 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ManyTypes4Py: A Benchmark Python Dataset for Machine Learning-based Type Inference
Apr 10, 2021
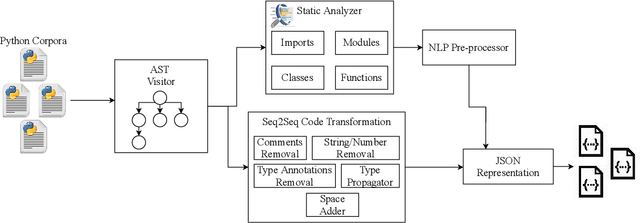
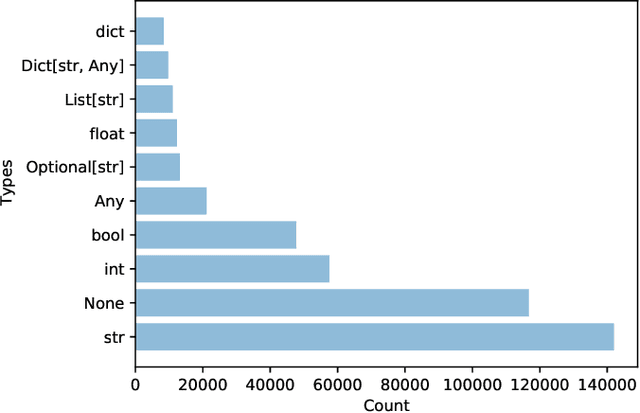

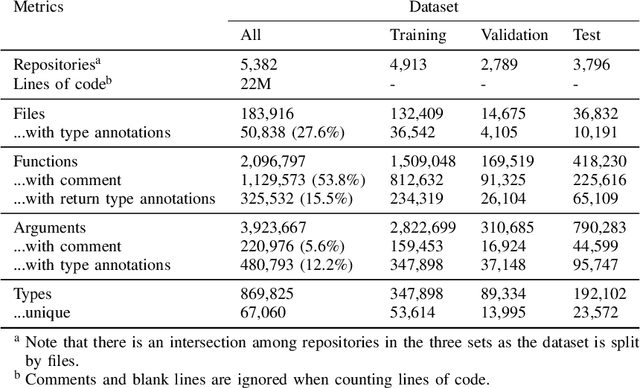
In this paper, we present ManyTypes4Py, a large Python dataset for machine learning (ML)-based type inference. The dataset contains a total of 5,382 Python projects with more than 869K type annotations. Duplicate source code files were removed to eliminate the negative effect of the duplication bias. To facilitate training and evaluation of ML models, the dataset was split into training, validation and test sets by files. To extract type information from abstract syntax trees (ASTs), a lightweight static analyzer pipeline is developed and accompanied with the dataset. Using this pipeline, the collected Python projects were analyzed and the results of the AST analysis were stored in JSON-formatted files. The ManyTypes4Py dataset is shared on zenodo and its tools are publicly available on GitHub.
A Spectral-Spatial-Dependent Global Learning Framework for Insufficient and Imbalanced Hyperspectral Image Classification
May 29, 2021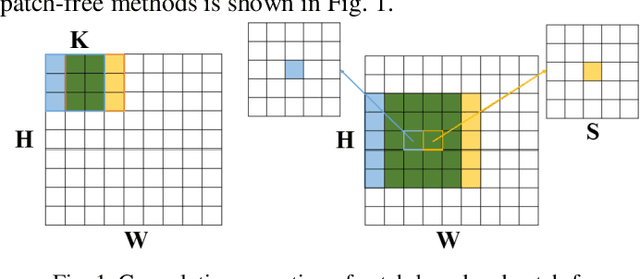
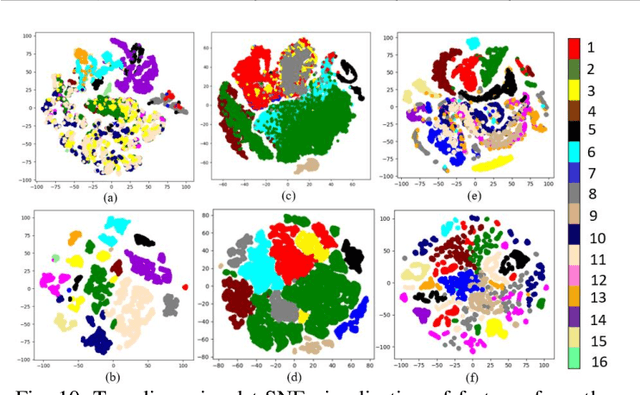
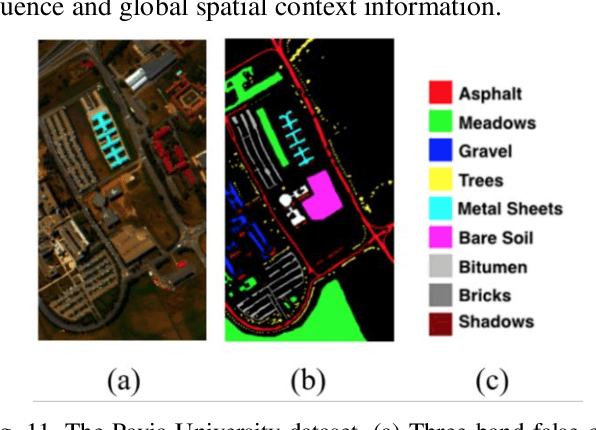

Deep learning techniques have been widely applied to hyperspectral image (HSI) classification and have achieved great success. However, the deep neural network model has a large parameter space and requires a large number of labeled data. Deep learning methods for HSI classification usually follow a patchwise learning framework. Recently, a fast patch-free global learning (FPGA) architecture was proposed for HSI classification according to global spatial context information. However, FPGA has difficulty extracting the most discriminative features when the sample data is imbalanced. In this paper, a spectral-spatial dependent global learning (SSDGL) framework based on global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) is proposed for insufficient and imbalanced HSI classification. In SSDGL, the hierarchically balanced (H-B) sampling strategy and the weighted softmax loss are proposed to address the imbalanced sample problem. To effectively distinguish similar spectral characteristics of land cover types, the GCL module is introduced to extract the long short-term dependency of spectral features. To learn the most discriminative feature representations, the GJAM module is proposed to extract attention areas. The experimental results obtained with three public HSI datasets show that the SSDGL has powerful performance in insufficient and imbalanced sample problems and is superior to other state-of-the-art methods. Code can be obtained at: https://github.com/dengweihuan/SSDGL.
Natural continual learning: success is a journey, not (just) a destination
Jun 15, 2021
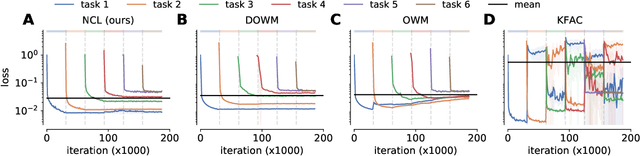
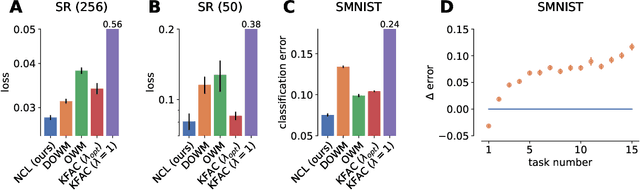
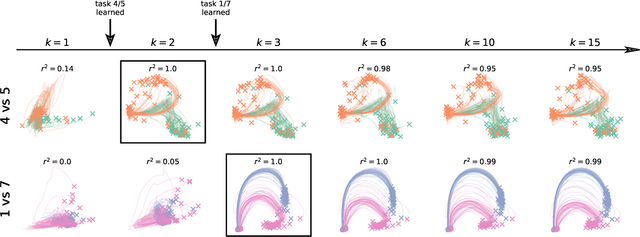
Biological agents are known to learn many different tasks over the course of their lives, and to be able to revisit previous tasks and behaviors with little to no loss in performance. In contrast, artificial agents are prone to 'catastrophic forgetting' whereby performance on previous tasks deteriorates rapidly as new ones are acquired. This shortcoming has recently been addressed using methods that encourage parameters to stay close to those used for previous tasks. This can be done by (i) using specific parameter regularizers that map out suitable destinations in parameter space, or (ii) guiding the optimization journey by projecting gradients into subspaces that do not interfere with previous tasks. However, parameter regularization has been shown to be relatively ineffective in recurrent neural networks (RNNs), a setting relevant to the study of neural dynamics supporting biological continual learning. Similarly, projection based methods can reach capacity and fail to learn any further as the number of tasks increases. To address these limitations, we propose Natural Continual Learning (NCL), a new method that unifies weight regularization and projected gradient descent. NCL uses Bayesian weight regularization to encourage good performance on all tasks at convergence and combines this with gradient projections designed to prevent catastrophic forgetting during optimization. NCL formalizes gradient projection as a trust region algorithm based on the Fisher information metric, and achieves scalability via a novel Kronecker-factored approximation strategy. Our method outperforms both standard weight regularization techniques and projection based approaches when applied to continual learning problems in RNNs. The trained networks evolve task-specific dynamics that are strongly preserved as new tasks are learned, similar to experimental findings in biological circuits.
Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding
Jun 04, 2021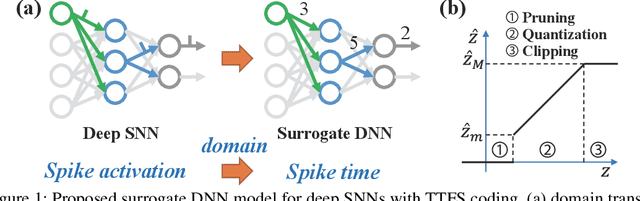
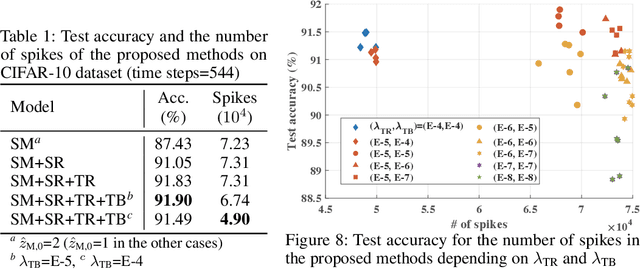
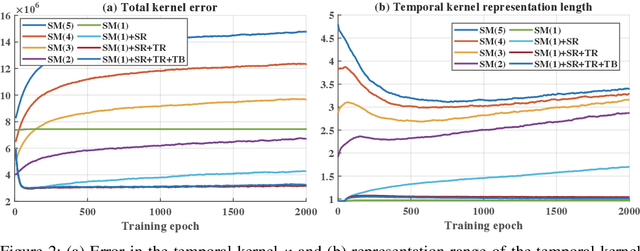
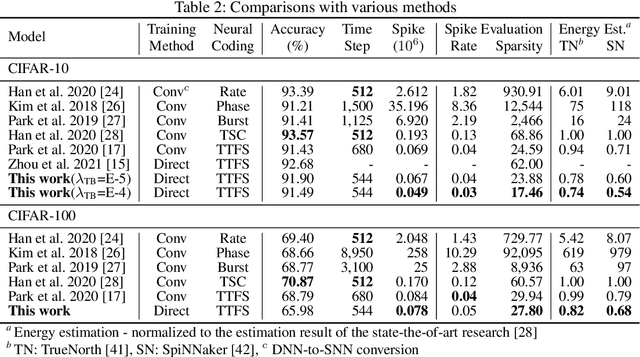
The tremendous energy consumption of deep neural networks (DNNs) has become a serious problem in deep learning. Spiking neural networks (SNNs), which mimic the operations in the human brain, have been studied as prominent energy-efficient neural networks. Due to their event-driven and spatiotemporally sparse operations, SNNs show possibilities for energy-efficient processing. To unlock their potential, deep SNNs have adopted temporal coding such as time-to-first-spike (TTFS)coding, which represents the information between neurons by the first spike time. With TTFS coding, each neuron generates one spike at most, which leads to a significant improvement in energy efficiency. Several studies have successfully introduced TTFS coding in deep SNNs, but they showed restricted efficiency improvement owing to the lack of consideration for efficiency during training. To address the aforementioned issue, this paper presents training methods for energy-efficient deep SNNs with TTFS coding. We introduce a surrogate DNN model to train the deep SNN in a feasible time and analyze the effect of the temporal kernel on training performance and efficiency. Based on the investigation, we propose stochastically relaxed activation and initial value-based regularization for the temporal kernel parameters. In addition, to reduce the number of spikes even further, we present temporal kernel-aware batch normalization. With the proposed methods, we could achieve comparable training results with significantly reduced spikes, which could lead to energy-efficient deep SNNs.
Lighting, Reflectance and Geometry Estimation from 360$^{\circ}$ Panoramic Stereo
Apr 20, 2021
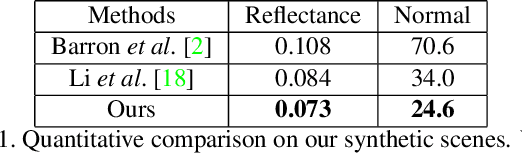
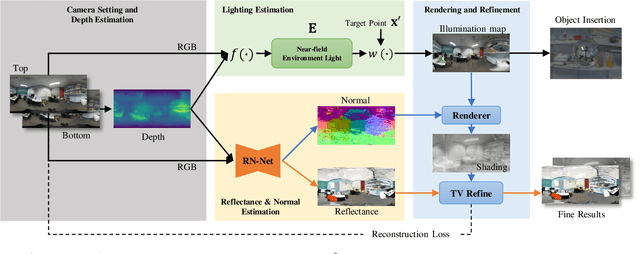
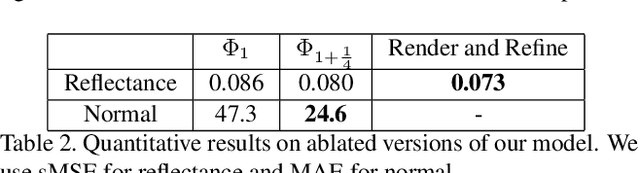
We propose a method for estimating high-definition spatially-varying lighting, reflectance, and geometry of a scene from 360$^{\circ}$ stereo images. Our model takes advantage of the 360$^{\circ}$ input to observe the entire scene with geometric detail, then jointly estimates the scene's properties with physical constraints. We first reconstruct a near-field environment light for predicting the lighting at any 3D location within the scene. Then we present a deep learning model that leverages the stereo information to infer the reflectance and surface normal. Lastly, we incorporate the physical constraints between lighting and geometry to refine the reflectance of the scene. Both quantitative and qualitative experiments show that our method, benefiting from the 360$^{\circ}$ observation of the scene, outperforms prior state-of-the-art methods and enables more augmented reality applications such as mirror-objects insertion.
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021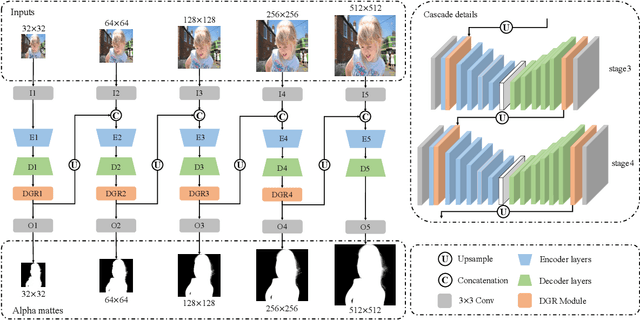
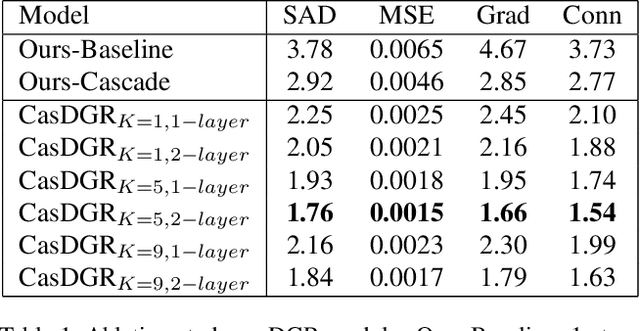
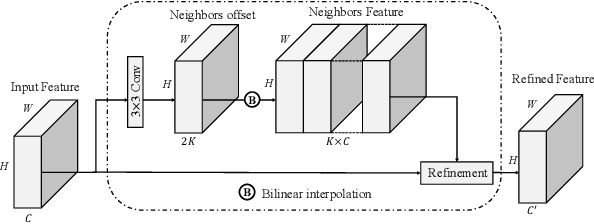
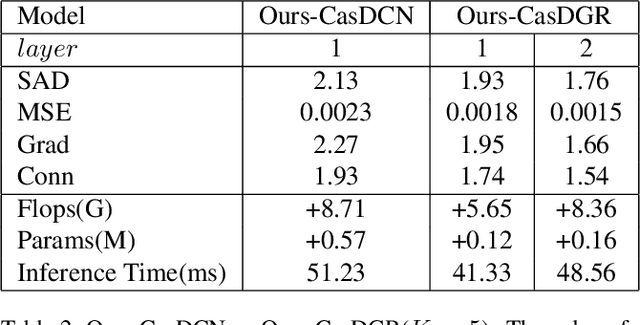
Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.
Domestic activities clustering from audio recordings using convolutional capsule autoencoder network
May 08, 2021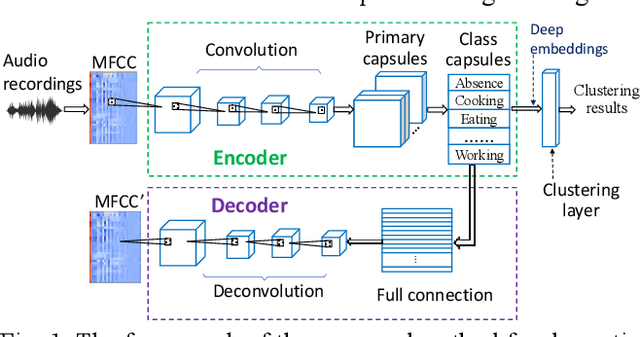


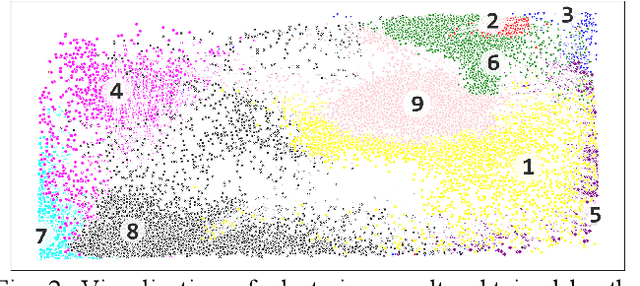
Recent efforts have been made on domestic activities classification from audio recordings, especially the works submitted to the challenge of DCASE (Detection and Classification of Acoustic Scenes and Events) since 2018. In contrast, few studies were done on domestic activities clustering, which is a newly emerging problem. Domestic activities clustering from audio recordings aims at merging audio clips which belong to the same class of domestic activity into a single cluster. Domestic activities clustering is an effective way for unsupervised estimation of daily activities performed in home environment. In this study, we propose a method for domestic activities clustering using a convolutional capsule autoencoder network (CCAN). In the method, the deep embeddings are learned by the autoencoder in the CCAN, while the deep embeddings which belong to the same class of domestic activities are merged into a single cluster by a clustering layer in the CCAN. Evaluated on a public dataset adopted in DCASE-2018 Task 5, the results show that the proposed method outperforms state-of-the-art methods in terms of the metrics of clustering accuracy and normalized mutual information.
Multiscale Clustering of Hyperspectral Images Through Spectral-Spatial Diffusion Geometry
Mar 29, 2021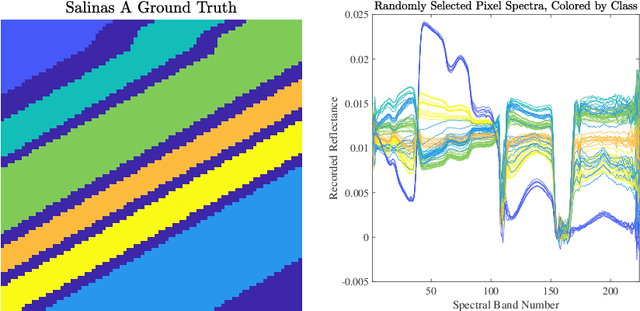
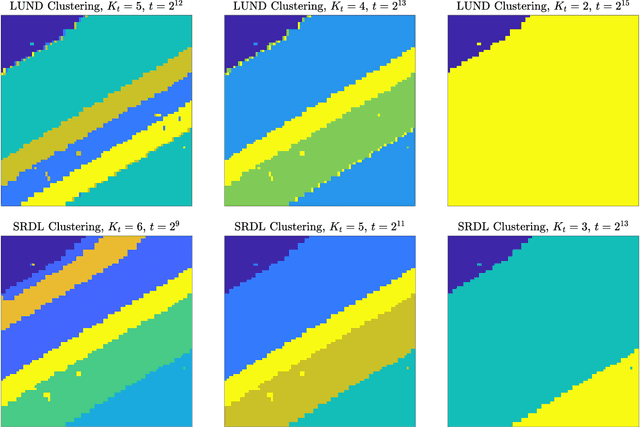
Clustering algorithms partition a dataset into groups of similar points. The primary contribution of this article is the Multiscale Spatially-Regularized Diffusion Learning (M-SRDL) clustering algorithm, which uses spatially-regularized diffusion distances to efficiently and accurately learn multiple scales of latent structure in hyperspectral images (HSI). The M-SRDL clustering algorithm extracts clusterings at many scales from an HSI and outputs these clusterings' variation of information-barycenter as an exemplar for all underlying cluster structure. We show that incorporating spatial regularization into a multiscale clustering framework corresponds to smoother and more coherent clusters when applied to HSI data and leads to more accurate clustering labels.
Post-Estimation Smoothing: A Simple Baseline for Learning with Side Information
Mar 12, 2020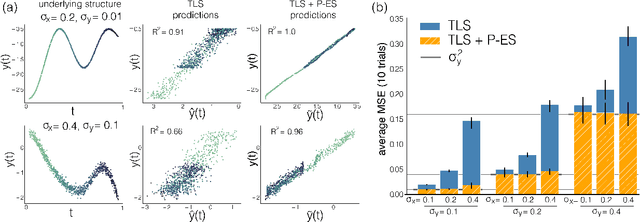
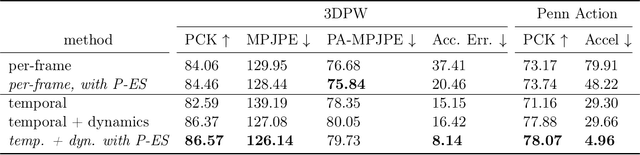
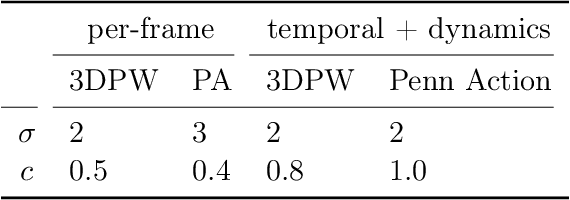
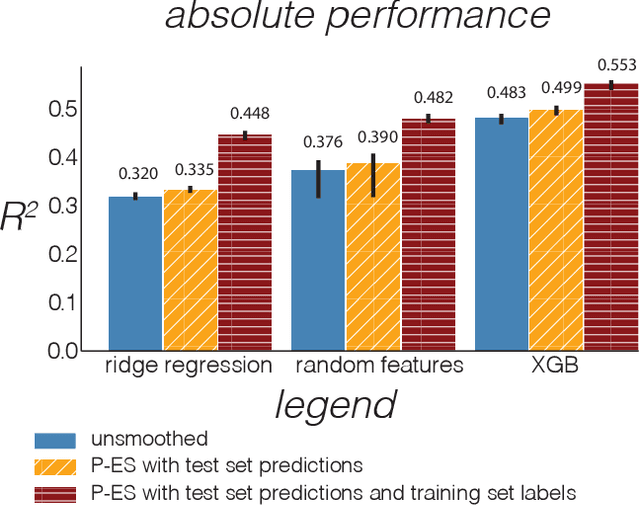
Observational data are often accompanied by natural structural indices, such as time stamps or geographic locations, which are meaningful to prediction tasks but are often discarded. We leverage semantically meaningful indexing data while ensuring robustness to potentially uninformative or misleading indices. We propose a post-estimation smoothing operator as a fast and effective method for incorporating structural index data into prediction. Because the smoothing step is separate from the original predictor, it applies to a broad class of machine learning tasks, with no need to retrain models. Our theoretical analysis details simple conditions under which post-estimation smoothing will improve accuracy over that of the original predictor. Our experiments on large scale spatial and temporal datasets highlight the speed and accuracy of post-estimation smoothing in practice. Together, these results illuminate a novel way to consider and incorporate the natural structure of index variables in machine learning.
An Analysis of Indexing and Querying Strategies on a Technologically Assisted Review Task
Apr 20, 2021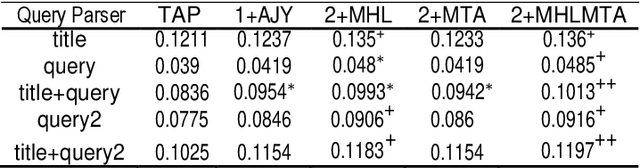
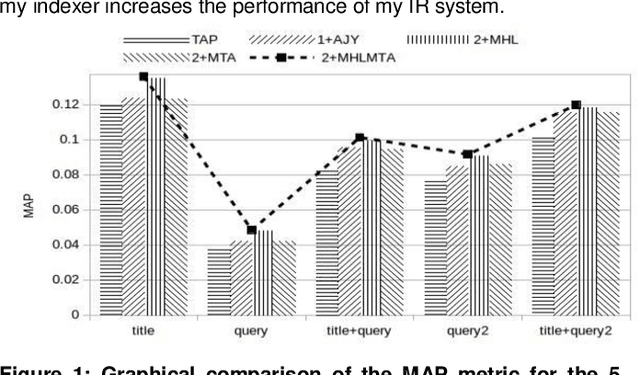
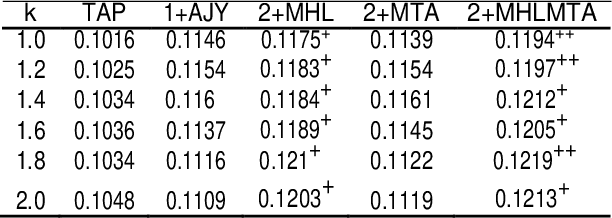
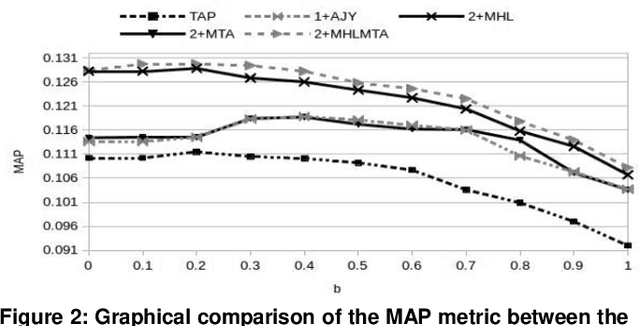
This paper presents a preliminary experimentation study using the CLEF 2017 eHealth Task 2 collection for evaluating the effectiveness of different indexing methodologies of documents and query parsing techniques. Furthermore, it is an attempt to advance and share the efforts of observing the characteristics and helpfulness of various methodologies for indexing PubMed documents and for different topic parsing techniques to produce queries. For this purpose, my research includes experimentation with different document indexing methodologies, by utilising existing tools, such as the Lucene4IR (L4IR) information retrieval system, the Technology Assisted Reviews for Empirical Medicine tool for parsing topics of the CLEF collection and the TREC evaluation tool to appraise system's performance. The results showed that including a greater number of fields to the PubMed indexer of L4IR is a decisive factor for the retrieval effectiveness of L4IR.