 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Transfer Learning: Negative Transfer and Effect of Prior Knowledge
May 04, 2021
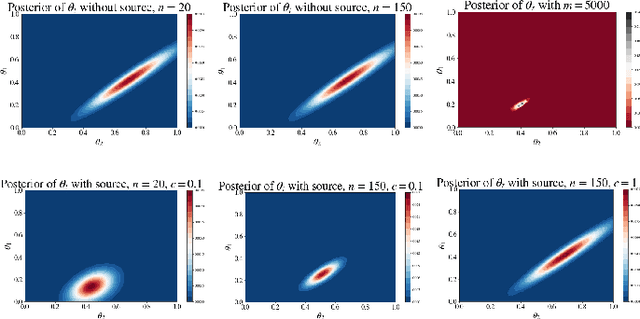
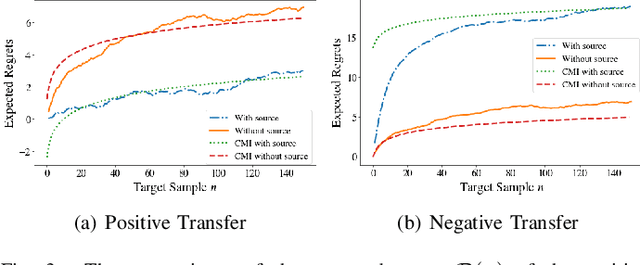
Transfer learning is a machine learning paradigm where the knowledge from one task is utilized to resolve the problem in a related task. On the one hand, it is conceivable that knowledge from one task could be useful for solving a related problem. On the other hand, it is also recognized that if not executed properly, transfer learning algorithms could in fact impair the learning performance instead of improving it - commonly known as "negative transfer". In this paper, we study the online transfer learning problems where the source samples are given in an offline way while the target samples arrive sequentially. We define the expected regret of the online transfer learning problem and provide upper bounds on the regret using information-theoretic quantities. We also obtain exact expressions for the bounds when the sample size becomes large. Examples show that the derived bounds are accurate even for small sample sizes. Furthermore, the obtained bounds give valuable insight on the effect of prior knowledge for transfer learning in our formulation. In particular, we formally characterize the conditions under which negative transfer occurs.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
May 31, 2021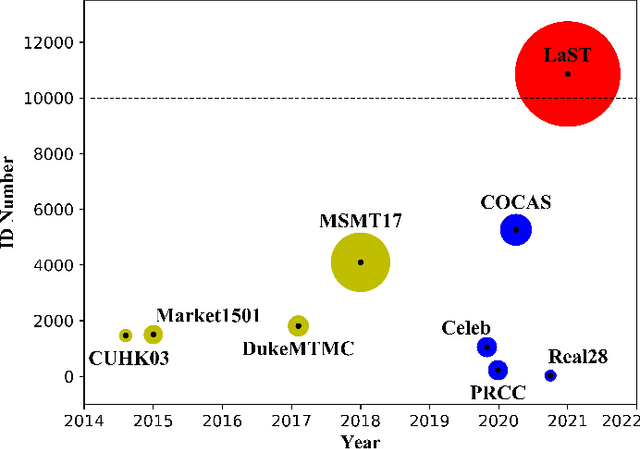
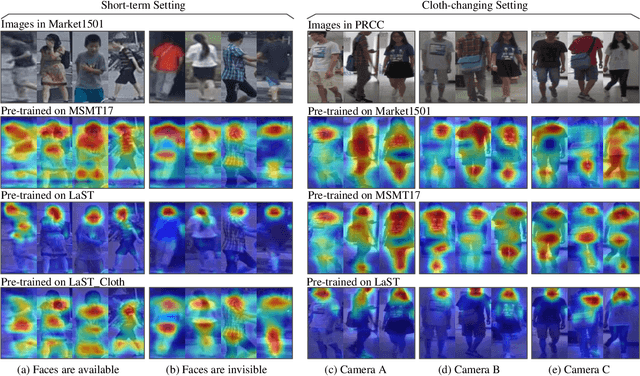
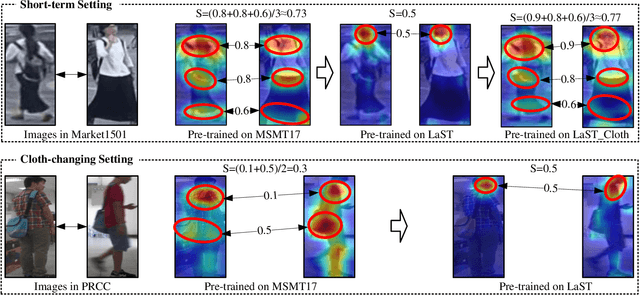

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal (LaST) person re-ID dataset, including 10,860 identities with more than 224k images. Compared with existing datasets, LaST presents more challenging and high-diversity reID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatiotemporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
HyperRNN: Deep Learning-Aided Downlink CSI Acquisition via Partial Channel Reciprocity for FDD Massive MIMO
Apr 25, 2021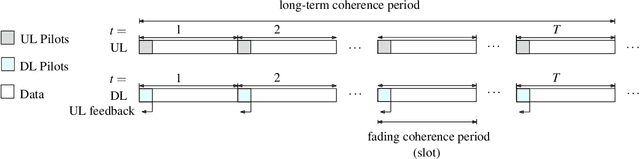
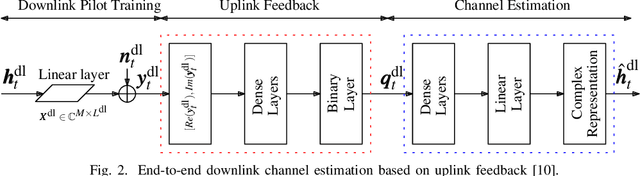
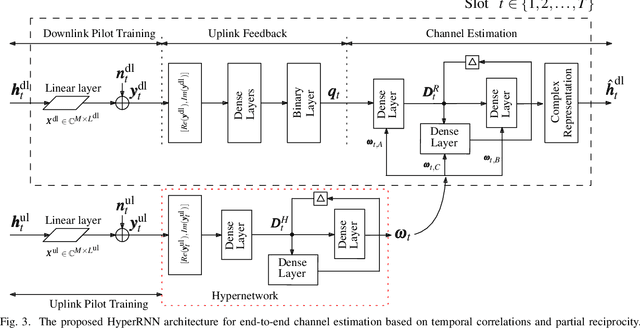
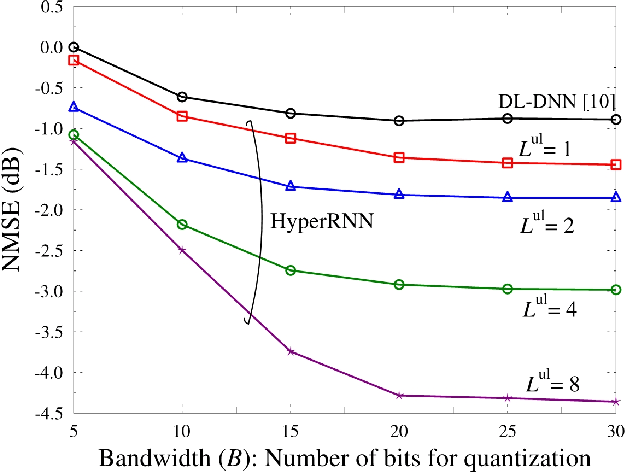
In order to unlock the full advantages of massive multiple input multiple output (MIMO) in the downlink, channel state information (CSI) is required at the base station (BS) to optimize the beamforming matrices. In frequency division duplex (FDD) systems, full channel reciprocity does not hold, and CSI acquisition generally requires downlink pilot transmission followed by uplink feedback. Prior work proposed the end-to-end design of pilot transmission, feedback, and CSI estimation via deep learning. In this work, we introduce an enhanced end-to-end design that leverages partial uplink-downlink reciprocity and temporal correlation of the fading processes by utilizing jointly downlink and uplink pilots. The proposed method is based on a novel deep learning architecture -- HyperRNN -- that combines hypernetworks and recurrent neural networks (RNNs) to optimize the transfer of long-term channel features from uplink to downlink. Simulation results demonstrate that the HyperRNN achieves a lower normalized mean square error (NMSE) performance, and that it reduces requirements in terms of pilot lengths.
Improving Hyper-Relational Knowledge Graph Completion
Apr 16, 2021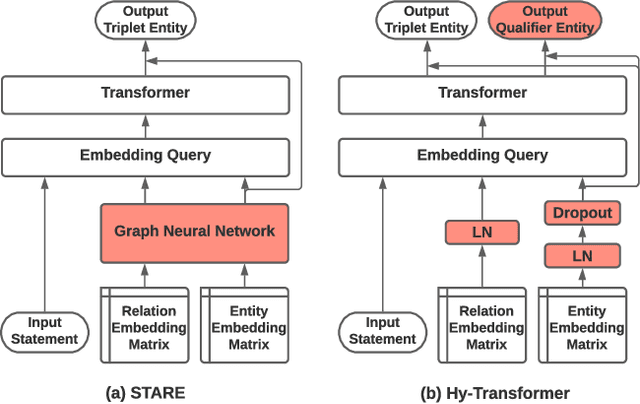
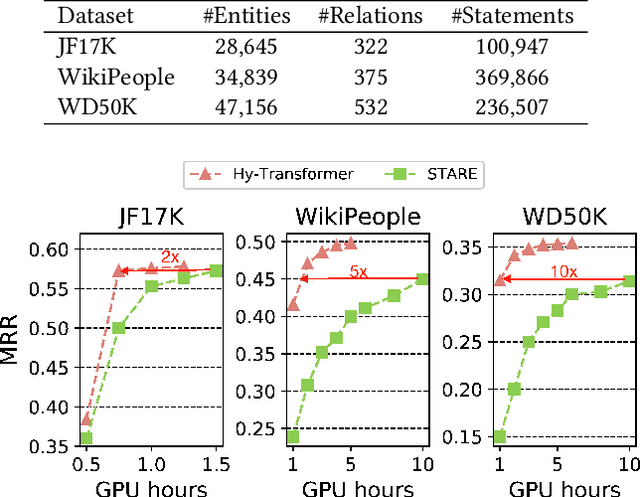
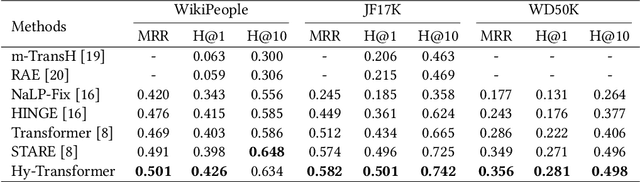
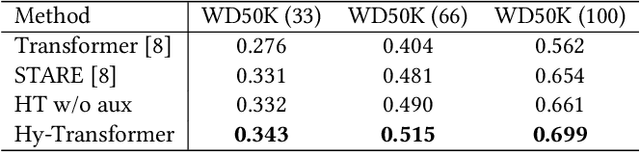
Different from traditional knowledge graphs (KGs) where facts are represented as entity-relation-entity triplets, hyper-relational KGs (HKGs) allow triplets to be associated with additional relation-entity pairs (a.k.a qualifiers) to convey more complex information. How to effectively and efficiently model the triplet-qualifier relationship for prediction tasks such as HKG completion is an open challenge for research. This paper proposes to improve the best-performing method in HKG completion, namely STARE, by introducing two novel revisions: (1) Replacing the computation-heavy graph neural network module with light-weight entity/relation embedding processing techniques for efficiency improvement without sacrificing effectiveness; (2) Adding a qualifier-oriented auxiliary training task for boosting the prediction power of our approach on HKG completion. The proposed approach consistently outperforms STARE in our experiments on three benchmark datasets, with significantly improved computational efficiency.
TransNAS-Bench-101: Improving Transferability and Generalizability of Cross-Task Neural Architecture Search
May 25, 2021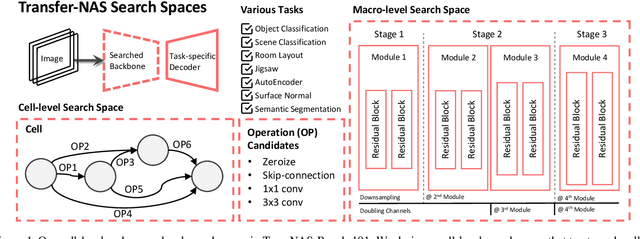
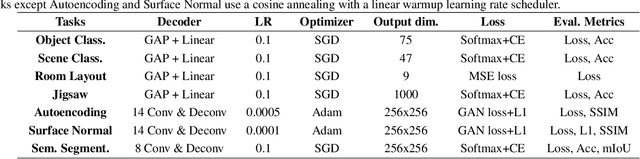


Recent breakthroughs of Neural Architecture Search (NAS) extend the field's research scope towards a broader range of vision tasks and more diversified search spaces. While existing NAS methods mostly design architectures on a single task, algorithms that look beyond single-task search are surging to pursue a more efficient and universal solution across various tasks. Many of them leverage transfer learning and seek to preserve, reuse, and refine network design knowledge to achieve higher efficiency in future tasks. However, the enormous computational cost and experiment complexity of cross-task NAS are imposing barriers for valuable research in this direction. Existing NAS benchmarks all focus on one type of vision task, i.e., classification. In this work, we propose TransNAS-Bench-101, a benchmark dataset containing network performance across seven tasks, covering classification, regression, pixel-level prediction, and self-supervised tasks. This diversity provides opportunities to transfer NAS methods among tasks and allows for more complex transfer schemes to evolve. We explore two fundamentally different types of search space: cell-level search space and macro-level search space. With 7,352 backbones evaluated on seven tasks, 51,464 trained models with detailed training information are provided. With TransNAS-Bench-101, we hope to encourage the advent of exceptional NAS algorithms that raise cross-task search efficiency and generalizability to the next level. Our dataset file will be available at Mindspore, VEGA.
SMASH: a Semantic-enabled Multi-agent Approach for Self-adaptation of Human-centered IoT
May 31, 2021

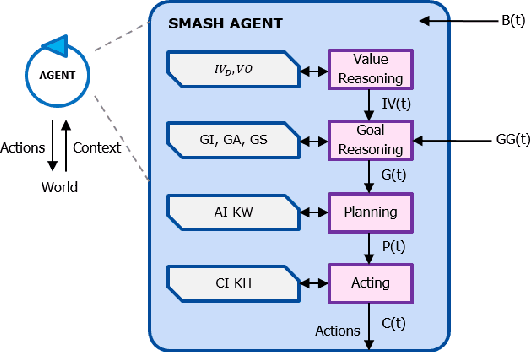
Nowadays, IoT devices have an enlarging scope of activities spanning from sensing, computing to acting and even more, learning, reasoning and planning. As the number of IoT applications increases, these objects are becoming more and more ubiquitous. Therefore, they need to adapt their functionality in response to the uncertainties of their environment to achieve their goals. In Human-centered IoT, objects and devices have direct interactions with human beings and have access to online contextual information. Self-adaptation of such applications is a crucial subject that needs to be addressed in a way that respects human goals and human values. Hence, IoT applications must be equipped with self-adaptation techniques to manage their run-time uncertainties locally or in cooperation with each other. This paper presents SMASH: a multi-agent approach for self-adaptation of IoT applications in human-centered environments. In this paper, we have considered the Smart Home as the case study of smart environments. SMASH agents are provided with a 4-layer architecture based on the BDI agent model that integrates human values with goal-reasoning, planning, and acting. It also takes advantage of a semantic-enabled platform called Home'In to address interoperability issues among non-identical agents and devices with heterogeneous protocols and data formats. This approach is compared with the literature and is validated by developing a scenario as the proof of concept. The timely responses of SMASH agents show the feasibility of the proposed approach in human-centered environments.
GCNBoost: Artwork Classification by Label Propagation through a Knowledge Graph
May 25, 2021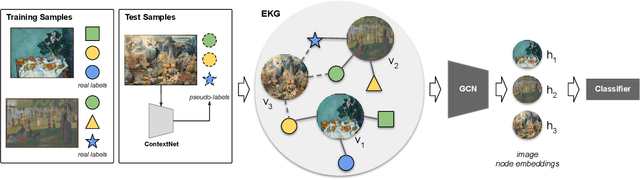
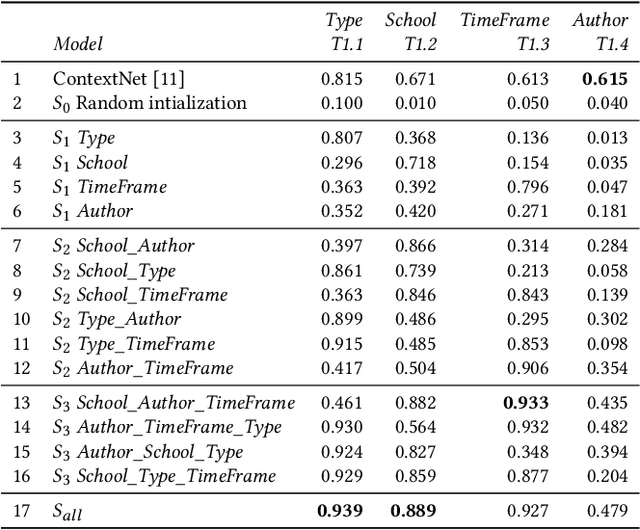
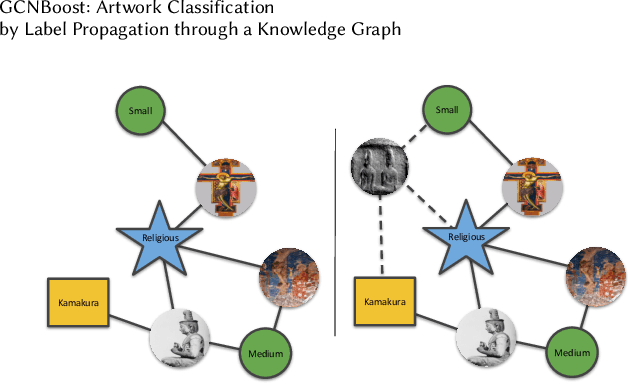
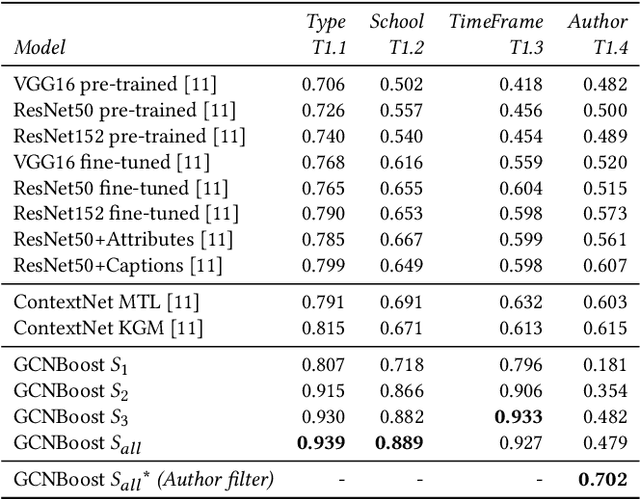
The rise of digitization of cultural documents offers large-scale contents, opening the road for development of AI systems in order to preserve, search, and deliver cultural heritage. To organize such cultural content also means to classify them, a task that is very familiar to modern computer science. Contextual information is often the key to structure such real world data, and we propose to use it in form of a knowledge graph. Such a knowledge graph, combined with content analysis, enhances the notion of proximity between artworks so it improves the performances in classification tasks. In this paper, we propose a novel use of a knowledge graph, that is constructed on annotated data and pseudo-labeled data. With label propagation, we boost artwork classification by training a model using a graph convolutional network, relying on the relationships between entities of the knowledge graph. Following a transductive learning framework, our experiments show that relying on a knowledge graph modeling the relations between labeled data and unlabeled data allows to achieve state-of-the-art results on multiple classification tasks on a dataset of paintings, and on a dataset of Buddha statues. Additionally, we show state-of-the-art results for the difficult case of dealing with unbalanced data, with the limitation of disregarding classes with extremely low degrees in the knowledge graph.
qRRT: Quality-Biased Incremental RRT for Optimal Motion Planning in Non-Holonomic Systems
Jan 07, 2021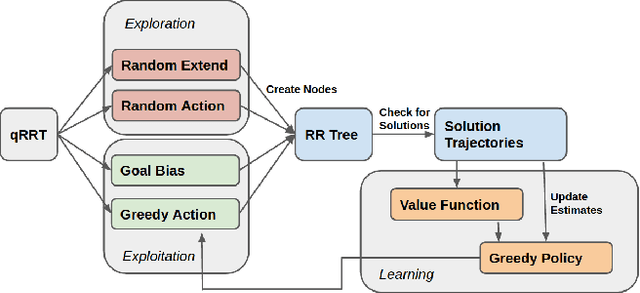
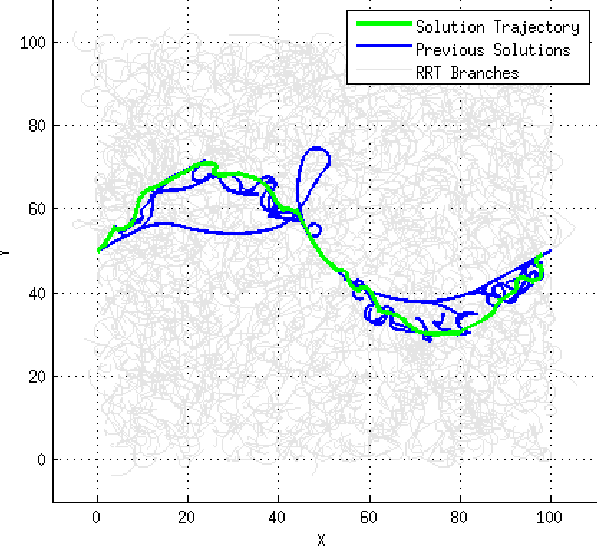
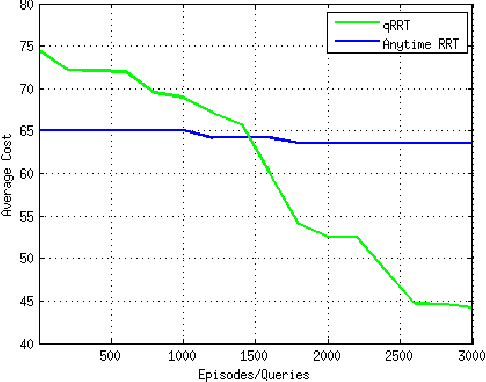
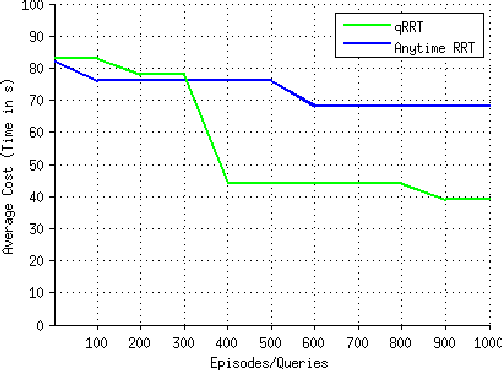
This paper presents a sampling-based method for optimal motion planning in non-holonomic systems in the absence of known cost functions. It uses the principle of learning through experience to deduce the cost-to-go of regions within the workspace. This cost information is used to bias an incremental graph-based search algorithm that produces solution trajectories. Iterative improvement of cost information and search biasing produces solutions that are proven to be asymptotically optimal. The proposed framework builds on incremental Rapidly-exploring Random Trees (RRT) for random sampling-based search and Reinforcement Learning (RL) to learn workspace costs. A series of experiments were performed to evaluate and demonstrate the performance of the proposed method.
Streaming computation of optimal weak transport barycenters
Feb 26, 2021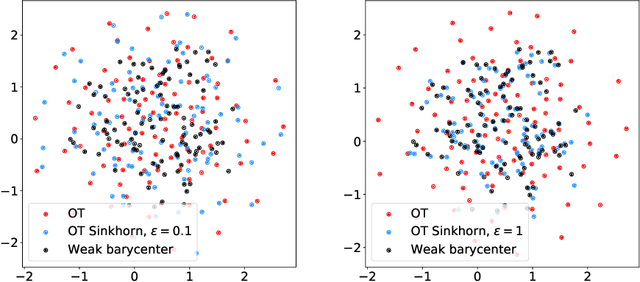
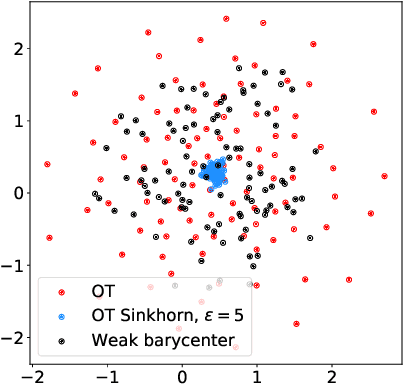
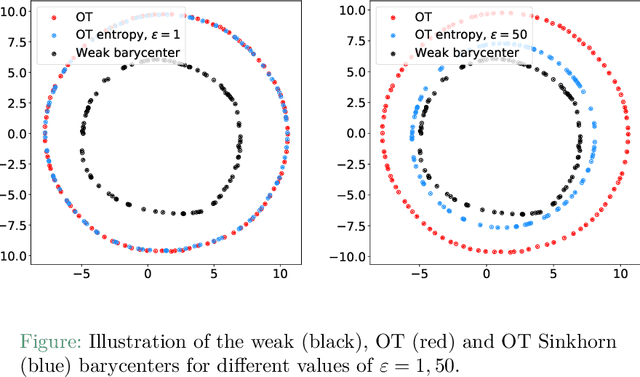
We introduce the weak barycenter of a family of probability distributions, based on the recently developed notion of optimal weak transport of measures arXiv:1412.7480(v4). We provide a theoretical analysis of the weak barycenter and its relationship to the classic Wasserstein barycenter, and discuss its meaning in the light of convex ordering between probability measures. In particular, we argue that, rather than averaging the information of the input distributions as done by the usual optimal transport barycenters, weak barycenters contain geometric information shared across all input distributions, which can be interpreted as a latent random variable affecting all the measures. We also provide iterative algorithms to compute a weak barycenter for either finite or infinite families of arbitrary measures (with finite moments of order 2), which are particularly well suited for the streaming setting, i.e., when measures arrive sequentially. In particular, our streaming computation of weak barycenters does not require to smooth empirical measures or to define a common grid for them, as some of the previous approaches to Wasserstin barycenters do. The concept of weak barycenter and our computation approaches are illustrated on synthetic examples, validated on 2D real-world data and compared to the classical Wasserstein barycenters.
Novel tile segmentation scheme for omnidirectional video
Mar 10, 2021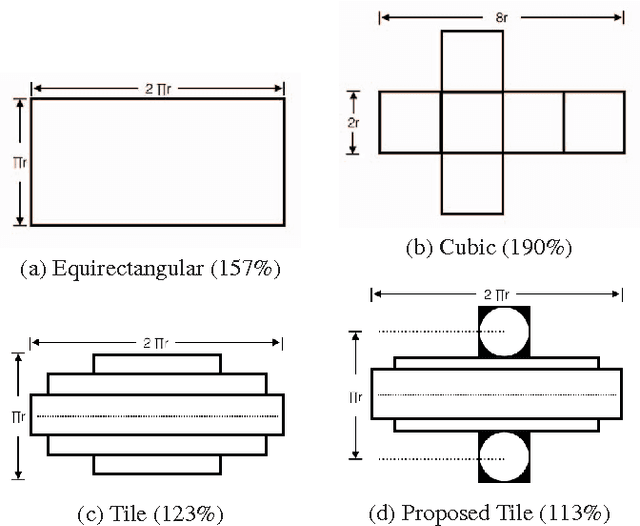
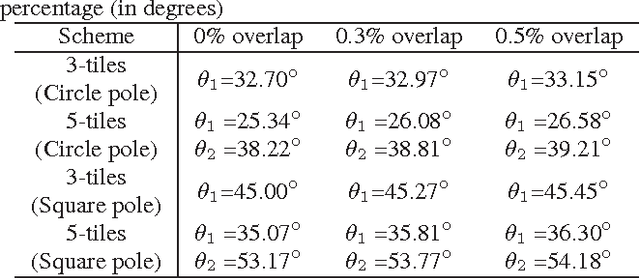
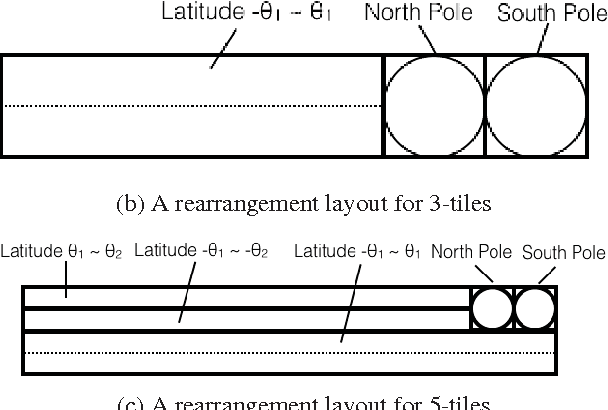
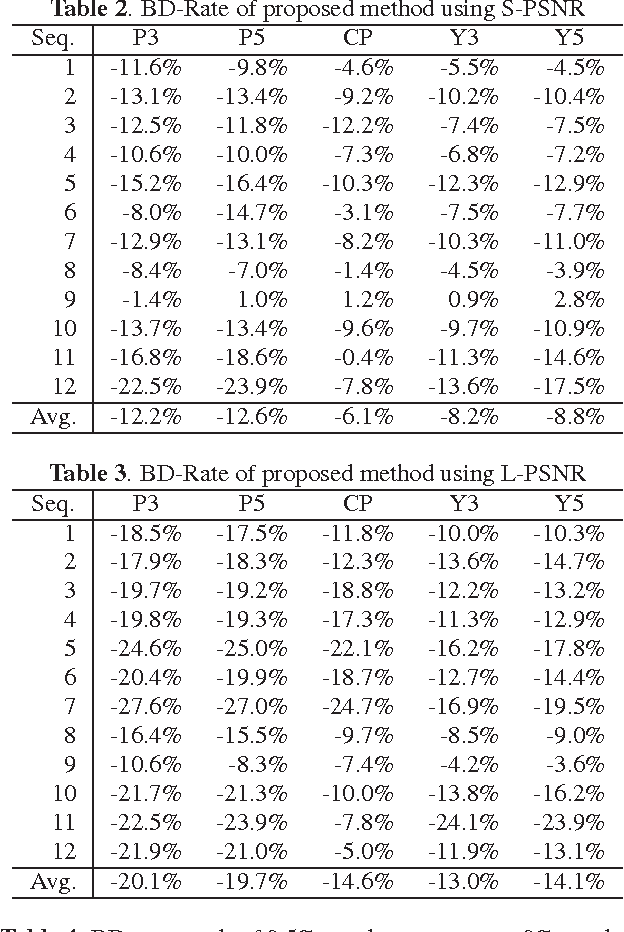
Regular omnidirectional video encoding technics use map projection to flatten a scene from a spherical shape into one or several 2D shapes. Common projection methods including equirectangular and cubic projection have varying levels of interpolation that create a large number of non-information-carrying pixels that lead to wasted bitrate. In this paper, we propose a tile based omnidirectional video segmentation scheme which can save up to 28% of pixel area and 20% of BD-rate averagely compared to the traditional equirectangular projection based approach.