 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information, learning and falsification
Nov 28, 2011
There are (at least) three approaches to quantifying information. The first, algorithmic information or Kolmogorov complexity, takes events as strings and, given a universal Turing machine, quantifies the information content of a string as the length of the shortest program producing it. The second, Shannon information, takes events as belonging to ensembles and quantifies the information resulting from observing the given event in terms of the number of alternate events that have been ruled out. The third, statistical learning theory, has introduced measures of capacity that control (in part) the expected risk of classifiers. These capacities quantify the expectations regarding future data that learning algorithms embed into classifiers. This note describes a new method of quantifying information, effective information, that links algorithmic information to Shannon information, and also links both to capacities arising in statistical learning theory. After introducing the measure, we show that it provides a non-universal analog of Kolmogorov complexity. We then apply it to derive basic capacities in statistical learning theory: empirical VC-entropy and empirical Rademacher complexity. A nice byproduct of our approach is an interpretation of the explanatory power of a learning algorithm in terms of the number of hypotheses it falsifies, counted in two different ways for the two capacities. We also discuss how effective information relates to information gain, Shannon and mutual information.
Attention-based Information Fusion using Multi-Encoder-Decoder Recurrent Neural Networks
Nov 13, 2017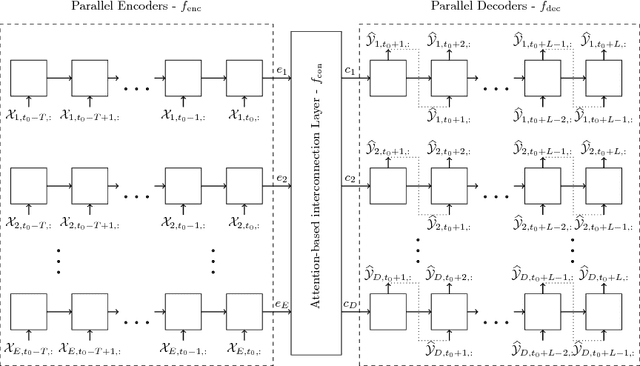
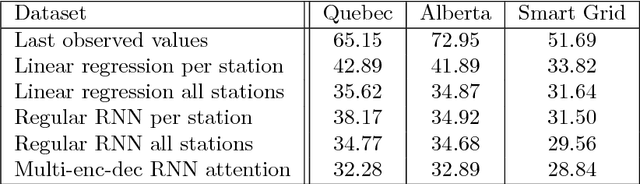
With the rising number of interconnected devices and sensors, modeling distributed sensor networks is of increasing interest. Recurrent neural networks (RNN) are considered particularly well suited for modeling sensory and streaming data. When predicting future behavior, incorporating information from neighboring sensor stations is often beneficial. We propose a new RNN based architecture for context specific information fusion across multiple spatially distributed sensor stations. Hereby, latent representations of multiple local models, each modeling one sensor station, are jointed and weighted, according to their importance for the prediction. The particular importance is assessed depending on the current context using a separate attention function. We demonstrate the effectiveness of our model on three different real-world sensor network datasets.
Federated Learning for Intrusion Detection System: Concepts, Challenges and Future Directions
Jun 16, 2021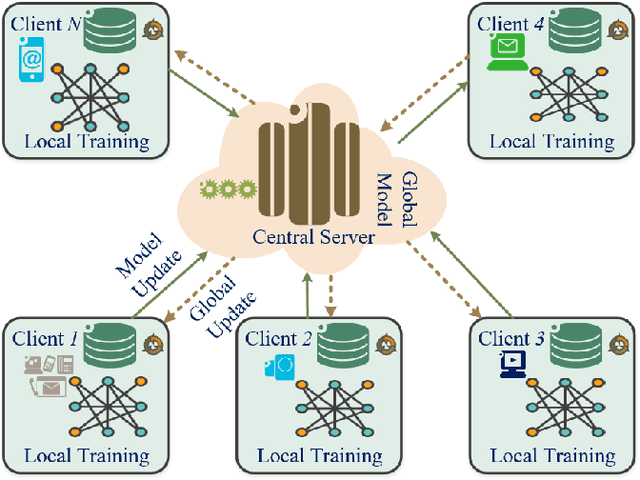

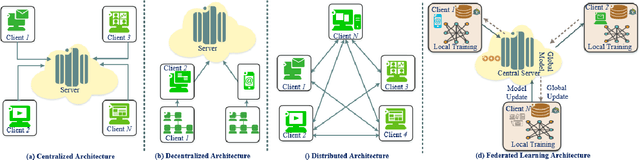
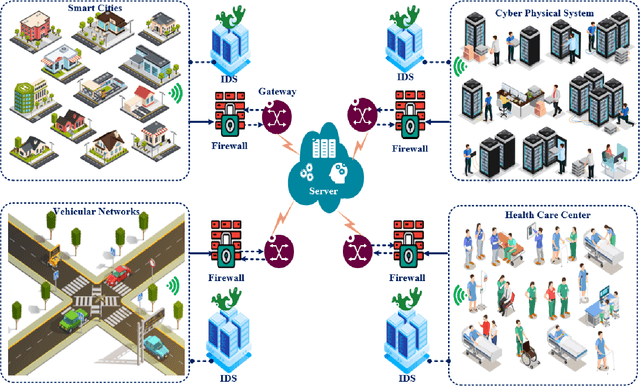
The rapid development of the Internet and smart devices trigger surge in network traffic making its infrastructure more complex and heterogeneous. The predominated usage of mobile phones, wearable devices and autonomous vehicles are examples of distributed networks which generate huge amount of data each and every day. The computational power of these devices have also seen steady progression which has created the need to transmit information, store data locally and drive network computations towards edge devices. Intrusion detection systems play a significant role in ensuring security and privacy of such devices. Machine Learning and Deep Learning with Intrusion Detection Systems have gained great momentum due to their achievement of high classification accuracy. However the privacy and security aspects potentially gets jeopardised due to the need of storing and communicating data to centralized server. On the contrary, federated learning (FL) fits in appropriately as a privacy-preserving decentralized learning technique that does not transfer data but trains models locally and transfers the parameters to the centralized server. The present paper aims to present an extensive and exhaustive review on the use of FL in intrusion detection system. In order to establish the need for FL, various types of IDS, relevant ML approaches and its associated issues are discussed. The paper presents detailed overview of the implementation of FL in various aspects of anomaly detection. The allied challenges of FL implementations are also identified which provides idea on the scope of future direction of research. The paper finally presents the plausible solutions associated with the identified challenges in FL based intrusion detection system implementation acting as a baseline for prospective research.
Alternating Fixpoint Operator for Hybrid MKNF Knowledge Bases as an Approximator of AFT
May 24, 2021Approximation fixpoint theory (AFT) provides an algebraic framework for the study of fixpoints of operators on bilattices and has found its applications in characterizing semantics for various classes of logic programs and nonmonotonic languages. In this paper, we show one more application of this kind: the alternating fixpoint operator by Knorr et al. for the study of the well-founded semantics for hybrid MKNF knowledge bases is in fact an approximator of AFT in disguise, which, thanks to the power of abstraction of AFT, characterizes not only the well-founded semantics but also two-valued as well as three-valued semantics for hybrid MKNF knowledge bases. Furthermore, we show an improved approximator for these knowledge bases, of which the least stable fixpoint is information richer than the one formulated from Knorr et al.'s construction. This leads to an improved computation for the well-founded semantics. This work is built on an extension of AFT that supports consistent as well as inconsistent pairs in the induced product bilattice, to deal with inconsistencies that arise in the context of hybrid MKNF knowledge bases. This part of the work can be considered generalizing the original AFT from symmetric approximators to arbitrary approximators.
An Efficient Method for the Classification of Croplands in Scarce-Label Regions
Mar 17, 2021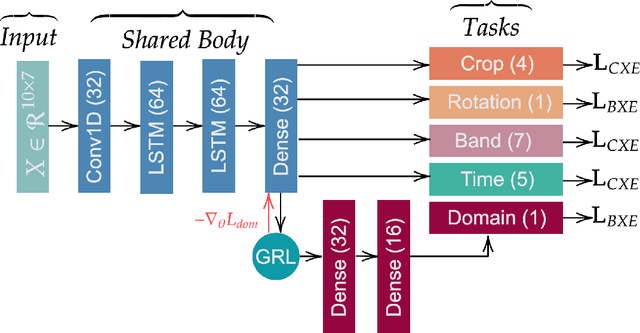
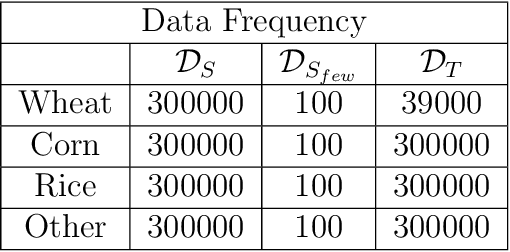
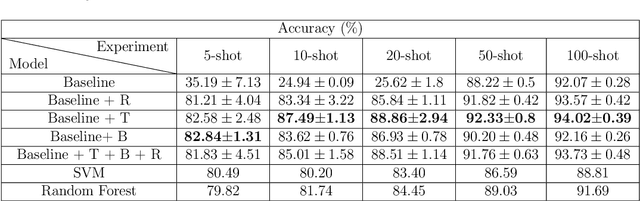
Two of the main challenges for cropland classification by satellite time-series images are insufficient ground-truth data and inaccessibility of high-quality hyperspectral images for under-developed areas. Unlabeled medium-resolution satellite images are abundant, but how to benefit from them is an open question. We will show how to leverage their potential for cropland classification using self-supervised tasks. Self-supervision is an approach where we provide simple training signals for the samples, which are apparent from the data's structure. Hence, they are cheap to acquire and explain a simple concept about the data. We introduce three self-supervised tasks for cropland classification. They reduce epistemic uncertainty, and the resulting model shows superior accuracy in a wide range of settings compared to SVM and Random Forest. Subsequently, we use the self-supervised tasks to perform unsupervised domain adaptation and benefit from the labeled samples in other regions. It is crucial to know what information to transfer to avoid degrading the performance. We show how to automate the information selection and transfer process in cropland classification even when the source and target areas have a very different feature distribution. We improved the model by about 24% compared to a baseline architecture without any labeled sample in the target domain. Our method is amenable to gradual improvement, works with medium-resolution satellite images, and does not require complicated models. Code and data are available.
Intent detection and slot filling for Vietnamese
Apr 05, 2021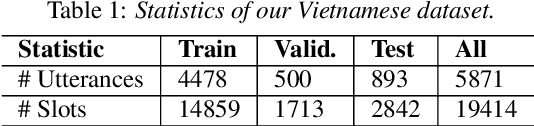
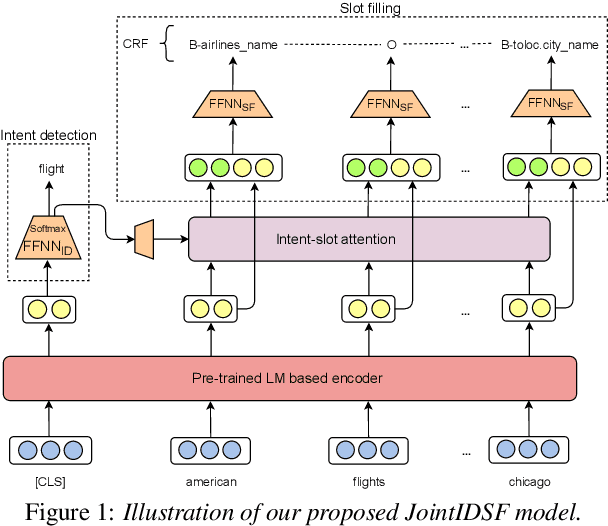


Intent detection and slot filling are important tasks in spoken and natural language understanding. However, Vietnamese is a low-resource language in these research topics. In this paper, we present the first public intent detection and slot filling dataset for Vietnamese. In addition, we also propose a joint model for intent detection and slot filling, that extends the recent state-of-the-art JointBERT+CRF model with an intent-slot attention layer in order to explicitly incorporate intent context information into slot filling via "soft" intent label embedding. Experimental results on our Vietnamese dataset show that our proposed model significantly outperforms JointBERT+CRF. We publicly release our dataset and the implementation of our model at: https://github.com/VinAIResearch/JointIDSF
Multiscale Anisotropic Harmonic Filters on non Euclidean domains
Feb 01, 2021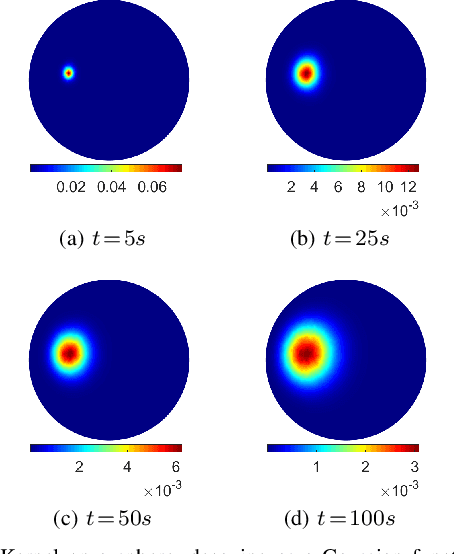
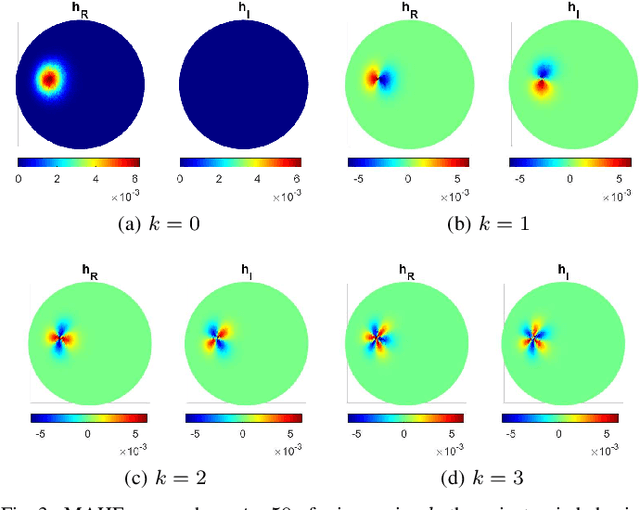
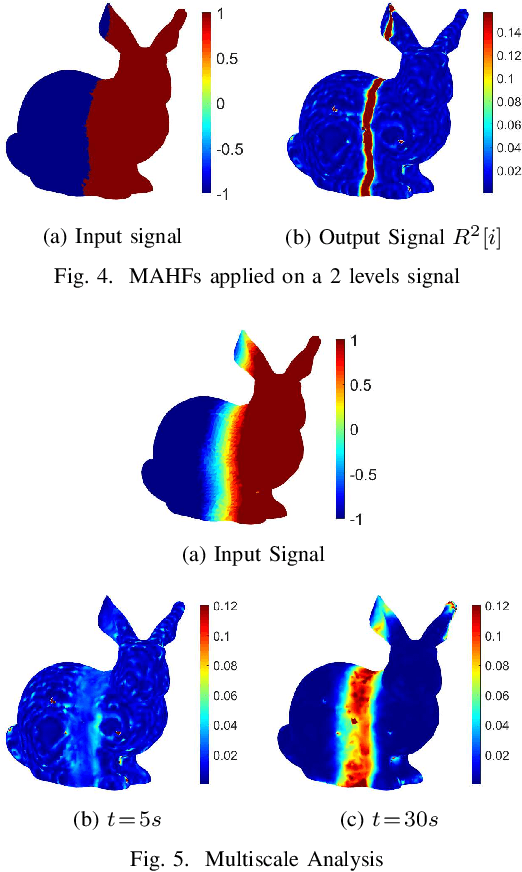
This paper introduces Multiscale Anisotropic Harmonic Filters (MAHFs) aimed at extracting signal variations over non-Euclidean domains, namely 2D-Manifolds and their discrete representations, such as meshes and 3D Point Clouds as well as graphs. The topic of pattern analysis is central in image processing and, considered the growing interest in new domains for information representation, the extension of analogous practices on volumetric data is highly demanded. To accomplish this purpose, we define MAHFs as the product of two components, respectively related to a suitable smoothing function, namely the heat kernel derived from the heat diffusion equations, and to local directional information. We analyse the effectiveness of our approach in multi-scale filtering and variation extraction. Finally, we present an application to the surface normal field and to a luminance signal textured to a mesh, aiming to spot, in a separate fashion, relevant curvature changes (support variations) and signal variations.
The distribution of information content in English sentences
Sep 24, 2016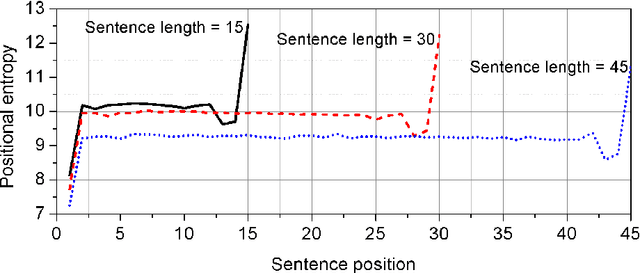
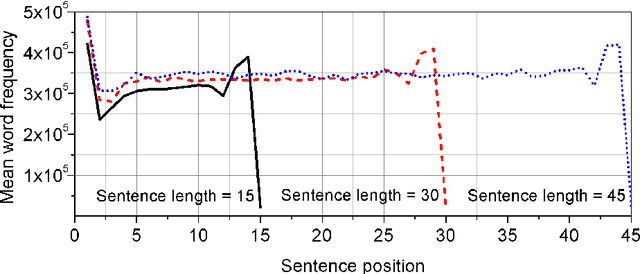
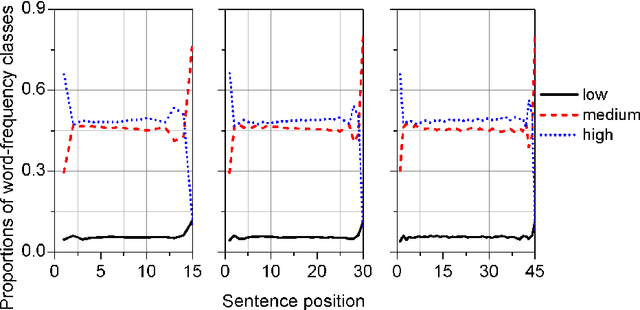
Sentence is a basic linguistic unit, however, little is known about how information content is distributed across different positions of a sentence. Based on authentic language data of English, the present study calculated the entropy and other entropy-related statistics for different sentence positions. The statistics indicate a three-step staircase-shaped distribution pattern, with entropy in the initial position lower than the medial positions (positions other than the initial and final), the medial positions lower than the final position and the medial positions showing no significant difference. The results suggest that: (1) the hypotheses of Constant Entropy Rate and Uniform Information Density do not hold for the sentence-medial positions; (2) the context of a word in a sentence should not be simply defined as all the words preceding it in the same sentence; and (3) the contextual information content in a sentence does not accumulate incrementally but follows a pattern of "the whole is greater than the sum of parts".
A Computationally Efficient 2D MUSIC Approach for 5G and 6G Sensing Networks
Apr 30, 2021
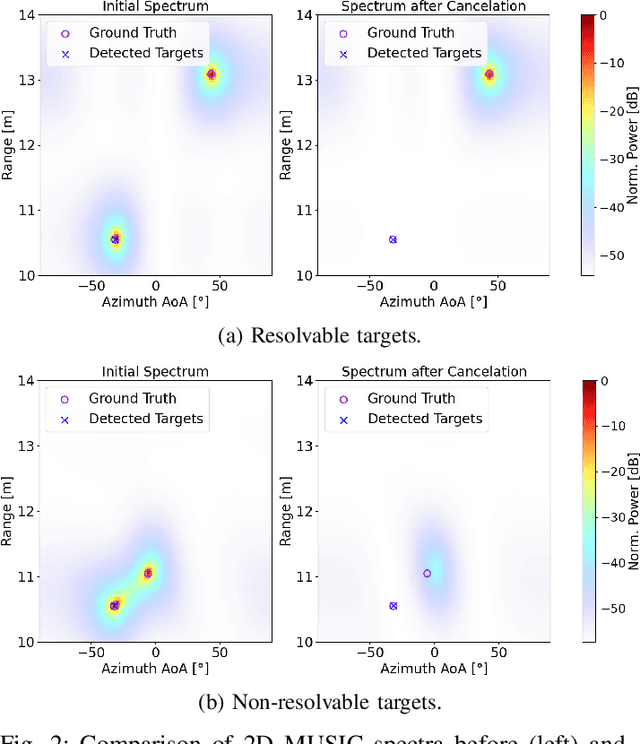
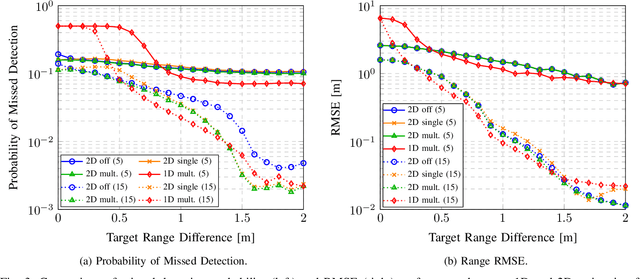

Future cellular networks are intended to have the ability to sense the environment by utilizing reflections of transmitted signals. Multi-dimensional sensing brings along the crucial advantage of being able to resort to multiple domains to resolve targets, enhancing detection capabilities compared to 1D estimation. However, estimating parameters jointly in 5G New Radio (NR) systems poses the challenge of limiting the computational complexity while preserving a high resolution. To that end, wepropose a channel state information (CSI) decimation technique for MUltiple SIgnal Classification (MUSIC)-based joint rangeangle of arrival (AoA) estimation. We further introduce multi-peak search routines to achieve additional detection capability improvements. Simulation results with orthogonal frequency-division multiplexing (OFDM) signals show that we attain higher detection probabilities for closely spaced targets than with 1D range-only estimation. Moreover, we demonstrate that for our considered 5G setup, we are able to significantly reduce the required number of computations due to CSI decimation.
Private learning implies quantum stability
Feb 14, 2021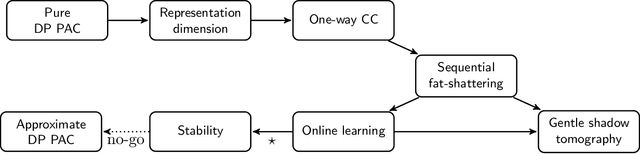
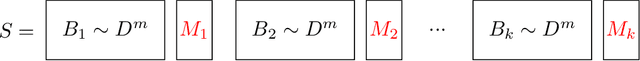

Learning an unknown $n$-qubit quantum state $\rho$ is a fundamental challenge in quantum computing. Information-theoretically, it is known that tomography requires exponential in $n$ many copies of $\rho$ to estimate it up to trace distance. Motivated by computational learning theory, Aaronson et al. introduced many (weaker) learning models: the PAC model of learning states (Proceedings of Royal Society A'07), shadow tomography (STOC'18) for learning "shadows" of a state, a model that also requires learners to be differentially private (STOC'19) and the online model of learning states (NeurIPS'18). In these models it was shown that an unknown state can be learned "approximately" using linear-in-$n$ many copies of rho. But is there any relationship between these models? In this paper we prove a sequence of (information-theoretic) implications from differentially-private PAC learning, to communication complexity, to online learning and then to quantum stability. Our main result generalizes the recent work of Bun, Livni and Moran (Journal of the ACM'21) who showed that finite Littlestone dimension (of Boolean-valued concept classes) implies PAC learnability in the (approximate) differentially private (DP) setting. We first consider their work in the real-valued setting and further extend their techniques to the setting of learning quantum states. Key to our results is our generic quantum online learner, Robust Standard Optimal Algorithm (RSOA), which is robust to adversarial imprecision. We then show information-theoretic implications between DP learning quantum states in the PAC model, learnability of quantum states in the one-way communication model, online learning of quantum states, quantum stability (which is our conceptual contribution), various combinatorial parameters and give further applications to gentle shadow tomography and noisy quantum state learning.