 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Higher-order tensor independent component analysis to realize MIMO remote sensing of respiration and heartbeat signals
May 03, 2021
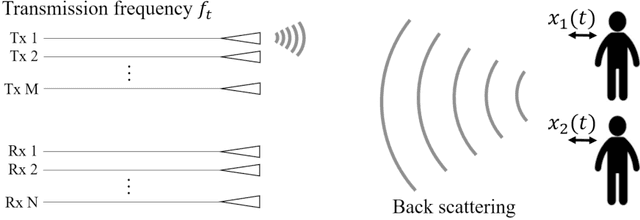
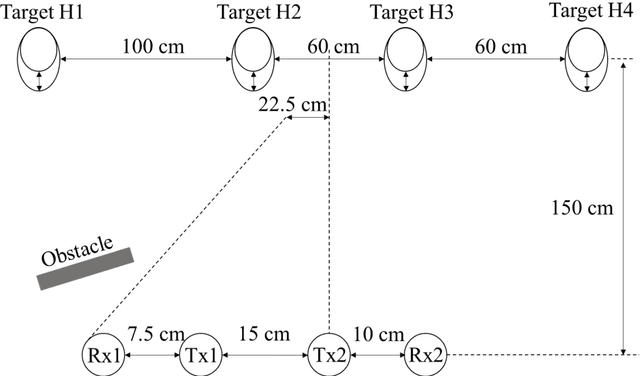
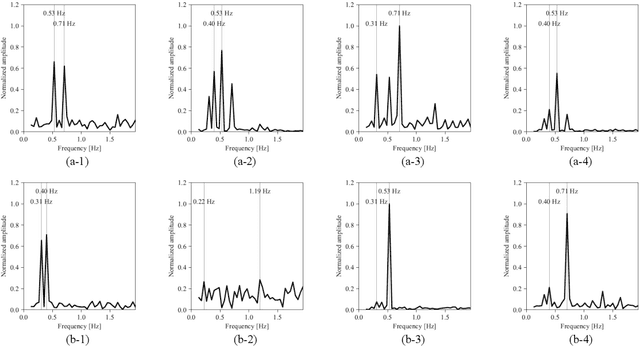
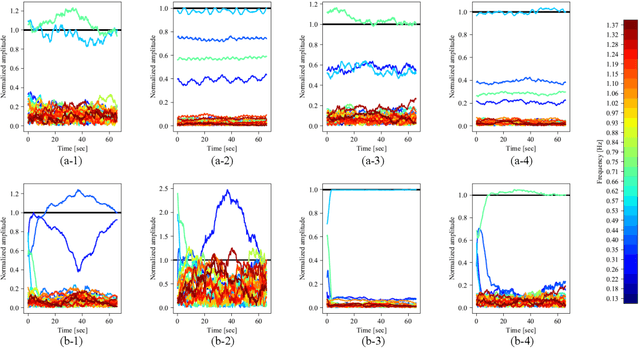
This paper proposes a novel method of independent component analysis (ICA), which we name higher-order tensor ICA (HOT-ICA). HOT-ICA is a tensor ICA that makes effective use of the signal categories represented by the axes of a separating tensor. Conventional tensor ICAs, such as multilinear ICA (MICA) based on Tucker decomposition, do not fully utilize the high dimensionality of tensors because the matricization in MICA nullifies the tensor axial categorization. In this paper, we deal with multiple-target signal separation in a multiple-input multiple-output (MIMO) radar system to detect respiration and heartbeat. HOT-ICA realizes high robustness in learning by incorporating path information, i.e., the physical-measurement categories on which transmitting/receiving antennas were used. In numerical-physical experiments, our HOT-ICA system effectively separate the bio-signals successfully even in an obstacle-affecting environment, which is usually a difficult task. The results demonstrate the significance of the HOT-ICA, which keeps the tensor categorization unchanged for full utilization of the high-dimensionality of the separation tensor.
DeepProbe: Information Directed Sequence Understanding and Chatbot Design via Recurrent Neural Networks
Mar 01, 2018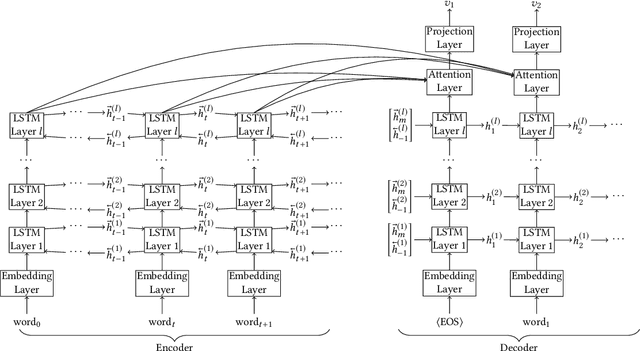

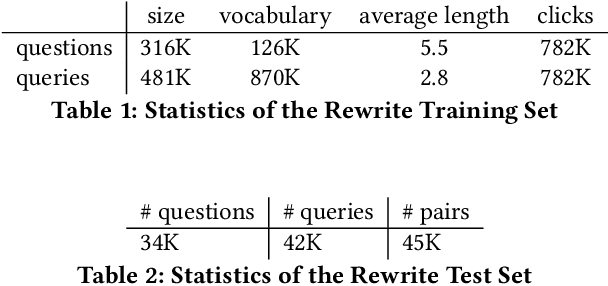
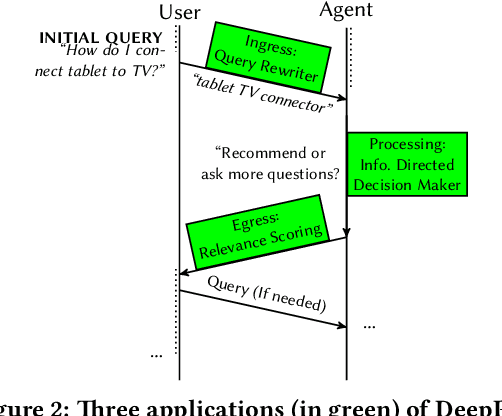
Information extraction and user intention identification are central topics in modern query understanding and recommendation systems. In this paper, we propose DeepProbe, a generic information-directed interaction framework which is built around an attention-based sequence to sequence (seq2seq) recurrent neural network. DeepProbe can rephrase, evaluate, and even actively ask questions, leveraging the generative ability and likelihood estimation made possible by seq2seq models. DeepProbe makes decisions based on a derived uncertainty (entropy) measure conditioned on user inputs, possibly with multiple rounds of interactions. Three applications, namely a rewritter, a relevance scorer and a chatbot for ad recommendation, were built around DeepProbe, with the first two serving as precursory building blocks for the third. We first use the seq2seq model in DeepProbe to rewrite a user query into one of standard query form, which is submitted to an ordinary recommendation system. Secondly, we evaluate DeepProbe's seq2seq model-based relevance scoring. Finally, we build a chatbot prototype capable of making active user interactions, which can ask questions that maximize information gain, allowing for a more efficient user intention idenfication process. We evaluate first two applications by 1) comparing with baselines by BLEU and AUC, and 2) human judge evaluation. Both demonstrate significant improvements compared with current state-of-the-art systems, proving their values as useful tools on their own, and at the same time laying a good foundation for the ongoing chatbot application.
Graph Learning: A Survey
May 03, 2021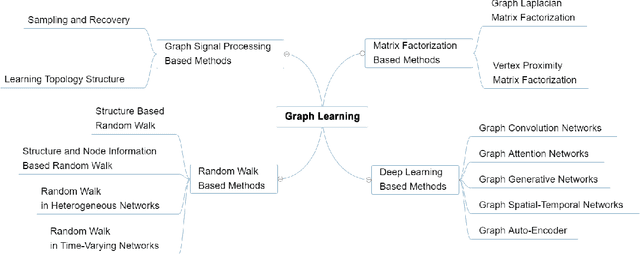
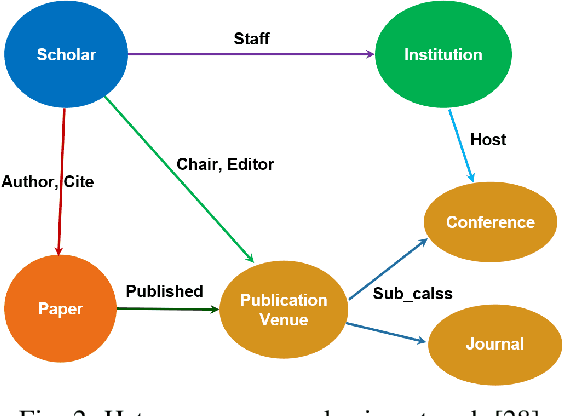
Graphs are widely used as a popular representation of the network structure of connected data. Graph data can be found in a broad spectrum of application domains such as social systems, ecosystems, biological networks, knowledge graphs, and information systems. With the continuous penetration of artificial intelligence technologies, graph learning (i.e., machine learning on graphs) is gaining attention from both researchers and practitioners. Graph learning proves effective for many tasks, such as classification, link prediction, and matching. Generally, graph learning methods extract relevant features of graphs by taking advantage of machine learning algorithms. In this survey, we present a comprehensive overview on the state-of-the-art of graph learning. Special attention is paid to four categories of existing graph learning methods, including graph signal processing, matrix factorization, random walk, and deep learning. Major models and algorithms under these categories are reviewed respectively. We examine graph learning applications in areas such as text, images, science, knowledge graphs, and combinatorial optimization. In addition, we discuss several promising research directions in this field.
* 19 pages, 6 figures
What is Wrong with One-Class Anomaly Detection?
Apr 20, 2021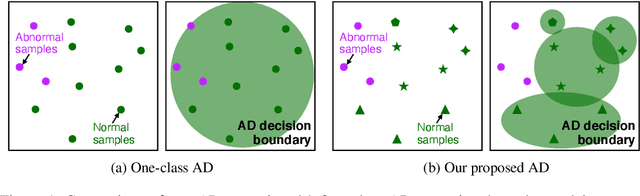
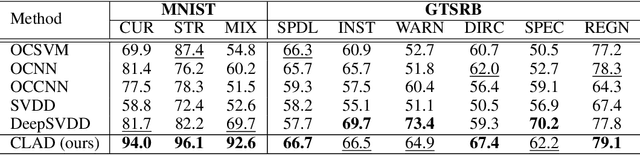
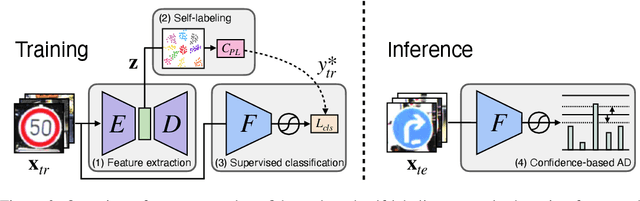
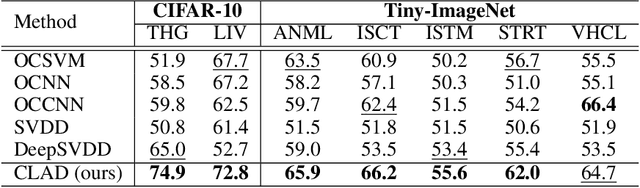
From a safety perspective, a machine learning method embedded in real-world applications is required to distinguish irregular situations. For this reason, there has been a growing interest in the anomaly detection (AD) task. Since we cannot observe abnormal samples for most of the cases, recent AD methods attempt to formulate it as a task of classifying whether the sample is normal or not. However, they potentially fail when the given normal samples are inherited from diverse semantic labels. To tackle this problem, we introduce a latent class-condition-based AD scenario. In addition, we propose a confidence-based self-labeling AD framework tailored to our proposed scenario. Since our method leverages the hidden class information, it successfully avoids generating the undesirable loose decision region that one-class methods suffer. Our proposed framework outperforms the recent one-class AD methods in the latent multi-class scenarios.
Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Feb 16, 2018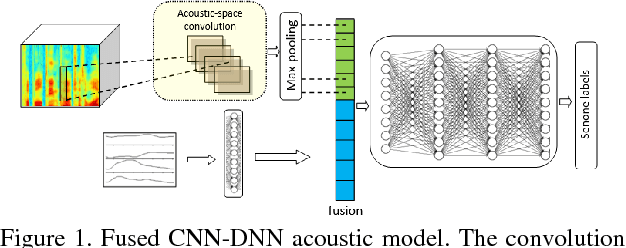
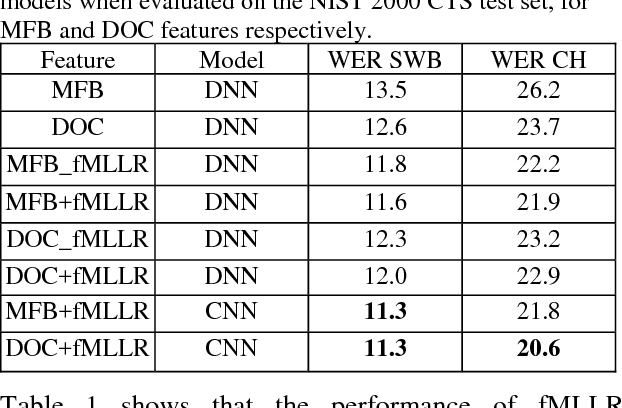
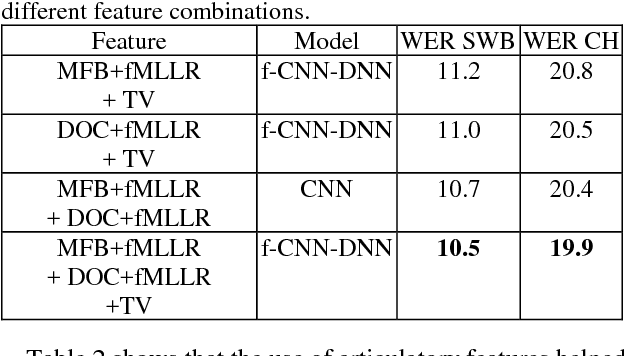
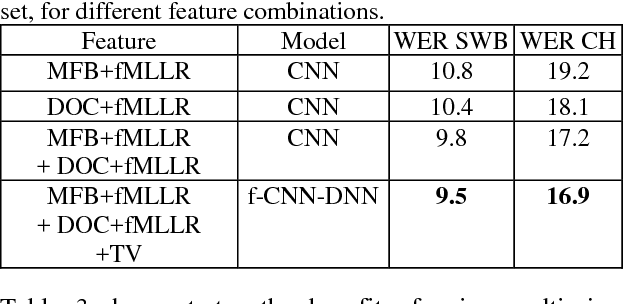
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.
Sums of Separable and Quadratic Polynomials
May 11, 2021
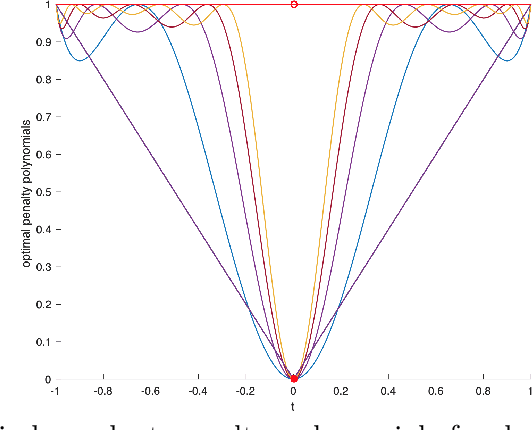

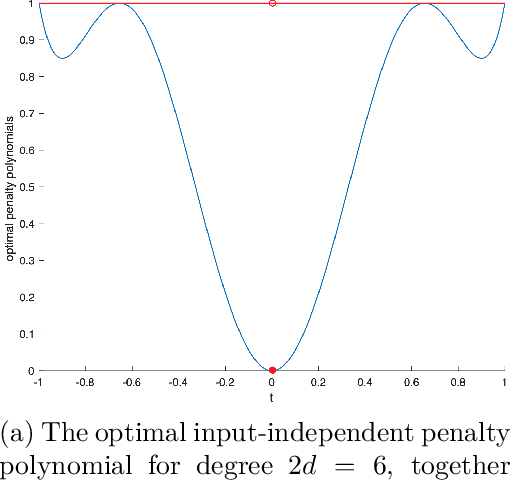
We study separable plus quadratic (SPQ) polynomials, i.e., polynomials that are the sum of univariate polynomials in different variables and a quadratic polynomial. Motivated by the fact that nonnegative separable and nonnegative quadratic polynomials are sums of squares, we study whether nonnegative SPQ polynomials are (i) the sum of a nonnegative separable and a nonnegative quadratic polynomial, and (ii) a sum of squares. We establish that the answer to question (i) is positive for univariate plus quadratic polynomials and for convex SPQ polynomials, but negative already for bivariate quartic SPQ polynomials. We use our decomposition result for convex SPQ polynomials to show that convex SPQ polynomial optimization problems can be solved by "small" semidefinite programs. For question (ii), we provide a complete characterization of the answer based on the degree and the number of variables of the SPQ polynomial. We also prove that testing nonnegativity of SPQ polynomials is NP-hard when the degree is at least four. We end by presenting applications of SPQ polynomials to upper bounding sparsity of solutions to linear programs, polynomial regression problems in statistics, and a generalization of Newton's method which incorporates separable higher-order derivative information.
Learning Passage Impacts for Inverted Indexes
Apr 24, 2021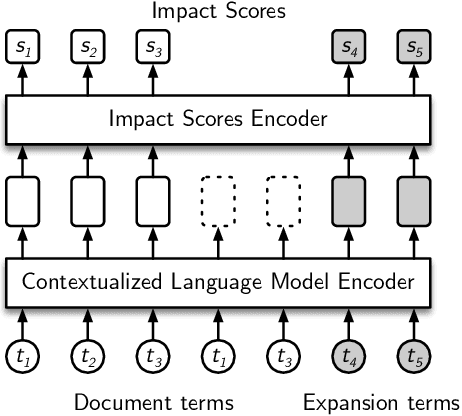

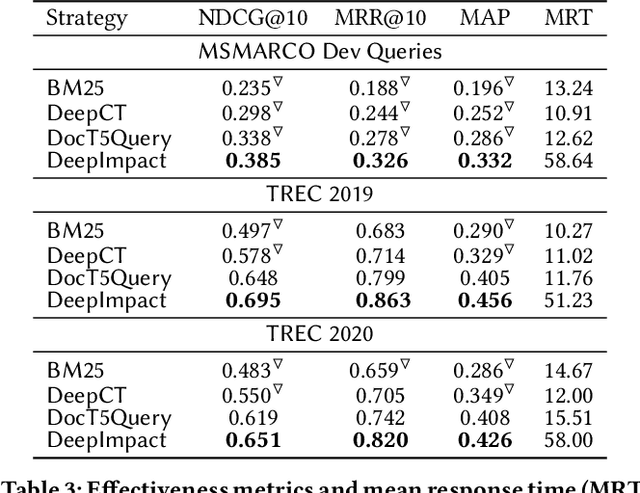
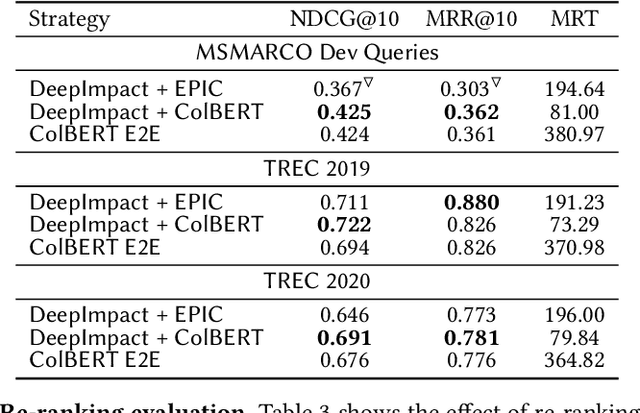
Neural information retrieval systems typically use a cascading pipeline, in which a first-stage model retrieves a candidate set of documents and one or more subsequent stages re-rank this set using contextualized language models such as BERT. In this paper, we propose DeepImpact, a new document term-weighting scheme suitable for efficient retrieval using a standard inverted index. Compared to existing methods, DeepImpact improves impact-score modeling and tackles the vocabulary-mismatch problem. In particular, DeepImpact leverages DocT5Query to enrich the document collection and, using a contextualized language model, directly estimates the semantic importance of tokens in a document, producing a single-value representation for each token in each document. Our experiments show that DeepImpact significantly outperforms prior first-stage retrieval approaches by up to 17% on effectiveness metrics w.r.t. DocT5Query, and, when deployed in a re-ranking scenario, can reach the same effectiveness of state-of-the-art approaches with up to 5.1x speedup in efficiency.
Exact information propagation through fully-connected feed forward neural networks
Jun 17, 2018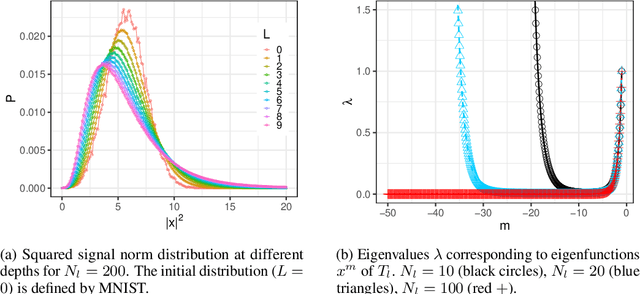
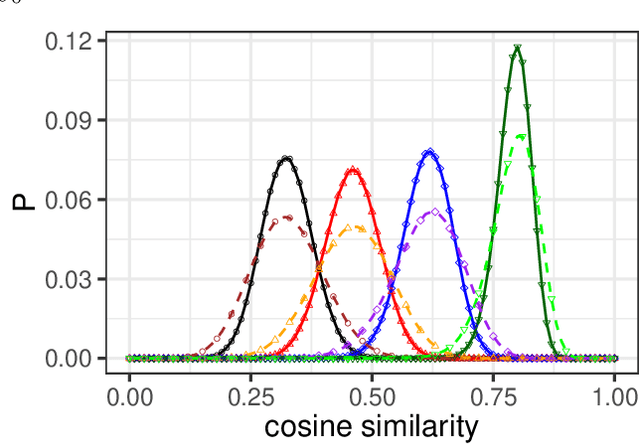
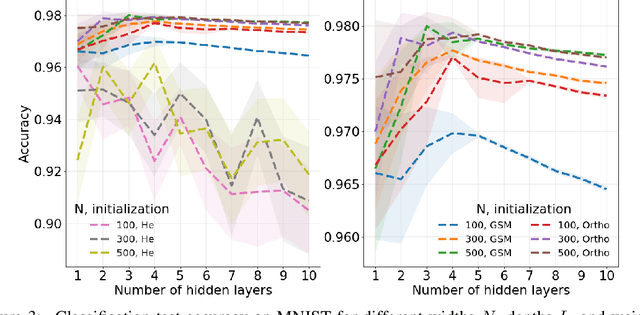
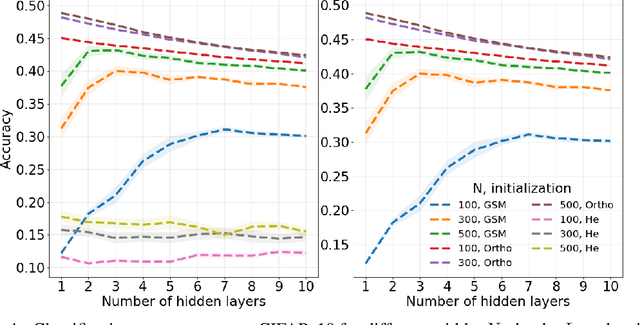
Neural network ensembles at initialisation give rise to the trainability and training speed of neural networks and thus support parameter choices at initialisation. These insights rely so far on mean field approximations that assume infinite layer width and study average squared signals. Thus, information about the full output distribution gets lost. Therefore, we derive the output distribution exactly (without mean field assumptions), for fully-connected networks with Gaussian weights and biases. The layer-wise transition of the signal distribution is guided by a linear integral operator, whose kernel has a closed form solution in case of rectified linear units for nonlinear activations. This enables us to analyze some of its spectral properties, for instance, the shape of the stationary distribution for different parameter choices and the dynamics of signal propagation.
Zero-Shot Reinforcement Learning on Graphs for Autonomous Exploration Under Uncertainty
May 11, 2021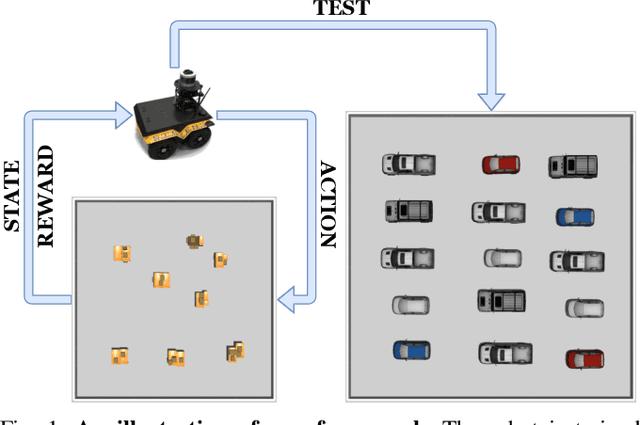


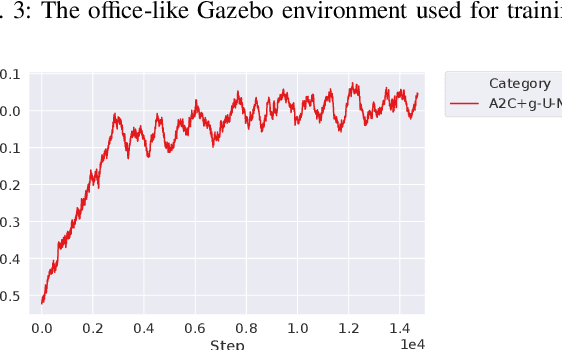
This paper studies the problem of autonomous exploration under localization uncertainty for a mobile robot with 3D range sensing. We present a framework for self-learning a high-performance exploration policy in a single simulation environment, and transferring it to other environments, which may be physical or virtual. Recent work in transfer learning achieves encouraging performance by domain adaptation and domain randomization to expose an agent to scenarios that fill the inherent gaps in sim2sim and sim2real approaches. However, it is inefficient to train an agent in environments with randomized conditions to learn the important features of its current state. An agent can use domain knowledge provided by human experts to learn efficiently. We propose a novel approach that uses graph neural networks in conjunction with deep reinforcement learning, enabling decision-making over graphs containing relevant exploration information provided by human experts to predict a robot's optimal sensing action in belief space. The policy, which is trained only in a single simulation environment, offers a real-time, scalable, and transferable decision-making strategy, resulting in zero-shot transfer to other simulation environments and even real-world environments.
MUSE: Multi-Scale Temporal Features Evolution for Knowledge Tracing
Jan 30, 2021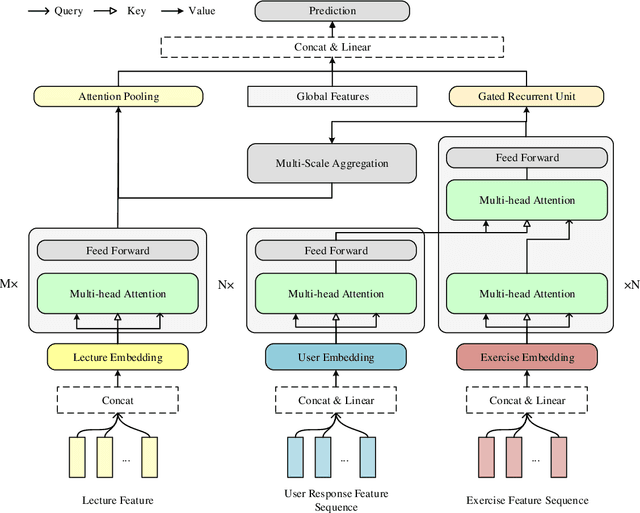
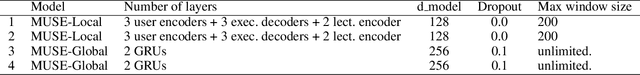
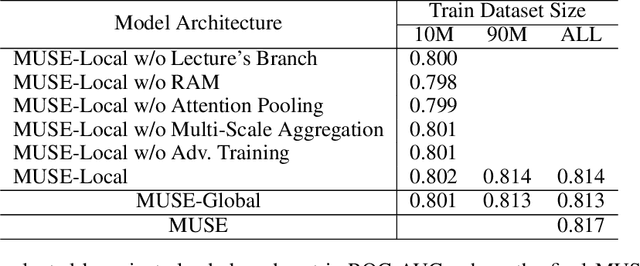
Transformer based knowledge tracing model is an extensively studied problem in the field of computer-aided education. By integrating temporal features into the encoder-decoder structure, transformers can processes the exercise information and student response information in a natural way. However, current state-of-the-art transformer-based variants still share two limitations. First, extremely long temporal features cannot well handled as the complexity of self-attention mechanism is O(n2). Second, existing approaches track the knowledge drifts under fixed a window size, without considering different temporal-ranges. To conquer these problems, we propose MUSE, which is equipped with multi-scale temporal sensor unit, that takes either local or global temporal features into consideration. The proposed model is capable to capture the dynamic changes in users knowledge states at different temporal-ranges, and provides an efficient and powerful way to combine local and global features to make predictions. Our method won the 5-th place over 3,395 teams in the Riiid AIEd Challenge 2020.