniques. We explore three approaches: a rule-based approach, a deep learning-based approach, and a contextualized language model-based approach. We evaluate our system on the n2c2-2018 ADE extraction dataset. Our experimental results demonstrate that the contextualized language model-based approach outperformed other models overall and obtain the state-of-the-art performance in ADE extraction with a Precision of 0.93, Recall of 0.96, and an $F_1$ score of 0.94; however, for certain relation types, the rule-based approach obtained a higher Precision and Recall than either learning approach.
* 9 pages, 4 figures
LookHops: light multi-order convolution and pooling for graph classification
Dec 28, 2020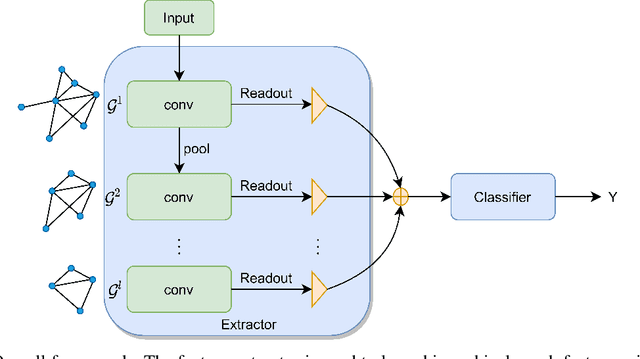
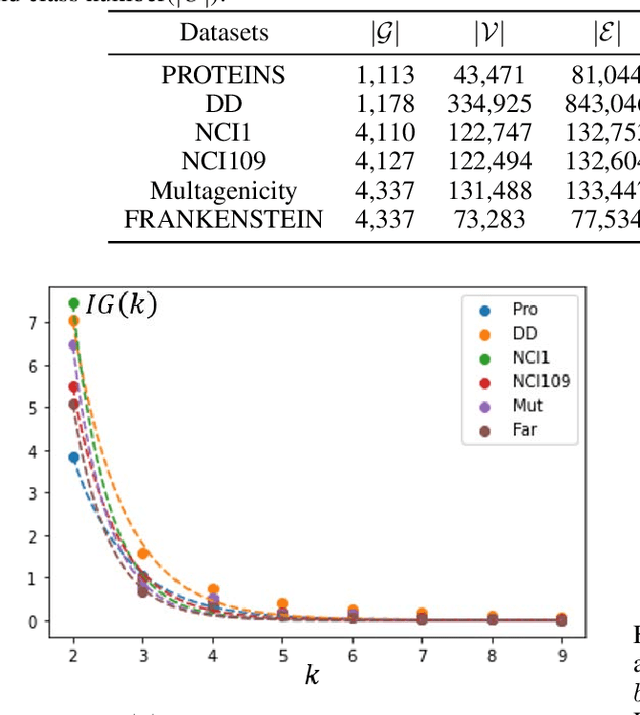
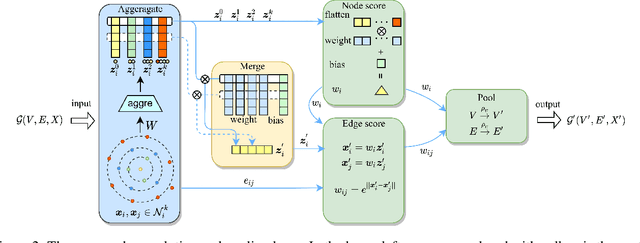

Convolution and pooling are the key operations to learn hierarchical representation for graph classification, where more expressive $k$-order($k>1$) method requires more computation cost, limiting the further applications. In this paper, we investigate the strategy of selecting $k$ via neighborhood information gain and propose light $k$-order convolution and pooling requiring fewer parameters while improving the performance. Comprehensive and fair experiments through six graph classification benchmarks show: 1) the performance improvement is consistent to the $k$-order information gain. 2) the proposed convolution requires fewer parameters while providing competitive results. 3) the proposed pooling outperforms SOTA algorithms in terms of efficiency and performance.
Recovering Quantized Data with Missing Information Using Bilinear Factorization and Augmented Lagrangian Method
Oct 07, 2018
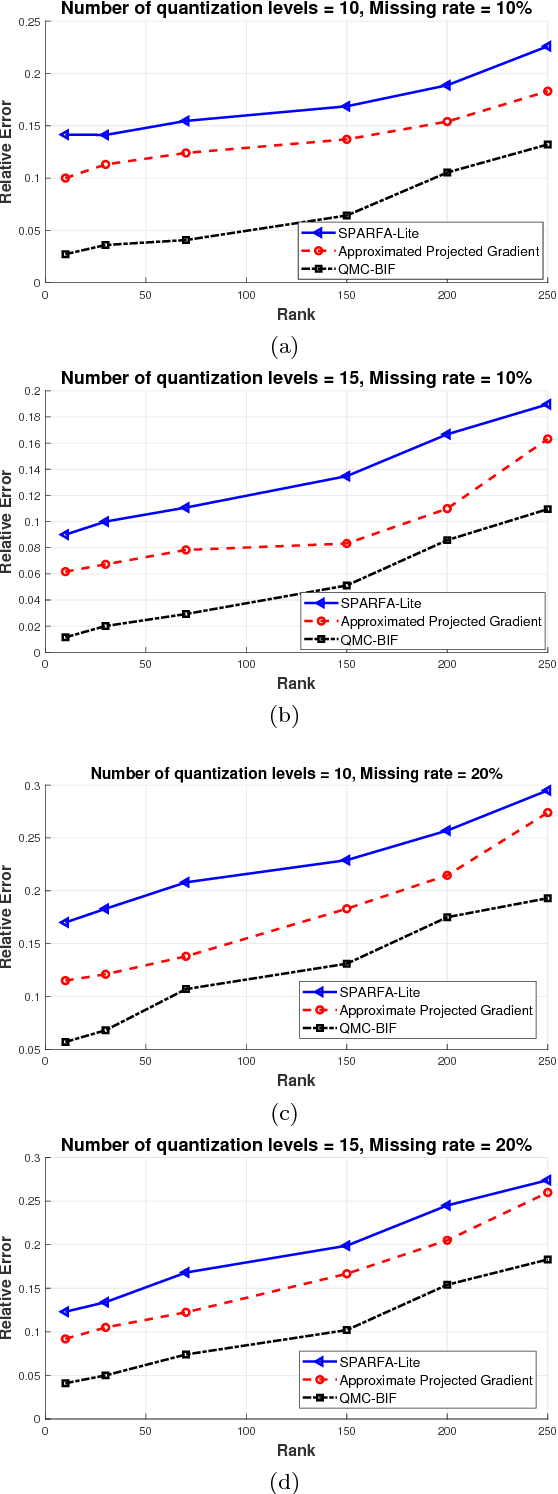

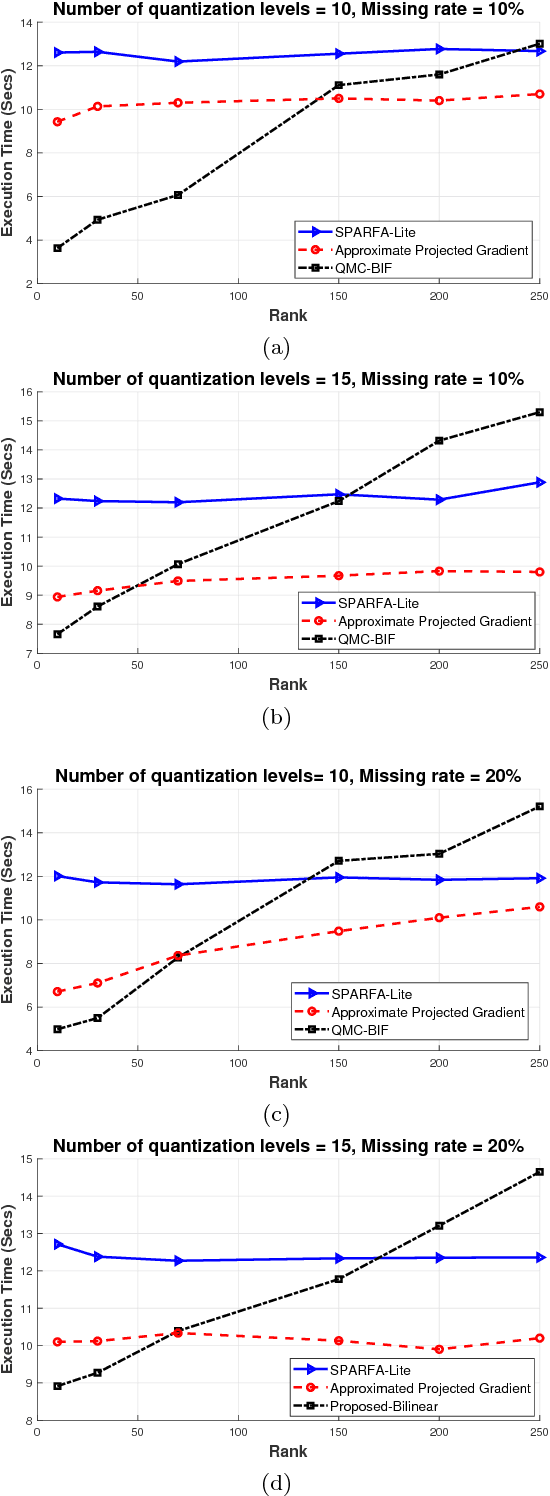
In this paper, we propose a novel approach in order to recover a quantized matrix with missing information. We propose a regularized convex cost function composed of a log-likelihood term and a Trace norm term. The Bi-factorization approach and the Augmented Lagrangian Method (ALM) are applied to find the global minimizer of the cost function in order to recover the genuine data. We provide mathematical convergence analysis for our proposed algorithm. In the Numerical Experiments Section, we show the superiority of our method in accuracy and also its robustness in computational complexity compared to the state-of-the-art literature methods.
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
Apr 21, 2021
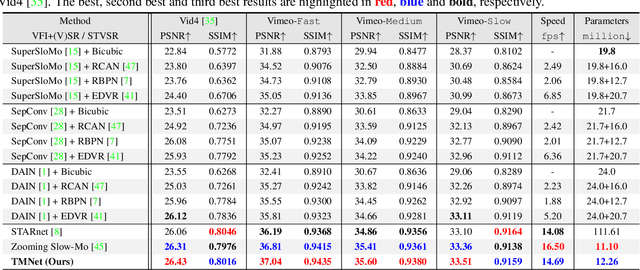
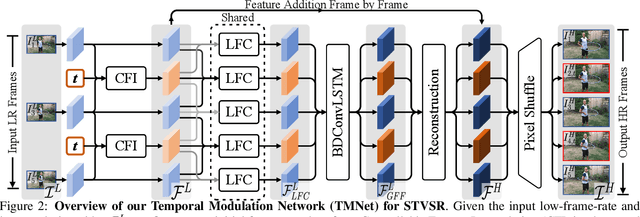
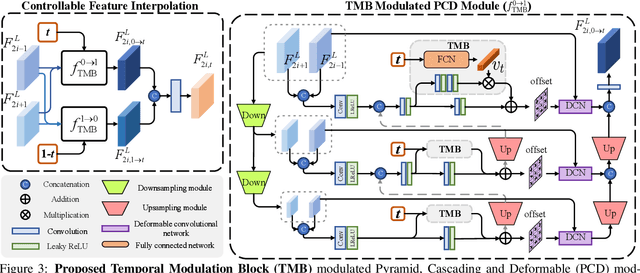
Space-time video super-resolution (STVSR) aims to increase the spatial and temporal resolutions of low-resolution and low-frame-rate videos. Recently, deformable convolution based methods have achieved promising STVSR performance, but they could only infer the intermediate frame pre-defined in the training stage. Besides, these methods undervalued the short-term motion cues among adjacent frames. In this paper, we propose a Temporal Modulation Network (TMNet) to interpolate arbitrary intermediate frame(s) with accurate high-resolution reconstruction. Specifically, we propose a Temporal Modulation Block (TMB) to modulate deformable convolution kernels for controllable feature interpolation. To well exploit the temporal information, we propose a Locally-temporal Feature Comparison (LFC) module, along with the Bi-directional Deformable ConvLSTM, to extract short-term and long-term motion cues in videos. Experiments on three benchmark datasets demonstrate that our TMNet outperforms previous STVSR methods. The code is available at https://github.com/CS-GangXu/TMNet.
Deep Chaos Synchronization
Apr 17, 2021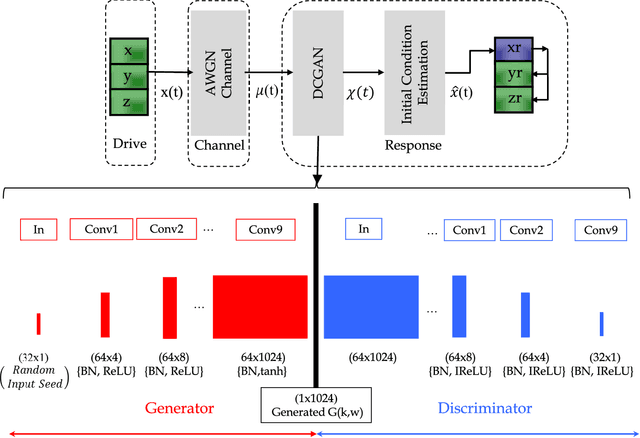
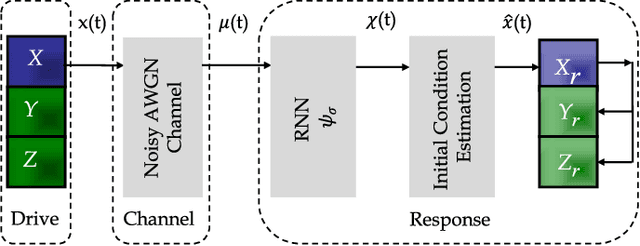
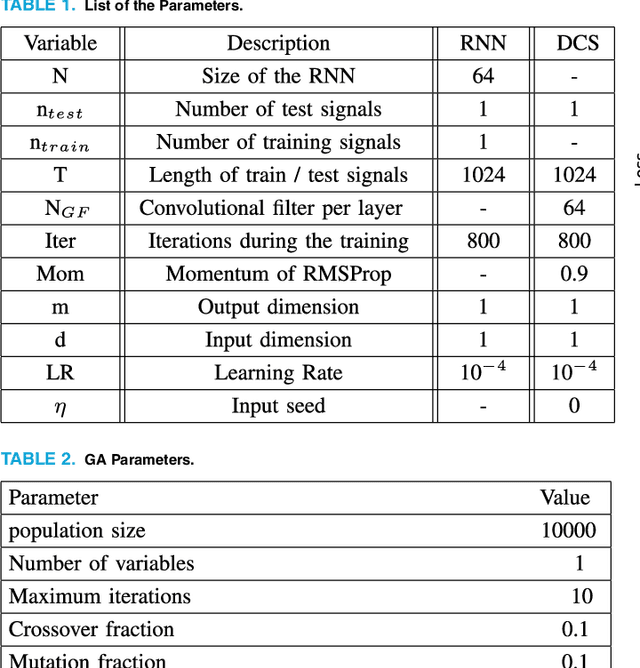
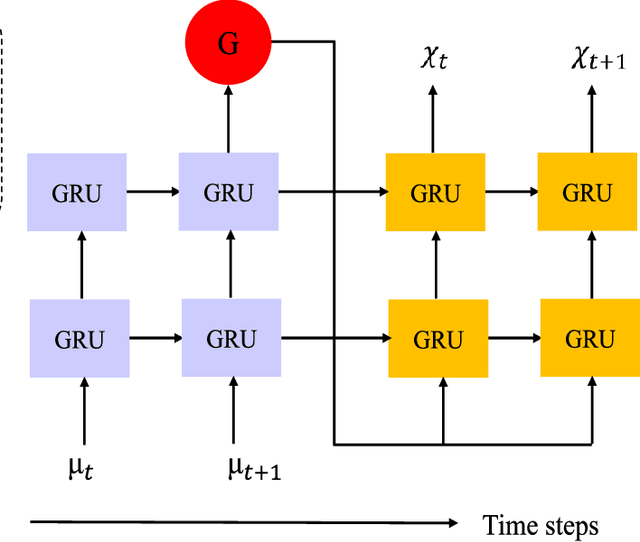
In this study, we address the problem of chaotic synchronization over a noisy channel by introducing a novel Deep Chaos Synchronization (DCS) system using a Convolutional Neural Network (CNN). Conventional Deep Learning (DL) based communication strategies are extremely powerful but training on large data sets is usually a difficult and time-consuming procedure. To tackle this challenge, DCS does not require prior information or large data sets. In addition, we provide a novel Recurrent Neural Network (RNN)-based chaotic synchronization system for comparative analysis. The results show that the proposed DCS architecture is competitive with RNN-based synchronization in terms of robustness against noise, convergence, and training. Hence, with these features, the DCS scheme will open the door for a new class of modulator schemes and meet the robustness against noise, convergence, and training requirements of the Ultra Reliable Low Latency Communications (URLLC) and Industrial Internet of Things (IIoT).
Knowledge-Based Paranoia Search in Trick-Taking
Apr 07, 2021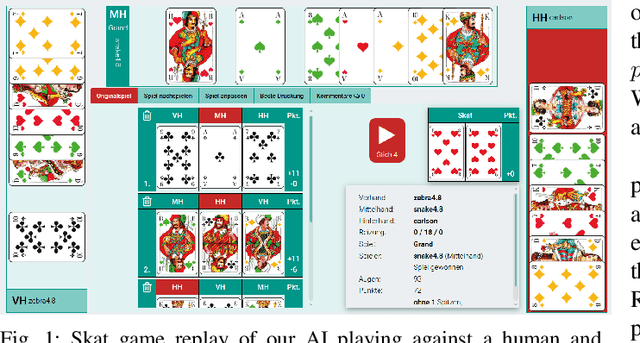


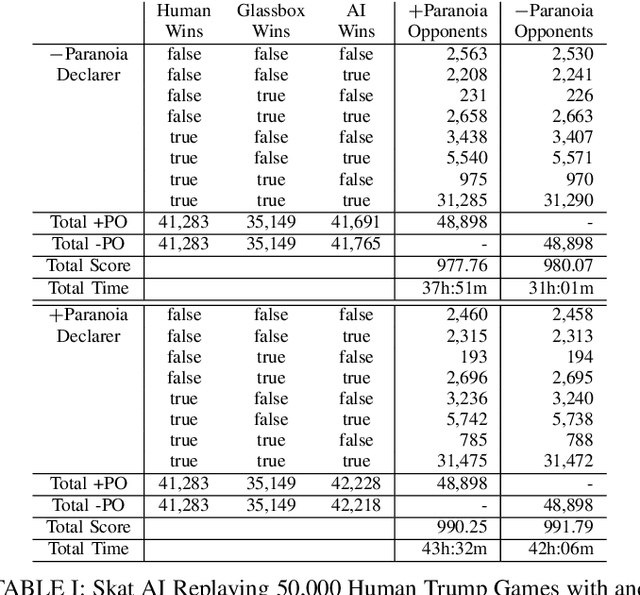
This paper proposes \emph{knowledge-based paraonoia search} (KBPS) to find forced wins during trick-taking in the card game Skat; for some one of the most interesting card games for three players. It combines efficient partial information game-tree search with knowledge representation and reasoning. This worst-case analysis, initiated after a small number of tricks, leads to a prioritized choice of cards. We provide variants of KBPS for the declarer and the opponents, and an approximation to find a forced win against most worlds in the belief space. Replaying thousands of expert games, our evaluation indicates that the AIs with the new algorithms perform better than humans in their play, achieving an average score of over 1,000 points in the agreed standard for evaluating Skat tournaments, the extended Seeger system.
Robust Lane Detection via Expanded Self Attention
Feb 14, 2021
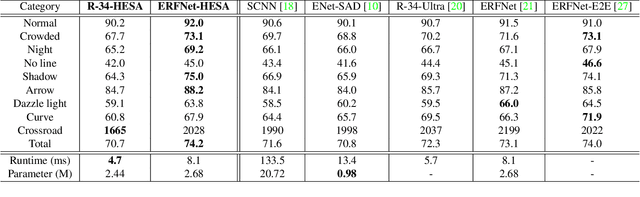
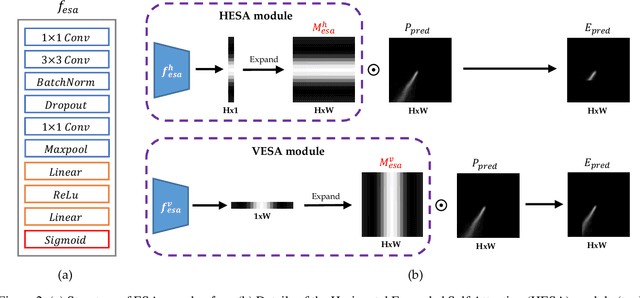
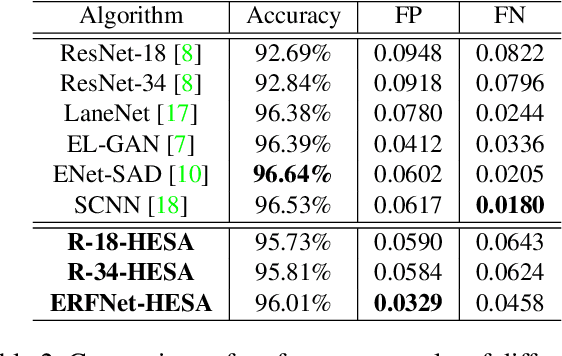
The image-based lane detection algorithm is one of the key technologies in autonomous vehicles. Modern deep learning methods achieve high performance in lane detection, but it is still difficult to accurately detect lanes in challenging situations such as congested roads and extreme lighting conditions. To be robust on these challenging situations, it is important to extract global contextual information even from limited visual cues. In this paper, we propose a simple but powerful self-attention mechanism optimized for lane detection called the Expanded Self Attention (ESA) module. Inspired by the simple geometric structure of lanes, the proposed method predicts the confidence of a lane along the vertical and horizontal directions in an image. The prediction of the confidence enables estimating occluded locations by extracting global contextual information. ESA module can be easily implemented and applied to any encoder-decoder-based model without increasing the inference time. The performance of our method is evaluated on three popular lane detection benchmarks (TuSimple, CULane and BDD100K). We achieve state-of-the-art performance in CULane and BDD100K and distinct improvement on TuSimple dataset. The experimental results show that our approach is robust to occlusion and extreme lighting conditions.