 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temp-Frustum Net: 3D Object Detection with Temporal Fusion
May 21, 2021
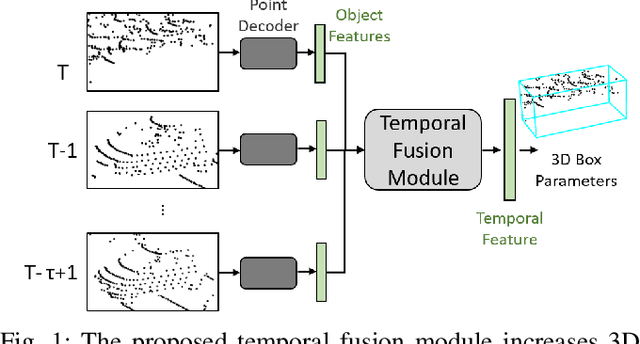
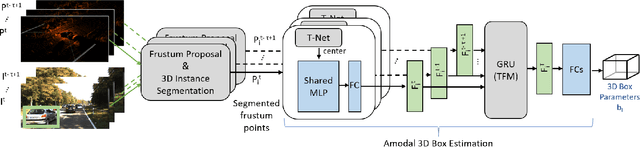


3D object detection is a core component of automated driving systems. State-of-the-art methods fuse RGB imagery and LiDAR point cloud data frame-by-frame for 3D bounding box regression. However, frame-by-frame 3D object detection suffers from noise, field-of-view obstruction, and sparsity. We propose a novel Temporal Fusion Module (TFM) to use information from previous time-steps to mitigate these problems. First, a state-of-the-art frustum network extracts point cloud features from raw RGB and LiDAR point cloud data frame-by-frame. Then, our TFM module fuses these features with a recurrent neural network. As a result, 3D object detection becomes robust against single frame failures and transient occlusions. Experiments on the KITTI object tracking dataset show the efficiency of the proposed TFM, where we obtain ~6%, ~4%, and ~6% improvements on Car, Pedestrian, and Cyclist classes, respectively, compared to frame-by-frame baselines. Furthermore, ablation studies reinforce that the subject of improvement is temporal fusion and show the effects of different placements of TFM in the object detection pipeline. Our code is open-source and available at https://github.com/emecercelik/Temp-Frustum-Net.git.
Alternating Fixpoint Operator for Hybrid MKNF Knowledge Bases as an Approximator of AFT
May 28, 2021Approximation fixpoint theory (AFT) provides an algebraic framework for the study of fixpoints of operators on bilattices and has found its applications in characterizing semantics for various classes of logic programs and nonmonotonic languages. In this paper, we show one more application of this kind: the alternating fixpoint operator by Knorr et al. for the study of the well-founded semantics for hybrid MKNF knowledge bases is in fact an approximator of AFT in disguise, which, thanks to the power of abstraction of AFT, characterizes not only the well-founded semantics but also two-valued as well as three-valued semantics for hybrid MKNF knowledge bases. Furthermore, we show an improved approximator for these knowledge bases, of which the least stable fixpoint is information richer than the one formulated from Knorr et al.'s construction. This leads to an improved computation for the well-founded semantics. This work is built on an extension of AFT that supports consistent as well as inconsistent pairs in the induced product bilattice, to deal with inconsistencies that arise in the context of hybrid MKNF knowledge bases. This part of the work can be considered generalizing the original AFT from symmetric approximators to arbitrary approximators.
Polarization Guided Specular Reflection Separation
Mar 22, 2021
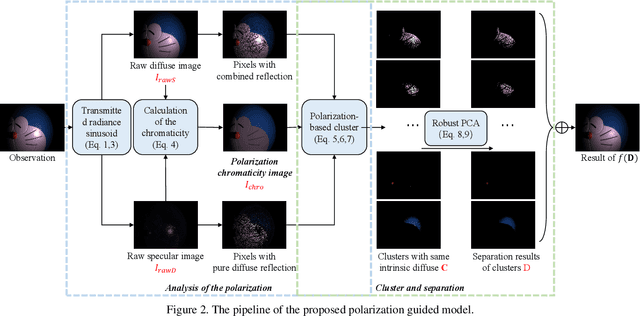
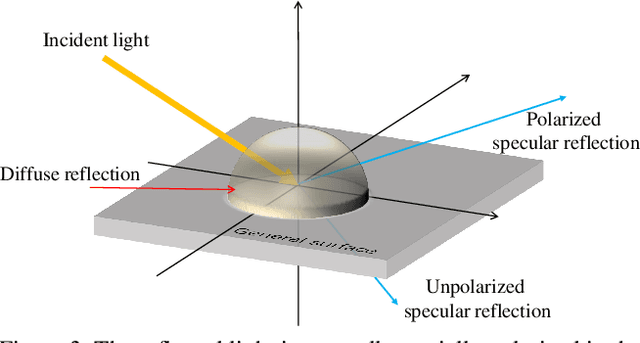
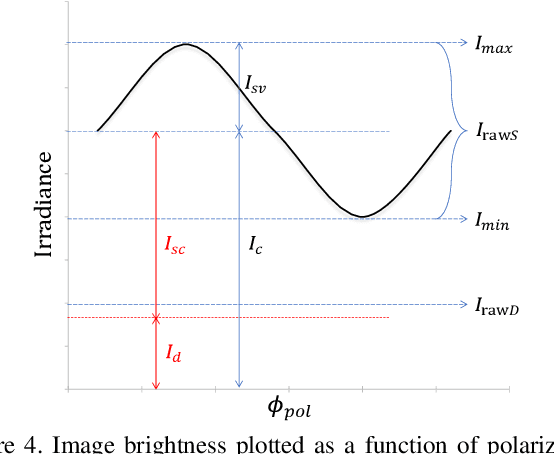
Since specular reflection often exists in the real captured images and causes deviation between the recorded color and intrinsic color, specular reflection separation can bring advantages to multiple applications that require consistent object surface appearance. However, due to the color of an object is significantly influenced by the color of the illumination, the existing researches still suffer from the near-duplicate challenge, that is, the separation becomes unstable when the illumination color is close to the surface color. In this paper, we derive a polarization guided model to incorporate the polarization information into a designed iteration optimization separation strategy to separate the specular reflection. Based on the analysis of polarization, we propose a polarization guided model to generate a polarization chromaticity image, which is able to reveal the geometrical profile of the input image in complex scenarios, such as diversity of illumination. The polarization chromaticity image can accurately cluster the pixels with similar diffuse color. We further use the specular separation of all these clusters as an implicit prior to ensure that the diffuse components will not be mistakenly separated as the specular components. With the polarization guided model, we reformulate the specular reflection separation into a unified optimization function which can be solved by the ADMM strategy. The specular reflection will be detected and separated jointly by RGB and polarimetric information. Both qualitative and quantitative experimental results have shown that our method can faithfully separate the specular reflection, especially in some challenging scenarios.
End-to-End Sequential Sampling and Reconstruction for MR Imaging
May 13, 2021
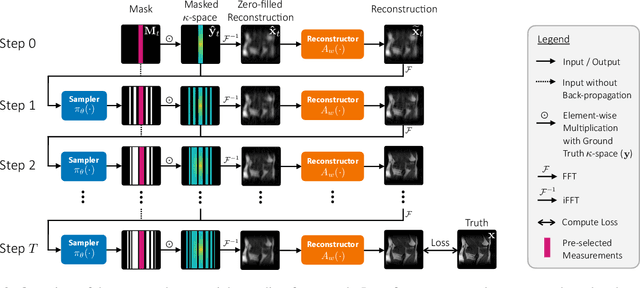


Accelerated MRI shortens acquisition time by subsampling in the measurement k-space. Recovering a high-fidelity anatomical image from subsampled measurements requires close cooperation between two components: (1) a sampler that chooses the subsampling pattern and (2) a reconstructor that recovers images from incomplete measurements. In this paper, we leverage the sequential nature of MRI measurements, and propose a fully differentiable framework that jointly learns a sequential sampling policy simultaneously with a reconstruction strategy. This co-designed framework is able to adapt during acquisition in order to capture the most informative measurements for a particular target (Figure 1). Experimental results on the fastMRI knee dataset demonstrate that the proposed approach successfully utilizes intermediate information during the sampling process to boost reconstruction performance. In particular, our proposed method outperforms the current state-of-the-art learned k-space sampling baseline on up to 96.96% of test samples. We also investigate the individual and collective benefits of the sequential sampling and co-design strategies. Code and more visualizations are available at http://imaging.cms.caltech.edu/seq-mri
Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation
Mar 15, 2021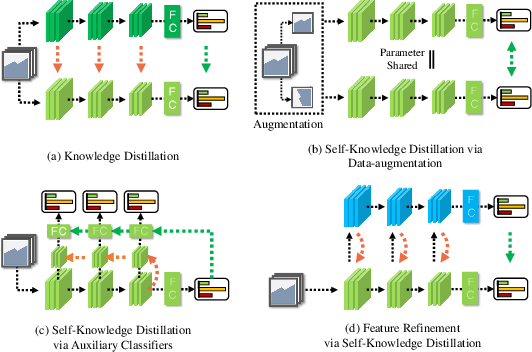
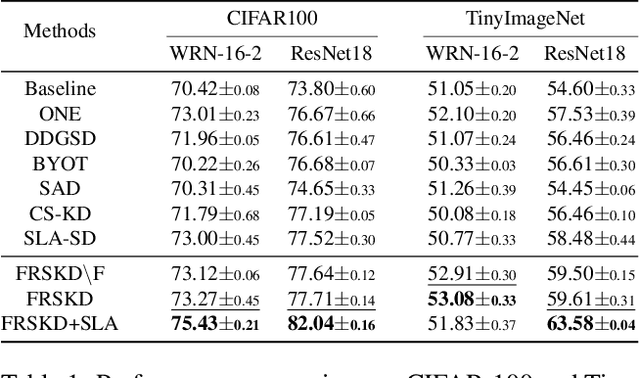
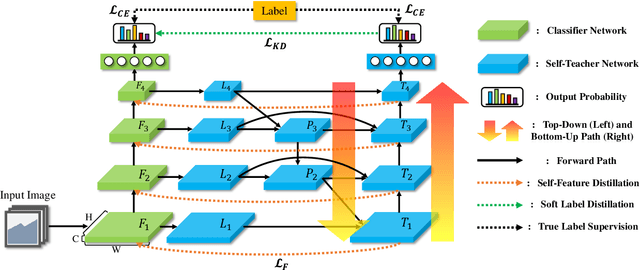
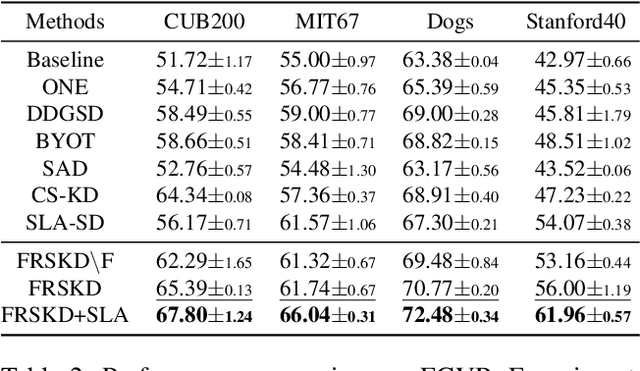
Knowledge distillation is a method of transferring the knowledge from a pretrained complex teacher model to a student model, so a smaller network can replace a large teacher network at the deployment stage. To reduce the necessity of training a large teacher model, the recent literatures introduced a self-knowledge distillation, which trains a student network progressively to distill its own knowledge without a pretrained teacher network. While Self-knowledge distillation is largely divided into a data augmentation based approach and an auxiliary network based approach, the data augmentation approach looses its local information in the augmentation process, which hinders its applicability to diverse vision tasks, such as semantic segmentation. Moreover, these knowledge distillation approaches do not receive the refined feature maps, which are prevalent in the object detection and semantic segmentation community. This paper proposes a novel self-knowledge distillation method, Feature Refinement via Self-Knowledge Distillation (FRSKD), which utilizes an auxiliary self-teacher network to transfer a refined knowledge for the classifier network. Our proposed method, FRSKD, can utilize both soft label and feature-map distillations for the self-knowledge distillation. Therefore, FRSKD can be applied to classification, and semantic segmentation, which emphasize preserving the local information. We demonstrate the effectiveness of FRSKD by enumerating its performance improvements in diverse tasks and benchmark datasets. The implemented code is available at https://github.com/MingiJi/FRSKD.
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021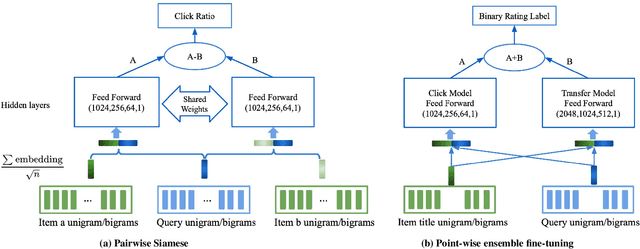



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
Continuity in Information Algebras
Jan 02, 2012In this paper, the continuity and strong continuity in domain-free information algebras and labeled information algebras are introduced respectively. A more general concept of continuous function which is defined between two domain-free continuous information algebras is presented. It is shown that, with the operations combination and focusing, the set of all continuous functions between two domain-free s-continuous information algebras forms a new s-continuous information algebra. By studying the relationship between domain-free information algebras and labeled information algebras, it is demonstrated that they do correspond to each other on s-compactness.
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
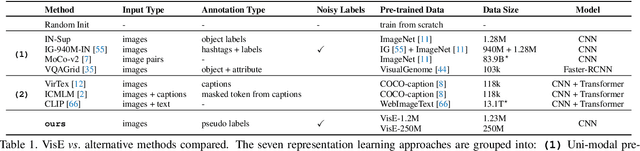
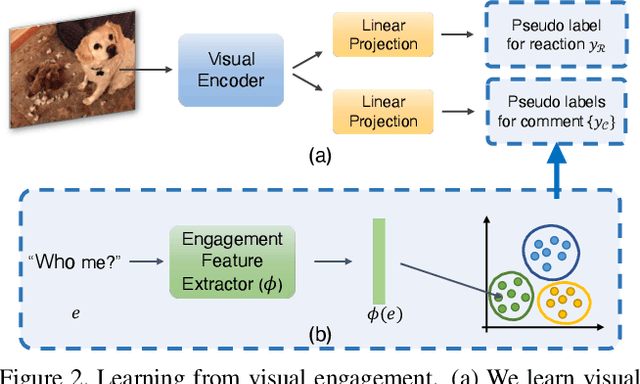
Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.
Forensic Analysis of Video Files Using Metadata
May 13, 2021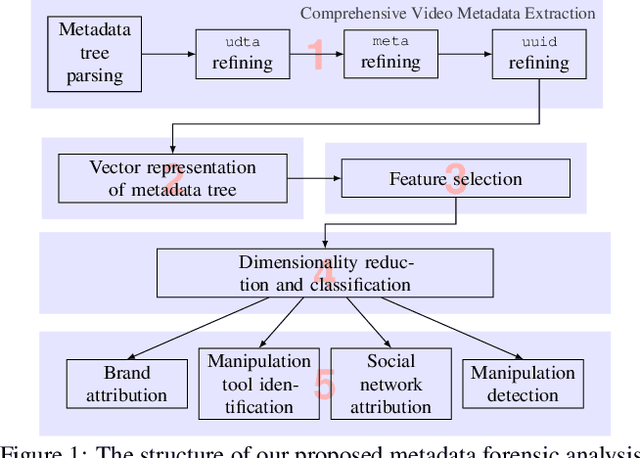

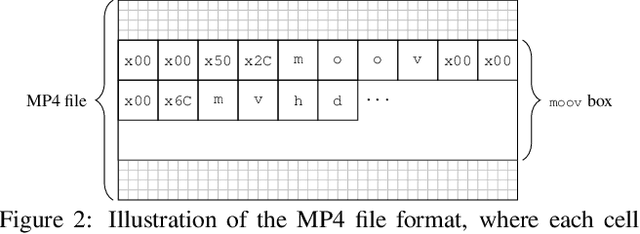
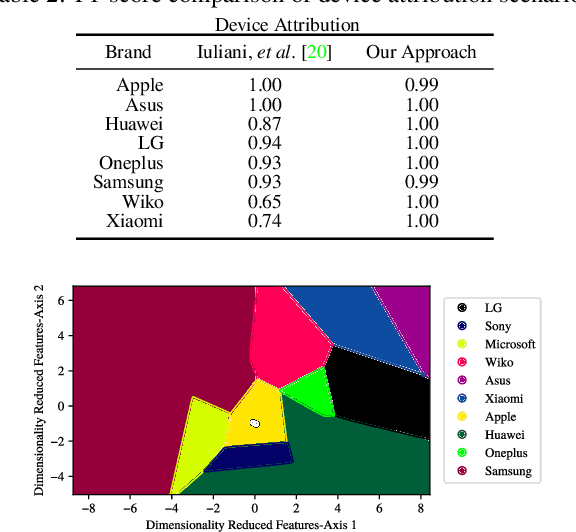
The unprecedented ease and ability to manipulate video content has led to a rapid spread of manipulated media. The availability of video editing tools greatly increased in recent years, allowing one to easily generate photo-realistic alterations. Such manipulations can leave traces in the metadata embedded in video files. This metadata information can be used to determine video manipulations, brand of video recording device, the type of video editing tool, and other important evidence. In this paper, we focus on the metadata contained in the popular MP4 video wrapper/container. We describe our method for metadata extractor that uses the MP4's tree structure. Our approach for analyzing the video metadata produces a more compact representation. We will describe how we construct features from the metadata and then use dimensionality reduction and nearest neighbor classification for forensic analysis of a video file. Our approach allows one to visually inspect the distribution of metadata features and make decisions. The experimental results confirm that the performance of our approach surpasses other methods.
Tech Report: A Homogeneity-Based Multiscale Hyperspectral Image Representation for Sparse Spectral Unmixing
Feb 11, 2021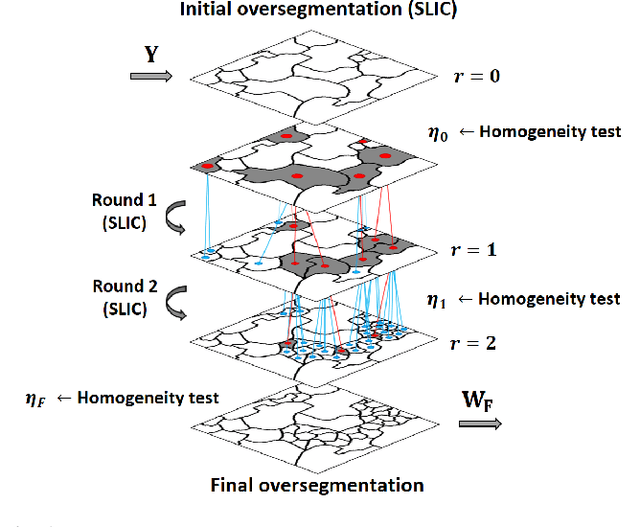
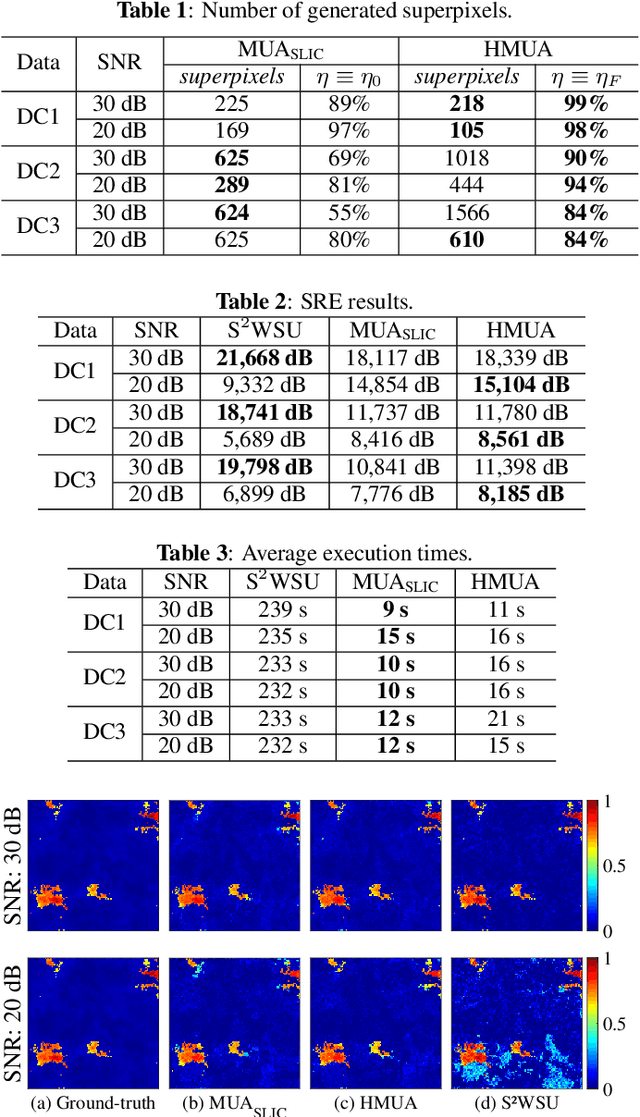

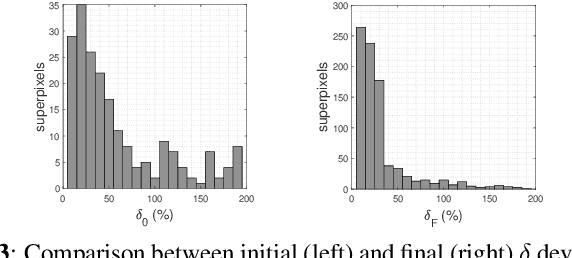
Several approaches have been proposed to solve the spectral unmixing problem in hyperspectral image analysis. Among them the use of sparse regression techniques aims to characterize the abundances in pixels based on a large library of spectral signatures known a priori. Recently, the integration of image spatial-contextual information significantly enhanced the performance of sparse unmixing. In this work, we propose a computationally efficient multiscale representation method for hyperspectral data adapted to the unmixing problem. The proposed method is based on a hierarchical extension of the SLIC oversegmentation algorithm constructed using a robust homogeneity testing. The image is subdivided into a set of spectrally homogeneous regions formed by pixels with similar characteristics (superpixels). This representation is then used to provide prior spatial regularity information for the abundances of materials present in the scene, improving the conditioning of the unmixing problem. Simulation results illustrate that the method is capable of estimating abundances with high quality and low computational cost, especially in noisy scenarios.