 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coupled Feature Learning for Multimodal Medical Image Fusion
Feb 17, 2021
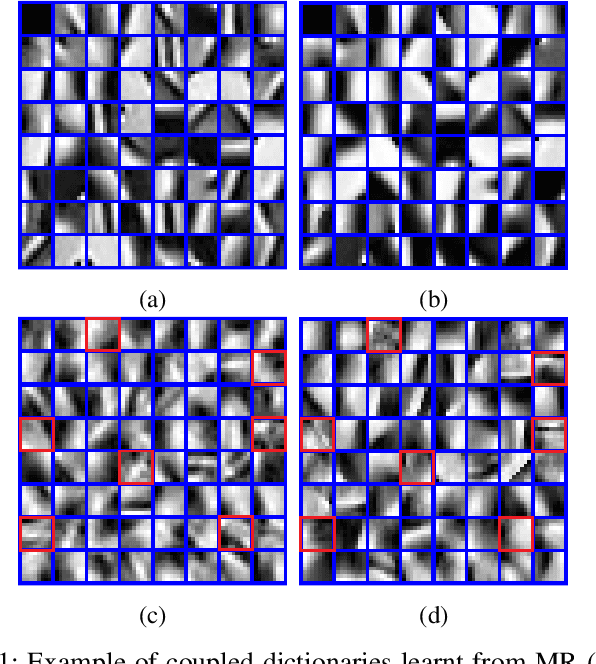
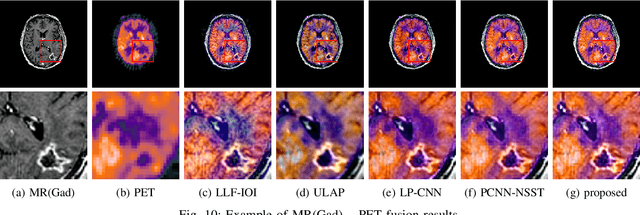
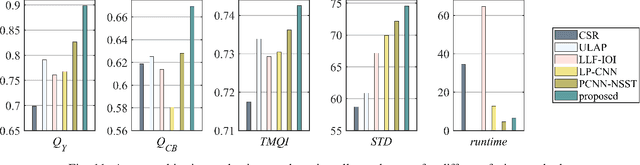
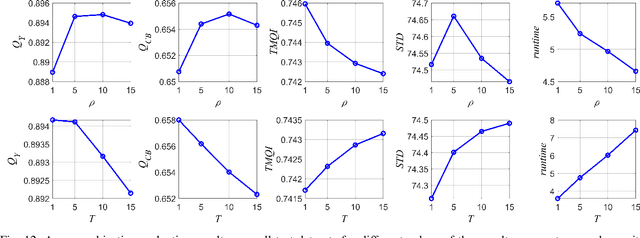
Multimodal image fusion aims to combine relevant information from images acquired with different sensors. In medical imaging, fused images play an essential role in both standard and automated diagnosis. In this paper, we propose a novel multimodal image fusion method based on coupled dictionary learning. The proposed method is general and can be employed for different medical imaging modalities. Unlike many current medical fusion methods, the proposed approach does not suffer from intensity attenuation nor loss of critical information. Specifically, the images to be fused are decomposed into coupled and independent components estimated using sparse representations with identical supports and a Pearson correlation constraint, respectively. An alternating minimization algorithm is designed to solve the resulting optimization problem. The final fusion step uses the max-absolute-value rule. Experiments are conducted using various pairs of multimodal inputs, including real MR-CT and MR-PET images. The resulting performance and execution times show the competitiveness of the proposed method in comparison with state-of-the-art medical image fusion methods.
Operation Embeddings for Neural Architecture Search
May 11, 2021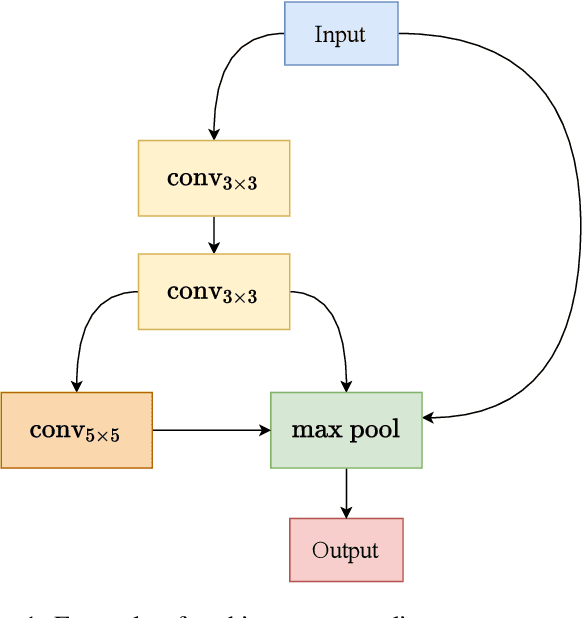
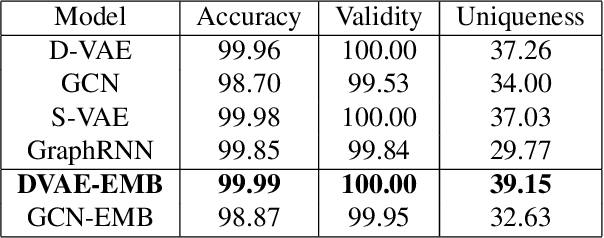
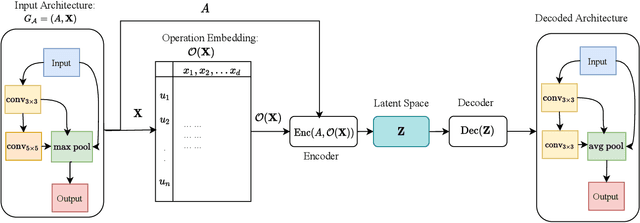
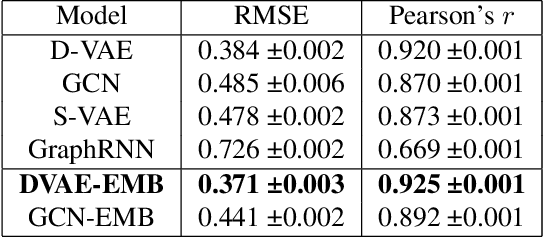
Neural Architecture Search (NAS) has recently gained increased attention, as a class of approaches that automatically searches in an input space of network architectures. A crucial part of the NAS pipeline is the encoding of the architecture that consists of the applied computational blocks, namely the operations and the links between them. Most of the existing approaches either fail to capture the structural properties of the architectures or use a hand-engineered vector to encode the operator information. In this paper, we propose the replacement of fixed operator encoding with learnable representations in the optimization process. This approach, which effectively captures the relations of different operations, leads to smoother and more accurate representations of the architectures and consequently to improved performance of the end task. Our extensive evaluation in ENAS benchmark demonstrates the effectiveness of the proposed operation embeddings to the generation of highly accurate models, achieving state-of-the-art performance. Finally, our method produces top-performing architectures that share similar operation and graph patterns, highlighting a strong correlation between architecture's structural properties and performance.
Improving the Transient Times for Distributed Stochastic Gradient Methods
May 11, 2021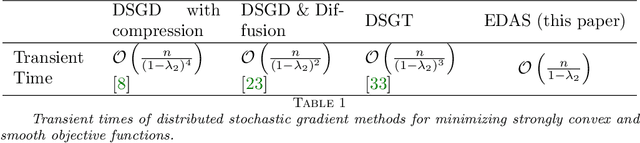
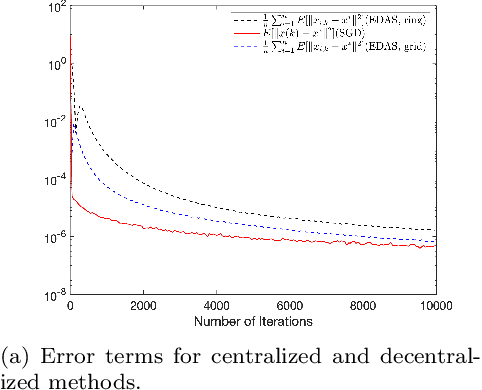
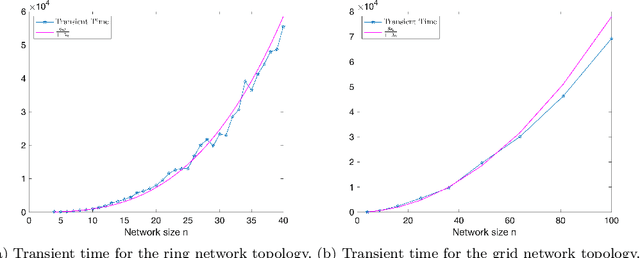
We consider the distributed optimization problem where $n$ agents each possessing a local cost function, collaboratively minimize the average of the $n$ cost functions over a connected network. Assuming stochastic gradient information is available, we study a distributed stochastic gradient algorithm, called exact diffusion with adaptive stepsizes (EDAS) adapted from the Exact Diffusion method and NIDS and perform a non-asymptotic convergence analysis. We not only show that EDAS asymptotically achieves the same network independent convergence rate as centralized stochastic gradient descent (SGD) for minimizing strongly convex and smooth objective functions, but also characterize the transient time needed for the algorithm to approach the asymptotic convergence rate, which behaves as $K_T=\mathcal{O}\left(\frac{n}{1-\lambda_2}\right)$, where $1-\lambda_2$ stands for the spectral gap of the mixing matrix. To the best of our knowledge, EDAS achieves the shortest transient time when the average of the $n$ cost functions is strongly convex and each cost function is smooth. Numerical simulations further corroborate and strengthen the obtained theoretical results.
Hybrid Device-to-Device and Device-to-Vehicle Networks for Energy-Efficient Emergency Communication
May 26, 2021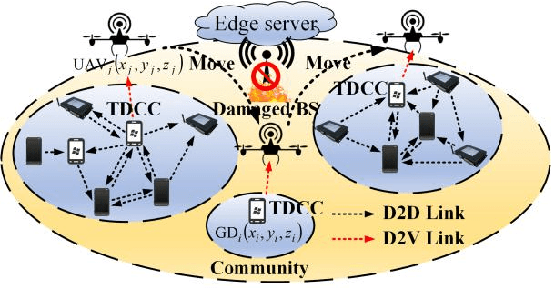

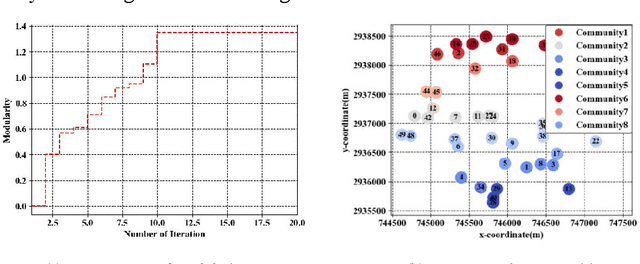

Considering the energy-efficient emergency response, subject to a given set of constraints on emergency communication networks (ECN), this article proposes a hybrid device-to-device (D2D) and device-to-vehicle (D2V) network for collecting and transmitting emergency information. First, we establish the D2D network from the perspective of complex networks by jointly determining the optimal network partition (ONP) and the temporary data caching centers (TDCC), and thus emergency data can be forwarded and cached in TDCCs. Second, based on the distribution of TDCCs, the D2V network is established by unmanned aerial vehicles (UAV)-based waypoint and motion planning, which saves the time for wireless transmission and aerial moving. Finally, the amount of time for emergency response and the total energy consumption are simultaneously minimized by a multiobjective evolutionary algorithm based on decomposition (MOEA/D), subject to a given set of minimum signal-to-interference-plus-noise ratio (SINR), number of UAVs, transmit power, and energy constraints. Simulation results show that the proposed method significantly improves response efficiency and reasonably controls the energy, thus overcoming limitations of existing ECNs. Therefore, this network effectively solves the key problem in the rescue system and makes great contributions to post-disaster decision-making.
Conditional Generation of Medical Images via Disentangled Adversarial Inference
Dec 08, 2020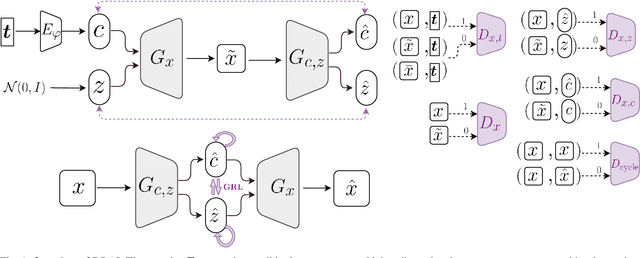
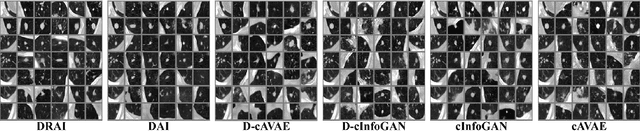


Synthetic medical image generation has a huge potential for improving healthcare through many applications, from data augmentation for training machine learning systems to preserving patient privacy. Conditional Adversarial Generative Networks (cGANs) use a conditioning factor to generate images and have shown great success in recent years. Intuitively, the information in an image can be divided into two parts: 1) content which is presented through the conditioning vector and 2) style which is the undiscovered information missing from the conditioning vector. Current practices in using cGANs for medical image generation, only use a single variable for image generation (i.e., content) and therefore, do not provide much flexibility nor control over the generated image. In this work we propose a methodology to learn from the image itself, disentangled representations of style and content, and use this information to impose control over the generation process. In this framework, style is learned in a fully unsupervised manner, while content is learned through both supervised learning (using the conditioning vector) and unsupervised learning (with the inference mechanism). We undergo two novel regularization steps to ensure content-style disentanglement. First, we minimize the shared information between content and style by introducing a novel application of the gradient reverse layer (GRL); second, we introduce a self-supervised regularization method to further separate information in the content and style variables. We show that in general, two latent variable models achieve better performance and give more control over the generated image. We also show that our proposed model (DRAI) achieves the best disentanglement score and has the best overall performance.
Word Embedding-based Text Processing for Comprehensive Summarization and Distinct Information Extraction
Apr 21, 2020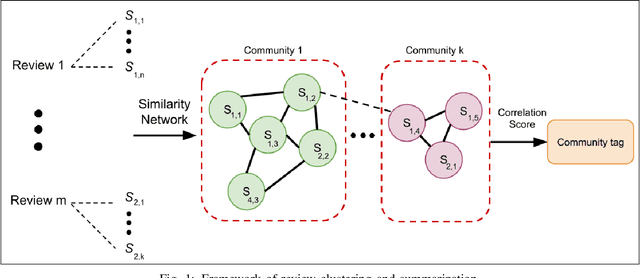
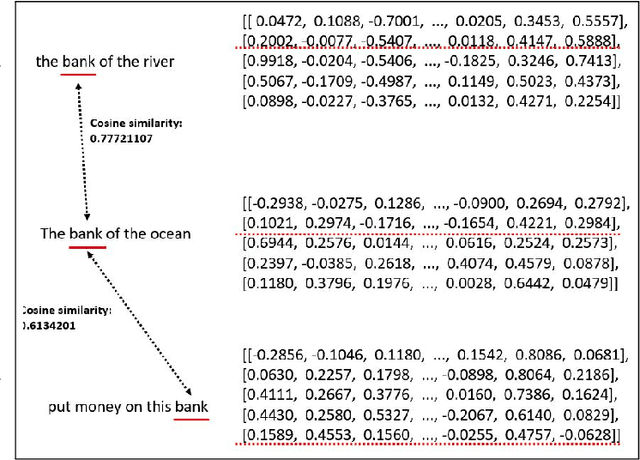

In this paper, we propose two automated text processing frameworks specifically designed to analyze online reviews. The objective of the first framework is to summarize the reviews dataset by extracting essential sentence. This is performed by converting sentences into numerical vectors and clustering them using a community detection algorithm based on their similarity levels. Afterwards, a correlation score is measured for each sentence to determine its importance level in each cluster and assign it as a tag for that community. The second framework is based on a question-answering neural network model trained to extract answers to multiple different questions. The collected answers are effectively clustered to find multiple distinct answers to a single question that might be asked by a customer. The proposed frameworks are shown to be more comprehensive than existing reviews processing solutions.
Dense Nested Attention Network for Infrared Small Target Detection
Jun 01, 2021

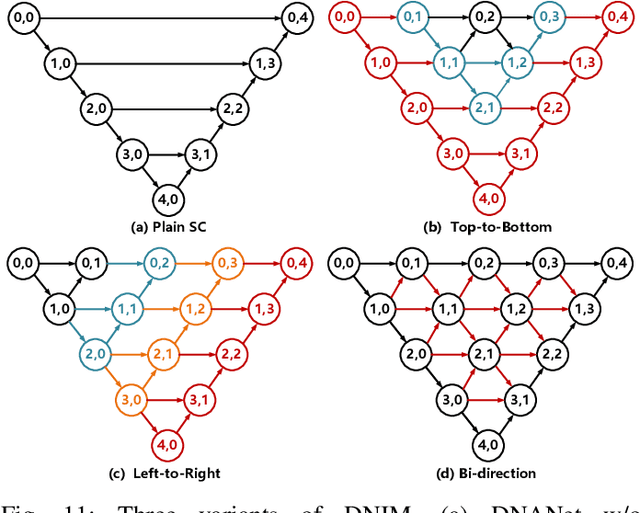
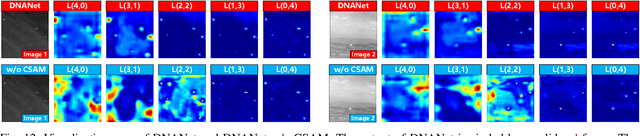
Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds. With the advances of deep learning, CNN-based methods have yielded promising results in generic object detection due to their powerful modeling capability. However, existing CNN-based methods cannot be directly applied for infrared small targets since pooling layers in their networks could lead to the loss of targets in deep layers. To handle this problem, we propose a dense nested attention network (DNANet) in this paper. Specifically, we design a dense nested interactive module (DNIM) to achieve progressive interaction among high-level and low-level features. With the repeated interaction in DNIM, infrared small targets in deep layers can be maintained. Based on DNIM, we further propose a cascaded channel and spatial attention module (CSAM) to adaptively enhance multi-level features. With our DNANet, contextual information of small targets can be well incorporated and fully exploited by repeated fusion and enhancement. Moreover, we develop an infrared small target dataset (namely, NUDT-SIRST) and propose a set of evaluation metrics to conduct comprehensive performance evaluation. Experiments on both public and our self-developed datasets demonstrate the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of probability of detection (Pd), false-alarm rate (Fa), and intersection of union (IoU).
NPRF: A Neural Pseudo Relevance Feedback Framework for Ad-hoc Information Retrieval
Oct 30, 2018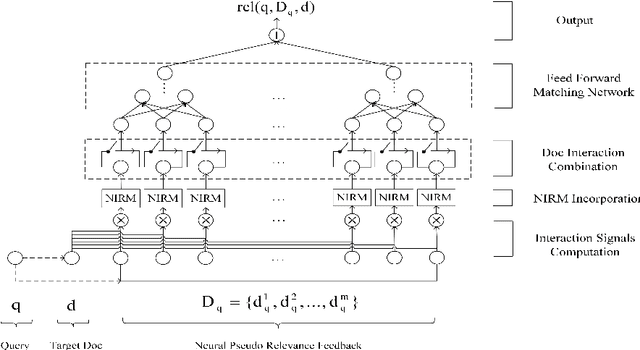
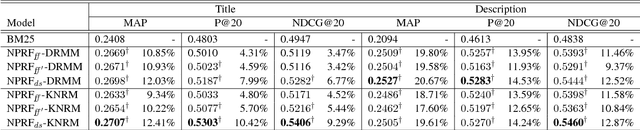
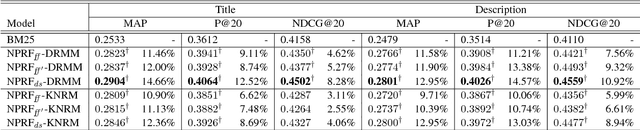
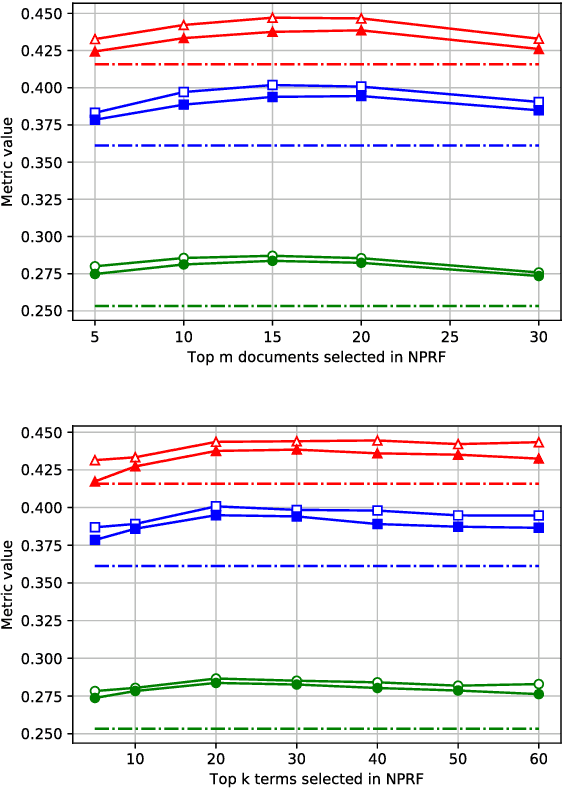
Pseudo-relevance feedback (PRF) is commonly used to boost the performance of traditional information retrieval (IR) models by using top-ranked documents to identify and weight new query terms, thereby reducing the effect of query-document vocabulary mismatches. While neural retrieval models have recently demonstrated strong results for ad-hoc retrieval, combining them with PRF is not straightforward due to incompatibilities between existing PRF approaches and neural architectures. To bridge this gap, we propose an end-to-end neural PRF framework that can be used with existing neural IR models by embedding different neural models as building blocks. Extensive experiments on two standard test collections confirm the effectiveness of the proposed NPRF framework in improving the performance of two state-of-the-art neural IR models.
Monocular Quasi-Dense 3D Object Tracking
Mar 12, 2021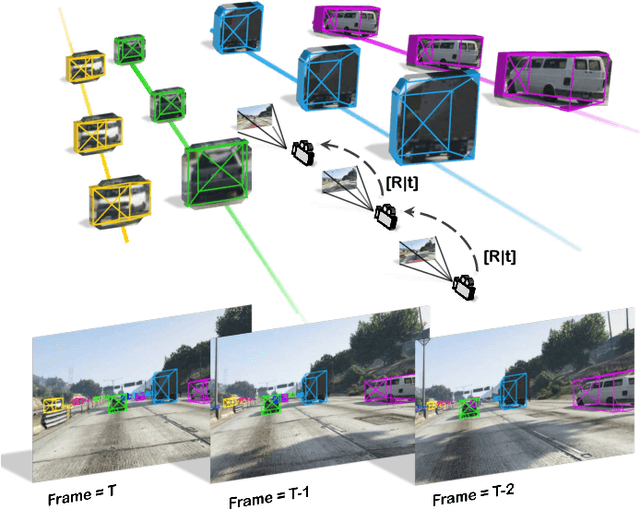
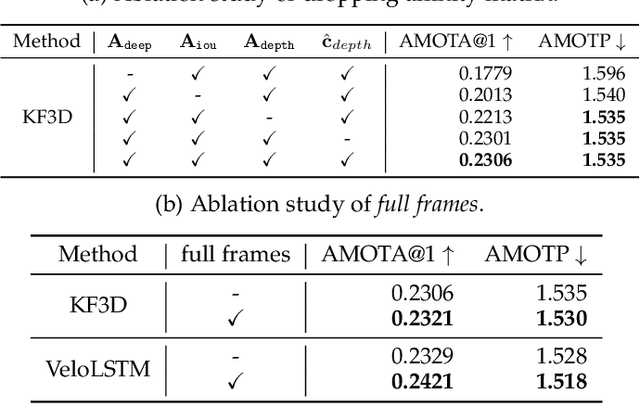
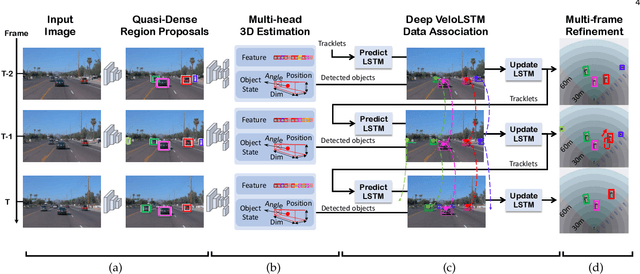
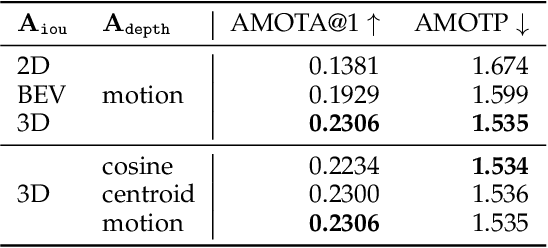
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021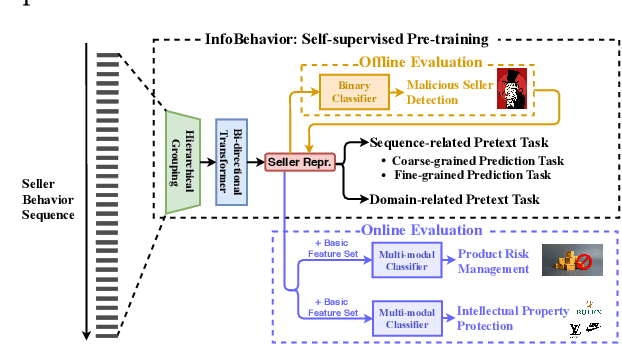
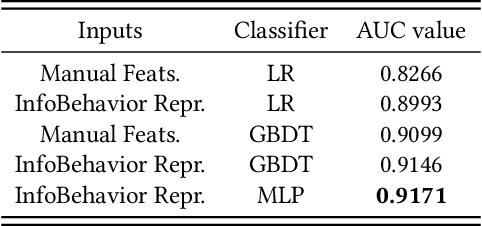
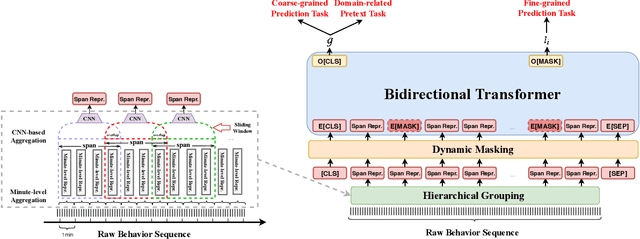
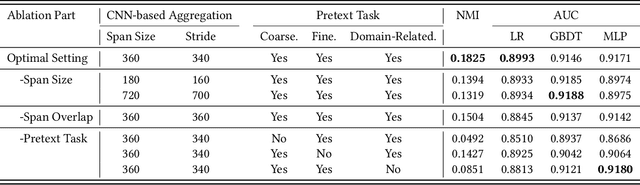
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.