 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EmoWrite: A Sentiment Analysis-Based Thought to Text Conversion
Mar 03, 2021
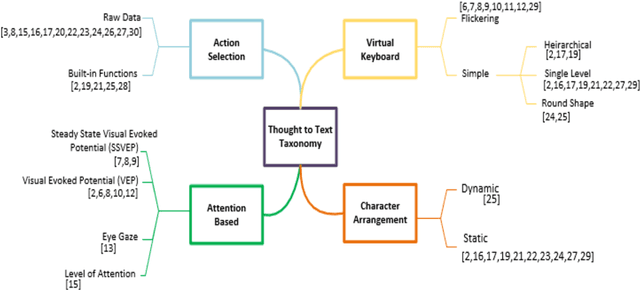
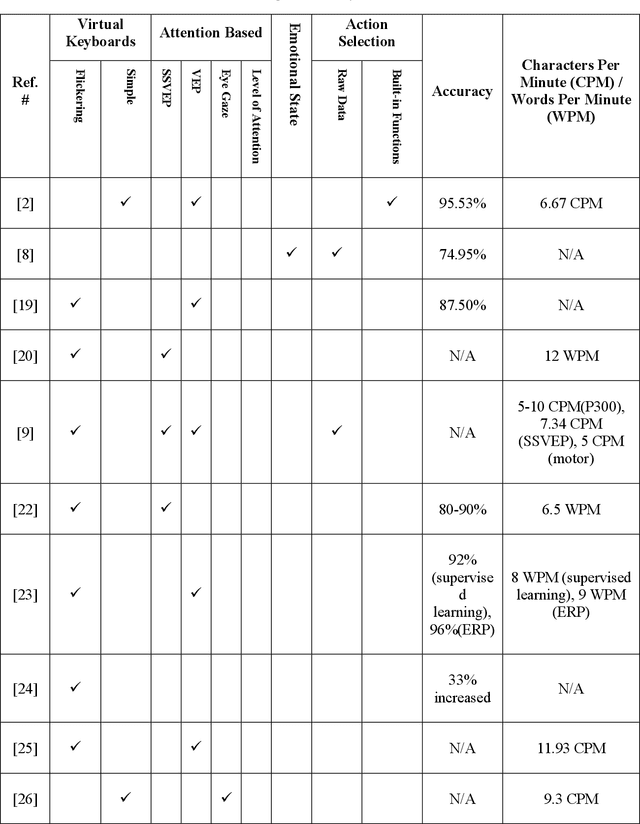
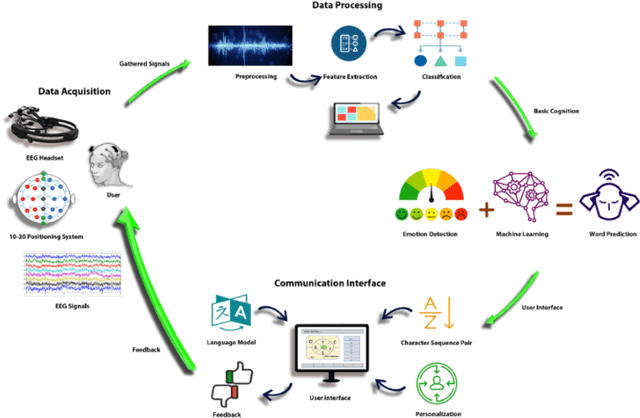

Brain Computer Interface (BCI) helps in processing and extraction of useful information from the acquired brain signals having applications in diverse fields such as military, medicine, neuroscience, and rehabilitation. BCI has been used to support paralytic patients having speech impediments with severe disabilities. To help paralytic patients communicate with ease, BCI based systems convert silent speech (thoughts) to text. However, these systems have an inconvenient graphical user interface, high latency, limited typing speed, and low accuracy rate. Apart from these limitations, the existing systems do not incorporate the inevitable factor of a patient's emotional states and sentiment analysis. The proposed system EmoWrite implements a dynamic keyboard with contextualized appearance of characters reducing the traversal time and improving the utilization of the screen space. The proposed system has been evaluated and compared with the existing systems for accuracy, convenience, sentimental analysis, and typing speed. This system results in 6.58 Words Per Minute (WPM) and 31.92 Characters Per Minute (CPM) with an accuracy of 90.36 percent. EmoWrite also gives remarkable results when it comes to the integration of emotional states. Its Information Transfer Rate (ITR) is also high as compared to other systems i.e., 87.55 bits per min with commands and 72.52 bits per min for letters. Furthermore, it provides easy to use interface with a latency of 2.685 sec.
Image Classification with Rejection using Contextual Information
Sep 03, 2015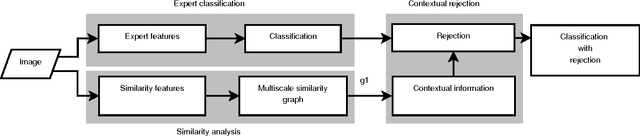
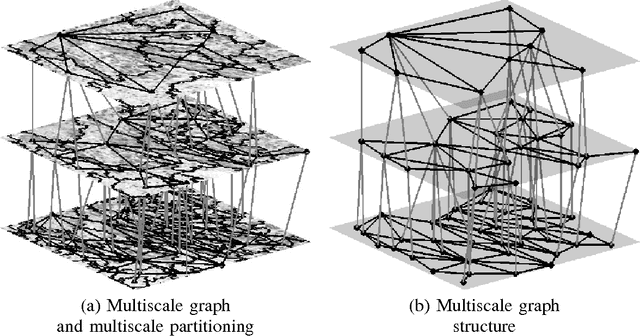
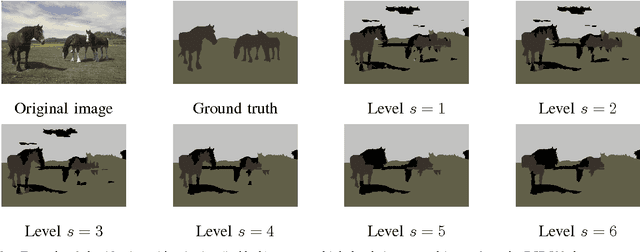
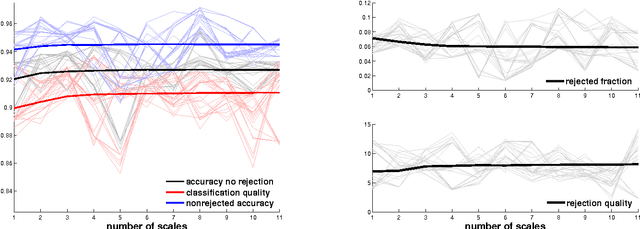
We introduce a new supervised algorithm for image classification with rejection using multiscale contextual information. Rejection is desired in image-classification applications that require a robust classifier but not the classification of the entire image. The proposed algorithm combines local and multiscale contextual information with rejection, improving the classification performance. As a probabilistic model for classification, we adopt a multinomial logistic regression. The concept of rejection with contextual information is implemented by modeling the classification problem as an energy minimization problem over a graph representing local and multiscale similarities of the image. The rejection is introduced through an energy data term associated with the classification risk and the contextual information through an energy smoothness term associated with the local and multiscale similarities within the image. We illustrate the proposed method on the classification of images of H&E-stained teratoma tissues.
Causal version of Principle of Insufficient Reason and MaxEnt
Feb 07, 2021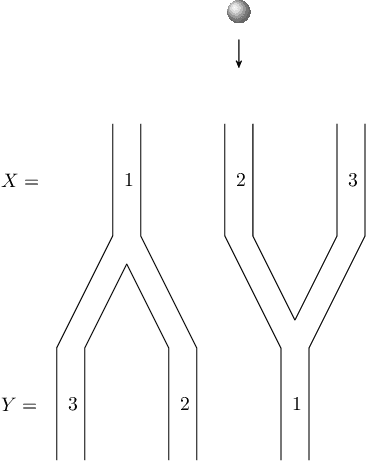
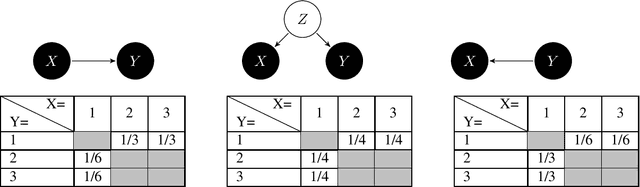
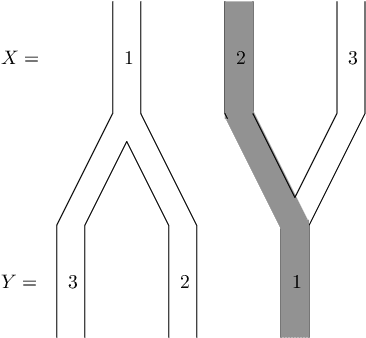
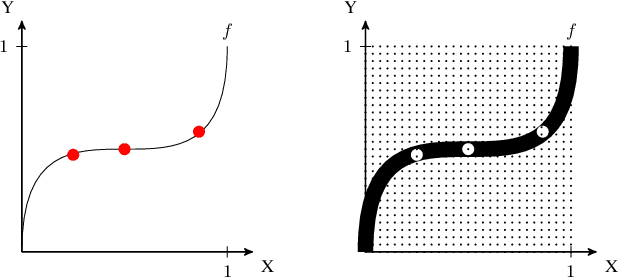
The Principle of insufficient Reason (PIR) assigns equal probabilities to each alternative of a random experiment whenever there is no reason to prefer one over the other. Maximum Entropy (MaxEnt) generalizes PIR to the case where statistical information like expectations are given. It is known that both principles result in paradox probability updates for joint distributions of cause and effect. This is because constraints on the conditional P(effect | cause) result in changes of P(cause) that assign higher probability to those values of the cause that offer more options for the effect, suggesting 'intentional behaviour'. Earlier work therefore suggested sequentially maximizing (conditional) entropy according to the causal order, but without further justification apart from plausibility for toy examples. We justify causal modifications of PIR and MaxEnt by separating constraints into restrictions for the cause and restrictions for the mechanism that generates the effect from the cause. We further sketch why Causal PIR also entails 'Information Geometric Causal Inference'. We briefly discuss problems of generalizing the causal version of MaxEnt to arbitrary causal DAGs.
Single Underwater Image Restoration by Contrastive Learning
Mar 17, 2021
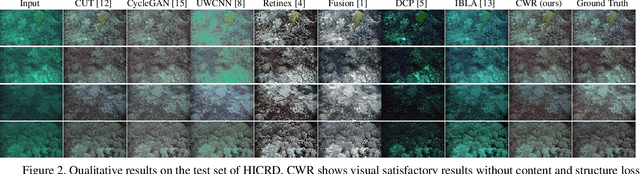
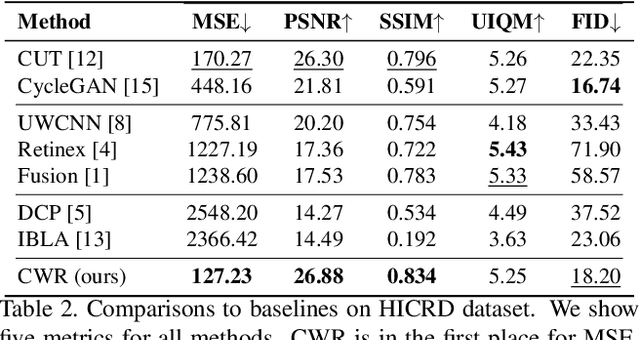
Underwater image restoration attracts significant attention due to its importance in unveiling the underwater world. This paper elaborates on a novel method that achieves state-of-the-art results for underwater image restoration based on the unsupervised image-to-image translation framework. We design our method by leveraging from contrastive learning and generative adversarial networks to maximize mutual information between raw and restored images. Additionally, we release a large-scale real underwater image dataset to support both paired and unpaired training modules. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method.
Max-Min Fair Energy-Efficient Beamforming Design for Intelligent Reflecting Surface-Aided SWIPT Systems with Non-linear Energy Harvesting Model
Mar 22, 2021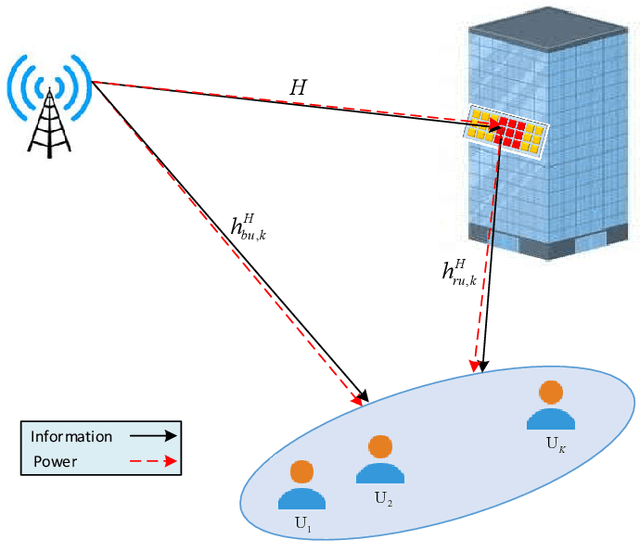
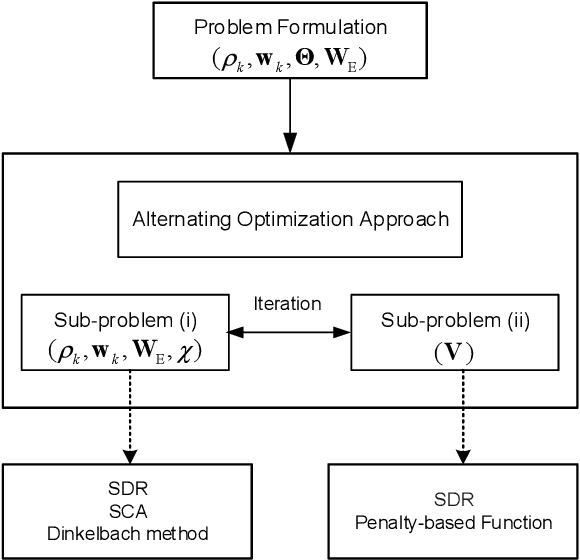
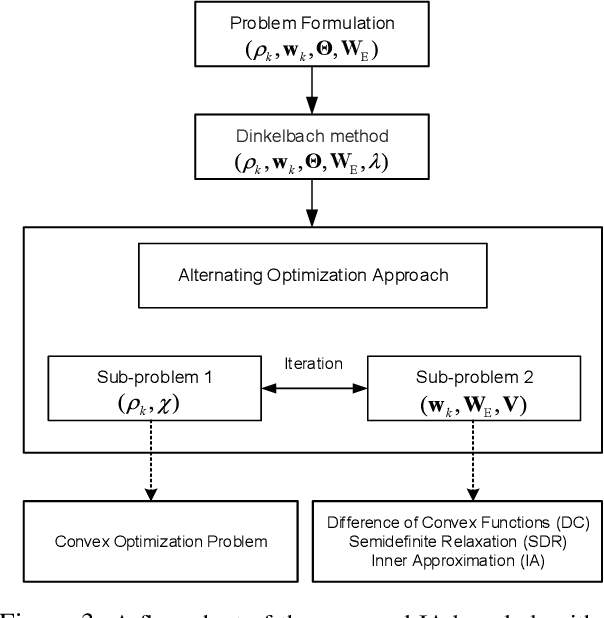
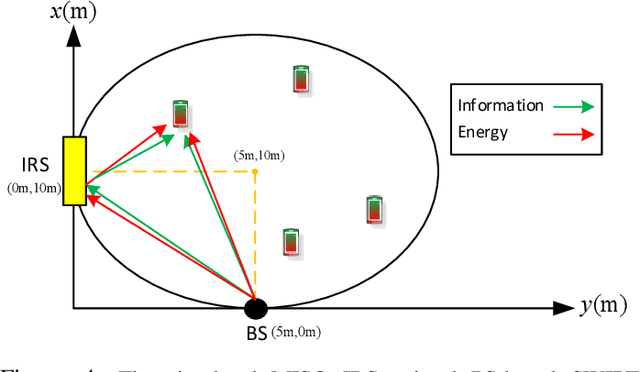
This paper considers an intelligent reflecting sur-face (IRS)-aided simultaneous wireless information and power transfer (SWIPT) network, where multiple users decode data and harvest energy from the transmitted signal of a transmit-ter. The proposed design framework exploits the cost-effective IRS to establish favorable communication environment to improve the fair energy efficient. In particular, we study the max-min energy efficiency (EE) of the system by jointly designing the transmit information and energy beamforming at the base station (BS), phase shifts at the IRS, as well as the power splitting (PS) ratio at all users subject to the minimum rate, minimum harvested energy, and transmit power constraints. The formulated problem is non-convex and thus challenging to be solved. We propose two algorithms namely penalty-based and inner approximation (IA)-based to handle the non-convexity of the optimization problem. As such, we divide the original problem into two sub-problems and apply the alternating optimization (AO) algorithm for both proposed algorithms to handle it iteratively. In particular, in the penalty-based algorithm for the first sub-problem, the semi-definite relaxation (SDR) technique, difference of convex functions (DC) programming, majorization-minimization (MM) approach, and fractional programming theory are exploited to transform the non-convex optimization problem into a convex form that can be addressed efficiently. For the second sub-problem, a penalty-based approach is proposed to handle the optimization on the phase shifts introduced by the IRS with the proposed algorithms. For the IA-based method, we optimize jointly beamforming vectors and phase shifts while the PS ratio is solved optimally in the first sub-problem...
Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx
Apr 23, 2021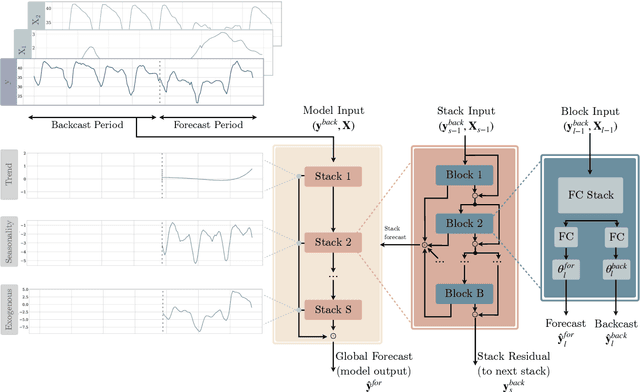

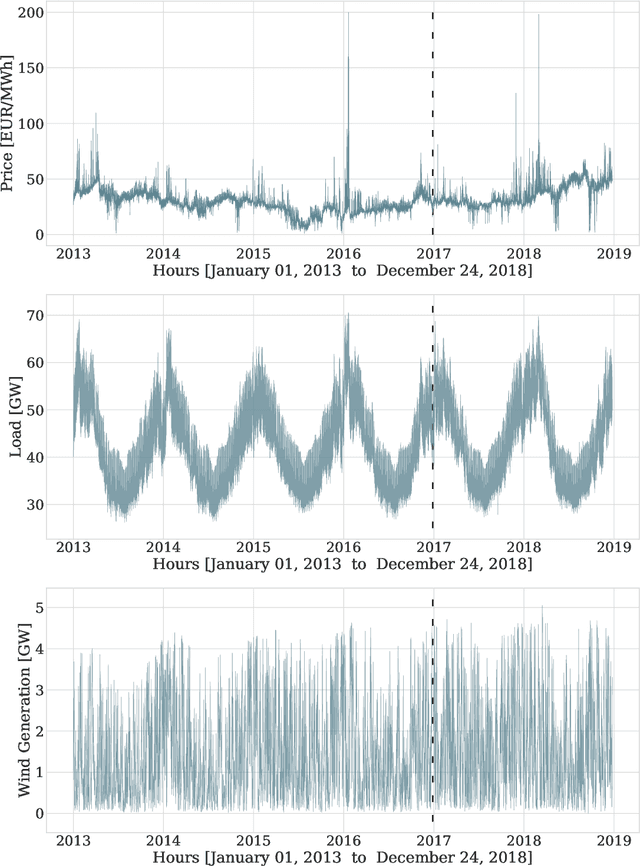

We extend the neural basis expansion analysis (NBEATS) to incorporate exogenous factors. The resulting method, called NBEATSx, improves on a well performing deep learning model, extending its capabilities by including exogenous variables and allowing it to integrate multiple sources of useful information. To showcase the utility of the NBEATSx model, we conduct a comprehensive study of its application to electricity price forecasting (EPF) tasks across a broad range of years and markets. We observe state-of-the-art performance, significantly improving the forecast accuracy by nearly 20% over the original NBEATS model, and by up to 5% over other well established statistical and machine learning methods specialized for these tasks. Additionally, the proposed neural network has an interpretable configuration that can structurally decompose time series, visualizing the relative impact of trend and seasonal components and revealing the modeled processes' interactions with exogenous factors. To assist related work we made the code available in https://github.com/cchallu/nbeatsx.
An Information-Theoretic Analysis of Thompson Sampling
Jun 08, 2015We provide an information-theoretic analysis of Thompson sampling that applies across a broad range of online optimization problems in which a decision-maker must learn from partial feedback. This analysis inherits the simplicity and elegance of information theory and leads to regret bounds that scale with the entropy of the optimal-action distribution. This strengthens preexisting results and yields new insight into how information improves performance.
A Two-stage Framework for Compound Figure Separation
Jan 25, 2021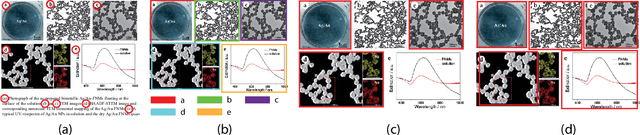
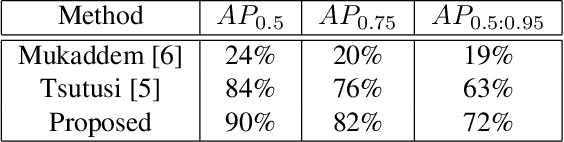
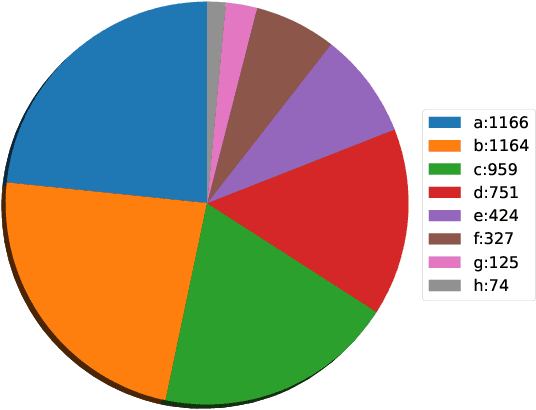
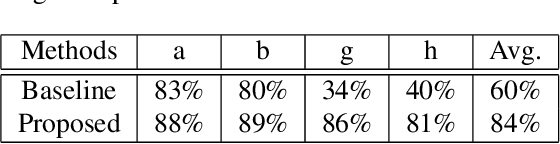
Scientific literature contains large volumes of complex, unstructured figures that are compound in nature (i.e. composed of multiple images, graphs, and drawings). Separation of these compound figures is critical for information retrieval from these figures. In this paper, we propose a new strategy for compound figure separation, which decomposes the compound figures into constituent subfigures while preserving the association between the subfigures and their respective caption components. We propose a two-stage framework to address the proposed compound figure separation problem. In particular, the subfigure label detection module detects all subfigure labels in the first stage. Then, in the subfigure detection module, the detected subfigure labels help to detect the subfigures by optimizing the feature selection process and providing the global layout information as extra features. Extensive experiments are conducted to validate the effectiveness and superiority of the proposed framework, which improves the detection precision by 9%.
3D Convolutional Neural Networks for Ultrasound-Based Silent Speech Interfaces
Apr 23, 2021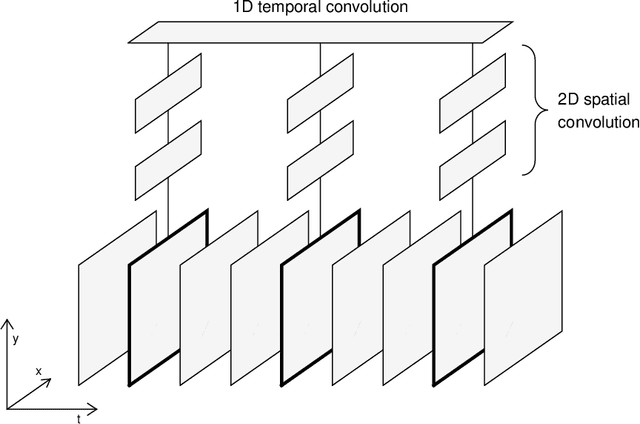
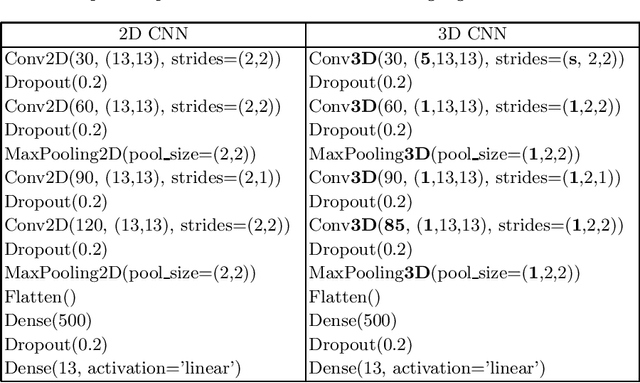

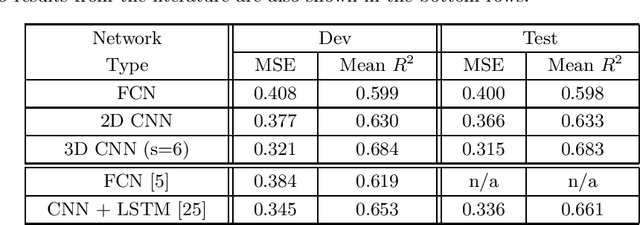
Silent speech interfaces (SSI) aim to reconstruct the speech signal from a recording of the articulatory movement, such as an ultrasound video of the tongue. Currently, deep neural networks are the most successful technology for this task. The efficient solution requires methods that do not simply process single images, but are able to extract the tongue movement information from a sequence of video frames. One option for this is to apply recurrent neural structures such as the long short-term memory network (LSTM) in combination with 2D convolutional neural networks (CNNs). Here, we experiment with another approach that extends the CNN to perform 3D convolution, where the extra dimension corresponds to time. In particular, we apply the spatial and temporal convolutions in a decomposed form, which proved very successful recently in video action recognition. We find experimentally that our 3D network outperforms the CNN+LSTM model, indicating that 3D CNNs may be a feasible alternative to CNN+LSTM networks in SSI systems.
Adapted Human Pose: Monocular 3D Human Pose Estimation with Zero Real 3D Pose Data
May 23, 2021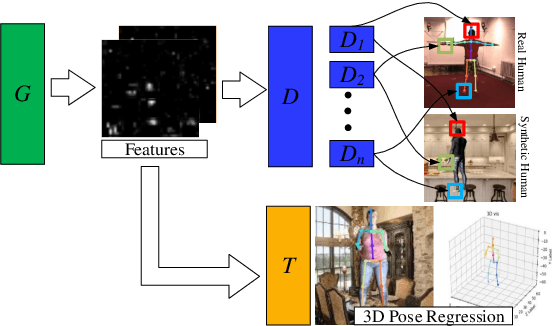
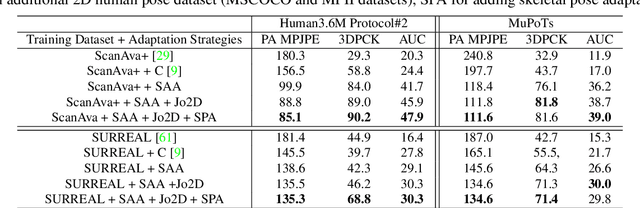
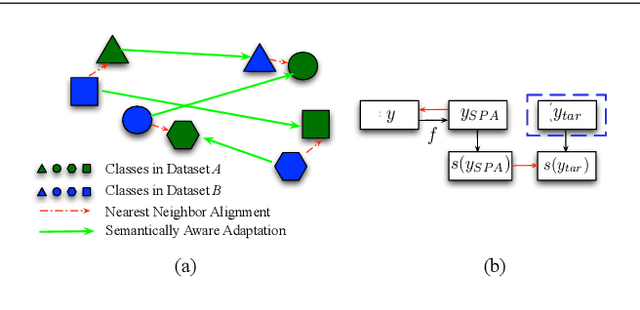
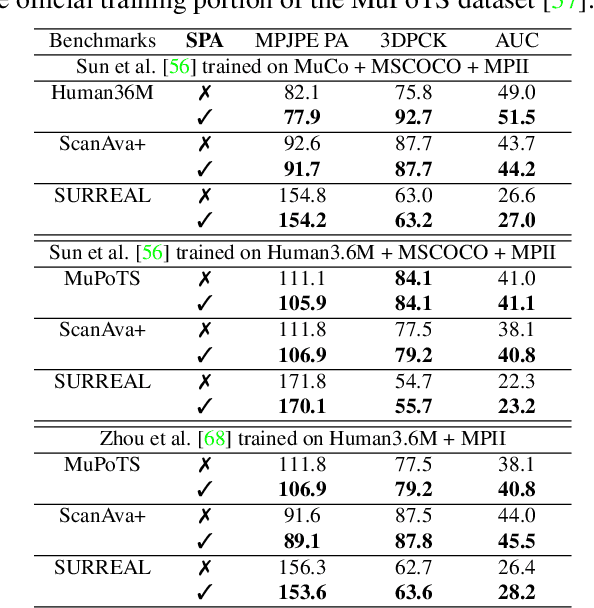
The ultimate goal for an inference model is to be robust and functional in real life applications. However, training vs. test data domain gaps often negatively affect model performance. This issue is especially critical for the monocular 3D human pose estimation problem, in which 3D human data is often collected in a controlled lab setting. In this paper, we focus on alleviating the negative effect of domain shift by presenting our adapted human pose (AHuP) approach that addresses adaptation problems in both appearance and pose spaces. AHuP is built around a practical assumption that in real applications, data from target domain could be inaccessible or only limited information can be acquired. We illustrate the 3D pose estimation performance of AHuP in two scenarios. First, when source and target data differ significantly in both appearance and pose spaces, in which we learn from synthetic 3D human data (with zero real 3D human data) and show comparable performance with the state-of-the-art 3D pose estimation models that have full access to the real 3D human pose benchmarks for training. Second, when source and target datasets differ mainly in the pose space, in which AHuP approach can be applied to further improve the performance of the state-of-the-art models when tested on the datasets different from their training dataset.