 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact of Spatial Frequency Based Constraints on Adversarial Robustness
Apr 26, 2021

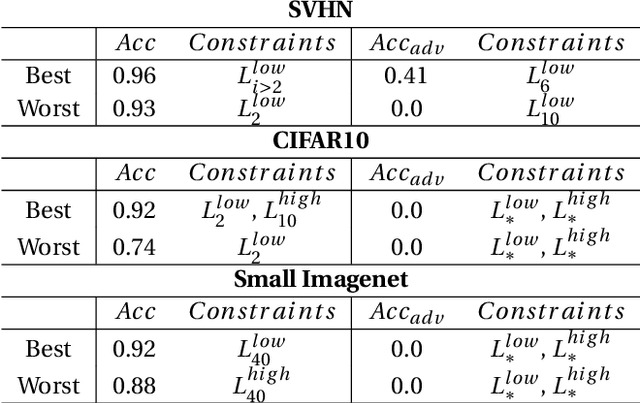
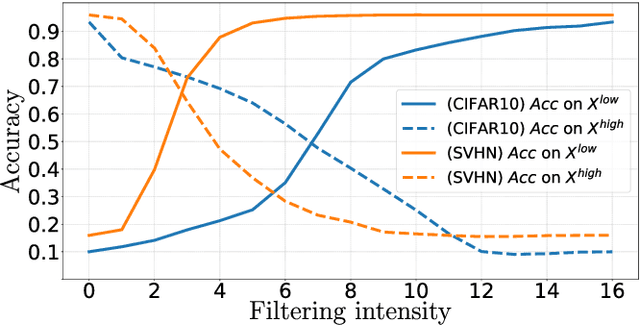
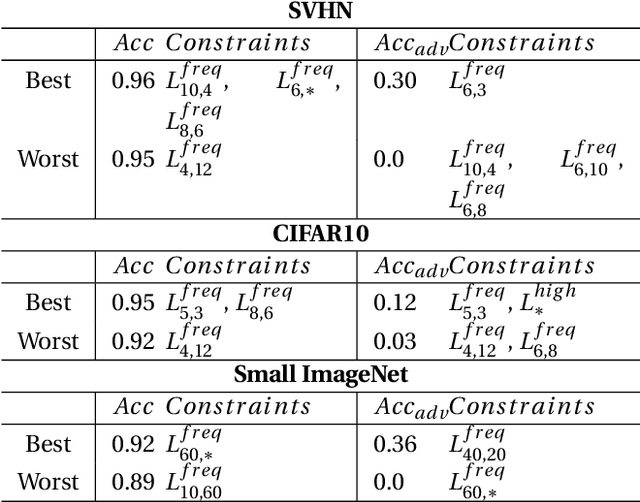
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
About Digital Communication Methods for Visible Light Communication
Jun 06, 2021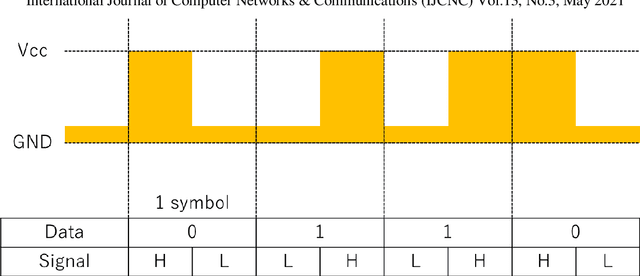

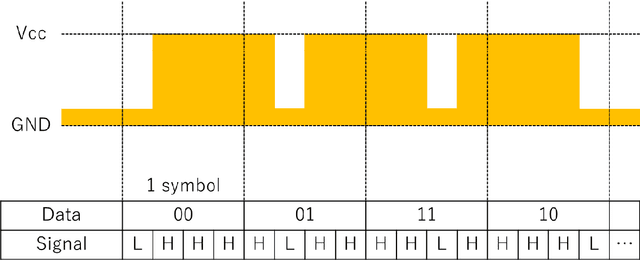

The visible light communication (VLC) by LED is one of the important communication methods because LED can work as high speed and VLC sends the information by high flushing LED. We use the pulse wave modulation for the VLC with LED because LED can be controlled easily by the microcontroller, which has the digital output pins. At the pulse wave modulation, deciding the high and low voltage by the middle voltage when the receiving signal level is amplified is equal to deciding it by the threshold voltage without amplification. In this paper, we proposed two methods that adjust the threshold value using counting the slot number and measuring the signal level. The number of signal slots is constant per one symbol when we use Pulse Position Modulation (PPM). If the number of received signal slots per one symbol time is less than the theoretical value, that means the threshold value is higher than the optimal value. If it is more than the theoretical value, that means the threshold value is lower. So, we can adjust the threshold value using the number of received signal slots. At the second proposed method, the average received signal level is not equal to the signal level because there is a ratio between the number of high slots and low slots. So, we can calculate the threshold value from the average received signal level and the slot ratio. We show these performances as real experiments.
Automatic model training under restrictive time constraints
Apr 21, 2021
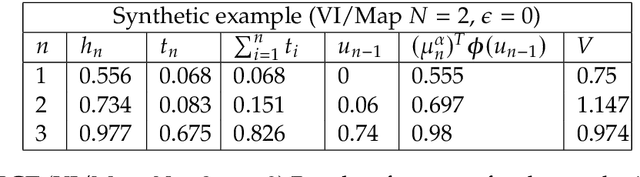
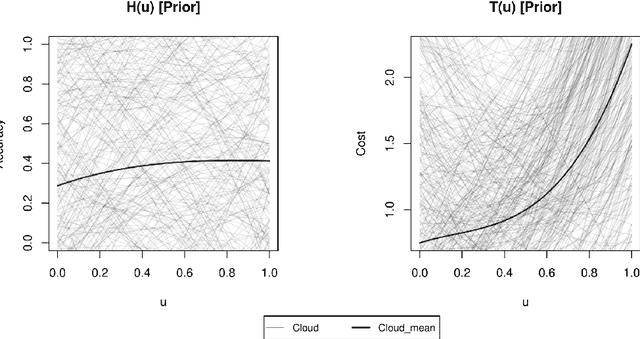

We develop a hyperparameter optimisation algorithm, Automated Budget Constrained Training (AutoBCT), which balances the quality of a model with the computational cost required to tune it. The relationship between hyperparameters, model quality and computational cost must be learnt and this learning is incorporated directly into the optimisation problem. At each training epoch, the algorithm decides whether to terminate or continue training, and, in the latter case, what values of hyperparameters to use. This decision weighs optimally potential improvements in the quality with the additional training time and the uncertainty about the learnt quantities. The performance of our algorithm is verified on a number of machine learning problems encompassing random forests and neural networks. Our approach is rooted in the theory of Markov decision processes with partial information and we develop a numerical method to compute the value function and an optimal strategy.
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 17, 2021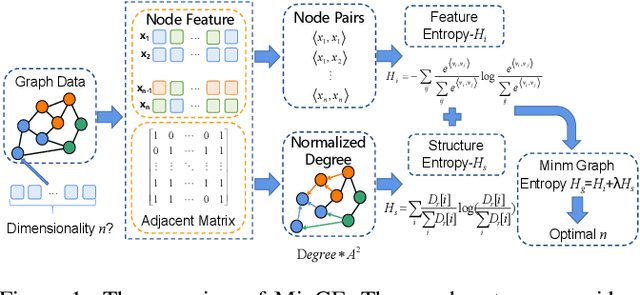
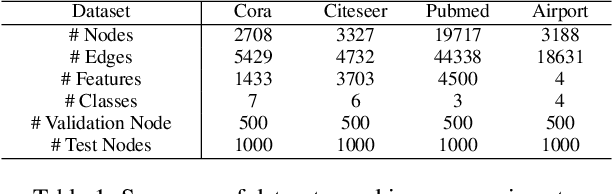
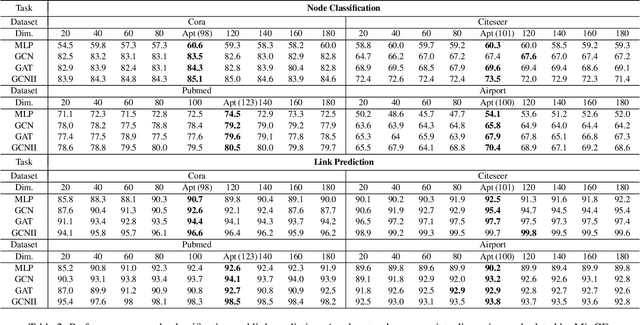
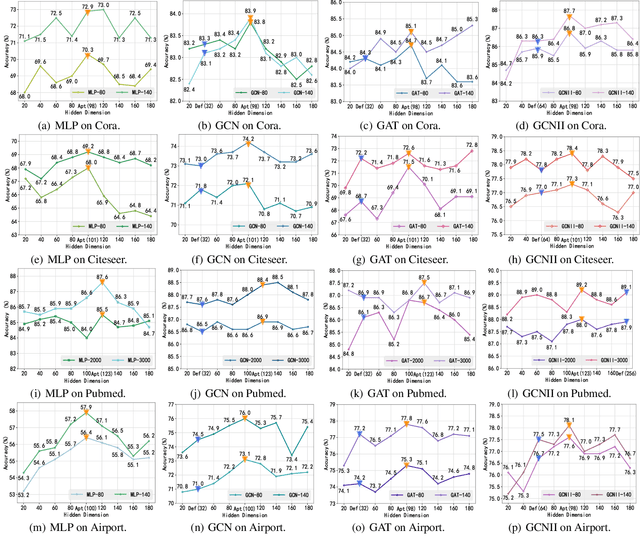
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
MILP-based Imitation Learning for HVAC control
Dec 01, 2020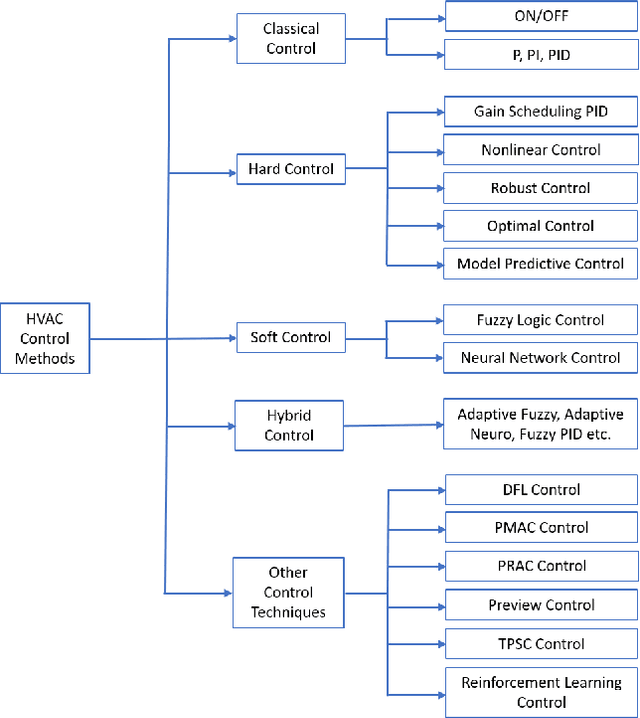
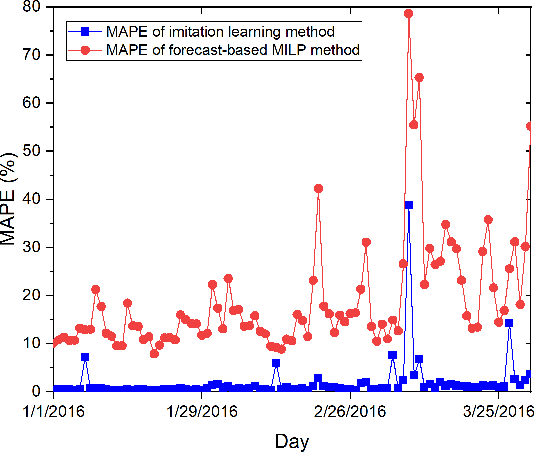
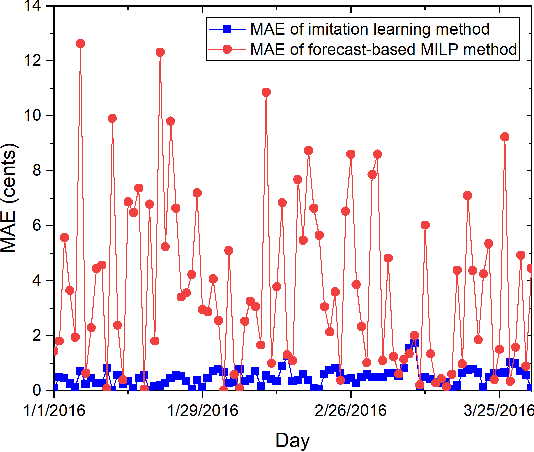
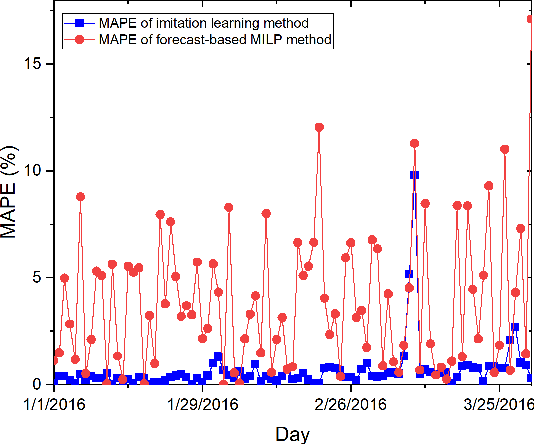
To optimize the operation of a HVAC system with advanced techniques such as artificial neural network, previous studies usually need forecast information in their method. However, the forecast information inevitably contains errors all the time, which degrade the performance of the HVAC operation. Hence, in this study, we propose MILP-based imitation learning method to control a HVAC system without using the forecast information in order to reduce energy cost and maintain thermal comfort at a given level. Our proposed controller is a deep neural network (DNN) trained by using data labeled by a MILP solver with historical data. After training, our controller is used to control the HVAC system with real-time data. For comparison, we also develop a second method named forecast-based MILP which control the HVAC system using the forecast information. The performance of the two methods is verified by using real outdoor temperatures and real day-ahead prices in Detroit city, Michigan, United States. Numerical results clearly show that the performance of the MILP-based imitation learning is better than that of the forecast-based MILP method in terms of hourly power consumption, daily energy cost, and thermal comfort. Moreover, the difference between results of the MILP-based imitation learning method and optimal results is almost negligible. These optimal results are achieved only by using the MILP solver at the end of a day when we have full information on the weather and prices for the day.
Tighter expected generalization error bounds via Wasserstein distance
Jan 22, 2021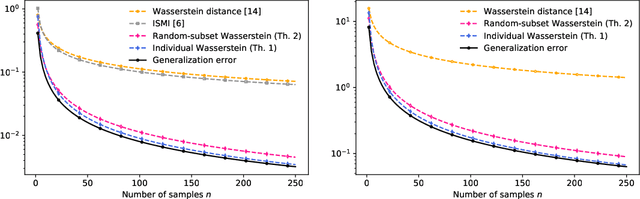
In this work, we introduce several expected generalization error bounds based on the Wasserstein distance. More precisely, we present full-dataset, single-letter, and random-subset bounds on both the standard setting and the randomized-subsample setting from Steinke and Zakynthinou [2020]. Moreover, we show that, when the loss function is bounded, these bounds recover from below (and thus are tighter than) current bounds based on the relative entropy and, for the standard setting, generate new, non-vacuous bounds also based on the relative entropy. Then, we show how similar bounds featuring the backward channel can be derived with the proposed proof techniques. Finally, we show how various new bounds based on different information measures (e.g., the lautum information or several $f$-divergences) can be derived from the presented bounds.
Projection: A Mechanism for Human-like Reasoning in Artificial Intelligence
Mar 24, 2021
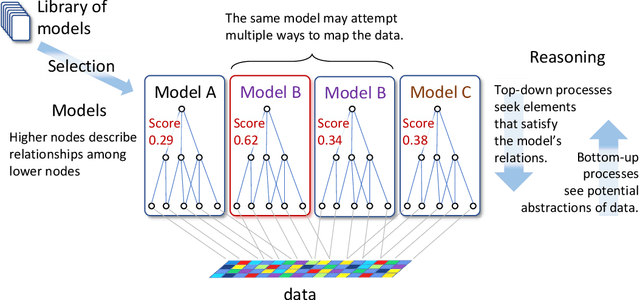

Artificial Intelligence systems cannot yet match human abilities to apply knowledge to situations that vary from what they have been programmed for, or trained for. In visual object recognition methods of inference exploiting top-down information (from a model) have been shown to be effective for recognising entities in difficult conditions. Here this type of inference, called `projection', is shown to be a key mechanism to solve the problem of applying knowledge to varied or challenging situations, across a range of AI domains, such as vision, robotics, or language. Finally the relevance of projection to tackling the commonsense knowledge problem is discussed.
Shadow-Mapping for Unsupervised Neural Causal Discovery
Apr 16, 2021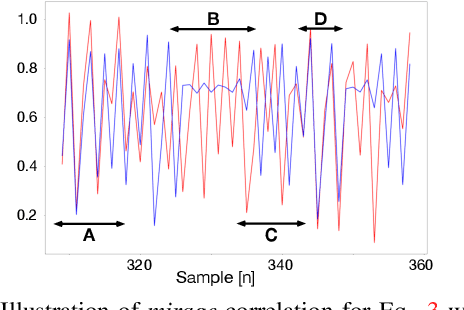
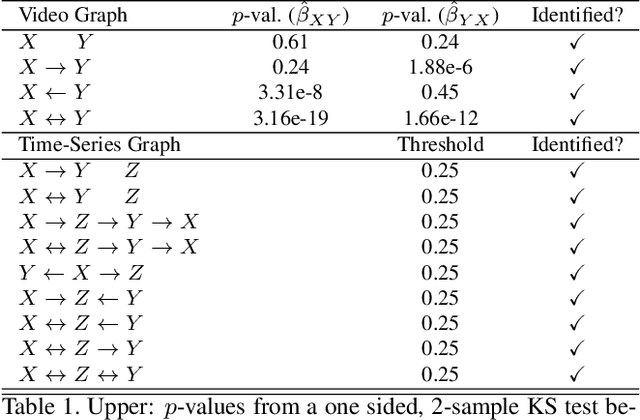
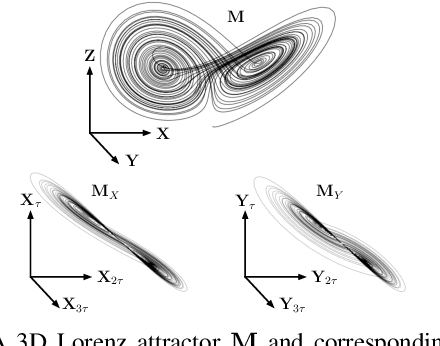
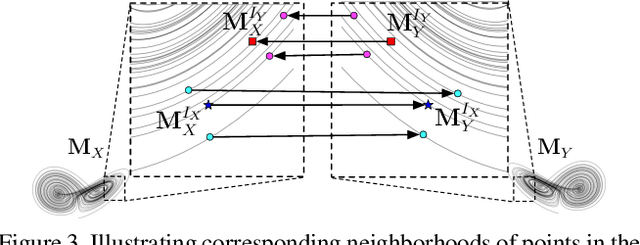
An important goal across most scientific fields is the discovery of causal structures underling a set of observations. Unfortunately, causal discovery methods which are based on correlation or mutual information can often fail to identify causal links in systems which exhibit dynamic relationships. Such dynamic systems (including the famous coupled logistic map) exhibit `mirage' correlations which appear and disappear depending on the observation window. This means not only that correlation is not causation but, perhaps counter-intuitively, that causation may occur without correlation. In this paper we describe Neural Shadow-Mapping, a neural network based method which embeds high-dimensional video data into a low-dimensional shadow representation, for subsequent estimation of causal links. We demonstrate its performance at discovering causal links from video-representations of dynamic systems.
Label-GCN: An Effective Method for Adding Label Propagation to Graph Convolutional Networks
Apr 05, 2021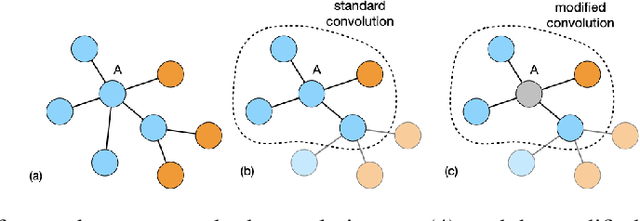

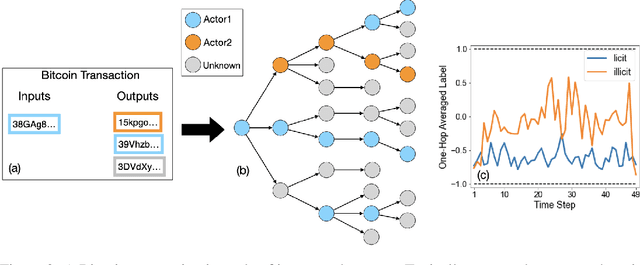
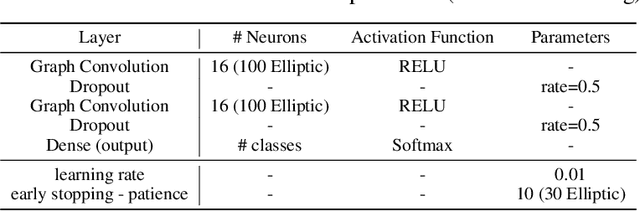
We show that a modification of the first layer of a Graph Convolutional Network (GCN) can be used to effectively propagate label information across neighbor nodes, for binary and multi-class classification problems. This is done by selectively eliminating self-loops for the label features during the training phase of a GCN. The GCN architecture is otherwise unchanged, without any extra hyper-parameters, and can be used in both a transductive and inductive setting. We show through several experiments that, depending on how many labels are available during the inference phase, this strategy can lead to a substantial improvement in the model performance compared to a standard GCN approach, including with imbalanced datasets.
Communication-Efficient Federated Learning with Dual-Side Low-Rank Compression
Apr 26, 2021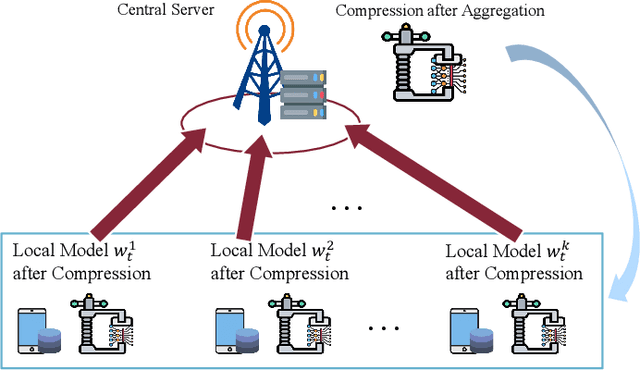

Federated learning (FL) is a promising and powerful approach for training deep learning models without sharing the raw data of clients. During the training process of FL, the central server and distributed clients need to exchange a vast amount of model information periodically. To address the challenge of communication-intensive training, we propose a new training method, referred to as federated learning with dual-side low-rank compression (FedDLR), where the deep learning model is compressed via low-rank approximations at both the server and client sides. The proposed FedDLR not only reduces the communication overhead during the training stage but also directly generates a compact model to speed up the inference process. We shall provide convergence analysis, investigate the influence of the key parameters, and empirically show that FedDLR outperforms the state-of-the-art solutions in terms of both the communication and computation efficiency.