 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Shadow Generation for Composite Image in Real-world Scenes
Apr 21, 2021
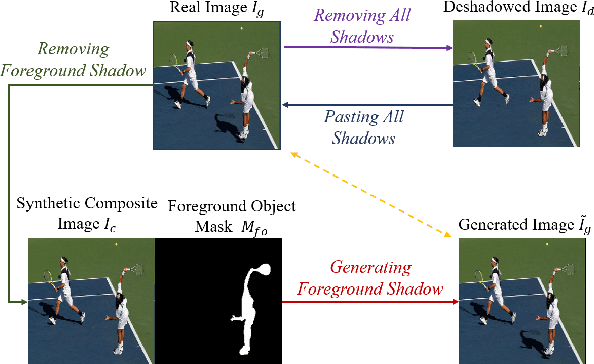
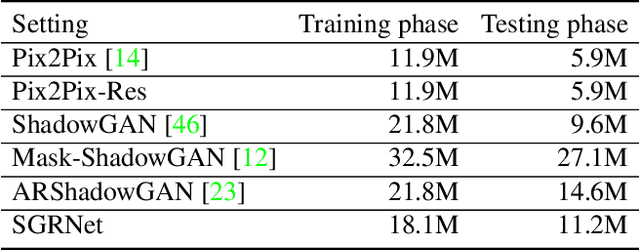

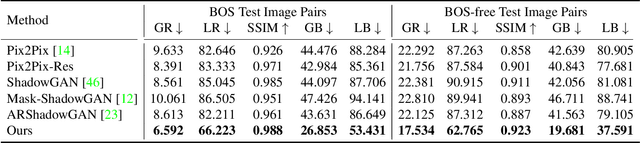
Image composition targets at inserting a foreground object on a background image. Most previous image composition methods focus on adjusting the foreground to make it compatible with background while ignoring the shadow effect of foreground on the background. In this work, we focus on generating plausible shadow for the foreground object in the composite image. First, we contribute a real-world shadow generation dataset DESOBA by generating synthetic composite images based on paired real images and deshadowed images. Then, we propose a novel shadow generation network SGRNet, which consists of a shadow mask prediction stage and a shadow filling stage. In the shadow mask prediction stage, foreground and background information are thoroughly interacted to generate foreground shadow mask. In the shadow filling stage, shadow parameters are predicted to fill the shadow area. Extensive experiments on our DESOBA dataset and real composite images demonstrate the effectiveness of our proposed method.
Streaming computation of optimal weak transport barycenters
Feb 26, 2021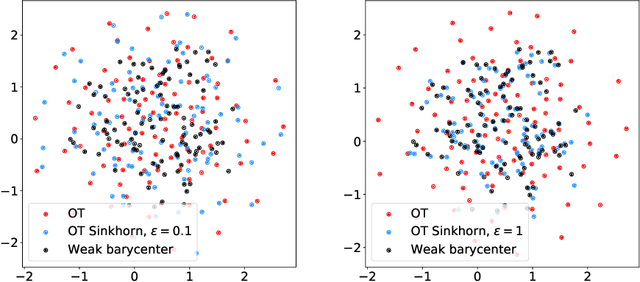
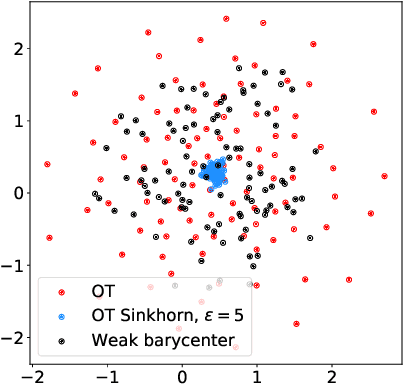
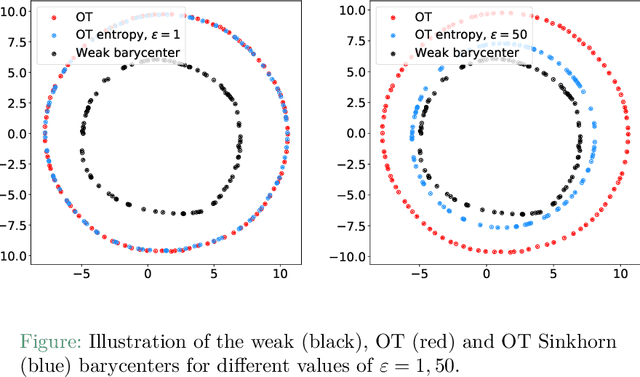
We introduce the weak barycenter of a family of probability distributions, based on the recently developed notion of optimal weak transport of measures arXiv:1412.7480(v4). We provide a theoretical analysis of the weak barycenter and its relationship to the classic Wasserstein barycenter, and discuss its meaning in the light of convex ordering between probability measures. In particular, we argue that, rather than averaging the information of the input distributions as done by the usual optimal transport barycenters, weak barycenters contain geometric information shared across all input distributions, which can be interpreted as a latent random variable affecting all the measures. We also provide iterative algorithms to compute a weak barycenter for either finite or infinite families of arbitrary measures (with finite moments of order 2), which are particularly well suited for the streaming setting, i.e., when measures arrive sequentially. In particular, our streaming computation of weak barycenters does not require to smooth empirical measures or to define a common grid for them, as some of the previous approaches to Wasserstin barycenters do. The concept of weak barycenter and our computation approaches are illustrated on synthetic examples, validated on 2D real-world data and compared to the classical Wasserstein barycenters.
LaboRecommender: A crazy-easy to use Python-based recommender system for laboratory tests
May 03, 2021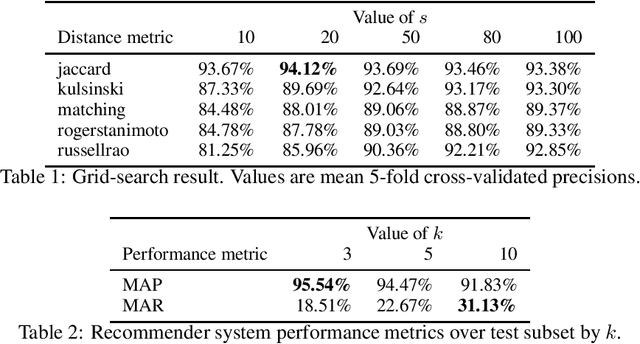
Laboratory tests play a major role in clinical decision making because they are essential for the confirmation of diagnostics suspicions and influence medical decisions. The number of different laboratory tests available to physicians in our age has been expanding very rapidly due to the rapid advances in laboratory technology. To find the correct desired tests within this expanding plethora of elements, the Health Information System must provide a powerful search engine and the practitioner need to remember the exact name of the laboratory test to correctly select the bag of tests to order. Recommender systems are platforms which suggest appropriate items to a user after learning the users' behaviour. A neighbourhood-based collaborative filtering method was used to model the recommender system, where similar bags, clustered using nearest neighbours algorithm, are used to make recommendations of tests for each other similar bag of laboratory tests. The recommender system developed in this paper achieved 95.54 % in the mean average precision metric. A fully documented Python package named LaboRecommender was developed to implement the algorithm proposed in this paper
Safe Model-based Off-policy Reinforcement Learning for Eco-Driving in Connected and Automated Hybrid Electric Vehicles
May 25, 2021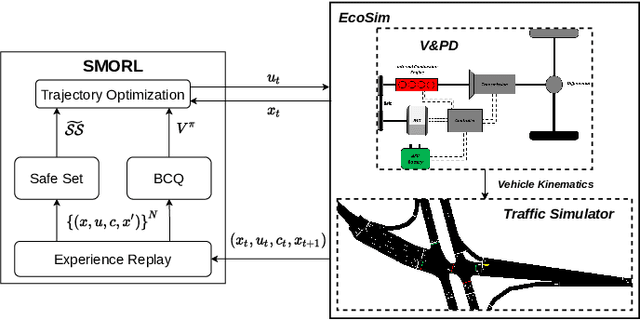
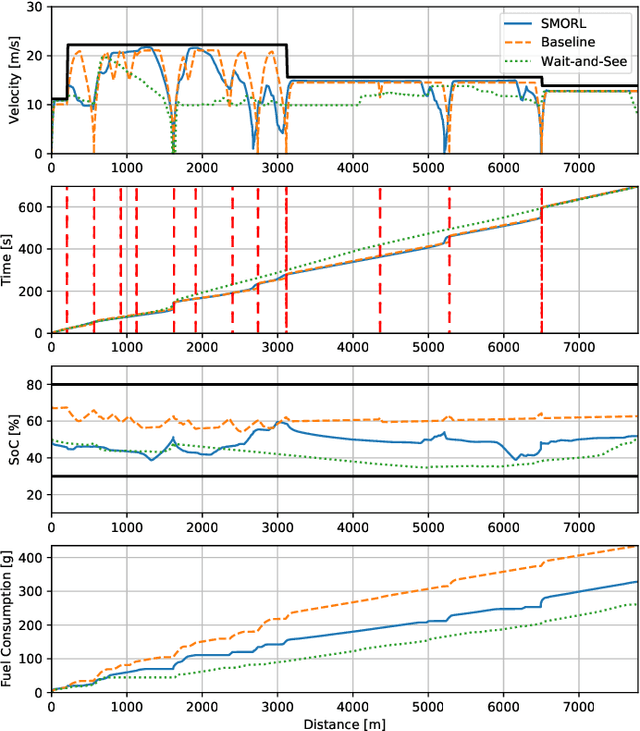
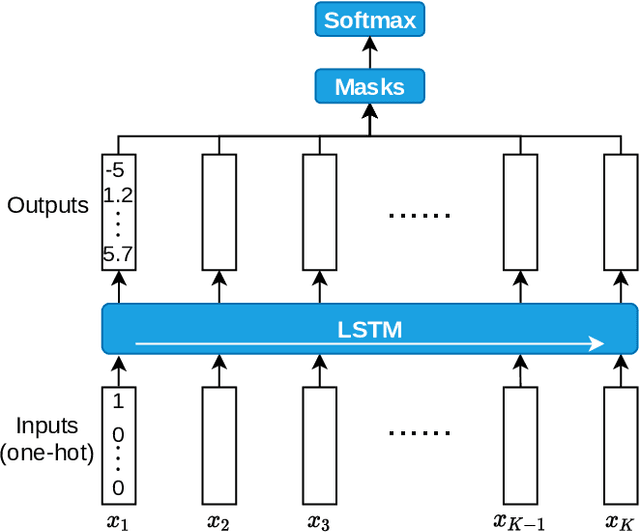
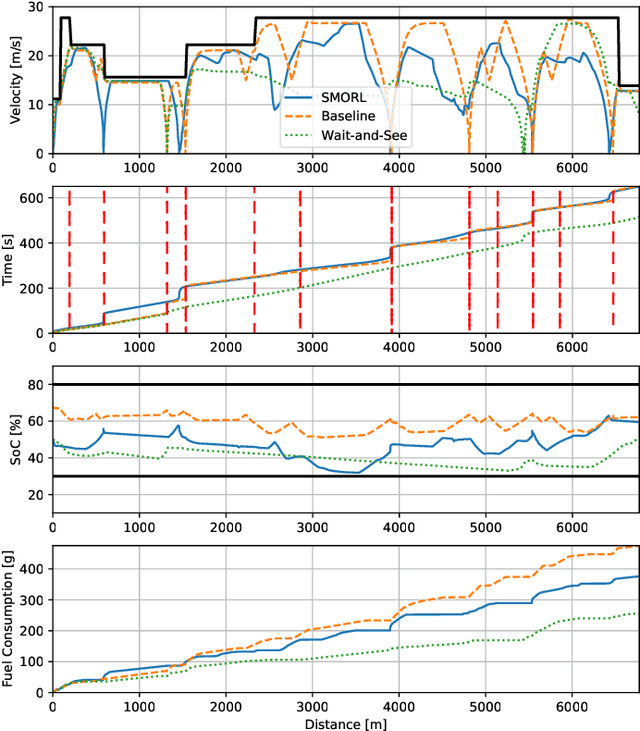
Connected and Automated Hybrid Electric Vehicles have the potential to reduce fuel consumption and travel time in real-world driving conditions. The eco-driving problem seeks to design optimal speed and power usage profiles based upon look-ahead information from connectivity and advanced mapping features. Recently, Deep Reinforcement Learning (DRL) has been applied to the eco-driving problem. While the previous studies synthesize simulators and model-free DRL to reduce online computation, this work proposes a Safe Off-policy Model-Based Reinforcement Learning algorithm for the eco-driving problem. The advantages over the existing literature are three-fold. First, the combination of off-policy learning and the use of a physics-based model improves the sample efficiency. Second, the training does not require any extrinsic rewarding mechanism for constraint satisfaction. Third, the feasibility of trajectory is guaranteed by using a safe set approximated by deep generative models. The performance of the proposed method is benchmarked against a baseline controller representing human drivers, a previously designed model-free DRL strategy, and the wait-and-see optimal solution. In simulation, the proposed algorithm leads to a policy with a higher average speed and a better fuel economy compared to the model-free agent. Compared to the baseline controller, the learned strategy reduces the fuel consumption by more than 21\% while keeping the average speed comparable.
SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
Apr 06, 2021

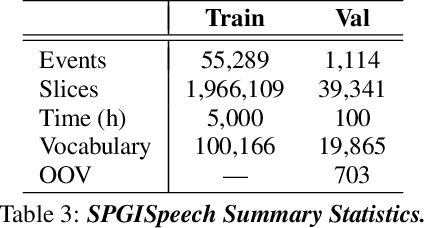
In the English speech-to-text (STT) machine learning task, acoustic models are conventionally trained on uncased Latin characters, and any necessary orthography (such as capitalization, punctuation, and denormalization of non-standard words) is imputed by separate post-processing models. This adds complexity and limits performance, as many formatting tasks benefit from semantic information present in the acoustic signal but absent in transcription. Here we propose a new STT task: end-to-end neural transcription with fully formatted text for target labels. We present baseline Conformer-based models trained on a corpus of 5,000 hours of professionally transcribed earnings calls, achieving a CER of 1.7. As a contribution to the STT research community, we release the corpus free for non-commercial use at https://datasets.kensho.com/datasets/scribe.
qRRT: Quality-Biased Incremental RRT for Optimal Motion Planning in Non-Holonomic Systems
Jan 07, 2021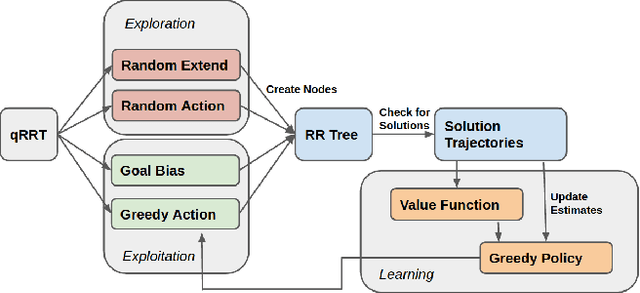
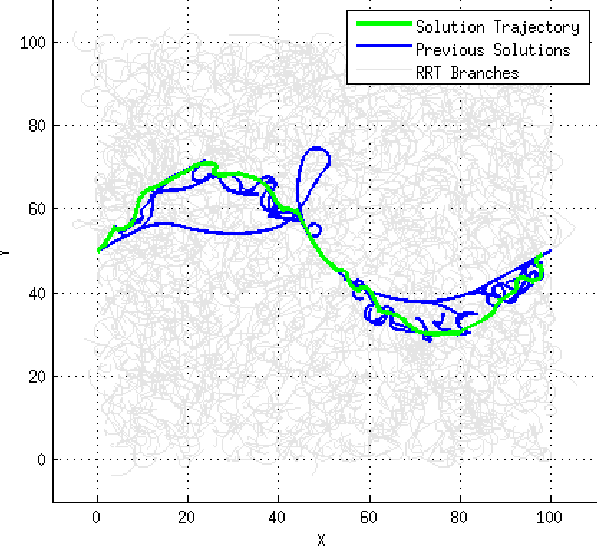
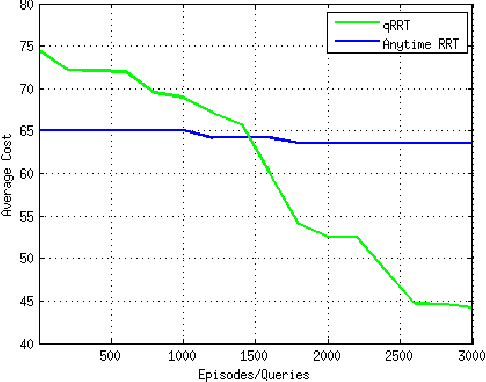
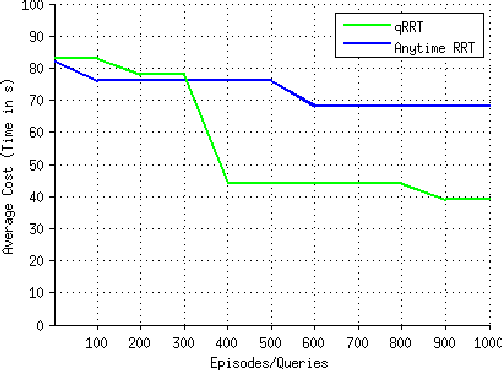
This paper presents a sampling-based method for optimal motion planning in non-holonomic systems in the absence of known cost functions. It uses the principle of learning through experience to deduce the cost-to-go of regions within the workspace. This cost information is used to bias an incremental graph-based search algorithm that produces solution trajectories. Iterative improvement of cost information and search biasing produces solutions that are proven to be asymptotically optimal. The proposed framework builds on incremental Rapidly-exploring Random Trees (RRT) for random sampling-based search and Reinforcement Learning (RL) to learn workspace costs. A series of experiments were performed to evaluate and demonstrate the performance of the proposed method.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
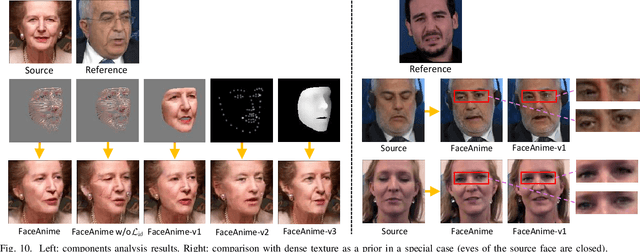
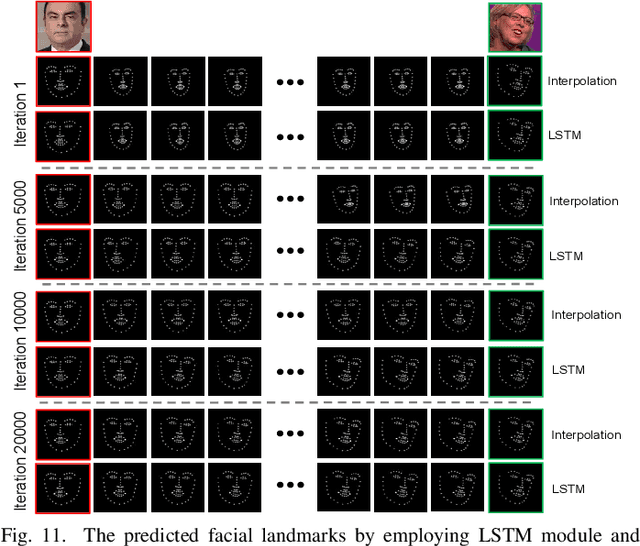
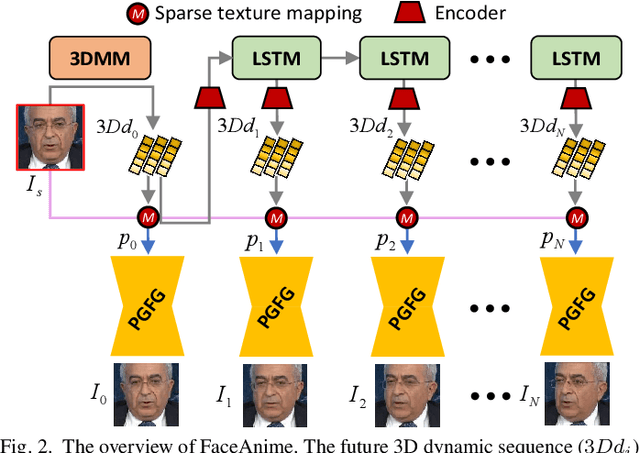
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 11, 2021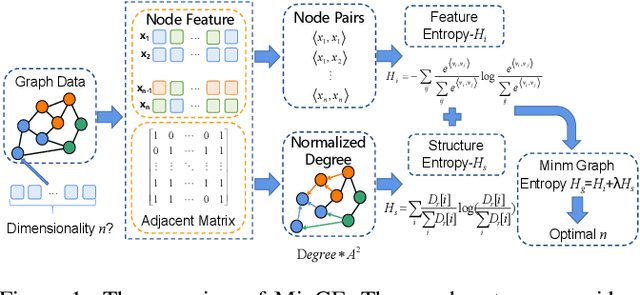
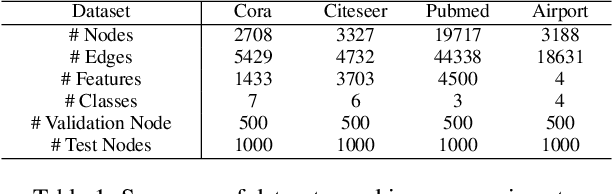
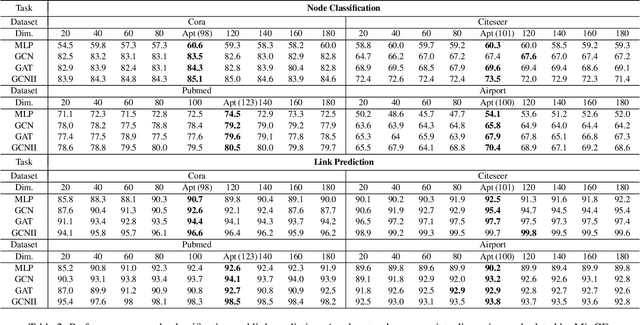
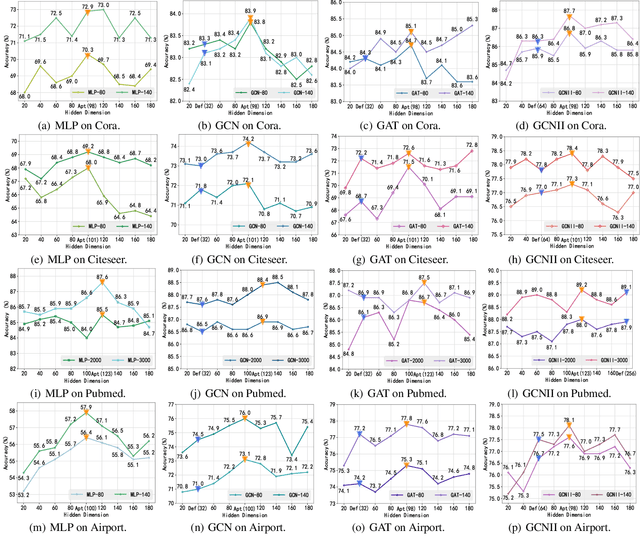
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
NLHD: A Pixel-Level Non-Local Retinex Model for Low-Light Image Enhancement
Jun 15, 2021


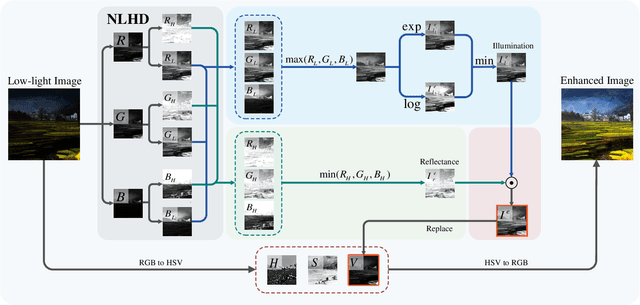
Retinex model has been applied to low-light image enhancement in many existing methods. More appropriate decomposition of a low-light image can help achieve better image enhancement. In this paper, we propose a new pixel-level non-local Haar transform based illumination and reflectance decomposition method (NLHD). The unique low-frequency coefficient of Haar transform on each similar pixel group is used to reconstruct the illumination component, and the rest of all high-frequency coefficients are employed to reconstruct the reflectance component. The complete similarity of pixels in a matched similar pixel group and the simple separable Haar transform help to obtain more appropriate image decomposition; thus, the image is hardly sharpened in the image brightness enhancement procedure. The exponential transform and logarithmic transform are respectively implemented on the illumination component. Then a minimum fusion strategy on the results of these two transforms is utilized to achieve more natural illumination component enhancement. It can alleviate the mosaic artifacts produced in the darker regions by the exponential transform with a gamma value less than 1 and reduce information loss caused by excessive enhancement of the brighter regions due to the logarithmic transform. Finally, the Retinex model is applied to the enhanced illumination and reflectance to achieve image enhancement. We also develop a local noise level estimation based noise suppression method and a non-local saturation reduction based color deviation correction method. These two methods can respectively attenuate noise or color deviation usually presented in the enhanced results of the extremely dark low-light images. Experiments on benchmark datasets show that the proposed method can achieve better low-light image enhancement results on subjective and objective evaluations than most existing methods.
Mining Large-Scale Low-Resource Pronunciation Data From Wikipedia
Jan 27, 2021
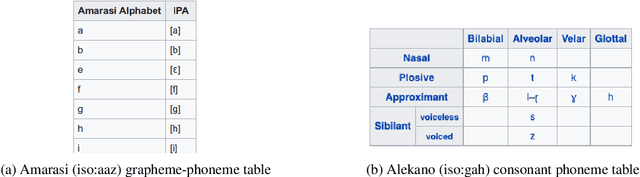


Pronunciation modeling is a key task for building speech technology in new languages, and while solid grapheme-to-phoneme (G2P) mapping systems exist, language coverage can stand to be improved. The information needed to build G2P models for many more languages can easily be found on Wikipedia, but unfortunately, it is stored in disparate formats. We report on a system we built to mine a pronunciation data set in 819 languages from loosely structured tables within Wikipedia. The data includes phoneme inventories, and for 63 low-resource languages, also includes the grapheme-to-phoneme (G2P) mapping. 54 of these languages do not have easily findable G2P mappings online otherwise. We turned the information from Wikipedia into a structured, machine-readable TSV format, and make the resulting data set publicly available so it can be improved further and used in a variety of applications involving low-resource languages.