 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty-aware Incremental Learning for Multi-organ Segmentation
Mar 09, 2021
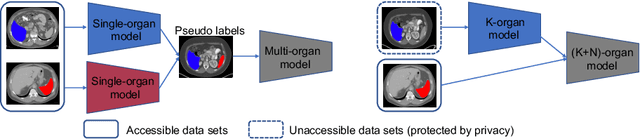
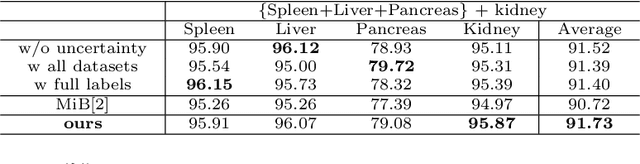
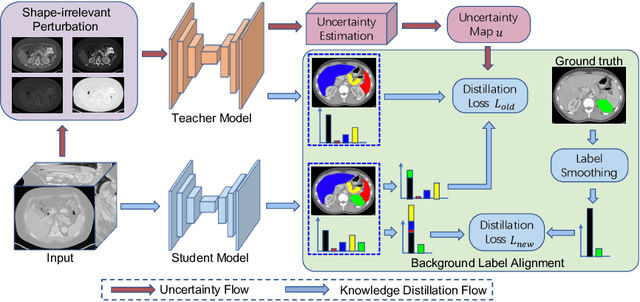
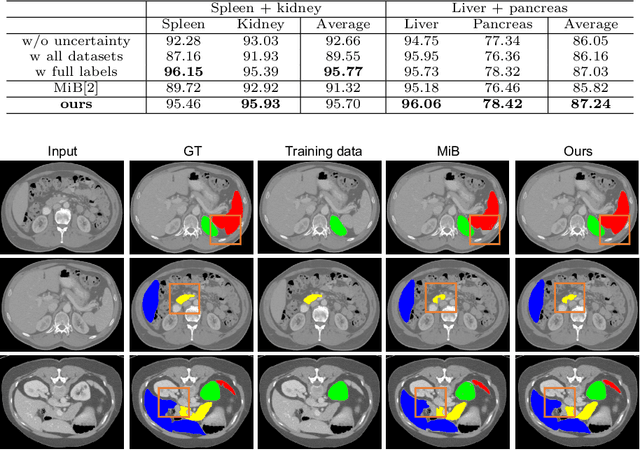
Most existing approaches to train a unified multi-organ segmentation model from several single-organ datasets require simultaneously access multiple datasets during training. In the real scenarios, due to privacy and ethics concerns, the training data of the organs of interest may not be publicly available. To this end, we investigate a data-free incremental organ segmentation scenario and propose a novel incremental training framework to solve it. We use the pretrained model instead of its own training data for privacy protection. Specifically, given a pretrained $K$ organ segmentation model and a new single-organ dataset, we train a unified $K+1$ organ segmentation model without accessing any data belonging to the previous training stages. Our approach consists of two parts: the background label alignment strategy and the uncertainty-aware guidance strategy. The first part is used for knowledge transfer from the pretained model to the training model. The second part is used to extract the uncertainty information from the pretrained model to guide the whole knowledge transfer process. By combing these two strategies, more reliable information is extracted from the pretrained model without original training data. Experiments on multiple publicly available pretrained models and a multi-organ dataset MOBA have demonstrated the effectiveness of our framework.
Asymptotic Freeness of Layerwise Jacobians Caused by Invariance of Multilayer Perceptron: The Haar Orthogonal Case
Apr 11, 2021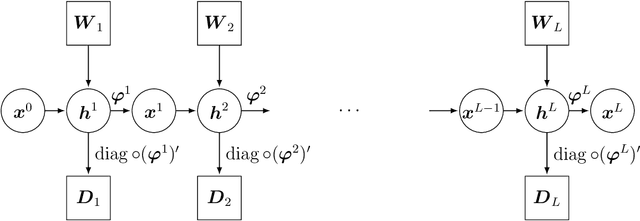
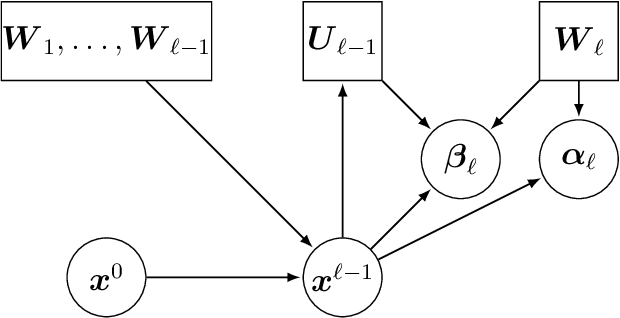
Free Probability Theory (FPT) provides rich knowledge for handling mathematical difficulties caused by random matrices that appear in research related to deep neural networks (DNNs), such as the dynamical isometry, Fisher information matrix, and training dynamics. FPT suits these researches because the DNN's parameter-Jacobian and input-Jacobian are polynomials of layerwise Jacobians. However, the critical assumption of asymptotic freenss of the layerwise Jacobian has not been proven completely so far. The asymptotic freeness assumption plays a fundamental role when propagating spectral distributions through the layers. Haar distributed orthogonal matrices are essential for achieving dynamical isometry. In this work, we prove asymptotic freeness of layerwise Jacobian of multilayer perceptrons in this case.
Towards Novel Target Discovery Through Open-Set Domain Adaptation
May 06, 2021
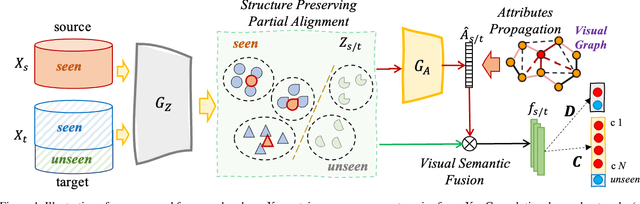
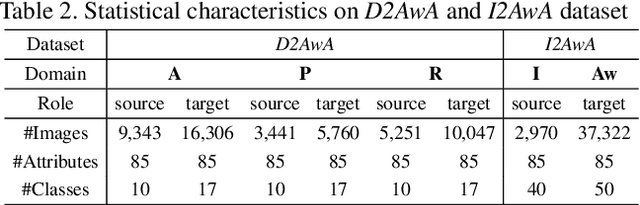
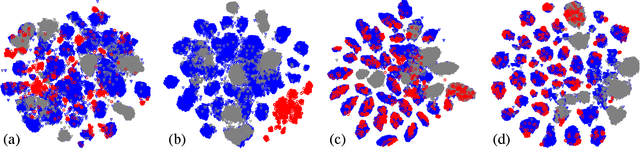
Open-set domain adaptation (OSDA) considers that the target domain contains samples from novel categories unobserved in external source domain. Unfortunately, existing OSDA methods always ignore the demand for the information of unseen categories and simply recognize them as "unknown" set without further explanation. This motivates us to understand the unknown categories more specifically by exploring the underlying structures and recovering their interpretable semantic attributes. In this paper, we propose a novel framework to accurately identify the seen categories in target domain, and effectively recover the semantic attributes for unseen categories. Specifically, structure preserving partial alignment is developed to recognize the seen categories through domain-invariant feature learning. Attribute propagation over visual graph is designed to smoothly transit attributes from seen to unseen categories via visual-semantic mapping. Moreover, two new cross-main benchmarks are constructed to evaluate the proposed framework in the novel and practical challenge. Experimental results on open-set recognition and semantic recovery demonstrate the superiority of the proposed method over other compared baselines.
Low-Complexity Interference Cancellation Algorithms for Detection in Media-based Modulated Uplink Massive-MIMO Systems
Jan 06, 2021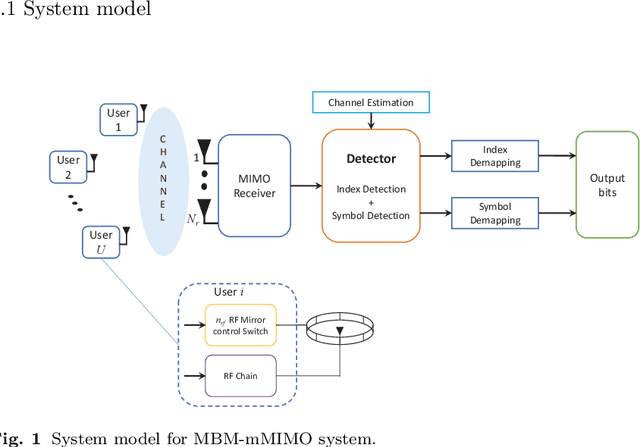
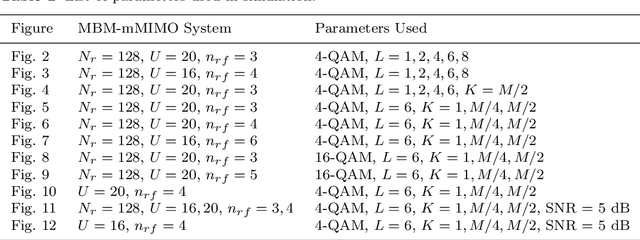
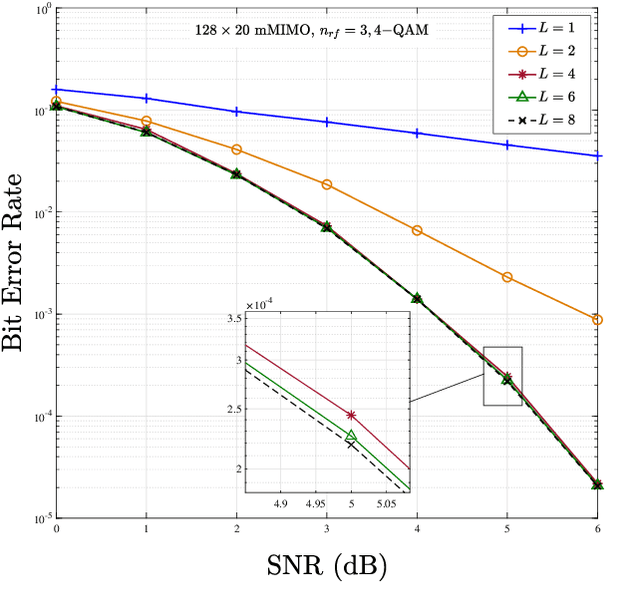
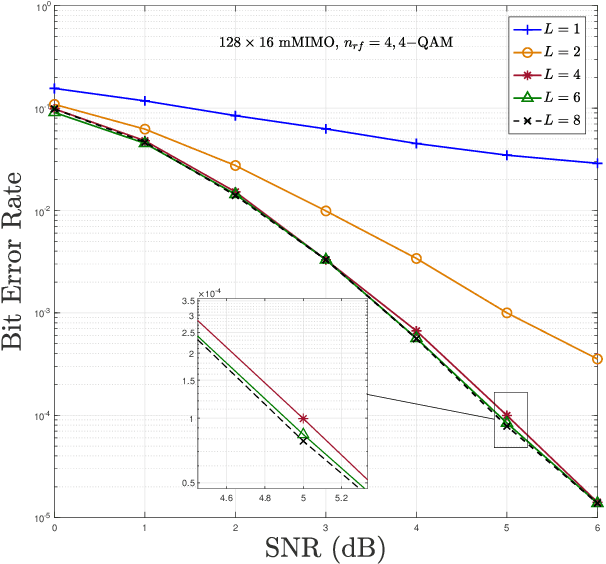
Media-based modulation (MBM) is a novel modulation technique that can improve the spectral efficiency of the existing wireless systems. In MBM, multiple radio frequency (RF) mirrors are placed near the transmit antenna(s) and are switched ON/OFF to create different channel fade realizations. In such systems, additional information is conveyed through the ON/OFF status of RF mirrors along with conventional modulation symbols. A challenging task at the receiver is to detect the transmitted information symbols and extract the additional information from the channel fade realization used for transmission. In this paper, we consider a massive MIMO (mMIMO) system where each user relies on MBM for transmitting information to the base station, and investigate the problem of symbol detection at the base station. First, we propose a mirror activation pattern (MAP) selection based modified iterative sequential detection algorithm. With the proposed algorithm, the most favorable MAP is selected, followed by the detection of symbol corresponding to the selected MAP. Each solution is subjected to the reliability check before getting the update. Next, we introduce a $K$ favorable MAP search based iterative interference cancellation (KMAP-IIC) algorithm. In particular, a selection rule is introduced in KMAP-IIC for deciding the set of favorable MAPs over which iterative interference cancellation is performed, followed by a greedy update scheme for detecting the MBM symbols corresponding to each user. Simulation results show that the proposed detection algorithms exhibit superior performance-complexity trade-off over the existing detection techniques in MBM-mMIMO systems.
Exploring Explicit and Implicit Visual Relationships for Image Captioning
May 06, 2021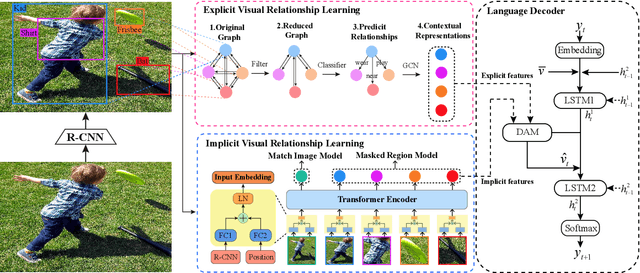
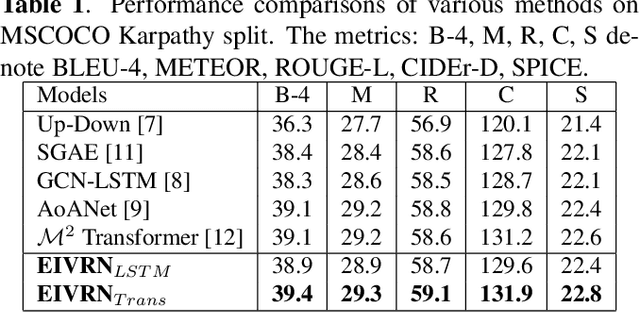
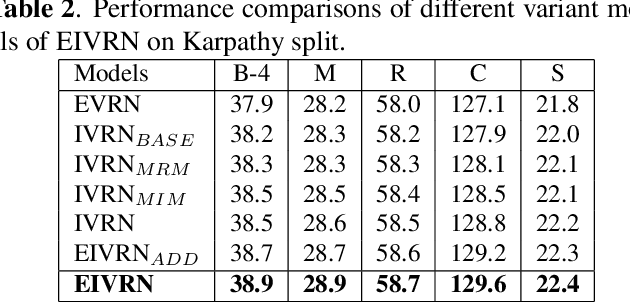
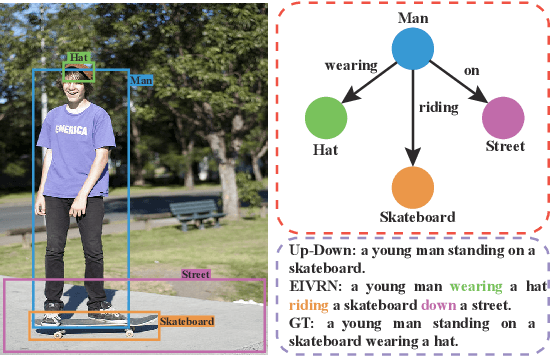
Image captioning is one of the most challenging tasks in AI, which aims to automatically generate textual sentences for an image. Recent methods for image captioning follow encoder-decoder framework that transforms the sequence of salient regions in an image into natural language descriptions. However, these models usually lack the comprehensive understanding of the contextual interactions reflected on various visual relationships between objects. In this paper, we explore explicit and implicit visual relationships to enrich region-level representations for image captioning. Explicitly, we build semantic graph over object pairs and exploit gated graph convolutional networks (Gated GCN) to selectively aggregate local neighbors' information. Implicitly, we draw global interactions among the detected objects through region-based bidirectional encoder representations from transformers (Region BERT) without extra relational annotations. To evaluate the effectiveness and superiority of our proposed method, we conduct extensive experiments on Microsoft COCO benchmark and achieve remarkable improvements compared with strong baselines.
Automated Timeline Length Selection for Flexible Timeline Summarization
May 29, 2021
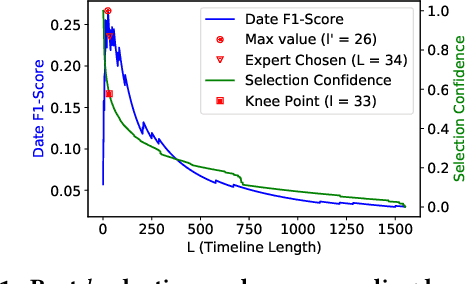
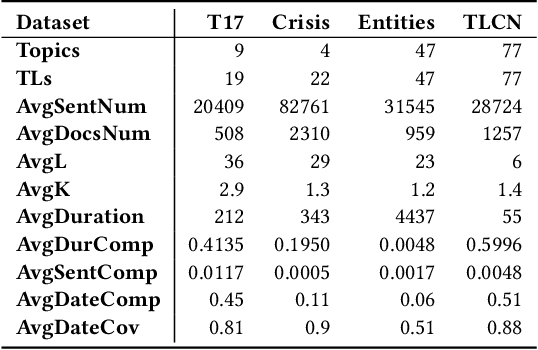
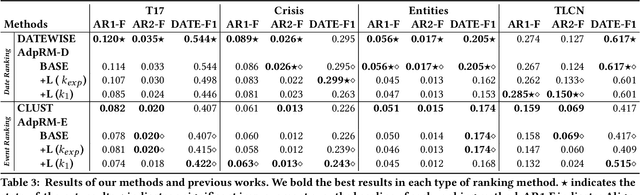
By producing summaries for long-running events, timeline summarization (TLS) underpins many information retrieval tasks. Successful TLS requires identifying an appropriate set of key dates (the timeline length) to cover. However, doing so is challenging as the right length can change from one topic to another. Existing TLS solutions either rely on an event-agnostic fixed length or an expert-supplied setting. Neither of the strategies is desired for real-life TLS scenarios. A fixed, event-agnostic setting ignores the diversity of events and their development and hence can lead to low-quality TLS. Relying on expert-crafted settings is neither scalable nor sustainable for processing many dynamically changing events. This paper presents a better TLS approach for automatically and dynamically determining the TLS timeline length. We achieve this by employing the established elbow method from the machine learning community to automatically find the minimum number of dates within the time series to generate concise and informative summaries. We applied our approach to four TLS datasets of English and Chinese and compared them against three prior methods. Experimental results show that our approach delivers comparable or even better summaries over state-of-art TLS methods, but it achieves this without expert involvement.
Probing artificial neural networks: insights from neuroscience
Apr 16, 2021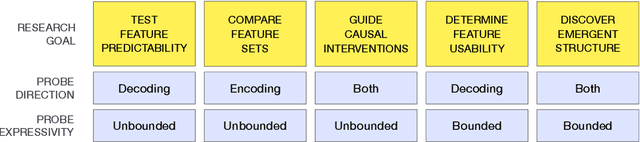
A major challenge in both neuroscience and machine learning is the development of useful tools for understanding complex information processing systems. One such tool is probes, i.e., supervised models that relate features of interest to activation patterns arising in biological or artificial neural networks. Neuroscience has paved the way in using such models through numerous studies conducted in recent decades. In this work, we draw insights from neuroscience to help guide probing research in machine learning. We highlight two important design choices for probes $-$ direction and expressivity $-$ and relate these choices to research goals. We argue that specific research goals play a paramount role when designing a probe and encourage future probing studies to be explicit in stating these goals.
Reconstructing Perceptive Images from Brain Activity by Shape-Semantic GAN
Jan 28, 2021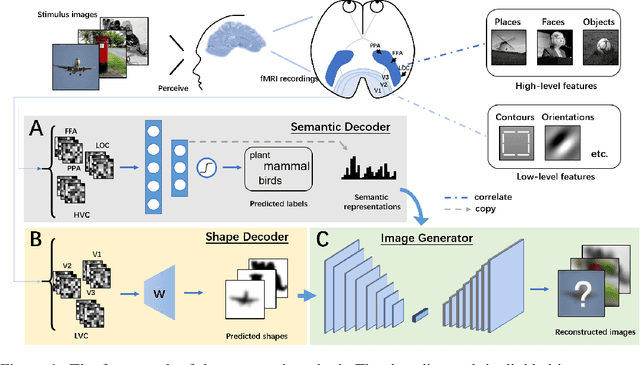
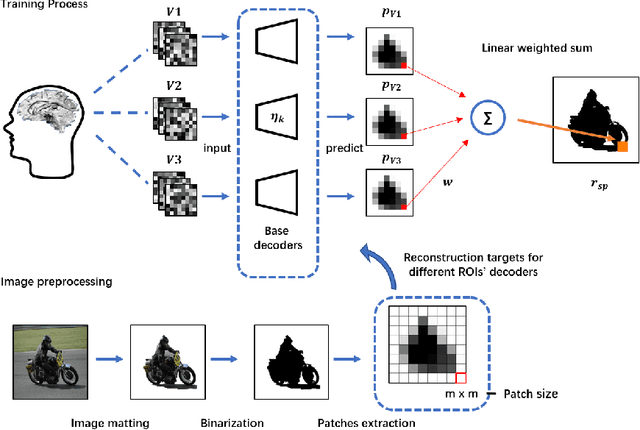
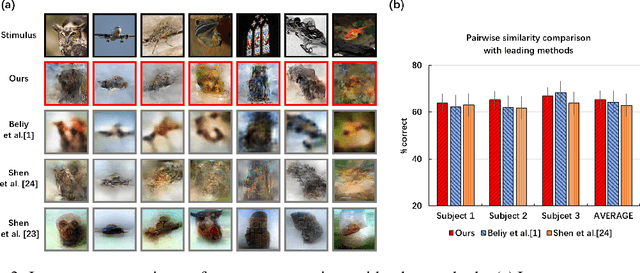
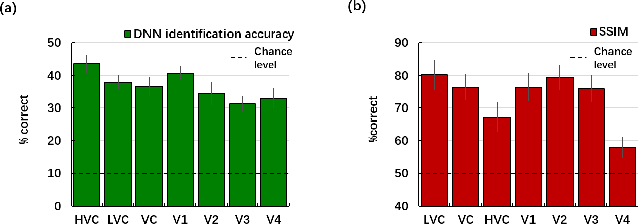
Reconstructing seeing images from fMRI recordings is an absorbing research area in neuroscience and provides a potential brain-reading technology. The challenge lies in that visual encoding in brain is highly complex and not fully revealed. Inspired by the theory that visual features are hierarchically represented in cortex, we propose to break the complex visual signals into multi-level components and decode each component separately. Specifically, we decode shape and semantic representations from the lower and higher visual cortex respectively, and merge the shape and semantic information to images by a generative adversarial network (Shape-Semantic GAN). This 'divide and conquer' strategy captures visual information more accurately. Experiments demonstrate that Shape-Semantic GAN improves the reconstruction similarity and image quality, and achieves the state-of-the-art image reconstruction performance.
Characterizing References from Different Disciplines: A Perspective of Citation Content Analysis
Jan 19, 2021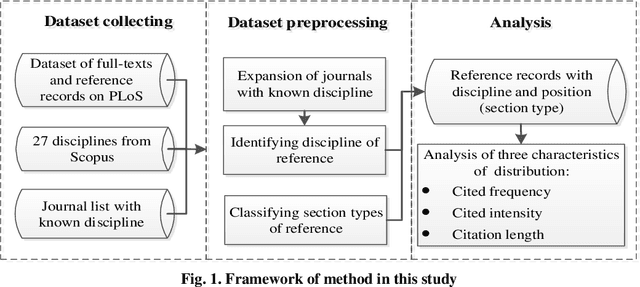
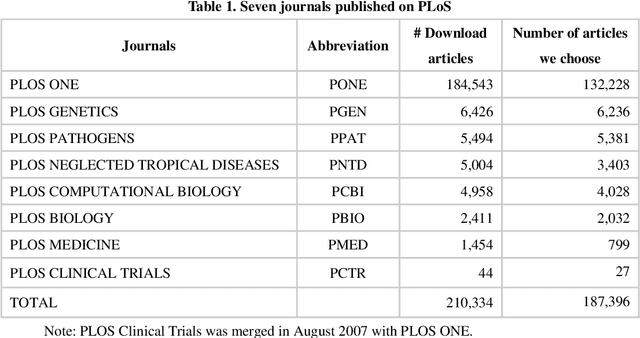
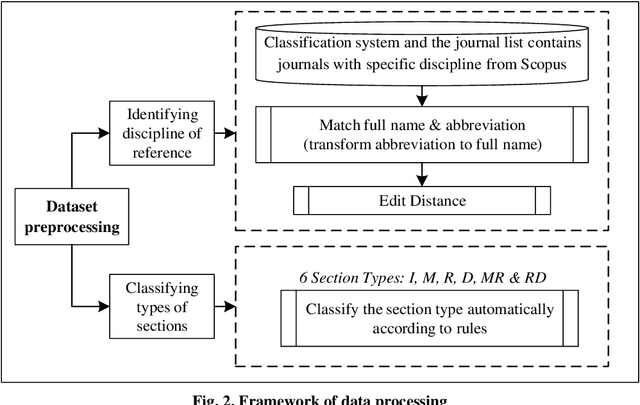
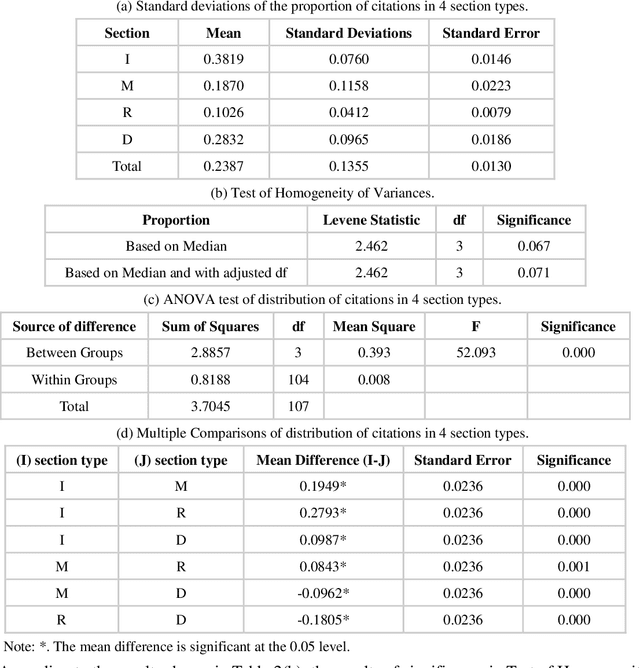
Multidisciplinary cooperation is now common in research since social issues inevitably involve multiple disciplines. In research articles, reference information, especially citation content, is an important representation of communication among different disciplines. Analyzing the distribution characteristics of references from different disciplines in research articles is basic to detecting the sources of referred information and identifying contributions of different disciplines. This work takes articles in PLoS as the data and characterizes the references from different disciplines based on Citation Content Analysis (CCA). First, we download 210,334 full-text articles from PLoS and collect the information of the in-text citations. Then, we identify the discipline of each reference in these academic articles. To characterize the distribution of these references, we analyze three characteristics, namely, the number of citations, the average cited intensity and the average citation length. Finally, we conclude that the distributions of references from different disciplines are significantly different. Although most references come from Natural Science, Humanities and Social Sciences play important roles in the Introduction and Background sections of the articles. Basic disciplines, such as Mathematics, mainly provide research methods in the articles in PLoS. Citations mentioned in the Results and Discussion sections of articles are mainly in-discipline citations, such as citations from Nursing and Medicine in PLoS.
Bosonic Random Walk Networks for Graph Learning
Dec 31, 2020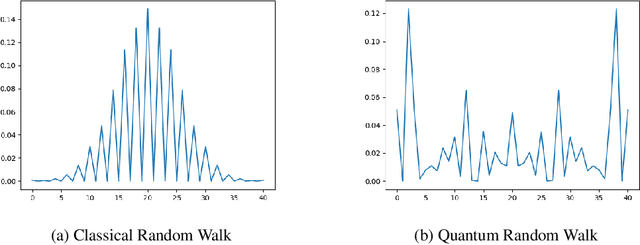
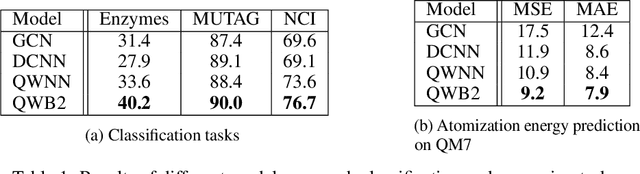
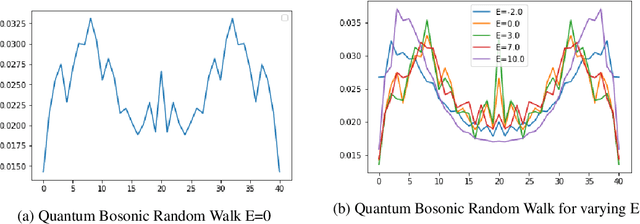
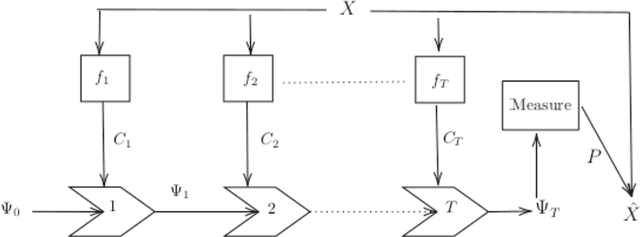
The development of Graph Neural Networks (GNNs) has led to great progress in machine learning on graph-structured data. These networks operate via diffusing information across the graph nodes while capturing the structure of the graph. Recently there has also seen tremendous progress in quantum computing techniques. In this work, we explore applications of multi-particle quantum walks on diffusing information across graphs. Our model is based on learning the operators that govern the dynamics of quantum random walkers on graphs. We demonstrate the effectiveness of our method on classification and regression tasks.