 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UIT-HSE at WNUT-2020 Task 2: Exploiting CT-BERT for Identifying COVID-19 Information on the Twitter Social Network
Oct 09, 2020



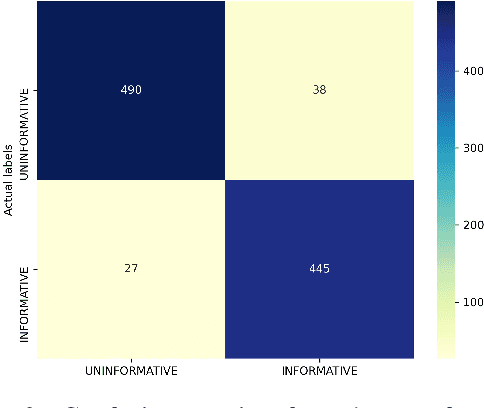
Recently, COVID-19 has affected a variety of real-life aspects of the world and led to dreadful consequences. More and more tweets about COVID-19 has been shared publicly on Twitter. However, the plurality of those Tweets are uninformative, which is challenging to build automatic systems to detect the informative ones for useful AI applications. In this paper, we present our results at the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. In particular, we propose our simple but effective approach using the transformer-based models based on COVID-Twitter-BERT (CT-BERT) with different fine-tuning techniques. As a result, we achieve the F1-Score of 90.94\% with the third place on the leaderboard of this task which attracted 56 submitted teams in total.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 03, 2021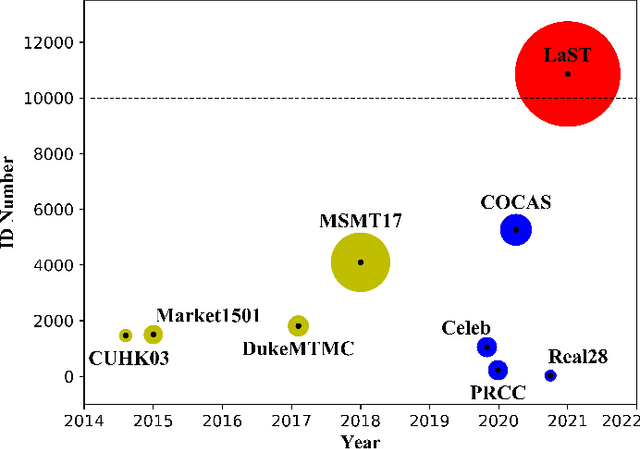
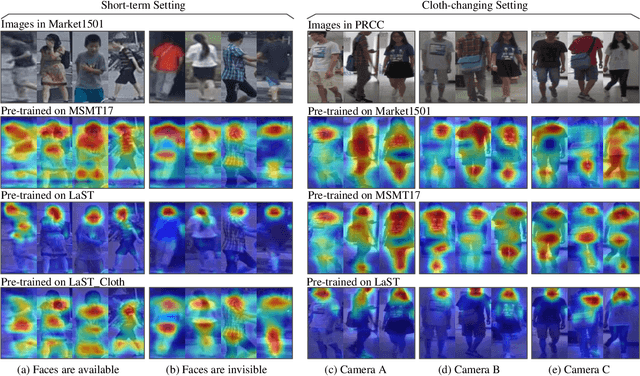
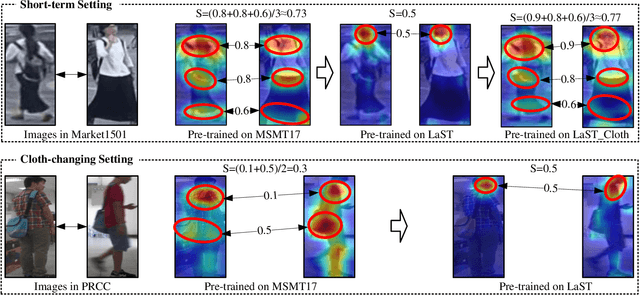

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal (LaST) person re-ID dataset, including 10,860 identities with more than 224k images. Compared with existing datasets, LaST presents more challenging and high-diversity reID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatiotemporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Exploring the Intrinsic Probability Distribution for Hyperspectral Anomaly Detection
May 14, 2021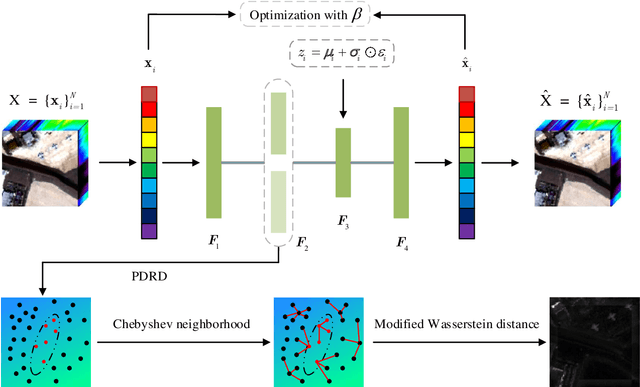
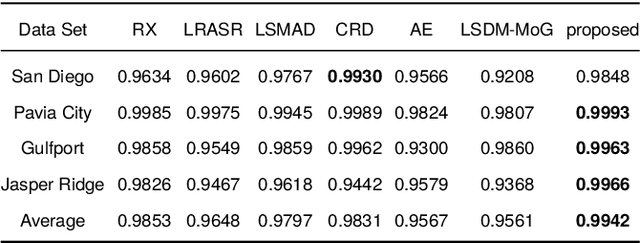

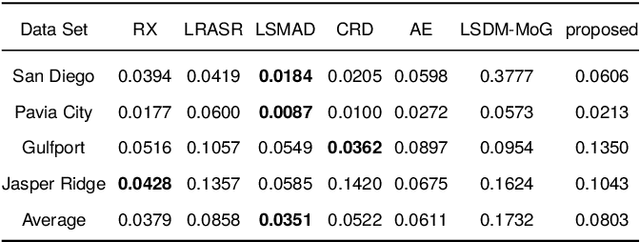
In recent years, neural network-based anomaly detection methods have attracted considerable attention in the hyperspectral remote sensing domain due to the powerful reconstruction ability compared with traditional methods. However, actual probability distribution statistics hidden in the latent space are not discovered by exploiting the reconstruction error because the probability distribution of anomalies is not explicitly modeled. To address the issue, we propose a novel probability distribution representation detector (PDRD) that explores the intrinsic distribution of both the background and the anomalies in original data for hyperspectral anomaly detection in this paper. First, we represent the hyperspectral data with multivariate Gaussian distributions from a probabilistic perspective. Then, we combine the local statistics with the obtained distributions to leverage the spatial information. Finally, the difference between the corresponding distributions of the test pixel and the average expectation of the pixels in the Chebyshev neighborhood is measured by computing the modified Wasserstein distance to acquire the detection map. We conduct the experiments on four real data sets to evaluate the performance of our proposed method. Experimental results demonstrate the accuracy and efficiency of our proposed method compared to the state-of-the-art detection methods.
The distribution of information content in English sentences
Sep 24, 2016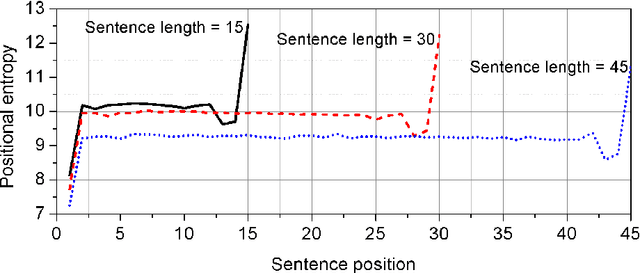
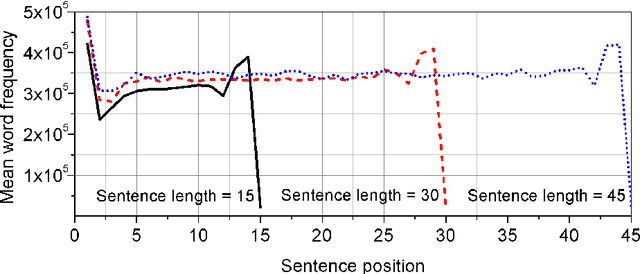
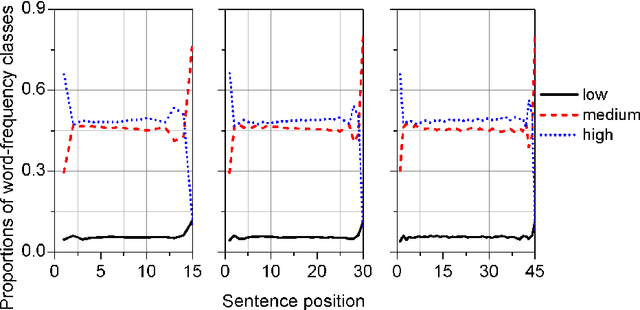
Sentence is a basic linguistic unit, however, little is known about how information content is distributed across different positions of a sentence. Based on authentic language data of English, the present study calculated the entropy and other entropy-related statistics for different sentence positions. The statistics indicate a three-step staircase-shaped distribution pattern, with entropy in the initial position lower than the medial positions (positions other than the initial and final), the medial positions lower than the final position and the medial positions showing no significant difference. The results suggest that: (1) the hypotheses of Constant Entropy Rate and Uniform Information Density do not hold for the sentence-medial positions; (2) the context of a word in a sentence should not be simply defined as all the words preceding it in the same sentence; and (3) the contextual information content in a sentence does not accumulate incrementally but follows a pattern of "the whole is greater than the sum of parts".
QA4IE: A Question Answering based Framework for Information Extraction
Apr 10, 2018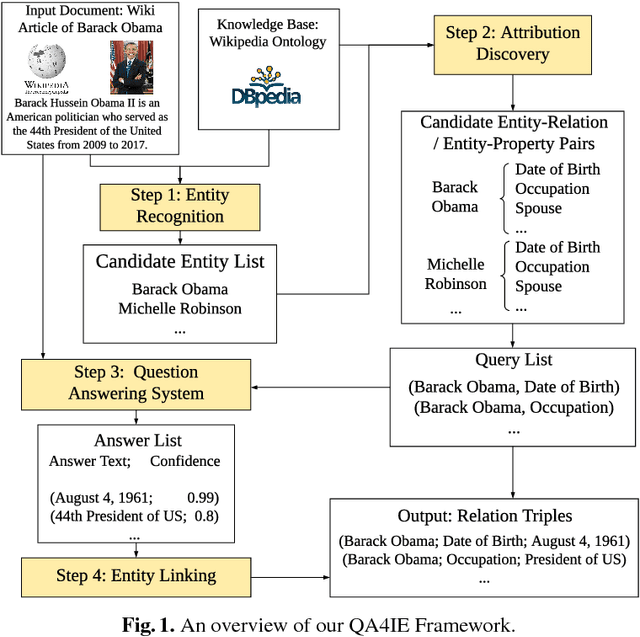
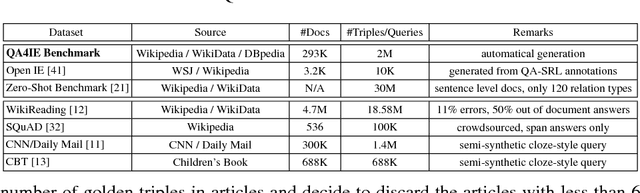
Information Extraction (IE) refers to automatically extracting structured relation tuples from unstructured texts. Common IE solutions, including Relation Extraction (RE) and open IE systems, can hardly handle cross-sentence tuples, and are severely restricted by limited relation types as well as informal relation specifications (e.g., free-text based relation tuples). In order to overcome these weaknesses, we propose a novel IE framework named QA4IE, which leverages the flexible question answering (QA) approaches to produce high quality relation triples across sentences. Based on the framework, we develop a large IE benchmark with high quality human evaluation. This benchmark contains 293K documents, 2M golden relation triples, and 636 relation types. We compare our system with some IE baselines on our benchmark and the results show that our system achieves great improvements.
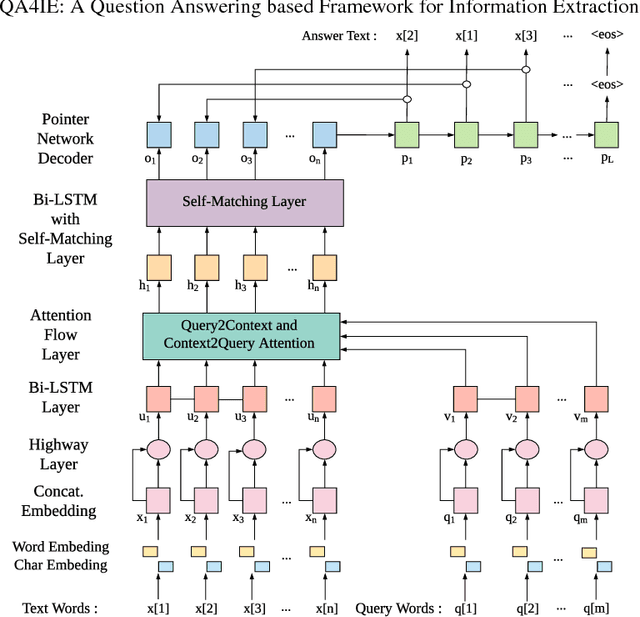
Verification of Size Invariance in DNN Activations using Concept Embeddings
May 14, 2021
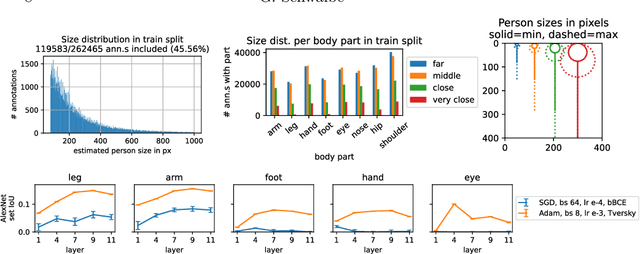
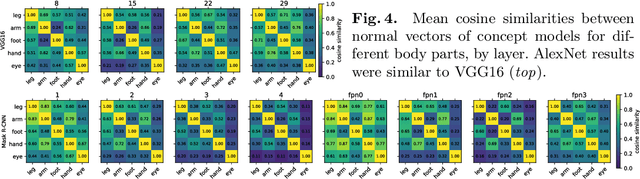
The benefits of deep neural networks (DNNs) have become of interest for safety critical applications like medical ones or automated driving. Here, however, quantitative insights into the DNN inner representations are mandatory. One approach to this is concept analysis, which aims to establish a mapping between the internal representation of a DNN and intuitive semantic concepts. Such can be sub-objects like human body parts that are valuable for validation of pedestrian detection. To our knowledge, concept analysis has not yet been applied to large object detectors, specifically not for sub-parts. Therefore, this work first suggests a substantially improved version of the Net2Vec approach (arXiv:1801.03454) for post-hoc segmentation of sub-objects. Its practical applicability is then demonstrated on a new concept dataset by two exemplary assessments of three standard networks, including the larger Mask R-CNN model (arXiv:1703.06870): (1) the consistency of body part similarity, and (2) the invariance of internal representations of body parts with respect to the size in pixels of the depicted person. The findings show that the representation of body parts is mostly size invariant, which may suggest an early intelligent fusion of information in different size categories.
Bangla Natural Language Processing: A Comprehensive Review of Classical, Machine Learning, and Deep Learning Based Methods
Jun 08, 2021

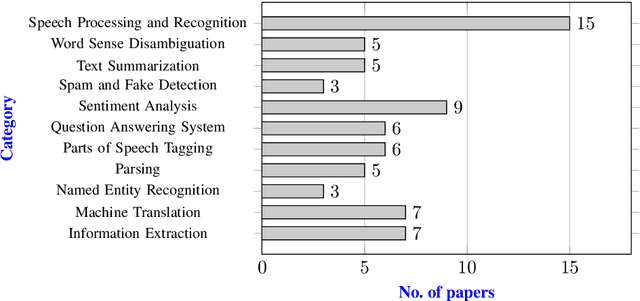
The Bangla language is the seventh most spoken language, with 265 million native and non-native speakers worldwide. However, English is the predominant language for online resources and technical knowledge, journals, and documentation. Consequently, many Bangla-speaking people, who have limited command of English, face hurdles to utilize English resources. To bridge the gap between limited support and increasing demand, researchers conducted many experiments and developed valuable tools and techniques to create and process Bangla language materials. Many efforts are also ongoing to make it easy to use the Bangla language in the online and technical domains. There are some review papers to understand the past, previous, and future Bangla Natural Language Processing (BNLP) trends. The studies are mainly concentrated on the specific domains of BNLP, such as sentiment analysis, speech recognition, optical character recognition, and text summarization. There is an apparent scarcity of resources that contain a comprehensive study of the recent BNLP tools and methods. Therefore, in this paper, we present a thorough review of 71 BNLP research papers and categorize them into 11 categories, namely Information Extraction, Machine Translation, Named Entity Recognition, Parsing, Parts of Speech Tagging, Question Answering System, Sentiment Analysis, Spam and Fake Detection, Text Summarization, Word Sense Disambiguation, and Speech Processing and Recognition. We study articles published between 1999 to 2021, and 50% of the papers were published after 2015. We discuss Classical, Machine Learning and Deep Learning approaches with different datasets while addressing the limitations and current and future trends of the BNLP.
Dynamic Texture Synthesis by Incorporating Long-range Spatial and Temporal Correlations
Apr 14, 2021

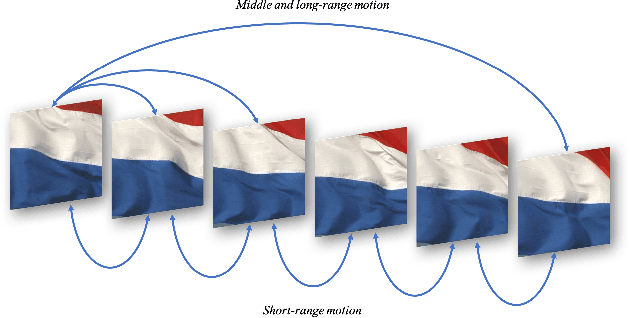

The main challenge of dynamic texture synthesis lies in how to maintain spatial and temporal consistency in synthesized videos. The major drawback of existing dynamic texture synthesis models comes from poor treatment of the long-range texture correlation and motion information. To address this problem, we incorporate a new loss term, called the Shifted Gram loss, to capture the structural and long-range correlation of the reference texture video. Furthermore, we introduce a frame sampling strategy to exploit long-period motion across multiple frames. With these two new techniques, the application scope of existing texture synthesis models can be extended. That is, they can synthesize not only homogeneous but also structured dynamic texture patterns. Thorough experimental results are provided to demonstrate that our proposed dynamic texture synthesis model offers state-of-the-art visual performance.
ABCNet: Attentive Bilateral Contextual Network for Efficient Semantic Segmentation of Fine-Resolution Remote Sensing Images
Feb 04, 2021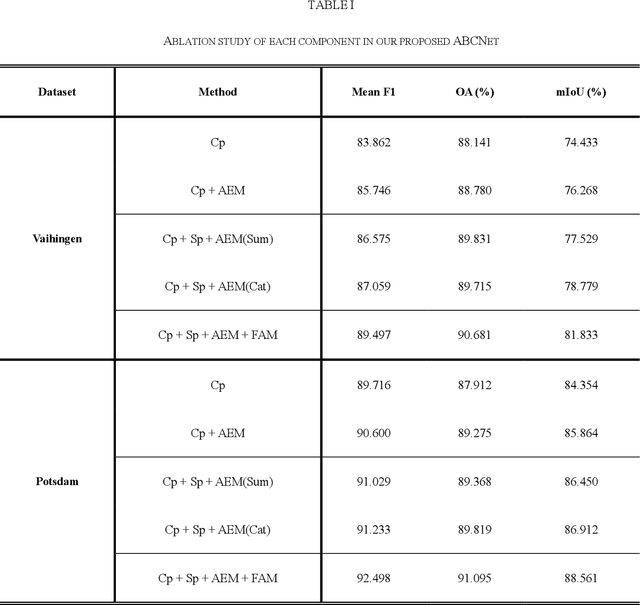
Semantic segmentation of remotely sensed images plays a crucial role in precision agriculture, environmental protection, and economic assessment. In recent years, substantial fine-resolution remote sensing images are available for semantic segmentation. However, due to the complicated information caused by the increased spatial resolution, state-of-the-art deep learning algorithms normally utilize complex network architectures for segmentation, which usually incurs high computational complexity. Specifically, the high-caliber performance of the convolutional neural network (CNN) heavily relies on fine-grained spatial details (fine resolution) and sufficient contextual information (large receptive fields), both of which trigger high computational costs. This crucially impedes their practicability and availability in real-world scenarios that require real-time processing. In this paper, we propose an Attentive Bilateral Contextual Network (ABCNet), a convolutional neural network (CNN) with double branches, with prominently lower computational consumptions compared to the cutting-edge algorithms, while maintaining a competitive accuracy. Code is available at https://github.com/lironui/ABCNet.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021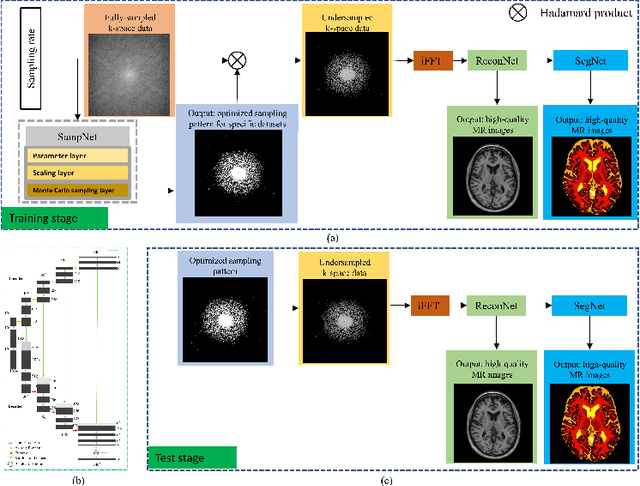
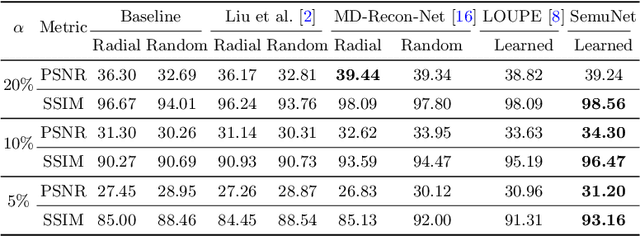
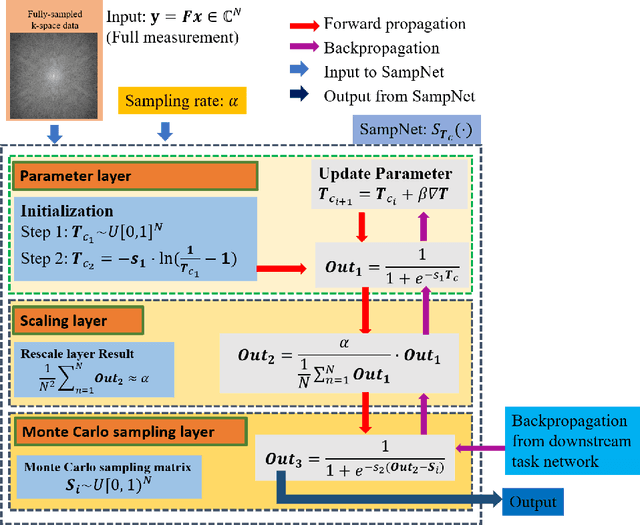
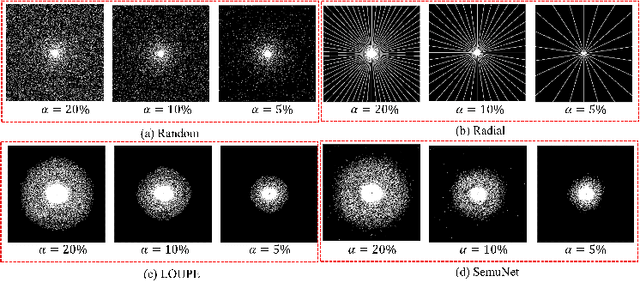
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.