 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large-scale memory failure prediction using mcelog-based Data Mining and Machine Learning
Apr 24, 2021
In the data center, unexpected downtime caused by memory failures can lead to a decline in the stability of the server and even the entire information technology infrastructure, which harms the business. Therefore, whether the memory failure can be accurately predicted in advance has become one of the most important issues to be studied in the data center. However, for the memory failure prediction in the production system, it is necessary to solve technical problems such as huge data noise and extreme imbalance between positive and negative samples, and at the same time ensure the long-term stability of the algorithm. This paper compares and summarizes some commonly used skills and the improvement they can bring. The single model we proposed won the top 15th in the 2nd Alibaba Cloud AIOps Competition belonging to the 25th Pacific-Asia Conference on Knowledge Discovery and Data Mining.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
UIT-HSE at WNUT-2020 Task 2: Exploiting CT-BERT for Identifying COVID-19 Information on the Twitter Social Network
Oct 09, 2020


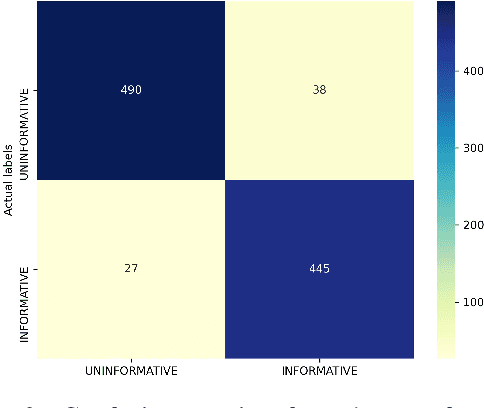
Recently, COVID-19 has affected a variety of real-life aspects of the world and led to dreadful consequences. More and more tweets about COVID-19 has been shared publicly on Twitter. However, the plurality of those Tweets are uninformative, which is challenging to build automatic systems to detect the informative ones for useful AI applications. In this paper, we present our results at the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. In particular, we propose our simple but effective approach using the transformer-based models based on COVID-Twitter-BERT (CT-BERT) with different fine-tuning techniques. As a result, we achieve the F1-Score of 90.94\% with the third place on the leaderboard of this task which attracted 56 submitted teams in total.
Adaptive Prototypical Networks with Label Words and Joint Representation Learning for Few-Shot Relation Classification
Jan 10, 2021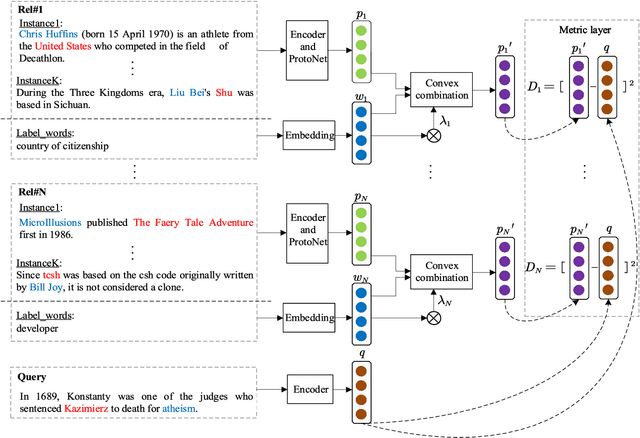
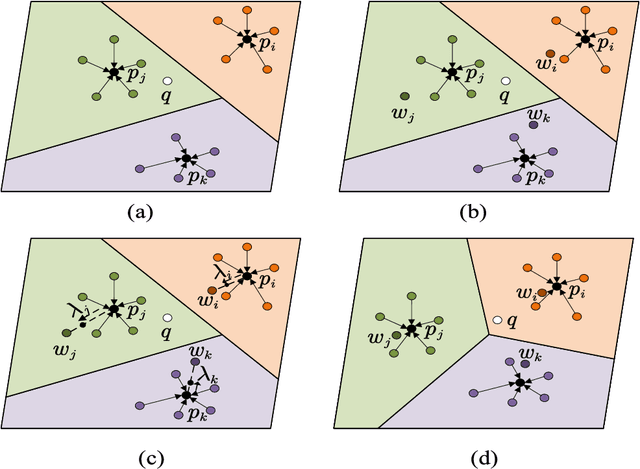
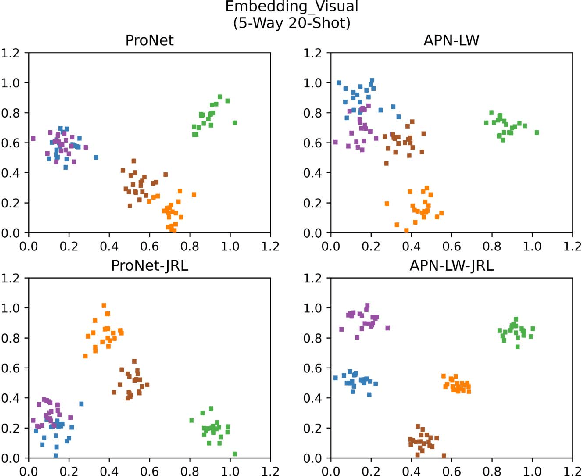
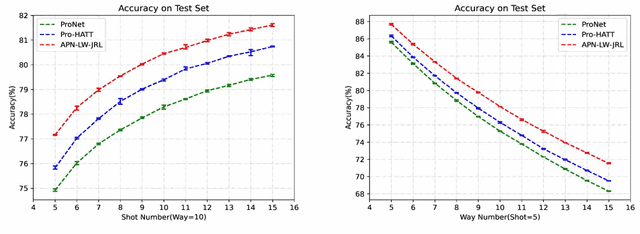
Relation classification (RC) task is one of fundamental tasks of information extraction, aiming to detect the relation information between entity pairs in unstructured natural language text and generate structured data in the form of entity-relation triple. Although distant supervision methods can effectively alleviate the problem of lack of training data in supervised learning, they also introduce noise into the data, and still cannot fundamentally solve the long-tail distribution problem of the training instances. In order to enable the neural network to learn new knowledge through few instances like humans, this work focuses on few-shot relation classification (FSRC), where a classifier should generalize to new classes that have not been seen in the training set, given only a number of samples for each class. To make full use of the existing information and get a better feature representation for each instance, we propose to encode each class prototype in an adaptive way from two aspects. First, based on the prototypical networks, we propose an adaptive mixture mechanism to add label words to the representation of the class prototype, which, to the best of our knowledge, is the first attempt to integrate the label information into features of the support samples of each class so as to get more interactive class prototypes. Second, to more reasonably measure the distances between samples of each category, we introduce a loss function for joint representation learning to encode each support instance in an adaptive manner. Extensive experiments have been conducted on FewRel under different few-shot (FS) settings, and the results show that the proposed adaptive prototypical networks with label words and joint representation learning has not only achieved significant improvements in accuracy, but also increased the generalization ability of few-shot RC models.
Embracing New Techniques in Deep Learning for Estimating Image Memorability
May 21, 2021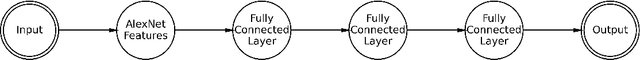
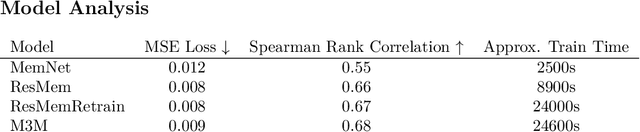
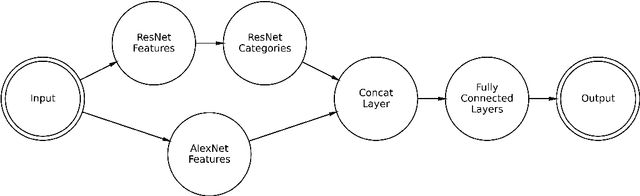
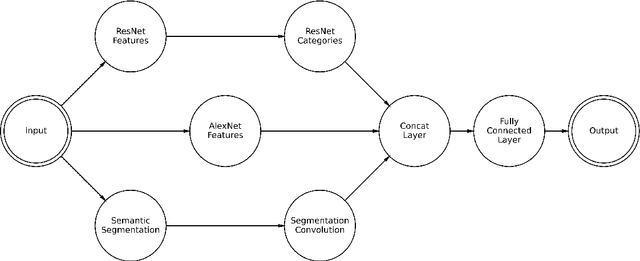
Various work has suggested that the memorability of an image is consistent across people, and thus can be treated as an intrinsic property of an image. Using computer vision models, we can make specific predictions about what people will remember or forget. While older work has used now-outdated deep learning architectures to predict image memorability, innovations in the field have given us new techniques to apply to this problem. Here, we propose and evaluate five alternative deep learning models which exploit developments in the field from the last five years, largely the introduction of residual neural networks, which are intended to allow the model to use semantic information in the memorability estimation process. These new models were tested against the prior state of the art with a combined dataset built to optimize both within-category and across-category predictions. Our findings suggest that the key prior memorability network had overstated its generalizability and was overfit on its training set. Our new models outperform this prior model, leading us to conclude that Residual Networks outperform simpler convolutional neural networks in memorability regression. We make our new state-of-the-art model readily available to the research community, allowing memory researchers to make predictions about memorability on a wider range of images.
Gradient-augmented Supervised Learning of Optimal Feedback Laws Using State-dependent Riccati Equations
Mar 06, 2021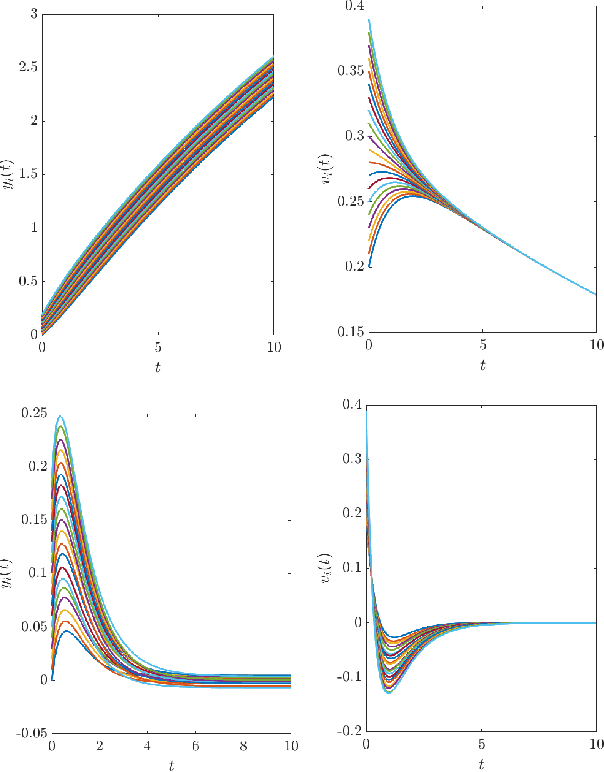
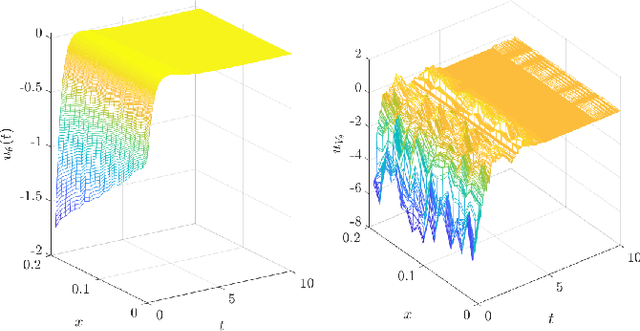
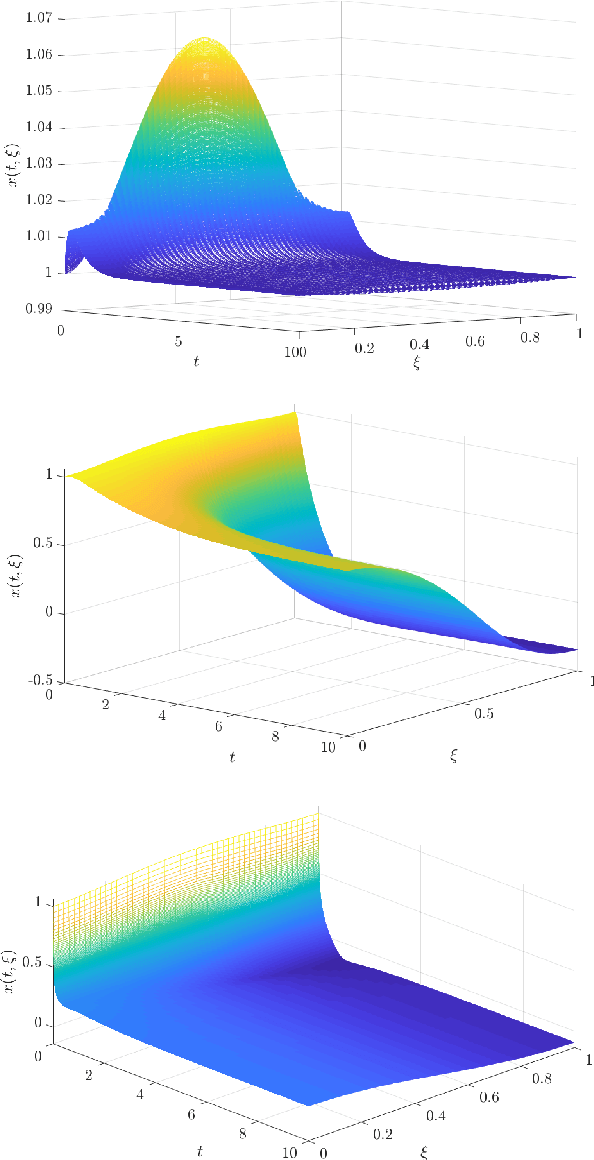
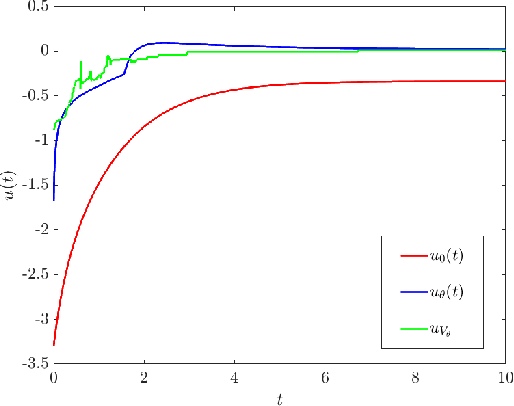
A supervised learning approach for the solution of large-scale nonlinear stabilization problems is presented. A stabilizing feedback law is trained from a dataset generated from State-dependent Riccati Equation solves. The training phase is enriched by the use gradient information in the loss function, which is weighted through the use of hyperparameters. High-dimensional nonlinear stabilization tests demonstrate that real-time sequential large-scale Algebraic Riccati Equation solves can be substituted by a suitably trained feedforward neural network.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021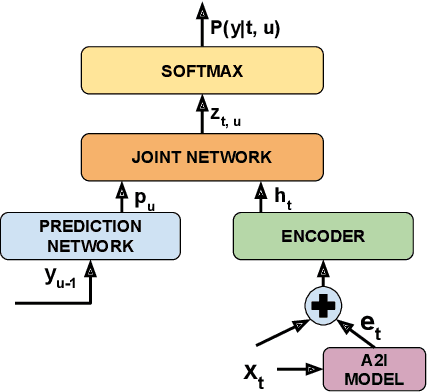
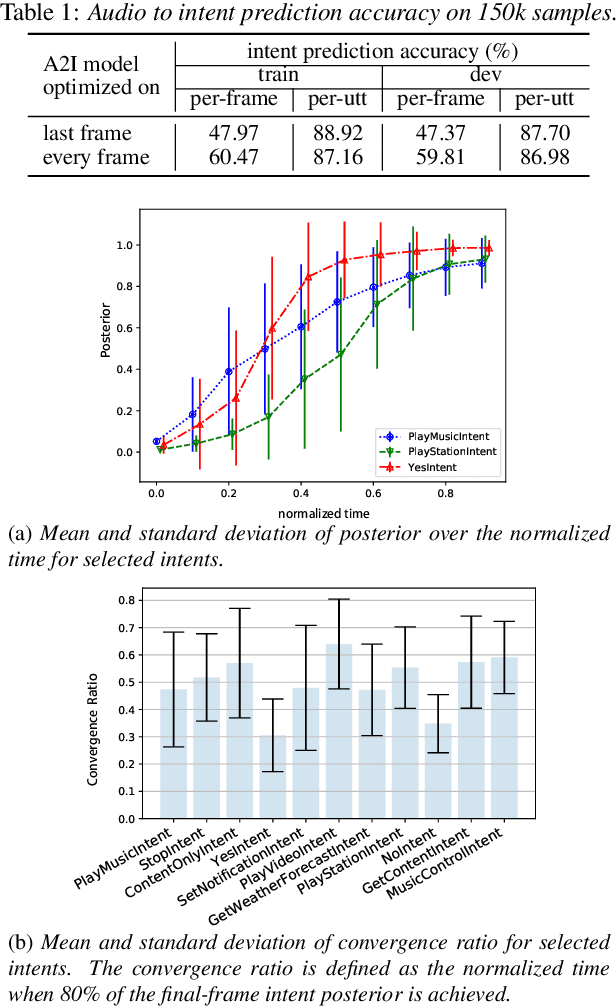
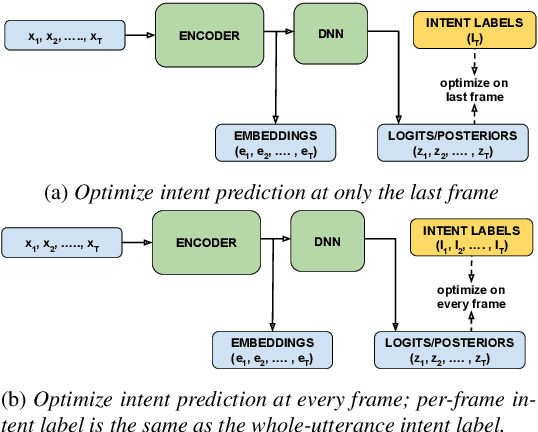
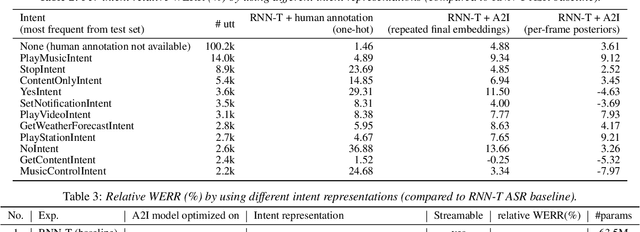
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Ask & Explore: Grounded Question Answering for Curiosity-Driven Exploration
Apr 24, 2021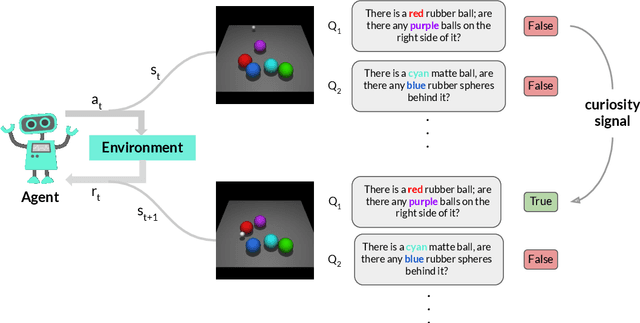
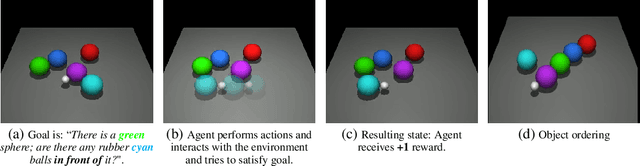
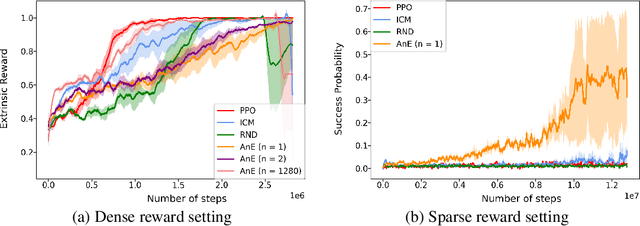
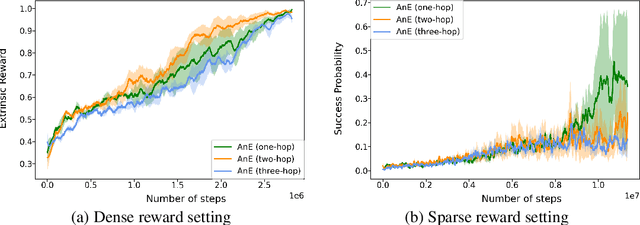
In many real-world scenarios where extrinsic rewards to the agent are extremely sparse, curiosity has emerged as a useful concept providing intrinsic rewards that enable the agent to explore its environment and acquire information to achieve its goals. Despite their strong performance on many sparse-reward tasks, existing curiosity approaches rely on an overly holistic view of state transitions, and do not allow for a structured understanding of specific aspects of the environment. In this paper, we formulate curiosity based on grounded question answering by encouraging the agent to ask questions about the environment and be curious when the answers to these questions change. We show that natural language questions encourage the agent to uncover specific knowledge about their environment such as the physical properties of objects as well as their spatial relationships with other objects, which serve as valuable curiosity rewards to solve sparse-reward tasks more efficiently.
Information, learning and falsification
Nov 28, 2011There are (at least) three approaches to quantifying information. The first, algorithmic information or Kolmogorov complexity, takes events as strings and, given a universal Turing machine, quantifies the information content of a string as the length of the shortest program producing it. The second, Shannon information, takes events as belonging to ensembles and quantifies the information resulting from observing the given event in terms of the number of alternate events that have been ruled out. The third, statistical learning theory, has introduced measures of capacity that control (in part) the expected risk of classifiers. These capacities quantify the expectations regarding future data that learning algorithms embed into classifiers. This note describes a new method of quantifying information, effective information, that links algorithmic information to Shannon information, and also links both to capacities arising in statistical learning theory. After introducing the measure, we show that it provides a non-universal analog of Kolmogorov complexity. We then apply it to derive basic capacities in statistical learning theory: empirical VC-entropy and empirical Rademacher complexity. A nice byproduct of our approach is an interpretation of the explanatory power of a learning algorithm in terms of the number of hypotheses it falsifies, counted in two different ways for the two capacities. We also discuss how effective information relates to information gain, Shannon and mutual information.
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
May 28, 2021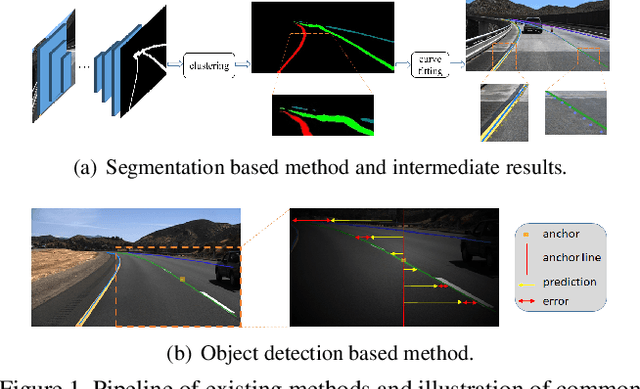
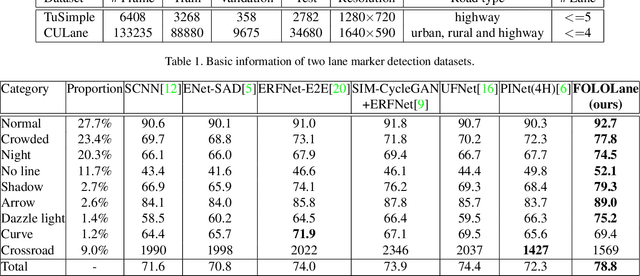
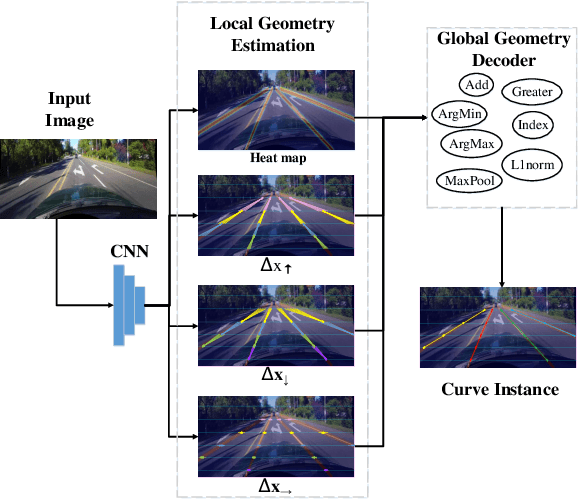

Mainstream lane marker detection methods are implemented by predicting the overall structure and deriving parametric curves through post-processing. Complex lane line shapes require high-dimensional output of CNNs to model global structures, which further increases the demand for model capacity and training data. In contrast, the locality of a lane marker has finite geometric variations and spatial coverage. We propose a novel lane marker detection solution, FOLOLane, that focuses on modeling local patterns and achieving prediction of global structures in a bottom-up manner. Specifically, the CNN models lowcomplexity local patterns with two separate heads, the first one predicts the existence of key points, and the second refines the location of key points in the local range and correlates key points of the same lane line. The locality of the task is consistent with the limited FOV of the feature in CNN, which in turn leads to more stable training and better generalization. In addition, an efficiency-oriented decoding algorithm was proposed as well as a greedy one, which achieving 36% runtime gains at the cost of negligible performance degradation. Both of the two decoders integrated local information into the global geometry of lane markers. In the absence of a complex network architecture design, the proposed method greatly outperforms all existing methods on public datasets while achieving the best state-of-the-art results and real-time processing simultaneously.